{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/tidb-multi-service-integration-2",
"result": {"pageContext":{"blog":{"id":"Blogs_483","title":"方案精讲丨降低架构复杂度、实现成本节约:TiDB 多业务融合方案(下)","tags":["多业务融合"],"category":{"name":"产品技术解读"},"summary":"在《多业务融合方案 - 上篇》中介绍了基础多业务融合方案,在本文中继续介绍多业务融合方案以下能力:多业务融合能力与 HTAP 结合;多业务融合在基础架构上通过修改 Leader 分布进一步提升整体隔离性;如何在线调整业务资源组。","body":"> 李振环,PingCAP 行业解决方案架构师,主要关注新经济行业和合作伙伴生态。有多年分布式数据库和大数据实战经验,之前在贝壳金服担任大数据平台技术负责人,负责贝壳金服大数据整体架构。\n\n多业务融合即将多个业务系统部署在同一套 TiDB 集群中,能够有效地帮助企业降低架构复杂度、节约成本,在竞争激烈的市场中获得更大的市场份额。\n\n如何提高资源隔离能力确保不同业务之间不相互影响是多业务融合方案设计要点。在[多业务融合方案 - 上篇](/blog/tidb-multi-service-integration-1)中介绍了基础多业务融合方案,在本文中继续介绍多业务融合方案以下能力:\n\n- 多业务融合能力与 HTAP 结合\n- 多业务融合在基础架构上通过修改 Leader 分布进一步提升整体隔离性\n- 如何在线调整业务资源组\n\n## HTAP 能力结合\n\n多业务融合之后用户提出了一些新的需求: \n\n1. 基于订单和商品信息得到当日热卖商品,基于用户标签给用户推荐热卖商品(实时分析)\n2. 实时风控需要查询商品、订单、支付、用户等行为数据做风控 (统一视图)\n3. 订单详细页面:展示订单基础信息、订单支付状态和商品详情(统一视图)\n\n这些需求在传统架构中实现复杂度高,但是借助多业务融合与 TiDB HTAP 实时分析的能力,可以大幅度降低实现复杂度和成本。\n\n需求 1 需要实现实时数据聚合分析,需求 2 和需求 3 需要实现统一视图(实时跨业务系统强一致性数据关联)。接下来分别看一下如何实现用户以上需求。\n\n### 多业务融合结合 TiFlash 实时数据分析\n\n需求 1 是实现实时数据聚合分析,传统方案会将订单、商品、用户等业务系统数据同步到统一的大数据平台,然后执行聚合 SQL 得到最终推荐结果。此过程需要维护复杂数据同步链路,数据时效性一般为 T + 1 ,无法满足实时数据推荐需求。基于多业务融合方案数据已经存储在统一的 TiDB 集群中,只需要使用 SQL 查询 TiFlash 业务数据即可得到最终推荐结果。具体实现架构如下图所示: \n\n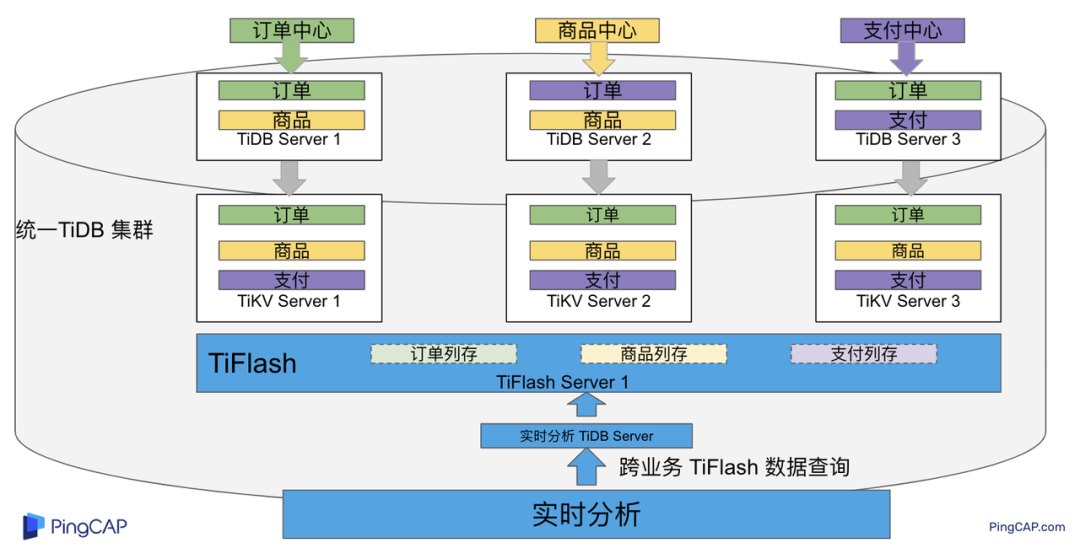\n多业务融合 + TiFlash 实时数据分析\n\n多业务融合之后支付、订单等数据已经统一存储在 TiDB 集群中,在此集群上扩展蓝色 TiFlash 实例和蓝色 TiDB 实例,并为分析相关的表创建 TiFlash 列存副本,设置新 TiDB 实例 session 级别变量:tidb_isolation_read_engines = tiflash ,强制所有数据分析 SQL 查询 TiFlash 数据副本。综上实现数据分析只使用蓝色 TiFlash 和 TiDB 资源,保持与业务系统隔离。与传统方案对比此方案具备以下优势:\n\n- 无数据同步链路:内置实时数据同步功能,减少用户运维成本\n- 强一致性数据分析:实现跨业务强一致性数据分析\n- 强大的 TiFlash 列存 MPP 分析能力:提升数据分析效率\n\n需要注意以上能力需要使用 TiDB 6.1.2 或者 6.3 以上版本。\n\n\n### 多业务融合结合读写分离能力\n\n需求 2 和需求 3 是实现统一视图的需求,并且请求 QPS 比较高。传统方案一般会通过各个业务系统开发 API 获取数据,然后在客户请求系统中统一聚合得到结果。此方案需要多个业务系统联合开发,并且客户端聚合数据复杂度高,在返回数据量较多时很容易 OOM 稳定性差。基于多业务融合加 TiDB 自带读写分离的能力实现跨业务系统实时统一视图查询,并且实现统一视图业务与在线交易业务资源隔离。具体实现架构如下图所示: \n\n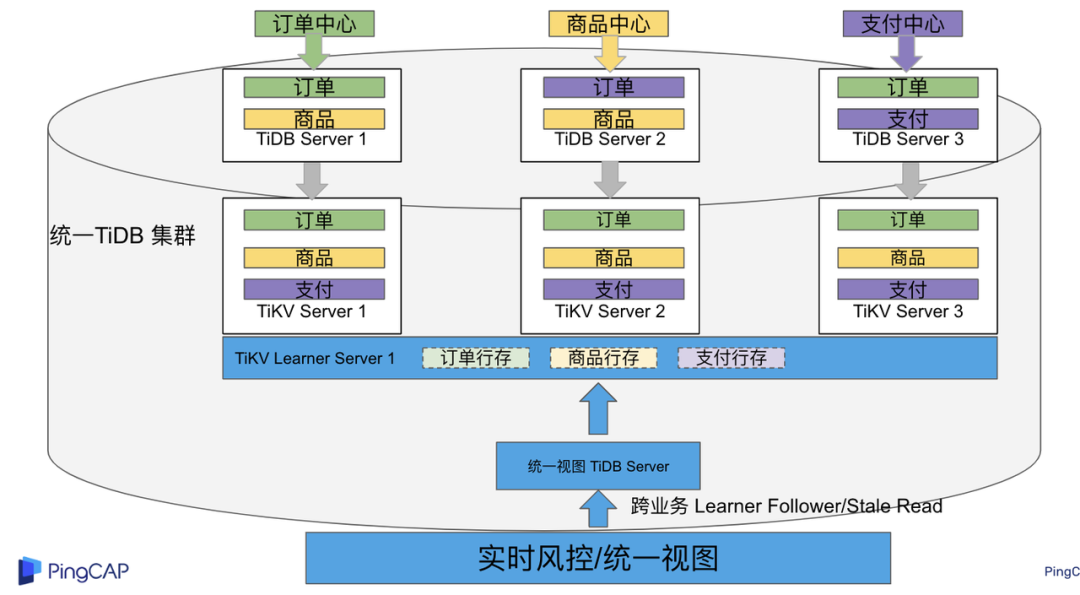\n多业务融合+读写分离\n\n多业务融合之后数据已经在统一 TiDB 集群中,为 TiDB 集群添加蓝色新 TiKV Learner 实例和 TiDB 实例。然后通过蓝色 TiDB 跨业务系统关联查询数据,统一视图 QPS 请求比较高,关联 SQL 比较复杂, 关联 SQL 默认会查询 TiKV leader ,为了降低关联 SQL 对集群业务的影响,通过简单配置,指定关联 SQL 使用蓝色 TikV Learner 副本,确保上图蓝色业务只使用蓝色计算和存储资源。综上通过 TiDB 行存读写分离的能力实现统一视图查询与业务读写资源隔离。具体实现方式如下:\n\n#### TiKV Learner 副本配置\n\n给新增 TiKV Learner 服务器上的 TiKV 实例打上 label 为 region : order_learner 。具体 tiup 配置文件内容如下:\n\n```\ntidb_servers:\n - host: 172.0.0.8\n config:\n labels:\n region: order_learner\n```\n\n通过 Placement Rules in SQL 为统一视图需求中查询的表添加 TiKV Learner 角色,具体 SQL 为:\n\n```\n# 此 SQL 创建规则,将 leader 和 follower 放置在 label 为 region:order 的 TiKV 实例中,并且创建一个 learner 角色,其数据放置在 region: learner 的 TiKV 实例中\nCreate placement policy p_order_learner LEADER_CONSTRAINTS=\"[+region=order]\" FOLLOWER_CONSTRAINTS=\"{+region=order: 2}\" LEARNER_CONSTRAINTS=\"{+region=order_learner: 1}\";\n\n# 此 SQL 将 order 表绑定到上面创建的规则上\nalter table `order`.`order` PLACEMENT POLICY=p_order_learner;\n```\n\n为统一视图所有表应用新规则之后,这些表在蓝色 TiKV 节点上都拥有一份 Learner 角色行存数据,此时一共有 4 个副本数据。\n\n#### 配置 TiDB 读取 TiKV Learner\n\n数据固定储存在 TiKV Learner 之后还需要配置蓝色 TiDB 固定从蓝色 TiKV Learner 读取数据,具体配置方式如下:设置新增蓝色 TiDB 实例 Label 为 region : order_learner ,确保 TiDB Label 与 TiKV Label 相同。