{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/tidb-in-guosen-securities",
"result": {"pageContext":{"blog":{"id":"Blogs_335","title":"TiDB 在国信证券海量数据高并发场景中的实践","tags":["用户实践","高并发","服务可观察"],"category":{"name":"案例实践"},"summary":"本文讲述了 TiDB 在国信证券海量数据高并发场景中的实践。国信证券从 2020 年 6 月开始接触 TiDB,从技术预研到第一个业务上线大约花了半年时间。第一个上线的业务是金太阳帐单,后面陆续在数据中台、服务观测等系统中应用。","body":"> **作者介绍** \n**陈培新**,参与国信证券基础平台研发工作(DevOps、微服务治理、Serverless)\n\n\n国信证券是一家全国性大型综合类证券公司,在 118 个城市和地区共设有 57 家分公司、185 家营业部,根据中证协发布的数据,近年来国信证券的总资产、净资产、净资本、营业收入、净利润等核心指标排名行业前列。\n\n国信证券从 2020 年 6 月开始接触 TiDB,从技术预研到第一个业务上线大约花了半年时间。第一个上线的业务是金太阳帐单,后面陆续在数据中台、服务观测等系统中应用。从只在东莞主机房的 TiDB 部署到 2021 年 9 月实现 TiDB 多机房的部署,并启动国产海光 x86 服务器的试点工作,国信证券在开源 NewSQL 数据库的探索和应用层面,积累了丰富的实践经验。目前,**国信证券共有 7 个 TiDB 集群,节点数量 109 个,最大表 100 亿,支撑了托管、经纪和自营等业务**。