—— TiMatch 赛队
\n\n\n——评委唐刘
\n\n> 点评非常惊艳,借助 TiKV 的扩展能力+ TiFlash 的分析能力,想象空间很大,希望能尽快 GA!\n>——评委冯光普
\n\n## 为什么选择图数据库这个方向?\n\n图技术已成为现代数据和分析能力的基础,能够在不同的数据资产中发现人、地点、事物、事件和位置之间的关系。依靠图技术可以快速回答以往需要了解情况并理解多个实体之间的联系和优势之后才能回答的复杂业务问题。\n\n图数据库一直是业界的热门话题。它具有用于语义查询的图形结构,使用顶点、边和属性来表示和存储数据,支持对在关系数据库系统中难以建模的复杂层次结构进行简单快速的检索,优雅地解决了传统关系数据库在针对复杂关系或多表 JOIN 情况运行结果时经常出现的性能或故障问题。我们身边有很多图应用的案例,比如 Google PageRank 算法;LinkedIn 用图管理社交关系,实现好友推荐;Amazon 用图实现实时的商品推荐;银行用图做风控,实现反欺诈和反洗钱等等。\n\n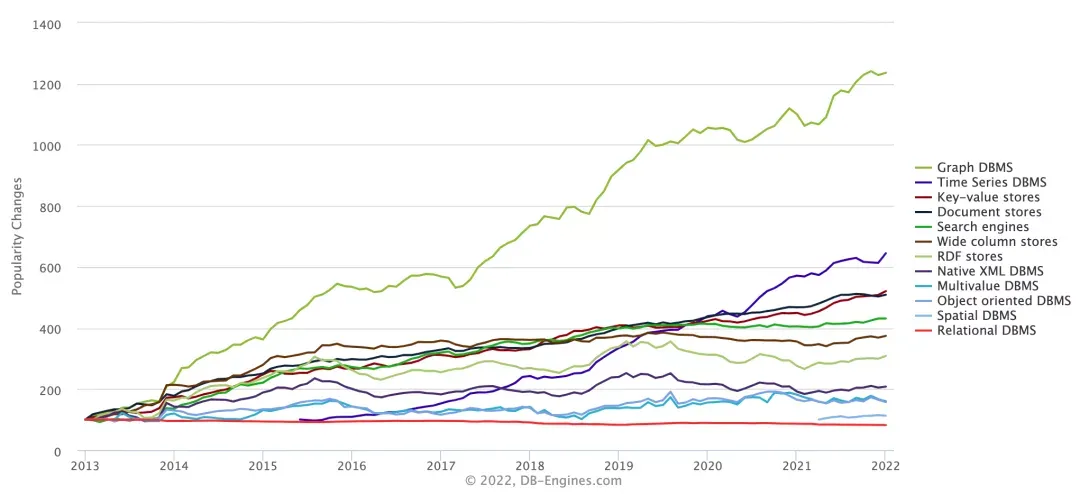\n\n从 DB Engine 的统计数据可以看到,在全球范围内,从 2014 年开始,图数据库的受欢迎程度一直呈现迅猛的上升态势,超越了其他各种类型的数据库。据 Gartner 预测,到 2025 年图技术在数据和分析创新中的占比将从 2021 年的 10% 上升到 80%,该技术将促进整个企业机构的快速决策。\n\n## 从去年的 TiGraph 到 TiMatch 项目实现了哪些提升?\n\n去年的 TiGraph 项目留下了一些遗憾,比如图查询语言不完备,没有接入 TiKV 存储引擎等。这次 Hackathon 赛事中 TiMatch 的任务就是基于 TiDB 和 TiKV 设计语法完备的分布式图数据库雏形,继续探索在 TiDB 之上构建一个成熟且易于使用的图数据库的路径,TiMatch 实现了三大方面的提升。\n\n\n\n### 提升语法的完备性,语言上面引入了 Oracle PGQL 语法\n\n通过在 WHERE 子句后引入 TRAVERSE 子句来进行图遍历,主要是探索看看是否能进行有效整合,是否可以无缝算子复用,语法是否足够简单,子查询是否可以友好地相互嵌套。虽然最终是达到了验证的目的,但是由于数据来源需要依赖底层的 SELECTION 算子,所以进行图计算时不能进行多个边匹配,在子图匹配和最短路径等其他图算法场景中难以构造对应的查询,本质上是语法的完备性存在问题。\n\n好在 2021 年 Oracle 的 PGQL 也在对图查询语言和 SQL 语言的兼容结合进行探索,并且发布了 1.0 的规范。我们直接参考了 PGQL 语法,在 TiDB 中实现了完整的 PGQL parser 提升了查询的完备性,在语法上支持图遍历、子图匹配、TopK、最短路径等图算法,算法的具体实现除了图遍历,今年也实现了最短路径查询。\n\n### 降低系统复杂度和学习成本\n\n简化和完备性的提升直觉上是相悖的,这次的方案在读取路径和写入路径上区别对待,读取路径尝试通过 PGQL 图查询语言来提升查询的完备性,需要引入新的语法规则。在写入路径上,探索出一个全新的方案,去年的方案我们引入了很多新的语法,比如:\n\n- CREATE EDGE/TAG\n- SHOW EDGES/TAGS\n- SHOW CREATE TAG/EDGE\n- DROP TAG/EDGE\n- ALTER TAG/EDGE\n- ...