具体 tiup 配置文件内容如下:\n\n```\ntidb_servers:\n - host: 172.0.0.8\n config:\n labels:\n region: order_learner\n```\n\n并设置 TiDB SQL 变量 tidb_replica_read 为 closest-replicas (就近读),设置此变量之后 TiDB 会优先就近读取与 TiDB Label 相同的 TiKV 副本数据。\n\n```\nset @@tidb_replica_read='closest-replicas' ;\nselect o.id ,p.amount from order.order o left join pay.pay on p.order_id = o.id limit 10\n```\n\n综上统一视图需求查询蓝色 TiDB 计算节点,基于就近读和 Learner 设置规则此 TiDB 会优先读取蓝色 TiKV 行存副本,读取过程支持强一致性读取,此时每次读取 Learner 时会与 Leader 做 ReadIndex 操作(此操作为轻量级操作),确保读取到最新的数据;也支持弱一致性读(stale read),此过程会跳过 ReadIndex 操作,并读取最近几秒内最新的统一 TSO 的数据,对于可以接受非最新强一致性业务可以使用弱读,进一步提升查询响应速度与 Leader 隔离性。\n\n#### 配置 TiDB 读取 TiKV Follower\n\n上述过程使用 TiKV Learner 副本实现读写分离,此时一共需要 4 个数据副本,也可以使用 3 副本实现读写分离。通过创建 Placement Rules in SQL 规则,将蓝色 TiKV 实例固定为 TiKV Follower 角色,确保与 Leader 角色隔离。创建规则具体 SQL 如下:\n\n```\n# 此 SQL 创建规则,将 leader 和 follower 放置在 label 为 region:order 的 TiKV 实例中,另外一个 follower 角色其数据放置在 region: learner 的 TiKV 实例中\ncreate placement policy p_order_follower LEADER_CONSTRAINTS=\"[+region=order]\" FOLLOWER_CONSTRAINTS=\"{+region=order: 1,+region=order_learner: 1}\";\n\n# 此 SQL 将 order 表绑定到上面创建的规则上\nalter table `order`.`order` PLACEMENT POLICY=p_order_follower\n```\n\n通过以上 SQL 将两个数据副本放置在 label 为 region : order 的 TiKV 实例中,另外一个 follower 角色其数据放置在 region: order_learner 的 TiKV 实例中。\n\n如上节内容所述,为 TiDB 也设置相同 label region: order_learner 并使用 SQL 开启就近读即可实现新增 TiDB 实例只读取新增蓝色 TiKV 实例数据,实现查询业务与 OLTP 业务资源隔离。\n\n### 多业务融合分布式事务\n\n多业务融合时可以使用 TiDB 本身分布式事务实现跨业务分布式事务,比如下单和支付需要在一个事务中提交或回滚,可以使用 TiDB 大权限用户执行以下 SQL :\n\n```\nbegin;\ninsert into `order`.`order` values(....);\ninsert into `pay`.`pay` values(....);\ncommit;\n```\n\n对比使用 seata 等分布式中间件,TiDB 只需要使用以上简单 SQL 和内置 Percolater 事务即可实现并确保跨业务分布式事务正确性。大大提高了跨业务分布式性能和正确性,并降低了开发复杂度。\n\n### 多业务融合 HTAP 能力总结\n\n在多业务融合场景中,利用 TiFlash 列存的扩展实现多业务实时分析,利用 TiKV Learner 的扩展实现多业务的统一视图,且保证业务之间的隔离互不影响。具体架构图如下:\n\n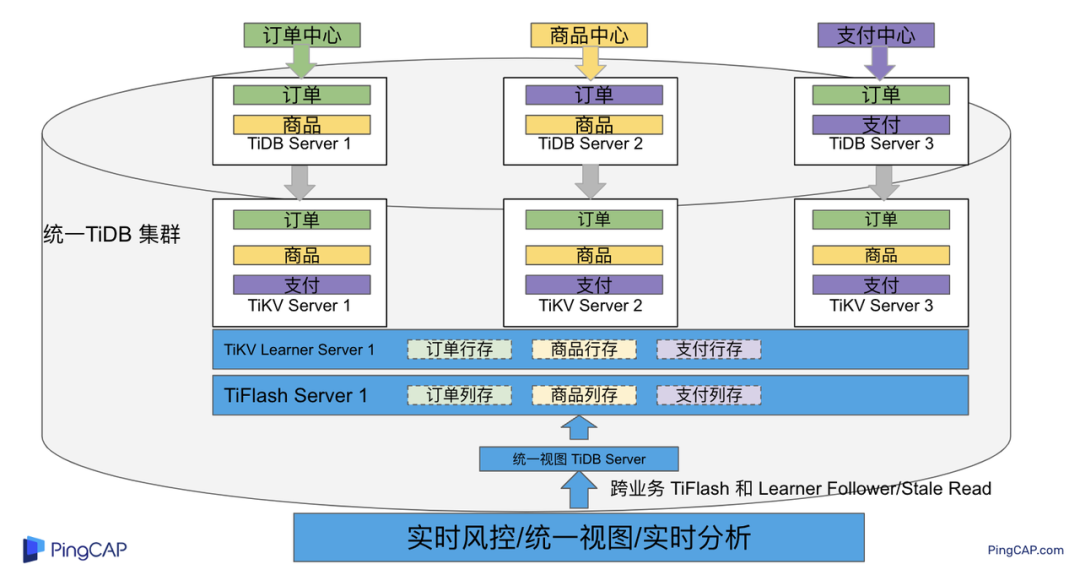\n多业务融合完整 HTAP 能力\n\n\n## Leader 分布调整\n\n在[多业务融合方案 - 上篇](/blog/tidb-multi-service-integration-1)中介绍了基础多业务融合形态。本节介绍动态调整 Leader 分布技术,满足部分客户更强单机多实例隔离性需求。 \n\n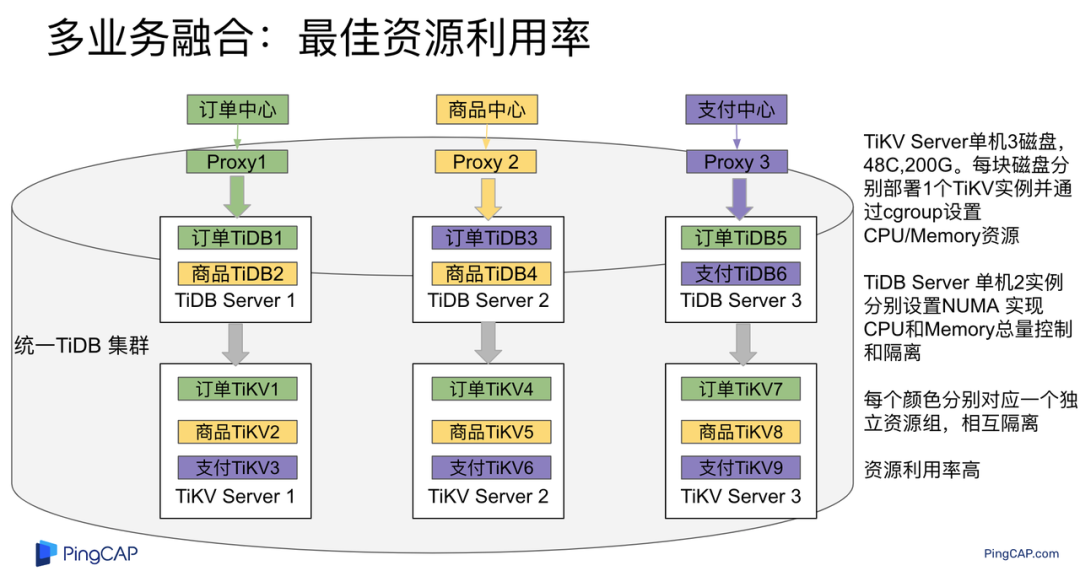\n多业务融合架构:最佳资源利用率\n\n\n### 多业务融合架构:性能冗余\n\n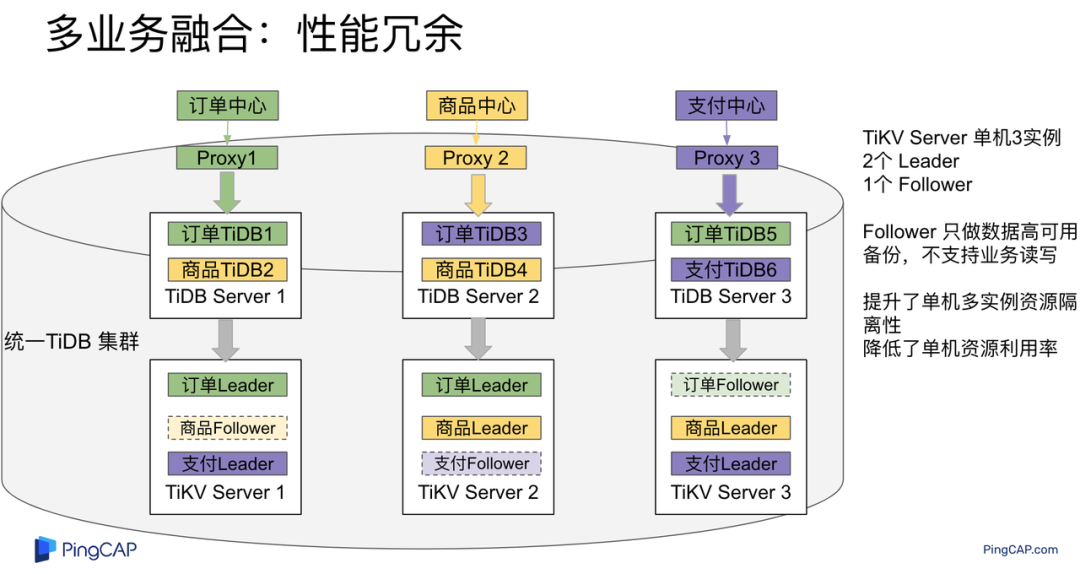\n多业务融合架构:性能冗余\n\n架构说明:各实例部署模式与图 2.1 相同,使用 Placement Rules in SQL 控制单台 TiKV Server 中 3 个 TiKV 实例只有 2 个 TiKV 实例承担 Leader 角色支持业务读写。通过减少单台 TiKV Server 在线服务 TiKV 实例个数,降低了单机 TiKV Server 资源利用率,减少了 TiKV Leader 实例资源争抢概率,提升 TiKV Leader 实例可用性。具体 Placement Rules in SQL 规则参考 2.1.3 部分说明。\n\n### 多业务融合架构:最佳隔离性\n\n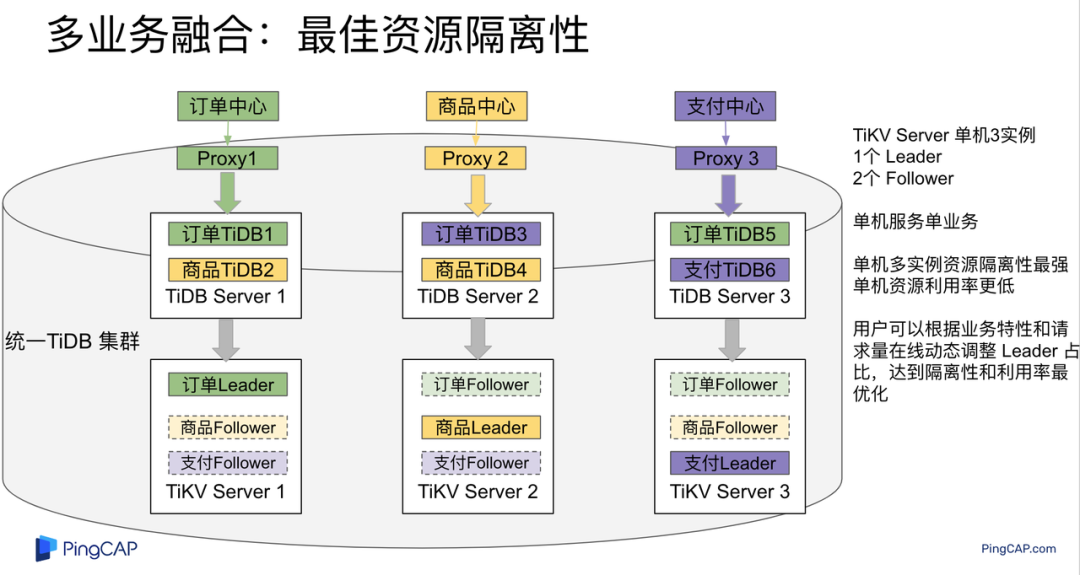\n多业务融合最佳隔离性\n\n架构说明:\n\n各实例部署模式与图 4.1 相同,使用 Placement Rules in SQL 控制单台 TiKV Server 中 3 个 TiKV 实例只有 1 个 TiKV 实例承担 Leader 角色支持业务读写,此时可以保证 TiKV Server 只为单个业务服务,达到最佳隔离性。用户可以基于业务特征在线动态调整多业务部署架构实现最佳资源利用率与最佳隔离性平衡。\n\n### 多业务融合架构:资源借用\n\n部分业务有大促需求,修改 Proxy 配置,让大促业务使用更多原本比较空闲的 TiDB 计算资源,提升业务数据计算能力。同时提前修改 Placement Rules in SQL 规则让大促相关的业务表分布在更多原本比较空闲的 TiKV 节点,以便提升大促表存储资源。等待大促结束再重新调整配置将计算和存储资源还给其它业务,让各业务资源重新保持隔离。\n\n### 多业务融合架构调整\n\n加上基础多业务融合架构,以上三种架构分别代表最佳资源利用率、性能冗余、最佳隔离性三种选择。推荐用户可以直接选择第一种部署模式,因为此部署模式简单易用资源利用率最高。