\n\n## 从 0 到 1,国信金太阳引入 TiDB\n\n身处互联网企业,大家可能跟富途牛牛接触的比较多。国信金太阳跟富途牛牛类似,它提供证券交易、理财和咨询相关的服务。我们使用证券软件最主要的功能就是交易,用户在做交易的时候,关注更多的是收益率以及什么时候去买卖股票,用户可以根据证券软件提供的功能对所有的交易做分析。国信金太阳的用户数大概有一千万左右,国信有一个大数据平台,存储了所有用户历年的交易数据,账单存量数据有一百多亿,清仓股票数据量大概是十亿,整个帐单和清仓股票增量数据大概是二十亿每年。\n\n下图是国信金太阳的数据服务架构。金太阳 App 直接连金太阳后端,后端架构基于国信自研的 gRPC 微服务框架构建。跟大多数券商系统一样,金太阳后端对接柜台系统,里面有交易、帐户、清算等各种后台应用。所有数据最后会推送到数据中心,数据中心每天或每周都会做跑批。跑批完之后,会将相关的数据推送到前端的数据库中,用户通过 App 端的查询服务来直接查询这个数据库,从而获取相关的帐单以及清仓股票的数据。\n\n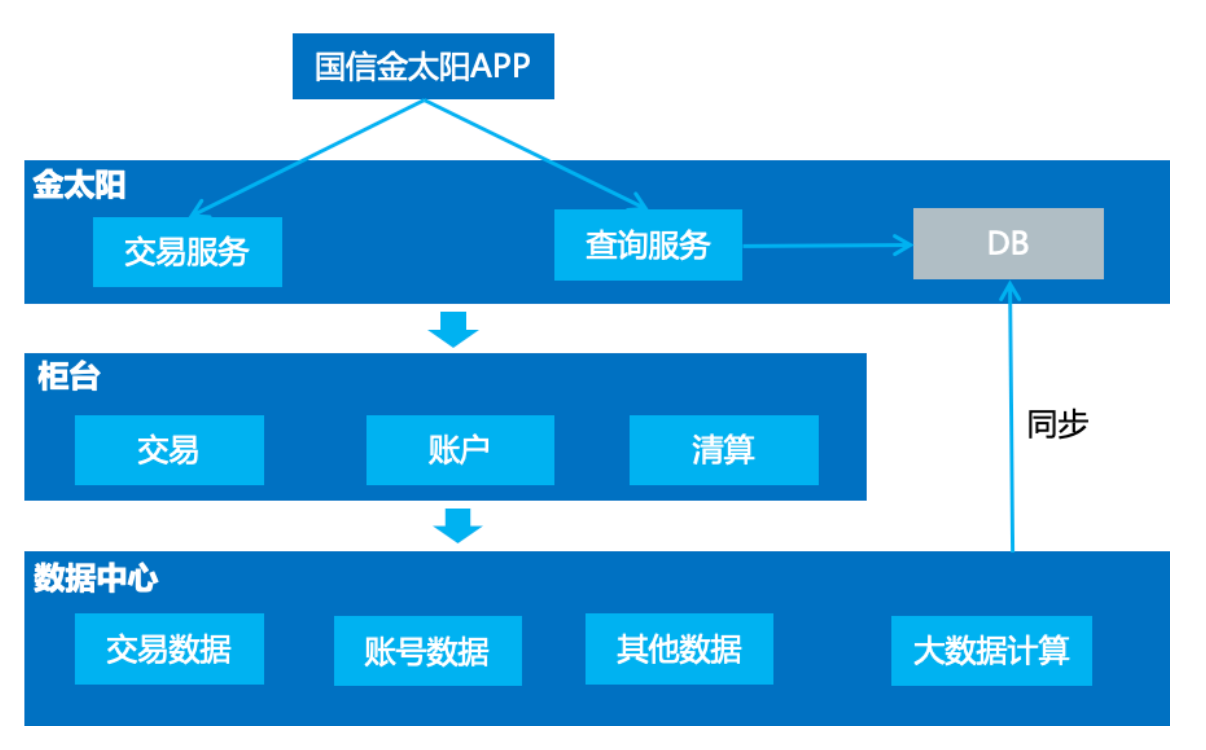\n\n图:国信金太阳数据服务架构\n\n整个账单经历了三个版本,账单 1.0 我们可以称它为**刀耕火种**的时代。在 1.0 版本的时候,只支持一年账单的查询,使用的是单库单表 SQL Server。具体是怎么实现的?首先,数据中心每天会将数据同步到一张临时表中,然后进行数据转换的服务,这个临时表的数据会加到正式表里面,正式表里面保存的是一年的数据量。在单库单表的情况下,通过一个中间程序将所有一年的数据都压缩到某一列里面去,里面是一个 JSON 字符串,存的是一年 365 天的数据。那如果新一天有新数据来了怎么办?