{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/tidb-query-optimization-and-tuning-5",
"result": {"pageContext":{"blog":{"id":"Blogs_390","title":"TiDB 查询优化及调优系列(五)调优案例实践","tags":["TiDB","TiDB 性能调优"],"category":{"name":"产品技术解读"},"summary":"本文为「TiDB 查询优化及调优」系列文章的第五篇,也是最终篇。通过这个系列文章,我们详细介绍了 TiDB 优化器、查询计划、慢查询以及调优的理论知识,并在本章节中进行了实战的分享。希望通过这个系列文章,大家能够更加深入地理解 TiDB 优化器,并通过这些调优技巧更好地提升系统性能。","body":"本篇文章为 TiDB 查询优化及调优系列的最终篇,主要汇集了一些用户常见的 SQL 优化案例,从背景、分析、影响、建议、实操几个角度进行解析。关于 SQL 调优原理的介绍见前面章节。\n\n\n相关阅读:\n\n[TiDB 查询优化及调优系列(一)TiDB 优化器简介](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-1)\n\n[TiDB 查询优化及调优系列(二)TiDB 查询计划简介](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-2)\n\n[TiDB 查询优化及调优系列(三)慢查询诊断监控及排查](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-3)\n\n[TiDB 查询优化及调优系列(四)查询执行计划的调整及优化原理](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-4)\n\n注:以下语句及结果基本为当时实际环境所记录的情况,因为版本更新原因,可能和现有格式略有差别,如 count 等价于现在的 estRows.\n\n## 案例1: Delete 涉及数据量过大导致 OOM\n\n```\nMySQL [db_stat]> explain delete from t_stat where imp_date<='20200202';\n+---------------------+--------------+------+------------------------------------------------------+\n| id | count | task | operator info |\n+---------------------+--------------+------+------------------------------------------------------+\n| TableReader_6 | 220895815.00 | root | data:Selection_5 |\n| └─Selection_5 | 220895815.00 | cop | le(db_stat.t_stat.imp_date, \"20200202\") |\n| └─TableScan_4 | 220895815.00 | cop | table:t_stat, range:[-inf,+inf], keep order:false |\n+---------------------+--------------+------+------------------------------------------------------+\n3 rows in set (0.00 sec)\nMySQL [db_stat]> select count(*) from t_stat where imp_date<='20200202';\n+-----------+\n| count(*) |\n+-----------+\n| 184340473 |\n+-----------+\n1 row in set (17.88 sec)\n```\n\n### 背景\n\n大批量清理数据时系统资源消耗高,在 TiDB 节点内存不足时可能导致 OOM\n\n### 分析\n\n`imp_date` 字段上虽然有索引,但是扫描的时间范围过大,无论优化器选择 IndexScan 还是 Table Scan,TiDB 都要向 TiKV Coprocessor 请求读取大量的数据\n\n### 影响\n\n- TiKV 节点 Coprocessor CPU 使用率快速上涨\n- 执行 Delete 操作的 TiDB 节点内存占用快速上涨,因为要将大批量数据加载到 TiDB 内存\n\n### 建议\n\n- 删除数据时,缩小数据筛选范围,或者加上 limit N 每次删除一批数据\n- 建议使用 Range 分区表,按照分区快速删除\n\n\n## 案例2 执行计划不稳定导致查询延迟增加\n\n```\nMySQL [db_stat]> explain SELECT * FROM `tbl_article_check_result` `t` WHERE (articleid = '20190925A0PYT800') ORDER BY checkTime desc LIMIT 100 ;\n+--------------------------+----------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+--------------------------+----------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n| Projection_7 | 100.00 | root | db_stat.t.type, db_stat.t.articleid, db_stat.t.docid, db_stat.t.version, db_stat.t.checkid, db_stat.t.checkstatus, db_stat.t.seclevel, db_stat.t.t1checkstatus, db_stat.t.t2checkstatus, db_stat.t.mdaichannel, db_stat.t.mdaisubchannel, db_stat.t.checkuser, db_stat.t.checktime, db_stat.t.addtime, db_stat.t.havegot, db_stat.t.checkcode |\n| └─Limit_12 | 100.00 | root | offset:0, count:100 |\n| └─IndexLookUp_34 | 100.00 | root | |\n| ├─IndexScan_31 | 30755.49 | cop | table:t, index:checkTime, range:[NULL,+inf], keep order:true, desc |\n| └─Selection_33 | 100.00 | cop | eq(db_dayu_1.t.articleid, \"20190925A0PYT800\") |\n| └─TableScan_32 | 30755.49 | cop | table:tbl_article_check_result, keep order:false |\n+--------------------------+----------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n6 rows in set (0.00 sec)\n```\n\n### 背景\n\n``articleid`` 和 ``checkTime`` 字段上分别建有单列索引,正常情况下走 ``articleid`` 上的索引比较快,偶尔执行计划不稳定时走 ``checkTime`` 上的索引,导致查询延迟达到分钟级别\n\n### 分析\n\n``LIMIT 100`` 限定了获取 100 条记录,如果 ``checkTime`` 和 ``articleid`` 列之间的相关度不高,在独立性假设失效时,优化器估算走 ``checkTime`` 上的索引并满足 ``articleid`` 条件时扫描的行数,可能比走 ``articleid`` 上的索引扫描的行数更少\n\n### 影响\n\n业务响应延迟不稳定,监控 Duration 偶尔出现抖动\n\n### 建议\n\n- 手动 analyze table,配合 crontab 定期 analyze,维持统计信息准确度\n- 自动 auto analyze,调低 analyze ratio 阈值,提高收集频次,并设置运行时间窗\n - set global tidb_auto_analyze_ratio=0.2;\n - set global tidb_auto_analyze_start_time='00:00 +0800';\n - set global tidb_auto_analyze_end_time='06:00 +0800';\n- 业务修改 SQL ,使用 force index 固定使用 articleid 列上的索引\n- 业务可以不用修改 SQL,使用 SPM (见上述章节)的 create binding 创建 force index 的绑定 SQL,可以避免执行计划不稳定导致的性能下降\n\n## 案例3 查询字段与值的数据类型不匹配\n\n```\nMySQL [db_stat]> explain select * from t_like_list where person_id=1535538061143263;\n+---------------------+------------+------+-----------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+---------------------+------------+------+-----------------------------------------------------------------------------------+\n| Selection_5 | 1430690.40 | root | eq(cast(db_stat.t_like_list.person_id), 1.535538061143263e+15) |\n| └─TableReader_7 | 1788363.00 | root | data:TableScan_6 |\n| └─TableScan_6 | 1788363.00 | cop | table:t_like_list, range:[-inf,+inf], keep order:false |\n+---------------------+------------+------+-----------------------------------------------------------------------------------+\n3 rows in set (0.00 sec)\n```\n\n### 背景\n\n``person_id`` 列上建有索引且选择性较好,但执行计划没有按预期走 ``IndexScan``\n\n### 分析\n\n``person_id`` 是字符串类型,但是存储的值都是数字,业务认为可以直接赋值;而优化器需要在字段上做 ``cast`` 类型转换,导致无法使用索引\n\n### 建议\n\n``where`` 条件的值加上引号,之后执行计划使用了索引:\n\n```\nMySQL [db_stat]> explain select * from table:t_like_list where person_id='1535538061143263';\n+-------------------+-------+------+----------------------------------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+-------------------+-------+------+----------------------------------------------------------------------------------------------------------+\n| IndexLookUp_10 | 0.00 | root | |\n| ├─IndexScan_8 | 0.00 | cop | table:t_like_list, index:person_id, range:[\"1535538061143263\",\"1535538061143263\"], keep order:false |\n| └─TableScan_9 | 0.00 | cop | table:t_like_list, keep order:false |\n+-------------------+-------+------+----------------------------------------------------------------------------------------------------------+\n3 rows in set (0.00 sec)\n```\n\n## 案例4 读热点导致 SQL 延迟增加\n\n### 背景\n\n某个数据量 600G 左右、读多写少的 TiDB 集群,某段时间发现 TiDB 监控的 Query Summary - Duration 指标显著增加,p99 如下图。\n\n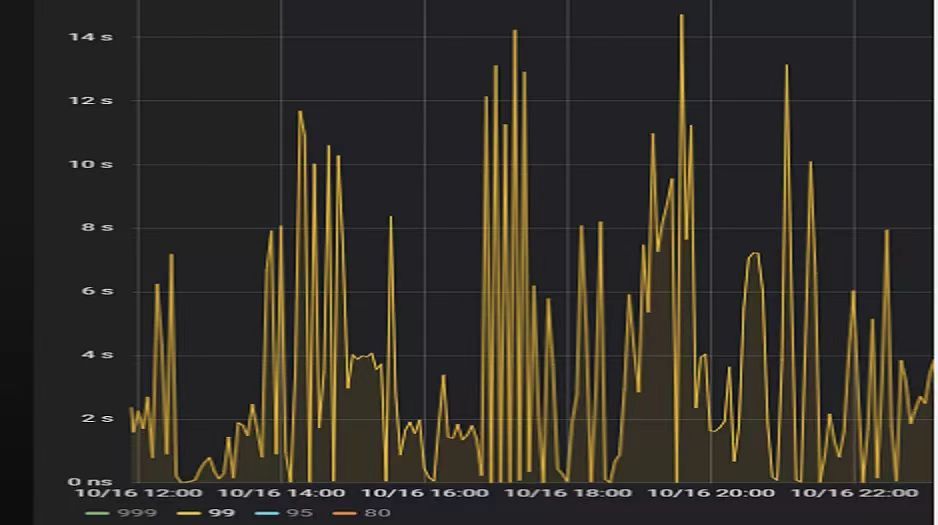\n\n查看 TiDB 监控下的 KV Duration 明显升高,其中 KV Request Duration 999 by store 监控看到多个 TiKV 节点 Duration 均有上涨。\n\n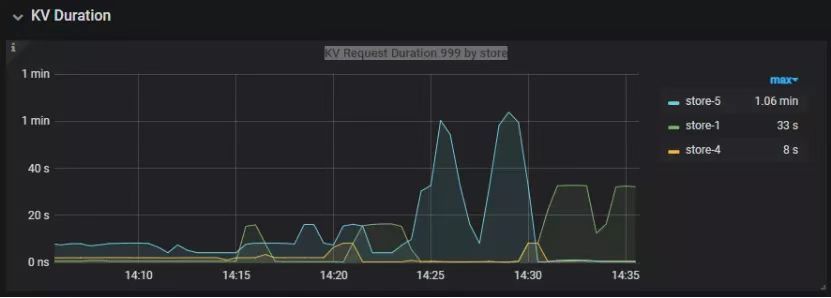\n\n查看 TiKV 监控 Coprocessor Overview:\n\n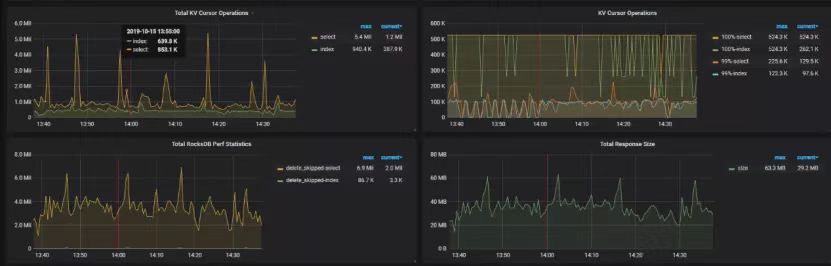\n\n查看监控 Coprocessor CPU:\n\n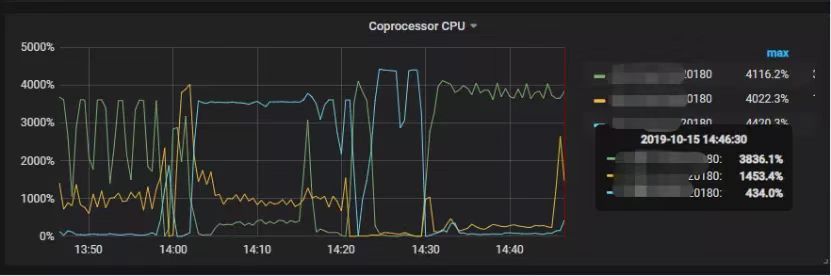\n\n发现 Coprocessor CPU 线程池几乎打满。下面开始分析日志,调查 Duration 和 Coprocessor CPU 升高的原因。\n\n\n### 慢查询日志分析\n\n使用 ``pt-query-digest`` 工具分析 TiDB 慢查询日志:\n\n```\n./pt-query-digest tidb_slow_query.log > result\n```\n\n分析慢日志解析出来的 TopSQL 发现 ``Process keys`` 和 ``Process time`` 并不是线性相关,``Process keys`` 数量多的 SQL 的 ``Process time`` 处理时间不一定更长,如下面 SQL 的 ``Process keys`` 为 22.09M,``Process time`` 为 51s。\n\n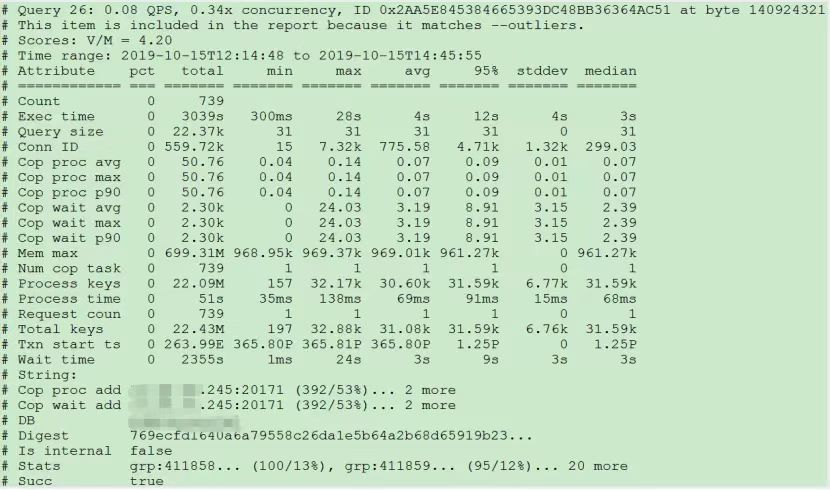\n\n下面 SQL 的 ``Process keys`` 为 12.68M,但是 ``Process time`` 高达 142353s。\n\n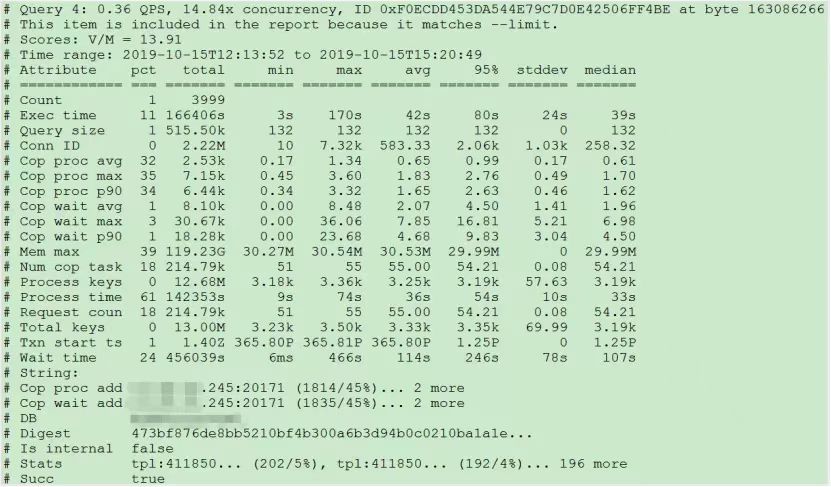\n\n过滤 ``Process time`` 较多的 SQL,发现 3 个典型的 ``slow query``,分析具体的执行计划。\n\n**SQL1**\n\n```\nselect a.a_id, a.b_id,uqm.p_id from a join hsq on a.b_id=hsq.id join uqm on a.a_id=uqm.id;\n```\n\n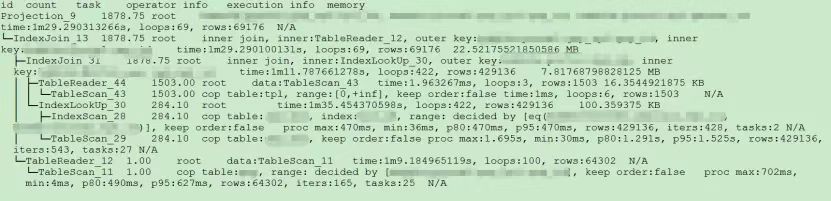\n\n**SQL2**\n\n```\nselect distinct g.abc, g.def, g.ghi, h.abcd, hi.jq from ggg g left join ggg_host gh on g.id = gh.ggg_id left join host h on gh.a_id = h.id left join a_jq hi on h.id = hi.hid where h.abcd is not null and h.abcd <> '' and hi.jq is not null and hi.jq <> '';\n```\n\n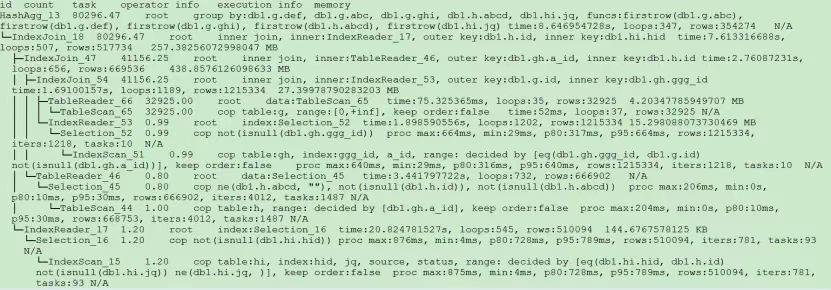\n\n**SQL3**\n\n```\nselect tb1.mt, tb2.name from tb2 left join tb1 on tb2.mtId=tb1.id where tb2.type=0 and (tb1.mt is not null and tb1.mt != '') and (tb2.name is not null or tb2.name != '');\n```\n\n\n\n分析执行计划未发现异常,查看相关表的统计信息也都没有过期,继续分析 TiDB 和 TiKV 日志。\n\n### 常规日志分析\n\n查看 TiKV 日志中标记为 [slow-query] 的日志行中的 region 分布情况。\n\n```\nmore tikv.log.2019-10-16-06\\:28\\:13 |grep slow-query |awk -F ']' '{print $1}' | awk '{print $6}' | sort | uniq -c | sort –n\n```\n\n找到访问频率最大的 3 个 region:\n\n```\n73 29452\n140 33324\n757 66625\n```\n\n这些 region 的访问次数远远高于其它 region,之后定位这些 region 所属的表名。首先查看 [slow-query] 所在行记录的 table_id 和 start_ts,然后查询 TiDB 日志获取表名,比如 table_id 为 1318,start_ts 为 411837294180565013,使用如下命令过滤,发现是上述慢查询 SQL 涉及的表。\n\n```\nmore tidb-2019-10-14T16-40-51.728.log | grep '\"/[1318/]\"' |grep 411837294180565013\n```\n\n### 解决\n\n对这些 region 做 split 操作,以 region 66625 为例,命令如下(需要将 x.x.x.x 替换为实际的 pd 地址)。\n\n```\npd-ctl –u http://x.x.x.x:2379 operator add split-region 66625\n```\n\n操作后查看 PD 日志\n\n```\n[2019/10/16 18:22:56.223 +08:00] [INFO] [operator_controller.go:99] [\"operator finish\"] [region-id=30796] [operator=\"\\\"admin-split-region (kind:admin, region:66625(1668,3), createAt:2019-10-16 18:22:55.888064898 +0800 CST m=+110918.823762963, startAt:2019-10-16 18:22:55.888223469 +0800 CST m=+110918.823921524, currentStep:1, steps:[split region with policy SCAN]) finished\\\"\"]\n```\n\n日志显示 region 已经分裂完成,之后查看该 region 相关的 slow-query:\n```\nmore tikv.log.2019-10-16-06\\:28\\:13 |grep slow-query | grep 66625\n```\n\n观察一段时间后确认 66625 不再是热点 region,继续处理其它热点 region。