{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/tiflash-source-code-reading-7",
"result": {"pageContext":{"blog":{"id":"Blogs_416","title":"TiFlash 源码阅读(七)TiFlash Proxy 模块","tags":["TiFlash 源码阅读"],"category":{"name":"产品技术解读"},"summary":"本文主要介绍的是 TiFlash Proxy 模块的实现,即 TiFlash 副本是如何被添加以及获取数据的 。","body":"## Overview\n\n在前面的介绍中,大家应该对 TiFlash 如何存储、计算有了一定的了解。那么今天我们主要讲解一下 TiFlash 如何被添加副本,以及获得数据的。\n\n如何对一张表添加一个 TiFlash 副本呢?是通过下面的指令\n\n`ALTER TABLE t SET TIFLASH REPLICA 1`\n\n也就是说,此时这张表对应的数据已经在集群中的 TiKV 上被存储了,我们实际上需要的是将数据从 TiKV 导入到 TiFlash 的存储中。\n\n有很多方案可以做到这一点,我们有一个很棒的产品 TiCDC,指定 TSO,它可以捕捉 TiKV ChangeLog,并将 TSO 时刻对应的状态同步到下游支持 MySQL 协议的数据库中。但 TiDB 作为一个 HTAP 数据库,我们希望 AP 部分的 TiFlash 能够提供实时一致性。例如在读取时,我们只需要 resolve 直接相关的一些 Region,而不是等待一个表甚至多个表的 resolve ts。\n\n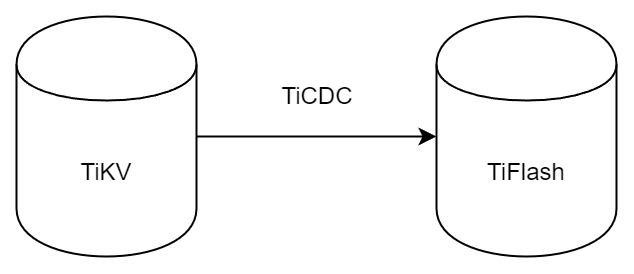\n\n因此,TiFlash 选择将自己作为一个“特殊的” TiKV 节点加入 TiDB 集群。这样的特殊性是必要的,例如 TiFlash 需要在合适的地方做行转列,或者让 TiKV 在行为上不依赖于底层的 RocksDB 存储等。这个特殊的 TiKV,就是 TiFlash Proxy。目前它是作为一个 TiKV fork 而存在的,但我们计划在未来将它作为一个 depend TiKV 的独立项目来维护。\n\n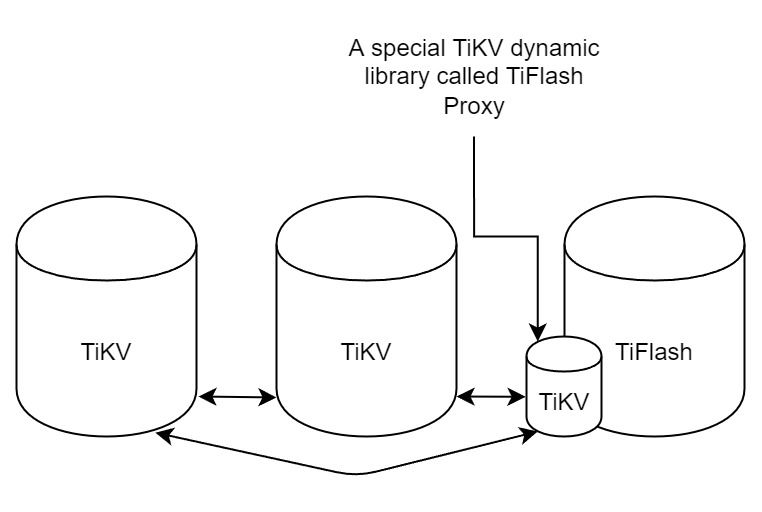\n\n在我们的官网上,给出了整个 TiFlash 的体系结构,其中 Raft Store 附近的模块就是 TiFlash Proxy。可以看到,它会和 PD 通信注册自己作为一个特殊的 TiKV store,加入 TiKV 中的各个 Raft Group 进行复制,将 TiKV 传来的数据 apply 给 TiFlash。\n\n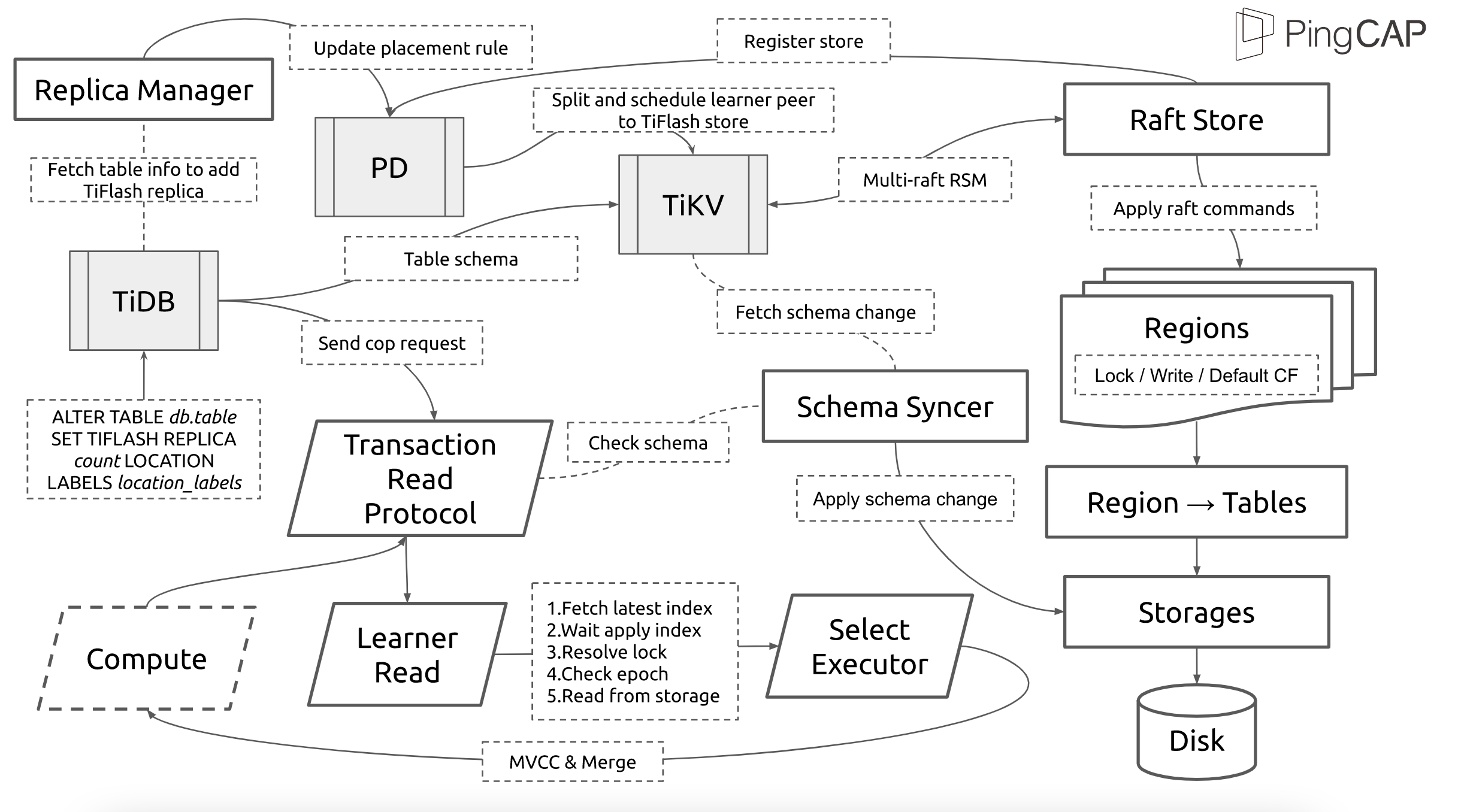\n\n但相比之下,我很喜欢用阿凡达这部电影中的纳威人和地球人作为比喻。没错,如果把 TiKV 比作纳威人,那么 TiFlash 就是进入纳威星球的地球人。地球人需要将自己伪装成纳威人的样子才能融入纳威族。因此便有了阿凡达,也就是 TiFlash Proxy。Proxy 满足 TiKV 协议对 Store 的定义,从而可以向 PD 注册识别自己。地球人可以操纵阿凡达,TiFlash 也可以控制 Proxy 的行为,特别是在 Apply 部分,将在稍后介绍。但 Proxy 是以 Learner 角色加入的 Raft 集群,不参加任何 Raft 的决议,所以即使我们搞砸了,Proxy 并不会像阿凡达一样给 TiKV 集群带来破坏。当然了,Raft Leader 需要往 Proxy Replicate 数据,这本身会造成一些负担。\n\n下面我们来具体介绍 Proxy 的实现。\n\n## FFI 机制\n\nTiKV 是用 Rust 实现的,而 TiFlash 是用 C++ 实现的。TiFlash Proxy 对 TiKV 进行改造,并作为一个动态链接库给到 TiFlash。为了实现 zero-overhead 的抽象,我们使用 Rust 的 FFI 实现和 C++ 的相互调用。\n\n使用 FFI 时需要小心处理 safe 和 unsafe code 的边界。例如需要保证共享对象的 layout 是一致的。此外,因为 FFI 机制通过指针进行交流,还需要 Pin 住这些对象,防止 Rust 将其移动。\n\n因此,Proxy 提供了 gen-proxy-ffi 模块来自动化这一过程。C++ 端和 Rust 端共享一个 ProxyFFI.h,任何新增的 FFI 调用只需要在该接口中定义一遍,调用 gen-proxy-ffi 模块即可生成 Rust 端的接口代码。\n\n在接口头文件之外,还有一个 @version 文件,存放接口文件的校验码,当接口文件变动时,@version 文件的内容也会被修改,TiFlash 在加载 Proxy 时,会校验 @version 中的内容,如果内容不一致,说明 proxy 的版本不匹配,程序会退出。\n\n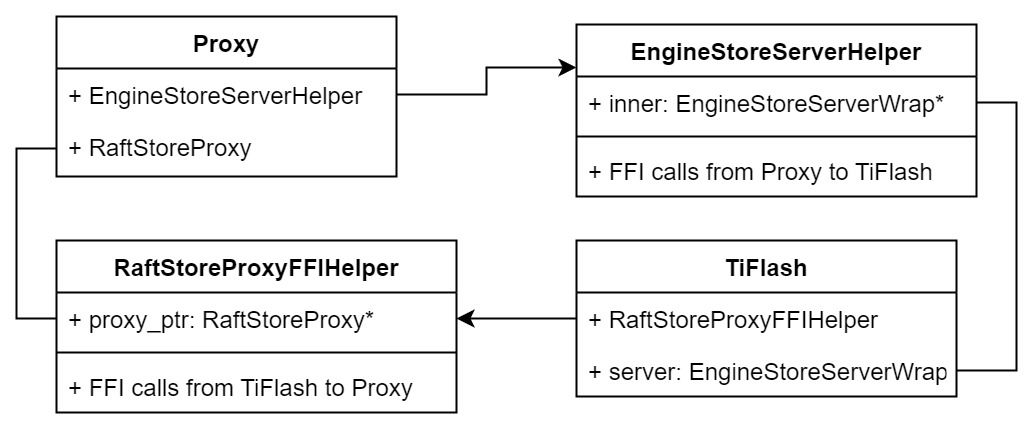\n\nTiFlash 和 Proxy 会各自将 FFI 函数封装入 Helper 对象中,然后再互相持有对方的 Helper 指针。其中 RaftStoreProxyFFIHelper 是 Proxy 给 TiFlash 调用的句柄,它封装了 RaftStoreProxy 对象。TiFlash 通过该句柄可以进行 ReadIndex、解析 SST、获取 Region 相关信息以及 Encryption 等相关工作。EngineStoreServerHelper 是 TiFlash 给 Proxy 调用的句柄,Proxy 通过该句柄可以向 TiFlash 写入数据和 Snapshot、获取 TiFlash 的各种状态等。\n\n这些结构的在 TiFlash 启动时进行初始化,只有当初始化成功后,TiFlash 才会进入正常服务。\n\n## 添加 TiFlash 副本\n\n下面我们看看,Proxy 是如何和 PD 交互,加入某个 Raft Group,并被注册为对应 Region 的一个特殊的 TiKV peer 的\n在执行 ALTER TABLE SET TIFLASH REPLICA 1 后,TiDB 将向 PD 创建一个 id 为 table-{tid}-r 的 Rule,这个 Rule 的作用是告诉 PD 给这个表对应的 key range 添加1个 learner peer。并且设置 label_constraints 为 engine in [\"tiflash\"] 让这个 rule 只对 TiFlash store 生效。但需要注意的是,我们设置的 key range 会将表中和索引相关的部分过滤掉,这样 PD 不会将 TiKV 自己索引对应的 Region 调度给 TiFlash。\n\n```bash\ncurl http://127.0.0.1:2379/pd/api/v1/config/rules/group/tiflash\n[\n {\n \"group_id\": \"tiflash\",\n \"id\": \"table-69-r\",\n \"index\": 120,\n \"start_key\": \"7480000000000000ff455f720000000000fa\",\n \"end_key\": \"7480000000000000ff4600000000000000f8\",\n \"role\": \"learner\",\n \"count\": 1,\n \"label_constraints\": [\n {\n \"key\": \"engine\",\n \"op\": \"in\",\n \"values\": [\n \"tiflash\"\n ]\n }\n ],\n \"create_timestamp\": 1657621816\n }\n]\n```\n\n在这个 rule 生效后,对应 key range 中的 Region 就可以被调度到 TiFlash 上了。此时会走 replicate peer 逻辑,Pd 只会告知待创建 peer 的 region id 和 peer id,而所有实际的数据将会后续通过 Region Leader 发送的 Snapshot 过来。\n\n而当 Pd 将某个 Region 调度走后,会触发 destroy peer,Proxy 也会将这个消息传递给 TiFlash,通知 TiFlash 将对应的 Region 删除。\n\n需要注意的是,Region 调度应当和数据库的 DDL 区分开来。诸如 DDL 之类的信息,实际上是 TiFlash 通过 TiKV 的 client-c 主动去拉的,并不在 Proxy 的同步范围内。\n\n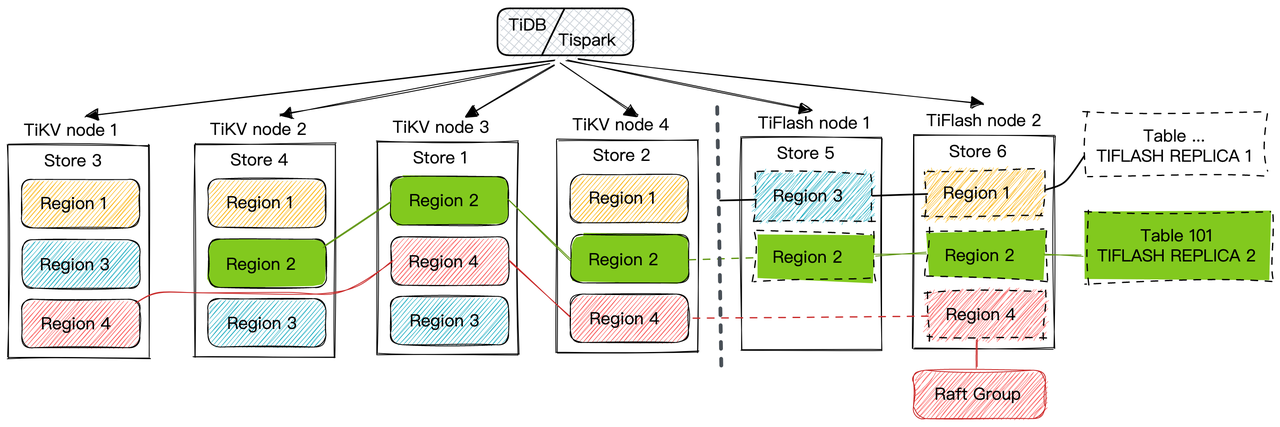\n\n## Proxy 的写入\n\n现在 TiFlash 已经通过 Proxy 加入了成为了一个副本,那么每个 Region 的数据都会从 Raft Group Leader 被 replicate 过来。当对应的 log entry 被 commit 后,就会被 ApplyFsm 处理到。下面我们就来看看,Proxy 是如何处理这些传过来的数据的。\n\n### TiFlash as a KvEngine\n\nTiKV 的盘上存储主要可以分为四部分,两个 Engine、SnapshotMgr 和 PlaceholderFile。其中 SnapshotMgr 用来管理 Raft Snapshot。PlaceholderFile 用来预留空间做 recovery。\n\n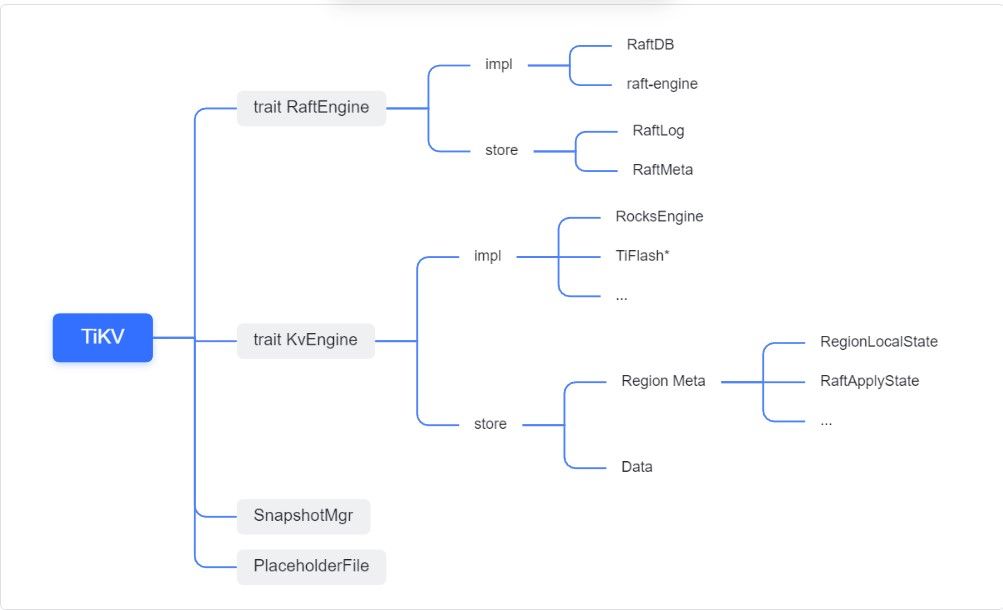\n\n下面来看两个 Engine,它们被抽象为两个 engine trait:KvEngine 和 RaftEngine。\n\nRaftEngine 中存储 RaftLog、以及 RaftLocalState 等和 Raft 算法直接相关的状态,它有基于 RocksDB 的实现 RaftDB 以及我们刚 GA 的组件 raft-engine 的实现。 \n\nKvEngine 中目前存储 RegionLocalState、RaftApplyState 这些和 Region 以及 Apply 相关的 meta 信息,以及真实写入的数据。\n\n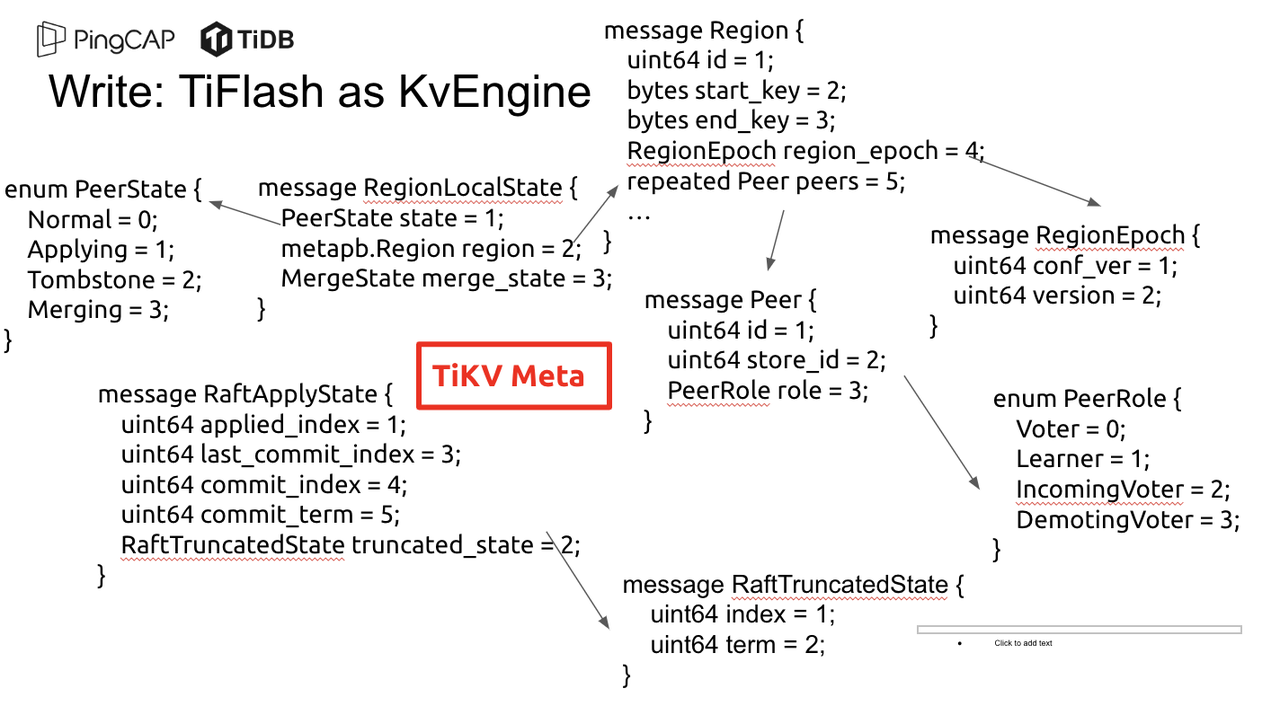\n\n简单介绍一下这些 meta 数据:\n\n1.RegionLocalState 主要包含 Region 的 range、epoch、各个 peer 以及当前 Region 状态,其中\n\n - RegionEpoch 会在 ConfChange,以及 Split 和 Merge 的时候发生变化,在处理 Raft 消息时,我们会校验 RegionEpoch 并拒绝掉过期的消息\n - PeerState 状态比如 Normal、Applying、Merging、Tombstone等。\n \n2.RaftApplyState 中包含 apply index、commit index、truncated state 等信息\n\n - apply index 表示当前 apply raft log 的进度。如果 apply raft log 在 persist 前发生宕机,那么重启后就会从较老的 apply index 开始重放日志。所以 apply raftlog 是需要支持幂等的,对于一些特殊的不支持幂等的指令,就需要 apply 完立刻 persist 并 fsync。\n - 因为日志不可能无限增长,所以 TiKV 会定期做 CompactLog 来 gc raft log。truncated state 表示上次做完 CompactLog 后现有日志的头部。\n \n通过抽象两个 trait,TiKV 赋予了我们定制存放 RaftLog 和 KV 数据的能力。总体上 TiFlash 可以被看做一个 KvEngine。但是,目前 TiKV 使用单个 RocksDB 实现 KvEngine,即 RocksEngine,并对此做出一些针对性的优化;而 TiFlash 使用 DelteTree 存储列式数据,并且支持多盘部署。在场景上的差异导致我们不能简单把 TiFlash 封装成 KvEngine。\n\n实际上,Proxy 在 KvEngine 的实现中区分了写入。对于 meta 信息,Proxy 保留了 RocksEngine 去存放它们,这样在 Proxy 侧才能正常运行 Fsm。但是对于写入的数据,我们通过之前说的 FFI 接口,将它们传给 TiFlash 处理,Proxy 不会像 TiKV 一样把数据重复写到 RocksEngine 中。因为最终我们读请求,是由 TiFlash 直接 serve,而不会转发给 Proxy 了。所以其实 KvEngine 中只有 meta,没有真实数据。\n\n\n\n### TiKV Write Pattern\n\n下面简单介绍下 TiKV 的写流程。TiKV 中有两个 BatchSystem,BaftBatchSystem 用来维护 Raft 状态机,它持有 ApplyBatchSystem。ApplyBatchSystem 负责写入被 Commit 的数据。ApplyBatchSystem 由 Poller 驱动,Poller::poll 中有个循环会不停驱动唯一的 control 以及若干的 normal 状态机。一个 normal 状态机实际对应一个 Region,在收到对应消息后,会调用 handle_normal 处理对应的 normal 状态机。具体到每个 normal 状态机中,有一个 WriteBatch 机制。每批的写由 prepare_for 开头,finish_for 结尾,中间伴随着多次 commit,表示 write 到盘上。对于不同的情形,会在 write 完做 fsync 或者不做。\n\n此外,在一轮循环的前后,都会分别调用 PollHandler::begin 和 PollerHandler::end,这里面会包含 write 和 fsync 的逻辑。也就是 BatchSystem 的意思,将一系列副作用落盘。\n\n```python\nwhile True:\n let (control_fsm, normal_fsms) = fetch_fsm()\n PollHandler::begin()\n handle_control()\n for normal_fsm in normal_fsms[..max_batch_size]:\n // In handle_normal()\n normal_fsm.prepare_for()\n normal_fsm.commit()\n ...\n normal_fsm.commit()\n normal_fsm.finish_for()\n PollHandler::end()\n```\n\n### Proxy 需要处理的写入\n\n为了详细阐释这个问题,我们先来看看 Proxy 实际要处理什么写入。Proxy 处理的写入主要分为普通的 KV write、Admin Command 以及 IngestSST。这些写入会被存放在内存中,并定时落盘。对于其中已提交的数据,会被写入到列式存储 DeltaTree 中;未提交的部分则由 RegionPersister 负责持久化到 PageStorage 上。\n\n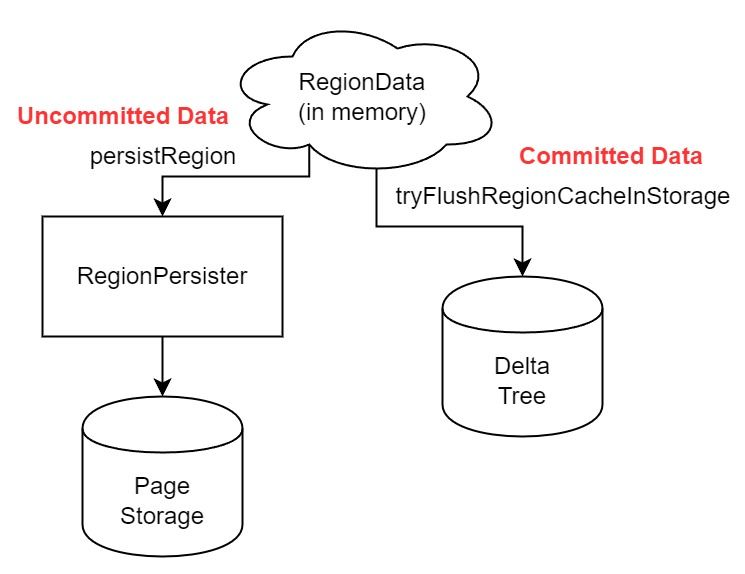\n\n普通的 KV write,就是一组 Put、Delete 和 DeleteRange 命令。对于这样的命令,TiKV 会定期刷盘存入自己的 RocksEngine 中。而 Proxy 直接通过 FFI 将对应的写入传递给 TiFlash,而不会往自己的 RocksEngine 中做任何的写入。\n特别地,DeleteRange 命令一般被 TiKV 用来删除表,但因为 TiFlash 自己会维护一份 schema,可以在 drop 时根据 gc safe time 自行删除表,所以 proxy 不需要将 DeleteRange 转发给 TiFlash。\n\nAdmin Command 用来维护 Raft 状态机,例如 CompactLog 用来 gc raft log,BatchSplit 用来将一个 Region 分成多个 Region。这些 Admin 通常可能涉及 meta 信息的修改,例如 Apply state。对于这些命令,我们会在 Proxy 端按照 TiKV 的方式执行得到结果,并传递给 TiFlash 侧。TiFlash 侧根据结果来更新自己的 meta 信息。简而言之,就是 Proxy 执行一遍,然后把题目和答案都拿给 TiFlash 抄。好处是,我们不需要在 TiFlash 端再复写一遍处理 Admin 的逻辑了。\n\n特别注意,有一些 Admin Command 我们是无法处理的,需要被 Skip 掉。例如 ComputeHash 和 VerifyHash 被用来校验存储的一致性。但是因为 TiKV 和 TiFlash 使用的底层存储不同,这样的校验是无法被完成的,所以 Proxy 会跳过这些命令的处理。另外诸如 CompactLog 的 Admin Command 有可能被 Skip 掉,这个在下文会详细介绍。\n\n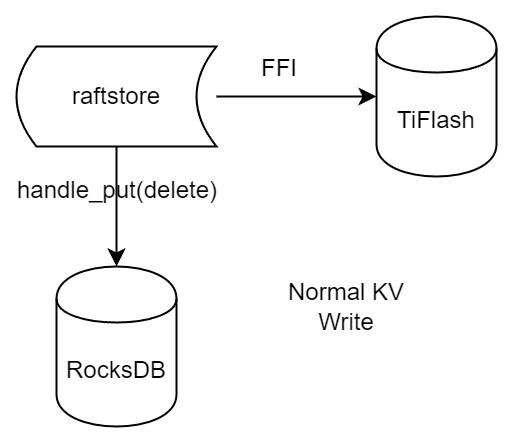\n\n此外,还有一种特殊的写入 IngestSST。IngestSST 是将一系列 SST 文件整体写入,可以将它看做用 SST 承载的 KV write。但实际上 IngestSST 中一般包含 write 列和 default 列。熟悉 percolator 算法的同学应该知道,它们分别对应于 commit 记录和真实数据。因为目前 IngestSST 大多是在 BR/Lightning 导入已提交的数据,所以 lock 列一定是空的。因为 TiKV 的存储引擎是 RocksDB,所以直接把 SST 文件插入到较深的 level 可以取得性能上的优化。但由于 TiFlash 使用 DeltaTree 做列式存储,在处理 IngestSST 时需要读出 KV 对并做行转列,相比 TiKV 的开销还是比较大的。\n另外,Apply Snapshot 也可以被视为广义上的写入。一个 Snapshot 实际上也是一系列 SST 组成的,所以在 Apply Snapshot 时同样需要做行转列。但我们不能混淆 IngestSST 和 Apply Snapshot。IngestSST 是一个特殊的写,而 Snapshot 是 Raft 算法中一个和写入平行的概念,当某个 Peer 新被创建,或者 raft 日志落后较多时,Leader 就会发送一个 Snapshot 给它以快速追赶进度。一个 Region peer 在做 Snapshot 的时候,是不能处理写入的。\n\n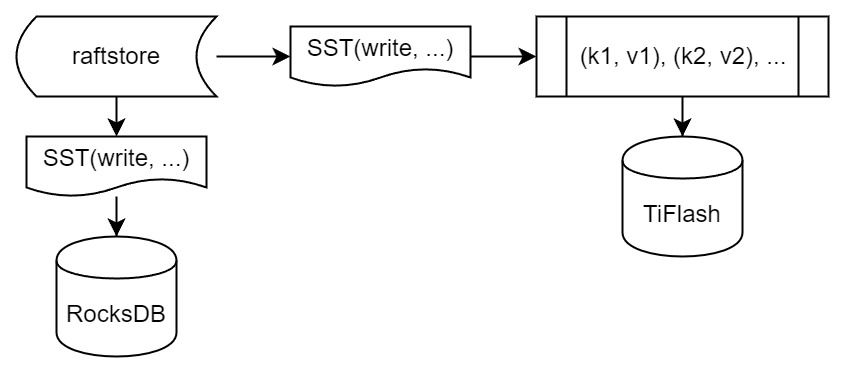\n\n此外,Proxy 还需要处理一个特殊情况,即 empty entry。根据 TiKV 的实现,如果新 Leader 当选,或者在 TransferLeader 时尝试 ReadIndex,那么会产生一个空的 entry。前者的话,前者的话,根据 Raft 论文,不能 commit 来自较旧term 的日志 entry,所以新 Leader 就需要提交一个 Empty Entry 来推进 commit。后者的话,是新 Leader 上任后需要 propose 一个空 entry 来更新自己的 commit_index 并续约 lease。这个空 entry 中没有任何的写入数据,TiKV 侧可以不做额外处理,但这个空 entry 却需要被转发给 Proxy 用来推进状态机。否则可能后续 wait index 就会超时。\n\n类似的,如果一个命令被执行失败了,我们同样要推进它的 apply index。这里的失败例如在 PrepareMerge 后,epoch 变大了,后续不匹配的 write 会被跳过。但基于同样的原因,我们依然要将被推进的 apply index 传递给 TiFlash 侧。\n\n### 针对 TiFlash 场景做出的优化\n\n#### Persistence\n\n下面我们介绍对于 TiFlash 的场景,Proxy 需要对 apply 过程做哪些优化性质的修改。\n\n首先需要注意到,TiKV 对 write 和 fsync 的频率的容忍度是比 TiFlash 高的,这是因为 RocksDB 落盘只需要 sync 一下 WAL 即可。而 TiFlash 存储,比如 DeltaTree,是没有单独的 WAL 的。因为 raftlog 就是 TiFlash 的 WAL。所以 TiFlash 落盘开销大,支持不了 TiKV 这样的频率。\n\n为了减少这样的开销,Proxy 有两方面调整优化。首先,如果 TiKV 的一个 WriteBatch 中只有普通的 kv write,那么在 commit 和 finish_for 时,Proxy 不会将更新后的 Apply State 和数据(其实这些数据也没写到 Proxy 里面)落盘。这样是安全的,如果发生宕机重启,那么会通过 RaftLog 从上次 persist 的 Apply Index 重放。容易看到,这种方案要求 Raft log 不能过早被之前提到的 CompactLog 给 truncate 掉,这就涉及第二个优化。\n\n首先,出于安全性考虑,我们必须在执行 CompactLog 时让 TiFlash 刷一次盘把数据彻底写入,如果出于种种原因,TiFlash 拒绝或者失败,我们就得回滚 CompactLog。