{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/ticdc-mq-throughput-performance-improvement-report",
"result": {"pageContext":{"blog":{"id":"Blogs_450","title":"TiCDC MQ 吞吐性能提升报告","tags":["TiCDC"],"category":{"name":"产品技术解读"},"summary":"TiCDC 是 TiDB 生态圈的一员,为 TiDB 提供数据同步服务,它订阅上游集群中的 TiKV 节点事务执行过程中产生的数据变更事件,输出到下游目标数据系统(如 TiDB / Kafka / MySQL)。","body":">A brief introduction of TiCDC write throughput enlarged by 7x when syncing a single large table\n\n## What is TiCDC and Table Pipeline\n\nTiCDC 是 TiDB 生态圈的一员,为 TiDB 提供数据同步服务,它订阅上游集群中的 TiKV 节点事务执行过程中产生的数据变更事件,输出到下游目标数据系统(如 TiDB / Kafka / MySQL)。目前被广泛用于异地容灾、异构逃生、数据归档、数据集成等场景。\n\nTiCDC 以表为单位同步数据,为每张表创建一个 Table Pipeline,它由两部分构成:1)KV-Client 和 Puller 模块负责从从 TiKV 拉取数据,写入到 Sorter;2)Mounter 和 Sink 从 Sorter 读取数据,写入到下游目标数据系统。\n\n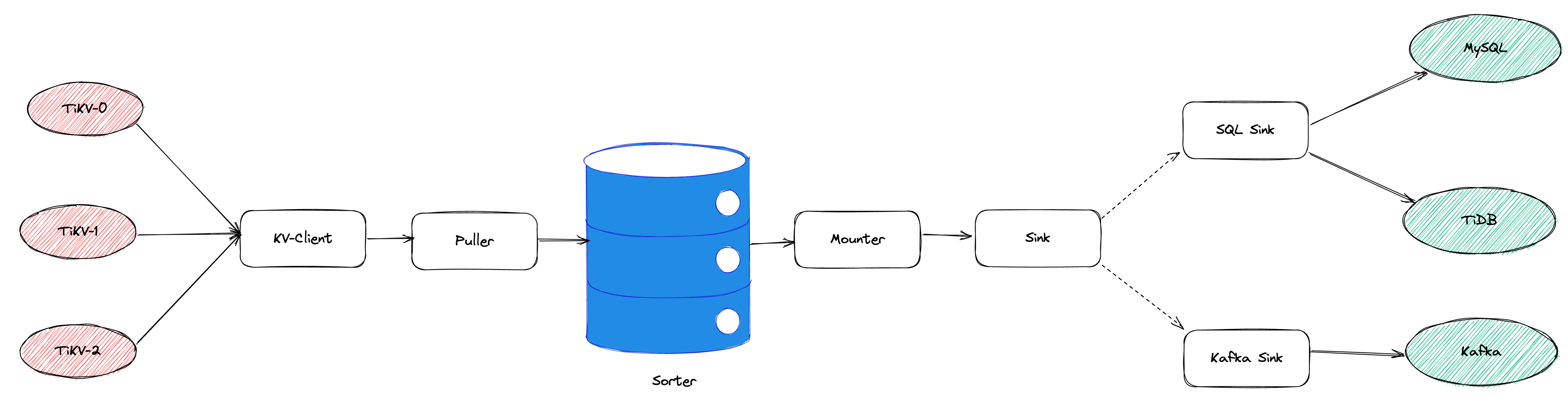\n\n图-1 Table Pipeline 介绍\n\n- KV-Client 访问上游 TiKV 节点。TiKV 以 Region 为单位,发送数据变更事件和 Resolved Ts 事件到 TiCDC。\n- Puller 从 KV-Client 接收数据并写入到 Sorter 中,并持续推进表级别的 Resovled Ts,标识该表当前接收数据的进度。\n- Mounter 模块将从 Sorter 中读取出来的数据解析为可被 Sink 处理的数据结构。\n- Sink 模块将数据同步到下游节点。 TiCDC 目前主要支持 MySQL Sink 和 Kafka Sink。\n\n## Why optimizing for single large table\n\n我们收到了一些用户需求反馈,他们希望 TiCDC 能够进一步提升吞吐性能,从而更好地支撑数据归档、大数据集成等场景。我们分析了这些场景的特点,发现它们的工作负载集中在少量的大单表上,具有如下特点:\n\n- 单表数据规模超过 10T,由超过 200k 的 Region 组成。\n- 数据列数量超过 100,平均行宽约 2k,写入 QPS 达到 10k / s。\n\n虽然 TiCDC 具备水平扩展能力,可以通过增加节点的方式来提升处理多张表时的性能,但在当前阶段,一张表只能被一个 CDC 节点处理,因此提升单一节点处理大单表的性能就非常有必要了。\n\n## Exploring problems\n\n为了定位上述场景下系统的性能瓶颈,我们做了一系列的压力测试和性能分析。我们根据上文所述的大单表的特点构建了相应规模的工作负载,使用 16C,32G 的虚拟机分别部署了一台 TiCDC 节点和 Kafka 节点作为测试环境。\n\n在调查问题的过程中,我们主要通过持续 Profiling 的方式来发现性能瓶颈点,同时结合监控面板,查看 CPU / Memory 等相关计算资源指标,有如下发现:\n\n### 大量 Resolved Ts 事件造成 CPU 开销显著\n\n\n\n图-2 KV-Client CPU Profiling\n\nKV-Client 模块在处理 Resolved Ts 事件时有明显 CPU 开销,近一半的 CPU 时间被 Golang Runtime 占用。\n\n\n\n图-3 Frontier 模块 CPU Profiling\n\nPuller 模块中的 Frontier 组件在处理大量 Resolved Ts 事件时也有显著的 CPU 开销。\n\n### Mounter & Encoder 模块吞吐能力不足\n\n我们再来看一下数据从 Sorter 流出之后的处理过程。Mounter 会对从 Sorter 读取到的数据进行解码,生成一个新的内部数据结构,然后就交给 Sink 模块,后者将事件发送到目标数据系统。\n\n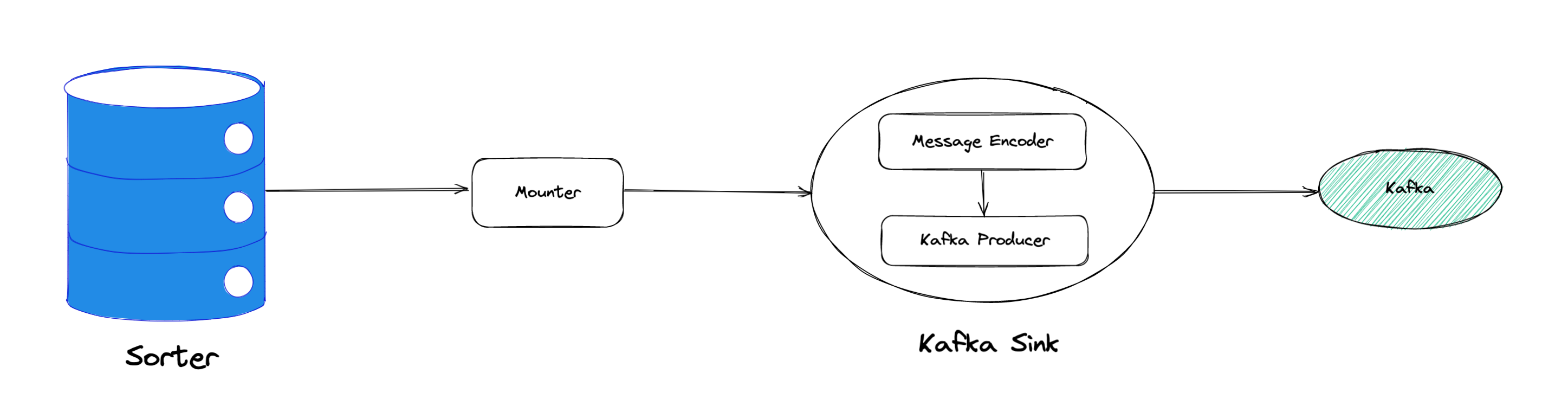\n\n图-4 数据流出简图\n\n从上图中我们可以看到,Mounter 和 Sink 是一个顺序关系。如果 Mounter 模块的吞吐量不足,势必会影响 Sink 模块的吞吐量。我们对 Mounter 模块的吞吐量做了 Benchmark 定量分析。我们使用了一种特殊的 Sink,它会将从 Mounter 接收到的数据直接丢弃,这种情况下我们认为 Sink 的吞吐量不是性能瓶颈。在测试中发现,这种情况下 Sink 的吞吐量只有 5k/s 左右,这说明数据流入 Sink 的速率不足,也就说明了 Mounter 模块的吞吐量不足,是必须优先解决的性能瓶颈。\n\n在 Kafka Sink 内部,首先会由 Encoder 模块将数据编码成特定的格式,然后交给 Kafka Producer 发送到目标 Kafka 集群。我们使用了和测试 Mounter 吞吐量类似的策略,来测试 Encoder 的性能,发现 Encoder 模块也存在吞吐量不足的问题。\n\n### CPU 使用率不足\n\n\n\n图-5 Mounter & Encoder CPU Profiling\n\n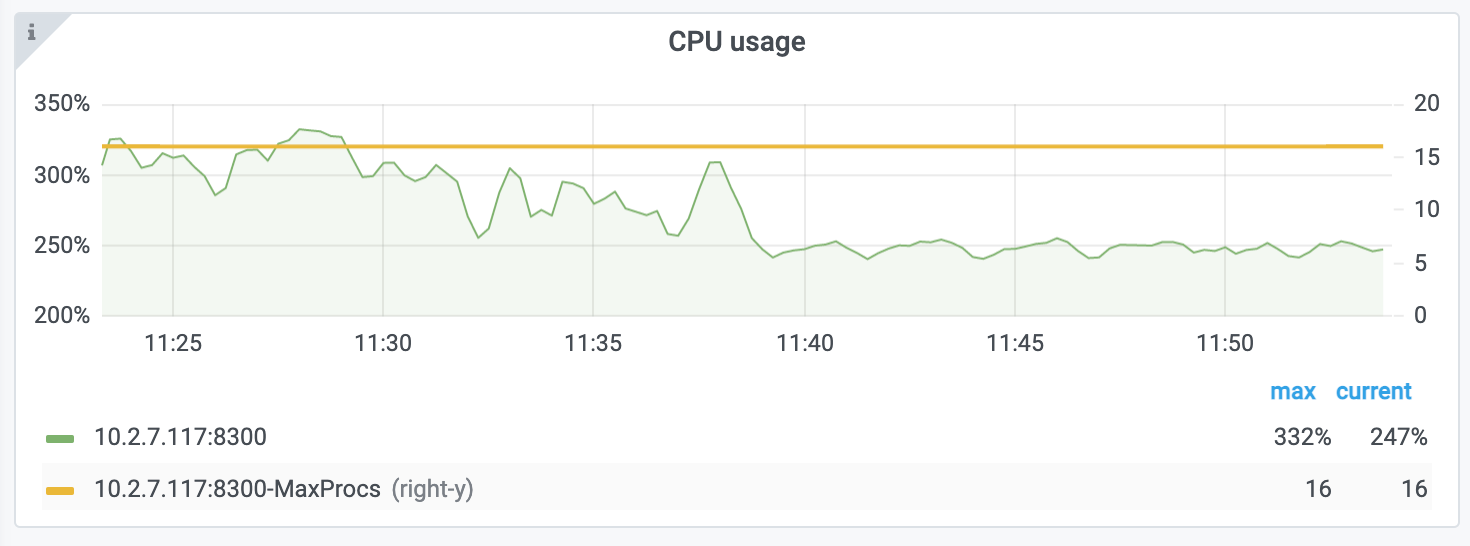\n\n图-6 CPU Usage\n\n同时,我们也查看了 CPU Profiling 。Mounter 模块和 Sink 内部的 Encoder 模块的 CPU 开销相对其他模块更为显著。同时查看监控发现,CPU 资源的整体使用率并不高,TiCDC 所在的机器有 16C,但 CPU 利用率不足 300%。Mounter 和 Encoder 的主要工作是对数据进行编解码,属于 CPU 密集型任务,所以在 Profiling 上看起来较为突出是正常的。整体 CPU 使用率低说明当前的数据消费链路对 CPU 使用效率低下,提升整体 CPU 使用率是解决问题的重要途径。\n\n## How we solve the problem\n\n经过上述性能测试和剖析 (Profiling),确定了整条 Table Pipeline 链路上需要被优化的性能瓶颈点。KV-Client 和 Puller 模块对 Region 数量颇为敏感,海量 Region 带来的大量 Resolved Ts 事件给二者带来了不可忽视的压力,因此有必要提升二者在处理 Resolved Ts 事件时的效率。对于 Mounter 和 Sink 模块,消除 Mounter 模块和 Encoder 模块的吞吐量瓶颈,是提升 TiCDC 吞吐量性能的关键。\n\n### Efficient to handle resolved ts event\n\nKV-Client 和 Puller 模块需要处理的 Resolved Ts 事件数量,和被监听的 Region 数量成正比,这是造成二者 CPU 开销高的主要因素。\n\n当前的 KV-Client 模块逐个处理 Resolved Ts 事件,这显然不是一个高效的方案。我们对其做出了改进了,让它批量地处理 Resolved Ts 事件,从而减少相关函数调用引起的上下文切换,降低 CPU 开销。同时优化了实现细节,降低模块内多线程并发访问过程中占用锁带来的 CPU 开销。测试结果表明,200k Regions 的场景下,CPU 使用率下降了 50%。\n\n[Frontier 组件](https://github.com/pingcap/tiflow/tree/master/cdc/puller)采用最小堆来维护所有 Regions 的 Resolved Ts,输出最小值作为表级别的 Resolved Ts。每次处理 Resolved Ts 事件时需要检查最小堆中的所有元素,以应对 Region 发生分裂合并导致的 Region 变更情况,所以 CPU 开销明显。