接下来介绍如果配置 Placement Rules in SQL 实现 Leader 在线调整,实现不同业务资源利用率和隔离性动态平衡。具体实现方式如下:\n\n设置 TiKV Label :\n\n```\nserver_configs:\n pd:\n replication.location-labels: ['one_leader','two_leader',’region’]\ntikv_servers:\n - host: 172.0.0.1 \n config:\n server.labels: \n one_leader: order_leader\n two_leader: order_leader\n region: order\n - host: 172.0.0.2\n config:\n server.labels: \n one_leader: order_follower\n two_leader: order_leader\n region: order\n - host: 172.0.0.3\n config:\n server.labels: \n one_leader: order_follower\n two_leader: order_follower\n region: order\n```\n\nLabel 说明:Label one_leader 只有一个值为 order_leader , Label tow_leader 有两个值为 order_leader , Label region 有三个值为 order,基于以上规则再配合 Placement Rules in SQL 可以实现 Leader 在线分布调整,实现三个 TiKV 分别有 1 2 3 个 Leader。\n\n创建三个 Placement Rules in SQL 规则,分别实现最佳资源利用率、性能冗余、最佳隔离性部署架构\n\n```\n#最佳资源利用率规则:3 Leader\nCREATE PLACEMENT POLICY `p_order_three_leader` PRIMARY_REGION=\"order\" REGIONS=\"order\";\nalter table `order`.`order` PLACEMENT POLICY=p_order_three_leader;\n\n#性能冗余规则: 2 Leader\nCREATE PLACEMENT POLICY `p_order_two_leader` LEADER_CONSTRAINTS=\"[+two_leader=order_leader]\" FOLLOWER_CONSTRAINTS=\"{+two_leader=order_leader: 1,+two_leader=order_follower: 1}\";\nalter table `order`.`order` PLACEMENT POLICY=p_order_two_leader;\n\n#最佳隔离性规则: 1 Leader\nCREATE PLACEMENT POLICY `p_order_one_leader` LEADER_CONSTRAINTS=\"[+one_leader=order_leader]\" FOLLOWER_CONSTRAINTS=\"{+one_leader=order_follower: 2}\";\nalter table `order`.`order` PLACEMENT POLICY=p_order_one_leader;\n\n#资源借用:此处以删除 Placement Rules in SQL 规则为例,删除之后数据默认分布到所有 TiKV 实例\nalter table `order`.`order` PLACEMENT POLICY default;\n```\n\n分别为业务数据库表应用以上规则,可以实现 3 个 TiKV 实例只有一个、两个、三个 Leader 。并且可以为某个业务实现动态在线调整最佳隔离性、性能冗余、最佳资源利用率和资源借用。以便满足不同业务在线资源隔离性调整需求。推荐一般用户使用最佳资源利用率部署架构。\n\n\n\n## 在线调整业务资源组\n\n在[多业务融合方案 - 上篇](/blog/tidb-multi-service-integration-1)中提到中小库归集时如果某些业务流量发生变化,可以实现动态调整资源组资源,具体实现说明如下。\n\n\n### TiDB 资源组调整\n\n在多业务融合方案中使用 Proxy 来实现 TiDB 节点路由,确保不同资源组使用 TiDB 节点不相同。在中小库归集场景中,假设某个小业务(用户中心)近期请求量慢慢增加可以通过 TiDB 在线扩缩容和调整 Proxy 方式将此业务由共享资源组调整到独立资源组。\n\n参考 TiDB 集群扩缩容 文档,添加 TiDB scale-out.yaml 配置文件\n\n```\ntidb_servers:\n - host: 172.0.0.8\n ssh_port: 22\n port: 4000\n status_port: 10080\n deploy_dir: /data/deploy/install/deploy/tidb-4000\n log_dir: /data/deploy/install/log/tidb-4000\n - host: 172.0.0.9\n ssh_port: 22\n port: 4000\n status_port: 10080\n deploy_dir: /data/deploy/install/deploy/tidb-4000\n log_dir: /data/deploy/install/log/tidb-4000\n```\n\n执行扩容命令完成 TiDB 扩容\n\n```\n#1.检查集群存在的潜在风险:\ntiup cluster check scale-out.yaml --cluster\n\n#2.自动修复集群存在的潜在风险:\ntiup cluster check scale-out.yaml --cluster --apply \n\n#3.执行 scale-out 命令扩容 TiDB 集群:\ntiup cluster scale-out scale-out.yaml \n\n#4.查看集群状态\ntiup cluster display \n```\n\n参考官网 TiDB 与 HAProxy 最佳实践说明 ,添加新 HAProxy 实例,修改配置文件,监听新的 TiDB 实例。启动新 HAProxy 服务,修改应用连接地址为新 HAProxy 地址,即可完成应用从共享 TiDB 计算资源组迁移到独立 TiDB 计算资源组\n\n```\nlisten tidb-cluster # 配置 database 负载均衡。\n bind 0.0.0.0:4000 # 浮动 IP 和 监听端口。\n mode tcp # HAProxy 要使用第 4 层的传输层。\n balance leastconn # 连接数最少的服务器优先接收连接。`leastconn` 建议用于长会话服务,例如 LDAP、SQL、TSE 等,而不是短会话协议,如 HTTP。该算法是动态的,对于启动慢的服务器,服务器权重会在运行中作调整。