所有热点 region 处理完成后,监控 Query Summary - Duration 显著降低。\n\n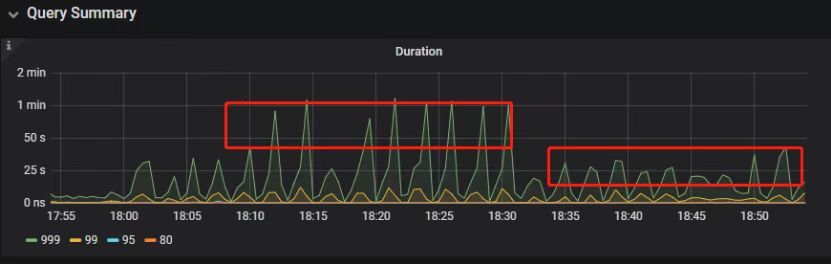\n\nDuration 稳定了保持一段时间,18:55 之后仍然有较高的 Duration 出现:\n\n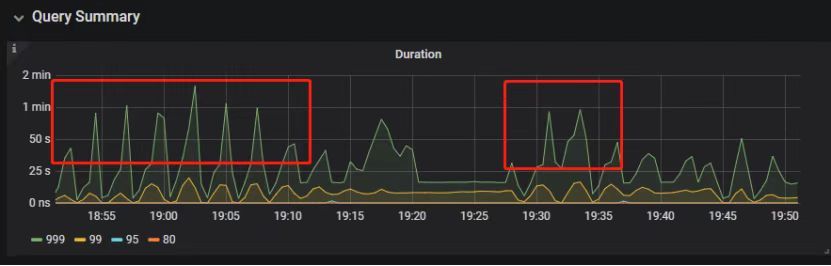\n\n\n观察压力较重的 tikv,移走热点 region 的 leader:\n\n```\npd-ctl –u http://x.x.x.x:2379 operator add transfer-leader 1 2 //把 region1 的 leader 调度到 store2\n```\n\nleader 迁走之后,原 TiKV 节点的 Duration 立刻下降,但是迁移到新 TiKV 节点的 Duration 随之上升。\n\n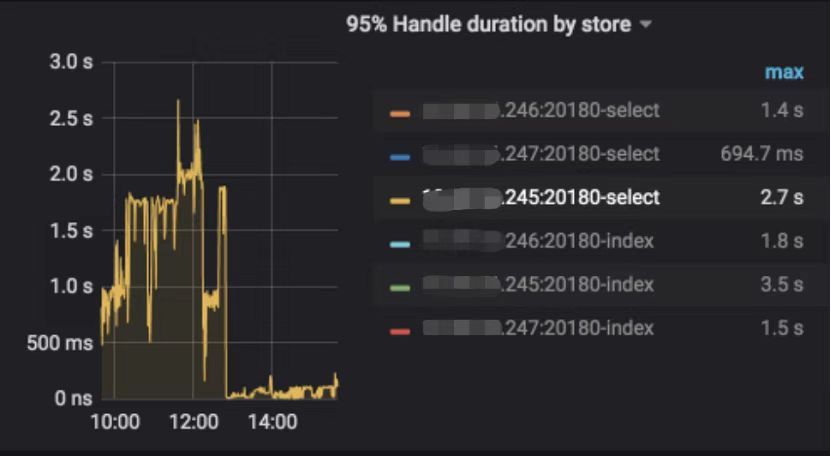\n\n之后多次对热点 region 进行 split 操作,最终 Duration 明显下降并恢复稳定。\n\n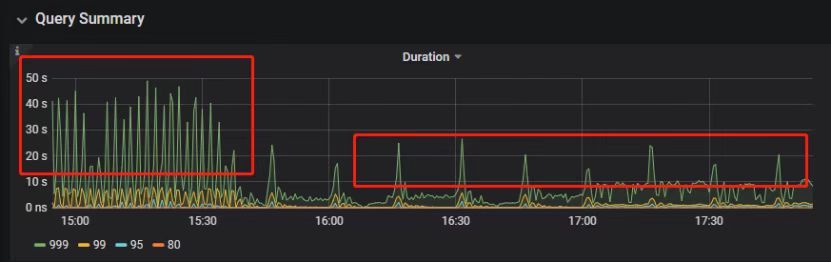\n\n### 案例总结\n对于分布式数据库的读热点问题,有时难以通过优化 SQL 的方式解决,需要分析整个 TiDB 集群的监控和日志来定位原因。严重的读热点可能导致部分 TiKV 达到资源瓶颈,这种短板效应限制了整个集群性能的充分发挥,通过分裂 region 的方式可以将热点 region 分散到更多的 TiKV 节点上,让每个 TiKV 的负载尽可能达到均衡,缓解读热点对 SQL 查询性能的影响。更多热点问题的处理思路可以参考 [TiDB 查询优化及调优系列(四)查询执行计划的调整及优化原理](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-4)。\n\n\n## 案例5 SQL 执行计划不准\n\n### 背景\n\nSQL 执行时间突然变长\n\n### 分析\n\n- SQL 语句\n\n```\nselect count(*)\nfrom tods.bus_jijin_trade_record a, tods.bus_jijin_info b \nwhere a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \nand a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \nand a.cancel_app_no is not null and a.id >= 177045000 \nand a.updated_at > date_sub(now(), interval 48 hour) ;\n```\n\n执行结果,需要 1 分 3.7s:\n\n```\nmysql> select count(*)\n -> from tods.bus_jijin_trade_record a, tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;\n+----------+\n| count(*) |\n+----------+\n| 708 |\n+----------+\n1 row in set (1 min 3.77 sec)\n```\n\n- 索引信息\n\n\n\n \n- 查看执行计划\n\n```\nmysql> explain \n -> select count(*)\n -> from tods.bus_jijin_trade_record a, tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;\n+----------------------------+--------------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+----------------------------+--------------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n| StreamAgg_13 | 1.00 | root | funcs:count(1) |\n| └─HashRightJoin_27 | 421.12 | root | inner join, inner:TableReader_18, equal:[eq(a.fund_code, b.fund_code)] |\n| ├─TableReader_18 | 421.12 | root | data:Selection_17 |\n| │ └─Selection_17 | 421.12 | cop | eq(a.pay_confirm_status, 1), eq(a.status, \"CANCEL_SUCCESS\"), gt(a.updated_at, 2020-03-03 22:31:08), in(a.type, \"PURCHASE\", \"APPLY\"), not(isnull(a.cancel_app_no)) |\n| │ └─TableScan_16 | 145920790.55 | cop | table:a, range:[177045000,+inf], keep order:false |\n| └─TableReader_37 | 6442.00 | root | data:TableScan_36 |\n| └─TableScan_36 | 6442.00 | cop | table:b, range:[-inf,+inf], keep order:false |\n+----------------------------+--------------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+\n\nTableScan_16,TableScan_36:表示在 TiKV 端分别对表 a 和 b 的数据进行扫描,其中 TableScan_16 扫描了 1.46 亿的行数;\nSelection_17:表示满足表 a 后面 where 条件的数据;\nTableReader_37: 由于表 b 没有独立的附加条件,所以直接将这部分数据返回给 TiDB;\nTableReader_18:将各个 coprocessor 满足 a 表条件的结果返回给 TiDB;\nHashRightJoin_27:将 TableReader_37 和 TableReader_18 上的结果进行 hash join;\nStreamAgg_13:进一步统计所有行数,将数据返回给客户端;\n```\n\n可以看到语句中 a 表(bus_jijin_trade_record)的条件 id >= 177045000,和 updated_at > date_sub(now(), interval 48 hour)上,这两个列分别都有索引,但是 TiDB 还是选择了全表扫描。\n\n按照上面两个条件分别查询数据分区情况\n\n```\nmysql> SELECT COUNT(*) FROM tods.bus_jijin_trade_record WHERE id >= 177045000 ;\n+-----------+\n| COUNT(*) |\n+-----------+\n| 145917327 |\n+-----------+\n1 row in set (16.86 sec)\n\nmysql> SELECT COUNT(*) FROM tods.bus_jijin_trade_record WHERE updated_at > date_sub(now(), interval 48 hour) ;\n+-----------+\n| COUNT(*) |\n+-----------+\n| 713682 |\n+-----------+\n```\n\n可以看到,表 bus_jijin_trade_record 有 1.7 亿的数据量,应该走 updated_at 字段上的索引。\n使用强制 hint 进行执行,6.27 秒就执行完成了,速度从之前 63s 到现在的 6.3s,提升了 10 倍。\n\n```\nmysql> select count(*)\n -> from tods.bus_jijin_trade_record a use index(idx_bus_jijin_trade_record_upt), tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;\n+----------+\n| count(*) |\n+----------+\n| 709 |\n+----------+\n1 row in set (6.27 sec)\n```\n\n强制 hint 后的执行计划:\n\n```\nmysql> explain \n -> select count(*)\n -> from tods.bus_jijin_trade_record a use index(idx_bus_jijin_trade_record_upt), tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;\n+------------------------------+--------------+------+----------------------------------------------------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+------------------------------+--------------+------+----------------------------------------------------------------------------------------------------------------------------+\n| StreamAgg_13 | 1.00 | root | funcs:count(1) |\n| └─HashRightJoin_24 | 421.12 | root | inner join, inner:IndexLookUp_20, equal:[eq(a.fund_code, b.fund_code)] |\n| ├─IndexLookUp_20 | 421.12 | root | |\n| │ ├─Selection_18 | 146027634.83 | cop | ge(a.id, 177045000) |\n| │ │ └─IndexScan_16 | 176388219.00 | cop | table:a, index:UPDATED_AT, range:(2020-03-03 23:05:30,+inf], keep order:false |\n| │ └─Selection_19 | 421.12 | cop | eq(a.pay_confirm_status, 1), eq(a.status, \"CANCEL_SUCCESS\"), in(a.type, \"PURCHASE\", \"APPLY\"), not(isnull(a.cancel_app_no)) |\n| │ └─TableScan_17 | 146027634.83 | cop | table:bus_jijin_trade_record, keep order:false |\n| └─TableReader_31 | 6442.00 | root | data:TableScan_30 |\n| └─TableScan_30 | 6442.00 | cop | table:b, range:[-inf,+inf], keep order:false |\n+------------------------------+--------------+------+----------------------------------------------------------------------------------------------------------------------------+\n```\n\n使用 hint 后的执行计划,预估 updated_at 上的索引会扫描 176388219,没有选择索引而选择了全表扫描,可以判定是由于错误的统计信息导致执行计划有问题。\n\n查看表 ``bus_jijin_trade_record`` 上的统计信息。\n\n```\nmysql> show stats_meta where table_name like 'bus_jijin_trade_record' and db_name like 'tods';\n+---------+------------------------+---------------------+--------------+-----------+\n| Db_name | Table_name | Update_time | Modify_count | Row_count |\n+---------+------------------------+---------------------+--------------+-----------+\n| tods | bus_jijin_trade_record | 2020-03-05 22:04:21 | 10652939 | 176381997 |\n+---------+------------------------+---------------------+--------------+-----------+\n\nmysql> show stats_healthy where table_name like 'bus_jijin_trade_record' and db_name like 'tods';\n+---------+------------------------+---------+\n| Db_name | Table_name | Healthy |\n+---------+------------------------+---------+\n| tods | bus_jijin_trade_record | 93 |\n+---------+------------------------+---------+\n```\n\n根据统计信息,表 ``bus_jijin_trade_record`` 有 176381997,修改的行数有 10652939,该表的健康度为:(176381997-10652939)/176381997 *100=93。\n\n### 解决\n\n重新收集统计信息\n\n```\nmysql> set tidb_build_stats_concurrency=10;\nQuery OK, 0 rows affected (0.00 sec)\n\n#调整收集统计信息的并发度,以便快速对统计信息进行收集 \nmysql> analyze table tods.bus_jijin_trade_record;\nQuery OK, 0 rows affected (3 min 48.74 sec)\n```\n\n查看没有使用 hint 语句的执行计划\n\n```\nmysql> explain select count(*)\n -> from tods.bus_jijin_trade_record a, tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;;\n+------------------------------+-----------+------+----------------------------------------------------------------------------------------------------------------------------+\n| id | count | task | operator info |\n+------------------------------+-----------+------+----------------------------------------------------------------------------------------------------------------------------+\n| StreamAgg_13 | 1.00 | root | funcs:count(1) |\n| └─HashRightJoin_27 | 1.99 | root | inner join, inner:IndexLookUp_23, equal:[eq(a.fund_code, b.fund_code)] |\n| ├─IndexLookUp_23 | 1.99 | root | |\n| │ ├─Selection_21 | 626859.65 | cop | ge(a.id, 177045000) |\n| │ │ └─IndexScan_19 | 757743.08 | cop | table:a, index:UPDATED_AT, range:(2020-03-03 23:28:14,+inf], keep order:false |\n| │ └─Selection_22 | 1.99 | cop | eq(a.pay_confirm_status, 1), eq(a.status, \"CANCEL_SUCCESS\"), in(a.type, \"PURCHASE\", \"APPLY\"), not(isnull(a.cancel_app_no)) |\n| │ └─TableScan_20 | 626859.65 | cop | table:bus_jijin_trade_record, keep order:false |\n| └─TableReader_37 | 6442.00 | root | data:TableScan_36 |\n| └─TableScan_36 | 6442.00 | cop | table:b, range:[-inf,+inf], keep order:false |\n+------------------------------+-----------+------+----------------------------------------------------------------------------------------------------------------------------+\n9 rows in set (0.00 sec)\n```\n\n可以看到,收集完统计信息后,现在的执行计划走了索引扫描,与手动添加 hint 的行为一致,且扫描的行数 757743 符合预期。\n\n此时执行时间变为 1.69s ,在执行计划没变的情况下,应该是由于缓存命中率上升带来的提升。\n\n```\nmysql> select count(*)\n -> from tods.bus_jijin_trade_record a, tods.bus_jijin_info b \n -> where a.fund_code=b.fund_code and a.type in ('PURCHASE','APPLY') \n -> and a.status='CANCEL_SUCCESS' and a.pay_confirm_status = 1 \n -> and a.cancel_app_no is not null and a.id >= 177045000 \n -> and a.updated_at > date_sub(now(), interval 48 hour) ;\n+----------+\n| count(*) |\n+----------+\n| 712 |\n+----------+\n1 row in set (1.69 sec)\n```\n\n### 案例总结\n\n可以看出该 SQL 执行效率变差是由于统计信息不准确造成的,在通过收集统计信息之后得到了正确的执行计划。