{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/real-time-cumulative-index-algorithm-based-on-tidb-and-flink",
"result": {"pageContext":{"blog":{"id":"Blogs_488","title":"基于 TiDB + Flink 实现的滑动窗口实时累计指标算法","tags":["TiDB","Flink"],"category":{"name":"案例实践"},"summary":"当前的市场环境对产品运营提出了更高的要求,特别是对数据指标实时性的要求日益严格。为了能够实时监测数据动态和特征用户的状态,我们采用了分布式数据库 TiDB 和计算框架 Flink 的组合,提出了一种基于滑动窗口的实时累计指标算法。","body":"> 本文作者李文杰,网易游戏计费 TiDB 负责人\n\n## 导读\n\n当前的市场环境对产品运营提出了更高的要求,特别是对数据指标实时性的要求日益严格。为了能够实时监测数据动态和特征用户的状态,我们采用了分布式数据库 TiDB 和计算框架 Flink 的组合,提出了一种基于滑动窗口的实时累计指标算法。该算法能够在市场营销活动中发挥积极的作用,显著改善用户体验并促进收益增长。\n\n## 前言\n\n在不少的支付分析场景里,大部分累计值指标可以通过 T+n 的方式计算得到。随着行业大环境由增量市场转为存量市场,产品的运营要求更加精细化、更快速反应,这对各项数据指标的实时性要求已经越来越高。产品如果能实时把握应用的整体运行情况或特征用户的状态,就可以及时安排合理的市场营销活动,这对改善用户的体验和促进收益的增长有明显的帮助。\n\n## 需求指标\n\n有一个场景为了进一步优化营销活动内容,希望我们实时提供每个玩家在最近 1 年、2 年、5 年、10 年内的实时消费总金额。 \n\n要实时计算每个玩家最近 N 年的实时消费累计总金额,一方面要考虑到这个指标随着时间推进它可能在不断增加,另一方面会有数据过期了而不再属于这个统计周期内,要及时减去,从而维护一个动态的累计值。 \n\n这里的每一个用户的“最近 N 年”指标是不断前进的,涉及到产品上线以来的全部用户,其累计的用户量、支付数据都在亿级别以上,且明确要求实时统计历史数据。综合分析下来,解决该问题具有一定的挑战性。 \n\n在经过充分调研和分析后,基于实时计算框架 Flink 和分布式数据库 TiDB 的组合使用,我们提出了一种实时计算滑动窗口内累计指标的算法,在一个数据库里同时支持实时 OLAP 计算和 OLTP 数据服务,有效地解决了这个问题,目前已经在线上稳定服务了一段时间。下面给大家分享下我们的思考和实践。\n\n## 数据特点\n\n首先我们先从整体上评估下数据的特点,分析一下数据规模、有哪些关键问题对我们的计算有影响。\n\n### 数据概况 \n\n- 基础数据量大,存在乱序、重复等问题:\n - 数据源历史数据量较大,亿级别;日增日志数据在百万级别;\n - 原始日志数据打印在不同应用机器上,没有集中统一存储,分散;\n - 由于业务有等待逻辑,业务时间字段存在乱序问题,即先产生的数据的日志打印时间可能晚于后产生的数据的打印时间,时间乱序的数据如果不及时处理可能会出现漏算的情况;\n - 由于业务有重试机制,相同的日志数据可能重复出现,数据重算会导致结果错误。\n- 聚合指标要求支持高并发访问:\n - 最终的结果指标要求支持 TP 服务访问,且满足高并发场景。\n\n线上的应用部署在不同的机器上,先后请求的数据的业务时间和日志打印时间,可能是乱序的,这会导致我们需要解决数据排序的问题。且由于业务存在请求重试逻辑,数据也有可能是重复的,需要设计好去重机制。\n\n### 实现重难点\n\n- 保证计算的实时性、准确性:\n - 需要处理数据乱序问题,使其有序,然后实时监听数据再分别进入统计周期开始边界、结束边界的变化情况,准确在累计值上执行加、减操作。\n- 计算的事务性:\n - 在对同一个用户的累计指标执行加、减操作时,要严格保证每个操作的原子性和隔离性;\n - 此外,还要保证不同用户之间的操作也是事务隔离的。\n- 累计指标可重入:\n - 数据经过统计窗口边界时,有且仅有一次被计算,需要处理原始数据重复问题;\n - 程序重启时数据计算结果应该保持不变,指标的值不会变多,也不会变少,即保证重入。