这里回滚的意思是,将 truncate state 回滚到之前的状态,不触发 gc 任务,但同样的,apply index 还是要推进的。因为开销大,所以这个刷盘的频率不能太高,并最好由 TiFlash 来控制。因此在执行完 CompactLog 后,FFI 到 TiFlash 端时,我们根据 row、size 和随机的超时时间来决定是否落盘,并最终决定 Proxy 是否回滚。方便起见,我们处理在 TiKV 每次定时的 CompactLog 时进行这样的判断。当然,TiFlash 可以在除 CompactLog 的其他写入 Command 时都返回 Persist,让 Proxy 去 persist apply state,但目前没有这么做。\n\n除了之前讨论的 CompactLog 之外,剩下的大部分 Admin Command,它们基本也都涉及对 meta 信息的修改。对于这些 Command,Proxy 和 TiKV 的处理方式一样,都会让 TiKV 触发一次落盘。\n\n对于普通 kv 写,能够延迟 persist,原因是我们禁止了一部分 CompactLog 去 schedule gc raft log 的任务,但对于 IngestSST 则不然。因为 SST 文件不像 Raftlog 一样通过 CompactLog 来 gc,TiKV 会在每次 commit 之后删除 SST,删除了数据就没了,所以原则上在 IngestSST 之后就立即 Persist。看起来开销很大是吧,所以,Proxy 对于 IngestSST 的写入也有优化。从性能来考虑,我们是可以直接生成 DTFile 到 DeltaTree 中的,从而避免很大的 default 列中的真实数据以 Region 形式存到 RegionPersister 中。但由于在某些时候,IngestSST 的 write 列或者 default 列不能完全 match,所以我们只能 flush 一部分到 DeltaTree 中,而将某些多出来的数据先存留在内存中。为了让这一部分数据 recoverable,我们会延迟 SST 文件的删除,直到我们确定 SST 中所有的数据已经持久化了。\n\nProxy 将 normal write 和 admin command 的两种写入抽象为了 fn_handle_write_raft_cmd 和 fn_handle_admin_raft_cmd 两个 FFI。它们会返回一个枚举,分别为 None、Persist 和 NotFound。一个 None 的返回值,说明 TiFlash 不希望将数据和 meta 信息立即落盘;一个 Persist 的返回值则相反。另外的 NotFound 返回值表示 Region 没有找到。我们有其他的 FFI 处理 IngestSST 等,在这里就不介绍了。\n\n#### Apply Snapshot\n\n对于 Apply Snapshot,TiKV 可以在 apply 的时候直接将收到的 sst 文件 ingest 到自己的 RocksDB 中。但因为 TiFlash 并不用 RocksDB,而是有自己的列式存储,所以会有一个比较耗时的行转列过程。TiKV 是将收到的 Apply Task 放到一个专门的 Apply Queue 中,并用一个单独的 RegionRunner 线程中串行地 Apply Snapshot,如果将行转列放在这个过程中,会极大降低效率。因此,Proxy 为 Apply Snapshot 过程引入一个 Pre-handle 步骤。在收到 Pending 的 Snapshot 后,会进入该步骤中,将 Snapshot 加入一个线程池中并发地进行行转列。\n\n在 Apply Queue 处理到 Snapshot 时,会去 retrieve pre handle 的结果。所以如果 pre handle 没有结束, apply snapshot 依然会被 block。但因为我们使用了线程池并发处理多个 snapshot 的 pre-handle,所以减少了等待的时间,\n\nApply Snapshot 过程也是一个 FFI 传递给 TiFlash,这个过程就是主要调用 checkAndApplySnapshot 函数进行校验、落盘以及修改 meta。\n\n同理,对于 IngestSST 写,也可以有类似的优化。但其实 TiKV 中已经有一个 low-priority pool 了,所以 Proxy 并没有对这一块做更改。\n\n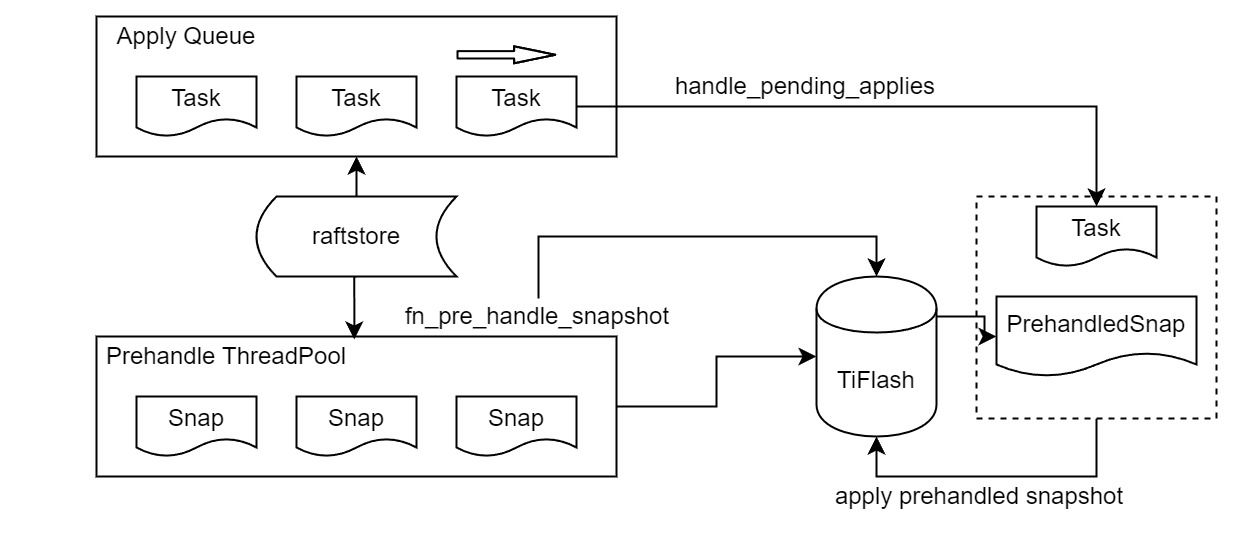\n\n## Proxy 的后续发展\n\n目前,Proxy 主要是 fork 的 TiKV 并修改产生的,这导致我们不太容易 Follow TiKV 的最新特性。因此,我们目前正在打算基于 TiKV 的 engine traits 和 Observer 机制做一个新的 Proxy。这样能够摆脱对 TiKV 源码级的依赖。\n\n在这之后,Proxy 更可以被看做是一个 TiKV 上支持异构 KvEngine 的框架,由此可以产生很多有趣的 idea。我们欢迎大家来基于该框架来继续碰撞出新的火花。\n\n## 问题回复\n\n1.为什么在 TiFlash 侧也有 Region、以及对应的 ApplyState 等状态信息,不能复用 Proxy 中的么?\n\n- 这实际上是个历史的设计问题。首先 Proxy 通过 FFI replicate 过来的信息已经足以维护 TiFlash 侧的 apply 状态了。Proxy 侧对状态的修改,通过 None/Persist 就可以维护。\n- 如果我们不再 TiFlash 侧维护一份,那么就需要频繁读和写 Proxy 侧的 Apply 信息,这会产生较多的 FFI 调用,以及可能的编解码的工作\n \n2.TiFlash Proxy 是否可以被静态链接到 TiFlash 中呢\n \n- 由于 Proxy 和 TiFlash 使用不同的 OpenSSL 的实现,而 Rust 又很喜欢打包自己的依赖,这可能在链接期产生重复符号的问题。\n- 但我们也有尝试一些方案,例如 rename 掉 Proxy 中的符号,目前来看是可行的\n \n3.TiFlash Proxy 如何 pick TiKV 的新特性和 bugfix\n- 目前 Proxy fork 了 TiKV,所以是源码级的依赖。跟进 TiKV 的大版本主要靠 merge release。此外,对于一些 critical 的 bugfix,我们会从 TiKV 做 cherry pick\n- 但这样的管理非常麻烦,并且也难以追上 TiKV 的更新。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n","date":"2022-08-25","author":"骆融臻","fillInMethod":"writeDirectly","customUrl":"tiflash-source-code-reading-7","file":null,"relatedBlogs":[{"relatedBlog":{"body":"## 背景\n\n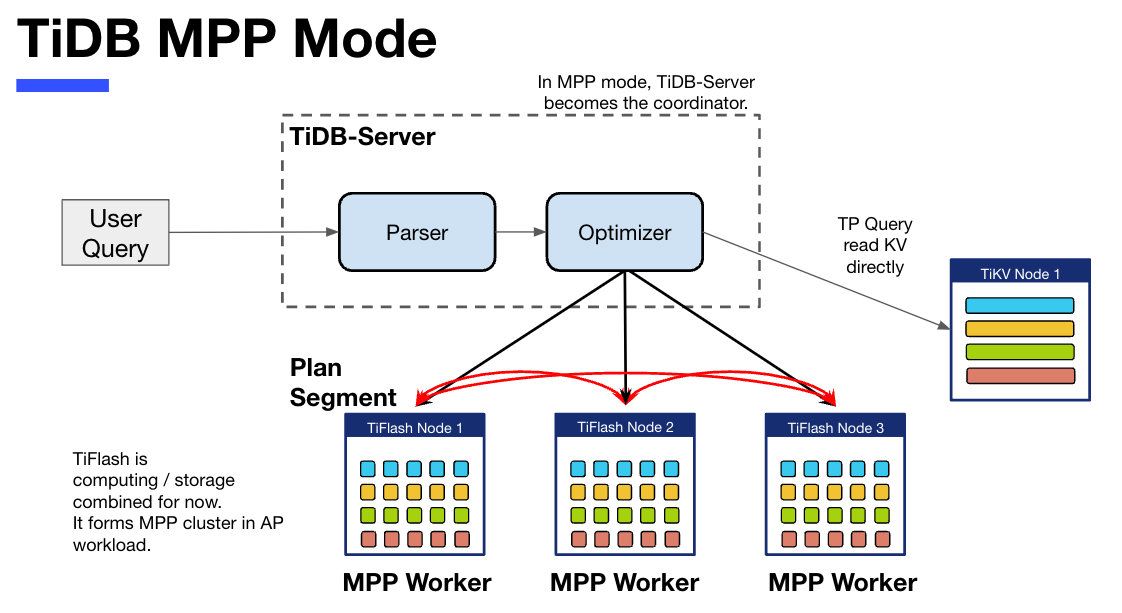\n\n本系列会聚焦在 TiFlash 自身,读者需要有一些对 TiDB 基本的知识。可以通过这三篇文章了解 TiDB 体系里的一些概念《[说存储](https://pingcap.com/zh/blog/tidb-internal-1)》、《[说计算](https://pingcap.com/zh/blog/tidb-internal-2)》、《[谈调度](https://pingcap.com/zh/blog/tidb-internal-3)》。\n\n今天的主角 -- TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,通过 Raft Learner 协议异步复制,但提供与 TiKV 一样的快照隔离支持。我们用这个架构解决了 HTAP 场景的隔离性以及列存同步的问题。自 5.0 引入 MPP 后,也进一步增强了 TiDB 在实时分析场景下的计算加速能力。\n\n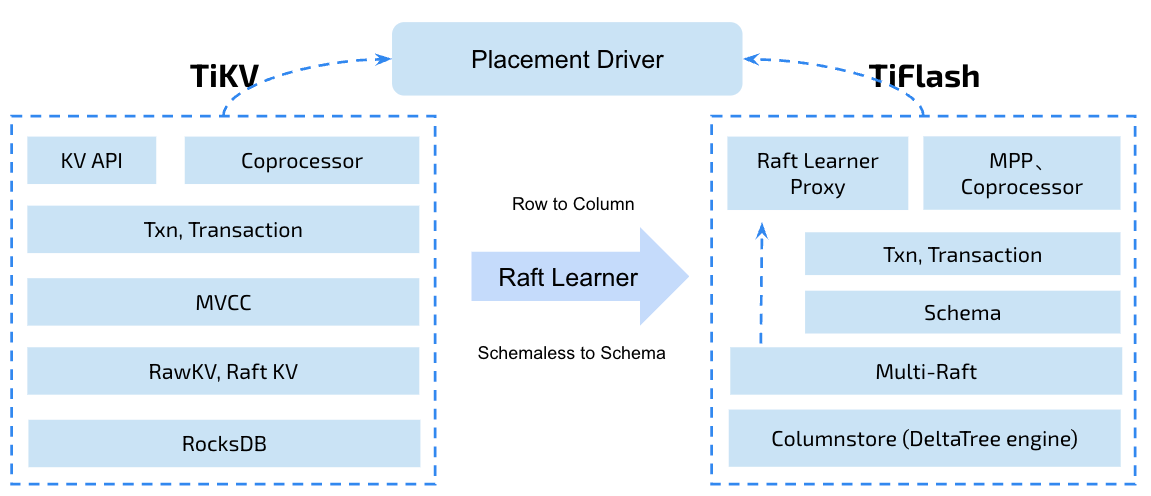\n\n上图描述了 TiFlash 整体逻辑模块的划分,通过 Raft Learner Proxy 接入到 TiDB 的 multi-raft 体系中。我们可以对照着 TiKV 来看:计算层的 MPP 能够在 TiFlash 之间做数据交换,拥有更强的分析计算能力;作为列存引擎,我们有一个 schema 的模块负责与 TiDB 的表结构进行同步,将 TiKV 同步过来的数据转换为列的形式,并写入到列存引擎中;最下面的一块,是稍后会介绍的列存引擎,我们将它命名为 DeltaTree 引擎。\n\n有持续关注 TiDB 的用户可能之前阅读过 [《TiDB 的列式存储引擎是如何实现的?》](https://zhuanlan.zhihu.com/p/164490310) 这篇文章,近期随着 [TiFlash 开源](https://pingcap.com/zh/blog/tiflash-is-open-sourced),也有新的用户想更多地了解 TiFlash 的内部实现。这篇文章会从更接近代码层面,来介绍 TiFlash 内部实现的一些细节。\n\n这里是 TiFlash 内一些重要的模块划分以及它们对应在代码中的位置。在今天的分享和后续的系列里,会逐渐对里面的模块开展介绍。\n\n```CSS\n# TiFlash 模块对应的代码位置\n\ndbms/\n\n└── src\n\n ├── AggregateFunctions, Functions, DataStreams # 函数、算子\n\n ├── DataTypes, Columns, Core # 类型、列、Block\n\n ├── IO, Common, Encryption # IO、辅助类\n\n ├── Debug # TiFlash Debug 辅助函数\n\n ├── Flash # Coprocessor、MPP 逻辑\n\n ├── Server # 程序启动入口\n\n ├── Storages\n\n │ ├── IStorage.h # Storage 抽象\n\n │ ├── StorageDeltaMerge.h # DeltaTree 入口\n\n │ ├── DeltaMerge # DeltaTree 内部各个组件\n\n │ ├── Page # PageStorage\n\n │ └── Transaction # Raft 接入、Scehma 同步等。 待重构 https://github.com/pingcap/tiflash/issues/4646\n\n └── TestUtils # Unittest 辅助类\n```\n\n\n\n## TiFlash 中的一些基本元素抽象\n\nTiFlash 这款引擎的代码是 18 年从 ClickHouse fork。ClickHouse 为 TiFlash 提供了一套性能十分强劲的向量化执行引擎,我们将其当做 TiFlash 的单机的计算引擎使用。在此基础上,我们增加了针对 TiDB 前端的对接,MySQL 兼容,Raft 协议和集群模式,实时更新列存引擎,MPP 架构等等。虽然和原本的 Clickhouse 已经完全不是一回事,但代码自然地 TiFlash 代码继承自 ClickHouse,也沿用着 CH 的一些抽象。比如:\n\nIColumn 代表内存里面以列方式组织的数据。IDataType 是数据类型的抽象。Block 则是由多个 IColumn 组成的数据块,它是执行过程中,数据处理的基本单位。\n\n在执行过程中,Block 会被组织为流的形式,以 BlockInputStream 的方式,从存储层 “流入” 计算层。而 BlockOutputStream,则一般从执行引擎往存储层或其他节点 “写出” 数据。\n\nIStorage 则是对存储层的抽象,定义了数据写入、读取、DDL 操作、表锁等基本操作。\n\n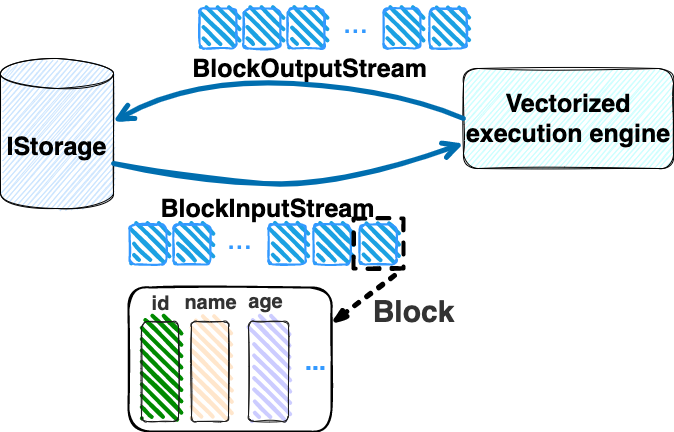\n\n## DeltaTree 引擎\n\n虽然 TiFlash 基本沿用了 CH 的向量化计算引擎,但是存储层最终没有沿用 CH 的 MergeTree 引擎,而是重新研发了一套更适合 HTAP 场景的列存引擎,我们称为 DeltaTree,对应代码中的 \"[StorageDeltaMerge](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/StorageDeltaMerge.h#L42)\"。\n\n### DeltaTree 引擎解决的是什么问题\n\nA. 原生支持高频率数据写入,适合对接 TP 系统,更好地支持 HTAP 场景下的分析工作。\n\nB. 支持列存实时更新的前提下更好的读性能。它的设计目标是优先考虑 Scan 读性能,相对于 CH 原生的 MergeTree 可能部分牺牲写性能\n\nC. 符合 TiDB 的事务模型,支持 MVCC 过滤\n\nD. 数据被分片管理,可以更方便的提供一些列存特性,从而更好的支持分析场景,比如支持 rough set index\n\n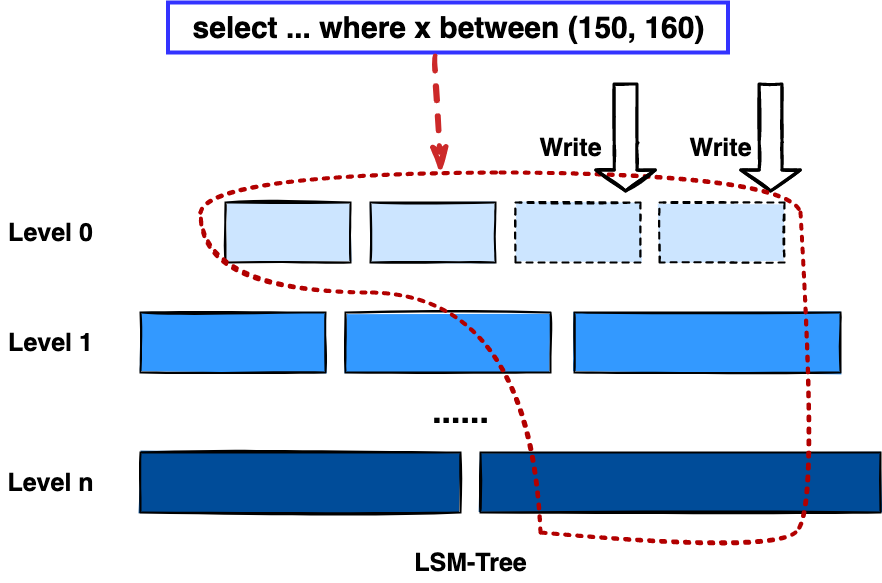\n\n为什么我们说 DeltaTree 引擎具备上面特性呢🤔 ?回答这个疑问之前,我们先回顾下 CH 原生的 MergeTree 引擎存在什么问题。MergeTree 引擎可以理解为经典的 LSM Tree(Log Structured Merge Tree)的一种列存实现,它的每个 \"part 文件夹\" 对应 SSTFile(Sorted Strings Table File)。最开始,MergeTree 引擎是没有 WAL 的,每次写入,即使只有 1 条数据,也会将数据需要生成一个 part。因此如果使用 MergeTree 引擎承接高频写入的数据,磁盘上会形成大量碎片的文件。这个时候,MergeTree 引擎的写入性能和读取性能都会出现严重的波动。这个问题直到 2020 年,CH 给 MergeTree 引擎引入了 WAL,才部分缓解这个压力 [ClickHouse/8290](https://github.com/ClickHouse/ClickHouse/pull/8290)。\n\n那么是不是有了 WAL,MergeTree 引擎就可以很好地承载 TiDB 的数据了呢?还不足够。因为 TiDB 是一个通过 MVCC 实现了 Snapshot Isolation 级别事务的关系型数据库。这就决定了 TiFlash 承载的负载会有比较多的数据更新操作,而承载的读请求,都会需要通过 MVCC 版本过滤,筛选出需要读的数据。而以 LSM Tree 形式组织数据的话,在处理 Scan 操作的时候,会需要从 L0 的所有文件,以及其他层中 与查询的 key-range 有 overlap 的所有文件,以堆排序的形式合并、过滤数据。在合并数据的这个入堆、出堆的过程中, CPU 的分支经常会 miss,cache 命中也会很低。测试结果表明,在处理 Scan 请求的时候,大量的 CPU 都消耗在这个堆排序的过程中。\n\n另外,采用 LSM Tree 结构,对于过期数据的清理,通常在 level compaction 的过程中,才能被清理掉(即 Lk-1 层与 Lk 层 overlap 的文件进行 compaction)。而 level compaction 的过程造成的写放大会比较严重。当后台 compaction 流量比较大的时候,会影响到前台的写入和数据读取的性能,造成性能不稳定。\n\nMergeTree 引擎上面的三点:写入碎片、Scan 时 CPU cache miss 严重、以及清理过期数据时的 compaction ,造成基于 MergeTree 引擎构建的带事务的存储引擎,在有数据更新的 HTAP 场景下,读、写性能都会有较大的波动。\n\n### DeltaTree 的解决思路以及模块划分\n\n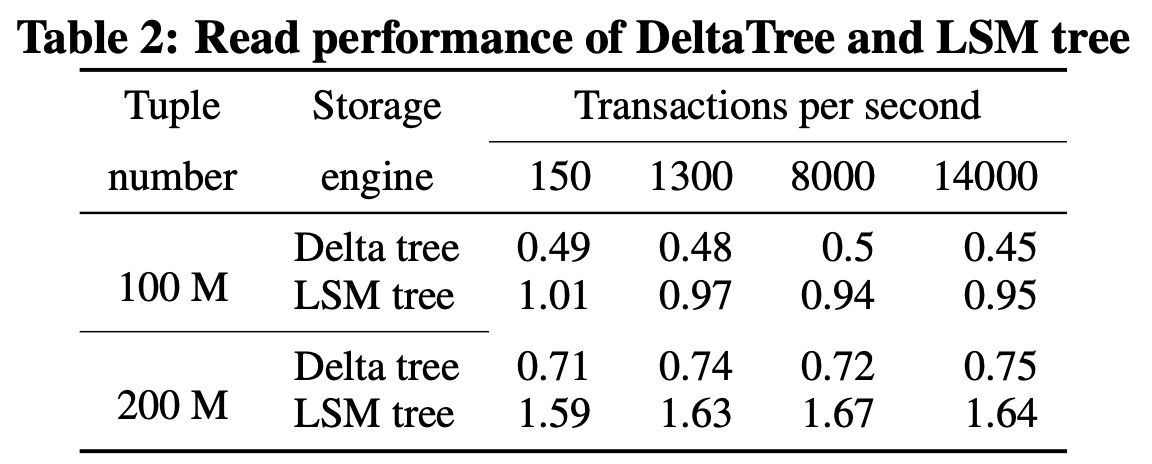\n\n在看实现之前,我们来看看 DeltaTree 的疗效如何。上图是 Delta Tree 与基于 MergeTree 实现的带事务支持的列存引擎在不同数据量(Tuple number)以及不同更新 TPS (Transactions per second) 下的读 (Scan) 耗时对比。可以看到 DeltaTree 在这个场景下的读性能基本能达到后者的两倍。\n\n\n\n那么 DeltaTree 具体面对上述问题,是如何设计的呢?\n\n首先,我们在表内,把数据按照 handle 列的 key-range,横向分割进行数据管理,每个分片称为 Segment。这样在 compaction 的时候,不同 Segment 间的数据就独立地进行数据整理,能够减少写放大。这方面与 PebblesDB[1] 的思路有点类似。\n\n另外,在每个 Segment 中,我们采用了 delta-stable 的形式,即最新的修改数据写入的时候,被组织在一个写优化的结构的末尾([DeltaValueSpace.h](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/DeltaMerge/Delta/DeltaValueSpace.h)),定期被合并到一个为读优化的结构中([StableValueSpace.h](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/DeltaMerge/StableValueSpace.h))。Stable Layer 存放相对老的,数据量较大的数据,它不能被修改,只能被 replace。当 Delta Layer 写满之后,与 Stable Layer 做一次 Merge(这个动作称为 Delta Merge),从而得到新的 Stable Layer,并优化读性能。很多支持更新的列存,都是采用类似 delta-stable 这种形式来组织数据,比如 Apache Kudu[2]。有兴趣的读者还可以看看《Fast scans on key-value stores》[3] 的论文,其中对于如何组织数据,MVCC 数据的组织、对过期数据 GC 等方面的优劣取舍都做了分析,最终作者也是选择了 delta-main 加列存这样的形式。\n\nDelta Layer 的数据,我们通过一个 PageStorage 的结构来存储数据,Stable Layer 我们主要通过 [DTFile](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/DeltaMerge/File/DMFile.h) 来存储数据、通过 PageStorage 来管理生命周期。另外还有 Segment、DeltaValueSpace、StableValueSpace 的元信息,我们也是通过 PageStorage 来存储。上面三者分别对应 DeltaTree 中 [StoragePool](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/DeltaMerge/StoragePool.h#L73) 这一数据结构的 log, data 以及 meta。\n\n### PageStorage 模块\n\n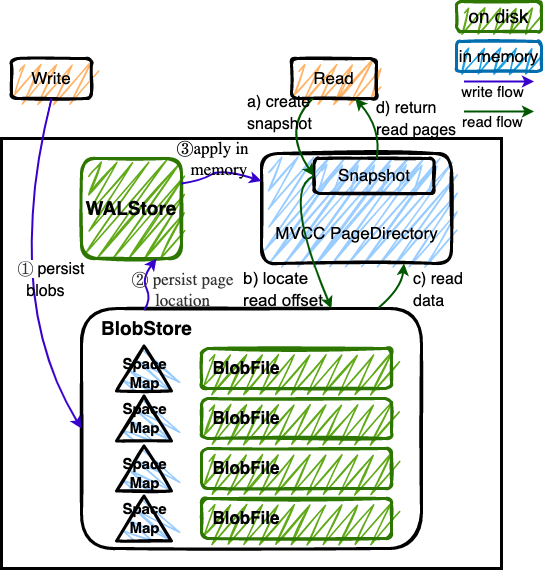\n\n上面提到, Delta Layer 的数据和 DeltaTree 存储引擎的一些元数据,这类较小的数据块,在序列化为字节串之后,作为 \"Page\" 写入到 PageStorage 来进行存储。PageStorage 是 TiFlash 中的一个存储的抽象组件,类似对象存储。它主要设计面向的场景是 Delta Layer 的高频读取:比如在 snapshot 上,以 PageID (或多个 PageID) 做点查的场景;以及相对于 Stable Layer 较高频的写入。PageStorage 层的 \"Page\" 数据块典型大小为数 KiB~MiB。\n\nPageStorage 是一个比较复杂的组件,今天先不介绍它内部的构造。读者可以先理解 PageStorage 至少提供以下 3 点功能:\n\n- 提供 WriteBatch 接口,保证写入 WriteBatch 的原子性\n- 提供 Snapshot 功能,可以获取一个不阻塞写的只读 view\n- 提供读取 Page 内部分数据的能力(只读选择的列数据)\n\n### 读索引 DeltaTree Index\n\n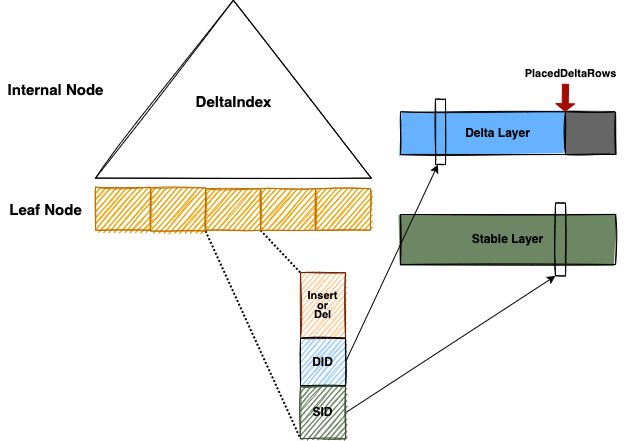\n\n前面提到,在 LSM-Tree 上做多路归并比较耗 CPU,那我们是否可以避免每次读都要重新做一次呢?答案是可以的。事实上有一些内存数据库已经实践了类似的思路。具体的思路是,第一次 Scan 完成后,我们把多路归并算法产生的信息想办法存下来,从而使下一次 Scan 可以重复利用。这份可以被重复利用的信息我们称为 Delta Index,它由一棵 B+ Tree 实现。利用 Delta Index,把 Delta Layer 和 Stable Layer 合并到一起,输出一个排好序的 Stream。**Delta Index 帮助我们把 CPU bound、而且存在很多 cache miss 的 merge 操作,转化为大部分情况下一些连续内存块的 copy 操作**,进而优化 Scan 的性能。