\n server tidb-1 172.0.0.8:4000 check inter 2000 rise 2 fall 3 # 检测 4000 端口,检测频率为每 2000 毫秒一次。如果 2 次检测为成功,则认为服务器可用;如果 3 次检测为失败,则认为服务器不可用。\n server tidb-2 172.0.0.9:4000 check inter 2000 rise 2 fall 3\n```\n\n### TiKV 资源组调整\n\n参考 TiDB 集群扩缩容 文档,添加 tikv-scale.yaml 文件,注意需要设置 TiKV Label ,此文件以最简单的 TiKV Leader 均匀分布部署模式为说明\n\n```\ntikv_servers:\n - host: 172.0.0.10 \n config:\n server.labels: \n region: user\n - host: 172.0.0.11 \n config:\n server.labels: \n region: user\n - host: 172.0.0.12 \n config:\n server.labels: \n region: user\n```\n\n参考 TiDB 集群扩缩容 文档,使用 TiUP 扩展集群,将以上 TiKV 加入到原集群,再创建 Placement Rules in SQL 规则,将用户中心业务数据都存储在新的 TiKV 实例上。\n\n```\nCREATE PLACEMENT POLICY `p_user` CONSTRAINTS = \"[+region=user]\";\nALTER DATABASE `user` PLACEMENT POLICY=p_user;\n\n# 修改数据库规则之后还需要修改数据库下每张已经存在的表的规则\nALTER TABLE `user`.`user` PLACEMENT POLICY=p_user;\n\n# 查看表规则应用进度\nSHOW PLACEMENT;\n```\n\n等待所有表进度都为 scheduled 之后即表示表数据已经从老 TiKV 实例迁移到新的 TiKV 实例。也可以使用以下 SQL 检查 user 数据库数据具体存放位置\n\n```\nselect distinct t2.db_name,t2.table_name,t2.region_id,t3.peer_id,t3.is_leader,t1.address,replace(replace(t1.label,', \"value\"',''),'\"key\": ','') as label from information_schema.tikv_store_status t1,information_schema.tikv_region_status t2,information_schema.tikv_region_peers t3 where t2.db_name='user' and t2.region_id=t3.region_id and t3.store_id=t1.store_id order by 1,2,3,4;\n```\n\n通过以上说明实现了业务在线从共享资源组迁移到独立资源组,提升了业务资源隔离能力。也可以使用类似方式将某个业务从独立资源组迁移到共享资源组。\n\n## 总结\n\n本文进一步介绍了多业务融合之后如何基于 TiDB 的能力实现用户扩展需求,充分体现了 TiDB HTAP 、架构灵活、弹性扩缩容能力。\n\n- TiDB 强大的 HTAP 能力:可以非常简单实现实时全域数据强一致性分析和统一视图的能力,充分释放和挖掘实时全域数据价值。\n- TiDB 灵活的架构:业务希望调整 Leader 分布进一步提升隔离能力,在多业务融合场景下实现最佳资源利用率和最佳隔离性的平衡。\n- TiDB 弹性扩缩容:可以在线实现业务从共享资源组调整到独立资源组,提高资源隔离性,也可以实现业务容独立资源组调整到共享资源组,提高资源利用率。","date":"2023-02-14","author":"李振环","fillInMethod":"writeDirectly","customUrl":"tidb-multi-service-integration-2","file":null,"relatedBlogs":[{"relatedBlog":{"body":"> 李振环,PingCAP 行业解决方案架构师,主要关注新经济行业和合作伙伴生态。有多年分布式数据库和大数据实战经验,之前在贝壳金服担任大数据平台技术负责人,负责贝壳金服大数据整体架构。\n\n多业务融合即将多个业务系统部署在同一套 TiDB 集群中,如何提高资源隔离能力确保不同业务之间不相互影响是多业务融合方案设计要点。如下图所示,本文主要介绍如何使用单 TiDB 集群支持多业务,并且保证业务之间隔离性。\n\n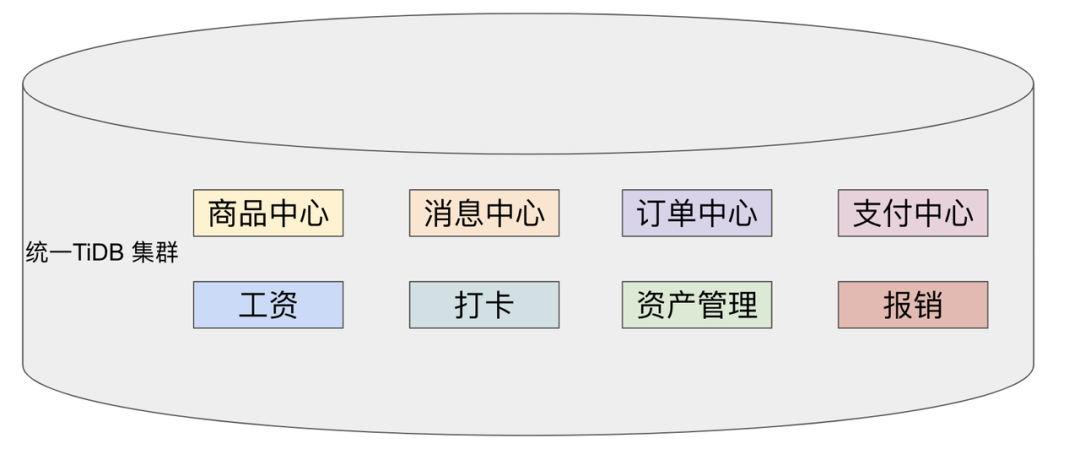\n多业务融合方案说明\n\n本文将介绍以下内容: \n- TiDB 资源控制和隔离:此部分主要介绍 TiDB 与 NUMA 和 cgroup 技术结合实现单机多实例部署时资源控制和隔离,以及 TiDB 自带的资源控制参数;\n- TiDB 数据隔离:此部分主要介绍 TiDB Label 与 Placement Rules in SQL 技术实现数据存储隔离;\n- 基于上述资源控制和数据隔离技术实现单集群多业务融合架构;\n- 方案收益分析;\n- 监控和报警隔离说明:融合部署的业务应用可以根据重要性分别配置监控和报警。\n\n## TiDB 资源控制和隔离\n\n### NUMA\n\n#### NUMA 介绍\n\nNUMA(Non-Uniform Memory Access) 非均匀内存访问架构是指多处理器系统中,内存的访问时间是依赖于处理器和内存之间的相对位置的。CPU 访问“本地” Memory 时速度更快,CPU 跨节点访问“远程” Memory 时速度较慢。\n\n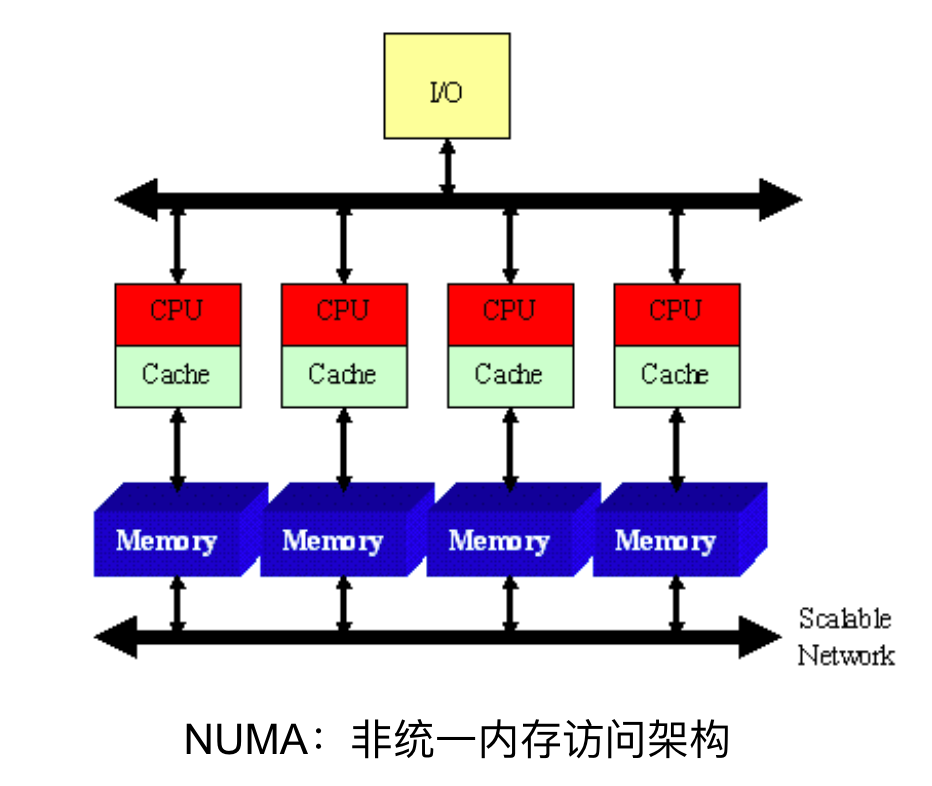\nNUMA 架构\n\nUMA(Uniform Memory Access) 均匀内存访问架构则是与NUMA相反,所以处理器对共享内存的访问距离和时间是相同的。\n\n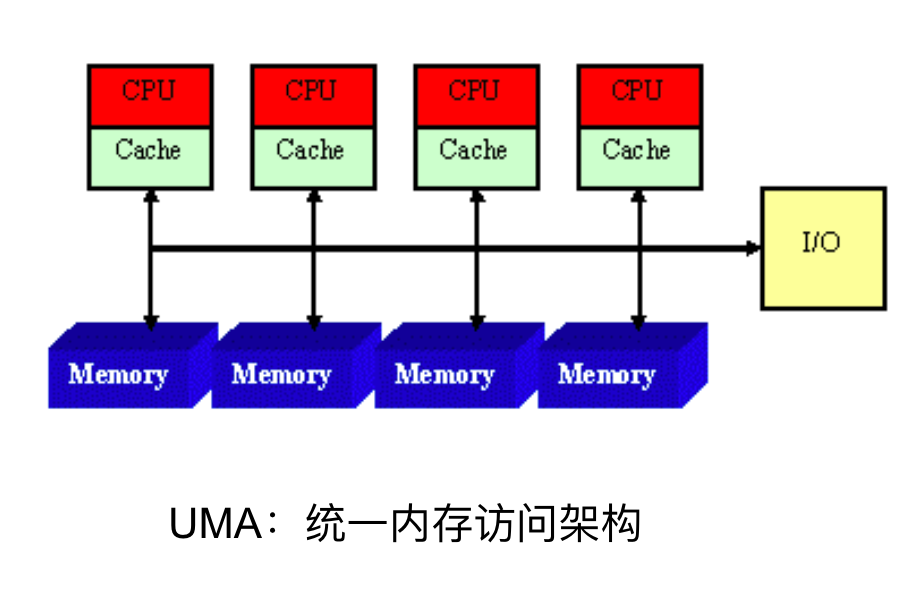\nUMA 架构\n\n可以使用 numactl -H 查看服务器 NUMA 分布。如下图所示:NUMA node 0 包含 0 2 4 6 8 等序号 CPU,包含 98210 MB “本地”内存;NUMA node 1 包含 1 3 5 7 9 等序号 CPU,包含 98210 MB “本地”内存。最后 node distance 显示 NUMA node 0 访问“本地”内存耗时 10 个单位时间,访问“远程” NUMA node 1 内存耗时 21 个单位时间。\n\n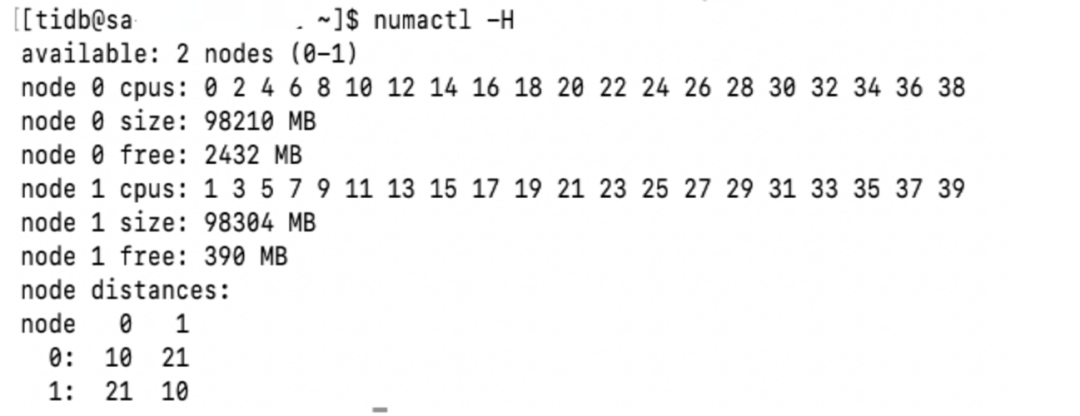\n查看 NUMA Node\n\n#### NUMA 与 TiDB 结合\n\nTiDB 支持与 NUMA 结合使用,在 TiUP 配置文件中可以给 TiDB,TiKV 等实例配置对应的 NUMA Node。