\n\n主要的问题在于对于统计最近一段时间内的值,这个“最近”是实时变化的,即统计区间的开始、结束时间点也是实时变化的,这个问题可能就比较复杂了,需要严格保证每个操作的原子性和隔离性,而且每笔数据不能重复算也不能漏算,否则就会出现数据错误。\n\n## 可选算法\n\n### 实时统计 \n\n该方案是指,当查询某个用户最近 N 年的累计值的请求发送过来时,直接到数据库统计得到结果,可以理解为是一个用户级的实时 AP 操作。这种方法在良好的表设计、索引设计下,大部分场景在秒级别可以完成查询,在并发高时数据库资源很容易出现算力瓶颈,导致服务不稳定,业务受影响。 \n\n- 优点\n - 方案简单,实现容易;\n - 能获取到准确的指标结果。\n\n- 缺点\n - 由业务方维护计算的方法,访问和计算是同时进行的,没有做到分离;\n - 数据库要有实时高并发的 AP 能力,对数据库要求过高;\n - 计算全部依托于数据库,IO、CPU等资源容易出现瓶颈;\n - 高并发时服务不稳定。\n\n总的来说,实时统计这个算法实现起来相对简单,但服务容易因算力问题影响,实时性不能保证,尤其是高并发场景容易出现问题,线上实时数据服务慎用该策略。 \n\n### 全量缓存+实时增量 \n\n该方案提前将全部用户的最近 N 年的累计值算好,并缓存起来,业务方可以实时读取这个缓存,也能支持高并发实时响应。然后计算侧根据实时变化的情况,更新每个用户指标值。如果是在统计周期内用户有新增数据,则在缓存值基础上累加,如果在统计周期内有用户的数据过期了,则在缓存值的基础上减去。总之,总是维护好用户的实时累计值。 \n\n- 优点\n - 支持实时高并发读取;\n - 业务访问和计算分离,访问延迟低。\n\n- 缺点\n - 实时维护缓存,要引入额外的机制保障数据更新的事务性;\n - 容易出现读写冲突问题;\n - 数据没有落地,故障或宕机时数据丢失风险高;\n - 计算复杂,且不可重入。\n\n实时全量缓存方案,解决了实时全量统计的实时性和高并发访问的问题,但是也带来了数据操作的事务性、安全性等问题,有一定的可取之处,但缺点也很明显。\n\n### 全量持久化+实时增量 \n\n考虑到业务侧是 OLTP 的访问特性,要求支持低延迟高并发,提供点查的方式才是最高效的。 \n\n该方案在数据初始化时先提前算好全部用户的累计值,并存储到关系型数据库,再基于数据库的基量数据进行实时的增量更新操作。如果是在统计周期内用户有新增数据,则在基量值上累加,如果在统计周期内有用户的数据过期了,则在基量值上减去,一直基于实时的变化量来维护最新的累计值。 \n\n- 优点\n - 支持实时高并发读取;\n - 业务访问和计算分离,访问延迟低;\n - 数据存储在数据库,保存有最新的数据状态,能保证数据安全和事务性,进而能保证计算是可重入的。\n\n- 缺点\n - 计算复杂,程序维护成本较高;\n - 数据库要求高,必须能存储大量数据且支持高并发访问,且能应对未来的业务增长量。\n\n综合考虑之后,我们选用了全量持久化+实时增量的方案。 \n\n目前业界领域内处理实时数据的技术工具,选用 Flink 应该是毫无疑义的。数据库方面选型,我们需要考虑下面的场景: \n\n- 首先要求数据库具有灵活的扩展性,必须能存储数以亿计的历史数据,且能应对还在不断增长的数据规模;\n\n- 其次要支持良好的事务特性,这一方面支持最好的就是关系型数据库,要能保证数据操作时的事务隔离;\n\n- 同时在高并发场景下保证读、写互不影响,支持业务高并发访问。\n\n满足这些苛刻要求的数据库其实不多,分布式数据库 TiDB 就是其中一个非常优秀的选项 ,它能很好地满足上面的场景需求。\n\n## 数据模型 \n\n我们计算用户最近 N 年的累计值,这里有两个关键要素,一个是统计时间周期,一个是用户。 \n\n下面我们以统计时间周期为分析切入点,引入时间窗口来解决我们的统计问题。 \n\n### 时间窗口定义 \n\n一段固定长度的时间区间,即我们需求里说的“最近 N 年”,我们可以称其为一个时间窗口。如果一个时间窗口支持随着时间变化,那这个窗口就是动态变化的,根据动态变化的情况会有许多细分的窗口类型,用以解决不同场景的问题。下面主要介绍和我们业务相关度较高的滑动窗口和会话窗口。 \n\n#### 滑动窗口\n\n滑动窗口是固定长度的时间窗口,随着时间变化以一定的频率前进,它们之间允许有重叠。