我们认为在一般场景下,绝大多数 Region 不会发生频繁的分裂合并。基于这一假设改进了 Frontier 的计算逻辑,在检测到没有 Region 发生变化的情况下,通过快速路径计算得到表级别的 Resolved Ts,这一改进提升了处理 Resolved Ts 事件的效率,测试结果表明 CPU 使用效率再次下降了 50%。\n\n上述两个优化工作完成之后,KV-Client 和 Puller 模块应对海量 Region 时的 CPU 开销有明显的下降,这也使得 TiCDC 能够更加高效地应对有大量 Region 的场景,在相同资源的情况下,支持比以前更大规模的数据量。\n\n### Boost CPU usage, enlarge throughput\n\n为了提升 Mounter 和 Encoder 的吞吐性能,对二者进行了多线程改造,提出了 Mounter Group 和 Encoder Group 模块。\n\n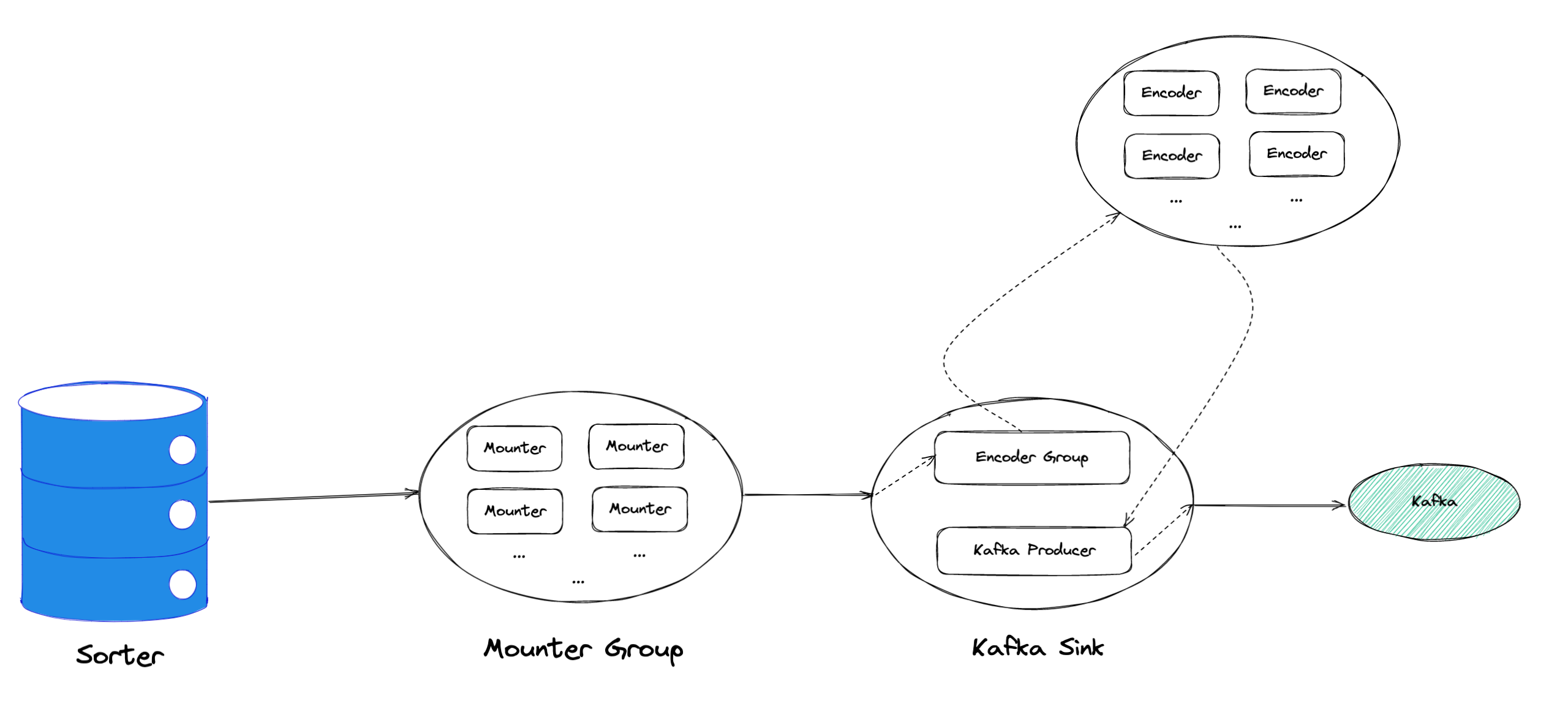\n\n图-7 多线程 Mounter & Encoder 示意图\n\n如上图所示,Mounter Group 内部维护了多个 Mounter 实例,批量地输入数据,并发地进行数据解码工作,提升整体解码效率。测试结果表明,Mounter Group 的吞吐量有 10 倍左右的提升。\n\nEncoder Group 的实现和前者类似,并发地对执行数据编码工作,吞吐性能也得到了显著提升。我们分析了 Kafka Sink 内部的运行过程,可以分为 3 个步骤:接收数据,使用 Encoder 编码数据,然后经由 Kafka Producer 发送到目标 Kafka 集群。我们发现这三个步骤是串行执行的,于是我们对这三个步骤做了多线程改造,“接收数据,编码数据,发送数据” 3 个过程以流水线的方式运行,这进一步提升了 Kafka Sink 的运行效率。\n\n\n\n图-8 Canal-JSON Encoder CPU Profiling\n\n\n\n图-9 Canal-JSON Encoder Allocate Objects Profiling\n\nEncoder 的编码效率也是一个影响吞吐量的重要因素。Canal-JSON 是我们推荐的一种编码协议,它使用 Golang 标准库的 JSON 库对数据进行编码工作。如上图-8 所示,CPU 开销显著,同时有明显的垃圾回收开销。图-9 是对应时段的内存分配对象 Profiling,可以看到在编码过程中分配了大量的对象,内存占用量明显。对此我们选择使用 [easyjson](https://github.com/mailru/easyjson/) 更为高效地生成 JSON 编码,这使得 Canal-JSON Encoder 的效率得到提升,不仅编码速度更快,而且减少了内存分配开销,降低了 GC 压力。\n\n## Experiment\n\n在完成了上述优化工作之后,我们使用 v6.3.0 版本的 TiCDC 作为参考对象,比较了优化前后吞吐性能之间的差异。我们使用的测试负载特点如下,单行数据有 60 个字段,单行数据长度约为 1.2k,我们认为这种规格的表具有代表性。在测试过程中,向上游 TiDB 集群写入 10,000,000 行数据,保证有足够的上游写入压力。测试环境和之前调查问题时使用的相同。\n\n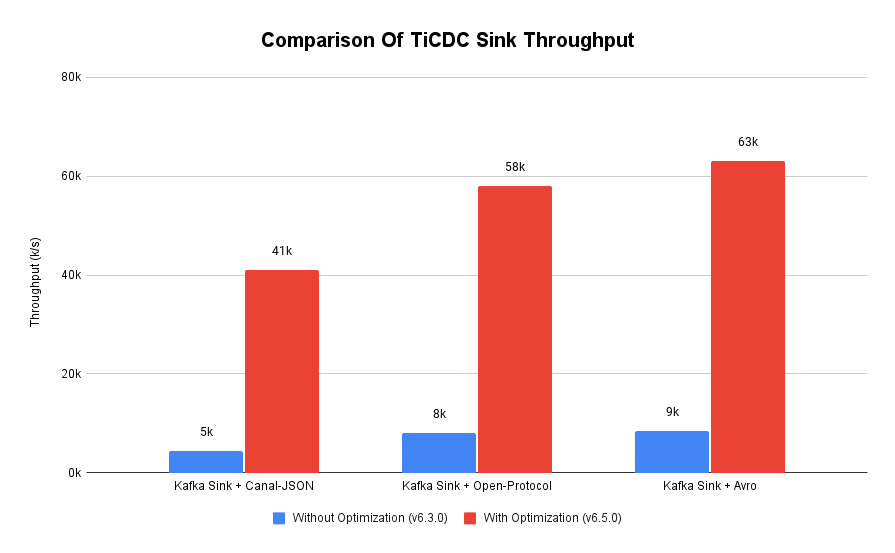\n\n图-10 MQ Sink 吞吐量提升实验结果对比\n\n我们分别测试了 [Canal-JSON](https://docs.pingcap.com/tidb/v6.0/ticdc-canal-json),[Avro](https://docs.pingcap.com/tidb/dev/ticdc-avro-protocol),[Open-protocol](https://docs.pingcap.com/tidb/dev/ticdc-open-protocol) 3 种协议对 Kafka Sink 吞吐量的影响。从上图中我们可以看到,在使用不同编码协议时,Kafka Sink 吞吐量有明显差异。Avro 格式编码实现高效,测试中显示出最好的性能。而 Canal-JSON 格式较为复杂,针对每个数据列都携带有元数据,编码开销更大,所以性能有所下降。与前面两者不同的是,Open-Protocol 在编码时会将多行数据编码到一个消息中,均摊了编码开销,也取得了不错的吞吐性能。\n\n## Conclusion & Future work\n\n本文讲述了针对大单表场景,我们做出的一系列性能分析和优化工作,在吞吐量指标上取得了显著的提升,Kafka Sink 的吞吐量提升了 7 倍有余。在未来我们依旧会针对该问题开展更多改进工作,比如我们发现 TiCDC 使用的第三方 Kafka 客户端实现存在性能瓶颈,是限制进一步提升 TiCDC Kafka Sink 吞吐量的主要因素,我们会在未来解决该问题。MySQL Sink 的性能目前还有待继续提升,我们会对它进行更多开发优化工作。","date":"2022-12-28","author":"金灵","fillInMethod":"writeDirectly","customUrl":"ticdc-mq-throughput-performance-improvement-report","file":null,"relatedBlogs":[{"relatedBlog":{"body":"这一次 TiCDC 阅读系列文章将会从源码层面来讲解 TiCDC 的基本原理,希望能够帮助读者深入地了解 TiCDC 。本篇文章是这一系列文章的第一期,主要叙述了 TiCDC 的目的、架构和数据同步链路,旨在让读者能够初步了解 TiCDC,为阅读其他源码阅读文章起到一个引子的作用。\n\n## TiCDC 是什么?\n\nTiCDC 是 TiDB 生态中的一个数据同步工具,它能够将上游 TiDB集群中产生的增量数据实时的同步到下游目的地。除了可以将 TiDB 的数据同步至 MySQL 兼容的数据库之外,还提供了同步至 Kafka 和 s3 的能力,支持 canal 和 avro 等多种开放消息协议供其他系统订阅数据变更。\n\n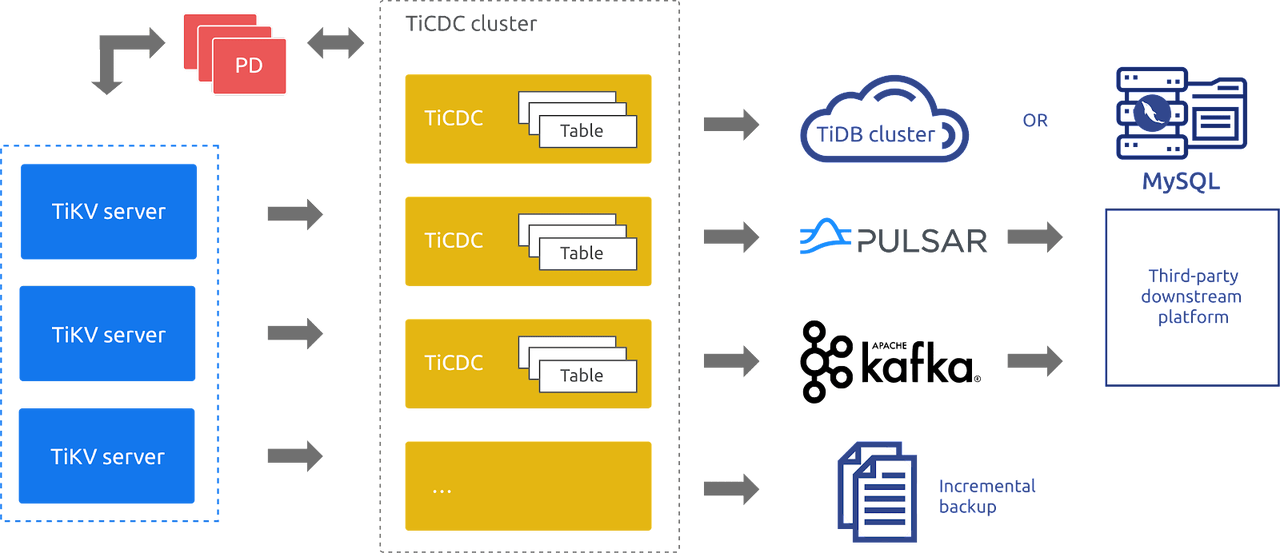\n\n上图描述了 TiCDC 在整个 TiDB 生态系统中的位置,它处于一个上游 TiDB 集群和下游其它数据系统的中间,充当了一个数据传输管道的角色。\n\n**TiCDC 典型的应用场景为搭建多套 TiDB 集群间的主从复制,或者配合其他异构的系统搭建数据集成服务。以下将从这两方面为大家介绍:**\n\n### 主从复制\n\n使用 TiCDC 来搭建主从复制的 TiDB 集群时,根据从集群的使用目的,可能会对主从集群的数据一致性有不同的要求。目前 TiCDC 提供了如下两种级别的数据一致性:\n\n\n\n- 快照一致性:通过开启 Syncpoint 功能,能够在实时的同步过程中,保证上下游集群在某个 TSO 的具备快照一致性。详细内容可以参考文档:[TiDB 主从集群的数据校验](https://docs.pingcap.com/zh/tidb/dev/upstream-downstream-diff)\n- 最终一致性:通过开启 Redo Log 功能,能够在上游集群发生故障的时候,保证下游集群的数据达到最终一致的状态。详细内容可以参考文档:[使用 Redo Log 确保数据一致性](https://docs.pingcap.com/zh/tidb/dev/replicate-between-primary-and-secondary-clusters#%E7%AC%AC-5-%E6%AD%A5%E4%BD%BF%E7%94%A8-redo-log-%E7%A1%AE%E4%BF%9D%E6%95%B0%E6%8D%AE%E4%B8%80%E8%87%B4%E6%80%A7)\n\n### 数据集成\n\n\n\n目前 TiCDC 提供将变更数据同步至 Kafka 和 S3 的能力,用户可以使用该功能将 TiDB 的数据集成进其他数据处理系统。在这种应用场景下,用户对数据采集的实时性和支持的消息格式的多样性会由较高的要求。当前我们提供了多种可供订阅的消息格式(可以参考 [配置 Kafka](https://docs.pingcap.com/zh/tidb/dev/ticdc-sink-to-kafka#sink-uri-%E9%85%8D%E7%BD%AE-kafka)),并在最近一段时间内对该场景的同步速度做了一系列优化,读者可以从之后的文章中了解相关内容。