\n\n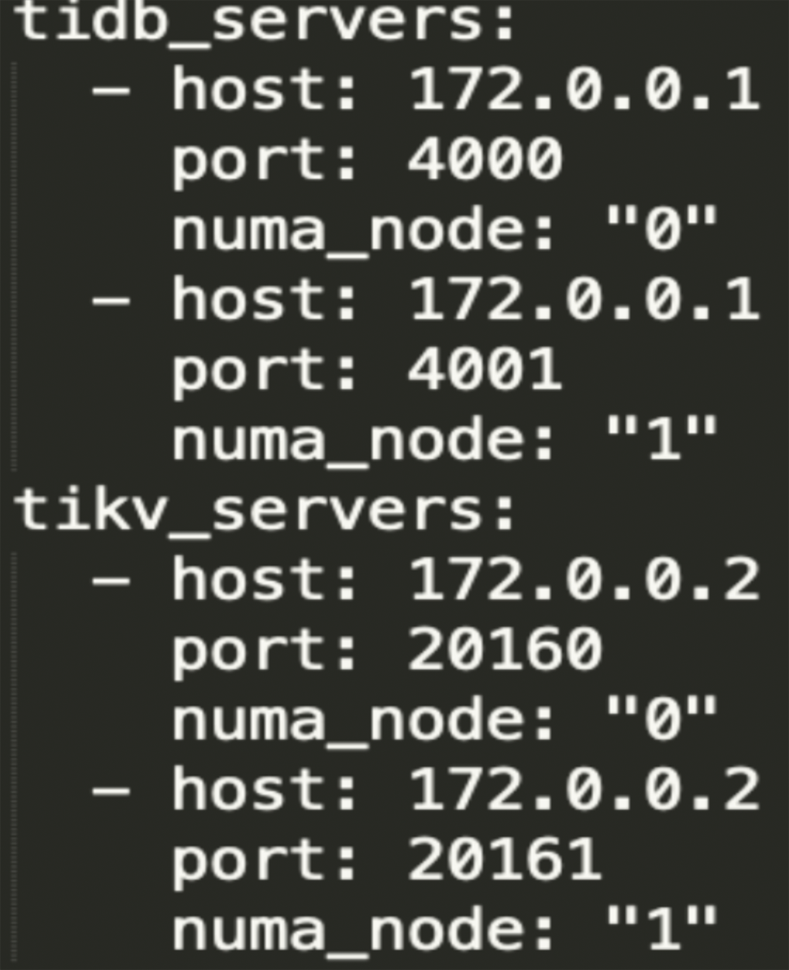\nNUMA 配置\n\n配置 NUMA node 之后使用 TiUP 启动集群,查看启动命令。\n\n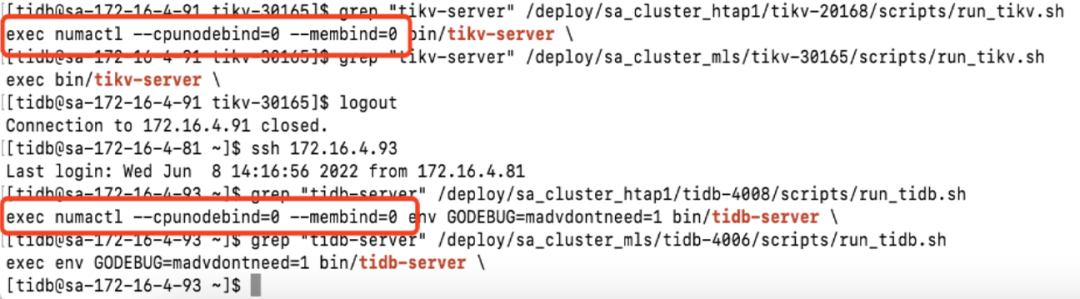\nNUMA 启动命令\n\n启动命令包含--cpunodebind=0 表示此进程只使用 NUMA node 0 的 CPU \n\n启动命令包含--membind=0 表示此进程只使用 NUMA node 0 的 Memory \n\n使用上图 TiUP 配置之后可以实现 TiDB 4000 端口实例和 TiKV 20160 端口实例只使用 NUMA node 0 的 CPU 和 Memory ,TiDB 4001 端口实例和 TiKV 20161 端口实例只使用 NUMA node 1 的 CPU 和 Memory ,确保单机不同进程之间 CPU 和 Memory 隔离。 \n\n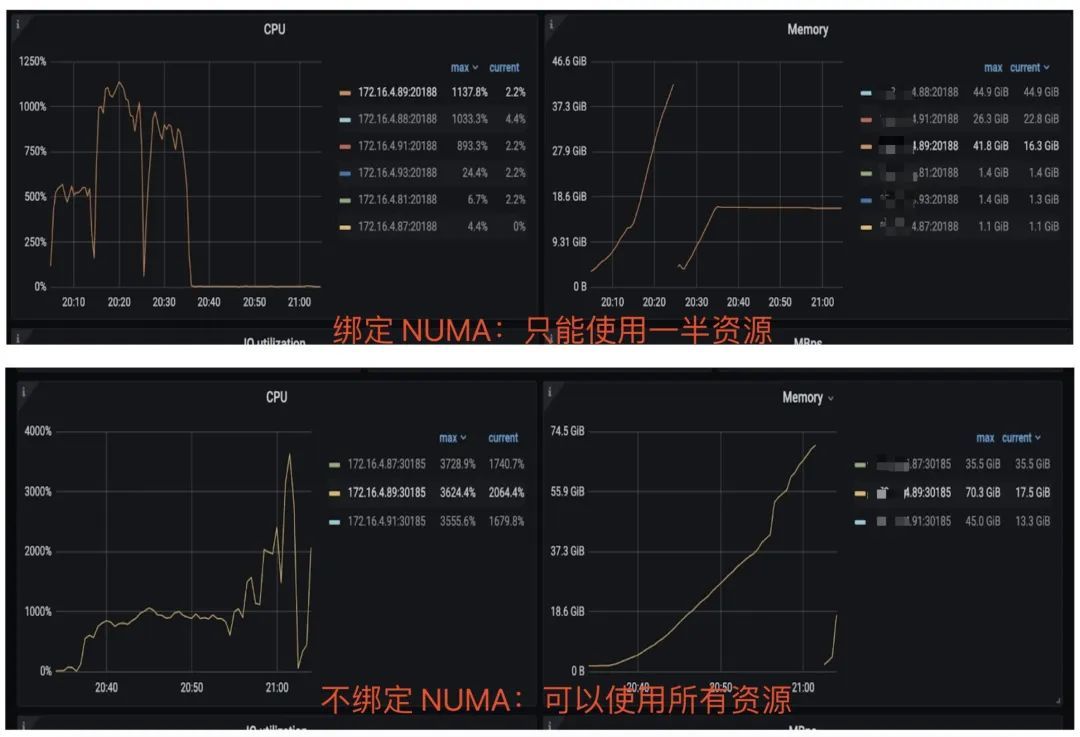\nNUMA 配置效果\n\n如上图所示:同一批服务器每个服务器 40C / 80G 资源,并有两个 NUMA Node 。图下半部分:集群 TiKV 不绑定 NUMA,在 TiDB 集群中跑压测时 TiKV 可以使用全部 36C / 70 G 资源。图上半部分:集群 TiKV 绑定 NUMA ,在 TiDB 集群中跑压测时 TiKV 只能使用 12C / 37G 资源即总资源一半。由此可见使用 NUMA 之后可以控制 TiKV 只使用单个 NUMA Node 资源。\n\n### cgroup 介绍\n\ncgroups 是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制。容器 Docker 就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。 \n\nTiDB 可以很简单在 TiUP 配置文件中与 cgroup 结合使用。实现对应 TiDB / TiKV 等实例只使用受 cgroup 控制的资源总量,实现单机不同进程之间 CPU 和 Memory 隔离。 \n\n为需要的 TiDB 和 TiKV实例分别添加以下配置 \n\nresource_control: \nmemory_limit: 32G #控制 TiDB 和 TiKV 进程使用 32G 内存 \ncpu_quota: 1600% #控制 TiDB 和 TiKV 进程使用 16 个 CPU \n\n添加配置后最终会在对应的 tidb 服务器生成对应的 systemd service 文件:例如 TiDB 文件:/etc/systemd/system/tidb-4000.service。可以查看 service 文件中 cgroup 对应的资源控制参数。 \n\n### TiDB 参数资源控制\n\n#### TiDB 计算资源控制\n\nTiDB 自带 CPU 和 Memory 控制参数,确保单机多实例部署时资源隔离。\n\n```\n TiDB CPU 控制\n [performance]\n max-procs=16 \n TiDB 内存控制\n [performance]\n tidb_server_memory_limit = \"32GB\" #6.4版本引入参数,当 tidb-server 实例的内存用量达到 32 GB 时,TiDB 会依次终止正在执行的 SQL 操作中内存用量最大的 SQL 操作,直至 tidb-server 实例内存使用下降到 32 GB 以下。\n```\n\n#### TiKV 存储资源控制\n\nTiKV 自带 CPU 和 Memory 控制参数,确保单机多实例部署时资源隔离。\n\n```\n server_configs:\n tikv: # Total CPU 16 Memory 32GB\n # TiKV CPU由读:readpool,写:raftstore,调度:storage,其它compact和flush不是时刻发生可以忽略\n server.grpc-concurrency: 5 #Default value 5: 不会占用 CPU 资源,属于 IO 密集型操作\n raftstore.apply-pool-size: 2 #Default value 2\n raftstore.store-pool-size: 2 #Default value 2 \n readpool.unified.max-thread-count: 12 #Default value:Total CPU * 80% \n storage.scheduler-worker-pool-size: 6 #Default value: 总CPU大于等于16时默认8,否则为4\n # TiKV 内存由三部分组成,block-cache/write-buffer/page cache。block和write可以控制,其余都是page\n readpool.storage.use-unified-pool: true\n readpool.coprocessor.use-unified-pool: true\n storage.block-cache.capacity: 14GB #Default value: Total Memory * 45%\n```\n\n#### 使用资源隔离方案部署集群\n\n通过上面 NUMA 、 cgroup 和 TiDB 本身资源参数控制,可以实现单机多实例部署,并确保隔离性。可以利用以上技术实现 6 台服务器 3 集群部署,不同业务使用不同 TiDB 集群确保资源隔离性。 \n\n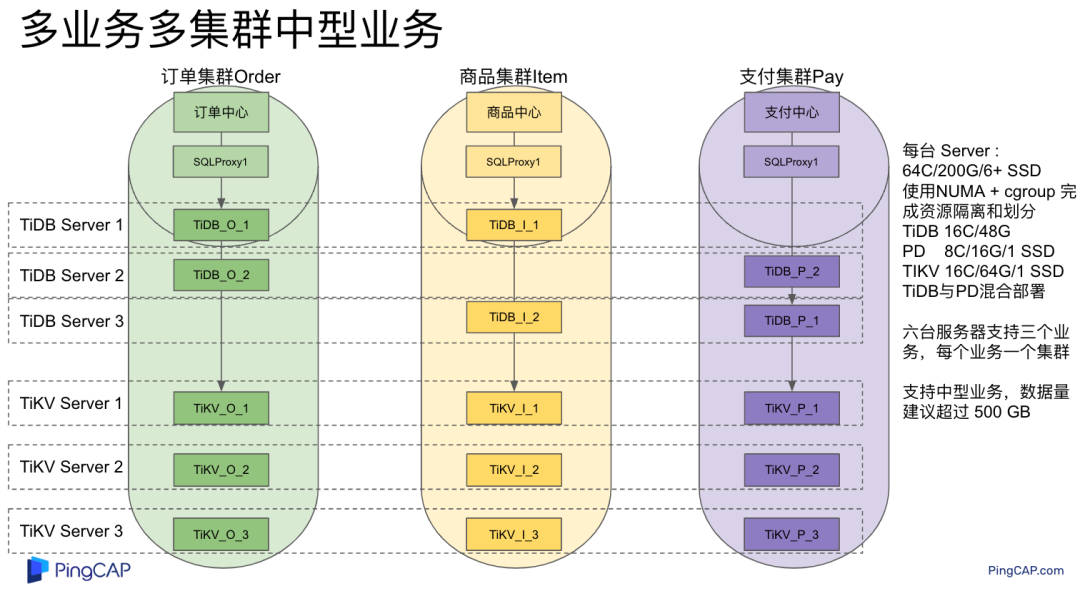\n多业务多集群部署架构\n\n架构说明: \n六台服务器,每台 64C/200G/3 * 2.5 TB NVME SSD。 \n选择其中三台服务器通过 NUMA + cgroup 等隔离方式部署 TiDB / PD / 监控。三台 Server 一共部署:TiDB * 6 (16C/48G) , PD *9 (8C/16G/1 SSD) , 监控*3 (8C/16G) \n选择另外三台 Server 部署 TiKV ,三台 Server 一共部署 TiKV * 9 (16C/64G/1 SSD) \n分别选择 2 TiDB + 3 PD + 3 TiKV + 1 监控部署订单、商品、支付三个集群,业务系统通过 Proxy 访问 2 个 TiDB 实例实现高可用。如上图所示需要确保单集群 3 TiKV 和 2 TiDB 需要分布在不同的服务器中。综上使用六台服务器实现 3 套 TiDB 集群部署,并确保高可用和业务完全隔离。\n\n## TiDB 数据隔离\n\nTiDB 提供了 Label 体系让 TiKV 数据分布更均匀并提供 TiDB 集群容灾能力,另外 TiDB 还提供了 Placement Rules in SQL 能力让用户可以通过 SQL 控制数据存放 TiKV 位置。\n\n### Label\n\n为了提升 TiDB 集群的高可用性和数据容灾能力,可以为 TiKV 节点配置 Label ,让 TiKV 尽可能在物理层面上分散,例如让 TiKV 节点分布在不同的机架甚至不同的机房。