滑动窗口的滑动距离(window slide)可以控制生成新窗口的频率。如果 slide 小于窗口大小,不同的滑动窗口会有部分重叠。这种情况下,一个数据点可能被多个窗口包含在内。 \n\n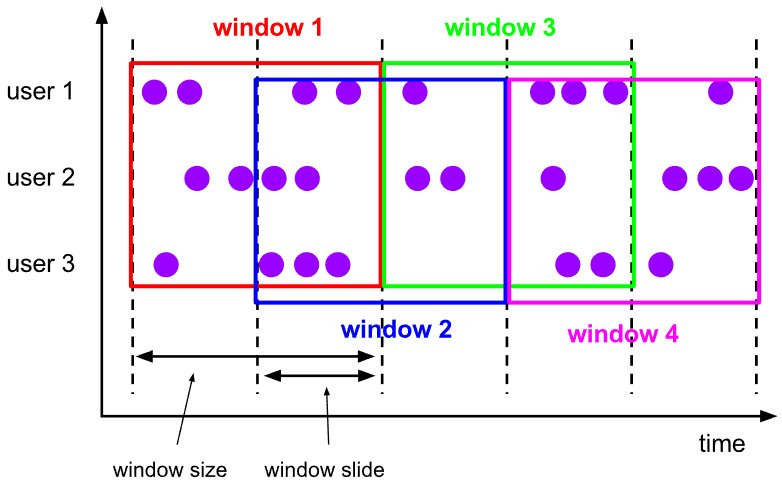\n\n如上图所示,比如我们设置了窗口的大小为 10 分钟,每 5 分钟滑动一次,则会在每 5 分钟后得到一个新的窗口, 且新窗口会包含一部分在之前的窗口里出现过的数据。 \n\n在滑动时间窗口中,我们通常要选择窗口大小和滑动步长。窗口大小指的是每个子时间段的长度,而滑动步长则指的是相邻子时间段之间的时间间隔。根据具体的场景,我们可以调整窗口大小和滑动步长,使得滑动时间窗口更好地适应不同的数据流处理需求。 \n\n这个数据模型,很符合我们的统计最近 N 年的实时累计值的场景。“最近 1 年”、“最近 2 年”、“最近 5 年”、“最近 10 年”就是我们的窗口大小,滑动步长是实时,这里为了分析方便,我们每 1 分钟滑动一次,即每分钟都会产生一个最近 N 年的滑动窗口。 \n\n#### 会话窗口\n\n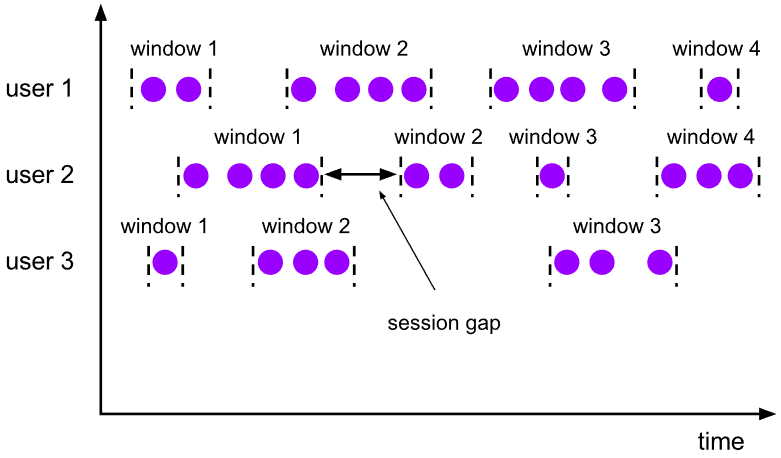\n\n与滑动窗口不同,会话窗口会为活跃数据创建窗口,会话窗口不会相互重叠,没有固定的开始或结束时间。我们可以设置固定的会话间隔(session gap)来定义多长时间算作不活跃。当超出了不活跃的时间段,当前的窗口就会关闭,并且将接下来的数据分发到新的会话窗口。 \n\n在我们的场景,相当于对每个用户维护一个永远不关闭的会话窗口,方便实时监听“最近”的情况,但会话窗口的开始时间不好跟随时间变化而动态设置。同时考虑到我们要分析的数据量在百万级以上,要实时维护这么多的会话窗口,资源消耗会比较多,难度会比较大。所以,会话窗口不合适我们的计算场景。 \n\n综合考虑后,我们选择了滑动窗口模型来开展我们的计算。这种处理技术常用于实时数据分析和流媒体处理中。它可以帮助我们对数据流中的信息进行实时监听并分析,能够快速响应数据流的变化。 \n\n## 业务实现 \n\n### 处理流程 \n\n整个处理数据流,过程大致如下: \n\n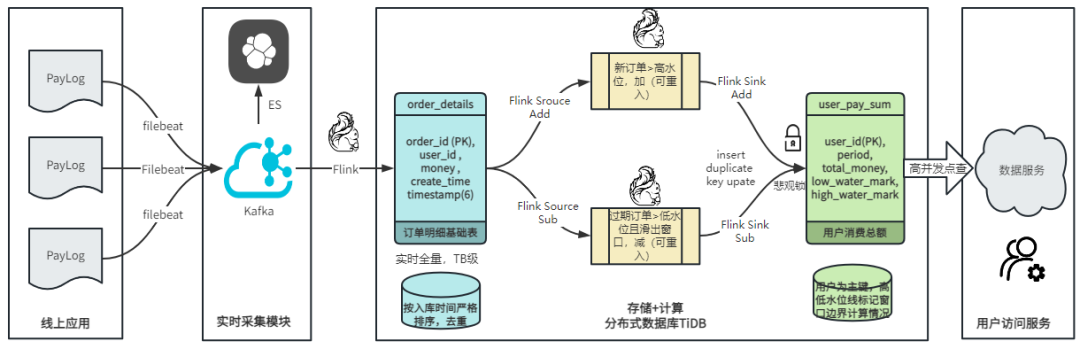\n\n**数据实时采集 **\n\n线上应用在不同机器上部署,实时产生日志数据,通过 Filebeat 采集并汇总数据流写入到 Kafka 中。\n\n**借助 TiDB 关系型数据库的特性解决数据乱序、重复问题,生成基础数据 ** \n\n设计合理的业务唯一键,给每一行数据设置一个精确到微秒的入库时间(create_time timestamp(6),CT),在我们的业务场景,能得全部入库数据按 CT 字段严格有序;\n\n同时,利用 TiDB 的唯一键特性对重复的数据去重;\n\nFlink 消费 Kafka,将经过 ETL 后基础数据实时写入到 TiDB 中生成基础数据表,供后续计算、数据校验、监控使用。\n\n**数据指标的持久化和可重入计算 **\n\n对 TiDB 的结果指标表设置用户维度的主键,同时设置每个用户在滑动窗口左、右边界已消费的数据的 CT 水位线,保证计算可重入要求,即经过窗口边界的数据只会计算一次;\n\nFlink 双 Source 读取按 CT 切片的开始边界、结束边界的数据,用双 Sink 分别负责指标的加、减。TiDB 集群事先设置为悲观锁事务模式,Flink 作业在 Sink 时执行串行的 INSERT ON DUPLICATE KEY UPDATE 语句完成累计值的加、减操作,可以保证操作事务的原子性、隔离性。经过调优上线后,该方式在我们的计算场景里也有不错的性能,能满足业务需求。\n\n**计算和对外访问同时服务** \n\n利用 TiDB 写操作不阻塞读的特性,在计算的同时数据也在实时对外服务,不影响线上服务可用性;\n\n用户是我们表的主键,而产品访问时是对用户的点查,所以我们的方案具备非常高的并发访问性能,远超过业务峰值。\n\n下面详细描述具体的计算过程。\n\n### 滑动窗口计算\n\n#### 窗口建模\n\n基于滑动窗口模型,结合我们的数据特性,定义了一个滑动的统计时间窗口,如下图。 \n\n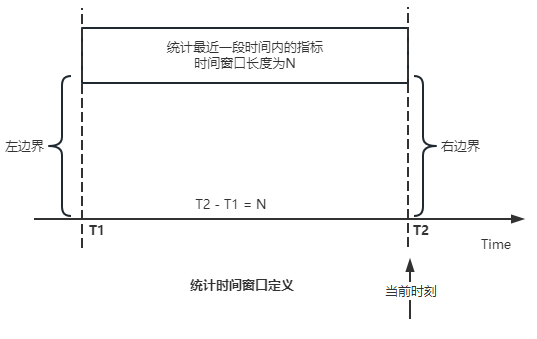\n\n最近 N 年的统计周期长度,由统计区间的开始时间 T1 (左边界) 和 T2 (右边界)共同决定,时间长度 N = T2 - T1 始终保持固定,即左右边界的间隔是固定不变的。 \n\n窗口的右边界 T2 随着时间变化,不断实时向前滑动,同时也牵引着整个窗口向前滑动。如下图所示,我们设定固定的前进频率为 Delta t ,窗口随该频率不断向前滑动,前进的步调频率最快可以到秒级,但是为了保证读取到的数据稳定性以及应对上游数据可能存在延迟的情况,我们通常设置为 30 秒或 1 分钟。 \n\n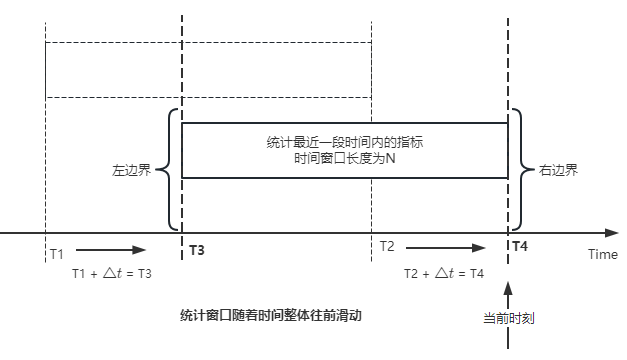\n\n#### 基础数据处理\n\n读取到线上日志数据写入到 TiDB 中生成基础数据时,我们借助 TiDB 关系型数据库的特性,解决数据排序、重复的问题。 \n\n- 通过提前设计合理的业务唯一键,Flink Sink 时用 INSERT INGORE 方式写入数据, 遇到相同的数据只会写入一行,达到去重的目的 ;\n- 同时,设置一个精确到微秒的入库时间字段(create_time timestamp(6),下文简称 CT),在我们的业务场景里数亿行数据全部入库,每一行数据都能做到按 CT 字段有序递增 。\n\nTiDB 不仅解决了海量数据的存储,还保证了优秀的读写性能。上游业务可以保证相同用户在同一时刻不会出现支付多笔的情况,为了防止极端情况的出现,Flink 使用串行 Sink 的方式写入基础数据,经过对几十亿行历史日志数据的重放入库验证,每一行数据都有严格的递增入库时间,可以保证其单调递增特性,同时也能达到万级的写入 QPS 性能。这是我们下面按时间切片来计算的关键所在。 \n\n#### 窗口内累计值计算 \n\n**1.计算流设计** \n\n为了保证同一个用户在相同步调下执行操作,我们起一条 Flink 计算流,流里设置两个 Source 和两个 Sink 分别负责指标累计值的加、减操作,Sink 时借助 TiDB 的悲观事务特性,整个过程可以保证操作的事务性和计算可重入。 \n\n- 这两个 Source 读取数据的时间点,分别指向统计时间窗口的左、右边界。指向右边界的指针负责用户累计金额的加操作,指向左边界的指针负责用户累计金额的减操作,它们使用相同的步调随着时间推进;\n- 假设有一个用户他每个时刻都有充值行为,那么随着时间推进,“最近 N 年”这个时间窗口也在不断推进,窗口的右边界是实时前进的,就会不断有新数据进来,计算累计值则需要不断加;窗口的左边界也在往前走,滑出左边界的数据就过期了、不在这个统计周期内了,所以左边界的指针就需不断减去这些值。\n\n在写入数据的时候,如果是首次计算则需要插入,如果不是首次写入则要求更新多列,于是我们使用了 INSERT ON DUPLICATE KEY UPDATE 方式执行加、减的操作,同时为了避免锁冲突而影响写效率,设置单线程串行的 Sink 行为。 \n\n**2.结果指标表设计** \n\n为了保证可重入和 Exactly Once 要求,即经过窗口边界的数据只计算一次。我们在 TiDB 数据库层面,在结果指标表内,我们通过对每个用户的指标设置两个水位线字段,分别标识最近一次的已经执行过的左边界、右边界数据。 \n\n- 以用户为维度,每个用户指标都有 low_water_mark 和 high_water_mark 这两个水位线时间来做标记这个累计指标的计算状态,它们来自基础数据表的入库时间。用户指标的 high_water_mark 与 low_water_mark 和 Flink 作业里窗口的左边界和右边界不太一样,作业里的左右边界时间是和真实世界一样的绝对时间 (True Time),而它们是业务上的逻辑时间,所以它们之间时间跨度,是可以超过窗口的长度的,这样以保证能统计到完整周期的指标。\n\n- 作业右边界指针读到的数据是最新的,要执行加操作,当在结果指标表没有该用户时(high_water_mark 为 null )说明是首次充值可以直接加,且同时设置该 CT 为其 low_water_mark 和 high_water_mark;如果该用户有在表里了则要求其 CT 大于 high_water_mark 才可以累加进去,否则不累加,累计进去的同时更新 high_water_mark 为当前 CT,以保证同一条数据的计算可重入,不会出现重复加的问题。