\n\n这些语法对已有的应用程序和 ORM 生态都会有比较大的兼容性冲击,需要进行大量的应用修改和生态兼容。\n\n今年我们在不停的讨论和尝试中找出了一个全新的方式,尽量少地侵入用户层接口,完全在数据库内部完成兼容,将外部兼容问题转换为数据库内部图模式的兼容性问题,局部看工作量变大了,但是更加符合全局最优解。\n\n1. 顶点的 DDL 语法完全不变化。\n1. 变的语法加入了 SOURCE/DESTINATION KEY Column Option,写法和 FOREIGN KEY 是一样的,所以对于开发者和 DBA 都不会有新的学习负担,MySQL 的 Column Option 有接近 20 个,所以新增的只有 Column Option 的 2/20,而 Column Option 的作用域及其小,相关去年的新增几十个语句级别的语法,今年可以说是相当轻量。\n\n是否有可能完全消除新语法?\n是可以的,比如使用以下的方式:\n\n```\nCREATE TABLE (\n a bigint /*T! SOURCE KEY REFERENCES students */,\n b bigint /*T! DESTINATION KEY REFERENCES students */\n)\n```\n\n使用注释的方式可以完全消除对上下游的影响,但是注释在语法解析阶段不容易很早就通过 parser 发现错误,并且很多人会忽略注释,所以这里没有完全追求 100% 的兼容性。\n\n**自动构建图拓扑** \n\n通过引入 SOURCE/DESTINATION KEY 之后,数据库内部就有足够的信息自动构建图拓扑,其实从图数据库的角度来说,主要是完成三部分工作:\n\n- 图数据存储\n- 图拓扑的维护\n- 图算 fan\n\n图数据(顶点)的存储和传统数据存储并不需要引入过去的差异性,大多是内部存储细节和 Key-Value 设计的差别,如何维护图拓扑和已有数据,如何新增图拓扑是一个新的问题,在本次 Hackathon 我们提出了一个新的方案,可以对已有数据通过 ALTER 语句和 SOURCE/DESTINATION KEY 信息自动构建已有数据的图拓扑,免去任何的数据迁移和业务改造过程。\n\n### 从单机存储 unistore 到 TiKV+TiFlash,提升数据集支持规模\n\nHackathon 2020 由于时间所限使用了用于跑单元测试的 unistore,而今年引入 TiKV 存储引擎,运算性能也极大的提升,在 Demo 演示中可以看到,100 万点的单源 6 度人脉查询只需要 200 毫秒,相比去年在 unistore 上 10 万数据需要 6 秒来说,性能提升极为明显。未来还可以引入 TiFlash,利用 TiFlash 的 MPP 能力进行大规模图计算。\n\n## 通过两届 Hackathon 的迭代在 TiDB 上实现图数据库 TiMatch 探索出了一条怎样的路径?\n\n- 首先是兼容 TiDB 已有的功能、已有的数据和已有的生态(DM/CDC/Lightning/ORM/ 等)\n- 考虑自适应图 DDL 和已有数据自动兼容,从而自动构建图拓扑\n- 支持 TiKV 存储引擎,进行完整的 Parser 实现\n- 完善图查询:遍历、路径过滤、最短路径、谓词下推、Coprocessor 下推等\n- 事务、索引、嵌套子查询等方面的考量\n\n## 在 Hackathon 上获得二等奖的好成绩最主要的原因是什么?