PD 调度器根据 TiKV 的拓扑信息,会自动在后台通过调度使得 Region 的各个副本尽可能隔离,从而使得数据容灾能力最大化。 \n\n例如在 TiUP 配置文件配置以下 Label 信息 \n\n```\n server_configs: \n pd:\n replication.location-labels: ['group', 'region']\ntikv_servers:\n - host: 172.0.0.1\n config:\n server.labels: \n group: order\n region: order\n - host: 172.0.0.2\n config:\n server.labels: \n group: order\n region: order\n - host: 172.0.0.3\n config:\n server.labels: \n group: order\n region: order\n```\n\n搭建集群之后可以在 dashbroad 看到集群对应拓扑图。\n\n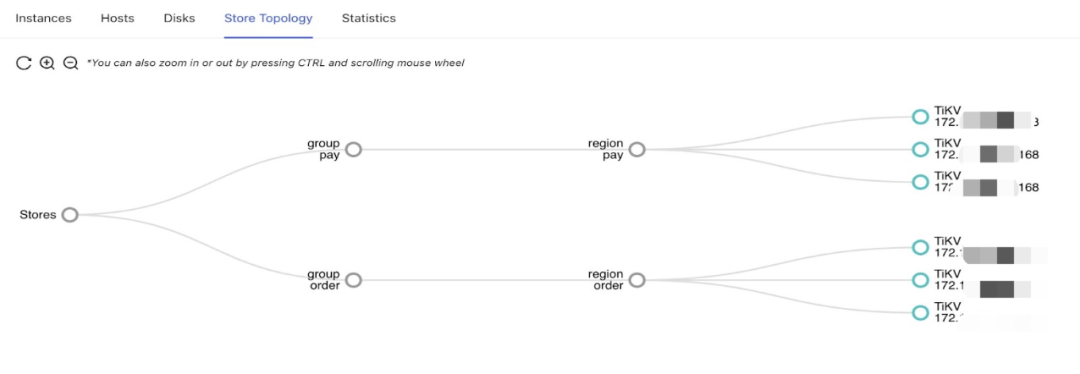\nLabel 构建拓扑\n\n### Placement Rules in SQL\n\nPlacement Rules in SQL 将 PD 的调度能力通过 SQL 暴露给用户,用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。通过该功能,用户可以将表和分区指定部署至不同的地域、机房、机柜、主机。适用场景包括低成本优化数据高可用策略、保证本地的数据副本可用于本地 Stale Read 读取、遵守数据本地要求等。 \n\n使用 Placement Rules in SQL 控制数据存放 TiKV 实例: \n\n```\nCREATE PLACEMENT POLICY `p_order` CONSTRAINTS = \"[+region=order]\";\nALTER DATABASE `order` PLACEMENT POLICY=p_order;\n```\n\n以上 SQL 将 order 数据库与 tikv label 为 region : order 的三个实例绑定,order 数据库下所有表数据都只会存放在 172.0.0.1:20160 172.0.0.2:20160 172.0.0.3:20160 三个实例中。 \n\n使用 Placement Rules in SQL 控制 Leader 和 Follower 存放位置 \n\n```\nCREATE PLACEMENT POLICY 'p_item' PRIMARY_REGION=”item_leader” REGIONS=”item_leader,item_follower”;\nALTER DATABASE item PLACEMENT POLICY=p_item;\n```\n\n以上 SQL 将 item 数据库与 p_item 规则绑定,将 item 数据库数据 Leader 副本存放在 label 为 region: item_leader 的 TiKV 实例中,Follower 副本存放在 region:item_leader 和 region:item_follower 的 TiKV 实例中。\n\n## 多业务融合架构\n\n### 多业务融合架构\n\n基于以上介绍的 TiDB 单机资源控制隔离能力与数据隔离能力,可以设计以下架构实现 TiDB 单集群多业务融合部署并保证隔离性。具体架构如下图所示: \n\n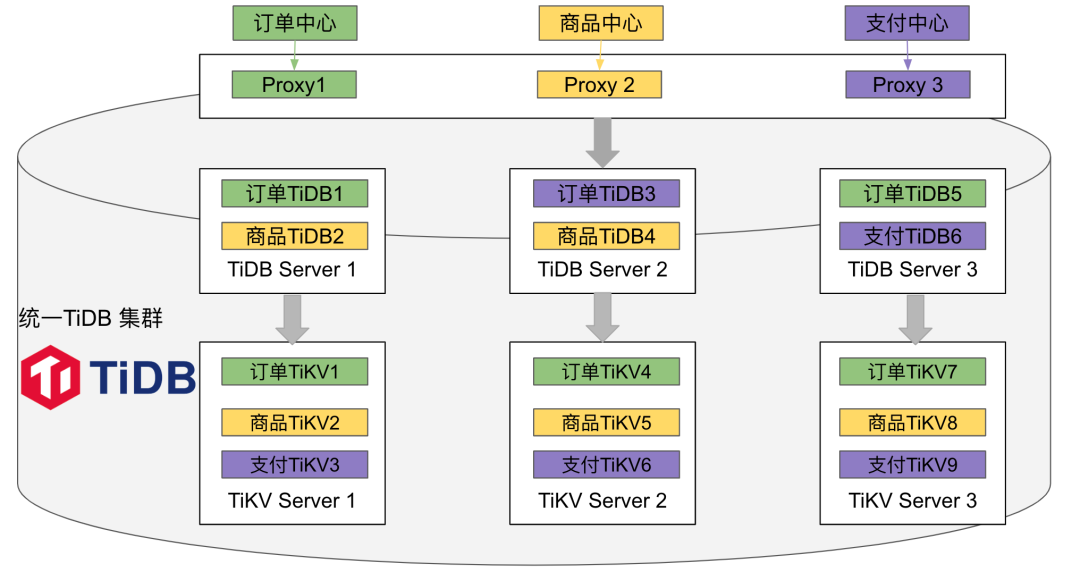\n多业务融合架构\n\n#### 单机多实例隔离\n\n上图架构中一共 6 台服务器每台服务器部署多个实例,使用 NUMA + cgroup 技术实现单机多实例资源隔离,具体说明如下: \n3 台 TiKV Server (48C/200G/3 * 1.5+ TB NVME SSD),通过 cgroup 隔离能力在每个服务器上部署 3 个 TiKV 实例,每个实例 16C/64G/1*SSD; \n3 台 TiDB Server (48C/200G/1 NVME SSD),通过 NUMA 隔离能力在每台服务器上部署 2 个 TiDB 实例,每个实例16C/48G ;另外每台服务器上再部署 PD 实例,每个实例 8C/16G/1 SSD。\n\n#### TiDB 计算资源隔离\n\n由于 TiDB 单实例没有高可用,一般会使用应用连接 Proxy 服务,Proxy 后面连接多个 TiDB 实例实现 TiDB 计算高可用,在多业务融合架构中同样可以使用 Proxy 来实现高可用和计算资源隔离,具体说明如下: \n绿色订单业务使用绿色 Proxy1 将订单业务请求固定路由到绿色 TiDB 1 和 TiDB 5 实例上; \n黄色商品业务使用黄色 Proxy2 将商品业务请求固定路由到黄色 TiDB 2 和 TiDB 4 实例上; \n紫色支付业务使用紫色 Proxy3 将支付业务请求固定路由到紫色 TiDB 3 和 TiDB 6 实例上; \n通过 Proxy 流量固定转发不同 TiDB 实例方式实现高可用和隔离性,确保不同颜色业务使用不同颜色 TiDB 计算实例。\n\n#### TiKV 存储资源隔离\n\n使用 Placement Rules in SQL 可以完成存储资源隔离,具体说明如下: \n创建订单数据放置规则,将绿色订单业务数据固定存储在绿色 TiKV 1 4 7 实例上; \n创建商品数据放置规则,将黄色商品业务数据固定存储在黄色 TiKV 2 5 8 实例上; \n创建支付数据放置规则,将紫色订单业务数据固定存储在紫色 TiKV 3 6 9 实例上; \n通过为不同业务创建独立 Placement Rules in SQL 规则,确保不同颜色业务数据放置在不同颜色 TiKV 存储实例。 \n\n具体业务和资源组关联 Placement Rules in SQL 如下:\n \n```\n# 创建规则并应用到 order 数据库,将 order 数据库数据存储在 label 为 region : order TiKV 实例中\nCREATE PLACEMENT POLICY `p_order` CONSTRAINTS = \"[+region=order]\";\nALTER DATABASE `order` PLACEMENT POLICY=p_order;\n```\n\n#### 资源隔离总结\n\n综上使用 NUMA 和 cgroup 实现单机多实例资源控制和隔离,使用 Proxy 实现 TiDB 计算隔离,使用 Placement Rules in SQL 实现存储隔离,确保多个颜色业务使用对应颜色资源组,不同颜色资源组之间资源隔离,最终实现多业务融合且隔离部署。 \n\n此时所有 TiKV 实例都可以承担 Leader 角色,承担业务读写请求,此时资源利用率最高。 \n\n大部分用户使用以上架构即可完成大部分业务融合部署,并保证计算和存储资源隔离性。