这边会起一个临时任务,将新的一天推过来的数据压入到这个 JSON 里面去,再倒推 365 天,把以前最早那天的数据清除,最后再写到正式表里面去。可以看到,这其实是一个非常原始的实现。为什么要使用 JSON 这种格式?因为我们的数据用户量大概有一千多万,如果是每天存一行的话,用单库单表肯定是 hold 不住的。所以一开始,我们用了一个非常取巧的方式,将 360 多行给它并了一行,这样的话整个表的数据量将近有一千多万,查询效率还可以。\n\n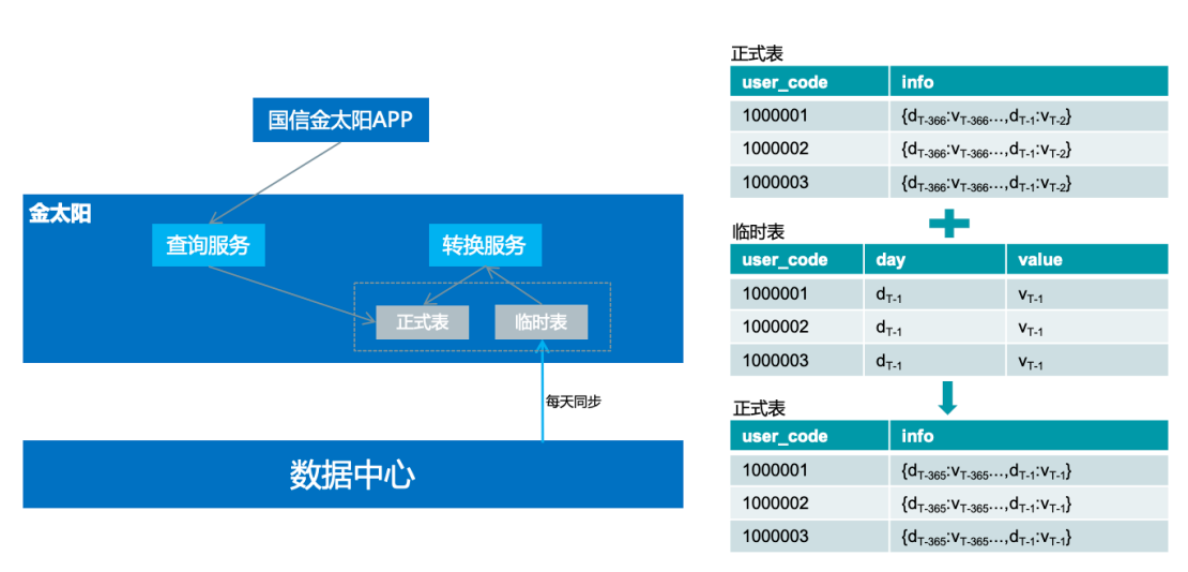\n\n图:账单 1.0 单库单表实现方式\n\n这种方式面临的问题是:业务上,用户是希望查询更长时间的数据,比如五年,使用单表的话,这一项其实是难以满足的。技术上,数据查询以及后续的更新压力大,难以扩展,有时候会出现数据更新出错,第二天用户来查询的时候,查到的数据就不准确了。\n\n为了应对这些业务和技术难点,国信在账单 2.0 版本使用 sharding-jdbc 来做分库分表。在引入这个技术的时候,我们也听说了 TiDB,考虑到**证券业务对稳定性要求较高**,当时对 TiDB 稳定性还有一定的担忧,所以选择了 sharding-jdbc。做了分库分表之后,可以支持 5 年帐单的查询,使用了 16 台 MySQL,总共分了 512 张表。数据中心与分库分表是如何进行同步的?数据中心还是和以前每天一样,先把数据写到临时表,转换服务会配置分库分表的规则,从临时表里面取数据,最后写到正式表里面。数据中心有个 ETL 工具,它不支持扩展,所以就没有直接写入到正式表。\n\n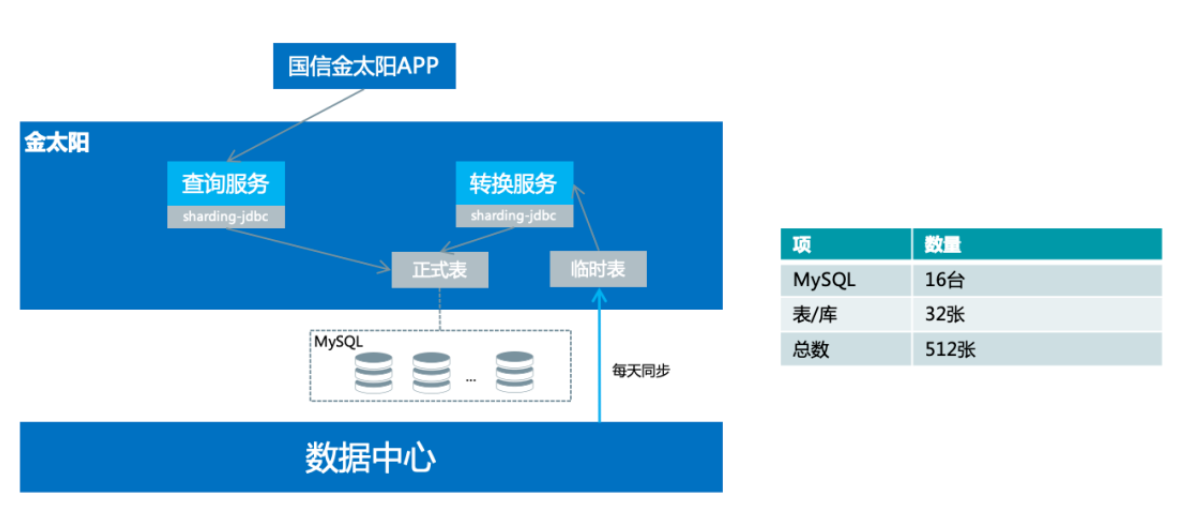\n\n图:账单 2.0 分库分表实现方式\n\n大概跑了两年时间,我们发现了新问题,分库分表虽然可以满足业务需求,但后续在扩展性方面有很大的约束,这些约束包括:第一,字段扩展困难,我们分了 512 张表,如果要有新业务上来,需要新增一个字段,这个时候 DBA 就会很痛苦,需要到每个分表新增字段。