\n\n## TiCDC 的架构\n\n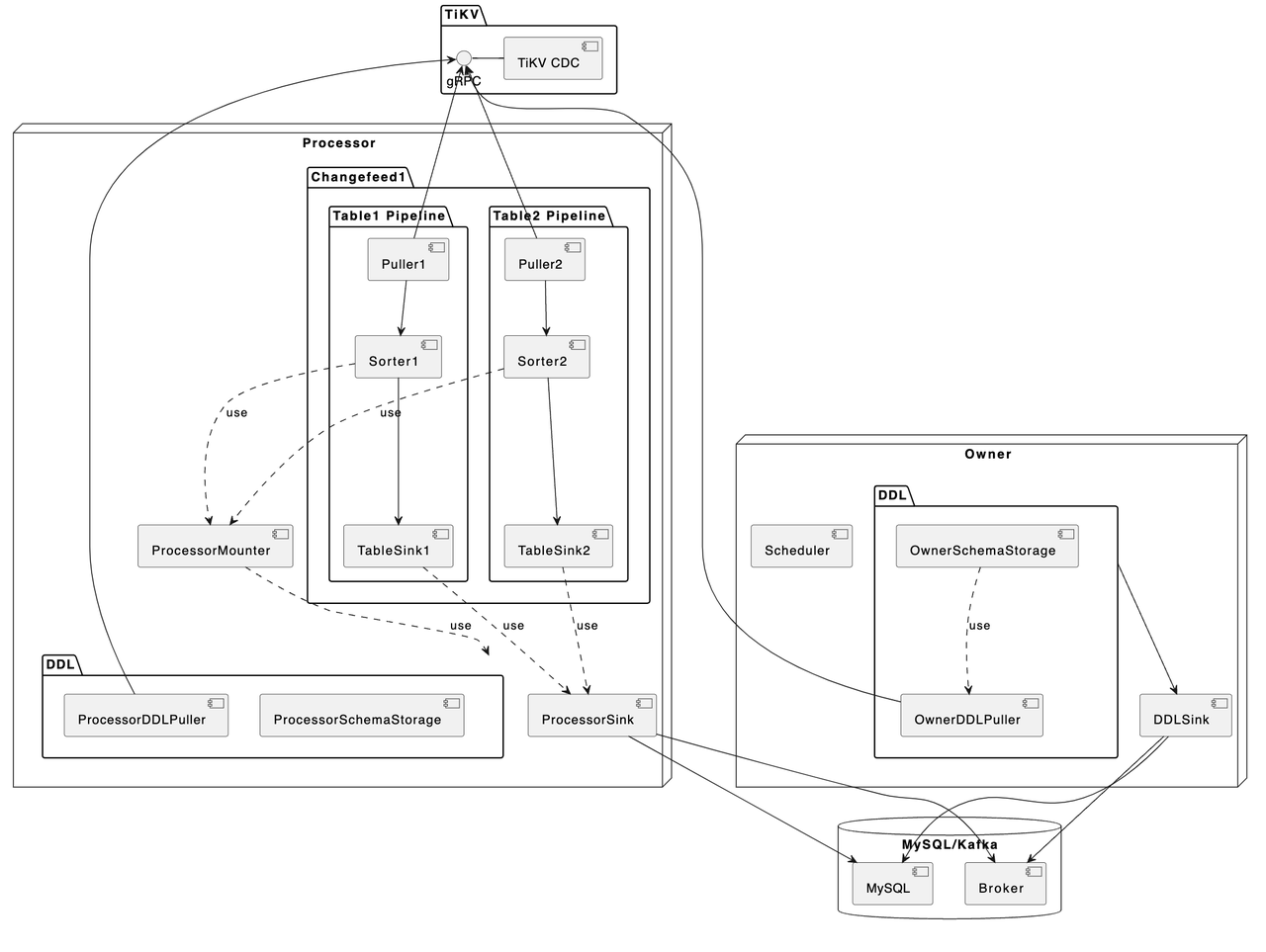\n\n确保数据传输的稳定性、实时性和一致性是 TiCDC 设计的核心目标。为了实现该目标,TiCDC 采用了分布式架构和无状态的服务模式,具备高可用和水平扩展的特性。想要深入了解 CDC 的架构,我们需要先认识下面这些概念:\n\n### 系统组件\n\n- TiKV:\n - TiKV 内部的 CDC 组件会扫描和拼装 kv change log。\n - 提供输出 kv change logs 的接口供 TiCDC 订阅。\n- Capture:\n - TiCDC 运行进程,多个 capture 组成一个 TiCDC 集群。\n - 同步任务将会按照一定的调度规则被划分给一个或者多个 Capture 处理。\n\n### 逻辑概念\n\n- KV change log:TiKV 提供的隐藏大部分内部实现细节的的 row changed event,TiCDC 从 TiKV 拉取这些 Event。\n- Owner:一种 Capture 的角色,每个 TiCDC 集群同一时刻最多只存在一个 Capture 具有 Owner 身份,它负责响应用户的请求、调度集群和同步 DDL 等任务。\n- ChangeFeed:由用户启动同步任务,一个同步任务中可能包含多张表,这些表会被 Owner 划分为多个子任务分配到不同的 Capture 进行处理。\n- Processor:Capture 内部的逻辑线程,一个 Capture 节点中可以运行多个 Processor。每个 Processor 负责处理 ChangeFeed 的一个子任务。\n- TablePipeline:Processor 内部的数据同步管道,每个 TablePipeline 负责处理一张表,表的数据会在这个管道中处理和流转,最后被发送到下游。\n\n### 基本特性\n\n- 分布式:具备高可用能力,支持水平扩展。\n- 实时性:常规场景下提供秒级的同步能力。\n- 有序性:输出的数据行级别有序,并且提供 At least once 输出的保证。\n- 原子性:提供单表事务的原子性。\n\n## TiCDC 的生命周期\n\n认识了以上的基本概念之后,我们可以继续了解一下 TiCDC 的生命周期。\n\n### Owner\n\n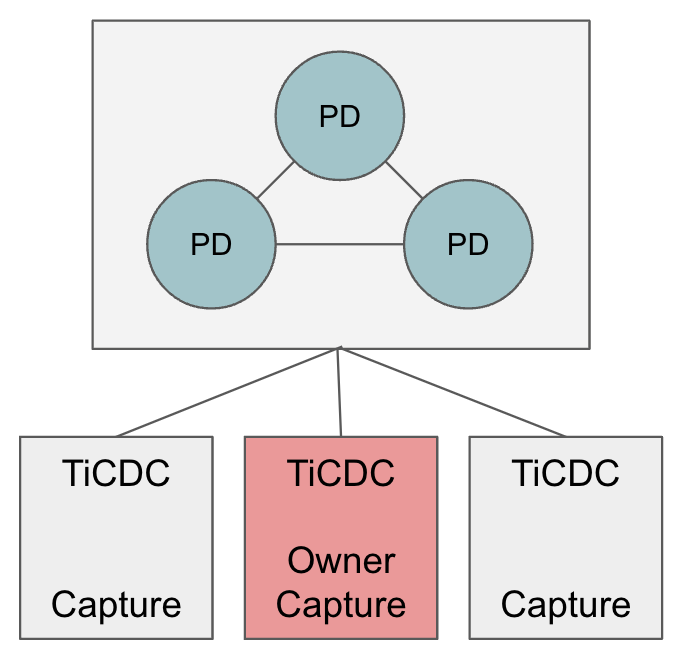\n\n首先,我们需要知道,TiCDC 集群的元数据都会被存储到 PD 内置的 Etcd 中。当一个 TiCDC 集群被部署起来时,每个 Capture 都会向 Etcd 注册自己的信息,这样 Capture 就能够发现彼此的存在。接着,各个 Capture 之间会竞选出一个 Owner ,Owner 选举流程在 [cdc/capture.go](https://github.com/pingcap/tiflow/blob/master/cdc/capture/capture.go#L393) 文件的 `campaignOwner` 函数内,下面的代码删除了一些错误处理逻辑和参数设置,只保留主要的流程:\n\n```go\nfor {\n // Campaign to be the owner, it blocks until it been elected.\n err := c.campaign(ctx)\n ...\n owner := c.newOwner(c.upstreamManager)\n c.setOwner(owner)\n ...\n err = c.runEtcdWorker(ownerCtx, owner,...)\n c.owner.AsyncStop()\n c.setOwner(nil)\n}\n```\n\n每一个 Capture 进程都会调用该函数,进入一个竞选的 Loop 中,每个 Capture 都会持续不断地在竞选 Owner。同一时间段内只有一个 Capture 会当选,其它候选者则会阻塞在这个 Loop 中,直到上一个 Owner 退出就会有新的 Capture 当选。\n\n最后真正的竞选是通过在 `c.campaign(ctx)` 函数内部调用 Etcd 的 `election.Campaign` 接口实现的,Etcd 保证了同一时间只有一个 Key 能够当选为 Owner。由于 Etcd 是高可用的服务,TiCDC 借助其力量实现了天然的高可用。\n\n竞选到 Owner 角色的 Capture 会作为集群的管理者,也负责监听和响应来自用户的请求。\n\n### ChangeFeed\n\nTiCDC 集群启动完毕之后,用户即可使用 TiCDC 命令行工具或者 OpenAPI 创建 ChangeFeed (同步任务)。\n一个 ChangeFeed 被创建之后,Owner 会负责对它进行检查和初始化,然后将以表为单位将划分为多个子任务分配给集群内的 Capture 进行同步。同步任务初始化的代码在 [cdc/owner/changefeed.go](https://github.com/pingcap/tiflow/blob/master/cdc/owner/changefeed.go#L404) 文件中。该函数的主要工作为:\n\n1. 向上游查询该同步任务需要同步的表的 Schema 信息,为接下来调度器分配同步任务做准备。\n2. 创建一个 `ddlPuller` 来拉取 DDL 。因为我们需要在同步的过程中保持多个 Capture 节点上 Schema 信息的一致,并且保证 DML 与 DDL 同步顺序。所以我们选择仅由 Owner 这个拥有 ChangeFeed 所以信息的角色同步 DDL。\n3. 创建 `scheduler` ,它会负责把该同步任务拆分成多个子任务,发送给别的 Capture 进行处理。\n\nCapture 接收到 Owner 发送过来的子任务之后,就会创建出一个 Processor 来处理它接收到的子任务,Processor 会为每张表创建出一个 TablePipeline 来同步对应的表的数据。Processor 会周期性的把每个 TablePipeline 的状态和进度信息汇报给 Owner,由 Owner 来决定是否进行调度和状态更新等操作。\n总而言之,TiCDC 集群和同步任务的状态信息会在 Owner 和 Processor 之间流转,而用户需要同步的数据信息则通过 TablePipeline 这个管道传递到下游,下一个小节将会对 TablePipeline 进行讲解,理解了它,就能够理解 TiCDC 是怎么同步数据的。\n\n### TablePipeline\n\n\n\n顾名思义,TablePipeline 是一个表数据流动和处理的管道。Processor 接收到一个同步子任务之后,会为每一张表创建出一个 TablePipeline,如上图所示,它主要由 Puller、Sorter、Mounter 和 Sink 构成。\n\n- Puller: 负责拉取对应表在上游的变更数据,它隐藏了内部大量的实现细节,包括与 TiKV CDC 模块建立 gRPC 连接和反解码数据流等。\n- Sorter: 负责对 Puller 输出的乱序数据进行排序,并且会把 Sink 来不及消费的数据进行落盘,起到一个蓄水池的作用。\n- Mounter:根据事务提交时的表结构信息解析和填充行变更,将行变更转化为 TiCDC 能直接处理的数据结构。在这里,Mounter 需要和一个叫做 SchemaStorage 的组件进行交互,这个组件在 TiCDC 内部维护了所需表的 Schema 信息,后续会有内容对这其进行讲解。\n- Sink:将 Mounter 处理过后的数据进行编解码,转化为 SQL 语句或者 Kafka 消息发送到对应下游。\n\n这种模块化的设计方式,比较有利于代码的维护和重构。值得一提的是,如果你对 TiCDC 有兴趣,希望能够让它接入到当前 CDC 还不支持的下游系统,那么只要自己编码实现一个对应的 Sink 接口,就可以达到目的。\n接下来,我们以一个具体例子的方式来讲解数据在 TiCDC 内部的流转。