\n\n### Rough Set Index\n\n很多数据库都会在数据块上加统计信息,以便查询时可以过滤数据块,减少不必要的 IO 操作。有的将这个辅助的结构称为 KnowledgeNode、有的叫 ZoneMaps。TiFlash 参考了 InfoBright [4] 的开源实现,采用了 Rough Set Index 这个名字,中文叫粗粒度索引。\n\nTiFlash 给 SelectQueryInfo 结构中添加了一个 [MvccQueryInfo](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/RegionQueryInfo.h#L52) 的结构,里面会带上查询的 key-ranges 信息。DeltaTree 在处理的时候,首先会根据 key-ranges 做 segment 级别的过滤。另外,也会从 DAGRequest 中将查询的 Filter [转化为 RSFilter](https://github.com/pingcap/tiflash/blob/afdd2e0ca23ccd6a19a604d90b9d75c971a3fe7c/dbms/src/Storages/DeltaMerge/FilterParser/FilterParser.h#L41) 的结构,并且在读取数据时,利用 RSFilter,做 ColumnFile 中数据块级别的过滤。\n\n在 TiFlash 内做 Rough Set Filter,跟一般的 AP 数据库不同点,主要在还需要考虑**粗粒度索引对** **MVCC** **正确性的影响**。比如表有三列 a、b 以及写入的版本 tso,其中 a 是主键。在 t0 时刻写入了一行 Insert (x, 100, t0),它在 Stable VS 的数据块中。在 t1 时刻写入了一个删除标记 Delete(x, 0, t1),这个标记存在 Delta Layer 中。这时候来一个查询 select * from T where b = 100,很显然如果我们在 Stable Layer 和 Delta Layer 中都做索引过滤,那么 Stable 的数据块可以被选中,而 Delta 的数据块被过滤掉。这时候就会造成 (x, 100, t0) 这一行被错误地返回给上层,因为它的删除标记被我们丢弃了。\n\n因此 TiFlash Delta layer 的数据块,只会应用 handle 列的索引。非 handle 列上的 Rough Set Index 主要应用于 Stable 数据块的过滤。一般情况下 Stable 数据量占 90%+,因此整体的过滤效果还不错。\n\n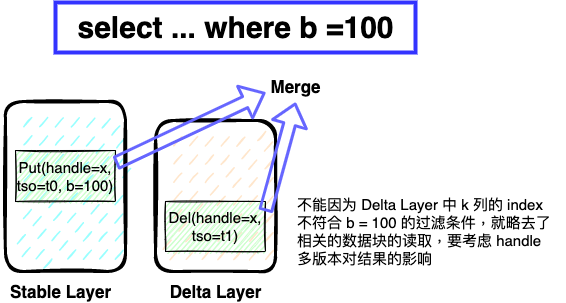\n\n### 代码模块\n\n下面是 DeltaTree 引擎内各个模块对应的代码位置,读者可以回忆一下前文,它们分别对应前文的哪一部分 ;)\n\n```CSS\n# DeltaTree 引擎内各模块对应的代码位置\n\ndbms/src/Storages/\n\n├── Page # PageStorage\n\n└── DeltaMerge\n\n ├── DeltaMergeStore.h # DeltaTree 引擎的定义\n\n ├── Segment.h # Segment\n\n ├── StableValueSpace.h # Stable Layer\n\n ├── Delta # Delta Layer\n\n ├── DeltaMerge.h # Stable 与 Delta merge 过程\n\n ├── File # Stable Layer 的存储格式\n\n ├── DeltaTree.h, DeltaIndex.h # Delta Index \n\n ├── Index, Filter, FilterParser # Rough Set Filter\n\n └── DMVersionFilterBlockInputStream.h # MVCC Filtering\n```\n\n## 小结\n\n本篇文章主要介绍了 TiFlash 整体的模块分层,以及在 TiDB 的 HTAP 场景下,存储层 DeltaTree 引擎如何进行优化的思路。简单介绍了 DeltaTree 内组件的构成和作用,但是略去了一些细节,比如 PageStorage 的内部实现,DeltaIndex 如何构建、应对更新,TiFlash 是如何接入 multi-Raft 等问题。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n\n**相关文章**\n\n[1] [SOSP'17: PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees](https://www.cs.utexas.edu/~rak/papers/sosp17-pebblesdb.pdf)\n\n[2] [Kudu: Storage for Fast Analytics on Fast Data](https://kudu.apache.org/kudu.pdf)\n\n[3] [VLDB'17: Fast scans on key-value stores](https://vldb.org/pvldb/vol10/p1526-bocksrocker.pdf)\n\n[4] [Brighthouse: an analytic data warehouse for ad-hoc queries](https://dl.acm.org/doi/abs/10.14778/1454159.1454174)\n\n> 点击查看更多 [TiFlash 源码阅读](https://pingcap.com/zh/blog?tag=TiFlash%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)系列文章","author":"黄俊深","category":1,"customUrl":"tiflash-source-code-reading-1","fillInMethod":"writeDirectly","id":379,"summary":"TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。本文为系列文章的第一篇,将对 TiDB HTAP 的整体形态进行介绍,并详细解析存储层 DeltaTree 引擎进行优化的设计思路以及其子模块","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(一)TiFlash 存储层概览"}},{"relatedBlog":{"body":"TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。在上一期源码阅读中,我们介绍了 TiFlash 的存储层,本文将对 TiFlash 计算层进行介绍,包括架构的演进,DAGRequest 协议、dag request 在 TiFlash 侧的处理流程以及 MPP 基本原理。\n\n本文作者:徐飞,PingCAP 资深研发工程师\n\n\n## 背景\n\n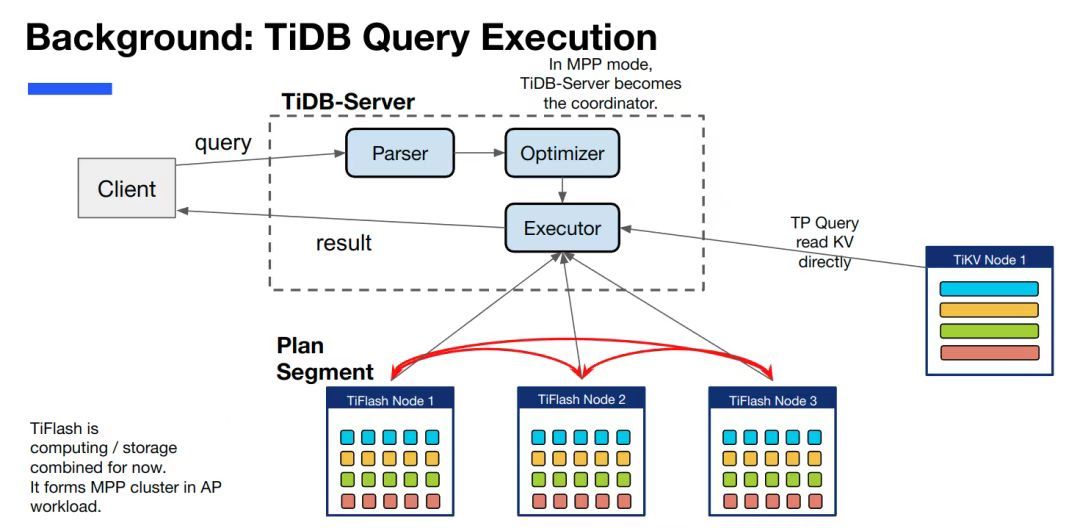\n\n上图是一个 TiDB 中 query 执行的示意图,可以看到在 TiDB 中一个 query 的执行会被分成两部分,一部分在 TiDB 执行,一部分下推给存储层(TiFlash/TiKV)执行。本文我们主要关注在 TiFlash 执行的部分。\n\n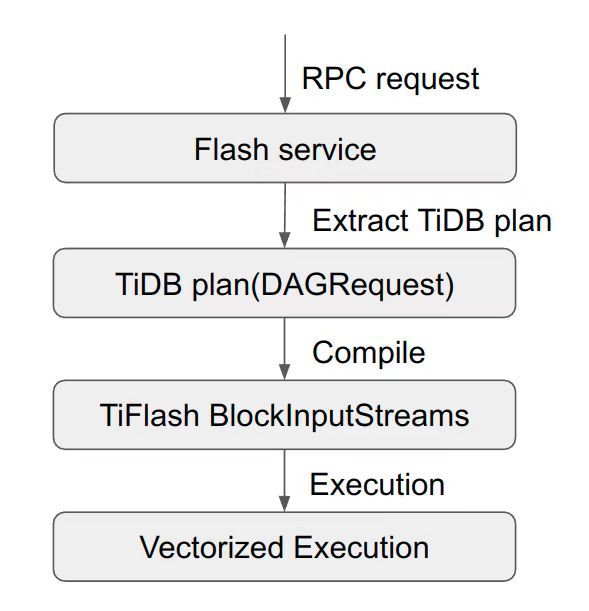\n\n这个是一个 TiDB 的查询 request 在 TiFlash 内部的基本处理流程,首先 Flash service 会接受到来自 TiDB 的 RPC 请求,然后会从请求里拿到 TiDB 的 plan,在 TiFlash 中我们称之为 DAGRequest,拿到 TiDB 的 plan 之后,TiFlash 需要把 TiDB 的 plan 编译成可以在 TiFlash 中执行的 BlockInputStream,最后在得到 BlockInputStream 之后,TiFlash 就会进入向量化执行的阶段。本文要讲的 TiFlash 计算层实际上是包含以上四个阶段的广义上的计算层。\n\n## TiDB + TiFlash 计算层的演进\n\n首先,我们从 API 的角度来讲一下 TiDB + TiFlash 计算层的演进过程:\n\n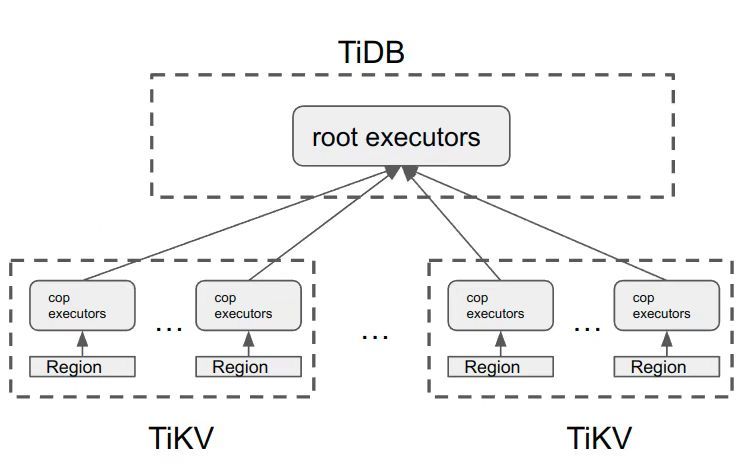\n\n最开始在没有引入 TiFlash 时,TiDB 是用过 Coprocessor 协议来与存储层(TiKV)进行交互的,在上图中,root executors 表示在 TiDB 中单机执行的算子,cop executors 指下推给 TiKV 执行的算子。在 TiDB + TiKV 的计算体系中,有如下几个特点:\n\n- TiDB 中的算子是在 TiDB 中单机执行的,计算的扩展性受限\n\n- TiKV 中的算子是在 TiKV 中执行的,而且 TiKV 的计算能力是可以随着 TiKV 节点数的增加而线性扩展的\n\n- 因为 TiKV 中并没有 table 的概念,Coprocessor 是以 Region 为单位的,一个 region 一个 coprocessor request\n\n- 每个 Coprocessor 都会带有一个用于 MVCC 读的 timestamp,在 TiFlash 中我们称之为 start_ts\n\n在 TiDB 4.0 中,我们首次引入了 TiFlash:\n\n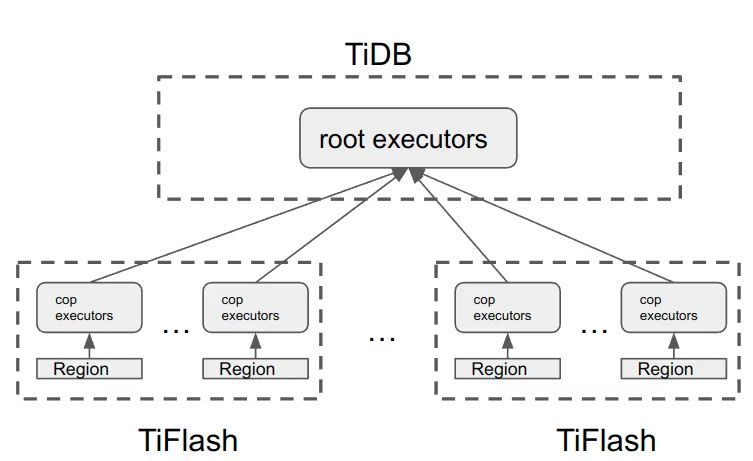\n\n在引入之初,我们基本上就是只对接了现有的 Coprocessor 协议,可以看出上面这个图上之前 TiDB + TiKV 的图其实是一样的,除了存储层从 TiKV 变成了 TiFlash。但是本质上讲引入 TiFlash 之前 TiDB + TiKV 是一个面向 TP 的系统,TiFlash 在简单对接 Coprocessor 协议之后,马上发现了一些对 AP 很不友好的地方,主要有两点:\n\n- Coprocessor 是以 region 为单位的,而 TiDB 中默认 region 大小是 96 MB,这样对于一个 AP 的大表,可能会包含成千上万个 region,这导致一个 query 就会有成千上万次 RPC\n\n- 每个 Coprocessor 只读一个 region 的数据,这让存储层很多读相关的优化都用不上\n\n在发现问题之后,我们尝试对原始的 Coprocessor 协议进行改进,主要进行了两次尝试:\n\n- BatchCommands:这个是 TiDB + TiKV 体系里就有的一个改进,原理就是在发送的时候将发送给同一个存储节点的 request batch 成一个,对于 TiFlash 来说,因为只支持 Coprocessor request,所以就是把一些 Coprocessor request batch 成了一个。因为 batch 操作是发送端最底层做的,所以 batch 在一起的 Coprocessor request 并没有逻辑上的联系,所以 TiFlash 拿到 BatchCoprocessor 之后也就是每个 Coprocessor request 依次处理。所以 BatchCommands 只能解决 RPC 过多的问题。\n\n- BatchCoprocessor:这个是 TiDB + TiFlash 特有的 RPC,其想法也很简单,就是对同一个 TiFlash 节点,只发送一个 request,这个 request 里面包含了所有需要读取的 region 信息。显然这个模式不但能减少 RPC,而且存储层能一次性的看到所有需要扫描的数据,也让存储层有了更大的优化空间。\n\n尽管在引入 BatchCoprocessor 之后,Coprocessor 的两个主要缺点都得到了解决,但是因为无论是 BatchCoprocessor 还是 Coprocessor 都只是支持对单表的 query,遇到复杂 sql,其大部分工作还是需要在 root executor 上单机执行,以下面这个两表 join 的 plan 为例:\n\n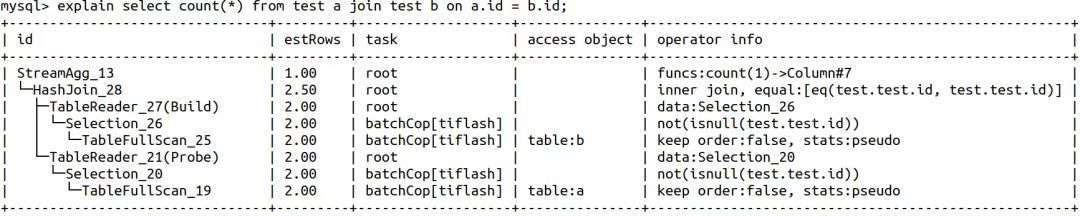\n\n只有 TableScan 和 Selection 部分可以在 TiFlash 中执行,而之后的 Join 和 Agg 都需要在 TiDB 执行,这显然极大的限制了计算层的扩展性。为了从架构层面解决这个问题,在 TiFlash 5.0 中,我们正式引入了 MPP 的计算架构:\n\n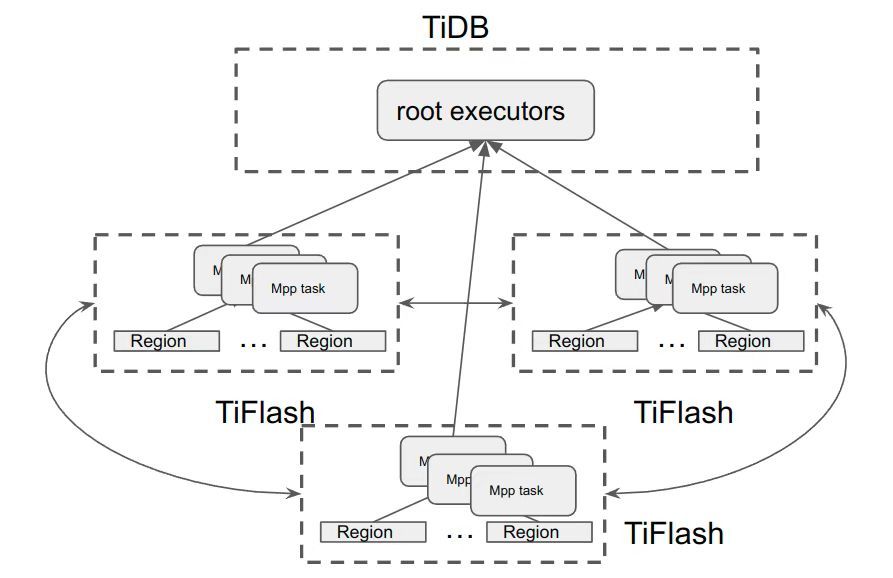\n\n引入 MPP 之后,TiFlash 支持的 query 部分得到了极大的丰富,对于理想情况下,root executor 直接退化为一个收集结果的 TableReader,剩下部分都会下推给 TiFlash,从而从根本上解决了 TiDB 中计算能力无法横向扩展的问题。\n\n## DAGRequest 到 BlockInputStream\n\n在 TiFlash 内部,接收到 TiDB 的 request 之后,首先会得到 TiDB 的 plan,在 TiFlash 中,称之为 DAGRequest,它是一个基于 protobuf 协议的一个定义,一些主要的部分如下:\n\n\n\n值得一提的就是 DAGRequest 中有两个 executor 相关的 field:\n\n- executors:这个是引入 TiFlash 之前的定义,其表示一个 executor 的数组,而且里面的 executor 最多就三个:一个 scan(tablescan 或者 indexscan),一个 selection,最后一个 agg/topN/limit\n\n- root_executors:显然上面那个 executors 的定义过于简单,无法描述 MPP 时的 plan,所以在引入 MPP 之后我们加了一个 root_executor 的 field,它是一个 executor 的 tree\n\n在得到 executor tree 之后,TiFlash 会进行编译,在编译的时候有一个中间数据结构是 DAGQueryBlock,TiDB 会先将 executor tree 转成 DAGQueryBlock 的tree,然后对 DAGQueryBlock 的 tree 进行后序遍历来编译。\n\nDAGQueryBlock 的定义和原始的 executor 数组很类似,一个 DAGQueryBlock 包含的 executor 如下:\n\n- SourceExecutor [Selection] [Aggregation|TopN|Limit] [Having] [ExchangeSender]\n\n其中 SourceExecutor 包含真正的 source executor 比如 tablescan 或者 exchange receiver,以及其他所有不符合上述 executor 数组 pattern 的 executor,如 join,project 等。\n\n可以看出来 DAGQueryBlock 是从 Coprocessor 时代的 executor 数组发展而来的,这个结构本身并没有太多的意义,而且也会影响很多潜在的优化,在不久的将来,应该会被移除掉。\n\n在编译过程中,有两个 TiDB 体系特有的问题需要解决:\n\n- 如何保证 TiFlash 的数据与 TiKV 的数据保持强一致性\n\n- 如何处理 Region error\n\n对于第一个问题,我们引入了 Learner read 的过程,即在 TiFlash 编译 tablescan 之前,会用 start_ts 向 raft leader 查询截止到该 start_ts 时,raft 的 index 是多少,在得到该 index 之后,TiFlash 会等自己这个 raft leaner 的 index 追上 leader 的 index。\n\n对于第二个问题,我们引入了 Remote reader 的概念,即如果 TiFlash 遇到了 region error,那么如果是 BatchCoprocessor 和 MPP request,那 TiFlash 会主动像其他 TiFlash 节点发 Coprocessor request 来拿到该 region 的数据。\n\n在把 DAGRequest 编译成 BlockInputStream 之后,就进入了向量化执行的阶段,在向量化执行的时候,有两个基本的概念:\n\n- Block:是执行期的最小数据单元,它由一个 column 的数组组成\n\n- BlockInputStream:相当于执行框架,每个 BlockInputStream 都有一个或者多个 child,执行时采用了 pull 的模型,下面是执行时的伪代码:\n\n\n\nBlockInputStream 可以分为两类:\n- 用于做计算的,例如:\n - DMSegmentThreadInputStream:与存储交互的 InpuStream,可以简单理解为是 table scan\n - ExchangeReceiverInputStream:从远端读数据的 InputStream\n - ExpressionBlockInputStream:进行 expression 计算的 InputStream\n - FilterBlockInputStream:对数据进行过滤的 InputStream\n - ParallelAggregatingBlockInputStream:做数据进行聚合的 InputStream\n\n- 用于并发控制的,例如:\n - UnionBlockInputStream:把多个 InputStream 合成一个 InputStream\n - ParallelAggregatingBlockInputStream:和 Union 类似,不过还会做一个额外的数据聚合\n - SharedQueryBlockInputStream:把一个 InputStream 扩散成多个 InputStream\n\n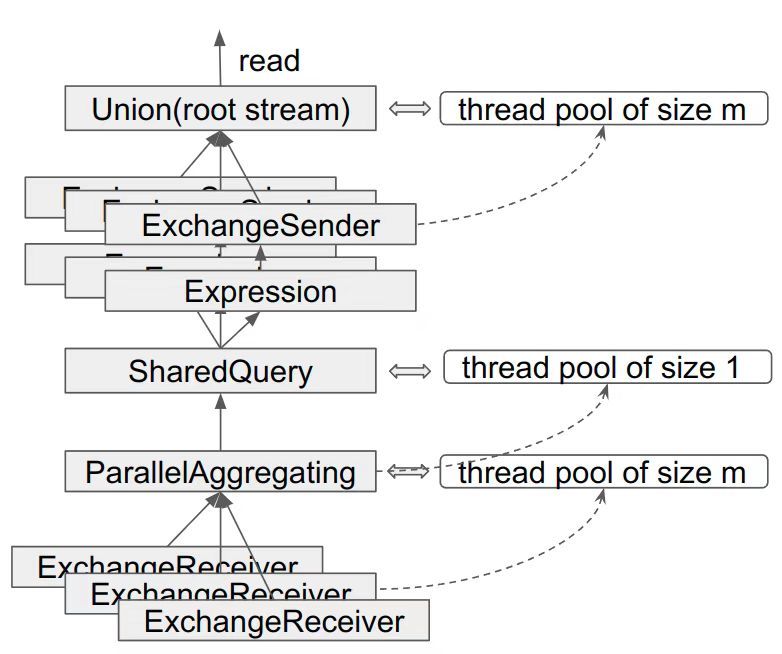\n\n用于计算的 InputStream 与用于并发控制的 InputStream 最大的不同在于用于计算的 InputStream 自己不管理线程,它们只负责在某个线程里跑起来,而用于并发控制的 InputStream 会自己管理线程,如上所示,Union,ParallelAggregating 以及 SharedQuery 都会在自己内部维护一个线程池。当然有些并发控制的 InputStream 自己也会完成一些计算,比如 ParallelAggregatingBlockInputStream。\n\n## MPP\n\n在介绍完 TiFlash 计算层中基本的编译以及执行框架之后,我们重点再介绍下 MPP。\n\nMPP 在 API 层共有三个:\n\n- DispatchMPPTask:用于 TiDB 向 TiFlash 发送 plan\n\n- EstablishMPPConnectionSyncOrAsync:用于 MPP 中上游 task 向下游 task 发起读数据的请求,因为无论是读的数据量以及读的时间会比较长,所以这个 RPC 是 streaming 的 RPC\n\n- CancelMPPTask:用于 TiDB 端 cancel MPP query\n\n在运行 MPP query 的时候,首先由 TiDB 生成 MPP task,TiDB 用 DispatchMPPTask 来将 task 分发给各个 TiFlash 节点,然后 TiDB 与 TiFlash 会用 EstablishMPPConnection 来建立起各个 task 之间的连接。\n\n与 BatchCoprocessor 相比,MPP 的核心概念是 Exchange,用于 TiFlash 节点之间的数据交换,在 TiFlash 中有三种 exchange 的类型:\n\n- Broadcast:即将一份数据 broadcast 到多个目标 mpp task\n\n- HashPartition:即将一份数据用 hash partition 的方式切分成多个 partition,然后发送给目标 mpp task\n\n- PassThrough:这个与 broadcast 几乎一样,不过 PassThrough 的目标 task 只能有一个,通常用于 MPP task 给 TiDB 返回结果\n\n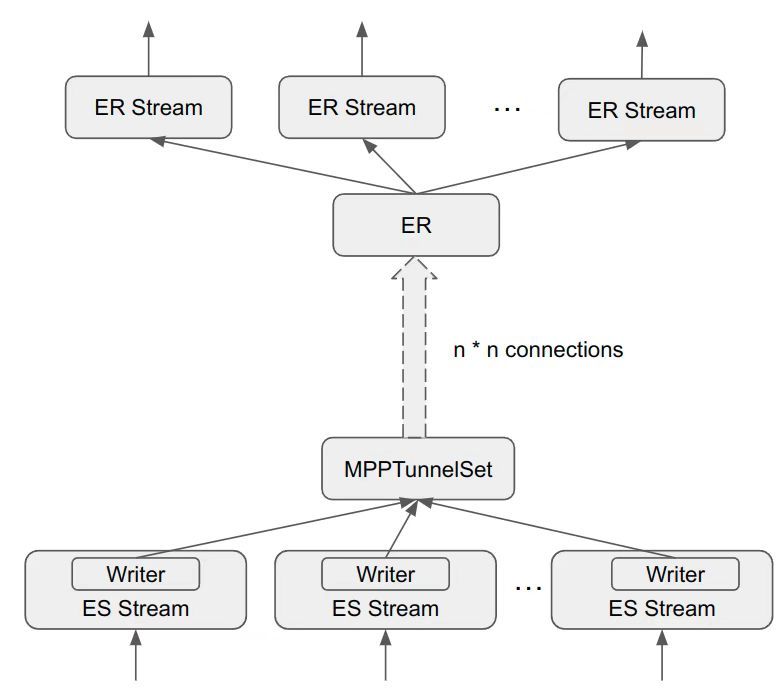\n\n上图是 Exchange 过程中的一些关键数据结构,主要有如下几个:\n\n- 接收端 \n - ExchangeReceiver:用于向其他 task 建立连接,接收数据并放在 result queue\n - ExchangeReceiverInputStream:执行框架中的一个 InputStream,多个 ER Stream 共同持有一个 ExchangeReceiver,并从其 result queue 中读数据\n\n- 发送端\n - MPPTunnel:持有 grpc streaming writer,用于将计算结果发送给其他 task,目前有三种模式\n - Sync Tunnel:用 sync grpc 实现的 tunnel\n - Async Tunnel:用 async grpc 实现的 tunnel\n - Local Tunnel:对于处于同一个节点的不同 task,他们之间的 Tunnel 不走 RPC,在内存里传输数据即可。