\n\n从最终结果 712 行记录来看,创建联合索引可以更大的降低扫描数据的量,更进一步提升性能。在性能已经满足业务要求情况下,联合索引会有额外的成本,留待以后尝试。\n\n\n本文为「TiDB 查询优化及调优」系列文章的第五篇,也是最终篇。通过这个系列文章,我们详细介绍了 TiDB 优化器、查询计划、慢查询以及调优的理论知识,并在本章节中进行了实战的分享。希望通过这个系列文章,大家能够更加深入地理解 TiDB 优化器,并通过这些调优技巧更好地提升系统性能。\n\n如果您对 TiDB 的产品有任何建议,欢迎来到 [internals.tidb.io](https://internals.tidb.io/) 与我们交流。\n\n> 点击查看更多 [TiDB 查询优化及调优](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98)文章","date":"2022-05-24","author":"Yu Dong","fillInMethod":"writeDirectly","customUrl":"tidb-query-optimization-and-tuning-5","file":null,"relatedBlogs":[{"relatedBlog":{"body":"与其它主流商业数据库一样,TiDB 的查询优化器负责用户及系统查询的优化,生成有效且高效的执行计划由执行器来执行。而优化器生成的执行计划的优劣直接影响查询的执行效率和性能。「TiDB 查询优化及调优」系列文章将通过一些具体的案例,向大家介绍 TiDB 查询及优化相关的原理和应用。本文为系列文章的第一篇,将简要介绍 TiDB 的查询优化器的优化流程。\n\n## TiDB 中常见的逻辑优化规则\n\n优化器的优化过程可以简单的看成在一个搜索问题,即针对一条查询,在由各种可能的执行计划构成的巨大搜索空间内寻找到该查询的最优执行计划。不同的数据库查询优化器根据架构不同,对应的优化流程也有所不同。TiDB 的查询优化流程主要分为逻辑优化和物理优化两部分。\n\n在逻辑优化中,利用关系代数的变换规则进行查询语句表达式的等价变换,并在这个过程中不断增加或修剪可能的计划搜索空间(例如不同的 join order),最后选择生成最优的逻辑计划树。在之后的物理优化过程中,对逻辑计划树中的算子节点生成实际执行的物理计划,并评估不同物理计划的实现算法(例如不同的 join 方法)或对象(例如使用不同的索引)的代价,从中选取代价最小的物理计划。\n\n下面分别对逻辑优化和物理优化做简介。\n\n逻辑优化是针对逻辑计划中的逻辑算子进行的优化流程。在介绍逻辑优化规则之前,我们先简介一下 TiDB 中的几种主要逻辑算子:\n\n- DataSource:数据源,表示一个源表,如 ``select * from t`` 中的 ``t`` 。\n\n- Selection:代表了相应的过滤条件,``select * from t where a = 5`` 中的 ``where a = 5`` 。\n\n- Projection:投影操作,也用于表达式计算, ``select c, a + b from t`` 里面的 ``c`` 和 ``a+b`` 就是投影和表达式计算操作。\n\n- Join:两个表的连接操作,``select t1.b, t2.c from t1 join t2 on t1.a = t2.a`` 中的 ``t1 join t2 on t1.a = t2.a`` 就是两个表 ``t1`` 和 ``t2`` 的连接操作。Join 有内连接,左连接,右连接等多种连接方式。\n\nSelection,Projection,Join(简称 SPJ) 是 3 种最基本的算子。\n\nTiDB 的逻辑优化是基于规则的优化,通过对输入的逻辑执行计划按顺序应用优化规则,使整个逻辑执行计划变得更加高效。这些常用逻辑优化规则包括:\n\n\n\n部分逻辑优化规则示例如下:\n\n**规则 4:Max / Min 优化**\n\nMax/ Min 优化,会对Max/ Min 语句进行改写。如下面的语句:\n\n``select min(id) from t;`` \n\n改成下面的写法,可以实现类似的效果:\n\n``select id from t order by id desc limit 1;``\n\n前一个语句生成的执行计划,是一个 TableScan 上面接一个 Aggregation,这是一个全表扫描的操作。后一个语句,生成执行计划是 TableScan + Sort + Limit。通常数据表中的 id 列是主键或者存在索引,数据本身有序,这样 Sort 就可以消除,最终变成 TableScan/IndexLookUp + Limit,这样就避免了全表扫描的操作,只需要读到第一条数据就能返回结果。\n\n最大最小消除由优化器“自动”地做这个变换。\n\n**规则 5:外连接消除**\n\n外连接消除指的是将整个连接操作从查询中移除。外连接消除需要满足一定条件:\n\n- 条件 1:LogicalJoin 的父亲算子只会用到 LogicalJoin 的 outer plan 所输出的列\n\n- 条件 2:\n\n - 条件 2.1:LogicalJoin 中的 join key 在 inner plan 的输出结果中满足唯一性\n\n - 条件 2.2:LogicalJoin 的父亲算子会对输入的记录去重\n\n条件 1 和条件 2 必须同时满足,但条件 2.1 和条件 2.2 只需满足一条即可。\n\n满足条件 1 和 条件 2.1 的一个例子:\n\n``select t1.a from t1 left join t2 on t1.b = t2.b;``\n\n可以被改写成:\n\n``select t1.a from t1;``\n\n## TiDB 中常见的物理优化\n\n物理优化是基于代价的优化,这一阶段中,优化器会为逻辑执行计划中的每个算子选择具体的物理实现,以将逻辑优化阶段产生的逻辑执行计划转换成物理执行计划。逻辑算子的不同物理实现有着不同的时间复杂度、资源消耗和物理属性等。在这个过程中,优化器会根据数据的统计信息来估算不同物理实现的代价,并选择整体代价最小的物理执行计划。\n\n物理优化需要做的决策有很多,例如:\n\n- 读取数据的方式:使用索引扫描或全表扫描读取数据。\n- 如果存在多个索引,索引之间的选择。\n- 逻辑算子的物理实现,即实际使用的算法。\n- 是否可以将算子下推到存储层执行,以提升执行效率。\n\n## TiDB 统计信息\n\n统计信息对于查询优化器来说是至关重要的输入信息,优化器将会利用统计信息来估算查询谓词的选择率,查询的各类基数,以及不同算子的代价,并利用这些估算来进行部分逻辑优化以及物理优化。如果统计信息存因为过时或缺失造成较大失真偏差,往往会对优化器的优化造成非常大的影响,从而影响到生成的查询计划。所以在此,我们会用较大篇幅介绍统计信息,以及相关的收集与维护,因为这是优化器在做查询优化的基石。\n\nTiDB 收集的统计信息包括了表级别和列级别的信息,表的统计信息包括总行数和修改的行数。列的统计信息包括不同值的数量、NULL 的数量、直方图、列上出现次数最多的值 TOPN 等信息。\n\nTiDB 的统计信息收集包括了手动收集和自动更新两种方式:\n\n- 手动收集:\n\n通过执行``ANALYZE`` 语句来收集统计信息。以数据库中 person 表为例,使用 analyze 的试行语句如下:\n\n```sql \nanalyze table person;\n```\n\n收集统计信息过程中,可以通过``show analyze status`` 语句查询执行状态,该语句也可以通过``where`` 子句对输出结果进行过滤,显示输出结果如下:\n\n```sql \nmysql> show analyze status where job_info = 'analyze columns';\n+--------------+------------+-----------------+---------------------+----------+\n| Table_schema | Table_name | Job_info | Start_time | State |\n+--------------+------------+-----------------+---------------------+----------+\n| test | person | analyze columns | 2020-03-07 06:22:34 | finished |\n| test | customer | analyze columns | 2020-03-07 06:32:19 | finished |\n| test | person | analyze columns | 2020-03-07 06:35:27 | finished |\n+--------------+------------+-----------------+---------------------+----------+\n3 rows in set (0.01 sec)\n```\n\n- 自动更新:\n\n在执行 DML 语句时,TiDB 会自动更新表的总行数以及修改的行数。这些信息会定期自动持久化,更新周期默认是 1 分钟(20 * stats-lease)\n\n注意:stats-lease 的默认值是 3s,如果将其设定为 0,则关闭统计信息自动更新。\n\n目前根据统计信息收集和使用的演进,TiDB 目前支持两个版本的统计信息,其中 Version 2 在 Version 1 的基础上做了更多的优化来改善统计信息的维护方式和精度,以及收集效率。具体的差异可以参考 [TiDB 统计信息简介文档](https://docs.pingcap.com/zh/tidb/dev/statistics)。\n\n在统计信息收集之后,可以查看统计信息以及表的健康度来确认统计信息是否有较大失真。\n\n查看表的统计信息 meta 信息:\n\n```sql \nmysql> show stats_meta where table_name = 'person';\n+---------+------------+----------------+---------------------+--------------+-----------+\n| Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count |\n+---------+------------+----------------+---------------------+--------------+-----------+\n| test | person | | 2020-03-07 07:20:54 | 0 | 4 |\n+---------+------------+----------------+---------------------+--------------+-----------+\n1 row in set (0.01 sec)\n```\n\n查看表的健康度信息:\n\n```sql \nmysql> show stats_healthy where table_name = 'person';\n+---------+------------+----------------+---------+\n| Db_name | Table_name | Partition_name | Healthy |\n+---------+------------+----------------+---------+\n| test | person | | 100 |\n+---------+------------+----------------+---------+\n1 row in set (0.00 sec)\n```\n\n可通过``SHOW STATS_HISTOGRAMS`` 来查看列的不同值数量以及 NULL 值数量等信息:\n\n```sql \nmysql> show stats_histograms where table_name = 'person';\n+---------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+\n| Db_name | Table_name | Partition_name | Column_name | Is_index | Update_time | Distinct_count | Null_count | Avg_col_size | Correlation |\n+---------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+\n| test | person | | name | 0 | 2020-03-07 07:20:54 | 4 | 0 | 6.25 | -0.2 |\n+---------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+\n1 row in set (0.00 sec)\n```\n\n可通过``SHOW STATS_BUCKETS`` 来查看直方图每个桶的信息:\n\n```sql \nmysql> show stats_buckets;\n+---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+\n| Db_name | Table_name | Partition_name | Column_name | Is_index | Bucket_id | Count | Repeats | Lower_Bound | Upper_Bound |\n+---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+\n| test | person | | name | 0 | 0 | 1 | 1 | jack | jack |\n| test | person | | name | 0 | 1 | 2 | 1 | peter | peter |\n| test | person | | name | 0 | 2 | 3 | 1 | smith | smith |\n| test | person | | name | 0 | 3 | 4 | 1 | tom | tom |\n+---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+\n4 rows in set (0.01 sec)\n```\n\n可通过执行``DROP STATS`` 语句来删除统计信息。语句如下:\n\n```sql \nmysql> DROP STATS person;\n```\n\nTiDB 的统计信息可以导入导出,方便备份以及值班人员复现定位相关问题。\n\n- 导出:通过以下接口可以获取数据库 ${db_name} 中的表${table_name}的 json 格式的统计信息:\n\n```sql \nhttp://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}\n```\n\n示例:获取本机上 test 数据库中 person 表的统计信息:\n\n```sql\ncurl -G \"http://127.0.0.1:10080/stats/dump/test/person\" > person.json\n```\n\n- 导入:将统计信息导出接口得到的 json 文件导入数据库中:\n\n```\nmysql> LOAD STATS 'file_name';\n```\nfile_name 为被导入的统计信息文件名。\n\n本文为「TiDB 查询优化及调优」系列文章的第一篇,后续将继续对 TiDB 查询计划、慢查询诊断监控及排查、调整及优化查询执行计划以及其他优化器开发或规划中的诊断调优功能等进行介绍。如果您对 TiDB 的产品有任何建议,欢迎来到 与我们交流。\n\n> 点击查看更多 [TiDB 查询优化及调优](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98)文章","author":"Yu Dong","category":1,"customUrl":"tidb-query-optimization-and-tuning-1","fillInMethod":"writeDirectly","id":374,"summary":"与其它主流商业数据库一样,TiDB 的查询优化器负责用户及系统查询的优化,生成有效且高效的执行计划由执行器来执行。而优化器生成的执行计划的优劣直接影响查询的执行效率和性能。本文将简要介绍 TiDB 查询优化器的优化流程。","tags":["TiDB","TiDB 性能调优"],"title":"TiDB 查询优化及调优系列(一)TiDB 优化器简介"}},{"relatedBlog":{"body":"「TiDB 查询优化及调优」系列文章将通过一些具体的案例,向大家介绍 TiDB 查询及优化相关的原理和应用,在[上一篇文章](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-1)中我们简要介绍了 TiDB 查询优化器的优化流程。\n\n查询计划(execution plan)展现了数据库执行 SQL 语句的具体步骤,例如通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。查阅及理解 TiDB 的查询计划是查询调优的基础。本文为系列文章的第二篇,将着重介绍 TiDB 查询计划以及如何查看。\n\n\n\n## 算子及 Task\n\n在上文的 TiDB 查询优化流程简介中有提到过,TiDB 的查询计划是由一系列的执行算子构成,这些算子是为返回查询结果而执行的特定步骤,例如表扫描算子,聚合算子,Join 算子等,下面以表扫描算子为例,其它算子的具体解释可以参看下文查看执行计划的小结。\n\n执行表扫描(读盘或者读 TiKV Block Cache)操作的算子有如下几类:\n- TableFullScan:全表扫描。\n- TableRangeScan:带有范围的表数据扫描。\n- TableRowIDScan:根据上层传递下来的 RowID 扫描表数据。时常在索引读操作后检索符合条件的行。\n- IndexFullScan:另一种“全表扫描”,扫的是索引数据,不是表数据。\n\n目前 TiDB 的计算任务分为两种不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 执行的计算任务,root task 是指在 TiDB 中执行的计算任务。\n\nSQL 优化的目标之一是将计算尽可能地下推到 TiKV 中执行。TiKV 中的 Coprocessor 能支持大部分 SQL 内建函数(包括聚合函数和标量函数)、SQL `LIMIT` 操作、索引扫描和表扫描。但是,所有的 Join 操作都只能作为 root task 在 TiDB 上执行。\n\n## 利用 EXPLAIN 查看分析查询计划\n\n与其它主流商业数据库一样,TiDB 中可以通过 EXPLAIN 语句返回的结果查看某条 SQL 的执行计划。\n\n### EXPLAIN 语句\n\n目前 TiDB 的 EXPLAIN 主要输出 5 列,分别是:``id``,``estRows``,``task``,``access object``, ``operator info``。执行计划中每个算子都由这 5 列属性来描述,``EXPLAIN``结果中每一行描述一个算子。每个属性的具体含义如下:\n\n\n\n### EXPLAIN ANALYZE 语句\n\n和 ``EXPLAIN`` 不同,``EXPLAIN ANALYZE`` 会执行对应的 SQL 语句,记录其运行时信息,和执行计划一并返回出来,可以视为 ``EXPLAIN`` 语句的扩展。``EXPLAIN ANALYZE`` 语句的返回结果中增加了 ``actRows``, ``execution info``, ``memory``, ``disk`` 这几列信息:\n\n\n\n例如在下例中,优化器估算的 ``estRows`` 和实际执行中统计得到的 ``actRows`` 几乎是相等的,说明优化器估算的行数与实际行数的误差很小。