{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/tidb-source-code-reading-8",
"result": {"pageContext":{"blog":{"id":"Blogs_288","title":"TiDB 源码阅读系列文章(八)基于代价的优化","tags":["TiDB 源码阅读","社区"],"category":{"name":"产品技术解读"},"summary":"本文是 TiDB 源码阅读系列文章的第八篇。内文会先简单介绍制定查询计划以及优化的过程,然后用较大篇幅详述在得到逻辑计划后的 Cost-Based Optimization(CBO)过程。","body":"## 概述\n\n本文是 TiDB 源码阅读系列文章的第八篇。内文会先简单介绍制定查询计划以及优化的过程,然后用较大篇幅详述在得到逻辑计划后,如何基于统计信息和不同的属性选择等生成各种不同代价的物理计划,通过比较物理计划的代价,最后选择一个代价最小的物理计划,即 Cost-Based Optimization(CBO)的过程。\n\n\n## 优化器框架 \n\n一般优化器分两个阶段进行优化,即基于规则的优化(Rule-Based-Optimization,简称 RBO)和基于代价的优化(CBO)。 \n\nTiDB 主要分为两个模块对计划进行优化:\n\n* 逻辑优化,主要依据关系代数的等价交换规则做一些逻辑变换。\n\n* 物理优化,主要通过对查询的数据读取、表连接方式、表连接顺序、排序等技术进行优化。\n\n相比 RBO,CBO 依赖于统计信息的准确性与及时性,执行计划会及时的根据数据变换做对应的调整。\n\n## 优化器流程\n\nTiDB 一个查询语句的简单流程:一个语句经过 parser 后会得到一个抽象语法树(AST),首先用经过合法性检查后的 AST 生成一个逻辑计划,接着会进行去关联化、谓词下推、聚合下推等规则化优化,然后通过统计数据计算代价选择最优的物理计划,最后执行。流程如下图 1。\n\n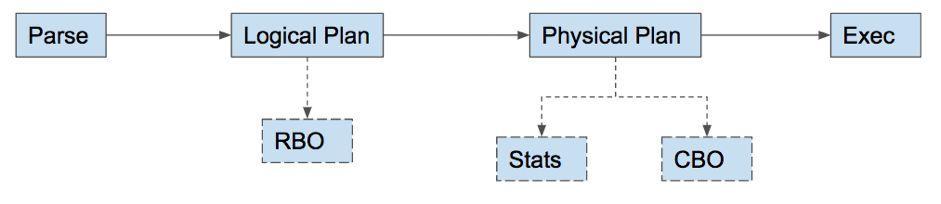\n\n 图 1
\n\n### 物理算子简介\n\n通过之前介绍物理层优化的方式,我们可以知道同一个逻辑算子可能因为它的数据读取、计算方式等不同会生成多个不同的物理算子,例如逻辑上的 Join 算子转换成物理算子可以选择 HashJoin、SortMergeJoin、IndexLookupJoin。\n\n这里会简单介绍一些逻辑算子可选择的物理算子。例如语句:`select sum(*) from t join s on t.c = s.c group by a`。此语句中逻辑算子有 DataSource、Aggregation、Join 和 Projection,接下来会对其中几个典型的逻辑算子对应的物理算子进行一个简单介绍,如下表:\n\n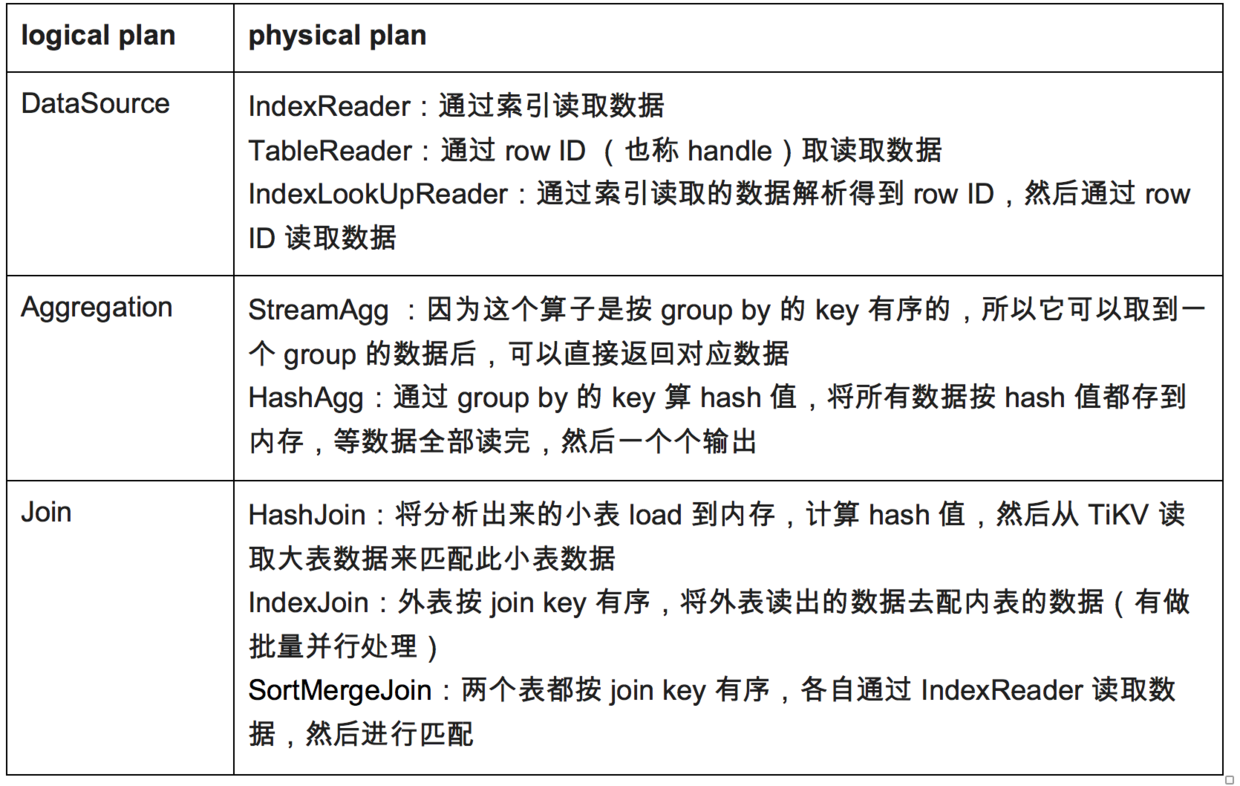\n\n## CBO 流程\n\n基于代价优化的的主要思路是计算所有可能的执行计划的代价,并挑选代价最小的执行计划的路径。那么可以倒推出,首先得到需要采集对应表的统计信息,那么就可以用来计算出每个算子的执行代价,最后将得到每条路径上算子的代价按路径各自累加获取代价最小的路径。具体的代码实现在 `plan/optimizer.go` 中 dagPhysicalOptimize 函数,本文介绍的流程基本上也都由此函数完成,代码如下: \n\n```go\nfunc dagPhysicalOptimize(logic LogicalPlan) (PhysicalPlan, error) {\n\n logic.preparePossibleProperties()\n\n logic.deriveStats()\n\n t, err := logic.convert2PhysicalPlan(&requiredProp{taskTp: rootTaskType, expectedCnt: math.MaxFloat64})\n\n if err != nil {\n\n return nil, errors.Trace(err)\n\n }\n\n p := t.plan()\n\n p.ResolveIndices()\n\n return p, nil\n\n}\n\n```\n\n出于易读性的考虑,接下来不会按代码调用顺序介绍,下面的段落与上面代码的函数对应情况如下:\n\n* prune prop 对应的函数 preparePossibleProperties。