\n - MPPTunnelSet:同一个 ExchangeSender 可能需要向多个 mpp task 传输数据,所以会有多个 MPPTunnel,这些 MPPTunnel 在一起组成一个 MPPTunnelSet\n - StreamingDAGResponseWriter:持有 MPPTunnelSet,主要做一些发送之前的数据预处理工作\n - 将数据 encode 成协议规定的格式\n - 如果 Exchange Type 是 HashPartition 的话,还需要负责把数据进行 Hash partition 的切分\n - ExchangeSenderBlockInputStream:执行框架中的一个 InputStream,持有 StreamingDAGResponseWriter,把计算的结果发送给 writer\n\n除了 Exchange,MPP 还有一个重要部分是 MPP task 的管理,与 BatchCoprocessor/Coprocessor 不同,MPP query 的多个 task 需要有一定的通信协作,所以 TiFlash 中需要有对 MPP task 的管理模块。其主要的数据结构如下:\n\n- MPPTaskManager:全局的 instance 用来管理该 TiFlash 节点上所有的 MPP task\n\n- MPPQueryTaskSet:属于同一个 query 的所有 MPP task 集合,在诸如 CancelMPPTask 时用于快速找到所有的目标 task\n\n- MPPTask:一个 MPP query 中的最基本单元,不同 MPP task 之间通过 Exchange 来交换数据\n\n以上就是 TiFlash 中 MPP 的相关实现,可以看出目前这个实现还是比较朴素的。在随后的测试和使用中,我们很快发现一些问题,主要有两个问题:\n\n第一个问题:对于一些 sql 本身很复杂,但是数据量(计算量)却不大的 query,我们发现,无论怎么增加 query 的并发,TiFlash 的 cpu 利用率始终会在 50% 以下。经过一系列的研究之后我们发现 root cause 是目前 TiFlash 的线程使用是需要时申请,结束之后即释放的模式,而频繁的线程申请与释放效率非常低,直接导致了系统 cpu 使用率无法超过 50%。解决该问题的直接思路即使用线程池,但是由于我们目前 task 使用线程的模式是非抢占的,所以对于固定大小的线程池,因为系统中没有全局的调度器,会有死锁的风险,为此我们引入了 DynamicThreadPool,在该线程池中,线程主要分为两类:\n\n- 固定线程:长期存在的线程\n\n- 动态线程:按需申请的线程,不过与之前的线程不同的是,该线程在结束当前任务之后会等一段时间,如果没有新的任务的话,才会退出\n\n第二个问题和第一个问题类似,也是线程相关的,即 TiFlash 在遇到高并发的 query 时,因为线程使用没有很好的控制,会导致 TiFlash server 遇到无法分配出线程的问题,为了解决此问题,我们必须控制 TiFlash 中同时使用的线程,在跑 MPP query 的时候,线程主要可以分为两部分:\n\n- IO 线程:主要指用于 grpc 通信的线程,在减小 grpc 线程使用方面,我们基本上是采用了业界的成熟方案,即用 async 的方式,我们实现了 async 的 grpc server 和 async 的 grpc client,大大减小了 IO 线程的使用量\n\n- 计算线程:为了控制计算线程,我们必须引入调度器,该调度器有两个最低目标:不造成死锁以及最大程度控制系统的线程使用量,最后我们在 TiFlash 里引入了 MinTSOScheduer:\n - 完全分布式的调度器,仅依赖 TiFlash 节点自身的信息\n - 基本的原理为 MinTSOScheduer 保证 TiFlash 节点上最小的 start_ts 对应的所有 MPP task 能正常运行。因为全局最小的 start_ts 在各个节点上必然也是最小的 start_ts,所以 MinTSOScheduer 能够保证全局至少有一条 query 能顺利运行从而保证整个系统不会有死锁,而对于非最小 start_ts 的 MPP task,则根据当前系统的线程使用情况来决定是否可以运行,所以也能达到控制系统线程使用量的目的。\n\n## 总结\n\n本文主要系统性地介绍了 TiFlash 计算层的基本概念,包括架构的演进,TiFlash 内部对 TiDB plan 的处理以及 MPP 基本原理等,以期望读者能够对 TiFlash 计算层有一个初步的了解。后续还会有一些具体实现诸如 TiFlash 表达式以及算子系统的细节介绍,敬请期待。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n\n> 点击查看更多 [TiFlash 源码阅读](https://pingcap.com/zh/blog?tag=TiFlash%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)系列文章","author":"徐飞","category":1,"customUrl":"tiflash-source-code-reading-2","fillInMethod":"writeDirectly","id":389,"summary":"本文将对 TiFlash 计算层进行介绍,包括架构的演进,DAGRequest 协议、dag request 在 TiFlash 侧的处理流程以及 MPP 基本原理。","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(二)计算层概览"}},{"relatedBlog":{"body":"TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。希望读者在阅读这一系列文章后,能够对 TiFlash 内部原理有一个清晰的理解,更熟悉 TiFlash 各个流程及概念,甚至能对 TiFlash 进行源码级别的编程开发。在[上一期源码阅读](https://pingcap.com/zh/blog/tiflash-source-code-reading-2)中,我们介绍了 TiFlash 的计算层。从本文开始,我们将对 TiFlash 各个组件的设计及实现进行详细分析。\n\n**本文作者**:施闻轩,TiFlash 资深研发工程师\n\n## 背景\n\nPingCAP 自研的 DeltaTree 列式存储引擎是让 TiFlash 站在 Clickhouse 巨人肩膀上得以实现可更新列存的关键。本文分为两部分,**主要介绍 DeltaTree 存储引擎的设计细节及对应的代码实现**。Part 1 部分主要涉及写入流程,Part 2 主要涉及读取流程。\n\n\n\n> 本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。\n\n\n\n## 前置知识\n\nTiFlash 关键的底层抽象都复用了 Clickhouse 已有的抽象概念,而非完全用 TiDB 抽象概念进行替代。本节首先介绍读者通常接触到的 TiDB 抽象概念在 TiFlash 中的形态及对应关系,以便读者在进一步深入 TiFlash 代码后不会产生混淆。\n\n### TiDB 逻辑表、物理表、TiFlash 表\n\n在 TiDB、TiKV 及 TiFlash 代码中,我们将在 TiDB 中通过 `CREATE TABLE` **SQL** **语句创建出来的表称为「逻辑表」**。例如,以下语句将会创建一个「逻辑表」:\n\n```SQL\nCREATE TABLE foo(c INT);\n```\n\n对应地,**我们将实际存储数据的表称为「物理表」**。对于非分区表,物理表与逻辑表相同。对于分区表,各个分区才是这张逻辑表的物理表。TiKV 及 TiFlash 由于主要涉及数据存取,因此它们绝大多数时候都在与物理表打交道、不关注逻辑表。\n\n以下会创建一个逻辑表,且具有 4 张物理表、在这 4 张物理表上存储了实际数据:\n\n```SQL\nCREATE TABLE bar (\n\n id INT NOT NULL,\n\n store_id INT NOT NULL\n\n)\n\nPARTITION BY RANGE (store_id) (\n\n PARTITION p0 VALUES LESS THAN (6),\n\n PARTITION p1 VALUES LESS THAN (11),\n\n PARTITION p2 VALUES LESS THAN (16),\n\n PARTITION p3 VALUES LESS THAN (21)\n\n);\n```\n\n> **小知识**\n>\n> 可以通过 [TiDB HTTP API](https://github.com/pingcap/tidb/blob/master/docs/tidb_http_api.md) 查看内部表结构。例如,对于前文示例中创建的 `foo` 表及 `bar` 表,查询出来的表结构如下:\n\n```YAML\ncurl http://127.0.0.1:10080/schema/test/foo\n\n{\n\n \"id\": 65,\n\n \"name\": {\n\n \"O\": \"foo\",\n\n \"L\": \"foo\"\n\n },\n\n \"cols\": [...],\n\n ...\n\n}\n\n\n\n❯ curl http://127.0.0.1:10080/schema/test/bar\n\n{\n\n \"id\": 67,\n\n \"name\": {\n\n \"O\": \"bar\",\n\n \"L\": \"bar\"\n\n },\n\n \"cols\": [...],\n\n \"partition\": {\n\n ...,\n\n \"definitions\": [\n\n {\n\n \"id\": 68,\n\n \"name\": {\n\n \"O\": \"p0\",\n\n \"L\": \"p0\"\n\n },\n\n ...\n\n },\n\n {\n\n \"id\": 69,\n\n \"name\": {\n\n \"O\": \"p1\",\n\n \"L\": \"p1\"\n\n },\n\n ...\n\n },\n\n {\n\n \"id\": 70,\n\n \"name\": {\n\n \"O\": \"p2\",\n\n \"L\": \"p2\"\n\n },\n\n ...\n\n },\n\n {\n\n \"id\": 71,\n\n \"name\": {\n\n \"O\": \"p3\",\n\n \"L\": \"p3\"\n\n },\n\n ...\n\n }\n\n ],\n\n },\n\n ...\n\n}\n```\n\n> 通过上述查询结果可知,`foo` 表的逻辑表 ID 为 65,由于没有分区,因此它的物理表 ID 也是 65。`bar` 表的逻辑表 ID 为 67,它具有四个物理表,ID 分别是 68、69、70、71,这四个分区对应的物理表存储了 `bar` 表中的数据。\n\n\n\nTiFlash 中我们维持了 Clickhouse 的表抽象概念。**每一张** **TiDB** **中的物理表都会对应地在 TiFlash 中创建出一张 Clickhouse 表来存储数据**,并指定存储引擎为 DeltaTree,关系如下所示:\n\n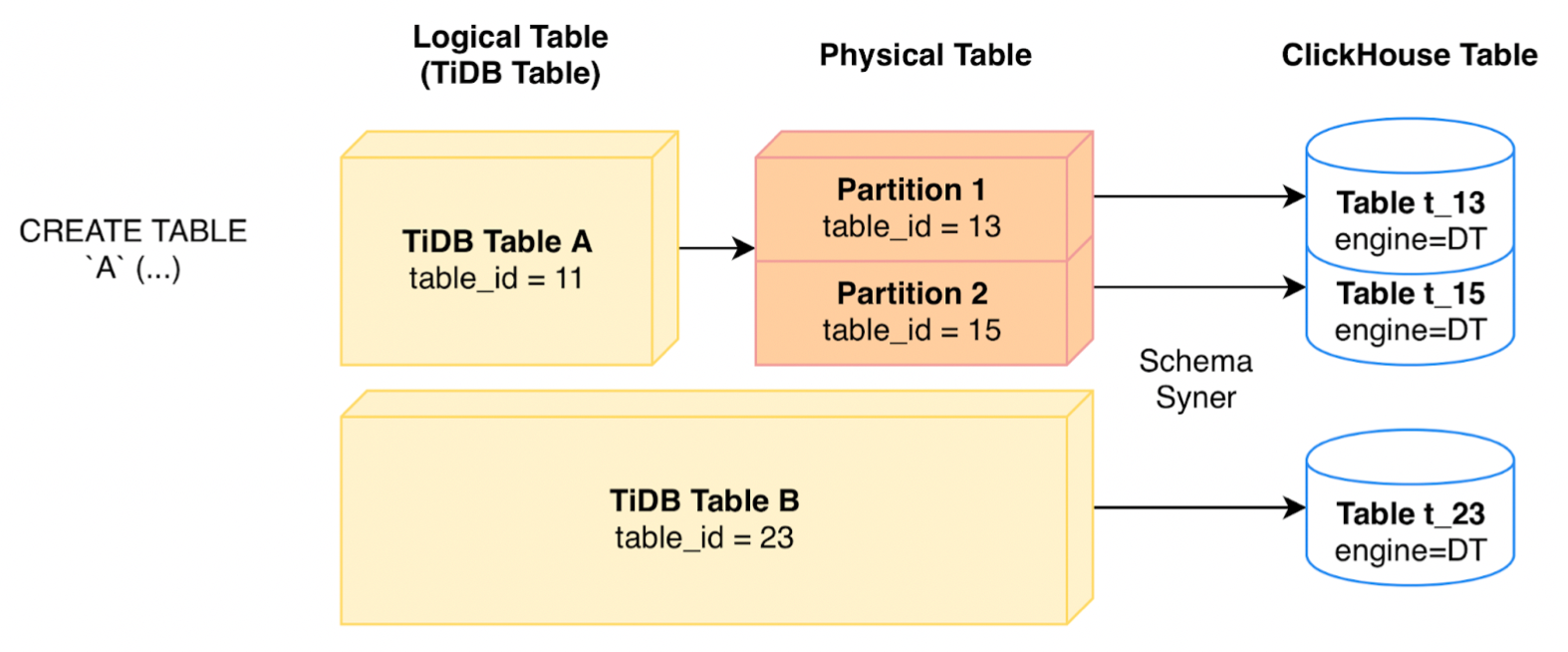\n\n例如,一个 ID = 13 的物理表会在 TiFlash 中对应 `t_13` 表。\n\n每张 DeltaTree 引擎的 TiFlash 表内部都对应了一个 `StorageDeltaMerge` 实例(参见 `StorageDeltaMerge.h`):\n\n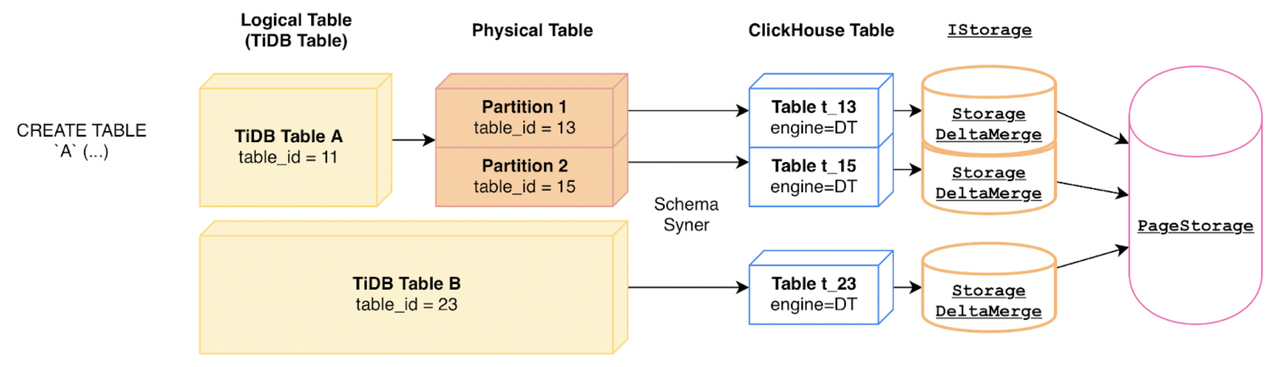\n\n> **备注 1**:DeltaMerge 是 DeltaTree 的前称。由于 DeltaMerge 与 TiDB 的 Data Migration 产品有一样的缩写 DM,因此 DeltaMerge 目前已统一改称 DeltaTree。代码中还未完全清理干净,欢迎感兴趣的小伙伴参与贡献。 \n**备注 2**:PageStorage 是一个 TiFlash 的抽象存储层,DeltaTree 引擎的一部分数据通过 PageStorage 模块进行存储。本文不对 PageStorage 模块做详细分析,这将由源码解读系列的其他文章进一步展开。\n\n### TiDB Region 与 TiFlash 表\n\n熟悉 TiDB 的读者可能会对 TiDB Region 这个概念比较熟悉。Region 是 TiDB **数据分片**(Sharding)的基本单位,一张物理表的数据将会切分到一个或多个 Region 中,从而实现数据分片存储及计算。在 TiFlash 存储引擎层面,由于 Region 的存在,因此**每个 TiFlash 表实际上会存储对应 TiDB 物理表的一部分数据**。\n\n以下图为例,假设部署了两个 TiFlash 节点。若设置了 employee 表的 TiFlash 副本数为 1,则这两个 TiFlash 节点各将存储 employee 表的约 50% 数据:\n\n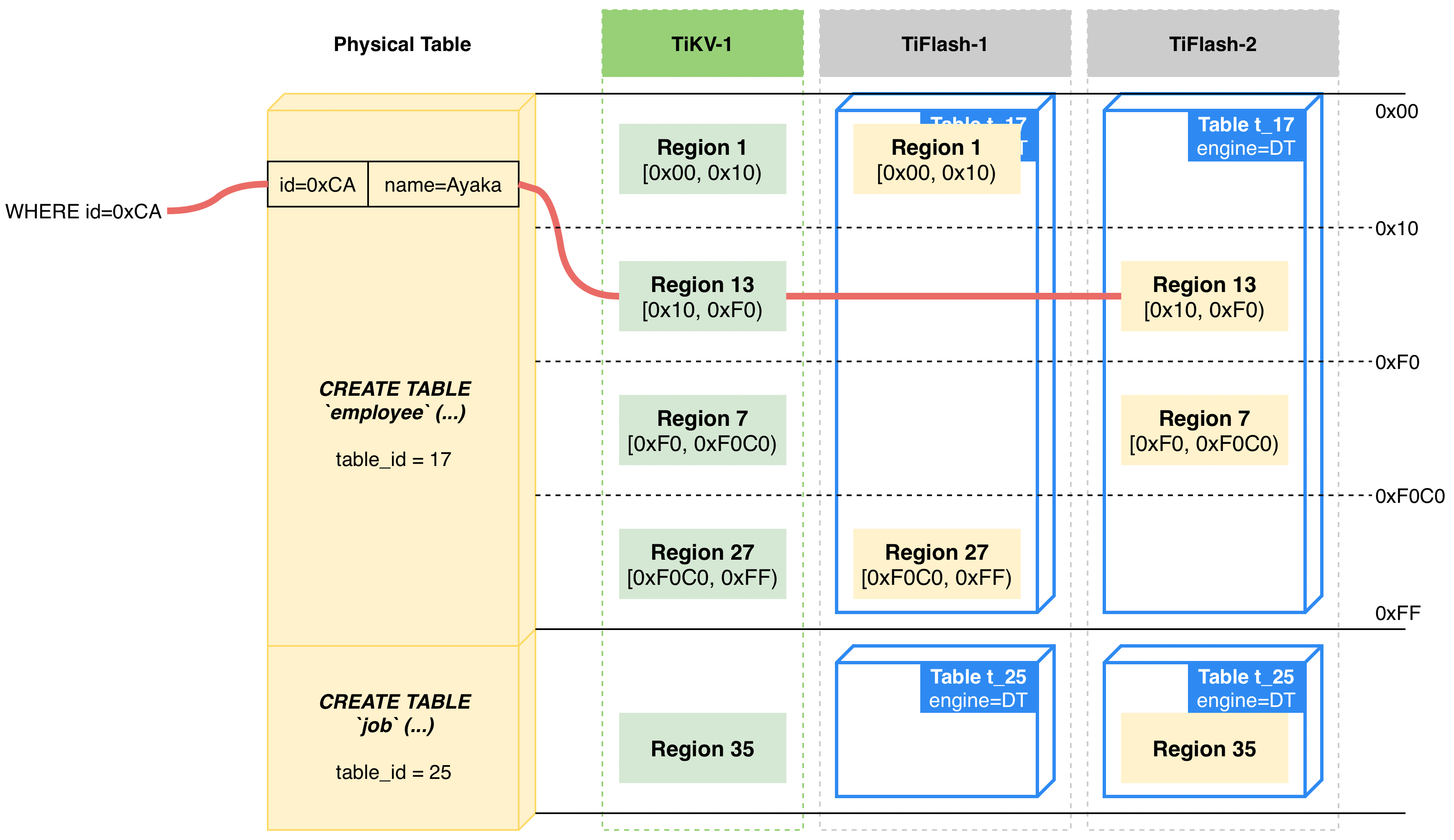\n\n同样的,假设 job 表设置的 TiFlash 副本数也为 1,由于它只有一个 Region,因此 job 表的数据会落在其中一个 TiFlash 节点上,其余 TiFlash 节点上没有数据。\n\n### Handle\n\n在 TiDB 产品(TiDB、TiKV 及 TiFlash)代码中会频繁出现 Handle 一词。为了兼容 MySQL 语法,在 TiDB 产品中通过 SQL 语句指定的主键不一定是物理数据中的主键。代码中将 SQL 语句指定的主键称为 Primary Key,而**物理数据对应的「真正的」、物理主键称为 Handle**。\n\nTiDB 产品中有以下几种不同的 Handle:\n\n**1.CommonHandle(自 v5.0+ 版本引入)**\n\n创建表时若指定主键为[聚簇索引(Clustered Index)](https://docs.pingcap.com/zh/tidb/stable/clustered-indexes),且主键不是 INT 类型,则该主键对应于 CommonHandle,例如:\n\n```SQL\n-- 指定 VARCHAR 类型的聚簇索引主键\n\nCREATE TABLE …(id VARCHAR PRIMARY KEY CLUSTERED);\n\n\n\n-- 指定聚簇索引联合主键\n\nCREATE TABLE …(… , PRIMARY KEY (a, b) CLUSTERED);\n```\n\n各模块代码中往往会采用 `is_common_handle == true` 代表这种情况。\n\n**2.IntHandle**\n\n创建表时若指定为 INT 或 UNSIGNED INT 类型(INT 的不同种类如 BIGINT、TINYINT 等也包括在内)的主键,则这个主键对应于 IntHandle,例如:\n\n```SQL\n-- 指定 INT 类型主键\n\nCREATE TABLE …(id INT PRIMARY KEY);\n\n\n\n-- 指定 UNSIGNED INT 类型主键\n\nCREATE TABLE …(id INT UNSIGNED PRIMARY KEY);\n```\n\n各模块代码中往往会采用 `is_common_handle == false && pk_is_handle == true` 代表这种情况。\n\n**3.TiDB 隐式主键**\n\n若创建表时没有指定主键,或没有开启聚簇索引,则 TiDB 内部会创建一个名为 `_tidb_rowid` 的隐式主键,并自动管理该隐式主键的值:\n\n```SQL\n-- 指定 VARCHAR 类型非聚簇索引主键\n\nCREATE TABLE …(id VARCHAR PRIMARY KEY);\n\n\n\n-- 指定 INT 类型非聚簇索引主键\n\nCREATE TABLE …(id INT PRIMARY KEY NONCLUSTERED);\n\n\n\n-- 不指定主键\n\nCREATE TABLE …(name VARCHAR);\n```\n\n各模块代码中往往会采用 `is_common_handle == false && pk_is_handle == false` 代表这种情况。\n\n> **小知识 1**\n>\n> 通过 [TiDB HTTP API](https://github.com/pingcap/tidb/blob/master/docs/tidb_http_api.md) 查看内部表结构时可以了解这张表的主键类型:\n\n```SQL\nmysql> CREATE TABLE yo(id INT PRIMARY KEY);\n\n\n\n❯ curl http://127.0.0.1:10080/schema/test/yo\n\n{\n\n \"id\": 73,\n\n \"name\": {\n\n \"O\": \"yo\",\n\n \"L\": \"yo\"\n\n },\n\n \"pk_is_handle\": true,\n\n \"is_common_handle\": false,\n\n ...\n\n}\n```\n\n\n\n> **小知识 2** \n> 可以直接通过 SQL 语句查询出 TiDB 隐式主键的值,甚至可以参与运算(如置于 WHERE 子句中):\n\n```SQL\nmysql> CREATE TABLE characters (name VARCHAR(32));\n\nQuery OK, 0 rows affected (0.06 sec)\n\n\n\nmysql> INSERT INTO characters VALUES (\"Klee\"), (\"Kazuha\");\n\nQuery OK, 2 rows affected (0.00 sec)\n\nRecords: 2 Duplicates: 0 Warnings: 0\n\n\n\nmysql> SELECT *, _tidb_rowid FROM characters;\n\n+--------+-------------+\n\n| name | _tidb_rowid |\n\n+--------+-------------+\n\n| Klee | 1 |\n\n| Kazuha | 2 |\n\n+--------+-------------+\n\n2 rows in set (0.00 sec)\n\n\n\nmysql> select * from characters where _tidb_rowid=2;\n\n+--------+\n\n| name |\n\n+--------+\n\n| Kazuha |\n\n+--------+\n\n1 row in set (0.00 sec)\n```\n\n### 存储引擎基本接口\n\nTiFlash 的 DeltaTree 引擎实现了 Clickhouse 数据表的标准存储引擎接口 `IStorage`,允许直接通过 Clickhouse SQL 进行访问,这样即可在不引入 TiDB 及 TiKV 的情况下直接对表上的数据进行简单的读写,对集成测试和调试都提供了很大的便利。Clickhouse 存储引擎上标准的读写是通过 `BlockInputStream` 及 `BlockOutputStream` 实现的,分别对应写入和读取,DeltaTree 也不例外。写入和读取的基本单位是 `Block`(请参见 `Block.h`)。 `Block` **以列为单位组织数据**,这些列合起来构成了若干行数据。\n\n当然,DeltaTree 引擎本身也需要服务于从 TiKV Raft 协议同步而来的数据写入,及来自 TiFlash MPP 引擎的数据读取。\n\n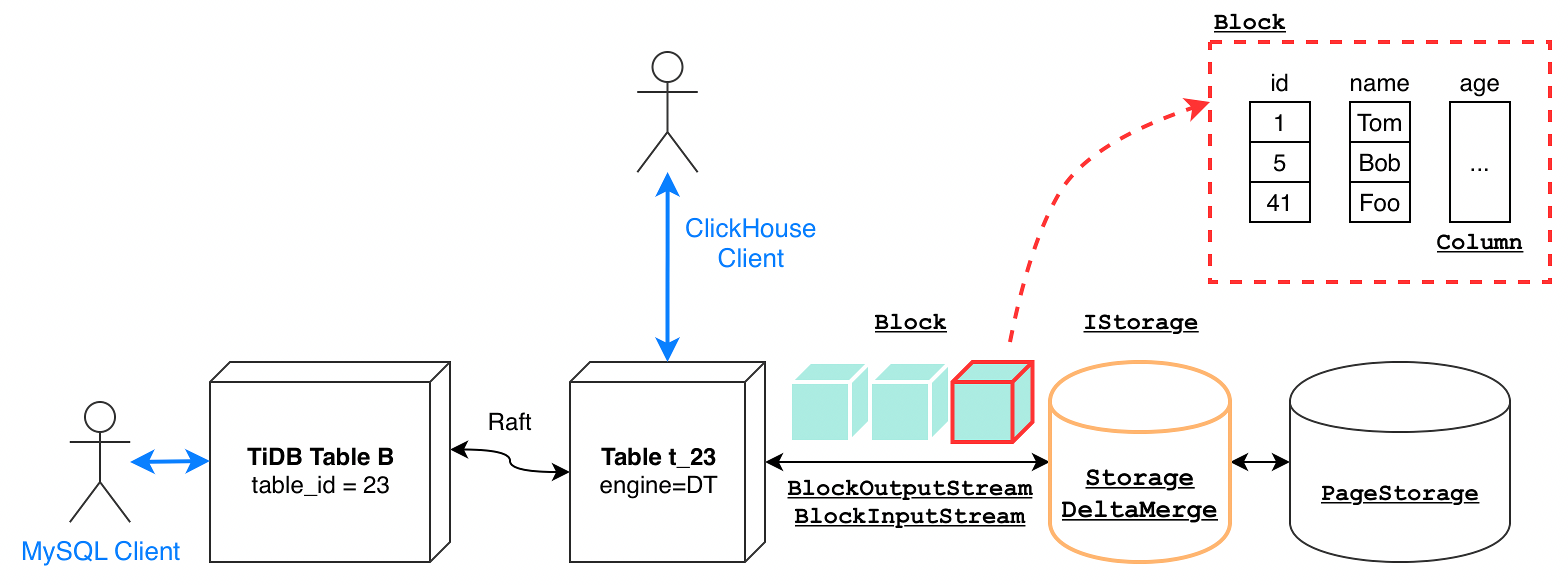\n\n\n`StorageDeltaMerge` 是 DeltaTree 存储引擎的最外层包装(参见 `StorageDeltaMerge.h`),它提供了以下接口来实现上述两类分别来自 TiDB 和 Clickhouse Client 的读写需求:\n\n- 来自 TiDB 的读请求 `StorageDeltaMerge::read() → BlockInputStream`\n\n- 来自 TiDB 的写请求\n - 从 Raft Log 增量同步:`StorageDeltaMerge::write(Block)`\n\n- 从 Raft Snapshot 全量写入:`StorageDeltaMerge::ingestFiles()`。并不是所有数据都需要通过 Raft Log 进行增量同步,例如在追加新副本时,往往就通过直接传递副本上全量数据(Raft Snapshot)的方式进行副本数据写入。