同时`` IndexLookUp_10`` 算子在实际执行过程中使用了约 9 KB 的内存,该 SQL 在执行过程中,没有触发过任何算子的落盘操作。\n\n```sql\nmysql> explain analyze select * from t where a < 10;\n+-------------------------------+---------+---------+-----------+-------------------------+------------------------------------------------------------------------+-----------------------------------------------------+---------------+------+\n| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |\n+-------------------------------+---------+---------+-----------+-------------------------+------------------------------------------------------------------------+-----------------------------------------------------+---------------+------+\n| IndexLookUp_10 | 9.00 | 9 | root | | time:641.245µs, loops:2, rpc num: 1, rpc time:242.648µs, proc keys:0 | | 9.23046875 KB | N/A |\n| ├─IndexRangeScan_8(Build) | 9.00 | 9 | cop[tikv] | table:t, index:idx_a(a) | time:142.94µs, loops:10, | range:[-inf,10), keep order:false | N/A | N/A |\n| └─TableRowIDScan_9(Probe) | 9.00 | 9 | cop[tikv] | table:t | time:141.128µs, loops:10 | keep order:false | N/A | N/A |\n+-------------------------------+---------+---------+-----------+-------------------------+------------------------------------------------------------------------+-----------------------------------------------------+---------------+------+\n3 rows in set (0.00 sec)\n```\n\n### 查看计划中算子的执行顺序\n\nTiDB 的执行计划是一个树形结构,树中每个节点即是算子。考虑到每个算子内多线程并发执行的情况,在一条 SQL 执行的过程中,如果能够有一个手术刀把这棵树切开看看,大家可能会发现所有的算子都正在消耗 CPU 和内存处理数据,从这个角度来看,算子是没有执行顺序的。\n\n但是如果从一行数据先后被哪些算子处理的角度来看,一条数据在算子上的执行是有顺序的。这个顺序可以通过下面这个规则简单总结出来:\n\n**``Build``总是先于 ``Probe`` 执行,并且 ``Build`` 总是出现 ``Probe`` 前面**\n\n这个原则的前半句是说:如果一个算子有多个子节点,子节点 ID 后面有 ``Build`` 关键字的算子总是先于有 ``Probe`` 关键字的算子执行。后半句是说:TiDB 在展现执行计划的时候,``Build`` 端总是第一个出现,接着才是 ``Probe`` 端。例如:\n\n```sql\nTiDB(root@127.0.0.1:test) > explain select * from t use index(idx_a) where a = 1;\n+-------------------------------+---------+-----------+-------------------------+---------------------------------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------------+---------+-----------+-------------------------+---------------------------------------------+\n| IndexLookUp_7 | 10.00 | root | | |\n| ├─IndexRangeScan_5(Build) | 10.00 | cop[tikv] | table:t, index:idx_a(a) | range:[1,1], keep order:false, stats:pseudo |\n| └─TableRowIDScan_6(Probe) | 10.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+-------------------------------+---------+-----------+-------------------------+---------------------------------------------+\n3 rows in set (0.00 sec)\n```\n\n这里 ``IndexLookUp_7`` 算子有两个孩子节点:``IndexRangeScan_5(Build)`` 和 ``TableRowIDScan_6(Probe)``。可以看到,``IndexRangeScan_5(Build)`` 是第一个出现的,并且基于上面这条规则,要得到一条数据,需要先执行它得到一个 ``RowID`` 以后,再由 ``TableRowIDScan_6(Probe)`` 根据前者读上来的 ``RowID`` 去获取完整的一行数据。\n\n这种规则隐含的另一个信息是:**在同一层级的节点中,出现在最前面的算子可能是最先被执行的,而出现在最末尾的算子可能是最后被执行的。** \n\n例如下面这个例子:\n```sql\nTiDB(root@127.0.0.1:test) > explain select * from t t1 use index(idx_a) join t t2 use index() where t1.a = t2.a;\n+----------------------------------+----------+-----------+--------------------------+------------------------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+----------------------------------+----------+-----------+--------------------------+------------------------------------------------------------------+\n| HashJoin_22 | 12487.50 | root | | inner join, inner:TableReader_26, equal:[eq(test.t.a, test.t.a)] |\n| ├─TableReader_26(Build) | 9990.00 | root | | data:Selection_25 |\n| │ └─Selection_25 | 9990.00 | cop[tikv] | | not(isnull(test.t.a)) |\n| │ └─TableFullScan_24 | 10000.00 | cop[tikv] | table:t2 | keep order:false, stats:pseudo |\n| └─IndexLookUp_29(Probe) | 9990.00 | root | | |\n| ├─IndexFullScan_27(Build) | 9990.00 | cop[tikv] | table:t1, index:idx_a(a) | keep order:false, stats:pseudo |\n| └─TableRowIDScan_28(Probe) | 9990.00 | cop[tikv] | table:t1 | keep order:false, stats:pseudo |\n+----------------------------------+----------+-----------+--------------------------+------------------------------------------------------------------+\n7 rows in set (0.00 sec)\n```\n\n要完成 ``HashJoin_22``,需要先执行 ``TableReader_26(Build)`` 再执行 ``IndexLookUp_29(Probe)``。而在执行 ``IndexLookUp_29(Probe)`` 的时候,又需要先执行 ``IndexFullScan_27(Build)`` 再执行 ``TableRowIDScan_28(Probe)``。所以从整条执行链路来看,``TableRowIDScan_28(Probe)`` 是最后被唤起执行的。\n\n### 查看表扫描的执行计划\n\n在上文介绍算子和任务时已经提到过表扫描算子,这里再稍微重复介绍一下,分为执行表扫描操作的算子和对扫描数据进行汇聚和计算的算子:\n\n执行表扫描(读盘或者读 TiKV Block Cache)操作的算子有如下几类:\n- TableFullScan:全表扫描。\n- TableRangeScan:带有范围的表数据扫描。\n- TableRowIDScan:根据上层传递下来的 RowID 扫描表数据。时常在索引读操作后检索符合条件的行。\n- IndexFullScan:另一种“全表扫描”,扫的是索引数据,不是表数据。\n- IndexRangeScan:带有范围的索引数据扫描操作。\n\nTiDB 会汇聚 TiKV/TiFlash 上扫描的数据或者计算结果,这种“数据汇聚”算子目前有如下几类:\n- TableReader:将 TiKV 上底层扫表算子 TableFullScan 或 TableRangeScan 得到的数据进行汇总。\n- IndexReader:将 TiKV 上底层扫表算子 IndexFullScan 或 IndexRangeScan 得到的数据进行汇总。\n- IndexLookUp:先汇总 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些 `RowID` 精确地读取 TiKV 上的数据。Build 端是 `IndexFullScan` 或 `IndexRangeScan` 类型的算子,Probe 端是 `TableRowIDScan` 类型的算子。\n- IndexMerge:和 `IndexLookupReader` 类似,可以看做是它的扩展,可以同时读取多个索引的数据,有多个 Build 端,一个 Probe 端。执行过程也很类似,先汇总所有 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些 RowID 精确地读取 TiKV 上的数据。Build 端是 `IndexFullScan` 或 `IndexRangeScan` 类型的算子,Probe 端是 `TableRowIDScan` 类型的算子。\n\nIndexLookUp 示例:\n```sql\nmysql> explain select * from t use index(idx_a);\n+-------------------------------+----------+-----------+-------------------------+--------------------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------------+----------+-----------+-------------------------+--------------------------------+\n| IndexLookUp_6 | 10000.00 | root | | |\n| ├─IndexFullScan_4(Build) | 10000.00 | cop[tikv] | table:t, index:idx_a(a) | keep order:false, stats:pseudo |\n| └─TableRowIDScan_5(Probe) | 10000.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+-------------------------------+----------+-----------+-------------------------+--------------------------------+\n3 rows in set (0.00 sec)\n```\n\n这里 ``IndexLookUp_6`` 算子有两个孩子节点:``IndexFullScan_4(Build)`` 和 ``TableRowIDScan_5(Probe)``。可以看到,``IndexFullScan_4(Build)`` 执行索引全表扫,扫描索引 ``a`` 的所有数据,因为是全范围扫,这个操作将获得表中所有数据的 ``RowID``,之后再由 ``TableRowIDScan_5(Probe)`` 去根据这些 ``RowID`` 去扫描所有的表数据。可以预见的是,这个执行计划不如直接使用 TableReader 进行全表扫,因为同样都是全表扫,这里的 ``IndexLookUp`` 多扫了一次索引,带来了额外的开销。\n\nTableReader 示例:\n```sql\nmysql> explain select * from t where a > 1 or b >100;\n+-------------------------+----------+-----------+---------------+----------------------------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------+----------+-----------+---------------+----------------------------------------+\n| TableReader_7 | 8000.00 | root | | data:Selection_6 |\n| └─Selection_6 | 8000.00 | cop[tikv] | | or(gt(test.t.a, 1), gt(test.t.b, 100)) |\n| └─TableFullScan_5 | 10000.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+-------------------------+----------+-----------+---------------+----------------------------------------+\n3 rows in set (0.00 sec)\n```\n\n在上面例子中 ``TableReader_7`` 算子的孩子节点是 Selection_6。以这个孩子节点为根的子树被当做了一个 ``Cop Task`` 下发给了相应的 TiKV,这个 ``Cop Task`` 使用 ``TableFullScan_5`` 算子执行扫表操作。Selection 表示 SQL 语句中的选择条件,可能来自 SQL 语句中的 ``WHERE``/``HAVING``/``ON`` 子句。由 ``TableFullScan_5`` 可以看到,这个执行计划使用了一个全表扫描的操作,集群的负载将因此而上升,可能会影响到集群中正在运行的其他查询。这时候如果能够建立合适的索引,并且使用 ``IndexMerge`` 算子,将能够极大的提升查询的性能,降低集群的负载。\n\nIndexMerge 示例:\n\n注意:目前 TIDB 的 ``Index Merge`` 为实验特性在 5.3 及以前版本中默认关闭,同时 5.0 中的 ``Index Merge`` 目前支持的场景仅限于析取范式(or 连接的表达式),对合取范式(and 连接的表达式)将在之后的版本中支持。 开启 ``Index Merge`` 特性,可通过在客户端中设置 session 或者 global 变量完成:``set @@tidb_enable_index_merge = 1;``\n\n```sql\nmysql> set @@tidb_enable_index_merge = 1;\nmysql> explain select * from t use index(idx_a, idx_b) where a > 1 or b > 1;\n+------------------------------+---------+-----------+-------------------------+------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+------------------------------+---------+-----------+-------------------------+------------------------------------------------+\n| IndexMerge_16 | 6666.67 | root | | |\n| ├─IndexRangeScan_13(Build) | 3333.33 | cop[tikv] | table:t, index:idx_a(a) | range:(1,+inf], keep order:false, stats:pseudo |\n| ├─IndexRangeScan_14(Build) | 3333.33 | cop[tikv] | table:t, index:idx_b(b) | range:(1,+inf], keep order:false, stats:pseudo |\n| └─TableRowIDScan_15(Probe) | 6666.67 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+------------------------------+---------+-----------+-------------------------+------------------------------------------------+\n4 rows in set (0.00 sec)\n```\n\n``IndexMerge`` 使得数据库在扫描表数据时可以使用多个索引。这里 ``IndexMerge_16`` 算子有三个孩子节点,其中 ``IndexRangeScan_13`` 和 ``IndexRangeScan_14`` 根据范围扫描得到符合条件的所有 ``RowID``,再由 ``TableRowIDScan_15`` 算子根据这些 ``RowID`` 精确的读取所有满足条件的数据。\n\n### 查看聚合计算的执行计划\n\nHash Aggregate 示例:\n\nTiDB 上的 Hash Aggregation 算子采用多线程并发优化,执行速度快,但会消耗较多内存。