假设我们现在建立如下表结构:\n\n```sql\nCREATE TABLE TEST(\n NAME VARCHAR (20) NOT NULL,\n AGE INT NOT NULL,\n PRIMARY KEY (NAME)\n);\n\n+-------+-------------+------+------+---------+-------+\n| Field | Type | Null | Key | Default | Extra |\n+-------+-------------+------+------+---------+-------+\n| NAME | varchar(20) | NO | PRI | NULL | |\n| AGE | int(11) | NO | | NULL | |\n+-------+-------------+------+------+---------+-------+\n```\n\n此时,在上游 TiDB 执行以下 DML:\n\n```sql\nINSERT INTO TEST (NAME,AGE)\nVALUES ('Jack',20);\n\nUPDATE TEST\nSET AGE = 25\nWHERE NAME = 'Jack';\n```\n\n下面我们就来看一看这两条 DML 会通过什么样的形式经过 TablePipeline ,最后写入下游。\n\n#### Puller 拉取数据\n上文中提到 Puller 负责与 TiKV CDC 组件建立 gPRC 连接然后拉取数据,这是 [/pipeline/puller.go](https://github.com/pingcap/tiflow/blob/master/cdc/processor/pipeline/puller.go#L67) 中的 Puller 大致的工作逻辑:\n\n```go\nn.plr = puller.New(... n.startTs, n.tableSpan(),n.tableID,n.tableName ...)\nn.wg.Go(func() error {\n ctx.Throw(errors.Trace(n.plr.Run(ctxC)))\n ...\n})\nn.wg.Go(func() error {\n for {\n select {\n case <-ctxC.Done():\n return nil\n case rawKV := <-n.plr.Output():\n if rawKV == nil {\n continue\n }\n pEvent := model.NewPolymorphicEvent(rawKV)\n sorter.handleRawEvent(ctx, pEvent)\n }\n }\n})\n```\n\n以上是经过简化的代码,可以看到在 `puller.New` 方法中,有两个比较重要的参数 `startTs` 和 `tableSpan()`,它们分别从时间和空间这两个维度上描述了我们想要拉取的数据范围。在 Puller 被创建出来之后,下面部分的代码分别启动了两个 goroutine,第一个负责运行 Puller 的内部逻辑,第二个则是等待 Puller 输出数据,然后把数据发给 Sorter。从 `plr.Output()` 中吐出来的数据长这个样子:\n\n```go\n// RawKVEntry notify the KV operator\ntype RawKVEntry struct {\n OpType OpType `msg:\"op_type\"`\n Key []byte `msg:\"key\"`\n // nil for delete type\n Value []byte `msg:\"value\"`\n // nil for insert type\n OldValue []byte `msg:\"old_value\"`\n StartTs uint64 `msg:\"start_ts\"`\n // Commit or resolved TS\n CRTs uint64 `msg:\"crts\"`\n ...\n}\n```\n\n所以,在上游 TiDB 写入的那两条 DML 语句,在到达 Puller 的时候会是这样这样的一个数据结构\n\n\n\n我们可以看到 Insert 语句扫描出的数据只有 value 没有 old_value,而 Update 语句则被转化为一条既有 value 又有 old_value 的行变更数据。\n\n这样这两条数据就成功的被 Puller 拉取到了 TiCDC,但是因为 TiDB 中一张表的数据会被分散到多个 Region 上,所以 Puller 会与多个 TiKV Region Leader 节点建立连接,然后拉取数据。那实际上 TiCDC 拉取到的变更数据可能是乱序的,我们需要对拉取到的所有数据进行排序才能正确的将事务按照顺序同步到下游。\n\n#### Sorter 排序\n\nTablePipeline 中的 Sorter 只是一个拥有 Sorter 名字的中转站,实际上负责对数据进行排序的是它背后的 Sorter Engine,Sorter Engine 的生命周期是和 Capture 一致的,一个 Capture 节点上的所有 Processor 会共享一个 Sorter Engine。想要了解它是怎么工作的,可以阅读 [EventSorter 接口](https://github.com/pingcap/tiflow/blob/master/cdc/sorter/sorter.go#L32)和其具体实现的相关代码。\n\n在这里,我们只需要知道数据进入 TablePipeline 中的 Sorter 后会被排序即可。假设我们现在除了上述的两条数据之外,在该表上又进行了其他的写入操作,并且该操作的数据在另外一个 Region。最终 Puller 拉到的数据如下:\n\n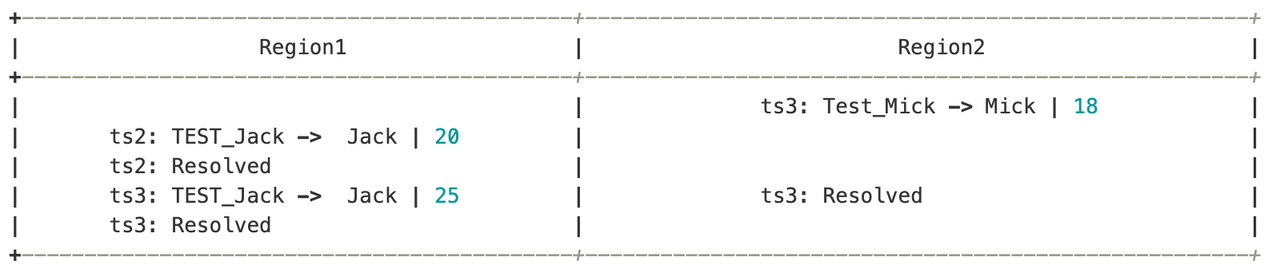\n\n除了数据之外,我们还可以看到 `Resolved` 的事件,这是一个在 TiCDC 系统中很重要的时间标志。当 TiCDC 收到 `Resolved` 时,**可以认为小于等于这个时间点提交的数据都已经被接收了,并且以后不会再有早于这个时间点的数据再发送下来,此时 TiCDC 可以此为界限来将收到的数据同步至下游。**\n\n此外,我们可以看到拉取到的数据并不是按照 commit_ts 严格排序的,Sorter 会根据 commit_ts 将它们进行排序,最终得到如下的数据:\n\n\n\n现在排好顺序的事件就可以往下游同步了,但是在这之前我们需要先对数据做一些转换,因为此时的数据是从 TiKV 中扫描出的 key-value,它们实际上只是一堆 bytes 数据,而不是下游想要消费的消息格式。\n\n#### Mounter 解析\n\n以上的 Event 数据从 Sorter 出来之后,Mounter 会根据其对应的表的 Schema 信息将它还原成按照表结构组织的数据。\n\n```go\ntype RowChangedEvent struct {\n StartTs uint64\n CommitTs uint64\n Table *TableName\n ColInfos []rowcodec.ColInfo\n Columns []*Column\n PreColumns []*Column\n IndexColumns [][]int\n ...\n}\n```\n\n可以看到,该结构体中还原出了所有的表和列信息,并且 Columns 和 PreColumns 就对应于 value 和 old_value。当 TiCDC 拿到这些信息之后我们就可以将数据继续下发至 Sink 组件,让其根据表信息和行变更数据去写下游数据库或者生产 Kafka 消息。值得注意的是,Mounter 进行的是一项 CPU 密集型工作,当一个表中所包含的字段较多时,Mounter 会消耗大量的计算资源。\n\n#### Sink 下发数据\n\n当 `RowChangedEvent` 被下发至 Sink 组件时,它身上已经包含了充分的信息,我们可以将其转化为 SQL 或者特定消息格式的 Kafka 消息。在上文的架构图中我们可以看到有两种 Sink,一种是接入在 Table Pipeline 中的 TableSink,另外一种是 Processor 级别共用的 ProcessorSink。它们在系统中有不同的作用:\n\n- TableSink 作为一种 Table 级别的管理单位,缓存着要下发到 ProcessorSink 的数据,它的主要作用是方便 TiCDC 按照表为单位管理资源和进行调度\n- ProcessorSink 作为真实要与数据库或者 Kafka 建立连接的 Sink 负责 SQL/Kafka 消息的转换和同步\n\n我们再来看一看 ProcessorSink 到底如何转换这些行变更:\n\n- 如果下游是数据库,ProcessorSink 会根据 `RowChangedEvent` 中的 Columns 和 PreColumns 来判断它到底是一个 `Insert`、`Update` 还是 `Delete` 操作,然后根据不同的操作类型,将其转化为 SQL 语句,然后再将其通过数据库连接写入下游:\n\n```sql\n/*\n因为只有 Columns 所以是 Insert 语句。