\n\n* 统计信息对应的获取函数 deriveStats。\n\n* 其余章节会介绍函数 convert2PhysicalPlan。\n\n### 整体流程\n\n这里会先描述整个 CBO 的流程。这部分逻辑的主体框架在文件 `plan/physical_plan_builder.go` ,具体处理的函数是 convert2PhysicalPlan。\n\n### 例子\n\n为了便于理解 CBO 的整个流程,这里会由一个例子展开。\n\n在展开前,先引入 required property,这个概念很重要。required property 是对算子返回值数据的要求,比如希望有些算子是按某些列有序的方式返回数据,那么会传对应的列信息,有些算子是没有要求的那么可以传空的 property。\n\n那么,现在我们举个例子,SQL 如下:\n\n```sql\nselect sum(s.a),count(t.b) from s join t on s.a = t.a and s.c < 100 and t.c > 10 group by s.a\n```\n\n(其中 a 是索引,b 也是索引)
\n\n此语句就是基于此语句的 on 条件对表 s 和表 t 做 join,然后对 join 结果做聚合。将其用图表示如图 2(此处为了与图 3 对比,此处省略 Projection 算子)。\n\n\n\n 图 2
\n\n\n\n得到了逻辑算子之后,我们怎么选择最优的物理算子呢?\n\nTiDB 是用记忆化搜索来处理的。由下往上和由上往下搜索的区别不大,考虑到后者的理解性更好,且按 parent 要求的 prop 传给children,能减少一些可能性(这个后面会具体介绍)。我们选择了由上往下的方式。\n\n接下来我们来具体介绍一下这个例子中的算子生成及选取流程。一开始的 prop 是空的,不会对 Agg 这个算子有要求。接下来就根据当前逻辑算子所有可能的 prop 构建对应的物理算子,Agg 则可以生成 Stream Agg 和 Hash Agg(此逻辑在如下面代码段的 genPhysPlansByReqProp 实现)。前者要求按 group bykey 有序,即按 a 列有序,所以他孩子的 prop 里面会带有 a 列。后者没有要求,则 prop 为空。此逻辑代码段在 `plan/physical_plan_builder.go` 中的:\n\n```go\nfor _, pp := range p.self.genPhysPlansByReqProp(prop) {\n\n t, err = p.getBestTask(t, pp)\n\n if err != nil {\n\n return nil, errors.Trace(err)\n\n }\n\n}\n```\n\n那么 Stream Agg 的 child 是 Join,Join 对应 3 种 物理算子,SortMerge Join(SMJ)、Hash Join(HJ)和 Index Join(IdxJ)。SMJ 算子要求按 join key 有序,所以构建 DS(DataSource)时,需要表 s 按 s.a 有序,表 t 按 t.a 有序。所以将 DS 构建成物理算子的时候虽然有 IdxScan(a),IdxScan(b)和 TableScan(TS),但是这些算子中满足 prop(s.a)只有 IdxScan(a)。这个例子中,只有 IdxScan(a)满足要求,返回给 SMJ,如果有另外的 算子满足的话,就会通过代价来选取,这部分内容会在“代价评估”具体介绍。\n\n使用记忆化搜索,将每个算子的 prop 计算 hash 值并存储到哈希表,所以在 HJ 算 DS(s)(带黄色箭头的路径)时会发现 SMJ 下面的 DS(s)计算过了,那么就会直接取值不做多余计算。\n\n篇幅有限这里只对左侧的路径做了描述。这个例子最后一层比较是 `HA + HJ + idx(c)` 和 `SA + MJ + idx(a)` 的比较,具体也是通过统计信息就算出代价,选取最优解。\n\n\n\n 图 3