下面是一个 Hash Aggregate 的例子:\n\n```sql\nTiDB(root@127.0.0.1:test) > explain select /*+ HASH_AGG() */ count(*) from t;\n+---------------------------+----------+-----------+---------------+---------------------------------+\n| id | estRows | task | access object | operator info |\n+---------------------------+----------+-----------+---------------+---------------------------------+\n| HashAgg_11 | 1.00 | root | | funcs:count(Column#7)->Column#4 |\n| └─TableReader_12 | 1.00 | root | | data:HashAgg_5 |\n| └─HashAgg_5 | 1.00 | cop[tikv] | | funcs:count(1)->Column#7 |\n| └─TableFullScan_8 | 10000.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+---------------------------+----------+-----------+---------------+---------------------------------+\n4 rows in set (0.00 sec)\n```\n\n一般而言 TiDB 的 ``Hash Aggregate`` 会分成两个阶段执行,一个在 TiKV/TiFlash 的 ``Coprocessor`` 上,计算聚合函数的中间结果。另一个在 TiDB 层,汇总所有 ``Coprocessor Task`` 的中间结果后,得到最终结果。\n \nStream Aggregate 示例:\n\nTiDB ``Stream Aggregation`` 算子通常会比 ``Hash Aggregate`` 占用更少的内存,有些场景中也会比 ``Hash Aggregate`` 执行的更快。当数据量太大或者系统内存不足时,可以试试 ``Stream Aggregate`` 算子。一个 ``Stream Aggregate`` 的例子如下:\n```sql\nTiDB(root@127.0.0.1:test) > explain select /*+ STREAM_AGG() */ count(*) from t;\n+----------------------------+----------+-----------+---------------+---------------------------------+\n| id | estRows | task | access object | operator info |\n+----------------------------+----------+-----------+---------------+---------------------------------+\n| StreamAgg_16 | 1.00 | root | | funcs:count(Column#7)->Column#4 |\n| └─TableReader_17 | 1.00 | root | | data:StreamAgg_8 |\n| └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:count(1)->Column#7 |\n| └─TableFullScan_13 | 10000.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |\n+----------------------------+----------+-----------+---------------+---------------------------------+\n4 rows in set (0.00 sec)\n```\n和 ``Hash Aggregate`` 类似,一般而言 TiDB 的 ``Stream Aggregate`` 也会分成两个阶段执行,一个在 TiKV/TiFlash 的 ``Coprocessor`` 上,计算聚合函数的中间结果。另一个在 TiDB 层,汇总所有 ``Coprocessor Task`` 的中间结果后,得到最终结果。\n\n### 查看 Join 的执行计划\n\nTiDB 的 Join 算法包括如下几类:\n- Hash Join\n- Merge Join\n- Index Hash Join\n- Index Merge Join\n\nApply\n\n下面分别通过一些例子来解释这些 Join 算法的执行过程\n\nHash Join 示例:\n\nTiDB 的 Hash Join 算子采用了多线程优化,执行速度较快,但会消耗较多内存。一个 Hash Join 的例子如下:\n\n```sql\nmysql> explain select /*+ HASH_JOIN(t1, t2) */ * from t t1 join t2 on t1.a = t2.a;\n+------------------------------+----------+-----------+---------------+-------------------------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+------------------------------+----------+-----------+---------------+-------------------------------------------------------------------+\n| HashJoin_33 | 10000.00 | root | | inner join, inner:TableReader_43, equal:[eq(test.t.a, test.t2.a)] |\n| ├─TableReader_43(Build) | 10000.00 | root | | data:Selection_42 |\n| │ └─Selection_42 | 10000.00 | cop[tikv] | | not(isnull(test.t2.a)) |\n| │ └─TableFullScan_41 | 10000.00 | cop[tikv] | table:t2 | keep order:false |\n| └─TableReader_37(Probe) | 10000.00 | root | | data:Selection_36 |\n| └─Selection_36 | 10000.00 | cop[tikv] | | not(isnull(test.t.a)) |\n| └─TableFullScan_35 | 10000.00 | cop[tikv] | table:t1 | keep order:false |\n+------------------------------+----------+-----------+---------------+-------------------------------------------------------------------+\n7 rows in set (0.00 sec)\n```\n\n``Hash Join`` 会将 ``Build`` 端的数据缓存在内存中,根据这些数据构造出一个 ``Hash Table``,然后读取 ``Probe`` 端的数据,用 ``Probe`` 端的数据去探测``(Probe)Build`` 端构造出来的 ``Hash Table``,将符合条件的数据返回给用户。\n\n``Merge Join`` 示例:\nTiDB 的 ``Merge Join`` 算子相比于 ``Hash Join`` 通常会占用更少的内存,但可能执行时间会更久。当数据量太大,或系统内存不足时,建议尝试使用。下面是一个 ``Merge Join`` 的例子:\n```sql\nmysql> explain select /*+ SM_JOIN(t1) */ * from t t1 join t t2 on t1.a = t2.a;\n+------------------------------------+----------+-----------+--------------------------+---------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+------------------------------------+----------+-----------+--------------------------+---------------------------------------------------+\n| MergeJoin_6 | 10000.00 | root | | inner join, left key:test.t.a, right key:test.t.a |\n| ├─IndexLookUp_13(Build) | 10000.00 | root | | |\n| │ ├─IndexFullScan_11(Build) | 10000.00 | cop[tikv] | table:t2, index:idx_a(a) | keep order:true |\n| │ └─TableRowIDScan_12(Probe) | 10000.00 | cop[tikv] | table:t2 | keep order:false |\n| └─IndexLookUp_10(Probe) | 10000.00 | root | | |\n| ├─IndexFullScan_8(Build) | 10000.00 | cop[tikv] | table:t1, index:idx_a(a) | keep order:true |\n| └─TableRowIDScan_9(Probe) | 10000.00 | cop[tikv] | table:t1 | keep order:false |\n+------------------------------------+----------+-----------+--------------------------+---------------------------------------------------+\n7 rows in set (0.00 sec)\n```\n\n``Merge Join`` 算子在执行时,会从 ``Build`` 端把一个 ``Join Group`` 的数据全部读取到内存中,接着再去读 ``Probe`` 端的数据,用 ``Probe`` 端的每行数据去和 ``Build`` 端的完整的一个 ``Join Group`` 依次去看是否匹配(除了满足等值条件以外,还有其他非等值条件,这里的 “匹配” 主要是指查看是否满足非等值职条件)。``Join Group`` 指的是所有 ``Join Key`` 上值相同的数据。\n\nIndex Hash Join 示例:\n\n``INL_HASH_JOIN(t1_name [, tl_name])`` 提示优化器使用 ``Index Nested Loop Hash Join`` 算法。该算法与 ``Index Nested Loop Join`` 使用条件完全一样,但在某些场景下会更为节省内存资源。\n\n```sql\nmysql> explain select /*+ INL_HASH_JOIN(t1) */ * from t t1 join t t2 on t1.a = t2.a;\n+----------------------------------+----------+-----------+--------------------------+--------------------------------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+----------------------------------+----------+-----------+--------------------------+--------------------------------------------------------------------------+\n| IndexHashJoin_32 | 10000.00 | root | | inner join, inner:IndexLookUp_23, outer key:test.t.a, inner key:test.t.a |\n| ├─TableReader_35(Build) | 10000.00 | root | | data:Selection_34 |\n| │ └─Selection_34 | 10000.00 | cop[tikv] | | not(isnull(test.t.a)) |\n| │ └─TableFullScan_33 | 10000.00 | cop[tikv] | table:t2 | keep order:false |\n| └─IndexLookUp_23(Probe) | 1.00 | root | | |\n| ├─Selection_22(Build) | 1.00 | cop[tikv] | | not(isnull(test.t.a)) |\n| │ └─IndexRangeScan_20 | 1.00 | cop[tikv] | table:t1, index:idx_a(a) | range: decided by [eq(test.t.a, test.t.a)], keep order:false |\n| └─TableRowIDScan_21(Probe) | 1.00 | cop[tikv] | table:t1 | keep order:false |\n+----------------------------------+----------+-----------+--------------------------+--------------------------------------------------------------------------+\n8 rows in set (0.00 sec)\n```\n\nIndex Merge Join 示例:\n``INL_MERGE_JOIN(t1_name [, tl_name])`` 提示优化器使用 ``Index Nested Loop Merge Join`` 算法。该算法相比于 ``INL_JOIN`` 会更节省内存。该算法使用条件包含 ``INL_JOIN`` 的所有使用条件,但还需要添加一条:``join keys`` 中的内表列集合是内表使用的 ``index`` 的前缀,或内表使用的 ``index`` 是 ``join keys`` 中的内表列集合的前缀。\n\n```sql\nmysql> explain select /*+ INL_MERGE_JOIN(t2@sel_2) */ * from t t1 where t1.a in ( select t2.a from t t2 where t2.b < t1.b);\n+---------------------------------+---------+-----------+--------------------------+-----------------------------------------------------------------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+---------------------------------+---------+-----------+--------------------------+-----------------------------------------------------------------------------------------------------------+\n| IndexMergeJoin_23 | 6.39 | root | | semi join, inner:Projection_21, outer key:test.t.a, inner key:test.t.a, other cond:lt(test.t.b, test.t.b) |\n| ├─TableReader_28(Build) | 7.98 | root | | data:Selection_27 |\n| │ └─Selection_27 | 7.98 | cop[tikv] | | not(isnull(test.t.a)), not(isnull(test.t.b)) |\n| │ └─TableFullScan_26 | 8.00 | cop[tikv] | table:t1 | keep order:false, stats:pseudo |\n| └─Projection_21(Probe) | 1.25 | root | | test.t.a, test.t.b |\n| └─IndexLookUp_20 | 1.25 | root | | |\n| ├─Selection_18(Build) | 1.25 | cop[tikv] | | not(isnull(test.t.a)) |\n| │ └─IndexRangeScan_16 | 1.25 | cop[tikv] | table:t2, index:idx_a(a) | range: decided by [eq(test.t.a, test.t.a)], keep order:true, stats:pseudo |\n| └─Selection_19(Probe) | 1.25 | cop[tikv] | | not(isnull(test.t.b)) |\n| └─TableRowIDScan_17 | 1.25 | cop[tikv] | table:t2 | keep order:false, stats:pseudo |\n+---------------------------------+---------+-----------+--------------------------+-----------------------------------------------------------------------------------------------------------+\n10 rows in set (0.01 sec)\n```sql\n\nApply 示例:\n\n```sql\nmysql> explain select * from t t1 where t1.a in ( select avg(t2.a) from t2 where t2.b < t1.b);\n+----------------------------------+----------+-----------+---------------+-------------------------------------------------------------------------------+\n| id | estRows | task | access object | operator info |\n+----------------------------------+----------+-----------+---------------+-------------------------------------------------------------------------------+\n| Projection_10 | 10000.00 | root | | test.t.id, test.t.a, test.t.b |\n| └─Apply_12 | 10000.00 | root | | semi join, inner:StreamAgg_30, equal:[eq(Column#8, Column#7)] |\n| ├─Projection_13(Build) | 10000.00 | root | | test.t.id, test.t.a, test.t.b, cast(test.t.a, decimal(20,0) BINARY)->Column#8 |\n| │ └─TableReader_15 | 10000.00 | root | | data:TableFullScan_14 |\n| │ └─TableFullScan_14 | 10000.00 | cop[tikv] | table:t1 | keep order:false |\n| └─StreamAgg_30(Probe) | 1.00 | root | | funcs:avg(Column#12, Column#13)->Column#7 |\n| └─TableReader_31 | 1.00 | root | | data:StreamAgg_19 |\n| └─StreamAgg_19 | 1.00 | cop[tikv] | | funcs:count(test.t2.a)->Column#12, funcs:sum(test.t2.a)->Column#13 |\n| └─Selection_29 | 8000.00 | cop[tikv] | | lt(test.t2.b, test.t.b) |\n| └─TableFullScan_28 | 10000.00 | cop[tikv] | table:t2 | keep order:false |\n+----------------------------------+----------+-----------+-----------------------------------------------------------------------------------------------+\n10 rows in set, 1 warning (0.00 sec)\n```\n\n### 其它关于 EXPLAIN 的说明\n\n``EXPLAIN FOR CONNECTION`` 用于获得一个连接中最后执行的查询的执行计划,其输出格式与 ``EXPLAIN`` 完全一致。