也有小部分用户和业务希望更强的隔离能力,参考 TiDB 官网环境搭建硬件说明,不同组件需要使用不同配置服务器,如果有适配的机型(如 PD 服务器 8C/16G/1 SSD),可以使用单机单实例部署,提升隔离性。如果没有适配的机型,也可以选择调整多业务融合架构中 TiKV Leader 分布,在继续使用单机多实例部署的情况下提升隔离性。我们将在后续文章中具体介绍。 \n\n### 中小业务融合架构\n\n之前章节都是分析多个中型业务(200G+)使用独立资源组实现多业务融合,对于超大型数据量的重要业务建议使用单集群。接下来分析一下小型业务如何使用多业务融合方案。 \n\n传统 MySQL 中,对于多个小型业务会选择直接在单个 MySQL 实例混合部署,在 MySQL 中创建多个 database 支持不同业务,此时多个小业务总 QPS 和业务量都在单个 MySQL 能力边界内,多个小业务都可以正常支持业务,隔离性不需要考虑。但是当某个业务激增时 MySQL 架构则无法快速在线扩展数据库,存在扩展性隐患。 \n\n在多业务融合方案中对于小型业务也采用类似 MySQL 混合部署的模式,将多个小型业务混合部署在单个资源组中,一个资源组包含 2 个 TiDB 实例和 3 个 TiKV 实例,其它中小型业务部署在其它资源组中,资源组之间保证资源隔离,资源组内部资源共享。具体部署架构图如下: \n\n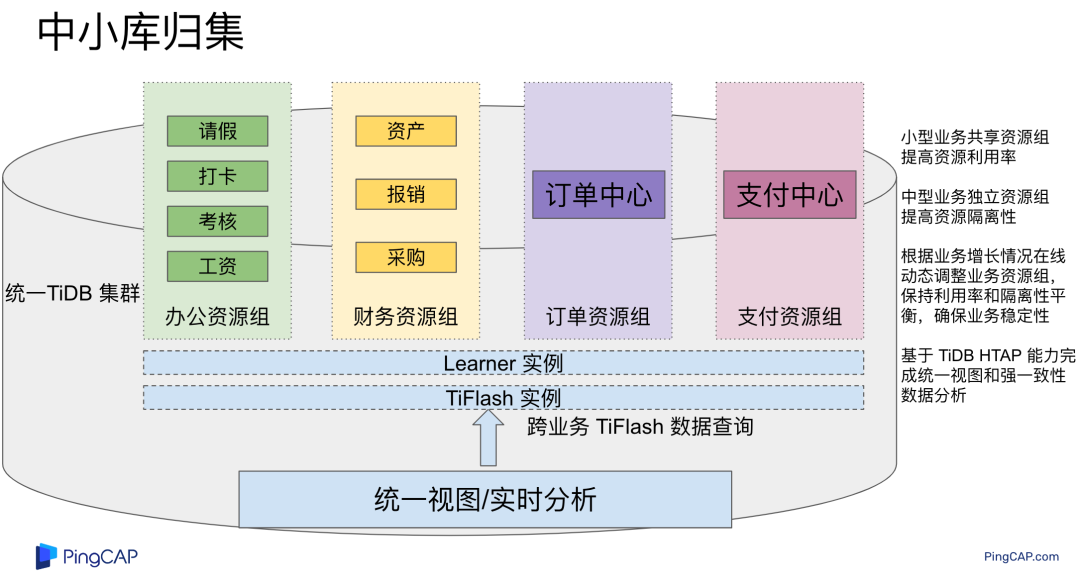\n多业务融合中小库归集\n\n如上图所示,请假、打卡、考核、工资等办公类系统 QPS 和业务量低,并且都属于办公类需求,都归属在办公资源组(2 TiDB + 3 TiKV)。同理资产、报销、采购归属在财务资源组,订单和支付 QPS 高,业务量大使用独立的资源组。多个小业务共享资源组提高了资源利用率,中型业务使用独立资源组提高资源隔离性,更重要的是利用 TiDB 在线动态扩展能力,当业务流量发生变化时可以在线动态将某个业务从共享资源组调整到独立资源组、从独立资源组调整到共享资源组以及如何在业务之间资源借用。很好地解决了 MySQL 混合部署时资源不能动态扩缩容的问题。 \n\n最后还可以借助 TiDB HTAP 的能力执行跨业务实时数据分析和统一视图,实现全域数据强一致性关联分析,实时洞察公司所有业务,了解公司每一笔金额来源和去处。\n\n## 方案收益分析\n\n多业务融合方案可以实现多个中小业务使用单集群,此方案可以为客户带来以下收益:\n- 降低起始环境成本\n- 节约总体硬件成本\n- 降低多集群运维压力\n- HTAP 全域数据关联分析\n\n### 降低起始环境搭建成本\n\n由于 TiDB 各个组件资源需求不一致,在本地化部署 TiDB 集群时,比较难找到正好适配的服务器搭建单服务器单实例,如某个服务器正好 8C/16GB/1 SSD 搭建 PD 服务,导致准备服务器成本提升。使用 NUMA 和 cgroup 能力则可以很好解决机型不适配的问题。使用 NUMA + cgroup 实现 3 台服务器搭建一套生产可用集群,具体如下图所示:\n\n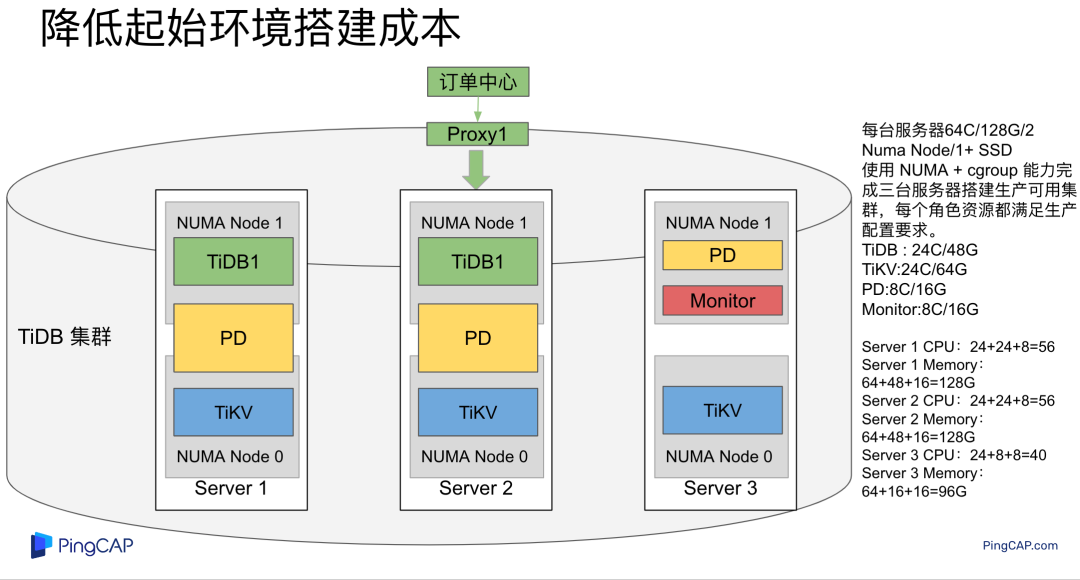\n多业务融合降低起始环境搭建成本\n\n具体部署说明: \n三台服务器,每台 64C/128G/2 NUMA Node/ 1+ SSDTiDB * 2 (24C/48G) 占用 Server 1 / 2 NUMA Node 1 节点; \nTiKV * 3 (24C/64G) 占用 Server 1 / 2 / 3 NUMA Node 0 节点; \nPD * 3 (8C/16G) 占用 Server 1 / 2 资源,第三个 PD 占用 Server 3 NUMA Node 1 节点; \n监控部署在 Server 3 NUMA Node 1 节点。 \n实现 3 台常见机型服务器搭建一套生产可用 TiDB 集群,每个实例都满足生产资源要求,并且基于 NUMA + cgroup 实现单机多实例之间资源隔离。对比 TiDB 官网需要 9 台恰好适配的服务器,使用以上 3 台通用服务器部署 TiDB 集群成本更低,采购更简单。降低新用户使用 TiDB 门槛。\n\n### 节约总体硬件成本\n\n对比目前一般用户目前 TiDB 集群部署方式,多业务融合一个中型业务只需要一个资源组资源(2 TiDB + 3 TiKV),并且利用单机多实例部署能力,一个资源组只需要 2 台服务器,可以显著节约硬件资源。假设每台服务器资源为 64C/128G/2 TB NVME SSD * 3,每台服务器部署 2 个 TiDB 实例或者 3 个 TiKV 实例,对比 MySQL 部署模式通用可以节约硬件。\n\n#### 小型业务硬件成本分析\n\n假设有 30 个小型业务,单个业务数据量 100 GB,峰值 QPS 2 K,小型业务数据数据高可用和稳定性要求偏低。MySQL 架构使用单机四实例部署,每个业务采用一主一备方式。则每个业务需要占用 2 / 4 = 0.5 台服务器资源、30个业务一共需要使用 15 台服务器。 \n\n同样业务使用多业务融合方式部署, 6 个小型业务占用一个独立资源组,此时每个资源组总存储为 600 GB,总 QPS 1.2 W,在独立资源组能力边界内。此时一个业务占用六分之一个资源组即每个业务需要使用 2/6=0.33 台服务器。对比 MySQL 节约 33% 硬件资源。\n\n#### 中型业务硬件成本分析\n\n假设有 30 个中型业务,每个业务数据量 600 GB,峰值 QPS 1.2 W,由于中型业务数据量较大,稳定性和数据高可用性要求高,MySQL 架构使用单机单实例部署,每个业务采用一主两备模式保证数据 3 副本高可用。此时每个业务需要 3 台服务器,30 个中型业务一共需要使用 90 台服务器。 \n\n同样业务使用多业务融合方式部署,每个业务独占一个资源组资源(2 TiDB + 3 TiKV),即 2 台服务器,30 个业务一共使用 60 台服务器左右。对比 MySQL 部署模式每个业务少占用一台服务器,节约 33% 硬件资源。由于 MySQL 扩展性问题,中型业务单表数据量超过几千万时 TiDB 具备性能优势。 \n\n#### 大型业务硬件成本分析\n\n假设有 5 个大型业务,每个业务数据量 3.6 TB,每个业务峰值 QPS 7 W,由于大型业务数据量大,稳定性和数据可用性要求高,MySQL 架构使用单机单实例分库分表方案,每个业务 6 个分片,并且使用一主两备模式保证数据 3 副本高可用,此时每个业务需要需要 18 台服务器,5 个大型业务一共需要 90 台服务器。 \n\n同样业务使用多业务融合方案部署,每个业务占用一个资源组资源,每个资源组包含 4 TiDB + 12 TiKV 即 2 + 4 = 6 台服务器(参考 官网 性能测试文档,3 TiDB + 3 TiKV 可以支持 40 W 点查QPS),5 个业务一共使用 30 台服务器,对比 MySQL 分库分表方案节约 66% 左右硬件资源。同时 TiDB 具备易运维、在线 DDL、支持跨分片查询等优势。 \n\n#### 超大型业务硬件成本分析\n\n假设有 1 个超大型业务,数据量 30 TB,业务峰值 QPS 50 W,MySQL 架构使用单机单实例分库分表方案,单个业务 50 个分片,并且使用一主两备模式保证数据 3 副本高可用,此时单个业务需要 150 台服务器。