第二,扩容极其麻烦,数据一开始预估不准确的话,后面分库分表的规则就一定要变,从一开始 512 张表要变到再乘以 2,变到一千多张表,DBA 迁移的工作非常繁杂,而且很容易出错。第三,同步还需要中间表,所以数据同步的时间也还是一样的慢,并且制约系统上线时间。第四,分表的定时创建跟清理也比较繁琐,每天会将一些日表删掉,比如五年前的表,然后还要去创建第二天的表,在开发的时候,始终是要使用这个定时器来做清理和创建。第五,运维方面,也要运维多个数据库。\n\n到了账单 3.0 的时候,公司的开发和运维方提出了需求,分库分表虽然可以搞定,但是太麻烦了。借这个机会,我们把 TiDB 引入到国信证券里面来,使用 NewSQL 数据库来支持 5 年账单查询。数据中心就直接将数据每天直接推到正式表里面,查询服务方面就是直接去查询 TiDB,在 TiDB 之上加了缓存,**每天同步入库的效率较以前提升了大概 70% 左右**。当前 TiDB 已经在国信三地机房里面做了部署,同时在东莞机房最近也在做国产海光 x86 服务器的试点。\n\n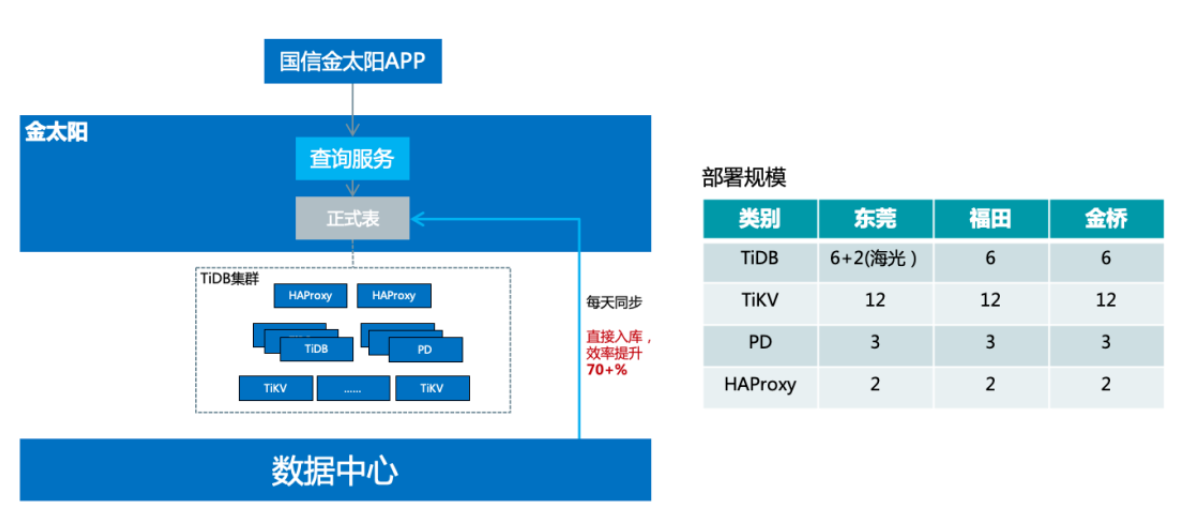\n\n图:账单 3.0 TiDB 分布式数据库实现方式\n\n接下来谈谈一年多来 TiDB 相关的使用心得。从开发角度来看,首先是大数据量删除,一开始没有经验,还是按照以前老的套路,比如要删除指定某一天的数据,直接就是 DELETE SQL WHERE = “某一天”,当时是周六,运维告警显示 TiDB 有很多台机器逐个地挂掉,后来找排查发现 DELETE SQL 太大了,后续把事务大小调到 10 G,扩展 TiDB 机器内存到 64 G,这部分是满足系统层面的扩展。