但 TiDB 中的实现与 MySQL 不同,除了输出格式之外,还有以下区别:\n\nMySQL 返回的是正在执行的查询计划,而 TiDB 返回的是最后执行的查询计划。\n\nMySQL 的文档中指出,MySQL 要求登录用户与被查询的连接相同,或者拥有 ``PROCESS`` 权限,而 TiDB 则要求登录用户与被查询的连接相同,或者拥有 ``SUPER`` 权限。 \n\n本文为「TiDB 查询优化及调优」系列文章的第二篇,后续将继续对 TiDB 慢查询诊断监控及排查、调整及优化查询执行计划以及其他优化器开发或规划中的诊断调优功能等进行介绍。如果您对 TiDB 的产品有任何建议,欢迎来到 与我们交流。\n\n> 点击查看更多 [TiDB 查询优化及调优](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98)文章","author":"Yu Dong","category":1,"customUrl":"tidb-query-optimization-and-tuning-2","fillInMethod":"writeDirectly","id":378,"summary":"查询计划(execution plan)展现了数据库执行 SQL 语句的具体步骤,例如通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。查阅及理解 TiDB 的查询计划是查询调优的基础。本文为系列文章的第二篇,将着重介绍 TiDB 查询计划以及如何查看。","tags":["TiDB","TiDB 性能调优"],"title":"TiDB 查询优化及调优系列(二)TiDB 查询计划简介"}},{"relatedBlog":{"body":"本章节介绍如何利用 TiDB 提供的系统监控诊断工具,对运行负载中的查询进行排查和诊断。除了[上一章节介绍的通过 EXPLAIN 语句来查看诊断查询计划问题](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-2)外,本章节主要会介绍通过 TiDB Slow Query 慢查询内存表,以及 TiDB Dashboard 的可视化 Statements 功能来监控和诊断慢查询。\n\n\n\n## Slow Query 慢查询内存表\n\nTiDB 默认会启用慢查询日志,并将执行时间超过规定阈值的 SQL 保存到日志文件。慢查询日志常用于定位慢查询语句,分析和解决 SQL 的性能问题。通过系统表``information_schema.slow_query`` 也可以查看当前 TiDB 节点的慢查询日志,其字段与慢查询日志文件内容一致。TiDB 从 4.0 版本开始又新增了系统表 ``information_schema.cluster_slow_query``,可以用于查看全部 TiDB 节点的慢查询。\n\n本节将首先简要介绍慢查询日志的格式和字段含义,然后针对上述两种慢查询系统表给出一些常见的查询示例。\n\n### 慢查询日志示例及字段说明\n\n下面是一段典型的慢查询日志:\n\n```\n# Time: 2019-08-14T09:26:59.487776265+08:00\n# Txn_start_ts: 410450924122144769\n# User: root@127.0.0.1\n# Conn_ID: 3086\n# Query_time: 1.527627037\n# Parse_time: 0.000054933\n# Compile_time: 0.000129729\n# Process_time: 0.07 Wait_time: 0.002 Backoff_time: 0.002 Request_count: 1 Total_keys: 131073 Process_keys: 131072 Prewrite_time: 0.335415029 Commit_time: 0.032175429 Get_commit_ts_time: 0.000177098 Local_latch_wait_time: 0.106869448 Write_keys: 131072 Write_size: 3538944 Prewrite_region: 1\n# DB: test\n# Is_internal: false\n# Digest: 50a2e32d2abbd6c1764b1b7f2058d428ef2712b029282b776beb9506a365c0f1\n# Stats: t:414652072816803841\n# Num_cop_tasks: 1\n# Cop_proc_avg: 0.07 Cop_proc_p90: 0.07 Cop_proc_max: 0.07 Cop_proc_addr: 172.16.5.87:20171\n# Cop_wait_avg: 0 Cop_wait_p90: 0 Cop_wait_max: 0 Cop_wait_addr: 172.16.5.87:20171\n# Mem_max: 525211\n# Succ: true\n# Plan_digest: e5f9d9746c756438a13c75ba3eedf601eecf555cdb7ad327d7092bdd041a83e7\n# Plan: tidb_decode_plan('ZJAwCTMyXzcJMAkyMAlkYXRhOlRhYmxlU2Nhbl82CjEJMTBfNgkxAR0AdAEY1Dp0LCByYW5nZTpbLWluZiwraW5mXSwga2VlcCBvcmRlcjpmYWxzZSwgc3RhdHM6cHNldWRvCg==')\ninsert into t select * from t;\n```\n\n以下逐一介绍慢查询日志中各个字段的含义。\n\n注意:慢查询日志中所有时间相关字段的单位都是秒。\n\n**(1) 慢查询基础信息:**\n\n- `Time`:表示日志打印时间。\n\n- `Query_time`:表示执行该语句花费的时间。\n\n- `Parse_time`:表示该语句在语法解析阶段花费的时间。\n\n- `Compile_time`:表示该语句在查询优化阶段花费的时间。\n\n- `Digest`:表示该语句的 SQL 指纹。\n\n- `Stats`:表示 table 使用的统计信息版本时间戳。如果时间戳显示为 `pseudo`,表示用默认假设的统计信息。\n\n- `Txn_start_ts`:表示事务的开始时间戳,也就是事务的唯一 ID,可以用该值在 TiDB 日志中查找事务相关的其他日志。\n\n- `Is_internal`:表示是否为 TiDB 内部的 SQL 语句。`true` 表示是 TiDB 系统内部执行的 SQL 语句,``false`` 表示是由用户执行的 SQL 语句。\n\n- `Index_ids`:表示该语句使用的索引 ID。\n\n- `Succ`:表示该语句是否执行成功。\n\n- `Backoff_time`:表示遇到需要重试的错误时该语句在重试前等待的时间。常见的需要重试的错误有以下几种:遇到了 lock、Region 分裂、tikv server is busy。\n\n- `Plan_digest`:表示 plan 的指纹。\n\n- `Plan`:表示该语句的执行计划,运行 ``select tidb_decode_plan('...') `` 可以解析出具体的执行计划。\n\n- `Query`:表示该 SQL 语句。慢日志里不会打印字段名 Query,但映射到内存表后对应的字段叫 ``Query``。\n\n**(2) 和事务执行相关的字段:**\n\n- `Prewrite_time`:表示事务两阶段提交中第一阶段(``prewrite`` 阶段)的耗时。\n\n- `Commit_time`:表示事务两阶段提交中第二阶段(``commit`` 阶段)的耗时。\n\n- `Get_commit_ts_time`:表示事务两阶段提交中第二阶段(``commit`` 阶段)获取 ``commit`` 时间戳的耗时。\n\n- `Local_latch_wait_time`:表示事务两阶段提交中第二阶段(``commit`` 阶段)发起前在 TiDB 侧等锁的耗时。\n\n- `Write_keys`:表示该事务向 TiKV 的 Write CF 写入 Key 的数量。\n\n- `Write_size`:表示事务提交时写 key 和 value 的总大小。\n\n- `Prewrite_region`:表示事务两阶段提交中第一阶段(``prewrite`` 阶段)涉及的 TiKV Region 数量。每个 Region 会触发一次远程过程调用。\n\n**(3) 和内存使用相关的字段:**\n\n- `Memory_max`:表示执行期间 TiDB 使用的最大内存空间,单位为 ``byte``。\n\n**(4) 和用户相关的字段:**\n\n- `User`:表示执行语句的用户名。\n\n- `Conn_ID`:表示用户的连接 ID,可以用类似 ``con:3`` 的关键字在 TiDB 日志中查找该链接相关的其他日志。\n\n- `DB`:表示执行语句时使用的 database。\n\n**(5) 和 TiKV Coprocessor Task 相关的字段:**\n\n- `Process_time`:该 SQL 在 TiKV 上的处理时间之和。因为数据会并行发到 TiKV 执行,该值可能会超过 ``Query_time``。\n\n- `Wait_time`:表示该语句在 TiKV 上的等待时间之和。因为 TiKV 的 Coprocessor 线程数是有限的,当所有的 Coprocessor 线程都在工作的时候,请求会排队;若队列中部分请求耗时很长,后面的请求的等待时间会增加。\n\n- `Request_count`:表示该语句发送的 Coprocessor 请求的数量。\n\n- `Total_keys`:表示 Coprocessor 扫过的 key 的数量。\n\n- `Process_keys`:表示 Coprocessor 处理的 key 的数量。相较于 ``total_keys``,processed_keys 不包含 MVCC 的旧版本。如果 ``processed_keys`` 和 ``total_keys`` 相差很大,说明旧版本比较多。\n\n- `Cop_proc_avg`:cop-task 的平均执行时间。\n\n- `Cop_proc_p90`:cop-task 的 P90 分位执行时间。\n\n- `Cop_proc_max`:cop-task 的最大执行时间。\n\n- `Cop_proc_addr`:执行时间最长的 cop-task 所在地址。\n\n- `Cop_wait_avg`:cop-task 的平均等待时间。\n\n- `Cop_wait_p90`:cop-task 的 P90 分位等待时间。\n\n- `Cop_wait_max`:cop-task 的最大等待时间。\n\n- `Cop_wait_addr`:等待时间最长的 cop-task 所在地址。\n\n### Slow Query 内存表使用排查\n\n下面通过一些示例展示如何通过 SQL 查看 TiDB 的慢查询。\n\n**检索当前节点 Top N 慢查询**\n\n以下 SQL 用于检索当前 TiDB 节点的 Top 2 慢查询:\n\n```\n> select query_time, query\n from information_schema.slow_query -- 检索当前 TiDB 节点的慢查询\n where is_internal = false -- 排除 TiDB 内部的慢查询\n order by query_time desc\n limit 2;\n+--------------+------------------------------------------------------------------+\n| query_time | query |\n+--------------+------------------------------------------------------------------+\n| 12.77583857 | select * from t_slim, t_wide where t_slim.c0=t_wide.c0; |\n| 0.734982725 | select t0.c0, t1.c1 from t_slim t0, t_wide t1 where t0.c0=t1.c0; |\n+--------------+------------------------------------------------------------------+\n```\n\n**检索全部节点上指定用户的 Top N 慢查询**\n\n以下 SQL 会检索全部 TiDB 节点上指定用户 ``test`` 的 Top 2 慢查询:\n\n```\n> select query_time, query, user\n from information_schema.cluster_slow_query -- 检索全部 TiDB 节点的慢查询\n where is_internal = false \n and user = \"test\"\n order by query_time desc\n limit 2;\n+-------------+------------------------------------------------------------------+----------------+\n| Query_time | query | user |\n+-------------+------------------------------------------------------------------+----------------+\n| 0.676408014 | select t0.c0, t1.c1 from t_slim t0, t_wide t1 where t0.c0=t1.c1; | test |\n+-------------+------------------------------------------------------------------+----------------+\n```\n\n**检索同类慢查询**\n\n在得到 Top N 慢查询后,可通过 SQL 指纹继续检索同类慢查询。\n\n```\n-- 先获取 Top N 的慢查询和对应的 SQL 指纹\n> select query_time, query, digest\n from information_schema.cluster_slow_query\n where is_internal = false\n order by query_time desc\n limit 1;\n+-------------+-----------------------------+------------------------------------------------------------------+\n| query_time | query | digest |\n+-------------+-----------------------------+------------------------------------------------------------------+\n| 0.302558006 | select * from t1 where a=1; | 4751cb6008fda383e22dacb601fde85425dc8f8cf669338d55d944bafb46a6fa |\n+-------------+-----------------------------+------------------------------------------------------------------+\n\n-- 再根据 SQL 指纹检索同类慢查询\n> select query, query_time\n from information_schema.cluster_slow_query\n where digest = \"4751cb6008fda383e22dacb601fde85425dc8f8cf669338d55d944bafb46a6fa\";\n+-----------------------------+-------------+\n| query | query_time |\n+-----------------------------+-------------+\n| select * from t1 where a=1; | 0.302558006 |\n| select * from t1 where a=2; | 0.401313532 |\n+-----------------------------+-------------+\n```\n\n**检索统计信息为 ``pseudo`` 的慢查询**\n\n如果慢查询日志中的统计信息被标记为 ``pseudo``,往往说明 TiDB 表的统计信息更新不及时,需要运行 ``analyze table`` 手动收集统计信息。以下 SQL 可以找到这一类慢查询:\n\n```\n如果慢查询日志中的统计信息被标记为 pseudo,往往说明 TiDB 表的统计信息更新不及时,需要运行 analyze table 手动收集统计信息。