\n\n- 调试及测试目的来自 Clickhouse SQL 读请求 `StorageDeltaMerge::read() → BlockInputStream`\n\n- 调试及测试目的来自 Clickhouse SQL 写请求 `StorageDeltaMerge::write() → BlockOutputStream`\n\n## DeltaTree 结构\n\n### Segment\n\nDeltaTree 引擎由一组 Segment 构成,Segment 会按需进行分裂及合并。**DeltaTree 存储的所有数据都按 Handle 列(物理主键)进行值域切分,切分为不同的 Segment**(参见 `Segment.h`)。\n\n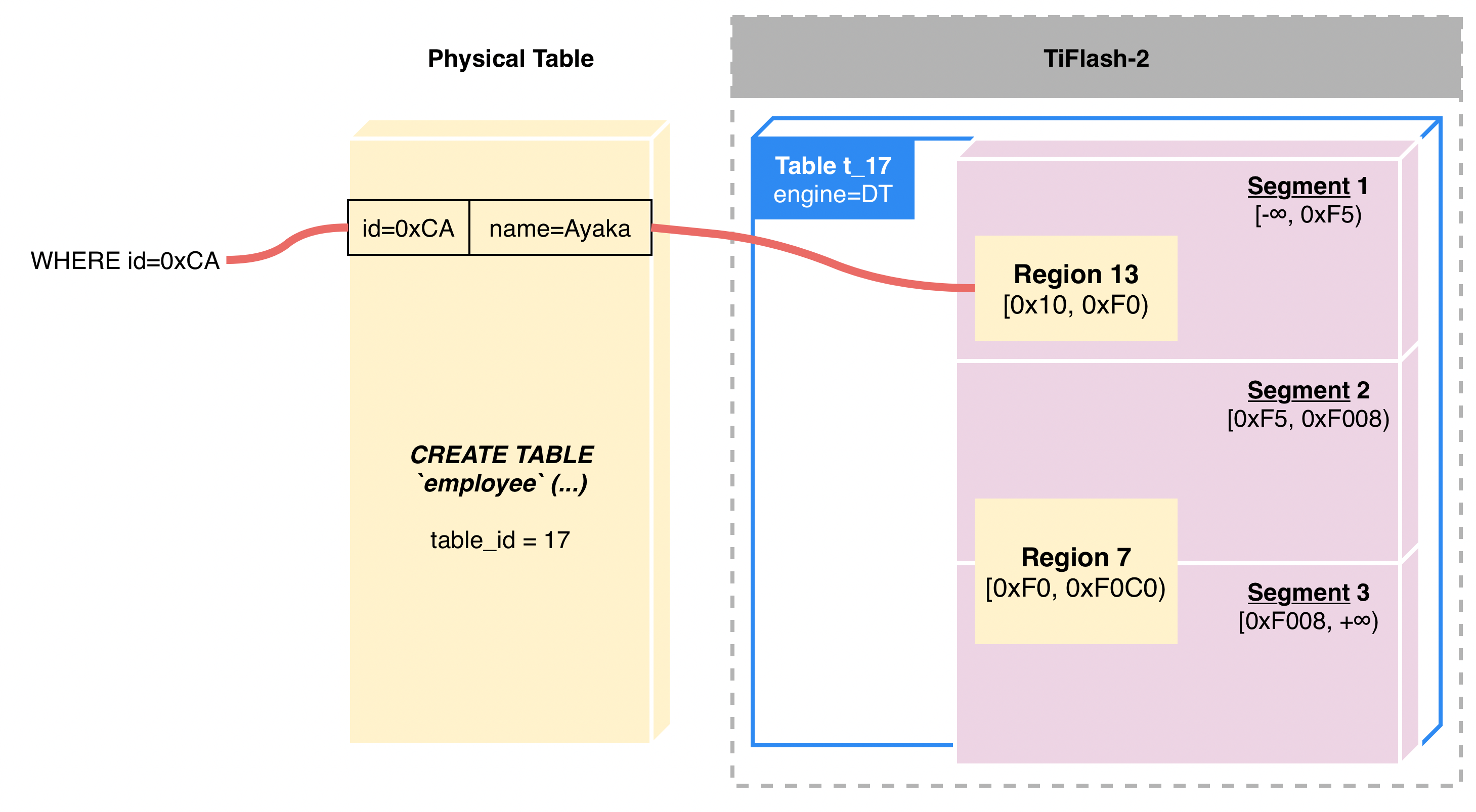\n\nSegment 形式上与 Region 有些类似,都是在依据 Handle 进行值域切分。TiFlash 的 Segment 单位较大,以便能够一次性对比较大的 Column 数据进行批量处理。一个 Segment 往往可以达到 500MB(可通过 `dt_segment_limit_size` 及 `dt_segment_limit_rows` 参数控制),相对应地,Region 一般则不超过 96MB。\n\n注意,Segment 本身与 Region 没有直接的对齐关系。例如一个 Segment 可以包含一个完整的 Region,或包含很多个 Region,也可能包含了一个 Region 的一部分。\n\n在内存中,我们简单地使用一棵红黑树记载所有 Segment:`Map`,Map 的 Key 为该 Segment 的 EndHandleKey。这使得我们能非常轻易地基于 Handle 找到它对应的 Segment。\n\n### Delta Layer, Stable Layer\n\n**单个 Segment 内部进一步按时域分为两层,一层是 Delta Layer**(参见 `DeltaValueSpace.h`)**,一层是 Stable Layer**(参见 `StableValueSpace.h`)。可以简单地想象成是一个两层的 LSM Tree:\n\n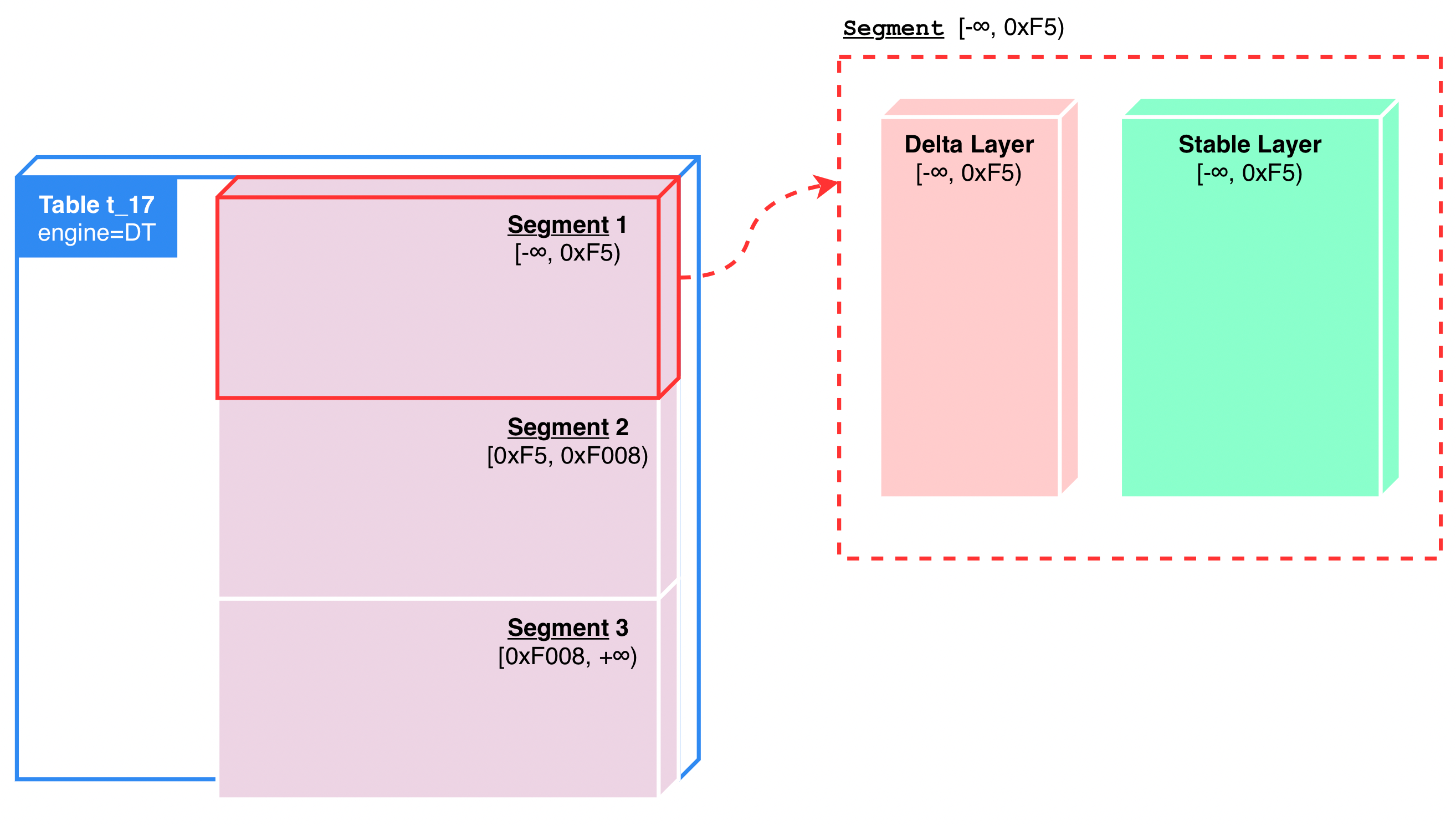\n\nDelta Layer 及 Stable Layer 在值域上是重叠的,它们都会包含整个 Segment 值域空间中的数据。**新写入或更新的数据存储在 Delta Layer 中,定期 Compaction 形成 Stable Layer。**其中单个 Segment 内的 Delta Layer 一般占 Segment 内数据的 5% 左右、剩余在 Stable Layer 中。\n\n由于 Delta Layer 主要存储新写入的数据,与写入密切相关,而绝大多数需要读取的数据又在 Stable Layer 中,因此这种双层设计给予了我们分别进行优化的空间,这两层我们采用了不同的存储结构。Delta Layer 主要面向写入场景进行优化,而 Stable Layer 则主要面向读取场景进行优化。\n\n### MVCC\n\n为了与 TiDB 的 MVCC 兼容,除了用户在建立 TiDB 表指定的列以外,DeltaTree 实际还会额外存储以下两列数据:\n\n#### MVCC 版本列\n\n该列存储了**从** **TiKV** **同步而来的行数据中记载的 commit_ts 的值,即** **MVCC** **版本号**。通过读取的时候按照该列进行过滤,TiDB 就能在访问 TiKV 及 TiFlash 时获得一致的快照隔离级别数据。若对同一行数据进行了多次更新,那么它们将产生不同的 MVCC 版本号。不同版本的相同行的数据将在 GC 的时候被清理。\n\n#### 删除标记列(Delete mark)\n\n**该列为 1 时代表对应行的数据被删除**。例如在 TiDB 中执行 DELETE 语句后,每一个删除的行在同步到 TiFlash 上后都成为了 Delete mark = 1 的列数据。这些数据会存储在表中,以便在读的时候对其进行过滤。这些数据会在 GC 的时候被清理。\n\n## 写入\n\n### 写入相关流程\n\n与写入有关的流程大致如下:\n\n1.写入时接受 Block 为单位的数据,数据置于内存中,对应结构为 `MemTableSet`(参见 `MemTableSet.h`) \n\n2.DeltaTree 后台定期将内存中的 MemTableSet 写入到磁盘上(这个过程称为 **Flush**),形成磁盘上持久化了的 Delta 层数据\n\n实际上,Delta 层数据并非是直接操作文件、存储在文件系统中,而是**通过 PageStorage 模块进行存储**。 PageStorage 是一层简单的对象存储层,提供了诸如快照、回滚、合并小 IO 等功能,针对 Delta 层数据高频 IO 等特性进行了优化。PageStorage 模块的详细设计分析将在源码阅读的后续文章中做详细介绍,本文不做展开。\n\n3.DeltaTree 后台定期将磁盘上 Delta 层的数据与磁盘上 Stable 层的数据进行合并(这个过程称为 **Merge Delta,也称为 Major Compaction**),并写入磁盘,形成新的 Stable 层数据\n\n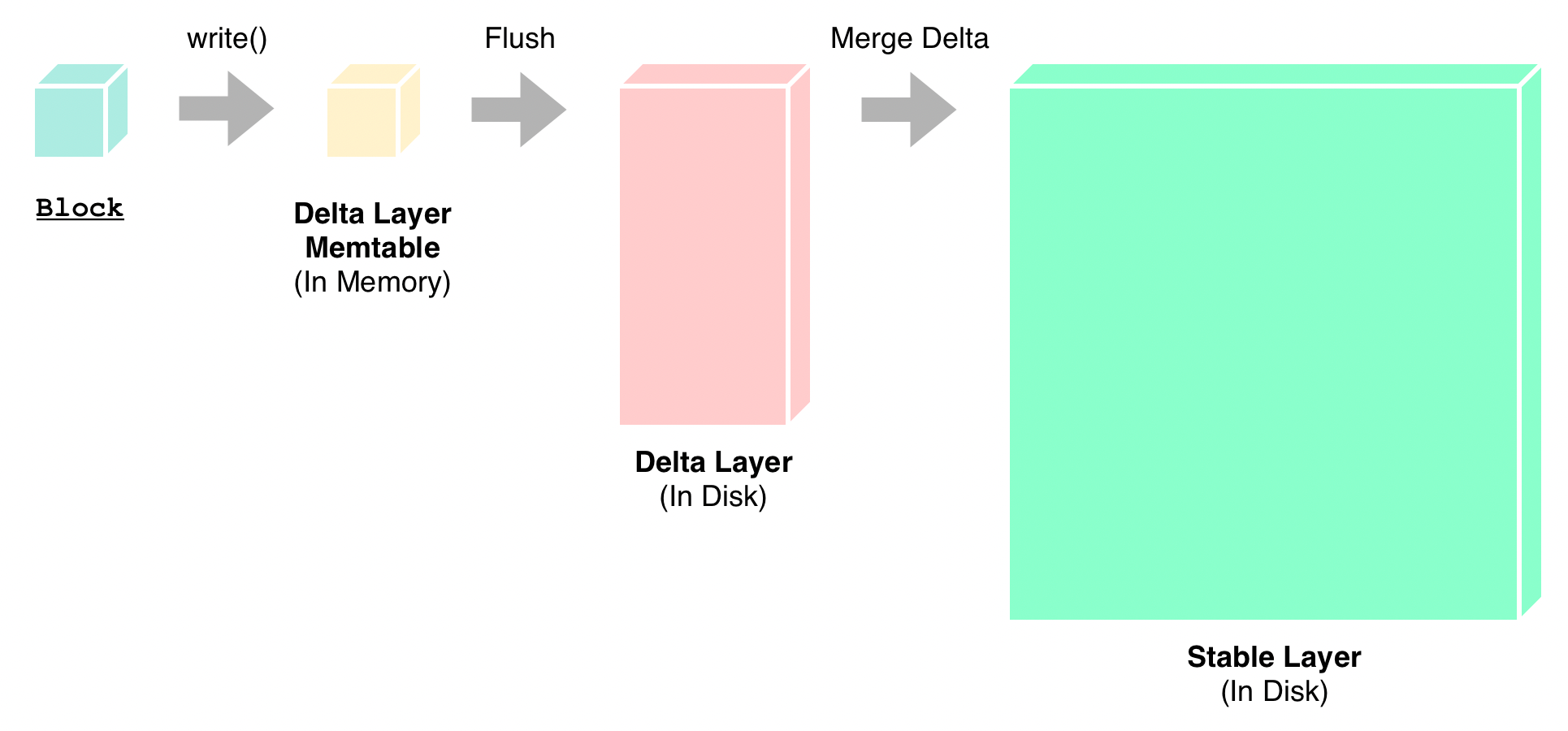\n\n该流程与标准的 LSM Tree 比较相似。\n\n### ColumnFile\n\nDeltaTree 引擎对 Delta Layer 及 Stable Layer 采用了不同的结构,分别针对写入和读取场景进行针对性优化。在 Delta Layer 中,数据的粒度是 ColumnFile。\n\n- 接受 Block 写入数据时,Block 会被包裹成 ColumnFileInMemory,追加到内存的 MemTableSet 中。ColumnFileInMemory 代表它包含了在内存中的、尚未被持久化的 Block 数据。\n- Flush 时,ColumnFileInMemory 中的数据会被写入到磁盘中(通过 PageStorage 存储),相应地,内存中结构会被替换成 ColumnFileTiny(继承自 ColumnFilePersisted),代表它内部的 Block 数据已经被持久化在磁盘上了、内存中仅有它的 metadata 信息,存放在 ColumnFilePersistedSet 中。\n\n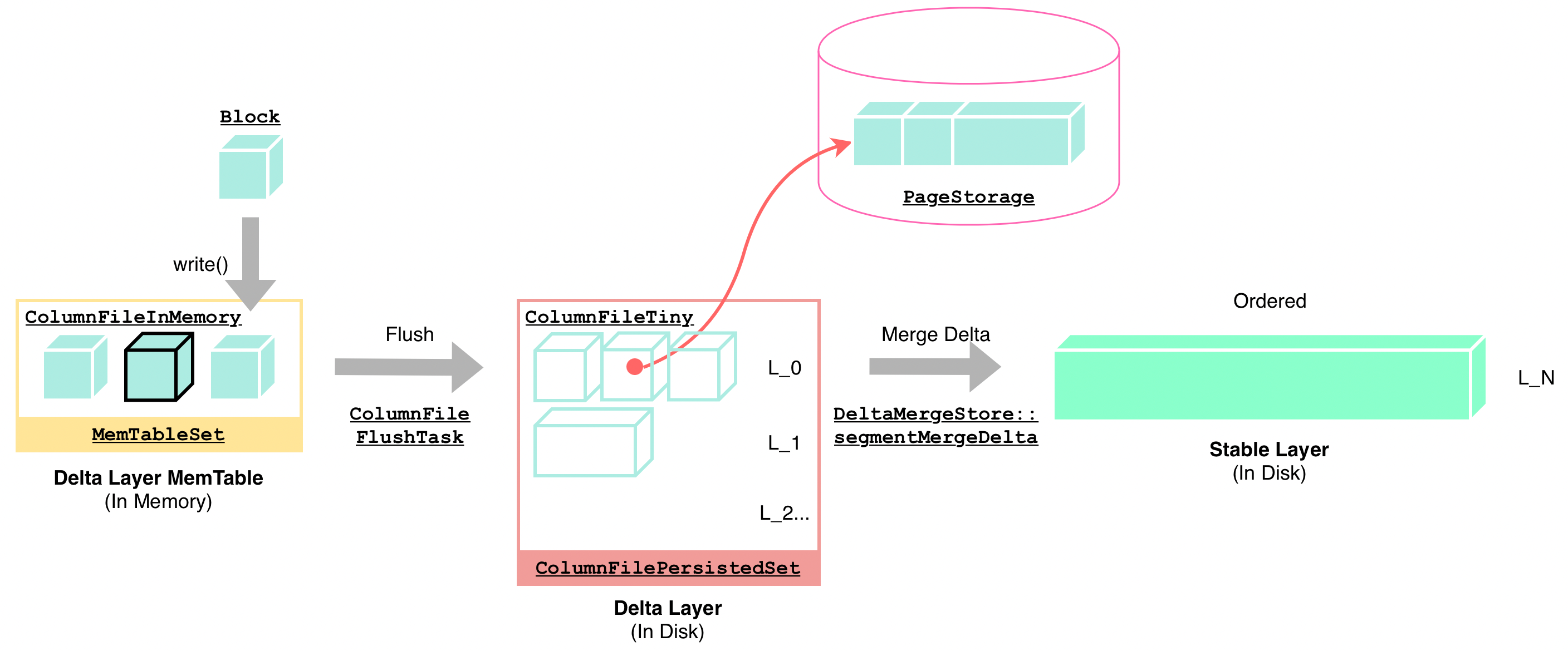\n\n除了上述两种 ColumnFile 以外,还有其他 ColumnFile 也比较重要,以下是一个 ColumnFile 的总体列表:\n\n#### ColumnFileInMemory\n\n该结构包含 Block 数据,**数据在内存中、尚未被持久化**。参见 `ColumnFileInMemory.h`。\n\n大多数对 DeltaTree 引擎的写入操作都会封装为 ColumnFileInMemory 进行后续处理。\n\n#### ColumnFilePersisted\n\n它仅仅是一个虚类,代表了所有继承自它的 ColumnFile 的数据都已经持久化在了磁盘中。参见 `ColumnFilePersisted.h`。\n\n#### ColumnFileBig\n\n继承自 ColumnFilePersisted。它指向一个已经存储于磁盘上的 DMFile 数据,参见 `ColumnFileBig.h`。DMFile 是 Stable 层数据的基本格式,后边将进行详细解释。\n\n在接受来自 Raft 层的全量数据快照(Raft Snapshot)时,构建的就是 ColumnFileBig 而非 ColumnFileInMemory。除此以外,Major Compaction 过程也会构建 ColumnFileBig。\n\n#### ColumnFileTiny\n\n继承自 ColumnFilePersisted。如前文所述,它指向一个已经存储在了 PageStorage 中的 Delta 层 Block 数据,参见 `ColumnFileTiny.h`。\n\n在 Flush 过程中,ColumnFileInMemory 会在将数据持久化后将自己转化为 ColumnFileTiny 来标记自己的数据已经被持久化了。除此以外,若写入过程收到的数据块较大,也会直接构造出 ColumnFileTiny,从而节约内存使用。\n\n#### ColumnFileDeleteRange\n\n继承自 ColumnFilePersisted。它代表在一个 Handle **范围内所有数据都被清除了**,参见 `ColumnFileDeleteRange.h`。例如,在加入新 TiFlash 节点后,其他 TiFlash 节点上副本的数据会被重新调度、以达到分布均匀的状态。此时会有 Region 副本在某些 TiFlash 节点上被擦除。这种范围内无差别的数据擦除便是通过 ColumnFileDeleteRange 来实现的,避免了普通的数据删除过程中需要先读取、再写入删除标记这种低效率的方式。\n\n### 前台写入步骤\n\n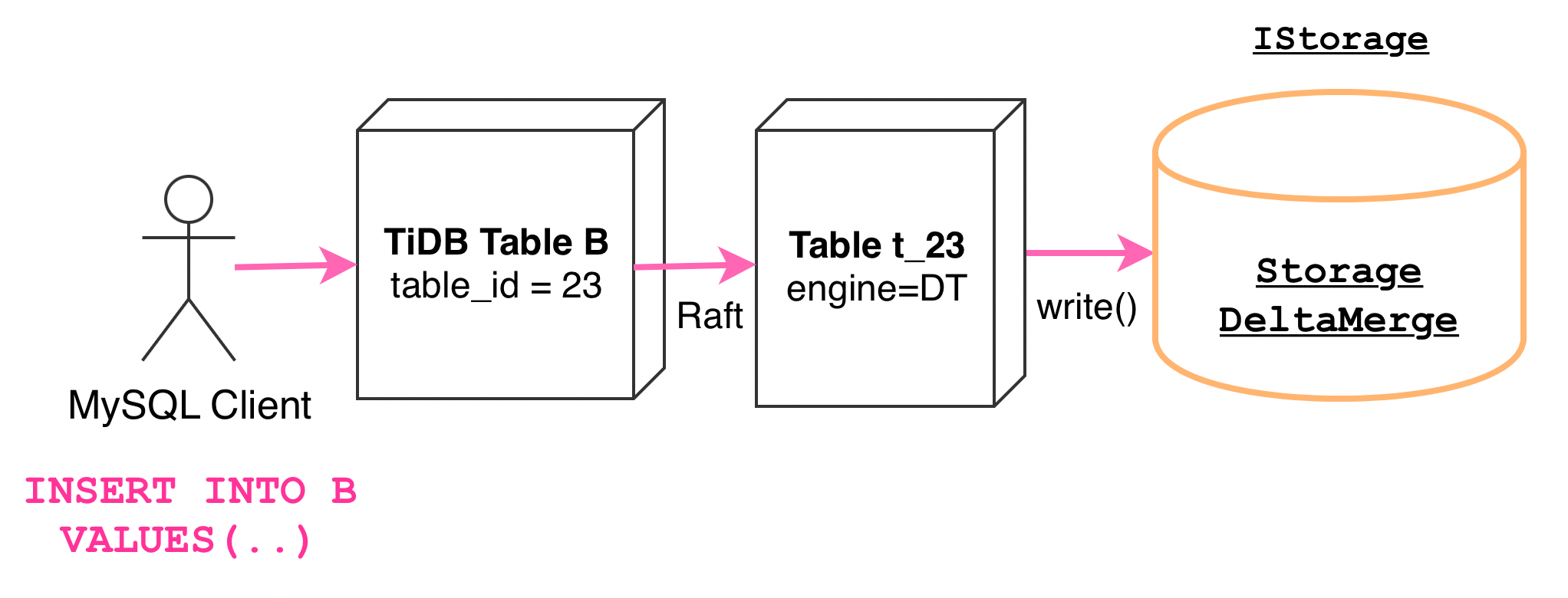\n\nDeltaTree 对外提供的写入接口中会做这些事情:\n\n1.对收到的 Block 进行排序。\n\n排序方式是 (Handle, Version)。这个排序方式与 TiKV 一致,使得 TiFlash 能保持和 TiKV 一样的数据先后顺序。\n\n2.对 Block 按照 Segment 值域进行切分,并写入到各个 Segment 的 MemTableSet 中。\n\n在写入的过程中,若当前 Segment 已积压的数据过多了,写入会被阻塞(Write Stall)并等待 Segment 完成更新。例如,可能用户猛烈地写入了大批数据,积压了大量数据来不及进行 Flush 或进行 Compaction。\n\n若不需要 Write Stall,则 Block 数据会被写入到一个已有的、位于 MemTableSet 的 ColumnFileInMemory 中,或 Block 数据比较大的话,则写入到一个 ColumnFileTiny 中、再加入 MemTableSet。\n\n3.尝试对 Segment 进行更新。\n\n例如,尝试触发 Flush、Compaction、Segment 的合并和分裂等。\n\n此时,单次写入操作便已完成。详情可参见 `DeltaMergeStore::write(Block)` 函数了解详细实现。\n\n需要注意的是,在前台写入路径上,**数据写入到内存** `**MemTableSet**` **中就写入完毕、可以返回了**,后续涉及磁盘 IO 的 Flush 及 Merge Delta 操作都是后台操作,不会对写入延迟产生直接影响。另外,由于 IO 发生在 Flush 阶段,而非写入阶段,因此这也起到了对于高频写入减少 IO 的效果。\n\n> 既然写入返回时数据还没写入到磁盘上,那么此时掉电了怎么办?实际上由于 TiFlash 从 TiKV Raft log 同步数据,因此 **Raft log 即为 TiFlash 数据的 WAL**。在掉电后,从上次已经完成 Flush 操作的 Raft Apply 位置恢复数据即可。\n\n### Flush 步骤\n\n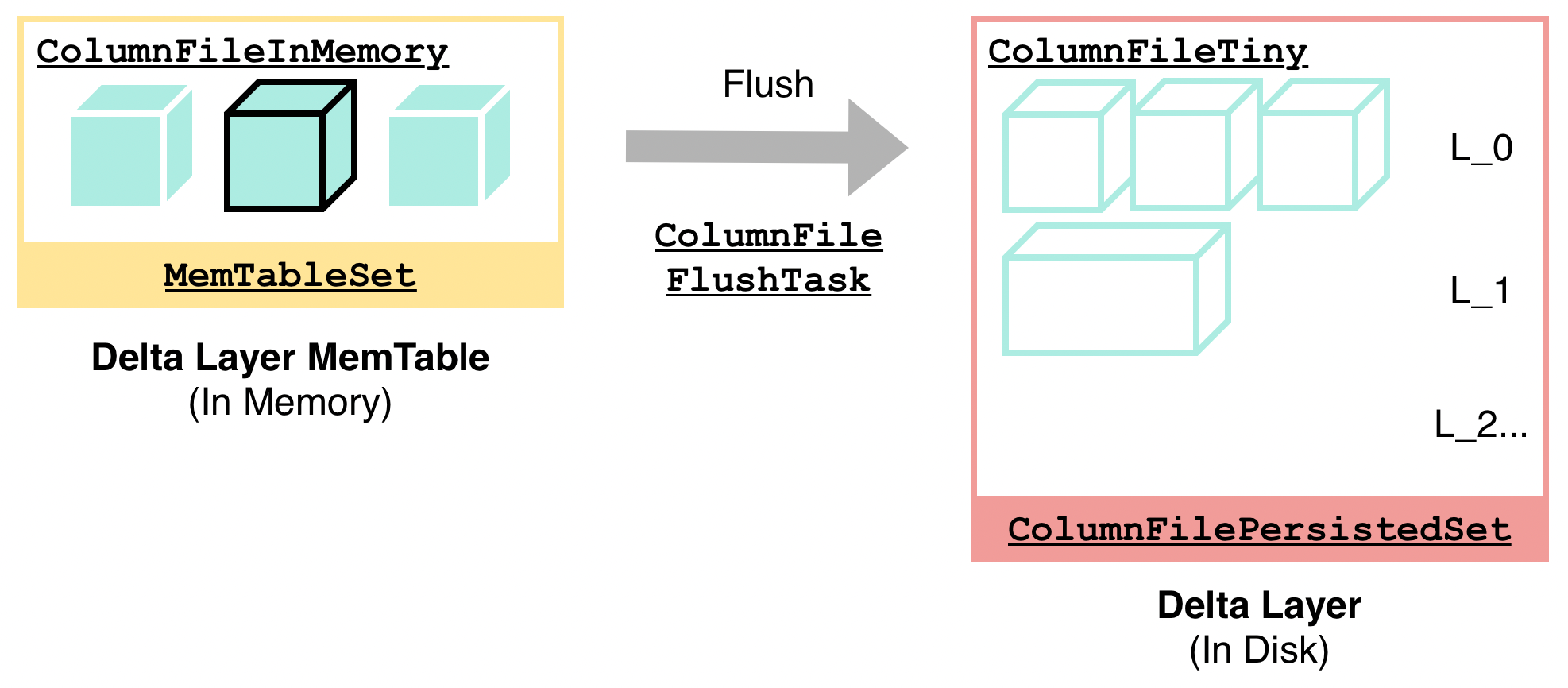\n\n通过 Flush 过程,内存中的数据会被写入到 Delta Layer 的持久化存储(PageStorage)中,步骤如下:\n\n1. 对 DeltaValueSpace 上锁并将所有的 MemTableSet 中的 ColumnFile 提取出来,构建出待 Flush 的任务列表。\n2. Prepare\n - 对每个 ColumnFile 再次按照 (Handle, Version) 进行排序。虽然每次写入过程中,待写入的 Block 本身会按照 (Handle, Version) 进行排序,但多次写入的 Block 可能会被追加到相同的 ColumnFileInMemory 中,因此在 ColumnFileInMemory 并不保证有序,Flush 的时候会再次进行排序。\n - 将排序后的数据写入 PageStorage,此时涉及磁盘 IO。\n3. 对 DeltaValueSpace 上锁,并 Apply\n - 将每一个已经完成写入的 ColumnFileInMemory 替换成 ColumnFilePersisted,放入 ColumnFilePersistedSet 内存结构。\n - 若这个过程失败了,则对已经写入 PageStorage 的数据进行回滚。\n\n在上述过程中,有一个比较有意思的设计是,**DeltaTree 会采用类似于乐观锁的方式,尽可能减少上锁时间,并采用事后回退的方式处理冲突**。例如,多个 Flush 可能同时发生——一个 Flush 在前台写入中触发,一个 Flush 在后台触发。在这个情况下,只有一个 Flush 会完成并成功修改内存结构。通过这种设计,整个结构上锁的时间内去除了可能有显著延迟的 IO 等操作,从而缩短了整个结构的上锁时间,提高了性能。读者会在接下来的其他 DeltaTree 的步骤中频繁地见到这种上锁模式。\n\n详细可参见 `DeltaValueSpace::flush` 函数及 `ColumnFileFlushTask.h`。\n\n### Minor Compaction 步骤\n\n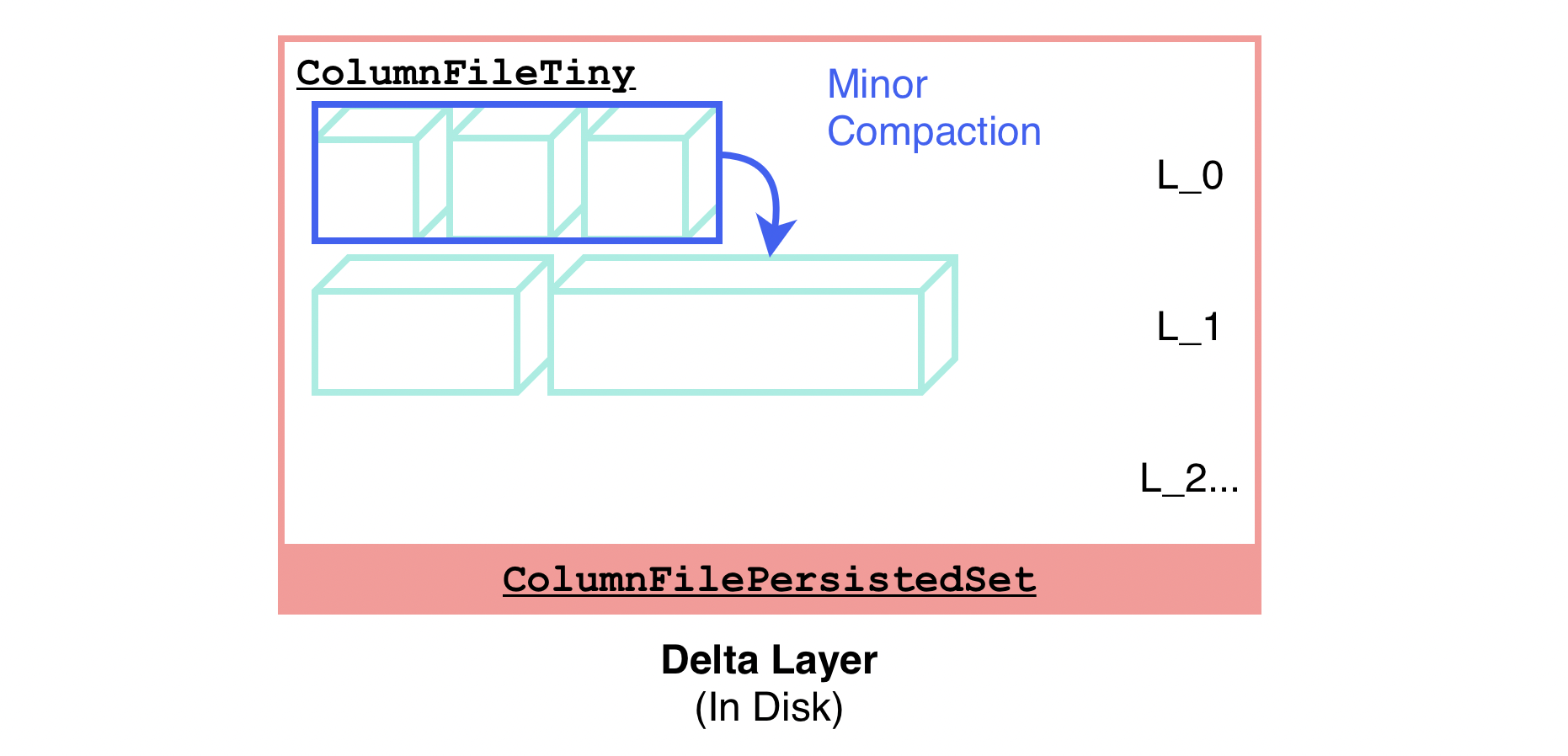\n\nColumnFilePersistedSet 可能会包含比较多的零碎小数据块,这些小数据块直到触发 Major Compaction(即 Merge Delta)时才会被清理、合并,这会对读的过程带来比较高的 IOPS**。为了节约读 IOPS,DeltaTree 后台会持续对零碎的、小的 ColumnFileTiny 进行合并**,合成一个大的 ColumnFileTiny,这个过程称为 Minor Compaction。\n\nDeltaTree 的 Minor Compaction 过程会形成类似于 LSM Tree 的多层结构,与 LSM Tree 有些相似,但不完全一致。例如,在当前设计中,Delta Layer 每一层的每一个 ColumnFileTiny 都不保证有序(合并 ColumnFileTiny 时仅仅是简单地数据头尾相接),而且各层的 ColumnFileTiny 之间也会有值域重叠。因此,在发起读请求的时候,事实上这些 ColumnFileTiny 实际上都有可能需要被读取到。\n\nMinor Compaction 过程如下,同样也是 Lock + Prepare + Lock & Apply 的模式:\n\n1. 对 DeltaValueSpace 上锁,并提取某一层中比较小的 ColumnFileTiny\n2. Prepare\n - 将这些 ColumnFileTiny 数据进行简单的头尾合并成一个新的 ColumnFileTiny,然后写入到下一层\n3. 对 DeltaValueSpace 上锁,并 Apply\n - 将 Prepare 过程中新生成的 ColumnFileTiny 及合并掉的 ColumnFileTiny 在内存结构中进行更新\n\n详细可参见 `DeltaValueSpace::compact` 函数。\n\n### Major Compaction (Merge Delta) 步骤\n\n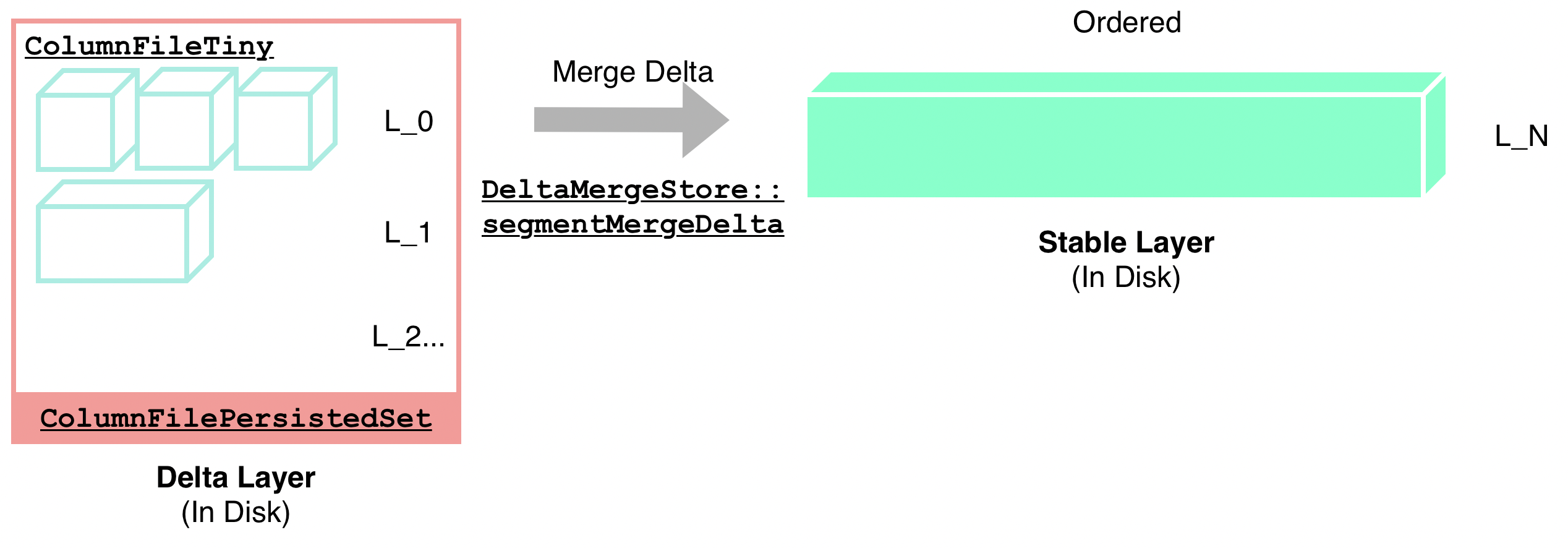\n\nDelta 层已持久化的增量更新数据与 Stable 层已持久化的、面向读优化的大部分数据进行合并的过程称为 Merge Delta,它也是整个 DeltaTree 存储引擎最主要的数据整理操作(Major Compaction)。在这个过程中,该 Segment 的**整个 Stable 层数据会与整个 Delta 层数据进行合并**,替换生成一个新的 Stable 层数据,步骤如下:\n\n1. 对整个 DeltaTree 存储层上读锁,从而取得一个 Delta 层数据、Stable 层数据、当前表结构(Schema)的快照\n2. Prepare\n - 从 Delta 层级 Stable 层联合读取有序、去重的数据\n - 将数据写入到一个 DMFile 作为新的 Stable 层\n3. 对整个 DeltaTree 存储层上写锁,并 Apply\n - 清理现有 Delta 及 Stable 层数据,并将新的 Stable 层数据在内存结构中进行更新\n\n详细可参见 `DeltaMergeStore::segmentMergeDelta` 函数。\n\n### Stable 层物理存储结构\n\n**Stable 层的数据按照 (Handle, Version) 排序**,**并切分了多个 Pack 作为 IO 粒度**(每个 Pack 大约是 8192 行,通过 `dt_segment_stable_pack_rows` 参数控制)。单一列内数据相邻地存储在一起,总体逻辑结构如下图所示:\n\n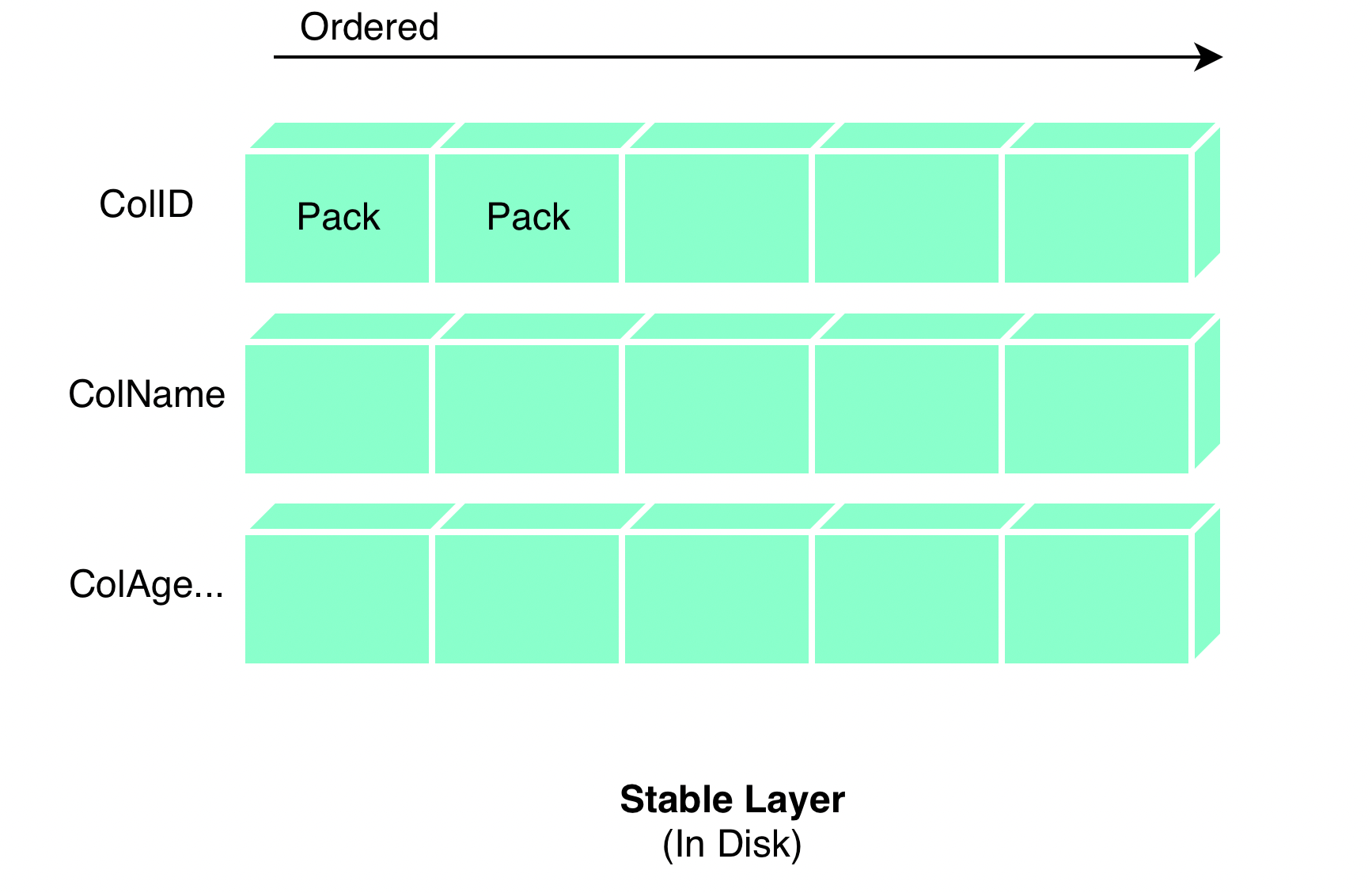\n\n不同于 Delta 通过 PageStorage 在磁盘上存储数据,Stable 层直接将上述结构及数据存储在磁盘文件上,该存储格式被称为 `DMFile`。虽然名字中有个 file,但 `DMFile` 实际是一个文件夹,其内部包含的文件如下所示:\n\n- **dmf_/pack:**\n\n存储了每个 Pack 的信息,例如 pack 中实际有多少行等等。详细可参见 `PackStats` 结构。\n\n- **dmf_/meta.txt:**\n\n记录了 DMFile 的格式(例如 V1、V2)等。\n\n- **dmf_/config:**\n\n记录了该 DMF 的一些配置信息,目前主要包含各个数据文件的 Checksum 方式等配置。详细可参见 `DMChecksumConfig` 结构。\n\n- **dmf_/.dat**\n\n压缩存储了 col_id 列的数据。默认情况下压缩方式是 LZ4,可通过 `dt_compression_method` 参数进行配置。\n\n- **dmf_/.mrk**\n\n标记文件,存储了各个 Pack 在 .dat 文件中的 offset。在读取数据内容时,可以通过这个标记文件中记录的偏移信息,跳过并只读取特定 Pack 的数据。详细可参见 `MarkInCompressedFile` 结构。\n\n- **dmf_/.idx**\n\n索引文件,目前 DeltaTree 只支持 Min Max 索引,该文件会存储 col_id 列在各个 Pack 区间上的最大最小值。在查询时,一些列上的查询条件可通过这里的 Min Max 索引跳过不需要的 Pack,从而减少 IO。详细可参见 `MinMaxIndex` 结构。\n\n## 动手实践!\n\n对一个系统加深理解的最好方法莫过于动手实践了。由于 TiFlash 保留了 Clickhouse Client 兼容的 SQL 查询接口,因此可以通过这个内部接口来对本文中描述的各种概念进行实验。\n\n启动包含 TiFlash 的 TiDB 集群后,可以通过 `tiup tiflash client` 快捷地通过 Clickhouse SQL 接口连入 TiFlash:\n\n```Ruby\n# Start Server\n\n$ tiup playground nightly\n\n\n\n# Run TiFlash Client\n\n$ tiup tiflash client --host 127.0.0.1\n```\n\n连入后,你可以执行大部分 Clickhouse SQL 语句(推荐仅进行查询语句),例如 `SELECT`、`SHOW TABLES` 等,也可以执行 TiFlash 特有的 Clickhouse SQL 语句,如:\n\n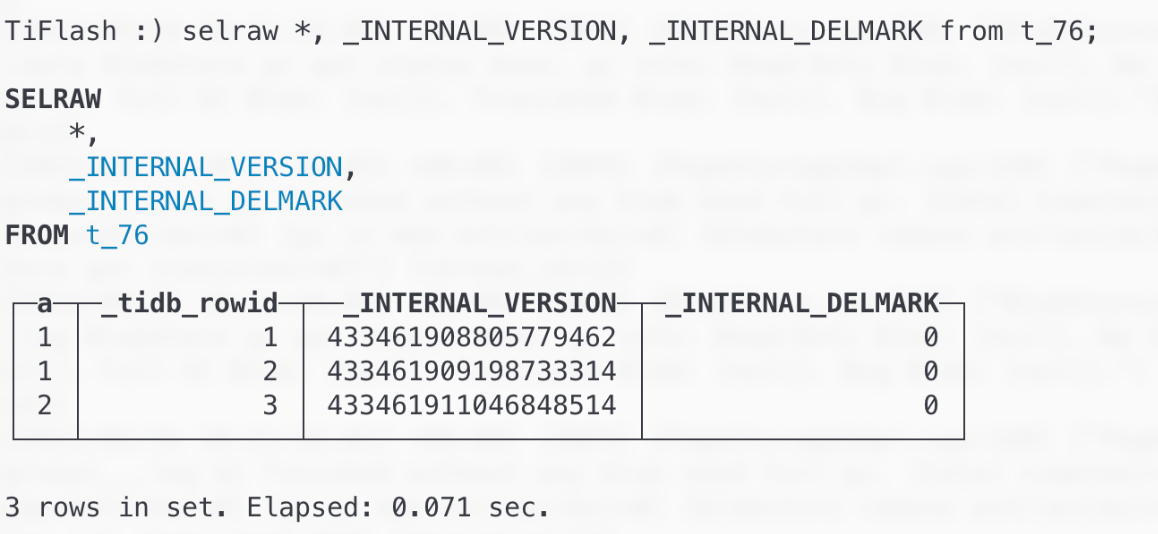\n\n除了 `SELRAW` 语句以外,`DBGInvoke` 也是一个常用的内部语句,本文不作详细展开,读者可在 TiFlash 源码中搜索 `> DBGInvoke` 查询到在各个测试文件中是如何调用 `DBGInvoke` 语句查询或操作内部结构的。\n\n## 结语\n\n本文主要针对 DeltaTree 引擎写入过程中涉及到的各个模块及其设计进行了分析。由于篇幅原因,从 DeltaTree 引擎中读数据的过程及相应优化将在下一篇中进行分析,读者可关注 TiFlash 源码解读的后续更新。另外,本文也仅仅是呈现了一个 TiFlash 给出的「答案」,即存储引擎设计成什么样可以支撑可更新、可高频写入、可进行高性能 OLAP 分析这些需求。至于这个「答案」本身是如何的得出来的、背后的设计思路及取舍并没有涵盖。我们将在下一期 TiFlash 源码阅读中给出详细的介绍。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n\n> 点击查看更多 [TiFlash 源码阅读](https://pingcap.com/zh/blog?tag=TiFlash%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)系列文章\n","author":"施闻轩","category":1,"customUrl":"tiflash-source-code-reading-3","fillInMethod":"writeDirectly","id":393,"summary":"本文分为两部分,主要介绍 TiFlash DeltaTree 存储引擎的设计细节及对应的代码实现。