另外一方面是在应用程序侧做改造,需要去做分批的删除,可考虑使用 Range 分区表,删除数据直接 truncate 或 drop 分区即可。\n\n第二个经验是对新上 TiDB 的业务,尽量要使用 AUTO-RANDOM 作为主键,对那种持续插入、大量插入,很大情况下可以避免插入的热点。对于多机房数据同步,TiDB 是需要主键或者唯一索引,无主键或者唯一索引会造成同步 OOM。在表已有大量数据的时候,如果要加这个主键,整个过程也会比较麻烦。\n\n## 三地高可用容灾架构的实现\n\n一开始只在国信东莞主机房作为试点去做 TiDB 的部署,后续运维要求 TiDB 要做容灾部署相关的工作,应用要实现三地的高可用多活。之前每个机房的应用是访问自己本地的 TiDB ,每个季度会做灾备演练,验证东莞整个主机房故障之后,异地上海与同城福田灾备的可用性。\n\nPingCAP 的老师一开始给了三个方案。第一个方案是最简单直白的,在**三个机房都部署一套单独的 TiDB 集群**。东莞机房做读写,用 TiCDC 或者 binlog 将对应的数据同步到其他两个机房的灾备集群。这个方案的优点是比较简单,做灾备演练的时候,如果东莞主机房挂了,其他两个机房的应用基本上不用做什么操作,还是可以继续使用。这个方案存在问题是副本数比较大,需要有 9 个副本,同步的时延可能也会大一点。\n\n第二个方案是比较经典的**两地三中心**,这个方案对于网络的要求比较高,而且如果东莞机房挂了,福田机房要做一下手动恢复。第三个是**同城双中心**,把东莞跟福田当成一个集群,将数据同步到上海灾备集群,也就是两个集群。但这个方案在做灾备演练的时候做恢复也会比较复杂。