\n\n- 左边界指标读到的数据是统计周期内过期的数据,目标是减去,原始数据的有序性保证了经过左边界的数据一定已经经过右边界,即一定已经完成了加的操作,所以不存在结果指标表没有该用户时的情况,为了避免重复减的问题,要求过期数据的 CT 小于统计周期开始时间且大于 low_water_mark 才执行减操作,同时更新 low_water_mark 为当前 CT。如果 CT 小于等于 low_water_mark 说明已经执行过减操作,不需要重复操作。\n\n利用 TiDB 写操作不阻塞读的特性,不管计算任务多么繁忙,只要不影响数据库性能,那线上服务都可以实时读到最新的结果指标,不会影响线上服务可用性,这一点也是 TiDB 非常优秀的地方。 \n\n**3.典型场景分析** \n\n下面我们通过不同场景来阐述该算法。 \n\n1)如上图所示,窗口在前一个统计窗口内容累计总金额值为 100,在经过一次滑动后,有一笔充值金额为 30 的新订单进入了统计周期内,体现在这笔订单的入库时间小于当前窗口的右边界,那么我们的计算 FLink 作业就能读取到该值,并在相应用户的累计值上执行加操作,得到实时的最近 N 年累计总充值指标。 \n\n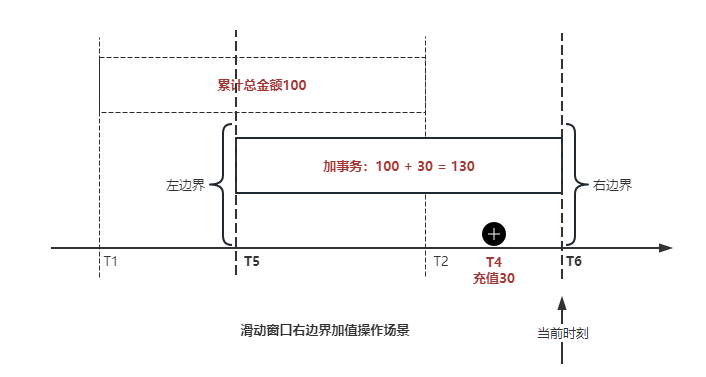\n\n2)同理,如下图,如果是有一笔数据随着窗口滑动而过期了,此时这笔订单的入库时间在最近 N 年之前,我们的计算 FLink 作业就能读取到该值,并在相应用户的累计值上执行减操作,得到实时的最近 N 年累计总充值指标。\n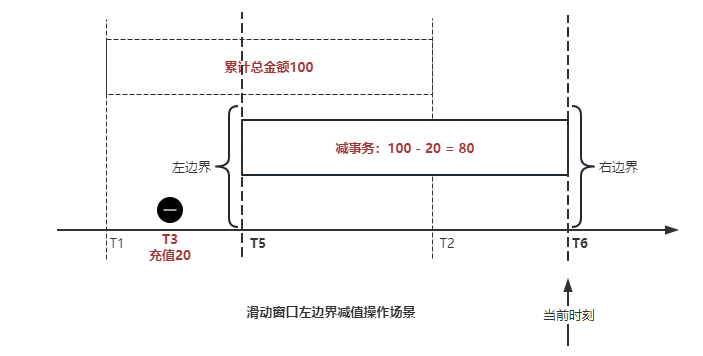\n\n\n3)更复杂的计算场景,如下图,如果随着窗口滑动同时有新数据进入,也有旧数据过期,那么流里设置的两个 Source 和两个 Sink 分别负责指标累计值的加、减操作。由于基础数据源是严格有序的和在 Sink 时设置了串行操作,同时我们将加、减操作放在了 TiDB 内执行,而 TiDB 具有优秀的事务机制保证,所以我们左、右边界的操作是相互独立的事务,互不影响。如果同时有多条新数据、多条过期数据,基础数据的有序性和 Sink 的事务性也可以保证数据的正常处理。\n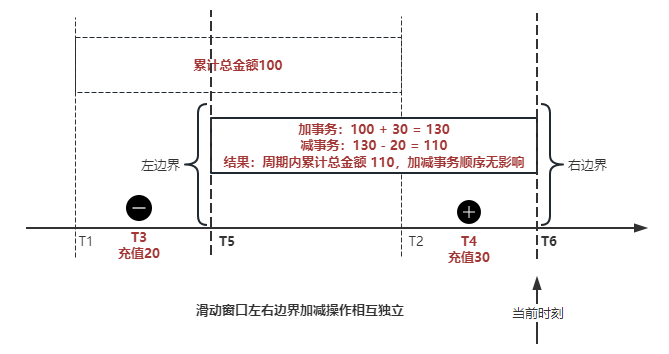\n\n## 应用与总结\n\n- 日志数据通过 Flink ETL 后写入到 TiDB 基础表,借助设置到微秒级别的入库时间,经过验证,在我们业务场景的数十亿行数据能能做到单调递增,这为我们后面的计算打下了关键性的基础。\n\n- 计算流首次启动时要处理历史数据,要设置好窗口的左右边界,假设要统计最近 1 年的累计消费金额,则需要手动指定右边界的 Source 起点为 365 天前,左边界的 Source 起点为 730 天前(左右边界共同决定统计窗口的长度)。设置 2 年、3 年、5 年、10 年的场景以此类推。\n\n - 在跑历史数据时,计算流的串行处理速度可以达到万级QPS,证明 TiDB 和 Flink 有非常优秀的计算能力;\n\n - 历史数据量大,初始化耗时通常较久,一个优化的方法是基于历史日志数据,使用离线统计的方式一次性先算好基量指标,然后 Flink 作业再基于此结果来计算。这可以大大缩短指标首次上线、故障恢复、数据重算等场景的时间,极大提高用户体验。\n\n- 计算策略里设计的每个环节都是可重入的,当遇到网络中断、数据库抖动或 Flink 流失败重启等故障,数据不会丢、也不会重算,可以保证数据的安全性。\n\n- 该算法已正式上线到生产环境,已稳定对外提供数据服务有数月之余。为了保证数据消费的稳定性,在不影响整体服务体验的情况下,我们设置 Flink 的消费时间比实时数据略迟一点时间,这也是一个实时计算的最佳实践经验。\n\n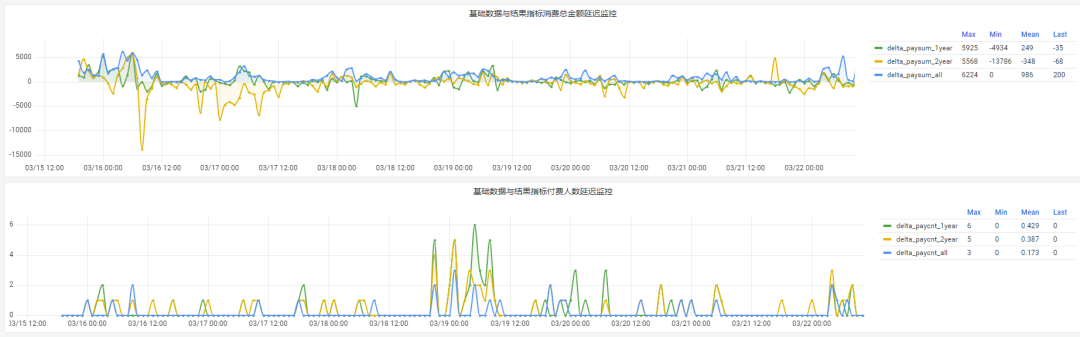\n\n## 适用场景 \n\n该基于 TiDB + Flink 的实时累计指标算法,目的是解决”最近一段时间的实时累计指标“的计算问题。 \n\n经过一些调整或优化,它也可以适用于很多的计算场景,如: \n\n- 有明确时间范围的实时指标:\n\n - 最近一段时间的实时充值总额、订单量、支付率等;\n\n - 最近一段时间的实时 PU/ARPU/ARPPU 等;\n\n - 最近一段时间的实时 AU/DAU//MAU、新增用户数等。\n\n- 适用的统计周期:最近一段时间,即最近 N 时/天/周/月/年,指定的统计时间窗口长度;\n\n- 适用的计算维度:产品、渠道、平台、用户、角色等。