Part 1 部分主要涉及写入流程,Part 2 主要涉及读取流程,本次分享为 Part 1。","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(三)TiFlash DeltaTree 存储引擎设计及实现分析 - Part 1"}},{"relatedBlog":{"body":"TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。在[上一期源码阅读](https://pingcap.com/zh/blog/tiflash-source-code-reading-3)中,我们介绍了 TiFlash 的存储引擎,本文将介绍 TiFlash DDL 模块的相关内容,包括 DDL 模块的设计思路, 以及具体代码实现的方式。\n\n本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。\n\n## Overview\n\n本章节,我们会先对 DDL 模块做一个 overview 的介绍,介绍 **DDL 在 TiFlash 中相关的场景**,以及 **TiFlash 中 DDL 模块整体的设计思想**。\n\n这边的 DDL 模块指的是对应负责处理 add column, drop column, drop table recover table 等这一系列 DDL 语句的模块,也是负责跟各数据库和表的 schema 信息打交道的模块。\n\n### DDL 模块在 TiFlash 中的相关场景\n\n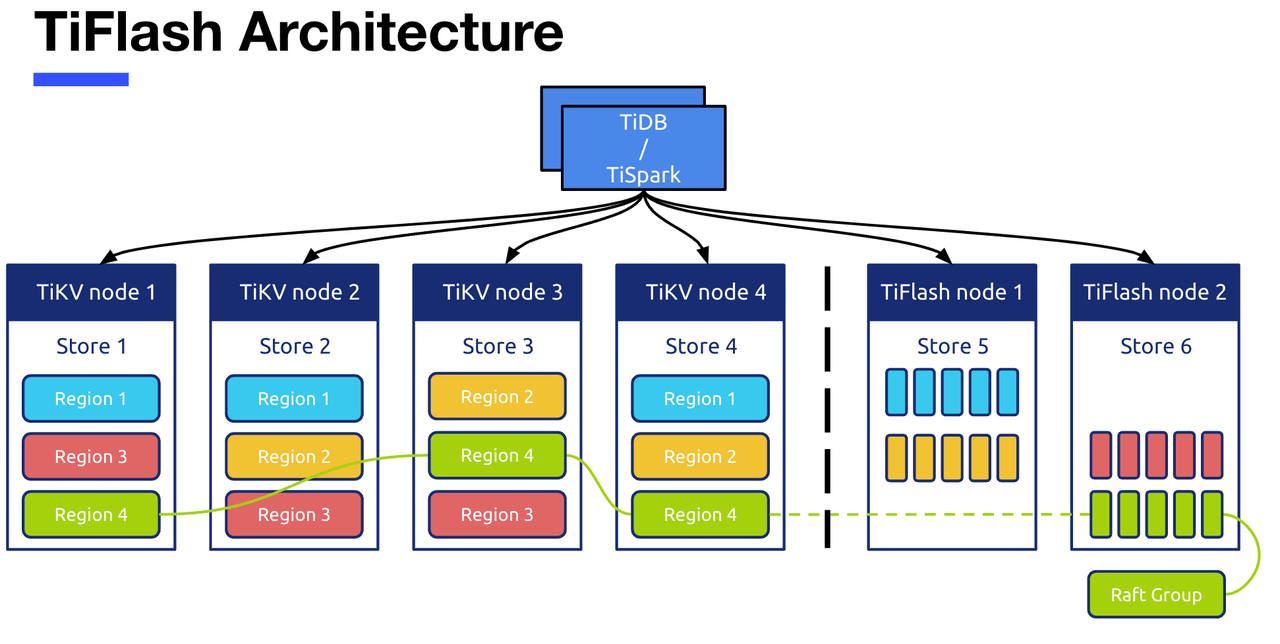\n\n图一 TiFlash 架构示意图\n\n图一是 TiFlash 的架构示意图,上方是 TiDB/TiSpark 的计算层节点,虚线的左边是四个 TiKV 的节点,右边就是两个 TiFlash 节点。这张图体现的是TiFlash 一个重要的设计理念:**通过利用 Raft 的共识算法,TiFlash 会作为 Raft 的 Learner 节点加入 Raft group 来进行数据的异步复制**。Raft Group 指的是 TiKV 中由多个 region 副本组成的 raft leader 以及 raft follower 组成的 group。从 TiKV 同步到 TiFlash 的数据,在 TiFlash 中同样是按照 region 划分的,但是在内部会通过列存的方式来存到 TiFlash 的列式存储引擎中。\n\n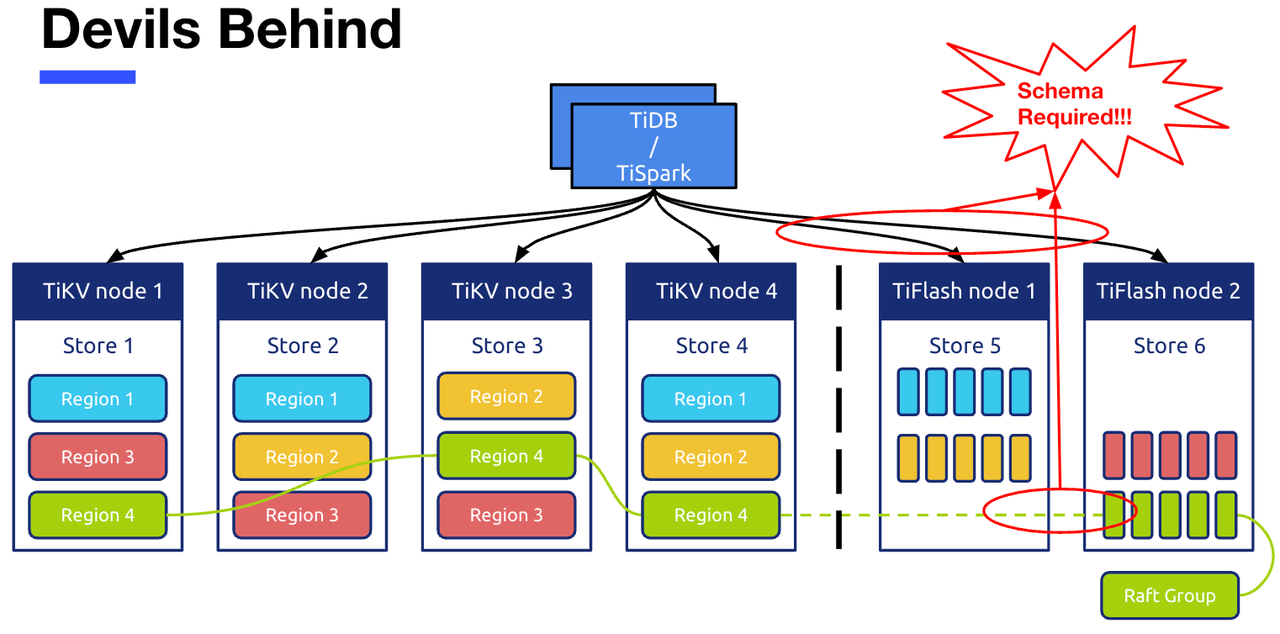\n图二 TiFlash 架构示意图(含 Schema)\n\n图二是一个概览的架构设计,掩盖了许多细节部分。其中图中这两个红圈对应的部分,就是本文要讨论的主角 **DDL模块**。\n\n下方的红圈是关于 TiFlash 的写操作。TiFlash 节点是以 learner 角色加入到了 TiKV 中一个个 region 对应的 raft group 中,通过 raft leader 不断发送 raft log 或者 raft snapshot 来给 learner 节点同步数据。 但是因为 TiKV 中数据都是行存的格式,而我们 TiFlash 中需要的数据则是列存的格式,所以 TiFlash 节点在接收到 TiKV 发送过来的这个行存格式的数据以后,需要把他进行一个行转列的转换,转换成需要的列存的格式。而这个转换,就需要依赖对应表的 schema 信息来完成。同样,上方的红圈指的是在 TiDB/TiSpark 来 TiFlash 中读取数据的过程,这个读数据的过程同样也是依赖 schema 来进行参与解析的。**因此,TiFlash 的读写操作都是需要强依赖 schema 的,schema 在 TiFlash 中亦是有重要的作用的**。\n\n### DDL 模块整体设计思想\n>在具体了解 TiFlash DDL 模块的整体设计思想之前,我们先来了解一下 DDL 模块在 TiDB 和 TiKV 中的对应情况,因为 TiFlash 接收到的 schema 的变更信息亦是从 TiKV 节点发送的。 \n#### TiDB 中 DDL 模块基本情况\nTiDB 的 DDL 模块是借鉴 Google F1 来实现的在分布式场景下,无锁并且在线的 schema 变更。具体的实现可以参考 [TiDB 源码阅读系列文章(十七)DDL 源码解析](https://pingcap.com/zh/blog/tidb-source-code-reading-17)。TiDB 的 DDL 机制提供了两大特点:\n\n1.**DDL 操作会尽可能避免发生 data reorg**(data reorg 指的是在表中进行数据的增删改)。\n\n - 图三这个 add column 的例子里面,原表有 a b 两列以及两行数据。当我们进行 add column 这个 DDL 操作时,我们不会在原有两行中给新增的 c 列填上默认值。如果后续有读操作会读到这两行的数据,我们则会在读的结果中给 c 列填上默认值。通过这样的方式,我们来避免在 DDL 操作的时候发生 data reorg。诸如 add column, drop column,以及整数类型的扩列操作,都不需要触发 data reorg 的。\n\n\n\n 图三 add column 样例\n \n - 但是对于有损变更的 DDL 操作(例如:缩短列长度(后续简称缩列)的操作,可能会导致用户数据截断的 DDL变更),我们不可避免会发生 data reorg。但是在有损变更的场景下,我们也不会在表的原始列上进行数据修改重写的操作,而是通过新增列,在新增列上进行转换,最后删除原列,对新增列更名的方式来完成 DDL 操作。图四这个缩列 (modify column) 的例子中,我们原表中有 a, b 两列 ,此次 DDL 操作需要把 a 列从 int 类型缩成 tiny int 类型。整个 DDL 操作的过程为:\n \n - 先新增一列隐藏列 _col_a_0。\n - 把原始 a 列中的数值进行转换写到隐藏列 _col_a_0 上。\n - 转换完成后,将原始的 a 列删除,并且将 _col_a_0 列重命名为 a 列。(这边提到的删除 a 列也并非物理上把 a 列的数值删除,是通过修改 meta 信息的方式来实现的)*\n \n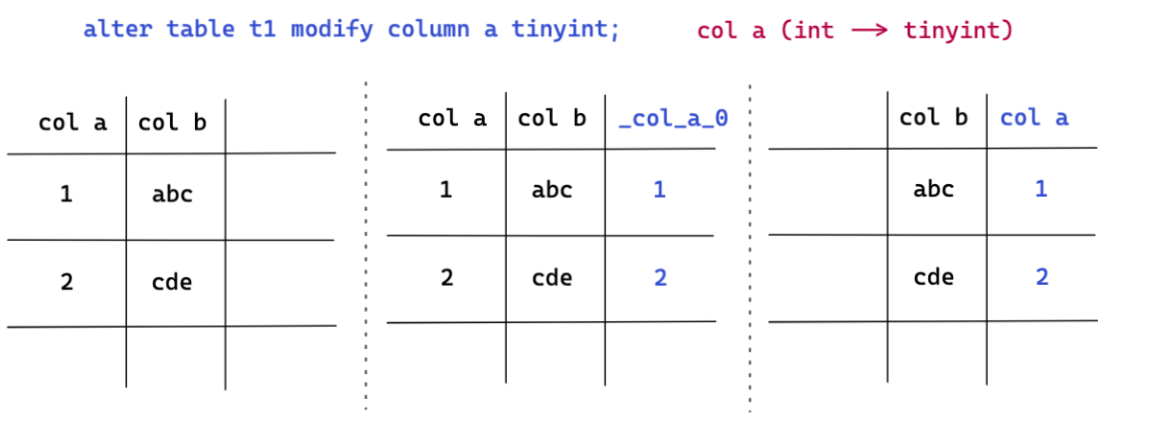\n\n图四 modify column 样例\n\n另外对于缩列这个 DDL 操作本身,我们要求缩列过程中不会发生数据的丢失。比如要从 int 缩成 tinyint时,就要求原有列的值都是在 tinyint 范围内的,而不支持出现本身超出 tinyint 的值转换成 tinyint 类型。对于后者的情况,会直接报错 overflow,缩列操作失败。\n\n2.**相对数据更新的 schema 永远可以解析旧的数据**。这一条结论亦是我们后面 TiFlash DDL 模块依赖的一条重要的保证。这个保证是依赖我们行存数据的格式来实现的。在存数据的时候,我们是将column id 和 column value 一起存储的,而非column name和column value一起存储。另外我们的行存格式可以简化的理解为是一个 column_id → data 的一个 map 方式(实际上我们的行存并非一个 map,而是用二进制编码的方式来存储的,具体可以参考 [Proposal: A new storage row format for efficient decoding](https://github.com/pingcap/tidb/blob/1a89decdb192cbdce6a7b0020d71128bc964d30f/docs/design/2018-07-19-row-format.md))。\n\n - 我们可以通过图五这个例子,来更好的理解一下这条特性。左边是一个两列的原表,通过 DDL 操作,我们删除了 a 列,新增了 c 列,转换为右边的 schema 状态。这时,我们需要用新的 schema 信息去解析原有的老数据,根据新 schema 中的每个 column id,我们去老数据中找到每个 column id 对应的值,其中 id_2 可以找到对应的值,但 id_3 并没有找到对应的值,因此,就给 id_3 补上该列的默认值。而对于数据中多个 id_1 对应的值, 就选择直接舍弃。通过这样的方式,我们就正确的解析了原来的数据。\n \n\n\n图五 新 schema 解析旧数据样例\n\n#### TiKV 中 DDL 模块基本情况\n\nTiKV 这个行存的存储层,本身是没有在节点中保存各个数据表对应的 schema 信息的,因为 TiKV 本身的读写过程都不需要依赖自身提供的 schema 信息。\n\n1. TiKV 的写操作本身是不需要 shcema ,因为写入 TiKV 的数据是上层已经完成转换的行存的格式的数据(也就是 kv 中的 v)。\n2. 对于 TiKV 的读操作\n - 如果读操作只需要直接把 kv 读出,则也不需要 schema 信息。\n - 如果是需要在 TiKV 中的 coprocesser 上处理一些 TiDB 下发给 TiKV 承担的下推计算任务的时候,TiKV 会需要 schema 的信息。但是这个 schema 信息,会在 TiDB 发送来的请求中包含,所以 TiKV 可以是直接拿 TiDB 发送的请求中的 schema 信息来进行数据的解析,以及做一些异常处理(如果解析失败的话)。因此 TiKV 这一类读操作也不会需要自身提供 schema 相关的信息。\n#### TiFlash 中 DDL 模块设计思想\nTiFlash 中 DDL 模块的设计思想主要包含了以下三点:\n1. **TiFlash 节点上会保存自己的 schema copy**。一部分是因为 TiFlash 对 schema 具有强依赖性,需要 schema 来帮助解析行转列的数据以及需要读取的数据。另一方面也因为 TiFlash 是基于 Clickhouse 实现的,所以很多设计也是在 Clickhouse 原有的设计上进行演进的,Clickhouse 本身设计中就是保持了一份 schema copy。\n2. 对于 TiFlash 节点上保存的 schema copy,我们选择通过**定期从 TiKV 中拉取最新的 schema**(本质其实是拿到 TiDB 中最新的 schema 信息)来进行更新,因为不断持续地更新 schema 的开销是非常大的,所以我们是选择了定期更新。\n3. 读写操作,会**依赖节点上的 schema copy 来进行解析**。如果节点上的 schema copy 不满足当下读写的需求,我们会**去拉最新的schema信息**,来保证schema 比数据新,这样就可以正确成功解析了(这个就是前面提到的 TiDB DDL 机制提供的保证)。具体读写时对 schema copy 的需求,会在后面的部分具体给大家介绍。\n\n## DDL Core Process\n>本章节中,我们将介绍 TiFlash DDL 模块核心的工作流程。\n\n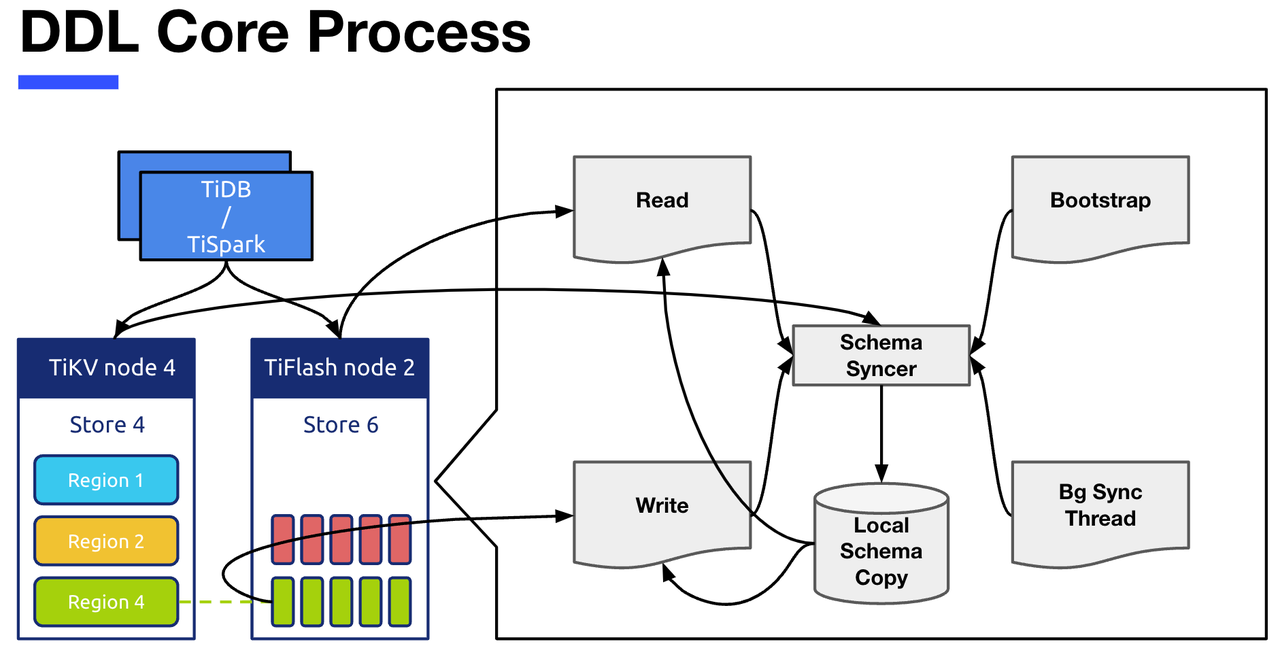\n\n图六 DDL Core Process\n\n图六左边是各个节点的一个缩略展示,右边放大显示了TiFlash 中跟 DDL 相关的核心流程,分别为:\n\n1. Local Schema Copy 指的是 TiFlash 节点上存的 schema copy 的信息。\n2. Schema Syncer 模块负责从 TiKV 拉取 最新的 Schema 信息,依此来更新 Local Schema Copy。\n3. Bootstrap 指的是 TiFlash Server 启动的时候,会直接调用一次 Schema Syncer,获得目前所有的 schema 信息。\n4. Background Sync Thread 是负责定期调用 Schema Syncer 来更新 Local Schema Copy 模块。\n5. Read 和 Write 两个模块就是 TiFlash 中的读写操作,读写操作都会去依赖 Local Schema Copy,也会在有需要的时候来调用 Schema Syncer 进行更新。\n\n下面我们就逐一来看每个部分是怎么实现的。\n### Local Schema Copy\nTiFlash 中 schema 信息最主要的是跟各个数据表相关的信息。在 TiFlash 的存储层中,每一个物理的表,都会对应一个 `StorageDeltaMerge` 的实例对象,在这个对象中有两个变量,是负责来存储跟schema 相关的信息的。\n\n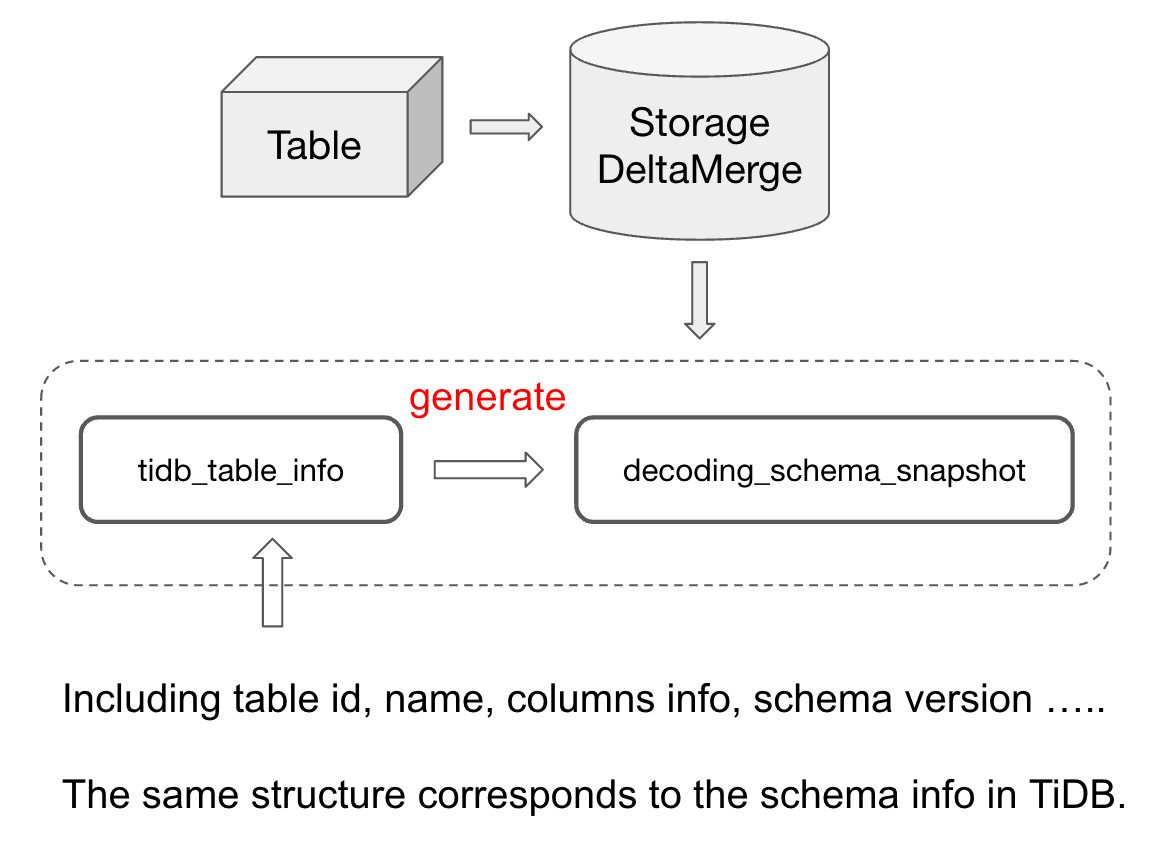\n\n\n图七 Schema Copy 存储示意图\n\n1. `tidb_table_info` 这个变量存的是 table 中各种 schema 信息,包括 table id,table name,columns infos,schema version等等。并且 `tidb_table_info` 的存储结构跟 TiDB / TiKV 中存储 table schema 的结构是完全一致的。\n2. `decoding_schema_snapshot` 则是根据 `tidb_table_info` 以及 `StorageDeltaMerge` 中的一些信息**生成**的一个对象。`decoding_schema_snapshot` 是为了优化写入过程中行转列的性能而提出的。因为我们在做行转列转换的时候,如果依赖 `tidb_table_info` 获取对应需要的 schema 信息,需要做一系列的转换操作来进行适配。考虑到 schema 本身也不会频繁更新,为了**避免每次行转列解析都需要重复做这些操作**,我们就用 `decoding_schema_snapshot` 这个变量来保存转换好的结果,并且在行转列过程中依赖 `decoding_schema_snapshot` 来进行解析。\n### Schema Syncer\nSchema Syncer 这个模块是由 `TiDBSchemaSyncer` 这个类来负责的。它通过 RPC 去 TiKV 中获取最新的 schema 的更新内容。对于获取到的 schema diffs,会找到每个 schema diff 对应的 table,在 table 对应的 `StorageDeltaMerge` 对象中来更新 schema 信息以及对应存储层相关的内容。\n\n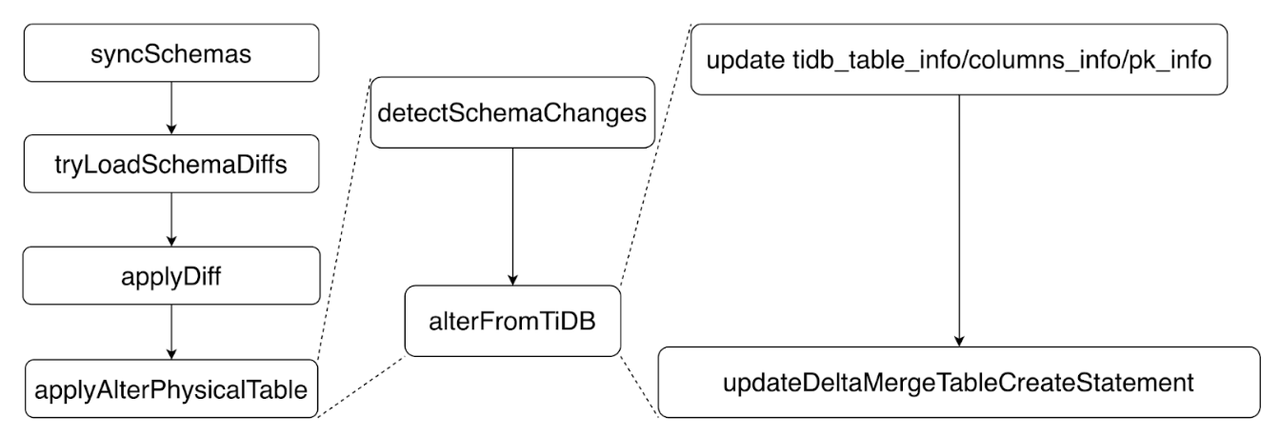\n\nSchemas 流程图\n\n整个过程是通过 `TiDBSchemaSyncer` 函数 `syncSchema`来实现的,具体的过程可以参考图八:\n1. 通过 `tryLoadSchemaDiffs`, TiKV 中拿到这一轮新的 schema 变更信息。\n2. 随后遍历所有的 diffs 来一个个进行 `applyDiff`。\n3. 对每个 diff,我们会找到他对应的 table,进行 `applyAlterPhysicalTable`。\n4. 在这其中,我们会 detect 到这轮更新中,跟这个表相关的所有 schema 变更,然后调用 `StorageDeltaMerge::alterFromTiDB` 来对这张表对应的 `StorageDeltaMerge` 对象进行变更。\n5. 具体变更中,我们会修改 `tidb_table_info` , 相关的 columns 和主键的信息。\n6. 另外我们还会更新这张表的建表语句,因为表本身发生了变化,所以他的建表语句也需要对应改变,这样后续做 recover 等操作的时候才能正确工作。\n\n在整个 `syncSchema` 的过程中,我们是不会更新 `decoding_schema_snapshot`的。`decoding_schema_snapshot`采用的是采用的是**懒惰更新**的方式,只有在具体的数据要发生写入操作了,需要调用到 `decoding_schema_snapshot`,它才会去检测自己目前是不是最新的 schema 对应的状态,如果不是,就会根据最新的 `tidb_table_info` 相关的信息来更新。也是通过这样的方式,我们可以减少很多不必要的转换。比如如果一张表频繁发生了很多 schema change,但是没有做任何的写操作, 那么就可以避免 `tidb_table_info`到 `decoding_schema_snapshot` 之间的诸多计算转换操作。\n\n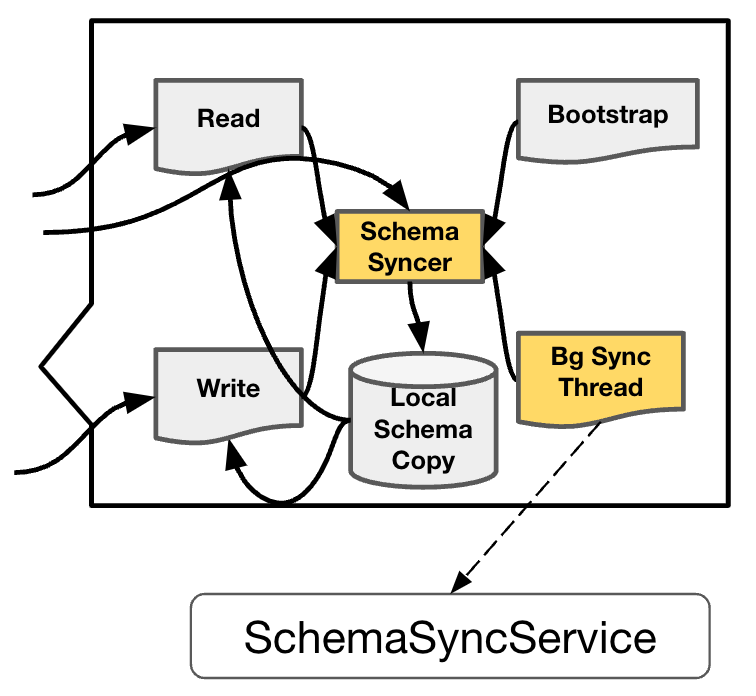\n\n\n图九 DDL Process\n\n对于周围涉及到调用 Schema Syncer 的模块,Read,Write,BootStrap 这三个模块都是直接的调用 `TiDBSchemaSyncer::syncSchema`。而 Background Sync Thread 则是通过 `SchemaSyncService` 来负责,在 TiFlash Server 启动的最开始阶段,把 `syncSchema` 这个函数塞到 background thread pool里面去,保持大概每隔10s调用一次,来实现定期更新。\n\n### Schema on Data Write\n\n我们先来了解一下,写的过程本身需要处理的情况。我们有一个要写入的行格式的数据,需要把他每一列内容进行解析处理,写入列存引擎中。另外我们节点中有 local schema copy 来帮助解析。但是,这行要写入的数据和我们的 schema copy 在时间上的先后顺序是不确定的。因为我们的数据是通过 raft log / raft snapshot 的形式发送过来的,是一个异步的过程。schema copy 则是定期来进行更新的,也可以看作是一个异步的过程,**所以对应的 schema 版本和 这行写入的数据 在 TiDB 上发生的先后顺序我们是不知道的**。写操作就是要在这样的场景下,正确的解析数据进行写入。\n\n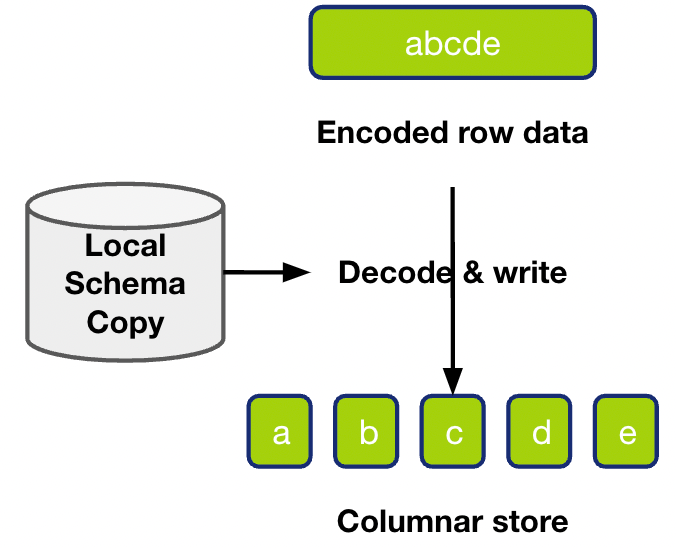\n\n图十 写入数据\n\n对于这样的场景,会有个非常直接的处理思路:我们可以在做行转列解析前,先拉取最新的 schema,从而保证我们的 schema 一定比要写入的数据更新,这样一定是可以成功解析的。但是一方面 schema 不是频繁变更的,另外每次写都要拉取 schema 是非常大的开销,所以我们写操作最终选择的做法是,**我们先直接用现有的 schema copy 来解析这行数据,如果解析成功了就结束,解析失败了,我们再去拉取最新的 schema 来重新解析**。\n\n在做第一轮解析时,除了正确解析完成以外,我们还可能遇到以下三种情况:\n\n1.第一种情况 **Unknown Column**, 即待写入的数据比 schema 多了一列 e。发生这种情况的可能有下面两种可能。\n\n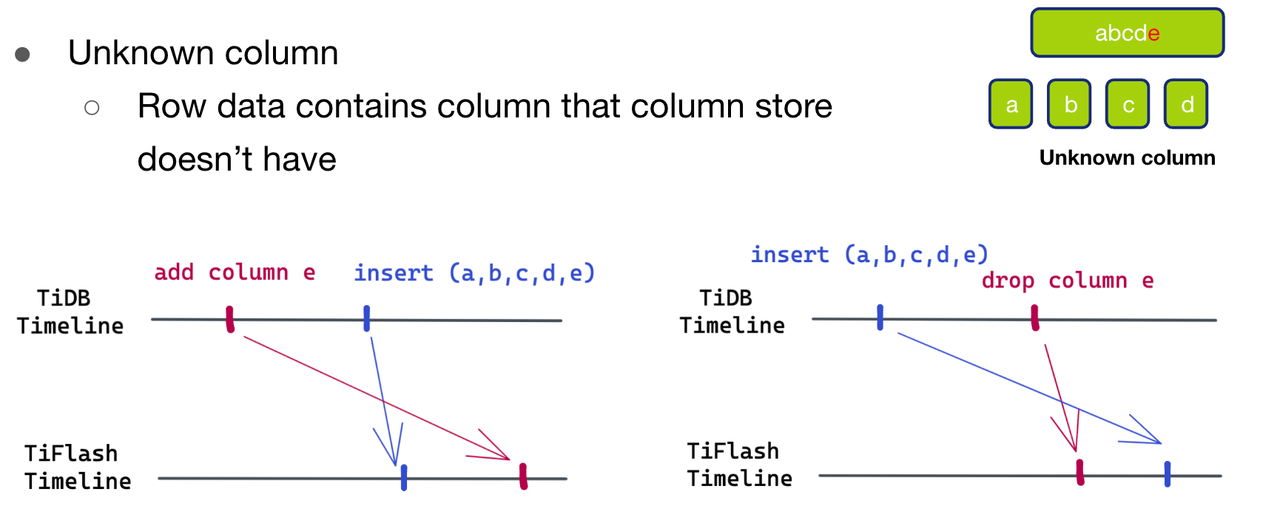\n\n 图十一 unknown column 场景\n \n - 第一种可能,如图十一(左)所示,待写入的数据比 schema 新。在 TiDB 的时间线上,先新增了一列 e,随后再插入了 (a,b,c,d,e) 这行数据。但是插入的数据先到到了 TiFlash ,add column e 的 schema 变更还没到 TiFlash 侧,所以就出现了数据比 schema 多一列的情况。\n - 第二种可能,如图十一(右)所示,待写入的数据比 schema 旧。在 TiDB 的时间线上,先插入了这行数据 (a,b,c,d,e),然后 drop column e。但是 drop column e 的 schema 变更先到达 TiFlash 侧, 插入的数据后到达,也会出现了数据比 schema 多一列的情况。\n 在这种情况下,我们也没有办法判断到底属于上述是哪一种情况,也没有一个共用的方法能处理,所以就只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。\n\n2.第二种情况 **Missing Column**,即待写入的数据比 schema 少了一列 e。同样,也有两种产生的可能性。\n\n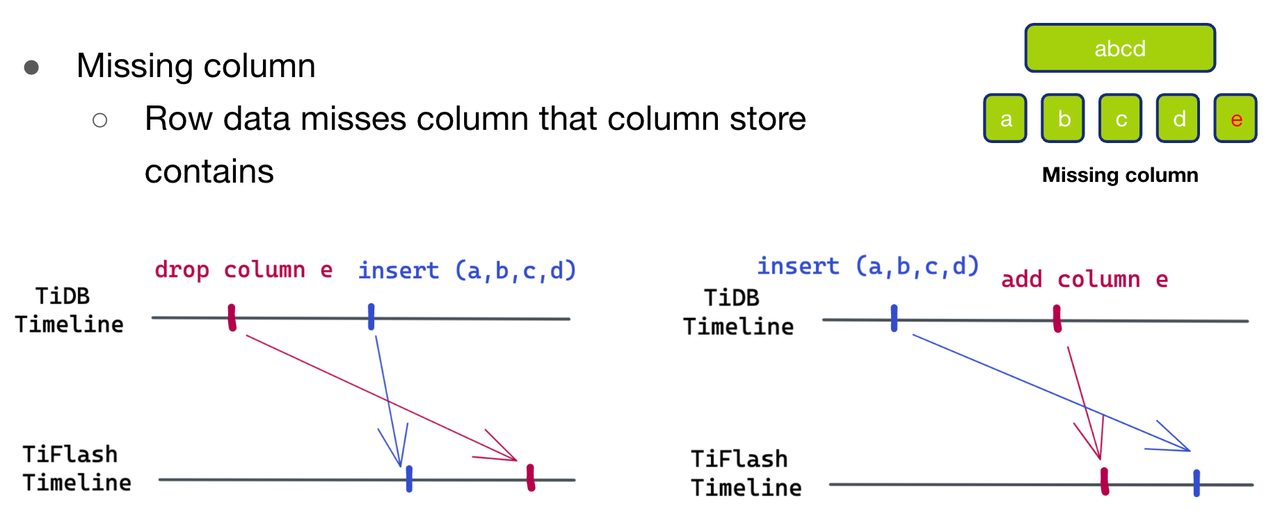\n\n 图十二 missing column 场景\n \n - 第一种可能,如图十二(左)所示,待写入的数据比 schema 新。在 TiDB 时间线上,先 drop column e,再插入数据(a,b,c,d)。\n - 第二种可能,如图十二(右)所示,待写入的数据比 schema 旧。 在 TiDB 时间线上,先插入了数据 (a,b,c,d),然后再插入了 e 列。\n \n同样我们这时候也没有办法判断是属于哪种情况,按照前面的做法,我们还是应该解析失败返回重新拉取在解析了。但是在这种情况下,如果多出来的 e 列 是有默认值的或者是支持填 NULL 的,我们可以直接给 e 列填上默认值或者 NULL 来返回解析成功。我们分别看一下在两种可能性下,我们这种填默认值或者 NULL 的处理会有什么样的影响。\n \n第一种可能的情况下,因为我们已经 drop 了 column e,所以后续所有的读操作都不会读到 column e 的操作,所以其实给 e 列填任何值,都不会影响正确性。而对于第二种可能的情况,本身 (a,b,c,d) 这行数据就是缺失 e 的值的,需要在读的时候给这行数据填 e 的默认值 或者 NULL 的,所以在这个情况下,我直接先给这行数据的 column e 填了默认值或者 NULL,也是完全可以正常工作的。所以这两种情况下,我们给 e 列填默认值或者 NULL 都是可以正确工作的,因此我们就不需要返回解析失败了。