\n\n\n(图中黑色字体算子为逻辑算子,蓝色字体为物理算子,黄色箭头为已经计算过代价的算子,会获取已经缓存在哈希表中的结果,红色虚线箭头为不符合 prop 的算子。)\n\n## 代价评估\n\n代价评估的调用逻辑在 `plan/physical_plan_builder.go` 中,代码如下:\n\n```go\nfunc (p *baseLogicalPlan) getBestTask(bestTask task, pp PhysicalPlan) (task, error) {\n\n tasks := make([]task, 0, len(p.children))\n\n for i, child := range p.children {\n\n childTask, err := child.convert2PhysicalPlan(pp.getChildReqProps(i))\n\n if err != nil {\n\n return nil, errors.Trace(err)\n\n }\n\n tasks = append(tasks, childTask)\n\n }\n\n resultTask := pp.attach2Task(tasks...)\n\n if resultTask.cost() < bestTask.cost() {\n\n bestTask = resultTask\n\n }\n\n return bestTask, nil\n\n}\n```\n\n### 统计信息\n\n这里会详细描述一下在 CBO 流程中统计信息的使用。具体采集统计信息的方法和过程,本文不具体展开,后续我们会有文章具体介绍。\n\n一个 statesInfo 的结构有两个字段: \n\n```go\n// statsInfo stores the basic information of statistics for the plan's output. It is used for cost estimation.\n\ntype statsInfo struct {\n\n count float64\n\n cardinality []float64\n\n}\n```\n\n其中 count 字段表示这个表的数据行数,每个表有一个值。cardinality 字段是用于表示每一列 distinct 数据行数,每个 column 一个。cardinality 一般通过统计数据得到,也就是统计信息中对应表上对应列的 DNV(the number of distinct value)的值。此数据具体的获取方式有两种:\n\n* 方式一,使用真实的统计数据,具体公式如下:\n\n```\nstatsTable.count / histogram.count * hist.NDV\n```\n\n(statsTable.count 会根据 stats lease 定期更新,histogram.count 只有用户手动 analyze 才更新)\n\n* 方式二,使用一个估计值,由于统计数据在某些情况下还没有收集完成,此时没有统计数据,具体公式如下:\n\n```\nstatsTable.count * distinctFactor\n```\n\n那么接下来我们举两个例子介绍通过统计数据获取算子的 statsInfo。\n\n* DataSource,首先通过前面介绍的两种公式获取 count 和 cardinality,接着用可下推的表达式计算 selectivity 的值,`selectivity = row count after filter / row count before filter`,最后用计算的 selectivity 来调整原来的 count 和 cardinality 的值。\n\n* LogicalJoin(inner join),此算子的 count 获取的公式:\n\n```\nN(join(s,t)) = N(s) * N(t) / (V(s.key) * V(t.key)) * Min(V(s.key), V(t.key))\n```\n\n(其中 N 为表的行数,V 为 key 的 cardinality 值)