\n\n","date":"2023-05-06","author":"李文杰","fillInMethod":"writeDirectly","customUrl":"real-time-cumulative-index-algorithm-based-on-tidb-and-flink","file":null,"relatedBlogs":[{"relatedBlog":{"body":"## 作者简介\n\n孙晓光,PingCAP Community Development 团队负责人,原知乎基础研发团队架构师,长期从事分布式系统相关研发工作,关注云原生技术。\n\n本文来自孙晓光在 **Apache Flink x TiDB Meetup · 北京站**的演讲,主要分享了知乎在 TiDB x Flink 批流一体方面的部分工作,并以实际业务为例介绍如何**充分利用两者的特点完成端对端实时计算的闭环交付**。\n\n## 背景\n\n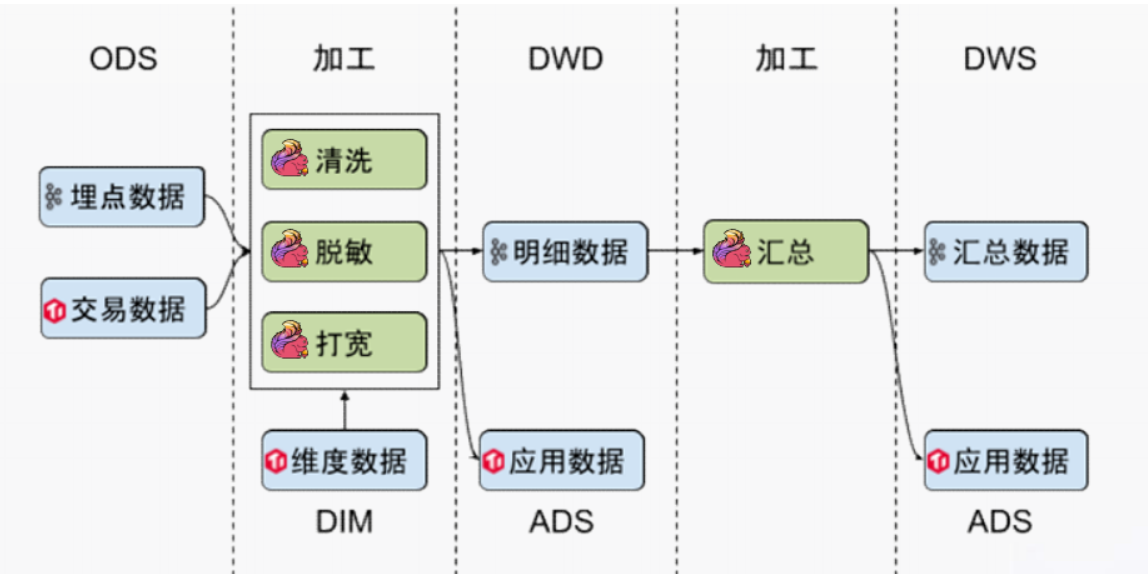\n\n上图是非常典型的**实时数仓链路**上的各个组件和数据,可以看到在很多地方 TiDB 和 Flink 都可以结合在一起去解决我们的业务问题。比如 TiDB 的大本营是**在线交易**,所以 **ODS** 是可以利用 TiDB 的,后边的**维表和应用数据存储**等也都可以利用 TiDB。\n\n## 实时业务场景\n\n### 场景分析\n\n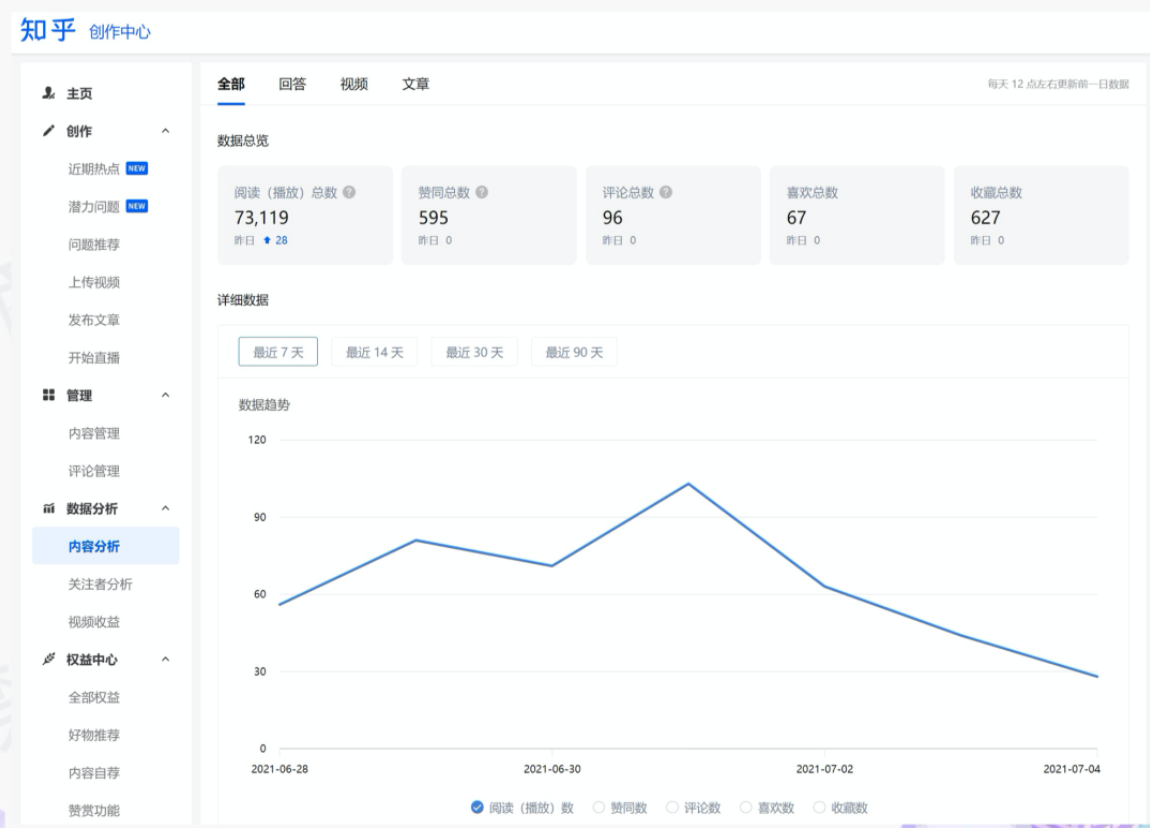\n\n先看一下知乎这边一个实际的业务场景,知乎主站上的创作中心为创作者提供了**内容交互数据**的分析能力。创作者可以在这看到自己创作的内容所获得的赞同、评论、喜欢、收藏的数据以及过去一段时间内这些数据的变化。\n\n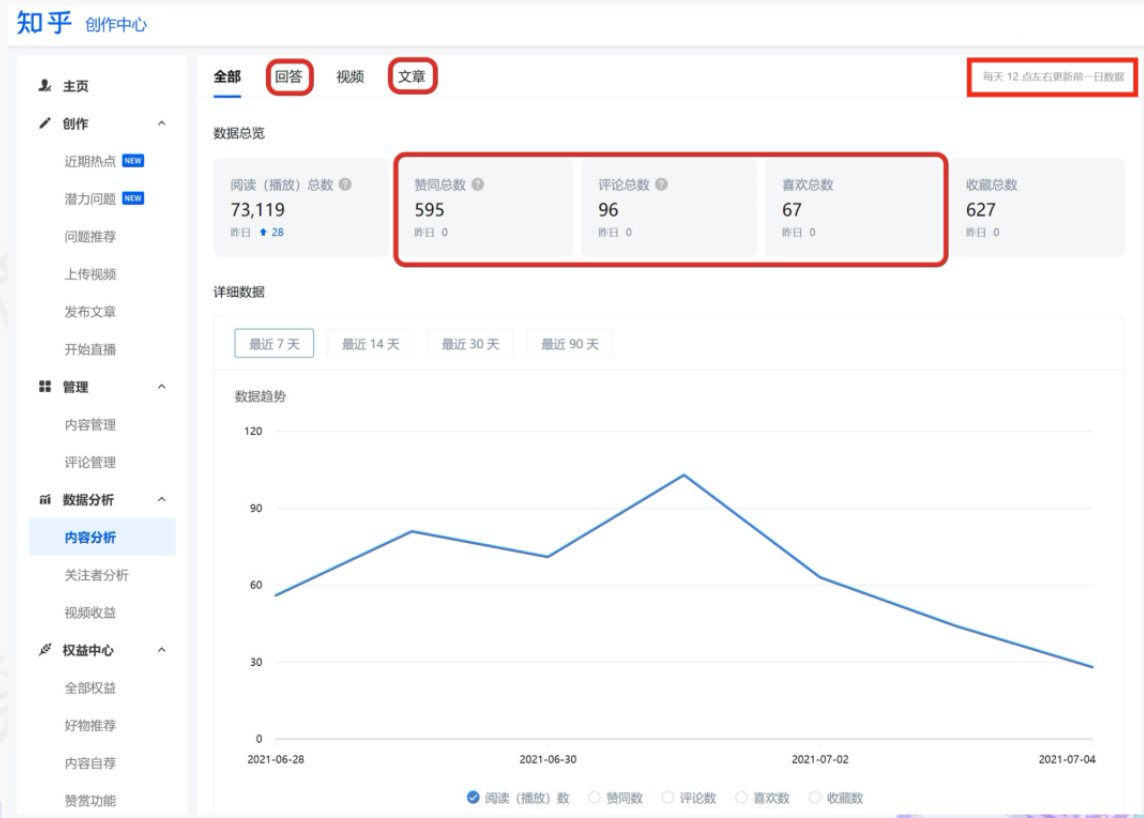\n\n这些数据可以帮助创作者更好地优化自己的创作。比如创作者对内容做了一些调整,然后发现交互数据开始发生显著的变化,创作者就可以基于这个信号对内容做相应的调整,去规避不好的或者进一步发扬光大好的策略,因此对创作者具有非常大的价值。另外,这个数据越即时,创作者的策略调整就能越即时。比如说创作者刚追更了一篇回答,希望立刻就可以看到相关的数据变化,如果数据变化是正向的,下次就可以做更多类似的调整。或者抽象出来过去好的调整都是什么,这样每次都可以基于之前的经验做出读者更喜欢的创作。\n\n可惜对创作者这么有价值的数据目前仍然不是实时的,大家可以在右上角看到数据更新的说明。这是我们在实时应用上还没有覆盖得足够好的一个证据,还是用传统的 **T+1** 的技术去实现的一个产品。\n\nFlink 是我们把类似创作中心这样的应用场景实时化必然的选择,然而同大量使用 MySQL 的公司不同,知乎站上接近 **40%** 的 MySQL 数据库已经完成了到 TiDB 的迁移,所以我们必须将 TiDB 和 Flink 的实时计算能力做一个深入的整合。在未来当 TiDB 成为我们绝对主力数据库的时刻,能够获得更好的综合收益。\n\n接下来我们探讨如何将内容交互数据的统计实时化,利用 TiDB 和 Flink 实现回答和文章这两种内容的喜欢、评论和赞同数据的实时计算。\n\n### 业务数据模型分析\n\n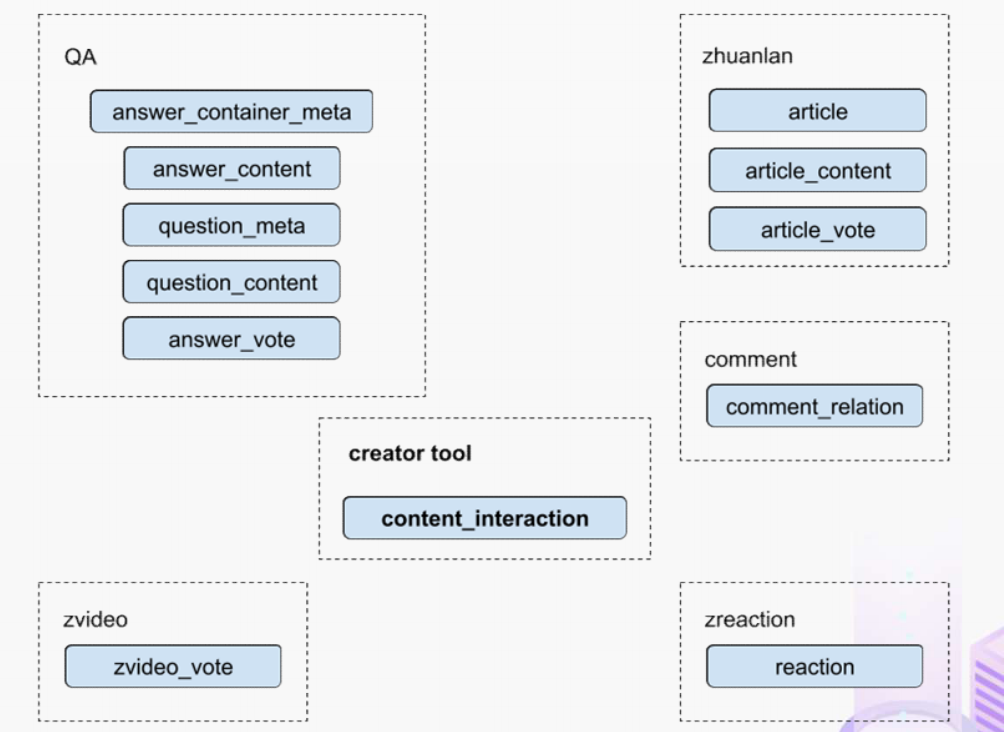\n\n图中是对这些数据进行实时计算所需要关注的相关业务,这几个业务包括问答也就是左边的 QA,还有右边的专栏文章,以及评论、用户交互、视频回答。我们希望通过整合这些分散在不同业务里面的数据,得到创作者中心里的用户交互的统计数据,而且我们希望它是**实时的**。\n\n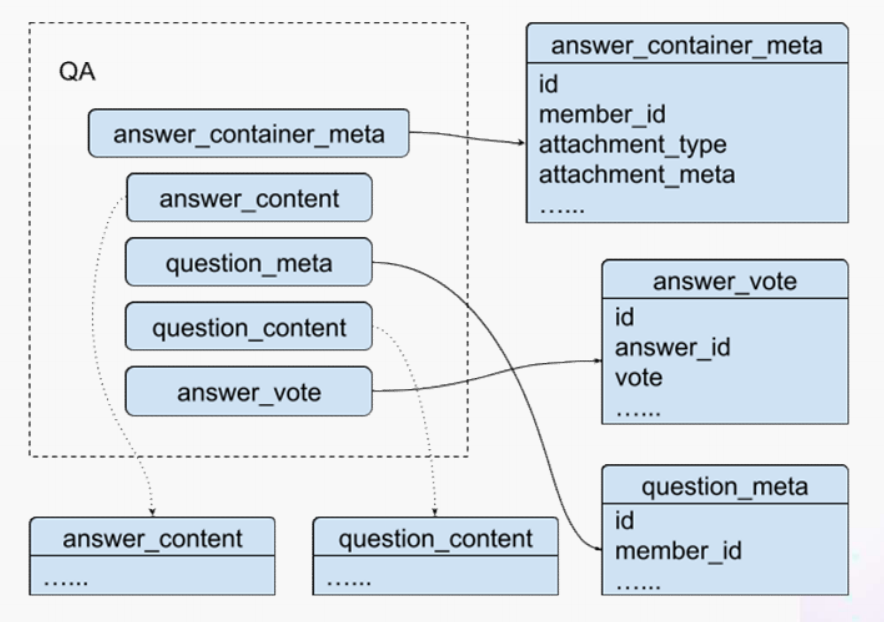\n\n首先我们先放大一下**问答业务**,左边是 QA 业务里比较基础的几个基本表,实质上我们并不需要为计算交互信息了解到所有表所有的细节,只需要关注右边这几张表的部分字段就可以了。从这些表里我们只需要知道回答的 id,这个回答创作者的 member_id 还有被点赞的回答 id,就可以完整地计算某一个人的某一个回答有多少点赞。\n\n\n\n与此相似的是**专栏文章**,这边同样列出了一些基础表。如果要去做专栏文章的点赞这件事情的实时计算,我们关注 **article 和 article_vote** 这两张表,利用 member_id、id 和 vote 字段可以非常容易的计算得到文章的点赞数。