\n*/\nINSERT INTO TEST (NAME,AGE)\nVALUES ('Jack',20);\n\n/*\n因为既有 Columns 且有 PreColumns 所以是 Update 语句。\n*/\nUPDATE TEST\nSET AGE = 25\nWHERE NAME = 'Jack';\n```\n\n- 如果下游是 Kafka, ProcessorSink 会作为一个 [Kafka Producer](https://docs.confluent.io/platform/current/clients/producer.html) 按照特定的消息格式将数据发送至 Kafka。 以 [Canal-JSON](https://docs.pingcap.com/tidb/v6.0/ticdc-canal-json) 为例,我们上述的 Insert 语句最终会以如下的 JSON 格式写入 Kafka:\n\n```json\n{\n \"id\": 0,\n \"database\": \"test\",\n \"table\": \"TEST\",\n \"pkNames\": [\n \"NAME\"\n ],\n \"isDdl\": false,\n \"type\": \"INSERT\",\n ...\n \"ts\": 2,\n \"sql\": \"\",\n ...\n \"data\": [\n {\n \"NAME\": \"Jack\",\n \"AGE\": \"25\"\n }\n ],\n \"old\": null\n}\n```\n\n这样,上游 TiDB 执行的 DML 就成功的被发送到下游系统了。\n\n## 结尾\n\n以上就是本文的全部内容。希望在阅读完上面的内容之后,读者能够对 TiCDC 是什么?为什么?怎么实现?这几个问题有一个基本的答案。","author":"江宗其","category":1,"customUrl":"ticdc-source-code-reading-1","fillInMethod":"writeDirectly","id":444,"summary":"本篇文章是 TiCDC 源码阅读系列文章的第一期,主要叙述了 TiCDC 的目的、架构和数据同步链路,旨在让读者能够初步了解 TiCDC,为阅读其他源码文章起到一个引子的作用。","tags":["TiCDC"],"title":"TiCDC 源码阅读(一)TiCDC 架构概览"}},{"relatedBlog":{"body":"## 内容概要\n\nTiCDC 是一款 TiDB 增量数据同步工具,通过拉取上游 TiKV 的数据变更日志,TiCDC 可以将数据解析为有序的行级变更数据输出到下游。\n\n本文是 TiCDC 源码解读的第二篇,将于大家介绍 TiCDC 的重要组成部分,TiKV 中的 CDC 模块。我们会围绕 4 个问题和 2 个目标展开。\n\n1. TiKV 中的 CDC 模块是什么?\n2. TiKV 如何输出数据变更事件流?\n3. 数据变更事件有哪些?\n4. 如何确保完整地捕捉分布式事务的数据变更事件?\n\n希望在回答完这4个问题之后,大家能:\n\n- 🔔 了解数据从 TiDB 写入到 TiKV CDC 模块输出的流程。\n- 🗝️ 了解如何完整地捕捉分布式事务的数据变更事件。\n\n在下面的内容中,我们在和这两个目标相关的地方会标记上 🔔 和 🗝️,以便提醒读者留意自己感兴趣的地方。\n\n## TiKV 中的 CDC 模块是什么?\n\n### CDC 模块的形态\n\n从代码上看,CDC 模块是 TiKV 源码的一部分,它是用 rust 写的,在 TiKV 代码库里面;从运行时上看,CDC 模块运行在 TiKV 进程中,是一个线程,专门处理 TiCDC 的请求和数据变更的捕捉。\n\n### CDC 模块的作用\n\nCDC 模块的作用有两个:\n\n1. 它负责捕捉实时写入和读取历史数据变更。这里提一下历史数据变更指已经写到 rocksdb 里面的变更。\n2. 它还负责计算 resolved ts。这个 resolved ts 是 CDC 模块里面特有的概念,形式上是一个 uint64 的 timestamp。它是 TiKV 事务变更流中的 perfect watermark,perfect watermark 的详细概念参考《Streaming System》的第三章,我们可以用 resolved ts 来告知下游,也就是 TiCDC,在 tikv 上所有 commit ts 小于 resolved ts 事务都已经完整发送了,下游 TiCDC 可以完整地处理这批事务了。\n\n### CDC 模块的代码分布\n\nCDC 模块的代码在 TiKV 代码仓库的 `compoenetns/cdc` 和 `components/resolved_ts` 模块。我们在下图中的黑框里面用红色标注了几个重点文件。\n\n在 `delegate.rs` 文件中有个同名的 `Delegate` 结构体,它可以认为是 Region 在 CDC 模块中的“委派”,负责处理这个 region 的变更数据,包括实时的 raft 写入和历史增量数据。\n\n在 `endpoint.rs` 文件中有个 `Endpoint` 结构体,它运行在 CDC 的主线程中,驱动整个 CDC 模块,上面的 delegate 也是运行在整个线程中的。\n\n`initializer.rs` 文件中的 `Initializer` 结构体负责增量扫逻辑,同时也负责 delegate 的初始化,这里的增量扫就是读取保存在 rocksdb 中的历史数据变更。\n\n`service.rs` 文件中的 `Service` 结构体,它实现了 ChagneData gRPC 服务,运行在 gRPC 的线程中,它负责 TiKV 和 TiCDC 的 RPC 交互,同时它和 `Endpoint` 中的 `Delegate` 和 `Initializer` 也会有交互,主要是接受来自它俩的数据变更事件,然后把这些事件通过 RPC 发送给 TiCDC。\n\n最后一个重要文件是 `resolver.rs`,它与上面的文件不太一样,在 resolve_ts 这个 component 中,里面的 `Resolver` 负责计算 resolved ts。\n\n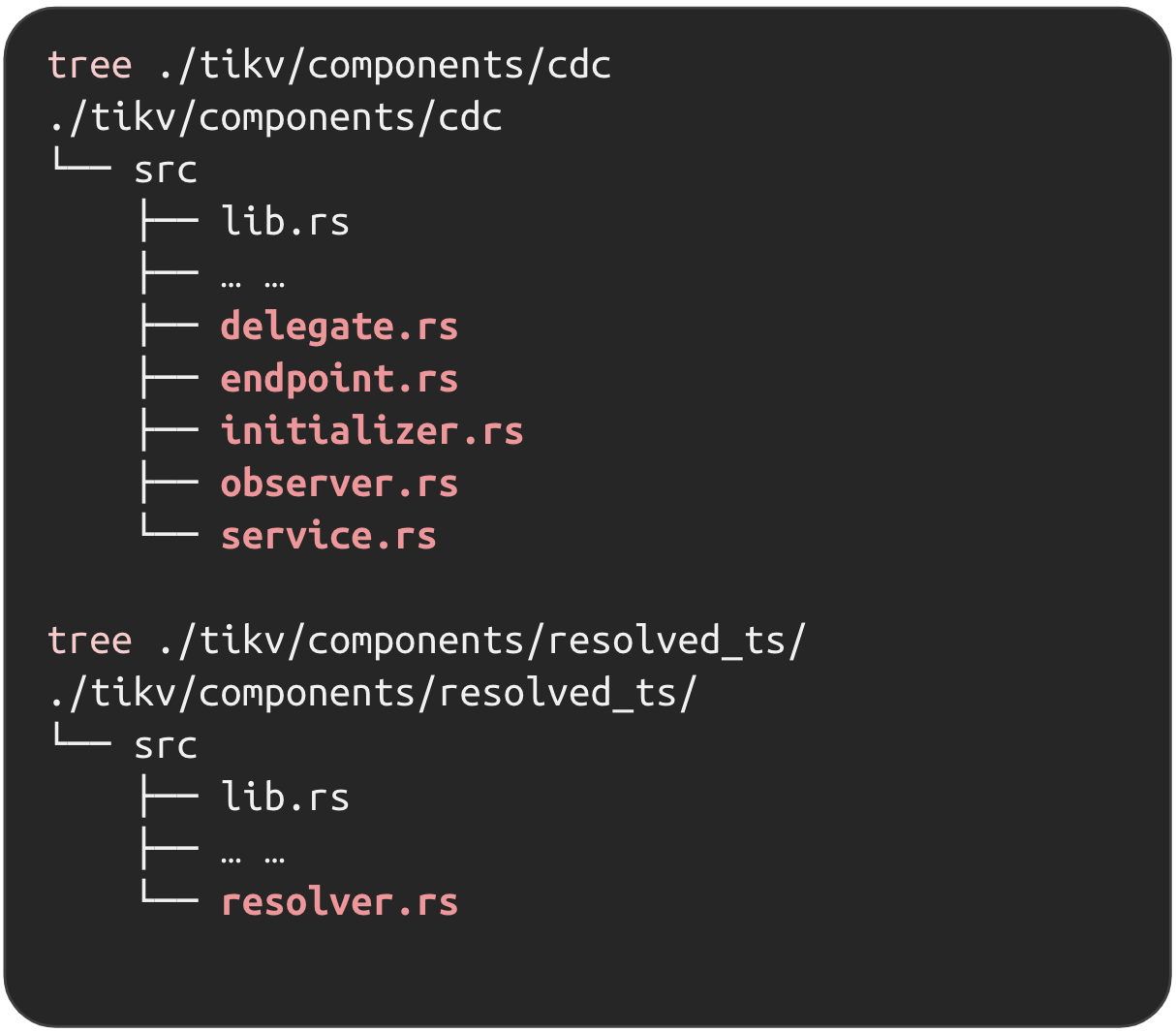\n\n## TiKV 如何输出数据变更事件流?\n\n我们从端到端的角度完整地走一遍数据的写入和流出。下图概括了数据的流动,我们以数据保存到磁盘为界,红色箭头代表数据从 TiDB 写入 TiKV 磁盘的方向,蓝色箭头代表数据从 TiKV 磁盘流出到 TiCDC 的方向。\n\n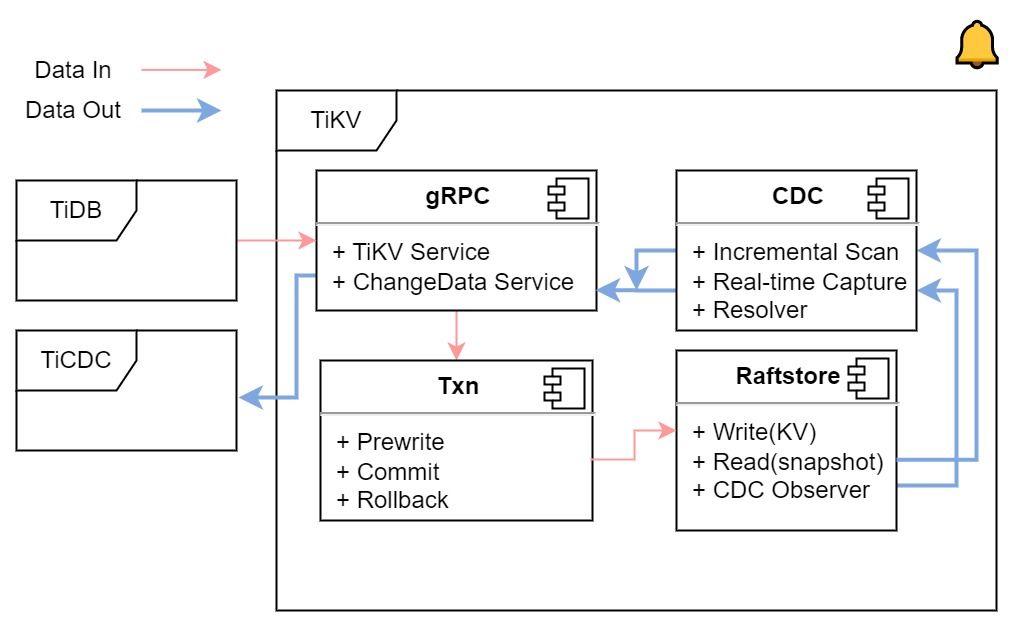\n\n### TiDB -> TiKV Service\n \n- txn prewrite: [Tikv::kv_prewrite(PrewriteRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/server/service/kv.rs#L242)\n- txn commit: [Tikv::kv_commit(CommitRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/server/service/kv.rs#L263)\n\n我们看下从 TiDB 指向 TiKV 的红线。我们知道数据来自 TiDB 的事务写入,对于一个正常的事务来说,TiDB 需要分两次调用 TiKV 的 gRPC 接口,分别是 kv_prewrite 和 kv_commit,对应了事务中的 prewrite 和 commit,在 request 请求中包含了要写入或者删除的 key 和它的 value,以及一些事务的元数据,比如 start ts,commit ts 等。