\n\n最主要的原因是这个项目站在了“三层”巨人的肩膀上面,才能呈现在大家的面前\n\n一层:思考上延续了 TiGraph,实现和语法上是一个垫付,语法上完备了许多 \n\n二层:在 TiDB 和 TiKV 既有框架上进行实现,扩展图数据库,拓展 TiDB 的场景 \n\n三层:引入了全新的语法,完成对图数据库查询的万备汛,从 Oracle PGQL 延伸过来,原版的语言有些地方比较啰嗦,不是很考究,对其进行了一定的修改,变得更加优雅\n\n其次,团队的明确分工,队员之间的彼此信任和无缝协作\n- 龙恒、夏雨杰、刘东坡:着重实现 TiDB 侧的语法分析、AST、Parser、写入路径等\n- 柏佳辰:负责 TiKV 侧算子下推,并承担队宣的角色(制作宣传视频 + PRC PPT 等)\n\n## 作为一名北美的选手首次参加 TiDB Hackathon 有什么感受?\n\n柏佳辰,GitHub ID:JeepYiheihou\n\n哈佛硕士毕业,现就职于 AWS 温哥华,从事 ElasticCache 缓存数据库核心研发工作,利用假期参与了此次 Hackathon。整个 Hackathon 的过程对我来说是一次开心的体验。赛队全情投入,竞争特别激烈,赛制给足了时间让我们进行思考和创意,很多项目的完成度很高,也涌现了不少实用的项目。评委们提了不少犀利的问题,可以看出他们不止看到当下项目的闪光点,更会以长远的眼光去发掘这些项目在未来的方向和价值,我觉得评委们也是非常 enjoy 这个过程。\n\n**全栈程序员是怎么炼成的?**\n\n因为热爱。赛队的视频以及 RFC 的 PPT 都是出自柏佳辰之手。之前学过八年的建筑学,做精美的 PPT 是必修课,做视频也是自学的。这次赛队的宣传视频,借鉴了黑客帝国的主题,有一些帧用的是 processing 进行编程的可视化,用了 pathon 语言呈现了图、网格和网络。在转行做程序员之前,对编程很感兴趣,自学学编程,接触过使用可视化工具来制作视频,刚好这次用上了。\n\n> 不管做转行前或者转行后的任何事情,做职业决定的时候,要确定你是真的热爱它。热爱它,你就会对这件事情全神贯注,投入精力进去。转行做程序员大家都知道怎么去做准备,重要的不是第一步你怎么跨入这个行业,重要的是怎么把后面的每一步都做好。\n\n工作之外,柏佳辰的爱好非常广泛:喜欢画画,画了一系列油画棒的画;喜欢摩托车;喜欢去健身房锻炼身体;喜欢看书,最近在看哲学的书,比如《理想国》。最大的爱好还是写代码和看论文,这也是为什么转行做程序员,想要尝试一些有挑战的事情,去解决一些问题,并且享受解决问题的过程以及收到的反馈。 \n\n> 延展阅读:点击查看更多 [TiDB Hackathon 2021 优秀项目分享](https://pingcap.com/zh/blog/?tag=TiDB%20Hackathon%202021)","date":"2022-01-18","author":"PingCAP","fillInMethod":"writeDirectly","customUrl":"when-tidb-meet-graph-database-2","file":null,"relatedBlogs":[]}}}, "staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}