\n\n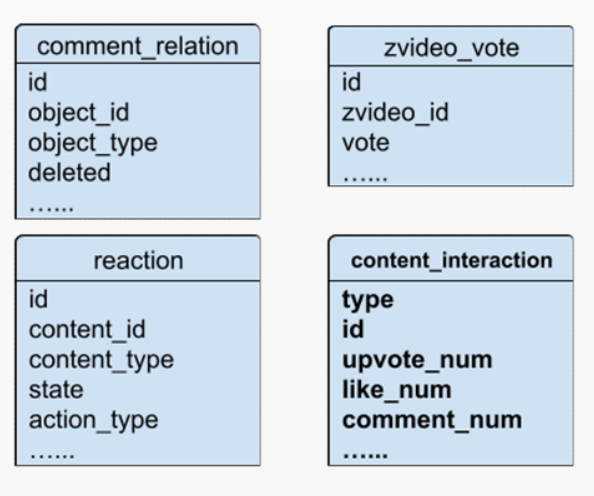\n\n除了在业务系统内的点赞交互数据,其它类型的交互数据分散在多个不同的业务系统中。比如**评论系统的 comment_relation 表,视频回答的 vote 表,还有其它交互的 reaction 表**。基于这些用户的行为数据,再加上内容数据就能够计算得到用户创作的完整交互数据了。\n\n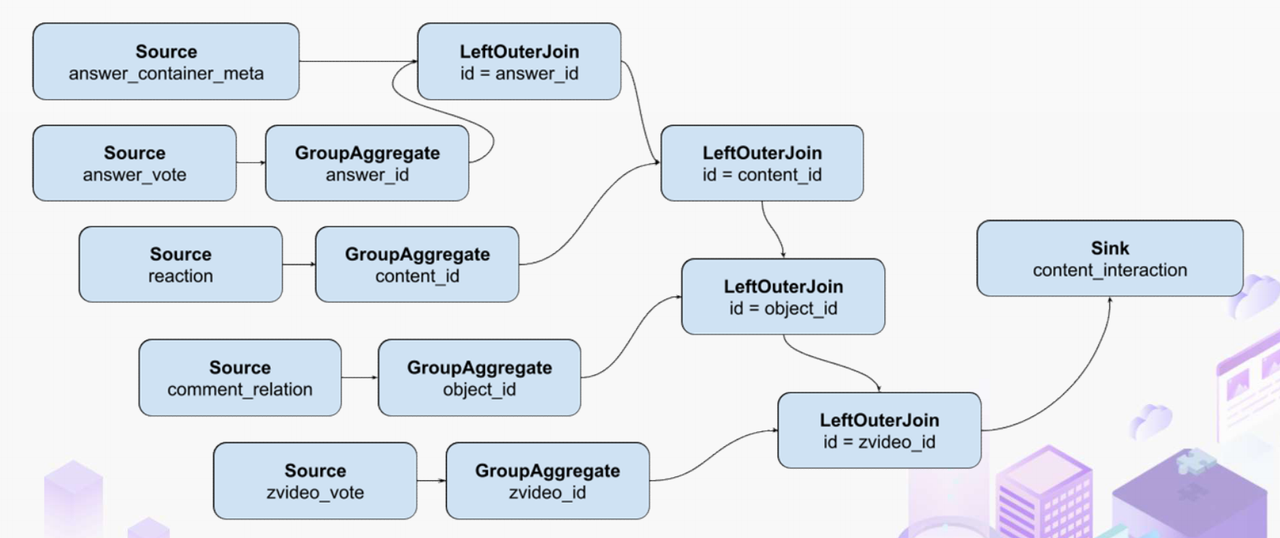\n\n从业务模型上可以得到交互数据计算的本质是把**各种不同类型的内容和各种交互行为的数据作为源表,然后按照对这些数据以内容的 ID 分组进行聚合计算**。比如说点赞就是一个 count 计算,因为表里一行数据就是一个点赞。如果说它是一个分值,那么这个数据的计算就是 sum。在拿到所有内容和所有交互聚合的结果后,再次同内容表做一个左连接就能拿到最后的计算结果了。\n\n### 传统解决方案\n\n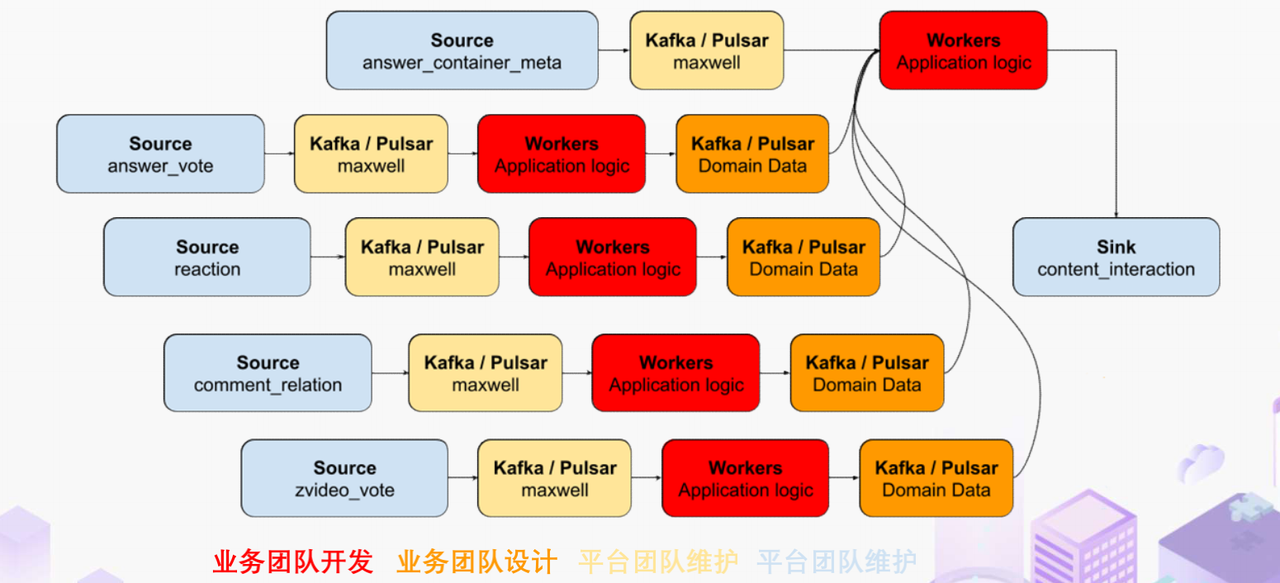\n\n在开始讲 Flink 的计算之前,我们可以先看看没有 Flink,同样的实时应用是什么样的开发模式。知乎内部有一套自己过去积累的技术框架去做这样的事件驱动计算,如果用这样的技术做实时计算,开发的方式是上图这个样子。\n\n业务工程师需要用自己熟悉的语言和框架来开发中间红色的这些基于**消息系统的 worker**,对拿到的实时数据变化事件进行**补数和聚合**操作,再将计算得到的结果以预先约定好的格式发送到消息系统。最后用一个最终的 worker,将内容源表和多个上游 worker 的实时计算结果拼接在一起得到最终的计算结果并保存到下游。这样我们就可以基于比较传统的技术来实现实时应用。在这种开发方式下,业务工程师需要关注多个 worker 的实现,和不同系统之间数据传递的格式。数据库和消息系统由平台团队来维护,对于工程师来说没有额外的学习成本,**学习成本低和易于理解**是这种传统开发方式的优点。\n\n\n\n这种开发方式存在着一些问题。比如上面图里有 5 个 worker,worker 程序首先是一个消息系统的 consumer,它需要根据业务需求对接收到的实时数据进行聚合计算,并填充必要的维度数据。在保证这些计算逻辑的正确性之后,还要把这些计算的结果正确的发送到消息系统的下游 topic 中。不夸张地讲这样的一个程序至少需要 1000 行的工作量,5 个这样的 worker 不论从**管理**还是**开发**甚至是**维护**方面的**成本**都是**非常高**的。另外,这些业务团队自行开发的 worker 程序需要由开发者**自行解决规模扩展性问题**,还需要独立地**预留资源应对突发流量造成全局的资源浪费**。难以在合理的成本下平衡弹性不足带来的系统规模问题。\n\n### Flink 解决方案\n\n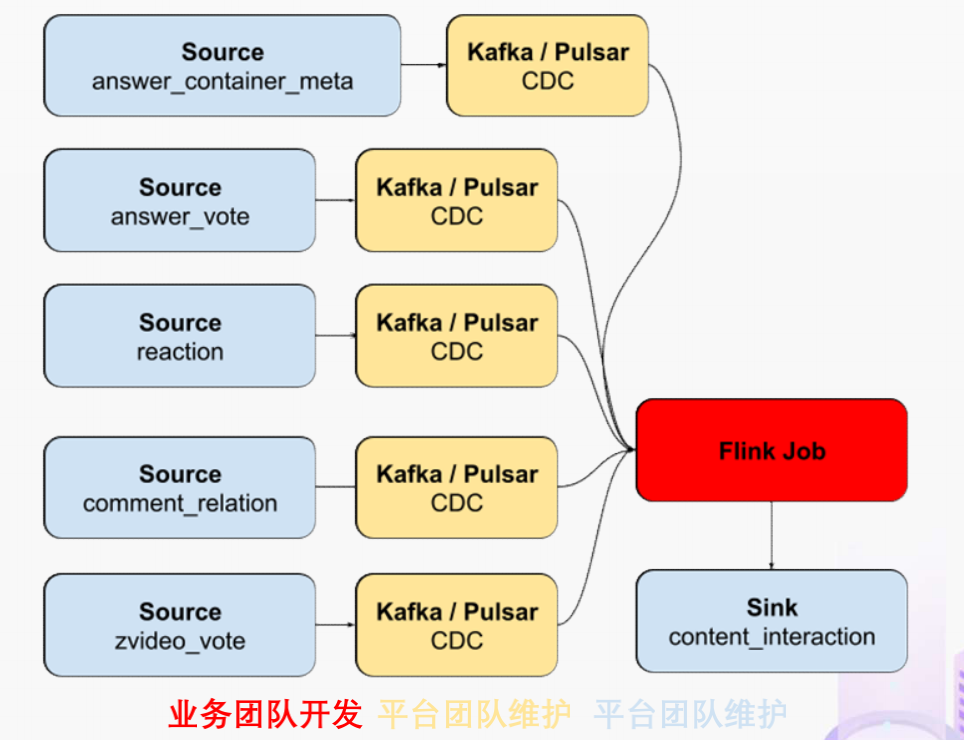\n\n作为对比,如果用 Flink 去开发整个应用的结构会变得非常简单。当我们使用 SQL 来开发应用时,得益于更高的**可维护性和可理解性**,我们能够在不损失可维护性的情况下将这个应用的全部逻辑放在一个 **job** 里统一维护。不论从业务团队的**开发成本**还是是**维护成本**角度看都是更优的选择。\n\n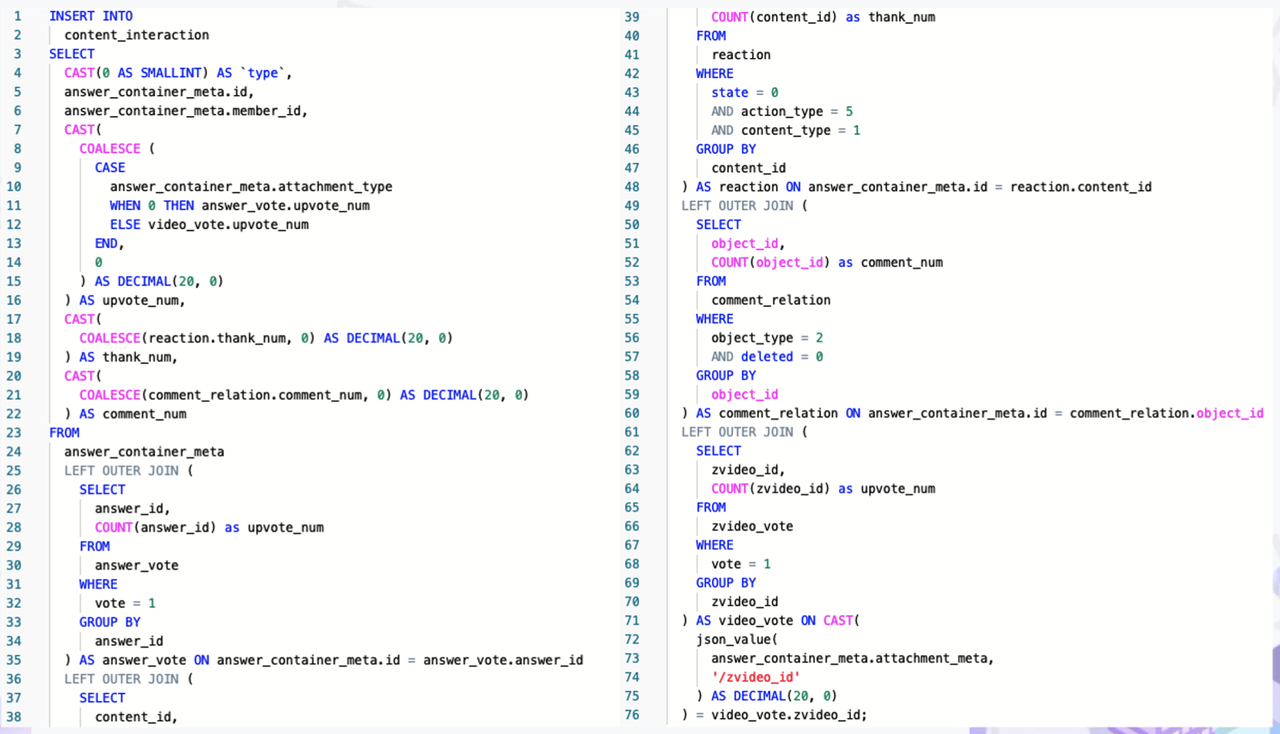\n\n如上图所示,这是回答用户交互数据的实时计算逻辑用 Flink SQL 来开发,最后得到的 SQL 。利用 SQL 这种声明式的方式开发业务逻辑,非常容易地理解和验证它的正确性。\n\n\n\n接下来看一下这种方式的**优势**:\n\n首先,单一 SQL 开发可维护性高,组件数少,维护成本低。\n\n其次,Flink 统一处理系统级问题,业务层**无需关心扩展性、高可用、性能优化和正确性的问题**,极大地降低了处理这些问题的负担。\n\n最后,SQL 开发**几乎没有额外的学习成本**。为什么说 “几乎”,这个业务是典型的在线工程师的工作领域,而在线工程师一定很熟悉 SQL。但他们日常工作中使用到的 SQL 范围和大数据工程师使用的 SQL 范围还存在着些许的不同。所以不能说 Flink SQL 没有学习成本,但这个成本非常低,**学习曲线**也非常**平缓**。