\n\n### TiKV Service -> Txn\n\n- txn prewrite: [Storage::sched_prewrite(PrewriteRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/server/service/kv.rs#L2189-L2241)\n- txn commit: [Storage::sched_commit(CommitRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/server/service/kv.rs#L2271-L2283)\n\n我们再看从 gRPC 指向 Txn 的红线。它代表 RPC 请求从 gRPC 模块流到事务模块的这一步。这里相应的也有两个 API 的调用,分别是 `sched_prewrite` 和 `sched_commit`,在这两个 API 中,事务模块会对 request 做一些检查,比如检查 write conflict,计算 commit ts 等(事务的细节可以参考 TiKV 的源码阅读文章,在这里就先跳过了。)\n\n### Txn -> Raftstore\n\n- txn prewrite: [Engine::async_write_ext(RaftCmdRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/storage/txn/scheduler.rs#L1323)\n- txn commit: [Engine::async_write_ext(RaftCmdRequest)](https://github.com/tikv/tikv/blob/v6.4.0/src/storage/txn/scheduler.rs#L1323)\n\n事务模块到 Raftstore 的红线代表:Request 通过检查后,会被事务模块序列化成对 KV 的操作,然后被组装成 `RaftCmdRequest`。`RaftCmdRequest` 再经由 `Engine::async_commit_ext API` 被发送至 Raftstore 模块。\n\n大家可以看到 prewrite 和 commit 都是变成了 `RaftCmdRequest`,也都是通过 `Engine::async_commit_ext` 发送到 Raftstore 模块的。这说明了什么呢?它说明了到 Engine 这一层,TiDB 的请求中的事务信息已经被“抹去”了,所有的事务信息都存到了 key 和 value 里面。\n\nRaftstore 模块会将这些 key value 提交到 Raft Log 中,如果 Raft Log Commit 成功,Apply 线程会将这些 key 和 value 写入到 Rocksdb。(这里面的细节可以参考 [TiKV 的源码阅读文章](https://cn.pingcap.com/blog/?tag=TiKV%20源码阅读),在这里就先跳过了。)\n\n### Rafstore -> CDC\n\n- RaftCmd: [CoprocessorHost::on_flush_applied_cmd_batch(Vec)](https://github.com/tikv/tikv/blob/v6.4.0/components/raftstore/src/store/fsm/apply.rs#L597)\n- Txn Record: [Engine::async_snapshot()](https://github.com/tikv/tikv/blob/v6.4.0/src/server/raftkv.rs#L431)\n \n从这里起,数据开始流出了,从 Raftstore 到 CDC 模块有两条蓝线,对应这里的两个重要的 API,分别为 `on_flush_applied_cmd_batch` 实时数据的流出,和 `async_snapshot` 历史增量数据的流出(后面会说细节)。\n \n### CDC -> gRPC -> TiCDC\n \n- ChangeDataEvent: [Service::event_feed() -> ChangeDataEvent](https://github.com/tikv/tikv/blob/v6.4.0/components/cdc/src/service.rs#LL201C8-L201C18)\n \n最后就是从 CDC 模块到 TiCDC 这几条蓝线了。数据进入 CDC 模块后,经过一系列转换,组装成 Protobuf message,最后交给 gRPC 通过 ChangeData service 中的 `EventFeed` 这个 RPC 发送到下游的 TiCDC。\n \n### CDC 模块中的数据流动\n\n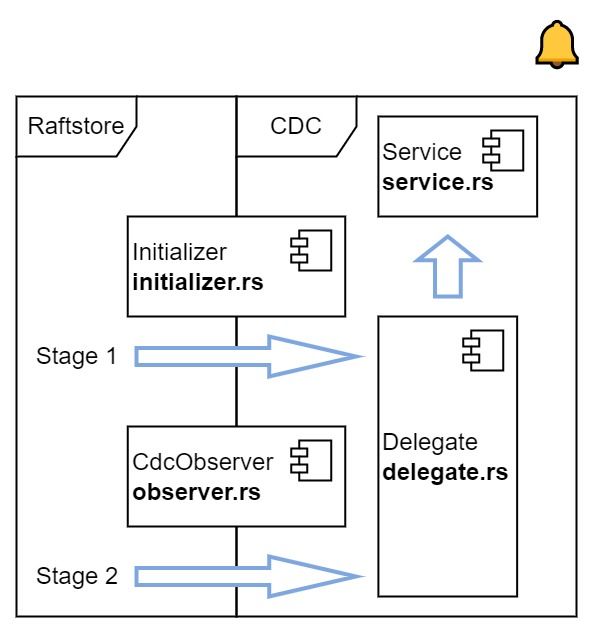\n\n上图示意了数据从 Raftstore 发送到 TiCDC 模块的细节。\n \n数据从 Raftstore 到 CDC 模块,可以分成两个阶段,对应两条链路:\n \n- **阶段 1,增量扫**,Initializer -> Delegate。\n \n Initializer 从 Raftstore 拿一个 Snapshot,然后在 Snapshot 上读一些历史数据变更,读的范围有两个维度:\n \n 1. 时间维度 `(checkpoint ts, current ts]`,checkpoint ts 可以理解成 changefeed 上的 checkpoint,current ts 代表 PD leader 上的当前时间。\n \n 2. key 范围 `[start key, end key)`,一般为 region 的 start key 和 end key。\n \n- **阶段 2,实时写入监听**,CdcObserver -> Delegate\n \n `CdcObserver` 实现对实时写入的监听。它运行在 Raftstore 的 Apply 线程中,只有在 TiCDC 对一个 Region 发起监听后才会启动运行。我们知道所有的数据都是通过 Apply 线程写入的,所以说 `CdcObserver` 能轻松地在第一时间把数据捕捉到,然后交给 `Delegate` 。\n \n我们再看一下数据从 CDC 模块到 gRPC 的流程,大体也有两部分。第一部分是汇总增量扫和实时写入;第二部分将这些数据是从 KV 数据反序列化成包含事务信息的 Protobuf message。我们再将这些事务结构体里面的信息给提取出来,填到一个 Protobuf message 里面。\n \n### Raftstore 和 TiCDC 的交互\n\n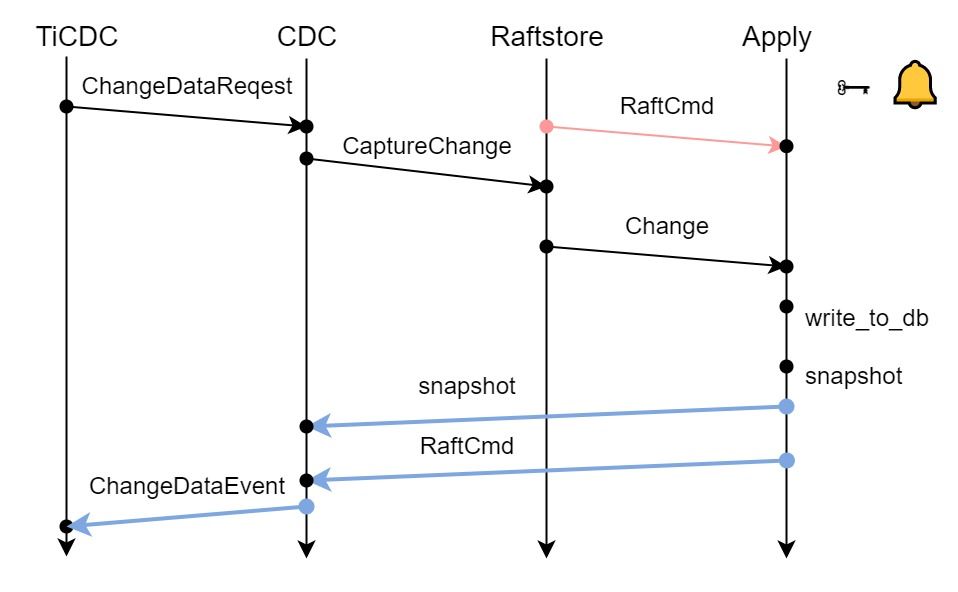\n\n上图是 Raftstore 和 CDC 模块的交互时序图。第一条线是 TiCDC,第二条是 CDC 线程,第三条是 Raftsotre 线程,第四条是 Apply 线程,图中每个点都是发生在线程上的一些事件,包含发消息、收消息和进程内部的处理逻辑。在这里我们重点说 Apply 线程。\n \nApply 线程在处理 Change 这个消息的时候,它会先要把缓存在内存中的 KV 的写入给刷到 RocksDB,然后获取 RocksDB 的 Snapshot,把 Snapshot 发送给 CDC 线程。这三步是串行的,保证了 Snapshot 可以看到之前所有的写入。有了这个机制保证,我们就可以确保 CDC 模块既不漏数据,也不多数据。\n \n## 数据变更事件有哪些?\n\n\n\n数据变更事件可分为两大类,第一类是 Event;第二类是 ResolvedTs。上图是 CDC Protobuf 的简化版定义,只保留了关键的 field。我们从上到下看下这个 Protobuf 定义。\n \n`EventFeed` 定义了 TiCDC 和 TiKV 之间的消息交互方式,TiCDC 在一个 RPC 上可以发起对多个 Region 的监听,TiKV 以 `ChangeDataEvent` 形式将多个 Region 的数据变更事件发送给 TiCDC。\n \n`Event` 代表着是 Region 级别的数据变更事件,包含了至少一个用户数据变更事件或者或者 Region 元数据的变更。它们是从单条 Raft Log 翻译得到的。我们可以注意到 `Event` 被 `repeat` 修饰了,也就是它可能包含了一个 region 多个数据变更,也可能包含多个不同 region 的数据变更。\n \n`Entries` 包含了多个 `Row`。因为在 `oneof` 里面不能出现 `repeated` ,所以我们用 `Entries` 包装了下。\n\n\n\n`Row` 里面的内容非常接近 TiDB 层面的数据了,它是行级别的数据变更,包含:\n1. 