\n\n可以理解为表 s 与表 t 中不重复值的平均行数的乘积乘上小表的不重复值行数。\n\n这里介绍的逻辑在 `stats.go` 文件里面的 plan/deriveStats 函数。\n\n### expected count\n\nexpected count 表示整个 SQL 结束前此算子期望读取的行数。例如 SQL:`select * from s where s.c1 < 5 order by id limit 3` (其中 c1 是索引列,id 是主键列)。我们可以简单认为得到两类可能的计划路径图,如图 4。 \n\n* 前者在 PhysicalLimit 时选择 id 有序,那么它的 expected count 为 3。因为有 c1 < 5 的过滤条件,所以在 TableScan 时 expected count 的值为 `min(n(s),3 / f (σ(c1<5) ))` 。\n\n* 后者在 TopN 的时候虽然知道它需要读取 3 行,但是它是按 id 列有序,所以它的 expected count 为 Max,在 IndexScan 的时候 expected count 是 `count * f (σ(c1<5)`。\n\n\n\n 图 4
\n\n\n\n### Task\n\n在代价评估时将物理算子关联到 task 这个对象结构。task 分为三种类型,分别是 cop single, cop double 和 root。前两种类型都可以下推到 coprocessor 执行。将其区分类型有两个原因:一个是它可以区分对应的算子是在 TiDB 处理还是被下推到 TiKV 的 coprocessor 处理;另外一个比较重要的原因是为了评估代价时更加准确。\n\n这里我们举个例子,SQL 如下:\n\n```sql\nselect * from t where c < 1 and b < 1 and a = 1\n```\n\n(其中 (a,b) 是索引, (b,a,c) 是索引,表 t 有 a、b 和 c 三列)
\n\n那么可以得到如下两种路径:\n\n* doubleread(即IndexLookUpReader ):`IndexScan( a = 1 and b < 1 ) -> TableScan -> Selection(c < 1)`\n\n* singleread(即IndexReader):`IndexScan( b < 1 ) -> Selection( a = 1 and c < 1 )`\n\n不区分 cop single 和 cop double 的时候,去搜索最底层,这会导致情况二被提前舍弃。但是实际上这两种路径,在第一种路径考虑向 TiKV 读两次数据的情况后,其代价很有可能超过第二种路径。所以我们会区分 copsingle 和 cop double,不在 IndexScan 的时候比较,而是在 Selection 结束的时候再比较开销,那么就很可能选第二种计划路径。这样就比较符合实际情况。\n\n我们通用的计算代价的公式:\n\n```\nCost(p) = N(p)*FN+M(p)*FM+C(p)*FC\n```\n\n(其中 N 表示网络开销,M 表示内存开销,C 表示 CPU 开销,F 表示因子)
\n\n将 plan 与 task 关联,并加上此 plan 的 cost。\n\ntask 处理的代码主要在文件 `plan/task.go` 中。\n\n## prune properties\n\n引入预处理 property 函数的原因是为了减少一些没有必要考虑的 properties,从而尽可能早的裁减掉成物理计划搜索路径上的分支,例如:\n\n```sql\nselect * from t join s on t.A = s.A and t.B = s.B\n```\n\n它的 property 可以是 {A, B}, {B, A}。\n\n如果我们有 n 个等式条件,那么我们会有 n! 种可能的 property。如果有了此操作,我们只能使用 t 表和 s 表本身拥有的 properties。\n\nproperties 是在 DataSource 这个 logical 算子中获取的,因为此算子中可以得到对应的主键和索引信息。\n\n此处逻辑由文件 `plan/property_cols_prune.go` 里的 preparePossibleProperties 函数处理。\n\n> 点击查看更多 [TiDB 源码阅读系列文章](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)","date":"2018-05-04","author":"李霞","fillInMethod":"writeDirectly","customUrl":"tidb-source-code-reading-8","file":null,"relatedBlogs":[]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}