\n\n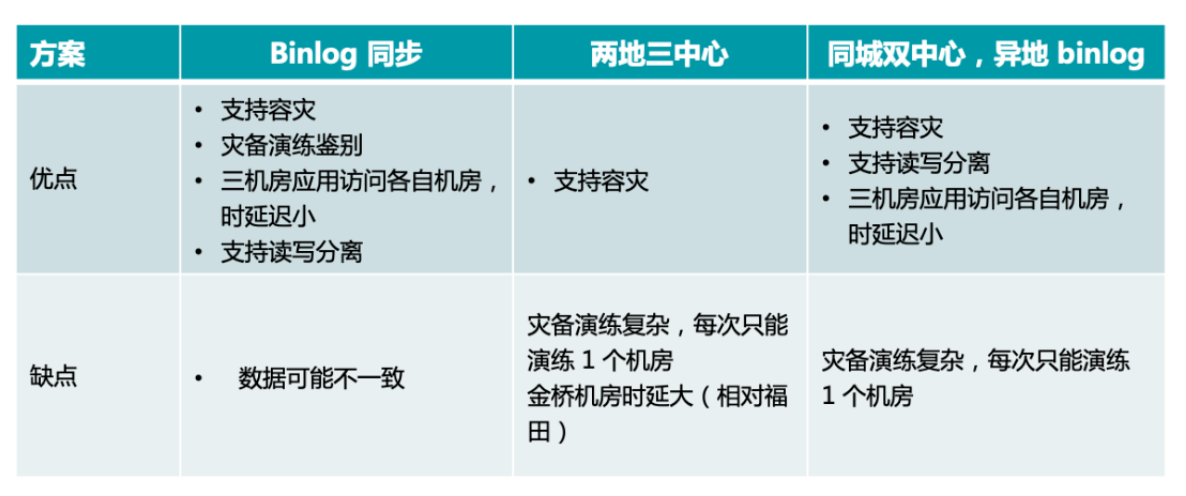\n\n图:多机房方案对比\n\n经过三个方案的对比,最后国信还是采用了最简单的 binlog 同步方案,每个机房部署一个 TiDB 集群,这也是根据业务特点来实现的。国信的业务基本上使用查询,不会存在多个机房同时写入,所以最后采用了这个最简单的方法。在多机房部署实现的过程中做了一些迁移导入的工作:一开始只有东莞机房,因为对于 TiDB 的使用不熟悉,有一些业务表是没有加主键或者没有唯一索引。福田机房搭建新的 TiDB 集群之后,我们发现在做两地集群同步的时候,同步器就直接 OOM 了,是因为没有加主键或唯一索引导致的。当时有一张最大的表已经到 60 多亿了,如果直接在表上加主键或者唯一索引的话其实是不可能的。\n\n那我们是怎么做到的呢?首先使用 Dumpling 将这个表导出到 CSV 文件,这个 CSV 文件的命名是带有表的名称的,在导出完成之后在原来的数据库上面去创建新表,里面加上主键或者唯一索引,再把导出的这两个 CSV 文件重命名跟新表一样,然后通过 Lightning 把数据导入到这个新的表里面,最后把旧表和新表给重命名,把这张新的表命名为正式表,正式表重命名为备份表,这样做的话可以尽量的减少对业务的影响,在导入导出的过程中,用户基本上是无感的。\n\n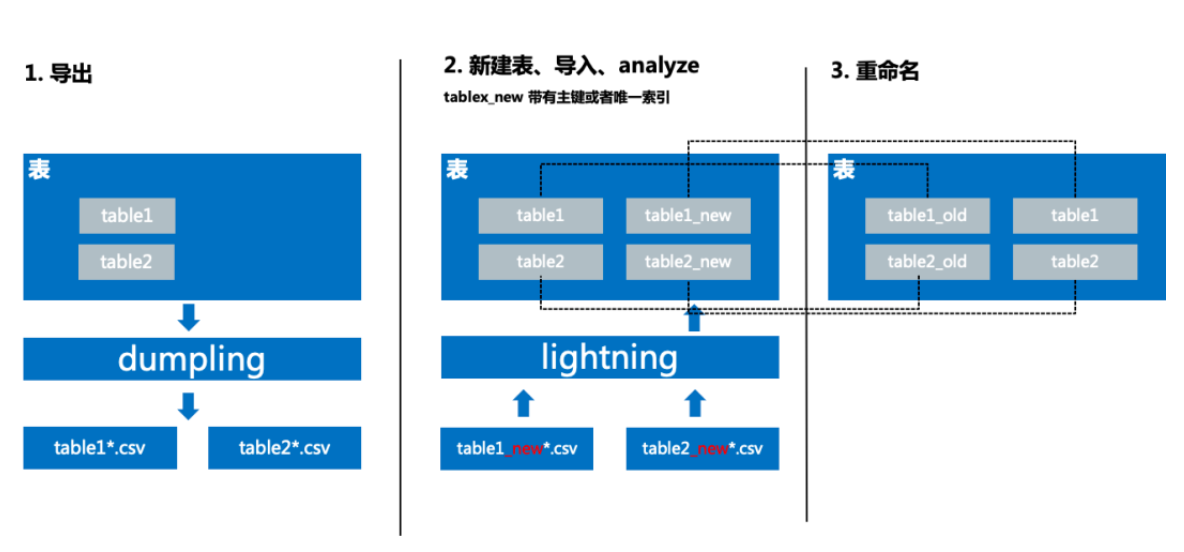\n\n图:无主键表处理\n\n## 服务可观察的探索\n\n最后谈谈在金太阳**服务可观察方面**的探索。应用在使用了微服务架构之后,部署的节点会非常多,而且调用链整个过程也非常复杂,这个时候想定位一个问题就会很复杂,根据业界当前比较流行的 “服务可观察” 概念我们做了一个应用来辅助开发的问题定位。这个 “服务可观察应用” 主要是包含三个部分,一个是日志,第二个是指标,最后一个是跟踪链。