对于此类超大型业务不建议使用多业务融合方案部署,推荐使用单独部署 TiDB 集群,参考官网 性能测试数据此时一共需要 28 TiDB + 35 TiKV 即 14 + 12 = 26 台服务器,对比分库分表方案约节约 80% 硬件资源。 \n\n基于以上小、中、大、超大业务分析,所有情况 TiDB 计算利用率低于 15% ,TiKV 存储利用率低于 35 %,不存在超用情况。具体总结如下: \n\n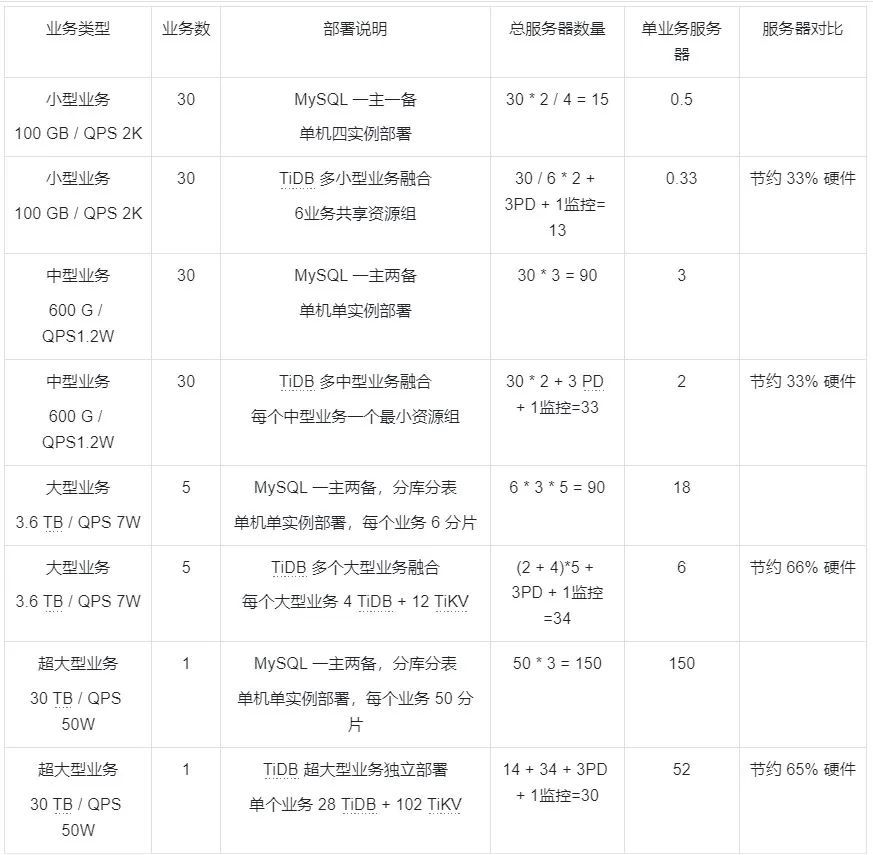\n\n### 降低多集群运维压力\n\n多个业务多集群需要耗费更多 DBA 运维人员支持数据库运维,比如可以统一升级集群、参数配置、数据备份、高可用、监控、报警、安全审计等。使用单集群支持多个业务可以大大减少运维成本。\n\n### HTAP 全域数据关联分析\n\n多业务多集群时,存在数据孤岛问题,想要跨业务关联数据或者实时分析时成本很高,使用多业务融合单集群之后可以很简单实现全域实时强一致性数据关联和分析。并保证分析和统一视图业务与业务隔离。也可以更简单实现跨业务分布式事务。\n\n### 资源借用\n\n某些大促活动时可以增加资源或者调整配置,让重要业务占用更多存储和计算资源保证大促平稳运行,等待大促结束之后再修改配置将资源再次均匀。\n\n### 收益总结\n\n在没有多业务融合之前 TiDB 分布式部署架构硬件成本偏高,一般用户会选择数据量较大的业务(大于 300 GB,服务稳定性要求高)使用 TiDB ,但是新客户对 TiDB 运维不熟悉,大业务上线 TiDB 存在运维风险和信心不足等问题。使用多业务融合之后用户可以在更多小型业务尝试使用 TiDB ,在小型业务运维过程中提升对 TiDB 数据库运维技能和产品信心,然后再利用 TiDB 弹性扩缩容能力迁入更多中型业务,或者使用独立集群迁入更多大型业务。有节奏的平稳的实现多个中小业务融合使用统一 TiDB 集群。 \n\n对比传统数据库多业务多集群方案,使用 TiDB 多业务融合方案,提升了用户数据高可用和扩展性,实现了全域数据实时关联分析,避免了多集群数据孤岛问题,同时降低了多集群硬件成本和运维压力。\n\n## 监控和报警隔离说明\n\n使用多业务融合之后多个业务使用单个 TiDB 集群,当某个 TiDB 组件出现报警或者瓶颈时之后无法直接定位到对哪个业务有影响,需要基于 Proxy 和 Label 拓扑才可以推算出问题实例对哪些业务产生影响。以上过程不够直观,部分业务希望可以直接以业务为视角查看监控和报警,具体实现方案如下:\n1. 复制此集群 Prometheus 、Grafana、Alertmanager 组件\n2. 修改以上监控报警组件端口配置,保证复制之后的各个组件可以独立启动\n3. 修改业务独立 Prometheus 中配置文件,删除其它业务对应实例,只保留单个业务对应的 TiDB 和 TiKV 实例。修改其它配置路径和数据位置配置信息,保证和原集群 Prometheus 配置不冲突\n4. 启动业务独立 Prometheus 服务\n5. 修改业务独立 Grafana 配置信息,保证和原集群 Grafana 配置不冲突\n6. 启动业务独立 Grafana 服务,并登陆服务\n7. 打开 Grafana DataSource 配置页面: http://172.0.0.1:PORT/datasources 修改应用 DataSource 中 Prometheus 地址为业务\n8. 此时可以看到业务独立 Grafana 监控页面只能看到此业务对应的 TiDB 和 TiKV 监控,实现了从业务视角实现监控。\n\n具体效果如下图所示: \n\n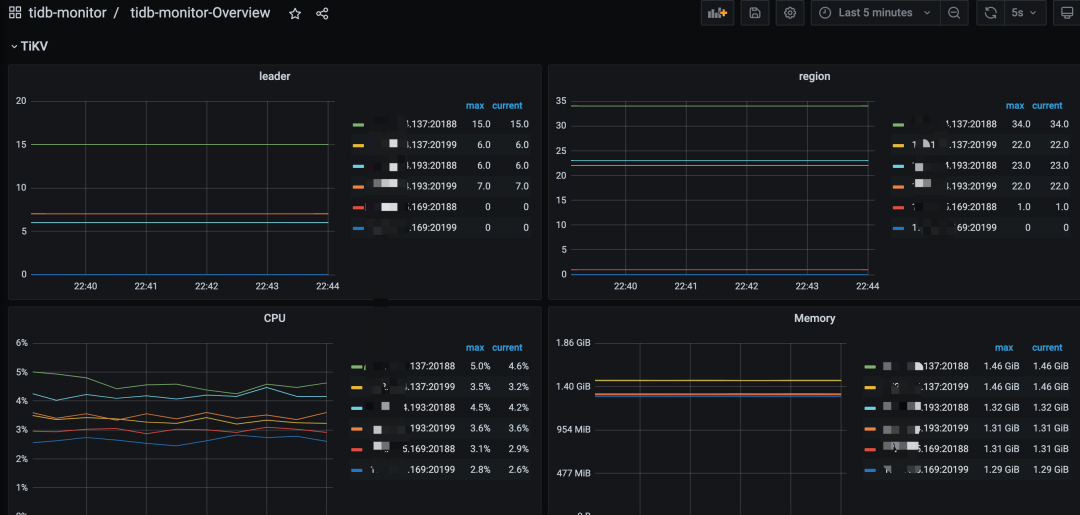\n原始集群 Grafana TiKV 监控\n\n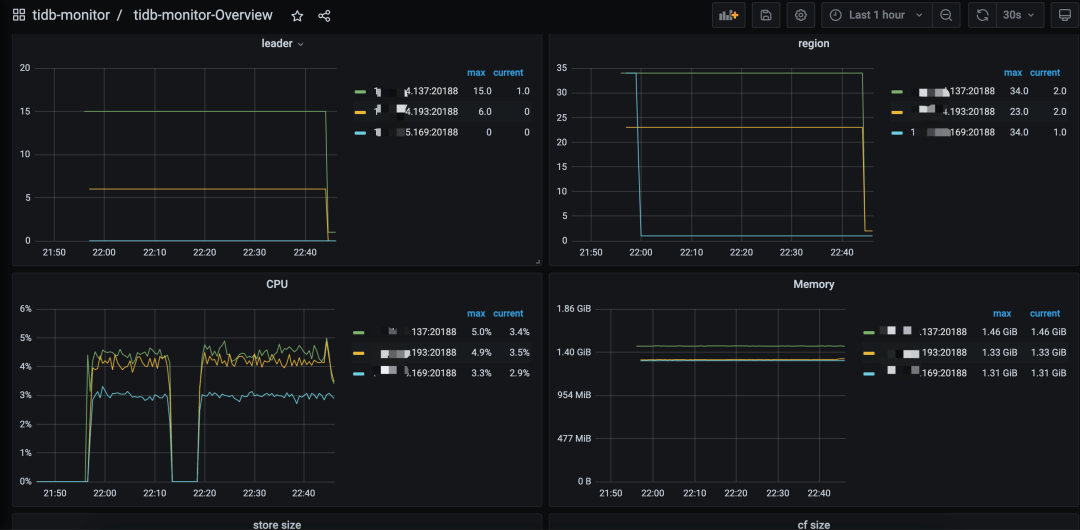\n业务独立 Grafana TiKV 监控\n\n对比两个图可以看到,原始集群 Grafana TiKV 有 6 个 TiKV 实例,业务独立 Grafana TiKV 只有 3 个 TiKV 实例,表示进入业务独立 Grafana 页面可以只看此业务下 TiDB 和 TiKV 监控信息,实现与其它业务监控隔离。报警也可以同理配置。\n\n## 总结\n\n本文先介绍了基于 NUMA 和 cgroup 方案实现 TiDB 单机多实例部署时资源隔离,之后介绍 TiDB 基于 Label 和 Placement Rules in SQL 的数据隔离技术,再基于 TiDB Proxy 请求路由和以上两个能力结合实现多业务融合技术架构,确保多业务单集群并且保证业务之间资源隔离,接着分析了多业务融合给用户带来的收益,最后用小篇幅说明多业务融合之后监控和报警如何实现隔离。 \n\n多业务融合之后,集群内包含多个业务,因此需要根据业务特点、业务间关联性等因素充分考虑集群内的业务规划,合理安排升级流程和验证。 \n\n隔离性总结: \n\n1. TiKV 数据隔离:Placement Rules in SQL 让用户可以通过 SQL 控制 PD 将不同业务数据调度存放到不同 TiKV 实例(资源组)\n2. TiDB 计算隔离:通过 Proxy 负载均衡控制不同业务请求不同 TiDB 实例\n3. 单机 TiDB、TiKV 多实例隔离:使用 NUMA、cgroup 和自带资源控制参数实现单机多实例部署架构下资源控制和隔离\n4. 监控隔离:通过多 Prometheus 和 Grafana 抓取和监控对应业务实例数据\n5. 架构特点:\n6. 架构灵活:可以在线控制 Leader 分布;在线调整业务使用共享、独立资源组,在线扩缩容资源组数量和资源组内部资源\n7. 粒度为实例级别:当前架构资源隔离到资源组级别,中型业务可以提前规划好业务使用资源组实例或者在线动态二次调整,小型业务共享使用资源组实例也支持在线动态二次调整\n8. 数据融合:一套集群数据天然打通,实现全域数据实时强一致性关联分析,并保证隔离性\n9. 省成本:节约硬件成本、节约运维成本\n\n对比传统数据库多业务多集群方案,使用 TiDB 多业务融合方案确保了多业务之间隔离性,TP AP 隔离性,同时提升了用户数据高可用、扩展性和 HTAP 数据分析能力,同时降低了多集群硬件成本和运维压力。\n\n后续预告:本文介绍了基础的多业务融合架构,后续会继续阐述多业务融合与 HTAP 能力结合、动态 Leader 分布调整和在线业务资源组调整等增强能力。","author":"李振环","category":1,"customUrl":"tidb-multi-service-integration-1","fillInMethod":"writeDirectly","id":482,"summary":"多业务融合即将多个业务系统部署在同一套 TiDB 集群中,如何提高资源隔离能力确保不同业务之间不相互影响是多业务融合方案设计要点。本文主要介绍如何使用单 TiDB 集群支持多业务,并且保证业务之间隔离性。","tags":["多业务融合"],"title":"方案精讲丨TiDB 多业务融合方案(上)"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}