以下 SQL 可以找到这一类慢查询:\n> select query, query_time, stats\n from information_schema.cluster_slow_query\n where is_internal = false\n and stats like '%pseudo%';\n+-----------------------------+-------------+---------------------------------+\n| query | query_time | stats |\n+-----------------------------+-------------+---------------------------------+\n| select * from t1 where a=1; | 0.302558006 | t1:pseudo |\n| select * from t1 where a=2; | 0.401313532 | t1:pseudo |\n| select * from t1 where a>2; | 0.602011247 | t1:pseudo |\n| select * from t1 where a>3; | 0.50077719 | t1:pseudo |\n| select * from t1 join t2; | 0.931260518 | t1:407872303825682445,t2:pseudo |\n+-----------------------------+-------------+---------------------------------+\n```\n\n**查询执行计划发生变化的慢查询**\n\n由于统计信息不准,可能导致同类型 SQL 的执行计划发生意料之外的改变。用以下 SQL 可以检索到哪些慢查询具有多种不同的执行计划:\n\n```\n> select count(distinct plan_digest) as count, digest,min(query) \n from information_schema.cluster_slow_query \n group by digest \n having count>1 \n limit 3\\G\n***************************[ 1. row ]***************************\ncount | 2\ndigest | 17b4518fde82e32021877878bec2bb309619d384fca944106fcaf9c93b536e94\nmin(query) | SELECT DISTINCT c FROM sbtest25 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (291638, 291737)];\n***************************[ 2. row ]***************************\ncount | 2\ndigest | 9337865f3e2ee71c1c2e740e773b6dd85f23ad00f8fa1f11a795e62e15fc9b23\nmin(query) | SELECT DISTINCT c FROM sbtest22 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (215420, 215519)];\n***************************[ 3. row ]***************************\ncount | 2\ndigest | db705c89ca2dfc1d39d10e0f30f285cbbadec7e24da4f15af461b148d8ffb020\nmin(query) | SELECT DISTINCT c FROM sbtest11 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (303359, 303458)];\n```\n\n```\n-- 借助 SQL 指纹进一步查询执行计划的详细信息\n> select min(plan),plan_digest \n from information_schema.cluster_slow_query\n where digest='17b4518fde82e32021877878bec2bb309619d384fca944106fcaf9c93b536e94' \n group by plan_digest\\G\n*************************** 1. row ***************************\n min(plan): Sort_6 root 100.00131380758702 sbtest.sbtest25.c:asc\n └─HashAgg_10 root 100.00131380758702 group by:sbtest.sbtest25.c, funcs:firstrow(sbtest.sbtest25.c)->sbtest.sbtest25.c\n └─TableReader_15 root 100.00131380758702 data:TableRangeScan_14\n └─TableScan_14 cop 100.00131380758702 table:sbtest25, range:[502791,502890], keep order:false\nplan_digest: 6afbbd21f60ca6c6fdf3d3cd94f7c7a49dd93c00fcf8774646da492e50e204ee\n*************************** 2. row ***************************\n min(plan): Sort_6 root 1 sbtest.sbtest25.c:asc\n └─HashAgg_12 root 1 group by:sbtest.sbtest25.c, funcs:firstrow(sbtest.sbtest25.c)->sbtest.sbtest25.c\n └─TableReader_13 root 1 data:HashAgg_8\n └─HashAgg_8 cop 1 group by:sbtest.sbtest25.c,\n └─TableScan_11 cop 1.2440069558121831 table:sbtest25, range:[472745,472844], keep order:false\n```\n\n**统计各个节点的慢查询数量**\n\n以下 SQL 统计指定时段内各个 TiDB 节点上出现过的慢查询数量:\n\n```\n> select instance, count(*) \n from information_schema.cluster_slow_query \n where time >= \"2020-03-06 00:00:00\" \n and time < now() \n group by instance;\n+---------------+----------+\n| instance | count(*) |\n+---------------+----------+\n| 0.0.0.0:10081 | 124 |\n| 0.0.0.0:10080 | 119771 |\n+---------------+----------+\n```\n\n**检索异常时段的慢查询**\n\n假定 ``2020-03-10 13:24:00`` 至 ``2020-03-10 13:27:00`` 期间发现 QPS 降低和查询响应时间升高等问题,可以用以下 SQL 过滤出仅仅出现在异常时段的慢查询:\n\n```\n> select * from\n (select /*+ AGG_TO_COP(), HASH_AGG() */ count(*),\n min(time),\n sum(query_time) AS sum_query_time,\n sum(Process_time) AS sum_process_time,\n sum(Wait_time) AS sum_wait_time,\n sum(Commit_time),\n sum(Request_count),\n sum(process_keys),\n sum(Write_keys),\n max(Cop_proc_max),\n min(query),min(prev_stmt),\n digest\n from information_schema.cluster_slow_query\n where time >= '2020-03-10 13:24:00'\n and time < '2020-03-10 13:27:00'\n adn Is_internal = false\n group by digest) AS t1\n where t1.digest not in\n (select /*+ AGG_TO_COP(), HASH_AGG() */ digest\n from information_schema.cluster_slow_query\n where time >= '2020-03-10 13:20:00' -- 排除正常时段 `2020-03-10 13:20:00` ~ `2020-03-10 13:23:00` 期间的慢查询\n and time < '2020-03-10 13:23:00'\n group by digest)\n order by t1.sum_query_time desc\n limit 10\\G\n***************************[ 1. row ]***************************\ncount(*) | 200\nmin(time) | 2020-03-10 13:24:27.216186\nsum_query_time | 50.114126194\nsum_process_time | 268.351\nsum_wait_time | 8.476\nsum(Commit_time) | 1.044304306\nsum(Request_count) | 6077\nsum(process_keys) | 202871950\nsum(Write_keys) | 319500\nmax(Cop_proc_max) | 0.263\nmin(query) | delete from test.tcs2 limit 5000;\nmin(prev_stmt) |\ndigest | 24bd6d8a9b238086c9b8c3d240ad4ef32f79ce94cf5a468c0b8fe1eb5f8d03df\n```\n\n## TiDB Dashboard 可视化 Statements\n\n上一节介绍了利用 Slow Query 内存表来排查慢查询,但 Slow Query 只会记录超过慢日志阈值的 SQL 而缺少对全部运行负载的诊断排查。本节会介绍通过使用 TiDB Dashboard 来排查定位问题查询。TiDB Dashboard 提供了 Statements 用来监控和统计 SQL,例如页面上提供了丰富的列表信息,包括延迟、执行次数、扫描行数、全表扫描次数等,用来分析哪些类别的 SQL 语句耗时过长、消耗内存过多等情况,帮助用户定位性能问题。\n\nTiDB 已支持多种性能排查工具。但在多种应用场景需求下,仍有不足,例如:\n\n1.Grafana 不能排查单条 SQL 的性能问题\n\n2.Slow log 只记录超过慢日志阀值的 SQL\n\n3.General log 本身对性能有一定影响\n\n4.Explain analyze 只能查看可以复现的问题\n\n5.Profile 只能查看整个实例的瓶颈\n\n因此推出可视化 Statements,可以直接在页面观察 SQL 执行情况,不需要查询系统表,便于用户定位性能问题。\n\n### 使用 TiDB Dashboard\n\n从4.0版本开始,TiDB 提供了一个新的 Dashboard 运维管理工具,集成在 PD 组件上,默认地址为 [http://pd-url:pd_port/dashboard](http://pd-url:pd_port/dashboard) 。 不同于 Grafana 监控是从数据库的监控视角出发,TiDB Dashboard 从 DBA 管理员角度出发,最大限度的简化管理员对 TiDB 数据库的运维,可在一个界面查看到整个分布式数据库集群的运行状况,包括数据热点、SQL 运行情况、集群信息、日志搜索、实时性能分析等。\n\n### 查看 Statements 整体情况\n\n登录后,在左侧点击「SQL 语句分析」即可进入此功能页面。\n\n在时间区间选项框中选择要分析的时间段,即可得到该时段所有数据库的 SQL 语句执行统计情况。\n\n如果只关心某些数据库,则可以在第二个选项框中选择相应的数据库对结果进行过滤,支持多选。\n\n结果以表格的形式展示,并支持按不同的列对结果进行排序,如下图所示。\n\n1.选择需要分析的时间段\n\n2.支持按数据库过滤\n\n3.支持按不同的指标排序\n\n注意:这里所指的 SQL 语句实际指的是某一类 SQL 语句。语法一致的 SQL 语句会规一化为一类相同的 SQL 语句。\n\n例如:\n\n```\nSELECT * FROM employee WHERE id IN (1, 2, 3);\nselect * from EMPLOYEE where ID in (4, 5);\n```\n\n规一化为\n\n```\nselect * from employee where id in (...);\n```\n\n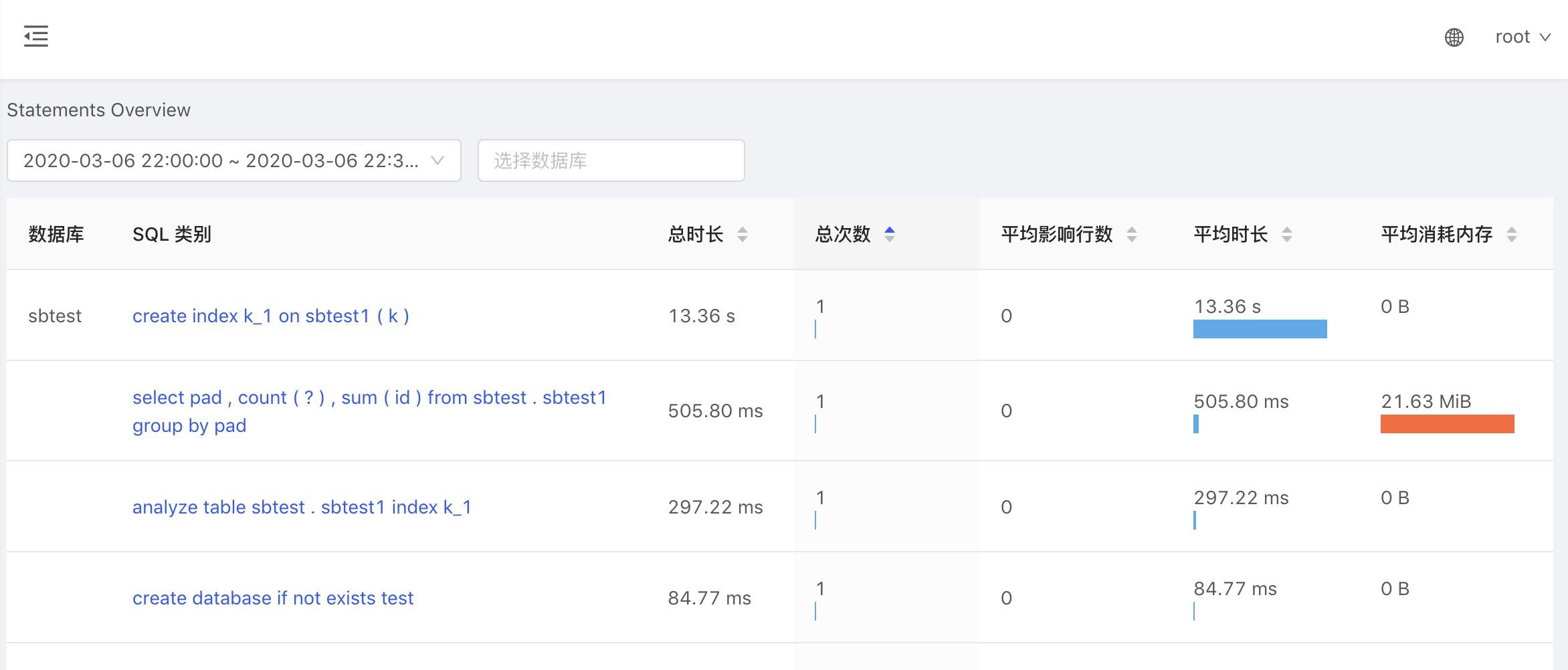\n\n\n在 SQL 类别列,点击某类 SQL 语句,可以进入该 SQL 语句的详情页查看更详细的信息,以及该 SQL 语句在不同节点上执行的统计情况。\n\n单个 Statements 详情页关键信息如下图所示。\n\n1.SQL 执行总时长\n\n2.平均影响行数(一般是写入)\n\n3.平均扫描行数(一般是读)\n\n4.各个节点执行指标(可以快速定位出某个节点性能瓶颈)\n\n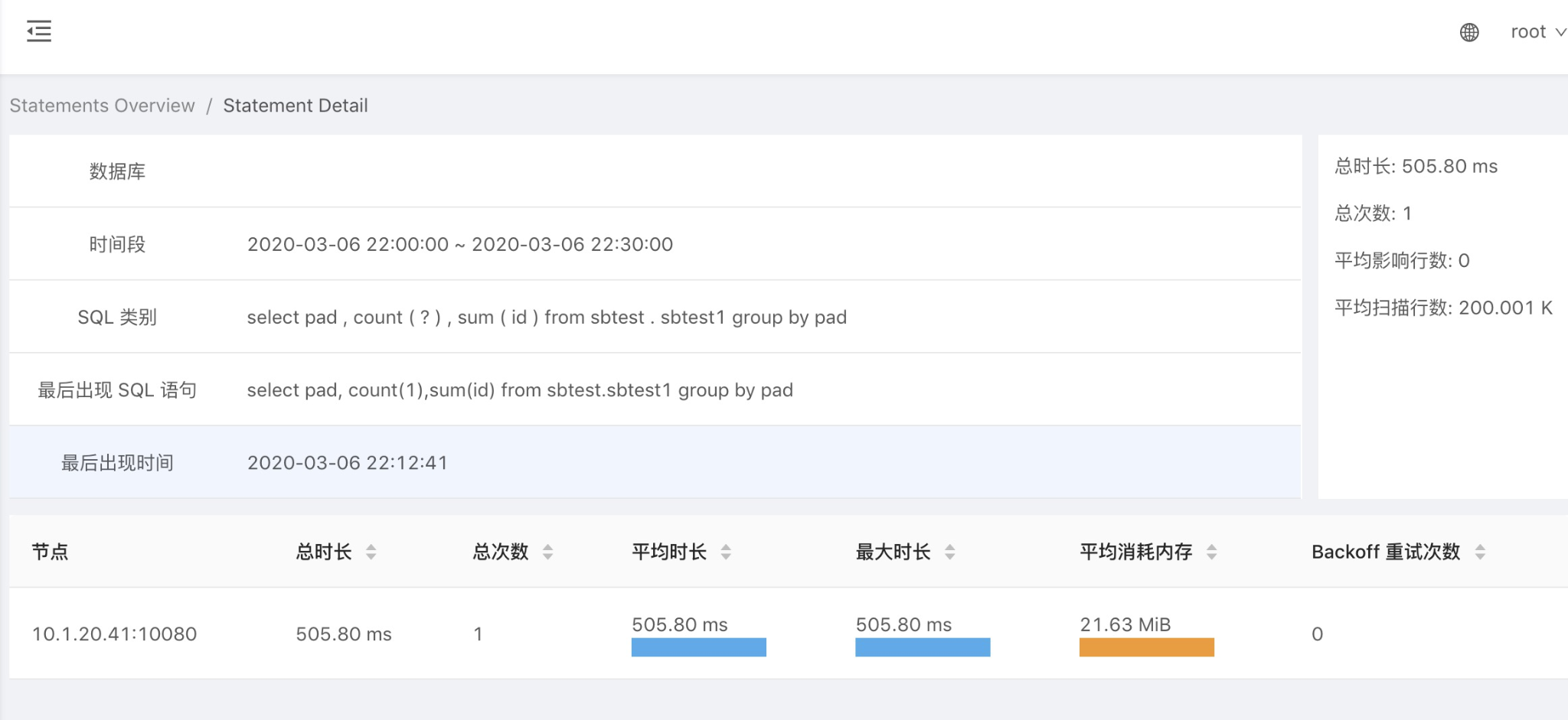\n\n### Statements 参数配置\n\n- ``tidb_enable_stmt_summary``\n Statements 功能默认开启,也可以通过设置系统变量打开,例如:\n\n```\nset global tidb_enable_stmt_summary = true;\n```\n\n- ``tidb_stmt_summary_refresh_interval``\n\n设置 ``performance_schema.events_statements_summary_by_digest`` 表的的清空周期,单位是秒 (s),默认值是 1800,例如:\n\n```\nset global tidb_stmt_summary_refresh_interval = 1800;\n```\n\n- ``tidb_stmt_summary_history_size``\n 设置 ``performance_schema.events_statements_summary_by_digest_history`` 表保存每种 SQL 的历史的数量,默认值是 24,例如:\n\n```\nset global tidb_stmt_summary_history_size = 24;\n```\n\n由于 Statements 信息是存储在内存表中,为了防止内存溢出等问题,需要限制保存的 SQL 条数和 SQL 的最大显示长度。这两个参数需要在 config.toml 的 ``[stmt-summary]`` 类别下配置:\n\n- 通过 ``max-stmt-count`` 更改保存的 SQL 种类数量,默认 200 条。当 SQL 种类超过 ``max-stmt-count`` 时,会移除最近没有使用的 SQL\n\n- 通过 ``max-sql-length`` 更改 ``DIGEST_TEXT`` 和 ``QUERY_SAMPLE_TEXT`` 的最大显示长度,默认是 4096\n\n注意:``tidb_stmt_summary_history_size``、``max-stmt-count``、``max-sql-length`` 几项配置影响内存占用,建议根据实际情况调整,不宜设置得过大。\n\n综上所述,可视化 Statements 可以快速定位某个 SQL 性能问题。\n\n本文为「TiDB 查询优化及调优」系列文章的第三篇,前文我们分别介绍了[优化器的基本概念](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-1) 和 [TiDB 的查询计划](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-2),后续将继续对 TiDB 调整及优化查询执行计划、其他优化器开发或规划中的诊断调优功能等进行介绍。\n如果您对 TiDB 的产品有任何建议,欢迎来到 [internals.tidb.io](https://internals.tidb.io/) 与我们交流。\n\n> 点击查看更多 [TiDB 查询优化及调优](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98)文章","author":"Yu Dong","category":1,"customUrl":"tidb-query-optimization-and-tuning-3","fillInMethod":"writeDirectly","id":381,"summary":"本章节介绍如何利用 TiDB 提供的系统监控诊断工具,对运行负载中的慢查询进行排查和诊断。","tags":["TiDB","TiDB 性能调优"],"title":"TiDB 查询优化及调优系列(三)慢查询诊断监控及排查"}},{"relatedBlog":{"body":"本章节会介绍在优化器产生的查询执行计划和预期不符时,如何通过 TiDB 提供的调优手段来调整及稳定查询计划。**本篇文章为查询执行计划的调整及优化原理解析**,主要会介绍如何通过使用 HINT 来调整查询的执行计划,以及如何利用 TiDB SPM 来绑定查询语句的查询执行计划;最后将介绍一些规划中的功能。\n\n**相关阅读:**\n\n[TiDB 查询优化及调优系列(一)TiDB 优化器简介](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-1)\n\n[TiDB 查询优化及调优系列(二)TiDB 查询计划简介](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-2)\n\n[TiDB 查询优化及调优系列(三)慢查询诊断监控及排查](https://pingcap.com/zh/blog/tidb-query-optimization-and-tuning-3)\n\n## 使用 HINT 调整查询执行计划\n\n当优化器选择了非预期或不优的执行计划,用户需要使用 Hint 进行执行计划的调整。TiDB 兼容了 MySQL 的 USE INDEX,FORCE INDEX,IGNORE INDEX 语法,同时开发了 TiDB 自身的 Optimizer Hints 语法,它基于 MySQL 5.7 中介绍的类似 comment 的语法,例如 /+ TIDB_XX(t1, t2) / 。下面是 TiDB 目前支持的 Hint 语法列表:\n\n\n\n### 使用 USE INDEX, FORCE INDEX, IGNORE INDEX\n\n与 MySQL 类似, 没有使用预期索引的查询计划是慢查询的常见原因,这时就要用 USE INDEX 指定查询用的索引,例如下面例子 USE/FORCE INDEX 使得原本全表扫描的 SQL 变成了通过索引扫描。