我们针对日志部分做了增强,把系统的请求和响应日志通过 ETL 工具转换到 TiDB 里面,然后做了可视化相关的工作。\n\n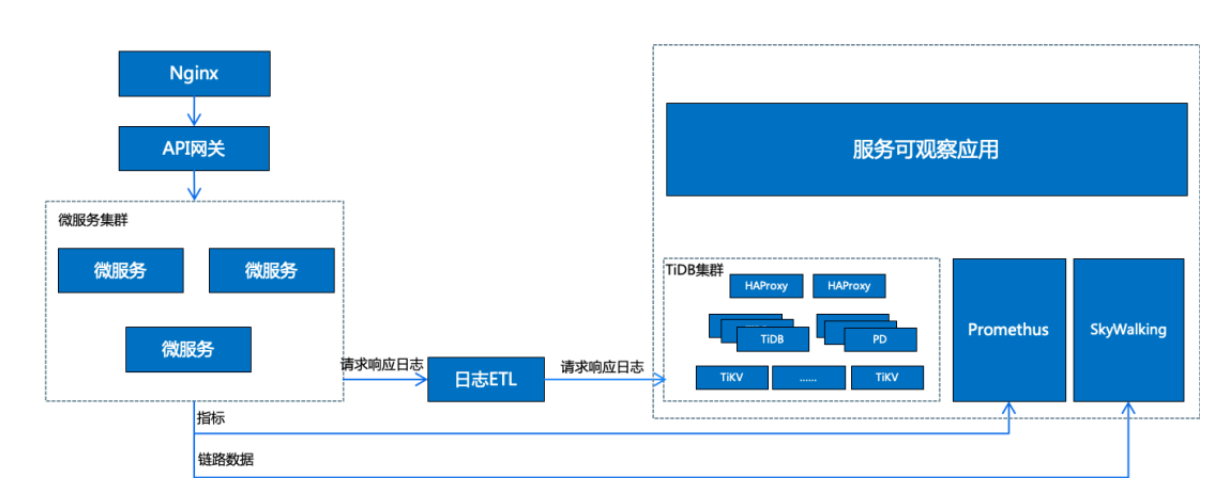\n\n图:金太阳服务的可观测性\n\n**可视化**部分是开发一直提的需求,采集了日志一般都是在 ELK 的 Kibana 里面看,都是一些文本,这是非常不直观的。我们做的优化是对于每个微服务的请求跟响应日志我们都导入到 TiDB 里面,用 “服务可观察” 应用去做展示。如果客户有什么问题,输入客户的手机号就可以很直观地看出这个客户在某个时间段做了什么操作,从而可以很快定位问题,同时我们也将内容和响应进行可视化,看起来更加方便。 \n\n当时在做 TiDB 入库也遇到一些问题,因为这个业务特点跟账单不一样,账单基本上都是每天晚上做插入,白天用户做查询操作。并且该业务在开市期间(上午九点到下午三点多)会做持续大量的插入,查询操作会比较小,有问题的时候才上去做查询。这是一个运维相关系统,所以没有用很好的磁盘,系统上线后就发现整个 TiDB 变得非常卡,一开始以为是插入的程序或者查询程序有问题,我们做了很多优化,发现还是不行,最后升级完磁盘之后发现整个性能获得了直接的提升。我们得到的经验就是上 TiDB 的话,一定要选择好的磁盘,这样才能确保处理效率。","date":"2022-01-17","author":"陈培新","fillInMethod":"writeDirectly","customUrl":"tidb-in-guosen-securities","file":null,"relatedBlogs":[]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}