事务的 start ts;\n2. 事务的 commit ts;\n3. 事务写入的类型,Prewrite/Commit/Rollback;\n4. 事务对数据的操作,`op_type` ,put 覆盖写一行和 delete 删除一行;\n5. 事务写入的 key;\n6. 事务写入的 value;\n7. 该事务之前的 value,old value 在很多 CDC 协议上都会有体现,比如说 MySQL 的 maxwell 协议中的 “old” 字段。\n \n## 如何确保完整地捕捉分布式事务的数据变更事件?\n \n### 什么是“完整”?\n \n我们需要定义完整是什么。在这里,“完整”的主体是 TiDB 中的事务,我们知道 TiDB 的事务会有两个写入事件,第一个是 prewrite,第二是 commit 或者 rollback。同时,TiDB 事务可能会涉及多个 key,这些有可能分布在不同的 region 上。所以,我们说“完整”地捕捉一个事务需要捕捉它涉及的**所有的 key** 和**所有的写入事件**。\n\n\n\n上图描绘了一个涉及了三个 key 的事务,P 代表事务的 prewrite,C 代表事务的 commit,虚线代表一次捕捉。\n \n前面两条虚线是不“完整”的捕捉,第一条虚线漏了所有 key 的 commit 事件,第二条虚线捕捉到了 k1 和 k2 的 prewrite 和 commit,但漏了 k3 的 commit。如果我们强行认为第二条虚线是“完整”的,则会破坏事务的原子性。\n \n最后一条虚线才是“完整”的捕捉,因为它捕捉到了所有 key 的所有写入。\n \n### 如何确认已经“完整”?\n \n确认“完整”的方法有很多种,最简单的办法就是--等。一般来说,只要我们等的时间足够长,比如等一轮 GC lifetime,我们也能确认完整。但是这个办法会导致 TiCDC 的 RPO 不达标。\n \n\n\n上图最后两条虚线是两次“完整”的捕捉,假如第四条线十年之后才产生的,显然它对我们来说是没有意义的。第四条虽然是“完整”的,但是不是我们想要的。所以我们需要一种机制能够尽快地告知我们已经捕捉完整了,也就是图中第三条虚线,在时间上要尽可能地靠近最后一个变更的捕捉。那这个机制的话就是前面提到的 resolved ts。\n \n### ResolvedTs 事件及性质\n\n\n\nResolvedTs 在 Protobuf 中的定义比较简单,一个 Region ID 数组和一个 resolved ts。它记录了**一批** Region 中**最小的** resolved ts,会混在数据变更事件流中发送给 TiCDC。从 resolved ts 事件生成的时候开始,TiDB 集群就不会产生 commit ts 小于 resolved ts 的事务了。从而 TiCDC 收到这个事件之后,便能确认这些 Region 上的数据变更事件的完整性了。\n \n### resolved ts 的计算\n\n\n\nResolved ts 的计算逻辑在 resolver.rs 文件中,可以用简单三行伪代码表示:\n \n- 第一行,它要从 PD 那边取一个 TS,称它为 `min_ts`。\n- 第二行,我们拿 `min_ts` 和 Region 中的所有 lock 的 start ts 做比较,取最小值,我们称它为 `new_resolved_ts` 。\n- 我们拿 `new_resolved_ts` 和之前的 `resolved_ts` 做比较,取最大值,这就是当前时刻的 resolved ts。因为它小于所有 lock 的 start ts,所有它一定小于这些 lock 的未来的 commit ts。同时,在没有 lcok 的时候,`min_ts` 会变成 resolved ts,也是就当前时刻 PD 上最新的 ts 将会变成 resolved ts,这确保了它有足够的实时性。\n \n### 数据变更事件流的例子\n\n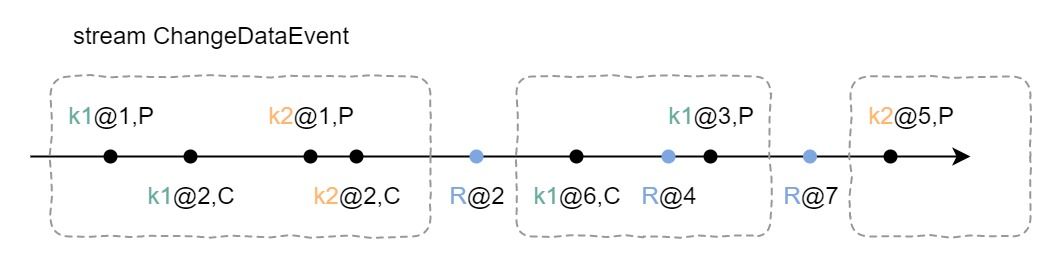\n\n上图是一个数据变更事件流的例子,也就是 gRPC EventFeed 中的 `stream ChangeDataEvent`。\n \n例子中有三个事务和三个 resolved ts 事件:\n \n- 第一个事务涉及了 k1 和 k2,它的 start ts 是 1, commit ts 是2。\n- 第二个事务只包含了 k1 这一个 key,它的 start ts 是 3,commit ts 是 6,注意,这个事务在事件流中出现了乱序,它的 commit 先于 prewrite 出现在这条流中。\n- 第三个事务包含了 k2 的一个事务,注意它只有一个 prewrite 事件,commit 事件还没发生,是一个正在进行中的一个事务。\n- 第一个 resolved ts 事件中的 resolved ts 是 2,代表 commit ts 小于等于 2 的事务已经完整发送,在这个例子中可以把第一个事务安全的还原出来。\n- 第二个 resolved ts 事件中的 resolved ts 是 4,这时 k1 的 commit 事件已经发送了,但是 prewrite 事件没有,4 就阻止了还原第二个事务。\n- 第三个 resolved ts 事件出现后,我们就可以还原第二个事务了。\n \n## 结尾\n \n以上就是本文的全部内容。希望在阅读上面的内容后,读者能知道文章开头的四个问题和了解:\n \n- 🔔数据从 TiDB 写入到 TiKV CDC 模块输出的流程\n- 🗝️了解如何完整地捕捉分布式事务的数据变更事件","author":"沈泰宁","category":1,"customUrl":"ticdc-source-code-reading-2","fillInMethod":"writeDirectly","id":445,"summary":"本文是 TiCDC 源码解读的第二篇,将介绍 TiCDC 的重要组成部分,TiKV 中的 CDC 模块。","tags":["TiCDC"],"title":"TiCDC 源码阅读(二)TiKV CDC 模块介绍"}},{"relatedBlog":{"body":"TiCDC 是一个通过拉取 TiKV 日志实现的 TiDB 增量数据同步工具,具有还原数据到与上游任意 TSO 一致状态的能力,同时提供开放数据协议,支持其他系统订阅数据变更。TiCDC 运行时是无状态的,借助 PD 内部的 etcd 实现高可用。TiCDC 集群支持创建多个同步任务,向多个不同的下游进行数据同步。\n\n在 4.0 之前,TiDB 提供 TiDB Binlog 实现向下游平台的近实时复制,在 TiDB 4.0 中,引入 TiCDC 作为 TiDB 变更数据的捕获框架。 TiCDC 首个 GA 版本随着 TiDB 4.0.6 正式发布,具备生产环境的运行能力,主要优势如下:\n\n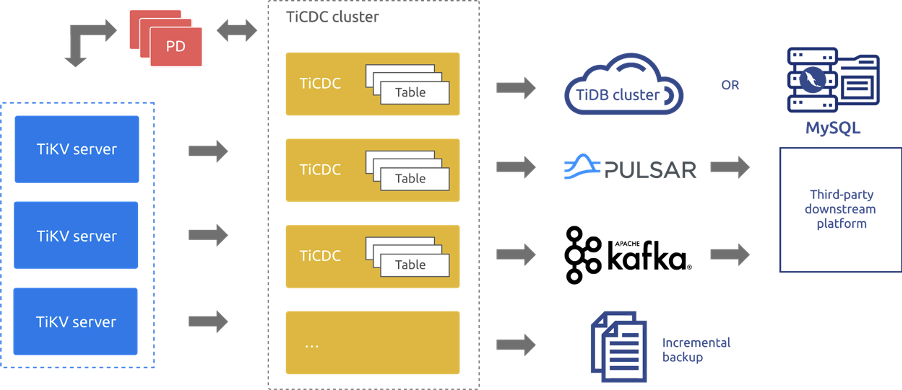\n\nTiCDC 系统架构图
\n\n- **数据高可用**:TiCDC 从 TiKV 获取变更日志,意味着只要 TiKV 具备高可用就能保证数据的高可用,遇到 TiCDC 全部异常关闭的极端情况,后续启动还能正常获取数据。\n\n- **水平扩展**:支持组建多 TiCDC 节点集群,将同步任务均匀地调度到不同节点上,面对海量数据时,可以通过添加节点解决同步压力过大的问题。\n\n- **自动故障转移**:当集群中的一个 TiCDC 节点意外退出时,该节点上的同步任务会自动调度到其余的 TiCDC 节点上。\n\n- **支持多种下游系统和输出多种格式**:目前已经支持兼容 MySQL 协议的数据库、Kafka 和 Pulsar 分布式流处理系统,支持输出的格式有 [Apache Avro](http://avro.apache.org/),[Maxwell](http://maxwells-daemon.io/) 和 [Canal](https://github.com/alibaba/canal)。 \n\n## 应用场景\n\n### 两中心主备\n\n数据库作为企业 IT 的核心,在稳定运行的基础之上,数据库的容灾建设成为保障业务连续性的前提条件。\n\n综合考量业务关键性、成本等因素,部分用户希望核心数据库只需要完成主备站点的容灾即可,利用 TiCDC 构建 TiDB 主备站点的容灾方案成为理想之选。该方案基于 TiCDC 的数据同步功能,可以适配两个中心长距离间隔、网络延迟较大的场景,进行两个数据中心 TiDB 集群之间的数据单向同步,保障事务的最终一致性,实现秒级 RPO 。\n\n### 环形同步与多活\n\n利用 TiCDC 实现三个 TiDB 集群之间的环形同步,构建 TiDB 多中心的容灾方案。当一个数据中心的机柜发生意外掉电,可以把业务切换到另一个数据中心的 TiDB 集群,实现事务的最终一致性和秒级 RPO。为了分担业务访问的压力,在应用层可以随时切换路由,将流量切换到目前负载较小的 TiDB 集群提供服务,实现负载均衡,在满足数据高可用的同时提升容灾能力。\n\n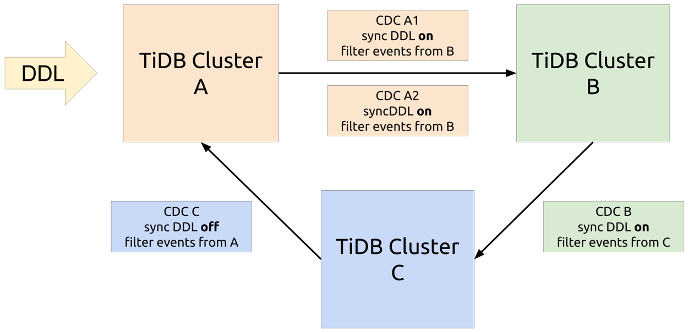\n\nTiCDC环形同步拓扑图