\n\n```sql\nmysql> explain select * from t; \n+-----------------------+---------+-----------+---------------+----------------------+\n| id | estRows | task | access object | operator info |\n+-----------------------+---------+-----------+---------------+----------------------+\n| TableReader_5 | 8193.00 | root | | data:TableFullScan_4 |\n| └─TableFullScan_4 | 8193.00 | cop[tikv] | table:t | keep order:false |\n+-----------------------+---------+-----------+---------------+----------------------+\n2 rows in set (0.00 sec) \n\nmysql> explain select * from t use index(idx_1); \n+-------------------------------+---------+-----------+-------------------------+------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------------+---------+-----------+-------------------------+------------------+\n| IndexLookUp_6 | 8193.00 | root | | |\n| ├─IndexFullScan_4(Build) | 8193.00 | cop[tikv] | table:t, index:idx_1(a) | keep order:false |\n| └─TableRowIDScan_5(Probe) | 8193.00 | cop[tikv] | table:t | keep order:false |\n+-------------------------------+---------+-----------+-------------------------+------------------+\n3 rows in set (0.00 sec) \nmysql> explain select * from t force index(idx_1); \n+-------------------------------+---------+-----------+-------------------------+------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------------+---------+-----------+-------------------------+------------------+\n| IndexLookUp_6 | 8193.00 | root | | |\n| ├─IndexFullScan_4(Build) | 8193.00 | cop[tikv] | table:t, index:idx_1(a) | keep order:false |\n| └─TableRowIDScan_5(Probe) | 8193.00 | cop[tikv] | table:t | keep order:false |\n+-------------------------------+---------+-----------+-------------------------+------------------+\n3 rows in set (0.00 sec)\n```\n下面的例子 IGNORE INDEX 使得原本走索引的 SQL 变成了全表扫描\n```sql\nmysql> explain select a from t where a=2; \n+------------------------+---------+-----------+-------------------------+-------------------------------+\n| id | estRows | task | access object | operator info |\n+------------------------+---------+-----------+-------------------------+-------------------------------+\n| IndexReader_6 | 1.00 | root | | index:IndexRangeScan_5 |\n| └─IndexRangeScan_5 | 1.00 | cop[tikv] | table:t, index:idx_1(a) | range:[2,2], keep order:false |\n+------------------------+---------+-----------+-------------------------+-------------------------------+\n2 rows in set (0.00 sec) \n\nmysql> explain select a from t ignore index(idx_1) where a=2 ;\n+-------------------------+---------+-----------+-----------------+------------------+\n| id | estRows | task | access object | operator info |\n+-------------------------+---------+-----------+-----------------+------------------+\n| TableReader_7 | 1.00 | root | | data:Selection_6 |\n| └─Selection_6 | 1.00 | cop[tikv] | eq(test.t.a, 2) | |\n| └─TableFullScan_5 | 8193.00 | cop[tikv] | table:t | keep order:false |\n+-------------------------+---------+-----------+-----------------+------------------+\n3 rows in set (0.00 sec)\n```\n和 MySQL 不同的是, 目前 TiDB 并没有对 USE INDEX 和 FORCE INDEX 做区分。当表上有多个索引时,建议使用 USE INDEX 。TiDB 的表都比较大,`analyze table` 会对集群性能造成较大影响,因此无法频繁更新统计信息。这时就要用 USE INDEX 保证查询计划的正确性\n\n### 使用 JOIN HINT\n\nTiDB 目前表 Join 的方式有 Sort Merge Join,Index Nested Loop Join,Hash Join,具体的每个 join 方式的实现细节可以参考 [TiDB源码阅读系列](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)\n语法:\n\n#### TIDB_SMJ(t1, t2)\n```sql\nSELECT /*+ TIDB_SMJ(t1, t2) */ * from t1,t2 where t1.id = t2.id;\n```\n提示优化器使用 Sort Merge Join 算法,简单来说,就是将 Join 的两个表,首先根据连接属性进行排序,然后进行一次扫描归并, 进而就可以得出最后的结果,这个算法通常会占用更少的内存,但执行时间会更久。 当数据量太大,或系统内存不足时,建议尝试使用。\n#### TIDB_INLJ(t1, t2)\n```sql\nSELECT /*+ TIDB_INLJ(t1, t2) */ * from t1,t2 where t1.id = t2.id;\n```\n提示优化器使用 Index Nested Loop Join 算法,Index Look Up Join 会读取外表的数据,并对内表进行主键或索引键查询,这个算法可能会在某些场景更快,消耗更少系统资源,有的场景会更慢,消耗更多系统资源。对于外表经过 WHERE 条件过滤后结果集较小(小于 1 万行)的场景,可以尝试使用。TIDB_INLJ() 中的参数是建立查询计划时,内表的候选表。即 TIDB_INLJ(t1) 只会考虑使用 t1 作为内表构建查询计划\n#### TIDB_HJ(t1, t2)\n```sql\nSELECT /*+ TIDB_HJ(t1, t2) */ * from t1,t2 where t1.id = t2.id;\n```\n提示优化器使用 Hash Join 算法,简单来说,t1 表和 t2 表的 Hash Join 需要我们选择一个 Inner 表来构造哈希表,然后对 Outer 表的每一行数据都去这个哈希表中查找是否有匹配的数据这个算法多线程并发执行,执行速度较快,但会消耗较多内存。\n\n另外其他的 hint 语法也在开发中如 /+ TIDB_STREAMAGG() / ,/+ TIDB_HASHAGG() / 等。\n\n使用 Hint 通常是在执行计划发生变化的时候,通过修改 SQL 语句调整执行计划行为,但有的时候需要在不修改 SQL 语句的情况下干预执行计划的选择。[执行计划绑定](https://docs.pingcap.com/zh/tidb/v4.0/sql-plan-management)提供了一系列功能使得可以在不修改 SQL 语句的情况下选择指定的执行计划。\n\n### 使用 MAX_EXECUTION_TIME(N)\n在 SELECT 等语句中可以使用 MAX_EXECUTION_TIME(N),它会限制语句的执行时间不能超过 N 毫秒,否则服务器会终止这条语句的执行。\n例如,下面例子设置了 1 秒超时\n```sql\nSELECT /*+ MAX_EXECUTION_TIME(1000) */ * FROM t1\n```\n此外,环境变量 `MAX_EXECUTION_TIME` 也会对语句执行时间进行限制。\n对于高可用和时间敏感的业务, 建议使用 `MAX_EXECUTION_TIME`,免错误的查询计划或 bug 影响整个 TiDB 集群的性能甚至稳定性。 OLTP 业务查询超时一般不超过 5 秒。\n需要注意的是,MySQL jdbc 的查询超时设置对 TiDB 不起作用。现实客户端感知超时时,向数据库发送一个 KILL 命令, 但是由于 tidb-server 是负载均衡的, 为防止在错误的 tidb-server 上终止连接, tidb-server 不会执行这个 KILL。这时就要用 `MAX_EXECUTION_TIME` 保证查询超时的效果。\n\n## 使用 SPM 绑定查询执行计划\n\n**执行计划是影响 SQL 执行性能的一个非常关键的因素,SQL 执行计划的稳定性也对整个集群的效率有着非常大的影响**。然而,当出现类似统计信息过时、添加或者删除了索引等情况时,优化器并不能确保一定生成一个很好的执行计划。此时执行计划可能发生预期外的改变,导致执行时间过长。因此 TiDB 提供了 SQL Plan Management 功能,用于为某些类型的 SQL 绑定执行计划(SQL Bind),并且被绑定的执行计划会根据数据的变化而不断地演进(注:演进功能尚未 GA)。\n\nSQL Bind 是 SQL Plan Management 的第一步。使用它,用户可以为某一类型的 SQL 绑定执行计划。当出现执行计划不优时,可以使用 SQL Bind 在不更改业务的情况下快速地对执行计划进行修复。\n创建绑定可以使用如下的 SQL:\n```sql\nCREATE [GLOBAL | SESSION] BINDING FOR SelectStmt USING SelectStmt;\n```\n该语句可以在 GLOBAL 或者 SESSION 作用域内为 SQL 绑定执行计划。在不指定作用域时,默认作用域为 SESSION。被绑定的 SQL 会被参数化,然后存储到系统表中。在处理 SQL 查询时,只要参数化后的 SQL 和系统表中某个被绑定的 SQL 匹配即可使用相应的优化器 Hint。\n\n“参数化” 指的是把 SQL 中的常量用 \"?\" 替代,统一语句中的大小写,清理掉多余的空格、换行符等操作。\n创建一个绑定的例子:\n```sql\nTiDB(root@127.0.0.1:test) > create binding for select * from t where a = 1 using select * from t use index(idx_a) where a = 1;\nQuery OK, 0 rows affected (0.00 sec)\n```\n查看刚才创建的 binding,下面输出结果中 Original_sql 即为参数化后的 SQL:\n```sql\nTiDB(root@127.0.0.1:test) > show bindings;\n+-----------------------------+----------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+\n| Original_sql | Bind_sql | Default_db | Status | Create_time | Update_time | Charset | Collation |\n+-----------------------------+----------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+\n| select * from t where a = ? | select * from t use index(idx_a) where a = 1 | test | using | 2020-03-08 14:00:28.819 | 2020-03-08 14:00:28.819 | utf8 | utf8_general_ci |\n+-----------------------------+----------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+\n1 row in set (0.00 sec)\n```\n如果要删除创建的 binding 可通过如下语句:\n```sql\nTiDB(root@127.0.0.1:test) > drop binding for select * from t where a = 1;\nQuery OK, 0 rows affected (0.00 sec)\n\nTiDB(root@127.0.0.1:test) > show bindings;\nEmpty set (0.00 sec)\n```\n为了解决只能手动创建 Binding 的问题,4.0 版本中 TiDB 提供了自动创建 Binding 功能,通过将 tidb_capture_plan_baselines 变量的值设置为 on,就可以自动为某一段时间内出现多次的 SQL 去创建绑定。TiDB 会为那些出现了至少两次的 SQL 创建绑定,统计 SQL 的出现次数依赖 TiDB 4.0 版本中提供的 Statements Summary 功能。可通过如下方法打开自动为出现了两次以上的 SQL 创建绑定的开关:\n```sql\nset tidb_enable_stmt_summary = 1; -- 开启 statement summary\nset tidb_capture_plan_baselines = 1; -- 开启自动绑定功能\n```\n接着连续跑两遍如下查询即可自动为其创建一条绑定:\n```sql\nTiDB(root@127.0.0.1:test) > select * from t;\nEmpty set (0.01 sec)\n\nTiDB(root@127.0.0.1:test) > select * from t;\nEmpty set (0.00 sec)\n```\n再查看 global bindings 即可发现自动创建的 binding:\n```sql\nTiDB(root@127.0.0.1:test) > show global bindings;\n+-----------------+---------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+\n| Original_sql | Bind_sql | Default_db | Status | Create_time | Update_time | Charset | Collation |\n+-----------------+---------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+\n| select * from t | SELECT /*+ USE_INDEX(@`sel_1` `test`.`t` )*/ * FROM `t` | test | using | 2020-03-08 14:09:30.129 | 2020-03-08 14:09:30.129 | | |\n+-----------------+---------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+\n1 row in set (0.00 sec)\n```\n\n## 其它优化器开发或规划中的诊断调优功能\n\n针对查询执行计划的监控,诊断,排查,和调优,**除了上述章节介绍的方法和功能外,TiDB 优化器开发了一些内部使用功能,同时目前还在开发或规划开发更多的相关功能**,将在后续版本中发布。这些功能包括但不限于:\n\n**Plan Change Capture:** 用于验证在升级中是否会引起查询执行计划回归/变更;\n\n**Plan Replayer:** 用于一键收集用户问题查询的相关信息,并一键导入 TiDB 用于问题复现以及查询计划的回归看护;\n\n**Optimizer Trace:** 用于收集和监控优化器内部优化逻辑流程,提升用户现场的问题诊断能力和效率,并为后续的基于诊断监控的反馈优化提供数据输入;\n\n**Visual Explain:** 图形化展示查询计划,特别是对于复杂查询的执行计划查看可以提升效率,并可在后续集成更多诊断信息;\n\n**Optimizer Diagnosis and Advisor:** 优化器自诊断和优化建议功能;并与 TiDB Dashboard, Auto Pilot 等集成;\n\n**SPM 扩展**:增加多基线计划版本绑定,改进完善绑定计划演进;\n\n**Plan Hint**:完善并提供更丰富的 Plan Hint;\n\n\n本文为「TiDB 查询优化及调优」系列文章的第四篇,详细介绍了如何通过 TiDB HINT 和 SPM 对查询执行计划进行调整和优化,简要列举了其他优化器开发或规划中的诊断调优功能等。**下篇文章为系列文章的最后一篇,将通过几个具体的案例介绍 TiDB 查询优化的实践**。\n\n如果您对 TiDB 的产品有任何建议,欢迎来到 [internals.tidb.io](https://internals.tidb.io/) 与我们交流。\n\n> 点击查看更多 [TiDB 查询优化及调优](https://pingcap.com/zh/blog/?tag=TiDB%20%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98)文章","author":"Yu Dong","category":1,"customUrl":"tidb-query-optimization-and-tuning-4","fillInMethod":"writeDirectly","id":386,"summary":"本文为「TiDB 查询优化及调优」系列文章的第四篇,详细介绍了如何通过 TiDB HINT 和 SPM 对查询执行计划进行调整和优化,简要列举了其他优化器开发或规划中的诊断调优功能等。","tags":["TiDB","TiDB 性能调优"],"title":"TiDB 查询优化及调优系列(四)查询执行计划的调整及优化原理"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}