但是如果多出的 e 列并不支持填默认值或者 NULL,那就只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。\n \n3.第三种情况 **Overflow Column**,即我们待写入的数据中有一列数值大于了我们 schema 中这一列的数据范围的。\n\n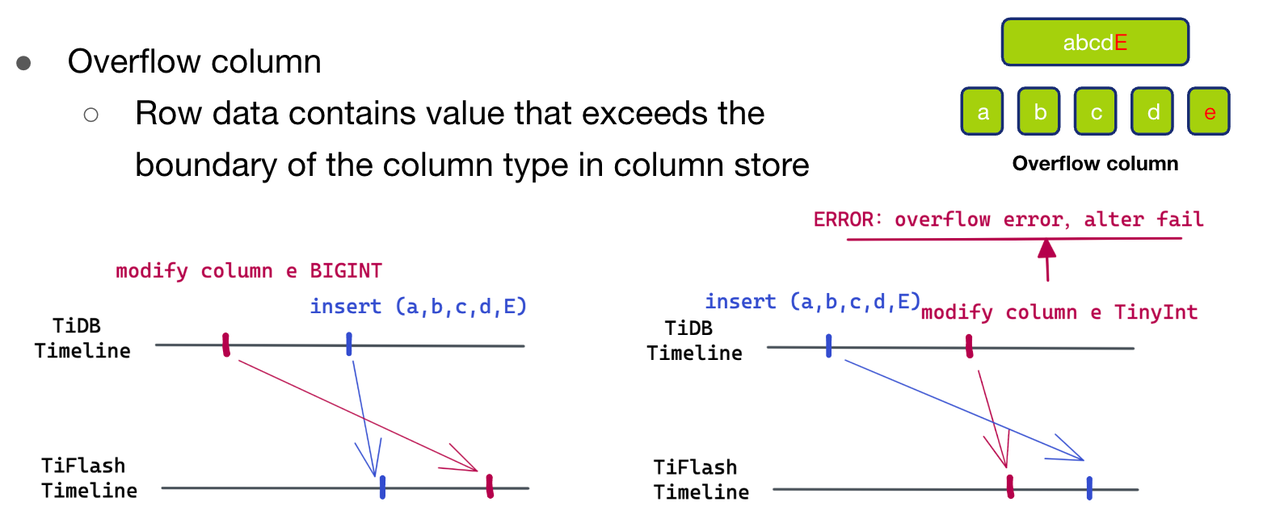\n\n 图十三 overflow column 场景\n \n 对于这种情况,只有图十三(左)这种情况,即先进行了扩列的操作,然后插入了新的数据,但是数据先于 schema 到达了 TiFlash。我们可以看一下图十三(右)来理解为什么不可能是先插入数据再触发缩列的情况。如果我们先插入了数据(a,b,c,d,E),然后对 e 列做了缩列操作,将 e 列从 int 类型缩成 tinyint 类型。而因为插入的这个 E 超过了 tinyint 的范围,所以这个 DDL 操作会报 overflow 的错误的,操作失败,因此无法导致 overflow column 这种现象。\n \n因此出现 overflow的场景,只可能是图十三(左)的这种情况。但是因为 schema change 还没有到达 TiFlash,我们并不知道新的列具体的数据范围是怎么样的,所以没有办法把这个 overflow 的值 E 写入 TiFlash 存储引擎,所以我们也只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。\n \n了解完再第一次解析的时候可能会遇到的三种异常情况,我们再来了解一下在第一次解析失败下,重新拉取最新的 schema 以后,再进行第二轮解析下会出现的情况。同样的,除了在第二轮正常的完成解析以外,我们还可能遇到前面的三种情况,但不一样的是,在第二轮解析时,可以保证我们的 **schema 比待写入的数据更新了**。\n\n\n\n\n图十四 第二轮解析异常场景\n\n1. 第一种情况 Unknown Column。因为 schema 比 待写入的数据新,所以我们可以肯定是因为在这行数据后,又发生了 drop column e 的操作,但是这个 schema change 先到达了 TiFlash 侧,所以导致了 Unknown Column 的场景。因此我们只需要直接把 e 列数据直接删除即可。\n2. 第二种情况 Missing Column。这种情况则是由于在这行数据后进行了 add column e 的操作造成的,因此我们直接给多余的列填上默认值即可。\n3. 第三种情况 Overflow Column。因为目前我们的 schema 已经比待写入的数据新了,所以再次出现 overflow column 的情况,一定是发生了异常,因此我们直接抛出异常。\n\n以上就是写数据过程的整体的思路,如果想了解具体的代码细节,可以搜索一下 `writeRegionDataToStorage` 这个函数。另外我们的行转列的过程是依赖 `RegionBlockReader` 这个类来实现的,这个类依赖的 schema 信息就是我们前面提到的 `decoding_schema_snapshot`。在行转列的过程中,`RegionBlockReader` 在拿 `decoding_schema_snapshot` 的时候会先检查 `decoding_schema_snapshot` 是否跟最新的 `tidb_table_info` 版本是对齐的,如果没对齐,就会触发 `decoding_schema_snapshot` 的更新,具体逻辑可以参考 `getSchemaSnapshotAndBlockForDecoding` 这个函数。\n\n### Schema on Data Read\n和写不太一样的是,在开始内部的读流程之前,我们需要先校验 schema version。我们上层发送的请求中,会带有 schema version 信息(Query_Version)。读请求校验需要满足的要求则是,**待读的表本地的 schema 信息和读请求里面的 schema version 对应的信息保持一致的**。\n\n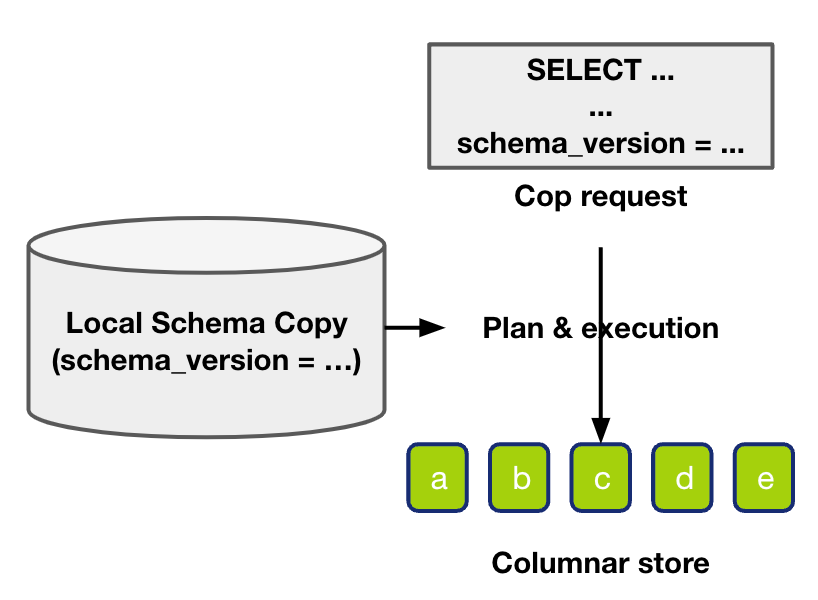\n\n\n图十五 读数据\n\nTiFlash 负责拉取 schema 的 `TiDBSchemaSyncer` 会记录整体的 schema version,我们这边称它为Local_Version。因此读操作的要求即 Query_Version = Local_Version。如果 Query_Version 大于 Local_Version,我们会认为本地 schema 版本落后了,因此触发 sync schema ,拉取最新的 schema,再重新进行校验。如果 Query_Version 小于 Local_Version,我们就会认为 query 的 schema 版本太老,因此会拒绝读请求,让上层节点更新 schema version 后重新发送请求。\n\n在这种设定下,如果我们有个表在非常频繁的发生 DDL 操作,那么他的 schema version 就会不断更新。因此如果此时又需要对这个表进行读操作,就很容易出现读操作一直在 Query_Version > Local_Version 和 Query_Version < Local_Version 两种状态下交替来回的状况。比如一开始读请求的 schema version 更大,触发 TiFlash sync schema,更新 local schema copy。更新后本地的 schema version 就比读请求新,因此触发拒绝读请求。读请求更新 schema version 后,我们又发现读请求的 schema version 比 本地 schema copy 更新了,周而复始 .... 对于这种情况,我们目前是没有做特殊处理的。我们会认为这种情况是非常非常罕见的,或者说不会发生的,所以如果不幸发生了这样的特殊情况,那只能等待他们达到一个平衡状态,顺利开始读操作。\n\n前面我们提到读操作要求 Query_Version 和 Local_Version 完全相等,因此非常容易出现出现不相等的情况,从而造成诸多重新发起查询或者重新拉取 schema 的情况。为了减少发生此种情况的次数,我们做了一个小的优化。\n\n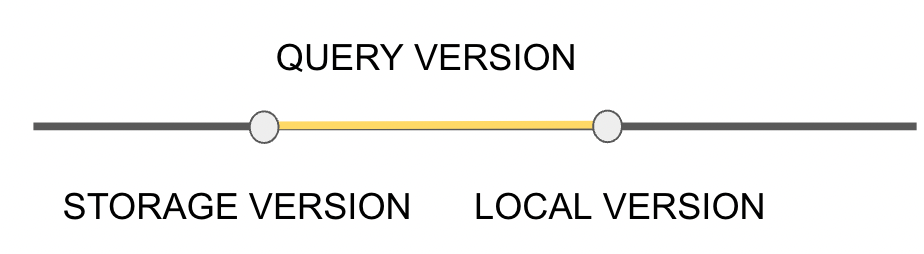\n\n\n图十六 version 关系示意图\n\n我们除了 TiFlash 整体有 schema version外,每张表也有自己的 schema version,我们称为 Storage_Version,并且我们的 Storage_Version 永远小于等于 Local_Version 的, 因为只有在最新的schema 变更的时候,确实修改了这张表,Storage_Version 才会恰好等于 Local_Version, 其他情况下,Storage_Version 都是小于 Local_Version 的。因此在 [Storage_Version, Local_Version] 这个区间中,我们这张表的 schema 信息是没有发生任何变化的。也就是 Query_Version只要在[Storage_Version, Local_Version] 这个区间内,读请求要求的这张表的 schema 信息和我们目前的 schema 版本就是完全一致的。所以我们就可以把 Query_Version < Local_Version 这个限定放松到 Query_Version < Storage_Version。在 Query_Version < Storage_Version 时,才需要更新读请求的 schema 信息。\n\n在校验结束后,负责读的模块根据我们对应表的 `tidb_table_info` 去建立 stream 进行读取。Schema 相关的流程,我们可以在 `InterpreterSelectQuery.cpp` 的 `getAndLockStorageWithSchemaVersion` 以及 `DAGStorageInterpreter.cpp` 的 `getAndLockStorages` 中进行进一步的了解。 `InterpreterSelectQuery.cpp` 和 `DAGStorageInterpreter.cpp` 都是来负责对 TiFlash 进行读表的操作,前者是负责 clickhouse client 连接下读取的流程,后者则是 TiDB 支路中读取的流程。\n\n## Special Case\n最后我们看一个例子,来了解一下 Drop Table 和 Recover Table 相关的情况。\n\n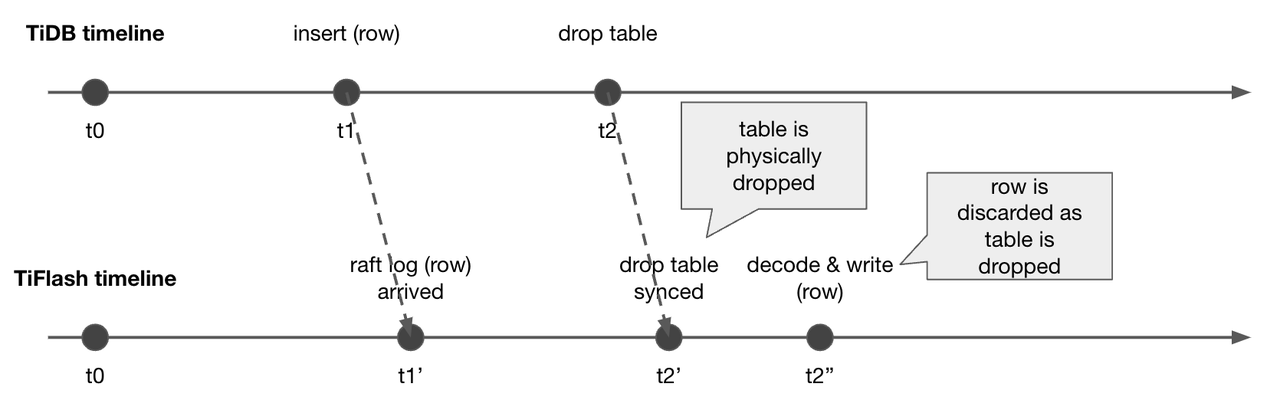\n\n\n图十七 special case 示意图一\n\n图十六中上方的线是 TiDB 的时间线,下方的线是 TiFlash 的时间线。在 t1 的时候,TiDB 进行了 insert 的操作,然后在 t2 的时候又进行了 drop table 的操作。t1' 的时候,TiFlash 收到了 insert 这条操作的 raft log,但是还没进行到解析和写入的步骤,然后在 t2' 的时候,TiFlash 同步到了 drop table 这条 schema DDL 操作,进行了 schema 的更新。等到 t2'' 的时候,TiFlash 开始 解析前面那条新插入的数据了,但是这时候因为对应的表已经被删除了,所以我们就会扔掉这条数据。到目前为止还没有任何的问题。\n\n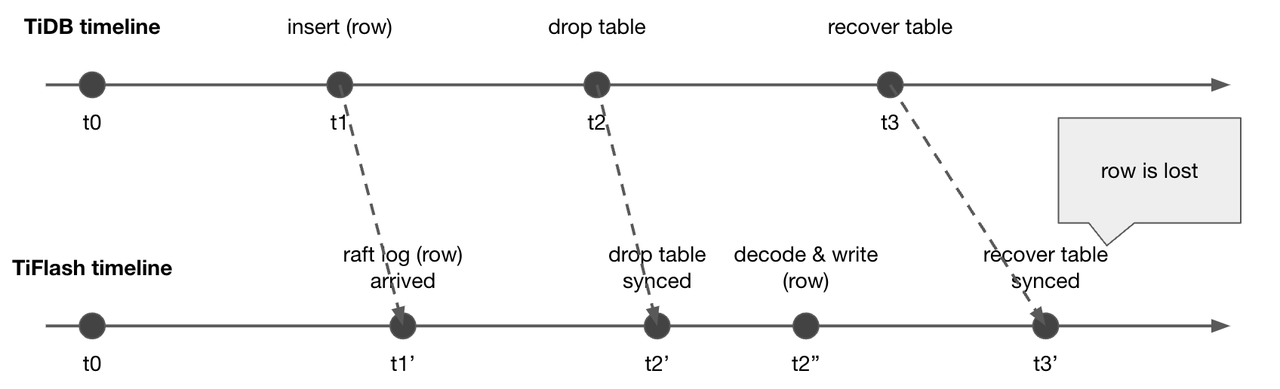\n\n\n图十八 special case 示意图二\n\n但是如果 t3 的时候我们又进行了 recover 的操作,将这张表恢复了,那最后插入的这条 row 数据就丢失了。数据丢失是我们不能接受的结果。因此 TiFlash 对于 drop table 这类的 DDL,会对这张表设上 tombstone,具体的物理回收延后到做 gc 操作的时候再发生。对于 drop table 后这张表上还存在的写操作,我们会继续进行解析和写入,这样在后续做 recover 的时候,我们也不会发生数据的丢失。\n\n## 小结\n\n本篇文章主要介绍了 TiFlash 中 DDL 模块的设计思想,具体实现和核心的相关流程。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n\n> 点击查看更多 [TiFlash 源码阅读](https://pingcap.com/zh/blog?tag=TiFlash%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)系列文章","author":"洪韫妍","category":1,"customUrl":"tiflash-source-code-reading-4","fillInMethod":"writeDirectly","id":402,"summary":"在上一期源码阅读中,我们介绍了 TiFlash 的存储引擎,本文将介绍 TiFlash DDL 模块的相关内容,包括 DDL 模块的设计思路, 以及具体代码实现的方式。","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析"}},{"relatedBlog":{"body":"**本文作者**:施闻轩,TiFlash 资深研发工程师\n\n## 背景\n\n在 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 中我们主要对 DeltaTree 引擎的结构和写入相关流程进行了介绍。本文对读取流程进行介绍。若读者尚未阅读过 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3),需要先阅读 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 文章了解前置知识。\n\n> 本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。\n\n## 读\n\n如 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 所述,写入时,DeltaTree 引擎形成的结构如下:\n\n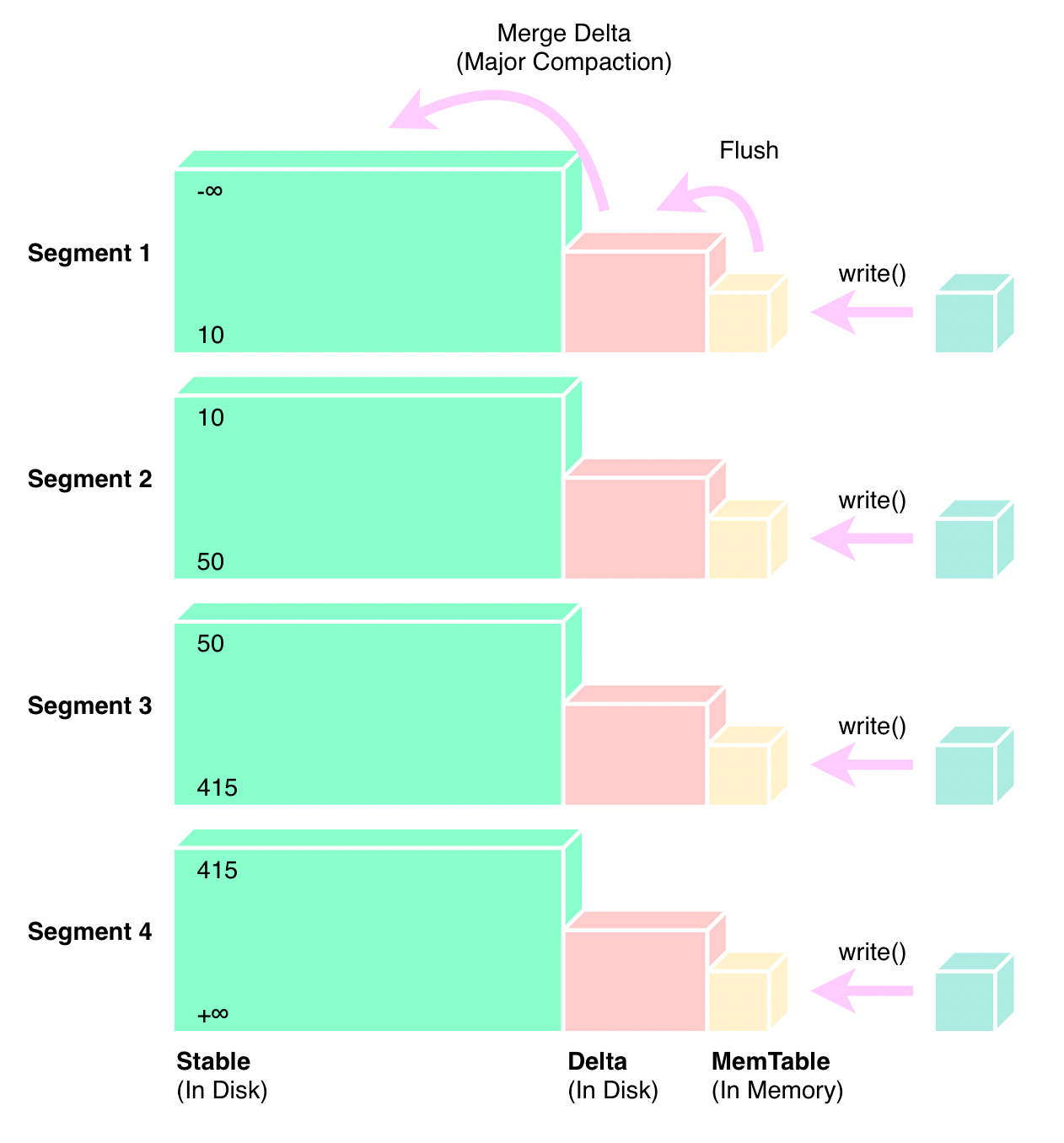\n\n数据首先在值域范围上进行切分,分成了多个不同的 Segment,然后在时域范围上进行切分,按照新老数据分为 Stable 层(绝大多数数据)和 Delta 层(刚写入的数据)。其中,Delta 层又分为磁盘上的数据和内存中的 MemTable 数据。定期的 Flush 的机制会将内存数据写入到磁盘中。\n\n如果想了解这个结构的详细情况,请参见 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3)。\n\n若要从这样的结构中依次扫描数据,那么需要对每个 Segment 的 Stable、磁盘上的 Delta 层、内存中的 MemTable 数据这三部分数据进行**联合扫描**:\n\n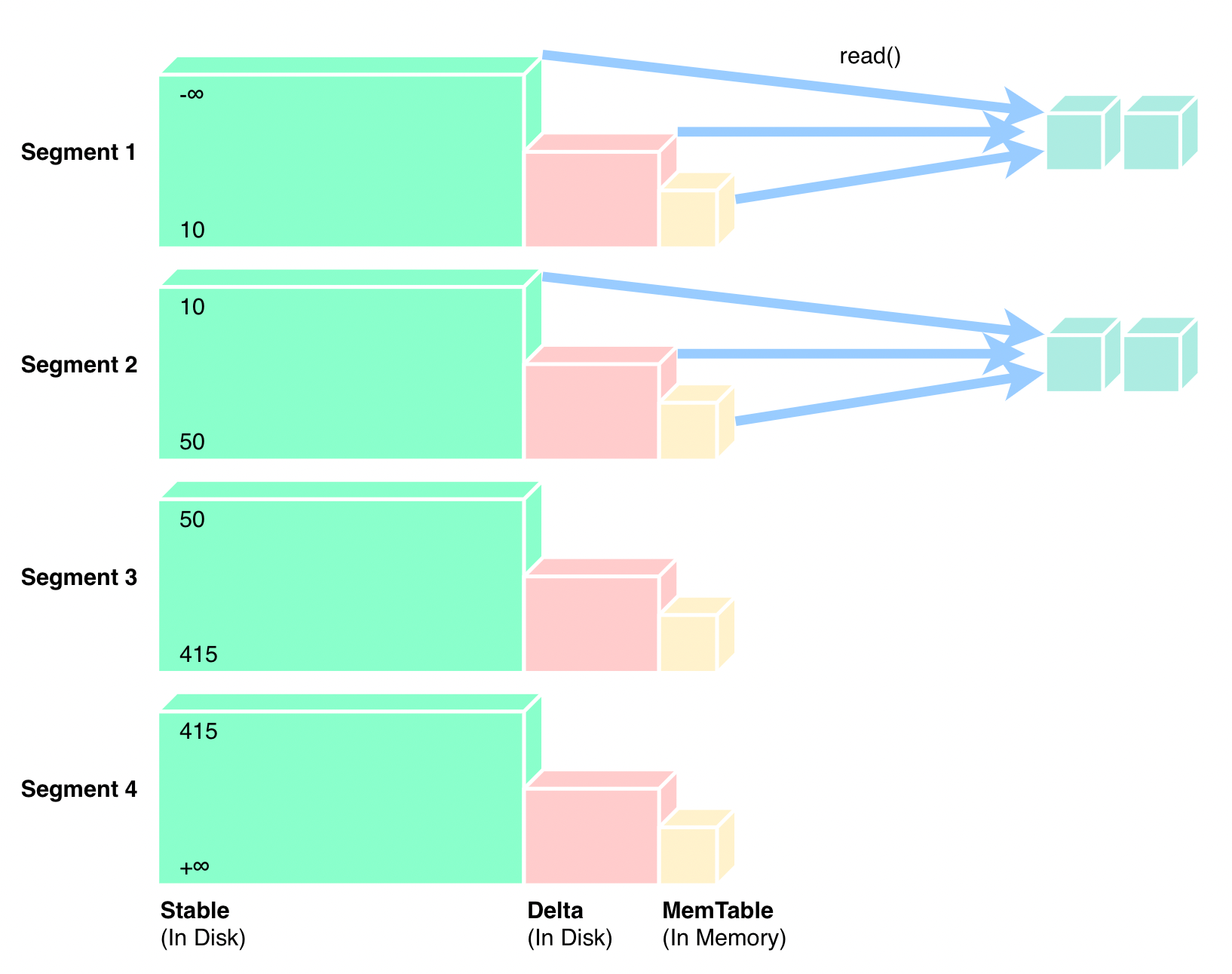\n\n对 LSM Tree 比较熟悉的读者会发现,单个 Segment 内类似于一个 2 层 LSM Tree,由于两层的值域是重叠的,因此需要同时读取,并结合 MVCC 版本号,以便得到一个最终结果。\n\n## 快照读\n\n在实际实现中,TiFlash 并非直接对这三块数据直接进行读取,而是首先为它们构建快照,然后**基于快照进行读取**。快照是一种抽象概念,被「快照」下来的数据在读取的时候永远不会发生变化,即使实际数据由于发生了并行写入发生了变更。\n\n快照读机制提供了以下好处:\n\n- 可以提供一定的 ACID 隔离(快照隔离级别),例如不会读出写到一半的数据\n\n- 长时间的读和写不会互相阻塞,可以同时进行,对于读大量数据的场景比较友好\n\n从逻辑上来说,在读之前拿个锁阻塞写、并复制一遍数据,就可以以最简单的方式实现快照。但显而易见的是,复制数据是一个非常耗时的操作(例如考虑要扫 1TB 数据)。以下详细分析 TiFlash 各个部分数据是如何实现高性能快照的。\n\n### MemTableSet 的快照\n\n对于 MemTable 中的 ColumnFileInMemory 数据,TiFlash 通过**复制 Block 数据区指针**的方式实现“快照”,不会复制它所包含的 Block 数据内容:\n\n```C++\nfor (const auto & file : column_files)\n{\n if (auto * m = file->tryToInMemoryFile(); m)\n {\n snap->column_files.push_back(std::make_shared(*m));\n }\n else\n {\n snap->column_files.push_back(file);\n }\n total_rows += file->getRows();\n total_deletes += file->getDeletes();\n}\n```\n\n注意,快照后的 ColumnFileInMemory 实际上与被快照的 ColumnFileInMemory 共享了相同的 Block 数据区域,而 ColumnFileInMemory 数据区是会随着新写入发生变更的。因此这个 ColumnFileInMemory “快照”并不保证后续读的时候不会遇到新数据,不是一个真正意义上的快照。**在读过程中,TiFlash 还额外进行了 TSO 的过滤来规避这些后续可能新写入的数据**。\n\n### 磁盘上 Delta 层数据的快照\n\n对于 ColumnFilePersistedSet,其各个 ColumnFile 的数据通过 PageStorage 存储在了磁盘中。这些数据是 immutable 的,不会随着新写入发生修改,因此直接复制 ColumnFile 结构体指针(`std::shared_ptr`)、对其引用计数进行更新即可。\n\n### 磁盘上 Stable 层数据的快照\n\n在 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 中我们可以了解到 Stable 层的数据也是 immutable 的:整个 Stable 层的数据文件不会被更改,只会在 Merge Delta 等过程中被整体替换成一个新的文件。因此与 Delta 层数据类似,Stable 层也是通过智能指针追踪引用计数、直接增加引用即可。\n\n通过这些分析大家可以发现,TiFlash 中的快照过程是非常轻量的,基本上都仅仅涉及到指针复制和引用计数的更新,因此其效率非常高。\n\n## Scan 实现\n\nScan 是各个 AP 分析引擎最重要的读操作,TiFlash 也不例外。TiFlash 中 Scan() 实现的语义为:给定一个主键区间,流式地、按顺序地返回在这个区间内指定列的所有数据。\n\nTiFlash 的 Scan 是三个流(Stream)的组合:\n\n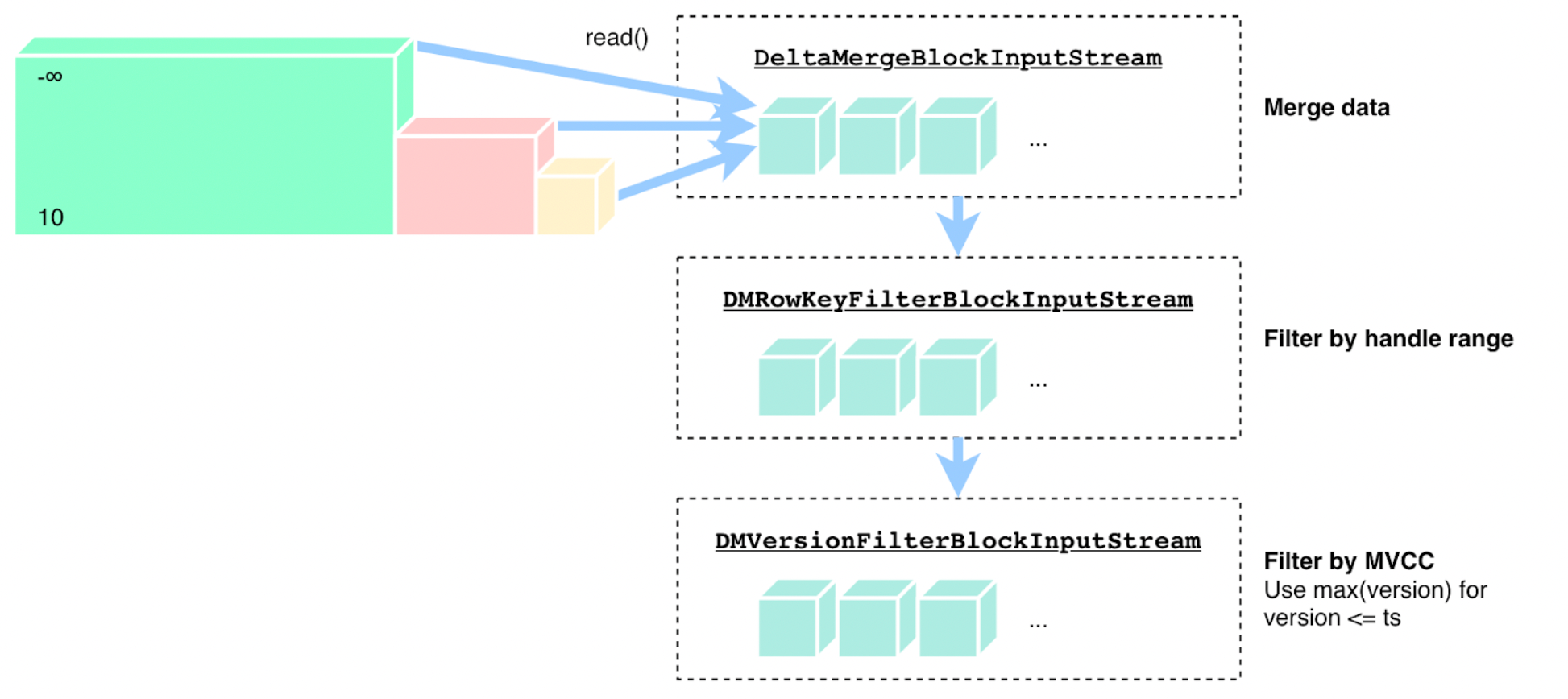\n\n- 最底层 DeltaMergeBlockInputStream:返回合并自 MemTableSet、磁盘上的 Delta 层、磁盘上的 Stable 层这三个来源的数据流。这个流返回的数据是有序的,一定按照 (Handle, Version) 升序排列,但并不保证返回的数据一定符合给定的区间范围。\n\n- DMRowKeyFilterBlockInputStream:依据 Handle 列的范围进行过滤并返回\n\n- DMVersionFilterBlockInputStream:依据 Version 列的值进行 MVCC 过滤\n\n### DeltaMergeBlockInputStream\n\n这个流有序地返回 MemTable、Delta、Stable 三层数据。在 [Part1](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 中我们介绍过,MemTable 中可能存在多个值域重叠的 ColumnFileInMemory(每个 ColumnFile 内部是有序的),而 Delta 中也可能存在多个值域重叠的 ColumnFileTiny,Stable 层则比较简单,只有一个 DMFile,且内部是有序的。\n\n以下边的图片为例,假设 MemTable、Delta、Stable 中各自有一些数据,我们期望 DeltaMergeBlockInputStream 返回的结果如图中最右侧红色表格所示:\n\n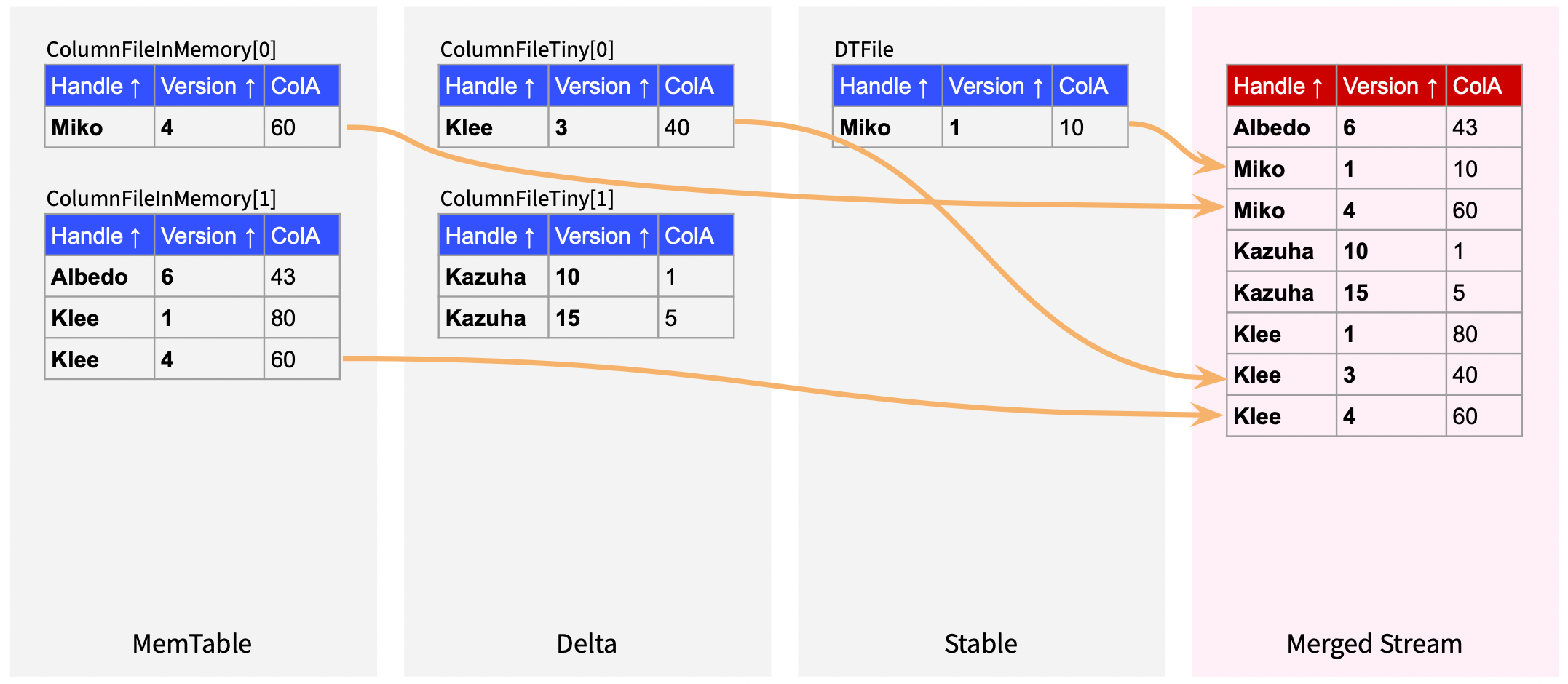\n\n由此可见,这个流本质是,对于多个有序流返回一个有序的合并后的流。这是一个标准的 K 路归并问题(K-way Sort Merge),这也正是很多 LSM Tree 存储引擎(如 RocksDB)等对于 N 层有序数据进行 Scan 的实现方式。K 路归并的流可以通过一个最小堆实现:\n\n1. 从各个底层流中取一行,放入最小堆中\n\n1. 从最小堆中取出当前最小的这一行(这一行一定是步骤 1 中各行里最小的),作为流输出的第一行\n\n1. 从取走行的流中补充一行到最小堆中\n\n1. 重复步骤 2\n\nK 路归并实现简单、使用广泛,但它也存在一些问题:\n\n- 无论读哪一列,都需要依据 Sort Key 作为最小堆的排序依据,换句话说 Sort Key 列总是需要被读出来,哪怕它并不是用户所请求的数据列\n\n- 基于堆的算法只能以行为单位处理,有较多的分支判断,无法充分利用 CPU 流水线\n\n**TiFlash** **中这个流并没有采用 K 路归并的方式实现,而是采用了业界比较新的 Positional Index 方式**。与 K 路归并不同的是,Positional Index 并不是基于 Sort Key 进行排序合并,而是基于各个记录的下标位置(即 Positional 名称的来源)进行差分合并。\n\n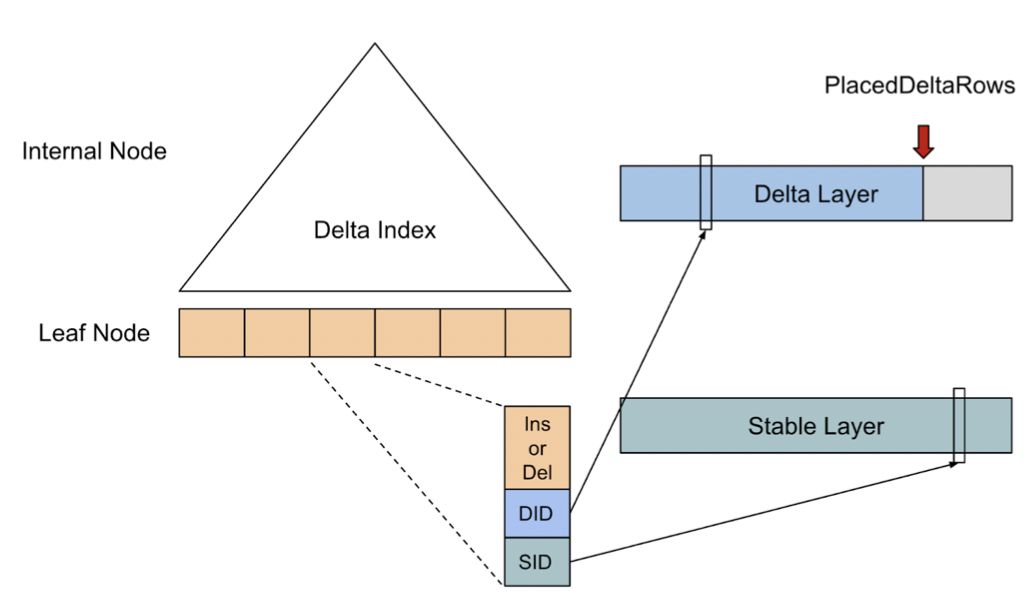\n\nTiFlash 在写入的时候并不会更新 Positional Index,而是在读取的时候按需更新,这使得 TiFlash 得以维持高频写入性能。Positional Index 结构及算法比较复杂,**后续的源码解读章节会单独涵盖**,因而本文不作详细展开。感兴趣的读者也可以自行阅读 `DeltaIndex.h` 了解详细实现。\n\n### DMRowKeyFilterBlockInputStream\n\n这个流会按照给定的 Handle 列范围对数据进行过滤。在 TiFlash 的实现中,虽然在从 Stable 读数据的时候也会指定读取的 Handle Range,但这个 Range 最终映射为了 Pack,返回的是**以 Pack 为单位的流数据**,因此还需要通过这个流对数据范围进行进一步准确地限定。\n\n### DMVersionFilterBlockInputStream\n\n这个流的目的是**实现** **MVCC** **过滤**,下图展示了这个流的基本工作:接受一组包含 Version 及 Handle 列的数据(按 Handle, Version 排序),Handle 列可能存在多个 Version,并给定一个 MVCC 版本号,按序返回各个 Handle 不超过这个版本号最大的版本行。