\n\n### 数据订阅\n\nTiCDC 为下游数据消费端提供实时、高吞吐、稳定的数据订阅服务,通过开放数据协议(Open Protocol )与 MySQL、Kafka、Pulsar、Flink、Canal、Maxwell 等多种异构生态系统对接,满足用户在大数据场景中对各类数据的应用与分析需求,广泛适用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等场景。\n\n## 最佳实践\n\n### 小红书\n\n小红书是年轻人的生活方式平台,用户可以通过短视频、图文等形式记录生活点滴,分享生活方式,并基于兴趣形成互动。截至到 2019 年 10 月,小红书月活跃用户数已经过亿,并持续快速增长。\n\n小红书在报表分析、大促实时大屏、物流仓储、电商数据中台、内容安全审核分析等多个场景使用 TiDB 承载核心业务。在内容安全审核分析场景,上游 TiDB 承载安全审核数据的实时记录,由线上应用直接写入,实现实时数据的监控和分析。\n\n在审核数据分析的业务流程中,通过 TiCDC 抽取 TiDB 的实时流数据,接到下游 Flink 进行实时计算聚合,计算结果再次写入 TiDB,用于审核数据的分析、人工效率的分析和管理等。小红书通过调用 TiCDC 内部 API([Sink Interface](https://pkg.go.dev/github.com/pingcap/ticdc@v0.0.0-20200914115832-993bfabc4696/cdc/sink?tab=doc#Sink)) 自定义 Sink,使用 Canal 协议发送数据到 Flink,对接已有业务系统,显著降低业务系统的改造成本。TiCDC 高效的数据同步,对异构数据生态的支持,为小红书业务数据的实时处理奠定了坚实基础。\n\n### 汽车之家\n\n汽车之家是全球访问量最大的汽车网站,致力于通过产品服务、数据技术、生态规则和资源为用户和客户赋能,建设“车媒体、车电商、车金融、车生活” 4 个圈。\n\nTiDB 在汽车之家已经稳定运行两年多的时间,承载了论坛回复,资源池,好友关系等重要业务。在 2020 年 818 大型促销活动中,汽车之家采用 TiDB 两地三中心的方案,为秒杀、红包、抽奖、摇一摇等场景提供全方位的数据保障,使用 TiCDC 将 TiDB 集群数据实时同步至下游的 MySQL 数据库,作为故障应急的备份,实现业务容灾能力的提升。TiCDC 数据同步的延迟在秒级别,很好地满足了线上促销类业务的实时性要求。\n\n智能推荐是汽车之家的一个重要业务,资源池是智能推荐的底层存储。资源池接收和汇聚各类资讯信息,进行数据加工后供首页推荐、产品展示、搜索等业务前台做推荐展示。资源池前期使用 MySQL 作为存储层,采用 MySQL Binlog 传入 ElasticSearch,满足检索场景需求。由于 MySQL 出现性能和容量的瓶颈,切换到 TiDB 之后,汽车之家采用 TiCDC 做异构数据的同步,替换原有的 MySQL Binlog 方案。TiCDC 高可用、低延迟、支持大规模集群等特性,为业务提供稳定的数据支撑。汽车之家基于 TiCDC 开发了日志数据输出到 Kafka 接口,实现海量异构数据的同步处理,目前已经上线并稳定运行两个多月。\n\n### 海尔智家\n\n海尔智家 APP 是海尔发布的移动端官方体验交互入口,为全球用户提供智慧家庭全流程服务、全场景智家体验与一站式智家定制方案。\n\n海尔智家的 IT 技术设施构建在阿里云上,核心业务要求数据库支持 MySQL 协议,在满足强一致分布式事务的基础上,提供灵活的在线扩展能力,并且可以与各类大数据技术生态紧密融合,TiDB 4.0 成为海尔智家的理想之选。\n\n利用 TiDB 增量数据同步工具 TiCDC 将用户信息和生活家信息同步到 ElasticSearch,提供近实时的搜索功能。目前用户表数据近千万,数据量达到 1.9G,Kafka 日消费消息量在 300万左右。此外,TiCDC 为智能推荐的大数据服务提供稳定、高效的数据同步,基于统一的 TiCDC Open Protocol 行级别的数据变更通知协议,极大方便了不同部门的数据解析需求,目前智能推荐的功能正在开发中。\n\n### 知乎\n\n知乎是中文互联网综合性内容平台,以“让每个人高效获得可信赖的解答”为品牌使命和北极星。\n\n知乎在首页个性化内容推荐、已读服务等场景中使用 TiDB 作为核心数据库,通过 TiCDC Open Protocol 输出日志到 Kafka,进行海量的消息处理。随着业务量级的增长,在使用的过程中遇到了诸多因 Kafka 架构和历史版本实现上的限制而引发的问题。考虑到 Pulsar 对原生跨地域复制(GEO-Replication)的支持同知乎未来基础设施云原生化的方向更加契合,知乎开始在一些业务中使用 Pulsar 替换 Kafka 。\n\n知乎对 TiCDC 的核心模块进行了一系列开发工作(https://github.com/pingcap/ticdc/pull/751, https://github.com/pingcap/ticdc/pull/869),把 TiCDC Sink 与 Pulsar 进行对接,实现 TiCDC 的数据同步到 Pulsar。借助 Pulsar 所具有的 GEO-Replication 功能,可以为 TiCDC 的消费者带来地理位置无关的变更事件订阅能力。Pulsar 集群的快速节点扩容、故障的快速恢复能力可以为 TiCDC 事件的消费方提供更优的数据实时性保障。\n\n从前期业务的实践来看,Pulsar 与 TiCDC 的应用取得了理想效果。知乎将推动各项业务从 Kafka 向 Pulsar 进行全面的迁移,未来也将应用 Pulsar 到跨集群同步 TiDB 数据的场景下。\n\n## 体验 TiCDC\n\n大家可以通过 TiUP ([部署文档](https://docs.pingcap.com/zh/tidb/stable/manage-ticdc#%E4%BD%BF%E7%94%A8-tiup-%E9%83%A8%E7%BD%B2%E5%AE%89%E8%A3%85-ticdc))上快速部署 TiCDC,通过 `cdc cli` 创建同步任务,将实时写入同步到下游的 TiDB 中,或者下游 Pulsar 中,又或者下游 Kafka 中([操作文档](https://docs.pingcap.com/zh/tidb/stable/manage-ticdc#%E7%AE%A1%E7%90%86%E5%90%8C%E6%AD%A5%E4%BB%BB%E5%8A%A1-changefeed))\n\n对于 4.0.6 GA 之前版本的用户,请参考[升级文档](https://docs.pingcap.com/zh/tidb/dev/manage-ticdc#%E4%BD%BF%E7%94%A8-tiup-%E5%8D%87%E7%BA%A7-ticdc)。\n\n## 致谢\n\n感谢[所有 TiCDC 的贡献者](https://github.com/pingcap/ticdc/graphs/contributors),TiCDC 能够走到 GA 离不开每一位贡献者的努力!","author":"PingCAP","category":1,"customUrl":"ticdc-ga","fillInMethod":"writeDirectly","id":219,"summary":"本文将向大家介绍 TiCDC,一个通过拉取 TiKV 日志实现的 TiDB 增量数据同步工具,具有还原数据到与上游任意 TSO 一致状态的能力,同时提供开放数据协议,支持其他系统订阅数据变更。","tags":["TiCDC","TiDB"],"title":"TiCDC 首个 GA 版本发布,特性与场景全揭秘丨TiDB 工具"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}