\n\n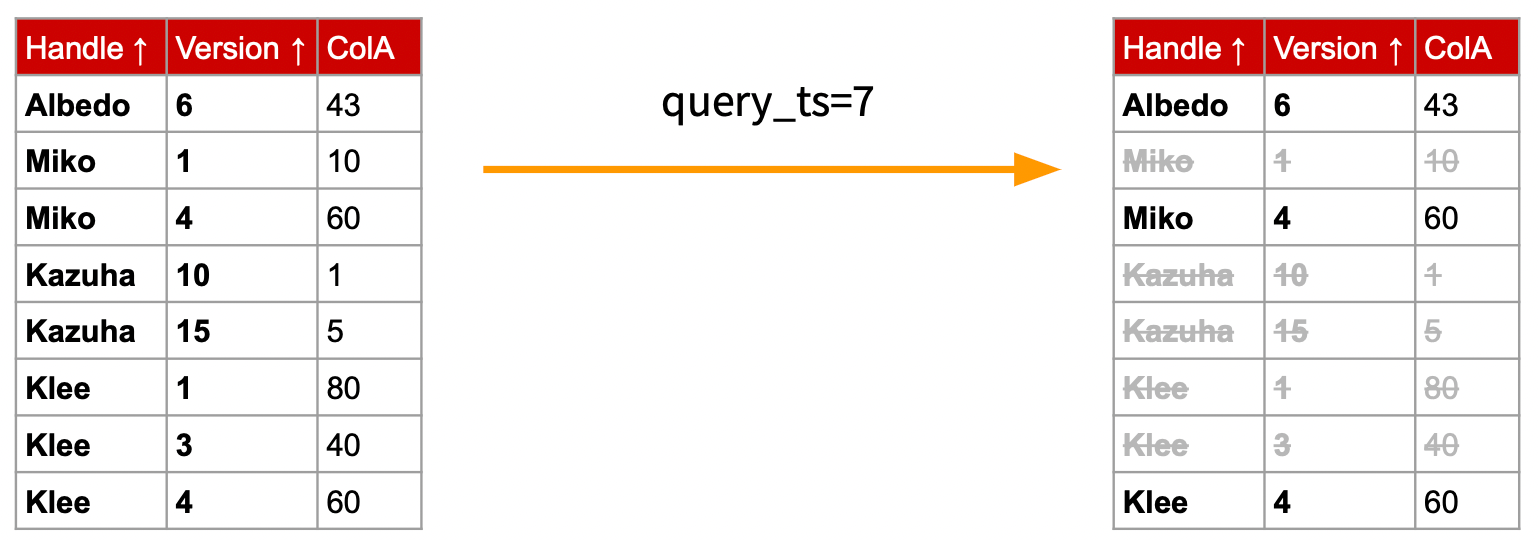\n\n由于整体数据是按 Handle, Version 有序排列的,因此这个流的算法比较简单,这里也不做详细展开,感兴趣的读者可以阅读 `DMVersionFilterBlockInputStream.h`。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n","author":"施闻轩","category":1,"customUrl":"tiflash-source-code-reading-5","fillInMethod":"writeDirectly","id":406,"summary":"在 Part1 中我们主要对 DeltaTree 引擎的结构和写入相关流程进行了介绍,本文将对读取流程进行介绍。","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(五)DeltaTree 存储引擎设计及实现分析 - Part 2"}},{"relatedBlog":{"body":"## 背景\n\n在前面的源码分析中对 TiFlash 的计算层和存储层都进行了深入的分析,其中 [TiFlash DeltaTree 存储引擎设计及实现分析 (Part 1)](https://pingcap.com/zh/blog/tiflash-source-code-reading-3) 、[TiFlash DeltaTree 存储引擎设计及实现分析 (Part 2)](https://pingcap.com/zh/blog/tiflash-source-code-reading-5) 对 TiFlash 存储层的读写流程进行了完整的梳理,如果读者没有阅读过这两篇文章,建议阅读后再继续本文的阅读。\n\n这里简单回顾一下,TiFlash 存储层的数据是按表分开存储的,每张表的数据会根据 Handle Range 切分为多个 Segment,每个 Segment 包含 Stable 层和 Delta 层,其中 Segment 的大部分数据存储在 Stable 层,Delta 层只负责处理少部分新写入的数据,并且在写入数据达到一定阈值后会将 Delta 层的数据合并到 Stable 层。在读取时需要通过 DeltaTree Index 这个数据结构将 Stable 层和 Delta 层合并成一个有序的数据流,本文会对 DeltaTree Index 在读取时的作用以及如何维护 DeltaTree Index 进行讲解。\n\n## 设计思路\n\n### 多路归并\n\nStable 层的数据是按照 DTFile 的形式存储的,并且数据是按照 Handle 列和 Version 列全局有序的。Delta 层的数据分为磁盘和内存两部分,并且都是按照 ColumnFile 的形式组织的,但是 ColumnFile 内部不保证完全有序。\n\n对于 Stable 层和 Delta 层合并这个问题,一个比较传统的做法是先对 Delta 层的不同 ColumnFile 进行内部排序,再通过多路归并的方式将 Stable 层和 Delta 层的数据合并成一个有序的数据流。但是这种方式需要涉及大量的比较操作以及入堆出堆操作等,因此性能比较差,所以我们希望能在这个基础上进一步优化性能。\n\n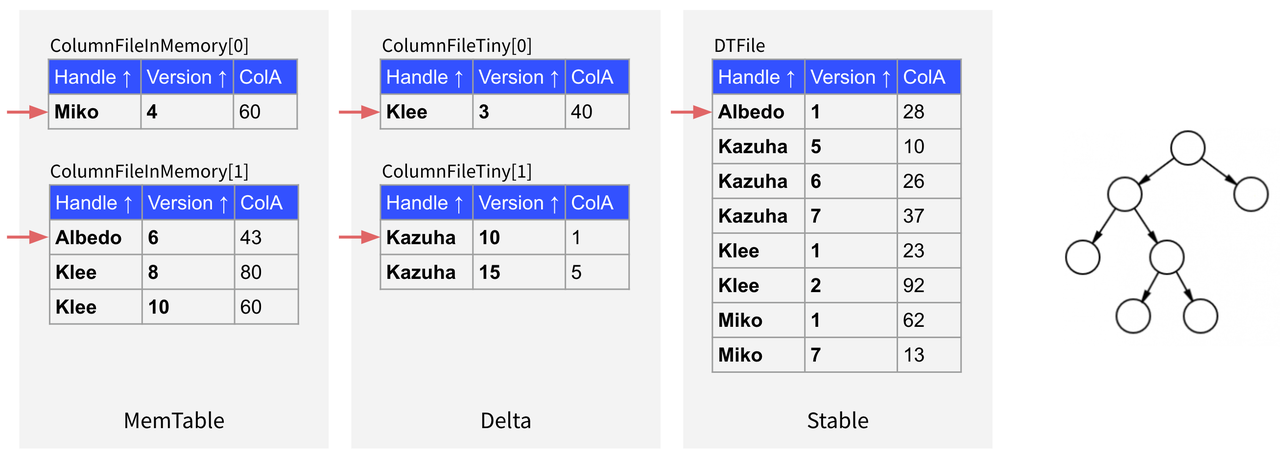\n\n我们考虑到既然多路归并比较耗时,那是否可以避免每次读都要重新做一次归并呢?答案是可以的。事实上有一些内存数据库已经实践了类似的思路。具体的思路是,第一次读取操作完成后,我们把多路归并算法产生的信息想办法存下来,从而使后续的读取可以重复利用这部分信息,对于新写入的数据可以通过增量更新的方式更新这部分信息即可。\n\n### DeltaTree Index\n\n那么现在的问题是如何存储多路归并算法产生的信息?一个比较朴素的想法是直接记录多路归并的操作顺序,在下一次读取时按照这个顺序读取即可。\n\n如下图所示,我们可以记录 Delta 层和 Stable 层合并后的有序数据流中的第一行来自 Stable 层的第一行数据,第二行来自 ColumnFileInMemory[1] 的第一行数据,第三行来自 Stable 层的第二行数据,并以此类推记录完整的操作顺序,这样在下一次读取时直接按照这个顺序读取就可以省略多路归并的过程,从而提高读取性能。但是这个方案的缺点也比较明显,就是我们需要为每一行数据记录相关的操作信息,因此会消耗大量的内存,而且这种记录方式不易进行增量更新,因此不太可行。\n\n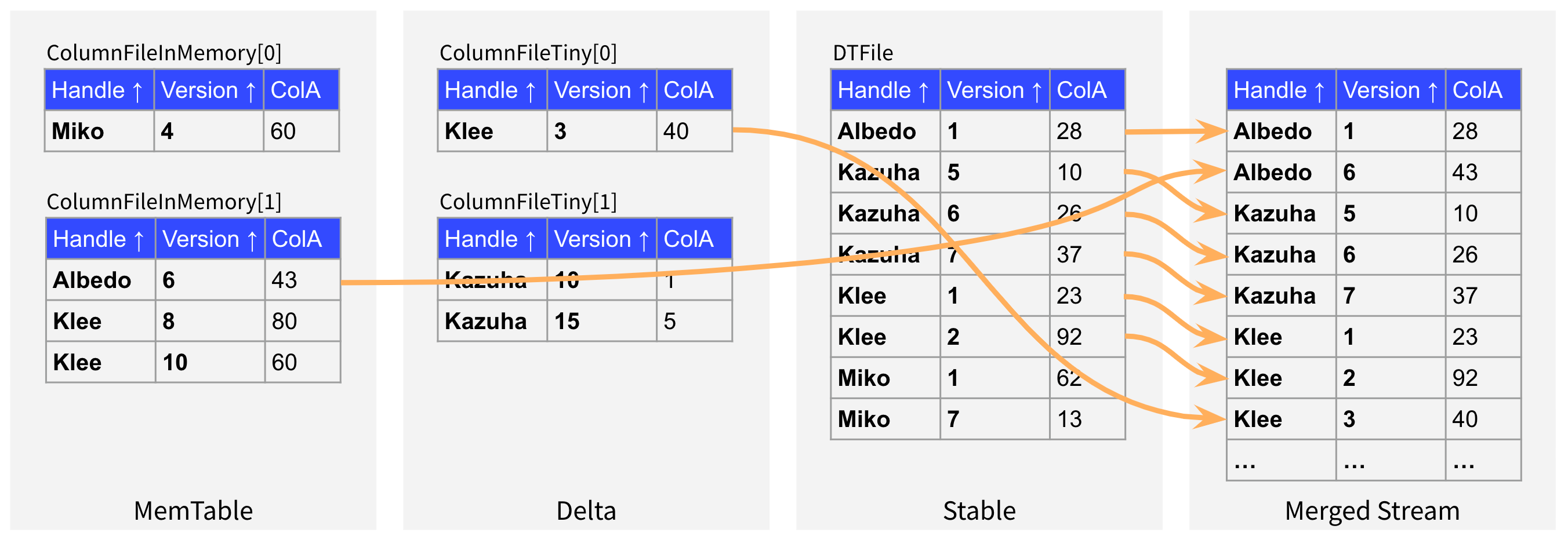\n\n此时我们注意到 Stable 层的数据是全局有序的,所以 Stable 层数据在合并的过程中一定是按顺序读取的。因此我们不需要再记录最终的有序数据流和 Stable 层数据的对应关系,只需要记录每条 Delta 层数据的读取顺序,然后再记录一下两次 Delta 层读取操作之间需要读取的 Stable 数据的行数,就可以完整记录整个多路归并算法产生的信息。\n\n如下图所示,我们可以只记录在第一次 Delta 层读取操作之前需要先从 Stable 层读取一行数据,在第二次 Delta 层读取操作之前需要再从 Stable 层读取五行数据,同时记录每次 Delta 层读取操作的具体内容,并以此类推即可记录完整的操作顺序。考虑到 Delta 层数据只占整个 Segment 数据的极小部分,所以这种记录方式的内存消耗非常小,因此这种方案比较可行。那么最后剩下的问题就是如何通过增量更新的方式维护这部分信息,为此我们也进行了多次设计迭代,并参考了许多现有的数据库的方案,最终形成的设计方案就是本文要介绍的 DeltaTree Index。\n\n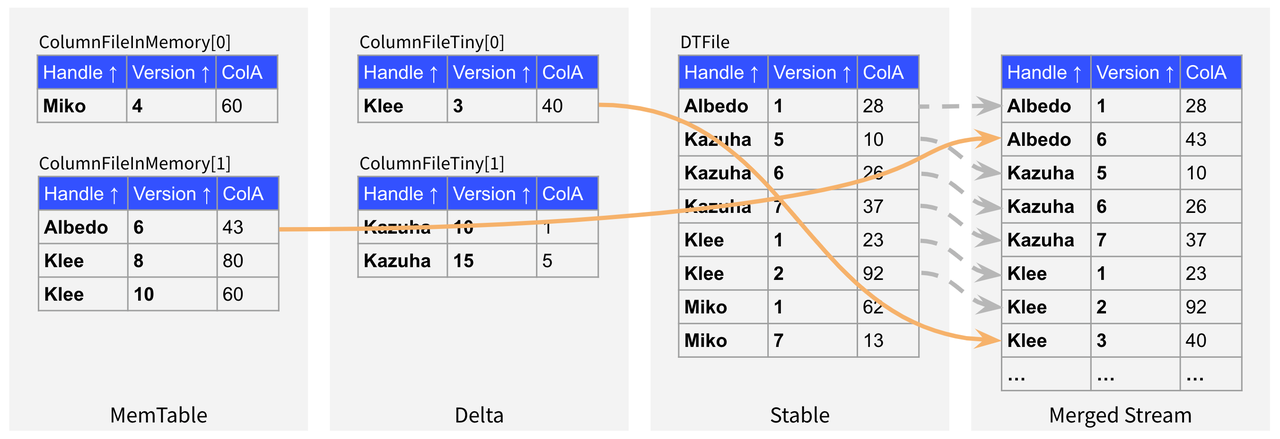\n\nDeltaTree Index 是一个类似 B+ 树的结构,为了演示方便,这里假设每个内部节点只有两个子节点,每个叶子节点可以容纳两个 Entry,如下图所示,其中 sid 在叶子节点中代表在处理当前 Entry 之前需要处理的 Stable 的数据行数,在内部节点中代表右子树中最小的 sid;is_insert 只在叶子节点中存在,代表这个 Entry 对应的是插入操作还是删除操作,其中删除操作代表的是删除 Stable 层某个位置的数据;delta_id 也只在叶子节点中存在,代表的是这个 Entry 对应数据在 Delta 层的偏移;count 在内部节点中代表对应子树中插入的数据行数减去删除的数据行数的值,而在叶子节点中 count 并没有实际存储下来,而是在遍历过程中计算得到,代表的是当前 Entry 之前插入的数据行数减去删除的数据行数的值;row_id 也是一个遍历过程中计算得到的值,代表的是对应 Entry 在合并之后的有序数据流中的位置。注意这里只是对这些字段做一个基础的介绍,在后续的具体流程中会对这些字段有更深入的讲解。\n\n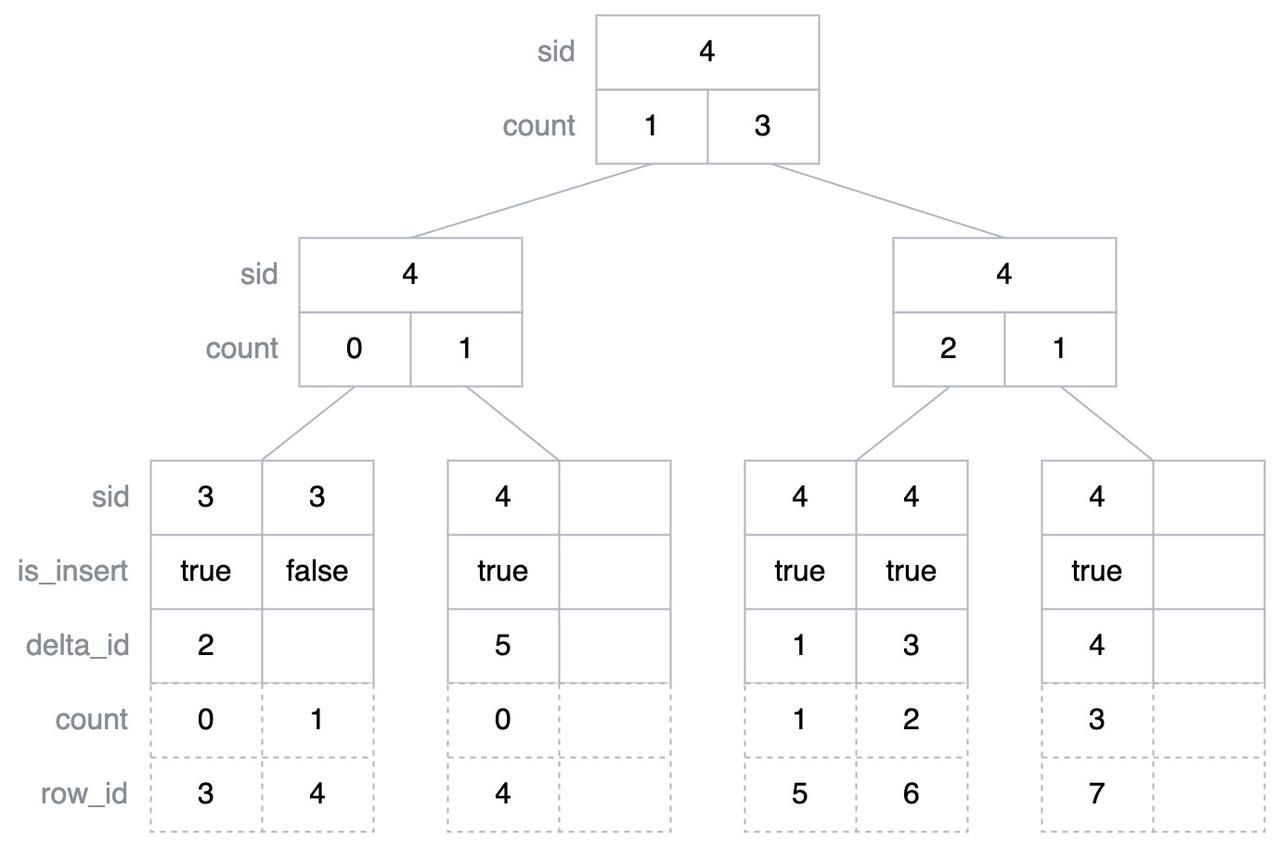\n\n## 关键流程\n\n### Search\n\n首先介绍一下 DeltaTree Index 的遍历操作,这个操作主要是根据 row_id 查找可能包含其对应 Entry 的最右侧的叶子节点,基本的思路是在遍历的过程中维护一个 count 变量,代表遍历过程中所有跳过的子树对应 count 字段值之和,由于内部节点中的 sid 代表的是其右子树中最小的 sid,因此内部节点的 sid 加上这里维护的 count 变量再加上其左子树的对应 count 值,就代表其右子树中最小的 row_id,将这个值与要查找的 row_id 比较即可以判断目标 row_id 是在左子树还是右子树中,然后继续向下遍历。\n\n```c++\nfindRightLeafByRId(row_id) {\n node = root\n count = 0\n while !isLeaf(node) {\n for i = 0; i < child; i++ {\n count = count + node[i].count\n if node[i].sid + count > row_id {\n count = count - node[i].count\n break\n }\n }\n node = node[i].child\n }\n return node\n}\n```\n\n下面以查找 row_id = 7 所在的最右侧叶子节点为例演示一下上面的算法,首先从根节点开始遍历,此时 count 的初始值为 0,根节点的 sid 加上其左子树的 count 值小于要查找的 row_id,即右子树最小的 row_id 小于要查找的 row_id,因此接下来需要继续遍历右子树。\n\n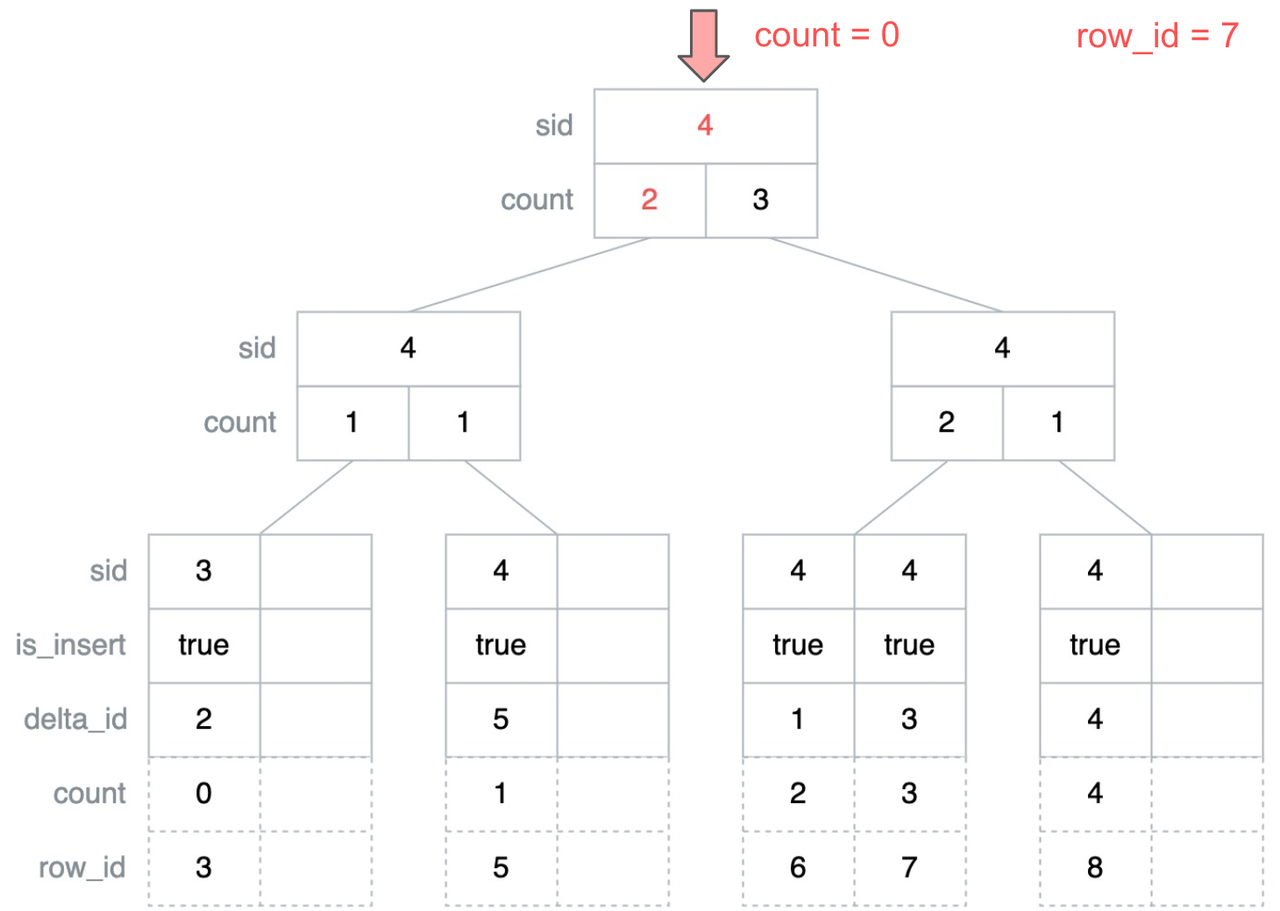\n\n这里继续按照上述的方法比较,可以计算得到当前节点的右子树最小的 row_id 为 8,大于要查找的 row_id,因此接下来需要继续遍历当前节点的左子树。\n\n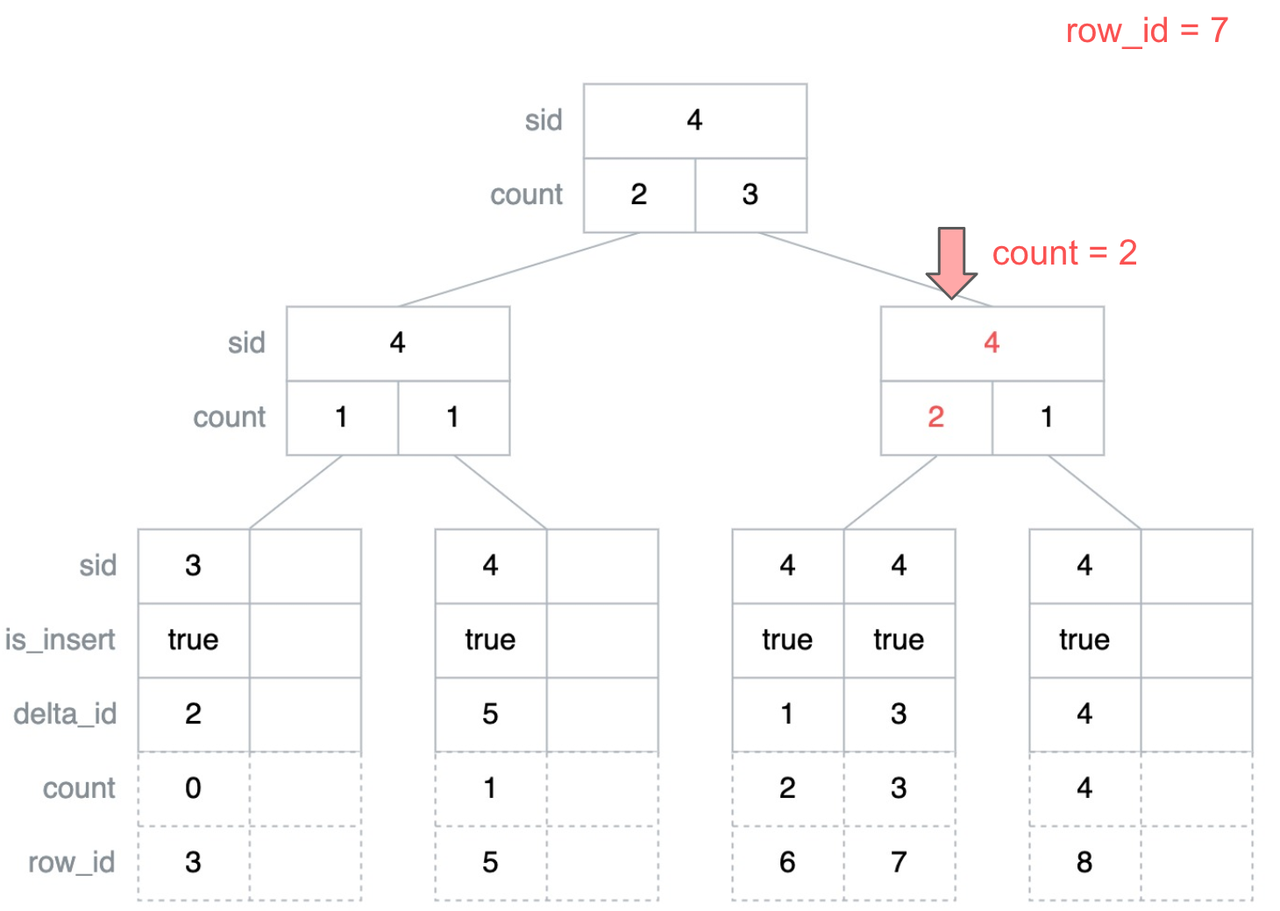\n\n这里已经遍历到叶子节点,那么这个叶子节点就是我们要查找的可能包含 row_id 为 7 的最右侧的叶子节点。\n\n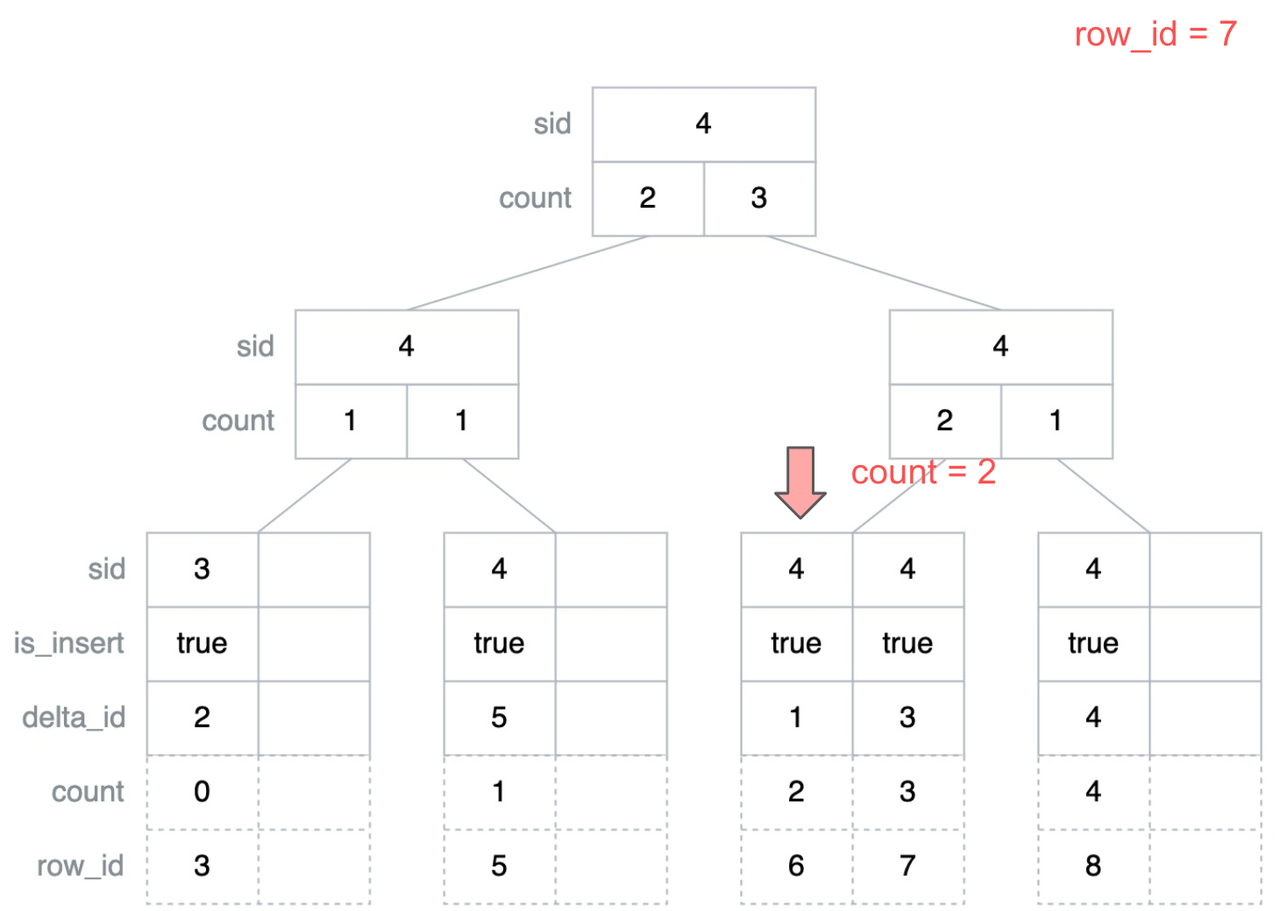\n\n### Add Insert\n\n对于 Delta 层内写入的所有数据行,都需要在 DeltaTree Index 中添加一条对应的 Insert Entry,对应的操作即为 DeltaTree Index 的 Add Insert 操作。在添加 Insert Entry 之前需要先获得对应数据行的 row_id,也即这条数据在 Stable 层和 Delta 层合并后的有序数据流中的位置,具体这个 row_id 如何获取我们放在后面再讲,这里先假设我们已经拿到这条数据对应的 row_id,那么 Add Insert 操作对应的伪代码如下(注意这里为了更方便的展示核心逻辑,省略了更新 B+ 树结构的相关操作)。\n\n```c++\nleaf, count = findRightLeafByRId(row_id)\npos, count = searchLeafForRId(leaf, row_id, count)\nshiftLeafEntries(leaf, pos, 1)\nleaf[pos].sid = row_id - count\nleaf[pos].delta_id = offset_in_delta_value_space\n```\n\n基本的思路是先通过 findRightLeafByRId 操作找到可能包含这个 row_id 的最右侧的叶子节点,然后再通过 searchLeafForRId 操作(这个操作比较简单,这里就不展示了)在这个叶子节点上遍历找到这个 row_id 对应的 Entry 所在的位置,并将该位置原来的 Entry 向右移动一格(移动的过程可能会触发节点分裂等操作),最后把相关信息更新到这个 Entry 中即可。其中这个 Entry 的 sid 是通过计算 row_id - count 得到的,这里可以直观理解一下这个计算的含义,我们用 Stream 代表 Stable 层和 Delta 层合并之后的有序数据流,那么这里的 row_id 是新插入数据在 Stream 中的位置,而我们要计算的 sid 可以拆解为两部分,第一部分是 Stream 中排在目标数据之前的 Stable 数据的行数,第二部分是处理该 Entry 之前已经被删除的 Stable 数据行数,其中第一部分可以通过 row_id 减去 Stream 中排在目标数据之前的 Delta 数据的行数计算得到,而 count 刚好代表的是当前 Entry 之前插入的数据行数减去删除的数据行数,所以 sid 可以通过计算 row_id - count 得到。\n\n另外值得注意的是在 TiDB 中的 Update 和 Delete 操作都是通过对相同主键写入更新版本的数据行完成的,因此在 SQL 层面的 Insert,Update 和 Delete 操作都是需要在 Delta 层写入新的数据,并在 DeltaTree Index 中添加新的 Insert Entry。\n\n### Add Delete\n\n然后再看一下如何在 DeltaTree Index 中添加新的 Delete Entry,这里也要先获取删除的数据行的 row_id,具体的获取方式也放在后面解释。对应的伪代码如下,\n\n```c++\nleaf, count = findRightLeafByRId(row_id)\npos, count = searchLeafForRId(leaf, row_id, count)\n// skip delete chain\nwhile leaf[pos].sid + count == row_id {\n if leaf[pos].is_insert {\n break \n }\n pos += 1\n count -= 1\n}\nif leaf[pos].sid + count == row_id {\n shiftLeafEntries(leaf, pos + 1, -1)\n} else {\n shiftLeafEntries(leaf, pos, 1)\n leaf[pos].sid = row_id - count\n leaf[pos].is_insert = false\n}\n```\n\n删除数据有两种情况,分别是删除 Delta 层中的数据和删除 Stable 层中的数据。其中删除 Delta 层的数据只需要删除 DeltaTree Index 中对应的 Insert Entry 即可,也就是如果在 DeltaTree Index 中查找到需要删除数据对应 row_id 的 Insert Entry 时,说明需要删除的数据在 Delta 层,此时直接将该 Insert Entry删除即可完成删除操作。但是对于 Stable 层数据的删除则相对复杂一点,需要在 DeltaTree Index 中写入一条 Delete Entry 来代表删除一条 Stable 层的数据,对应 Delete Entry 的 sid 计算逻辑和 Insert Entry 类似,这里不再赘述。\n\nAdd Delete 操作主要在 TiFlash 不同节点间 Region 发生迁移或者某张表的 TiFlash Replica 被删除时会触发,这些情况下某些 TiFlash 节点上的 Region 会被迁移走,因此需要删除该 Region 对应的数据,该删除操作通过向存储层写入一个 Delete Range 完成,这个 Delete Range 则会先写入 Delta 层,后续会扫描出该 Delete Range 覆盖的所有数据行,并依次对 DeltaTree Index 进行 Add Delete 操作。并且对于 Stable 层被删除的连续数据行,会将其对应的 Delete Entry 在 DeltaTree Index 中进行合并操作,即将这些连续删除数据行的 Delete Entry 合并为一个,并在其中记录连续删除的行数即可,这样可以大幅减小 Delete Range 操作对 DeltaTree Index 内存占用的影响。\n\n### Read\n\n上面介绍了 DeltaTree Index 的相关更新操作,接下来我们再看一下如何利用 DeltaTree Index 在读取时完成 Stable 层和 Delta 层的合并,相关的伪代码如下所示:\n\n```c++\ntotal_stable_rows = 0\niter = index.begin()\nwhile iter != index.end() {\n if iter->is_insert {\n rows = iter->sid - total_stable_rows\n read_stable_rows(rows)\n read_delta_row(delta_id)\n total_stable_rows += stable_rows\n } else {\n ignore_stable_rows(1)\n total_stable_rows += 1\n }\n iter++\n}\n```\n\n基本思路是遍历所有的叶子节点,遍历过程中如果遇到 Insert Entry,根据当前 Entry 的 sid 和已经处理的 Stable 层数据行数计算出接下来需要读取的 Stable 数据行数,读取完之后再从 Delta 层读取当前 Entry 对应的数据行。如果遇到 Delete Entry,则从 Stable 层中读取一行数据并抛弃即可。\n\n### MinMax Index\n\n现在我们已经知道如何用 DeltaTree Index 完成 Stable 层和 Delta 层的合并,但是这个过程需要扫描 Delta 层和 Stable 层的所有数据,然而集群上的很多查询不需要扫描全表的数据,因此我们想要尽可能过滤无效数据,避免无效的 IO 操作,所以我们通过引入 MinMax 索引来实现这个目的。\n\n由于 Stable 层数据是按照 DTFile 的形式存储的,且每个 DTFile 中包含多个 Pack,其中一个 Pack 中包含 8K 行或者更多的数据,因此我们可以记录每个 Pack 中不同列的最大值和最小值,如果查询中有涉及该列的相关条件时,可以根据该列的最大值和最小值判断对应 Pack 中是否可能包含需要扫描的数据,并过滤掉无效的 Pack 以减少 IO 操作的消耗,这就是 MinMax 索引的基本原理。\n\n但是在 TiFlash 中实现 MinMax Index 还有一个需要注意的关键点,就是我们需要保证相同主键的数据在同一个 Pack 中。比如看下面的例子,其中 Handle 代表的是主键列,Version 代表的是版本列,ColA 是一个普通列,假设有一个查询上包含条件 ColA < 30,那么我们可以根据 MinMax 索引判断 Pack 1 中没有需要扫描的数据,因此我们可以只从磁盘上扫描 Pack 0。但是假如这个查询的时间戳为 7,那么按照上述流程经过 MVCC 过滤后 Pack 0 中的最后一条数据会作为查询结果集的一部分返回。但是 Pack 1 中有一条主键相同且版本更新的数据,因此 Pack 0 中的最后一条数据理论上在 MVCC 过滤后应该被覆盖,而不是作为查询结果集返回。\n\n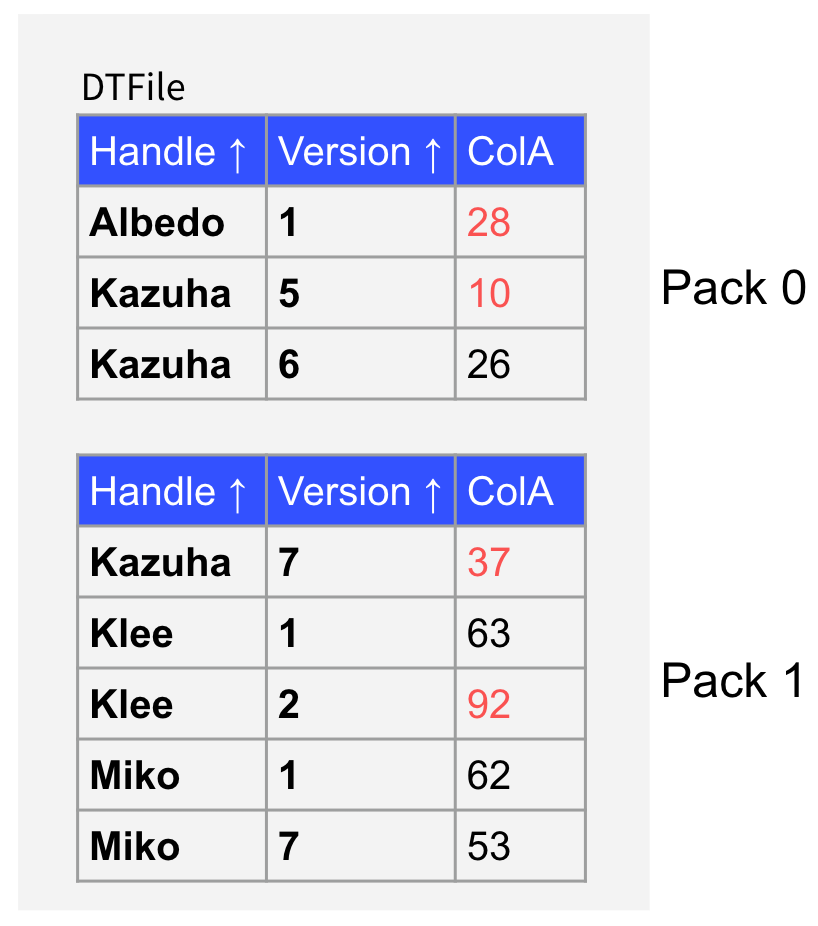\n\n所以我们在写入 DTFile 时必须保证相同主键的数据会写入同一个 Pack,这样在经过 MinMax 索引过滤后才不会发生上述例子的异常情况。\n\n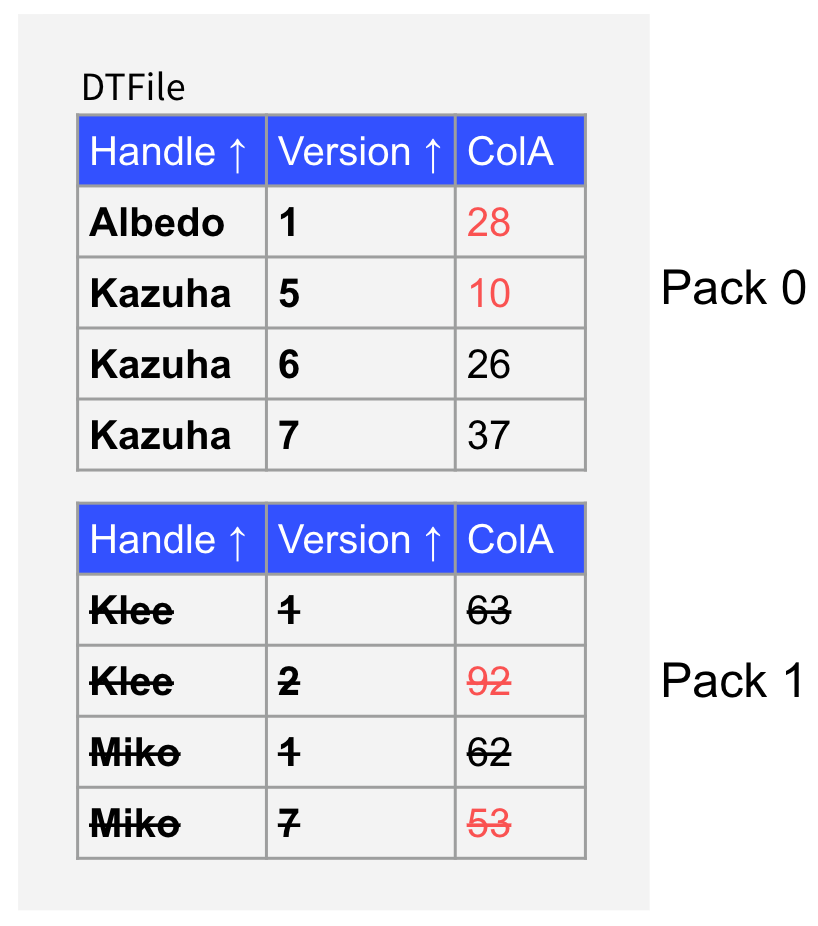\n\n### Place Rows and Deletes\n\n到目前为止如何更新 DeltaTree Index 以及如何利用 DeltaTree Index 完成读取操作已经全部介绍完成。但是前面还遗留了一个问题,就是如何获取需要插入或者删除的数据行的 row_id?其实这个问题的答案也非常简单,就是将当前的 Delta 层和 Stable 层进行合并之后,然后在其中找到需要插入或者删除数据行的 row_id 即可。\n\n当然如果每条数据的更新都要进行 Delta 层和 Stable 层的合并会带来非常大的开销,所以为了减少这个开销,我们采取了两种优化。第一个优化是对数据进行攒批,当写入的数据达到一定阈值后会在后台更新 DeltaTree Index,以此来均摊更新 DeltaTree Index 的开销。另一个优化就是采用 Skippable Place,由于 Stable 层的数据是全局主键有序的,所以可以通过主键上的 MinMax 索引跳过 Stable 层中与待更新数据范围没有重叠的 Pack,并且由于在获取所有待更新数据的 row_id 后也不会再继续读取后面的 Pack,所以通过这种优化可以使得在通常情况下只需要读取 Stable 层中和待更新数据有重叠的少部分 Pack 即可获取所有待更新数据的 row_id,因此可以大幅降低更新 DeltaTree Index 的开销。\n\n## 小结\n\nTiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件,因此 TiFlash 需要同时支持高频小批量写入以及优秀的读取性能。DeltaTree Index 结构的设计就是为了完成这个目的,更好地平衡 TiFlash 的读取和写入性能。本文只介绍了 DeltaTree Index 主要流程的基本原理,欢迎大家通过阅读 TiFlash 源码进一步了解更多的实现细节。\n\n> 体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。\n\n\n\n","author":"李德竹","category":1,"customUrl":"tiflash-source-code-reading-6","fillInMethod":"writeDirectly","id":413,"summary":"本文对 DeltaTree Index 在读取时的作用以及如何维护 DeltaTree Index 进行了讲解。","tags":["TiFlash 源码阅读"],"title":"TiFlash 源码阅读(六)DeltaTree Index 的设计和实现分析"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}