\n\n任何事情都有**两面性**,基于 Flink 开发实时应用也需要解决下面的这些问题:\n首先,SQL 的**表达力**并**不是无限**的,一定会有一些业务逻辑和业务场景很难拿目前的 Flink SQL 完全覆盖。如果我们用 **28 法则**来看这个问题,SQL 加上一些 UDF 就能够解决其中 80% 标准 Flink SQL 无法覆盖的问题,最后还剩下无法解决的 20% 问题有 DataStream API 进行兜底,确保整个业务问题能够在一个 Flink 技术栈上全部解决。\n\n另外,Flink SQL 开发简单,但 Flink 系统本身的**复杂度并不低**。这些复杂度对许多业务工程师来说是一个非常重的负担,他们并不希望理解 Flink 如何工作如何维护。他们更希望在一个可自助操作的平台上编写 SQL 解决自己的领域问题,避免关注运维 Flink 这样一个复杂的问题。对此我们需要以**平台化**的方式降低业务接入系统的成本,利用技术手段和规模效应把单个业务的成本降到合理水平。\n\n所以问题虽然存在,但都有合适的办法解决。\n\n### POC Demo\n\n\n\n刚刚讲到的创作中心实时应用还处于 POC 过程,POC 使用知乎站上实际的表结构,大家可以从 POC Demo 感受业务工程师能够基于 Flink 实现什么,实现的效果,以及正确性是否有保障。\n\n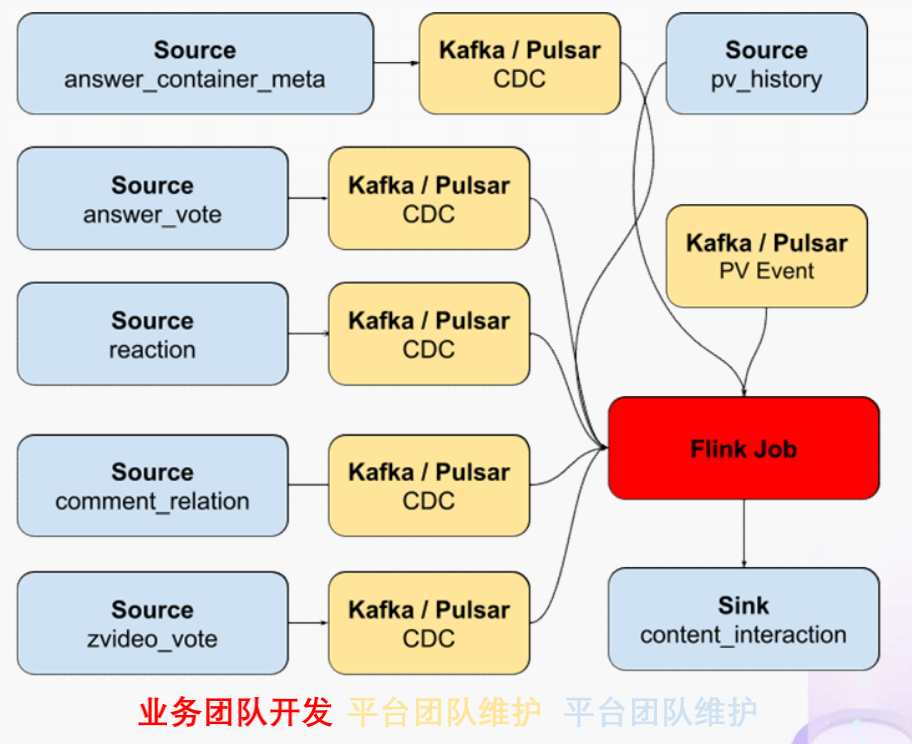\n\n前面看到的部分只包括了在线业务的技术栈范围,也就是说源数据在 TiDB 上,经过 Flink 处理后的计算结果也存储在 TiDB,**端到端**的解决实时计算问题。如果需要在计算中**引入离线产生的数据**怎么办?比如我们想要在计算结果中包含每个内容的实时 PV,我们可以把大数据系统中的 PV history 的表和 PV 实时流进行一个 union 操作,再按照内容 ID sum 在一起,就可以得到实时的内容维度 PV 数据。传统方式的实现可能要写 1-2 个 worker,现在只需要在 Flink job 中加几行 SQL 代码就可以实现。\n\n### 可能的疑问\n\n\n\n如果不熟悉 Flink 不熟悉大数据的同学现在可能会有一些疑问,接下来我们一一看下这几大类疑问。\n\n第一个就是计算到底怎么做的,在 **TP 系统里面都是客户端请求触发计算**,Flink 的计算是如何触发的呢?\n\n答案是在事件触发时进行计算,每产生一个 event 就会触发一次计算。对数据库里任何一行的变化都触发一次计算,触发的颗粒度可能太细导致成本过高。所以 Flink 里边有 mini batch 的优化,可以攒一批变化事件以批的模式驱动计算。如果是关于时间段内数据的计算,还可以用 window 机制,使用 Watermark/Trigger 来触发计算并获得结果。如果计算的过程中需要维护状态,那么 Flink runtime 会负责管理状态数据。\n\n第二个问题是 **window 在哪里**?\n\n并不是所有业务都必须要用 window,当计算和触发逻辑跟时间段没有关系的时候,就不需要使用 window。比如这里的 demo 场景计算逻辑由数据变更触发状态**永久有效**,整个逻辑中不需要使用 window。\n\n如果需要用 window 的时候怎么处理迟到的事件?这里有 **discard 和 retract** 两个主要的策略处理迟到事件,当遇到迟到事件时开发者可以选择扔掉迟到的数据,也可以用 retract 机制去处理。除此以外我们还可以用自定义的逻辑来处理迟到事件。总之 window 的作用是协助用户以**预置的窗口策略**,将落在某一时间段内的数据攒在一起触发计算,在有超出窗口的延迟数据到达时,按照应用期望的方式进行处理。\n\n第三是开发上手难度如何?\n\nStreaming SQL 在标准 SQL 的基础上建立,它的学习过程是**渐进性的、平缓的**。再配合上易扩展的 UDF 能力,能够解决大多数单纯使用 Flink SQL 无法解决的问题,少数只适合用编写代码方式解决的问题仍然有 Flink 的 DataStream API 可以解决。\n\n最后 TiDB 和 Flink 如何保证**计算结果的正确性**?\n\nTiDB 是一个**默认快照隔离级别的数据库**,我们能够直接拿到某个时间点的静止全局快照状态。在 SI 隔离级别下保证整个数据流的正确性非常容易。我们只需要拿到一个时间戳,并读取这个时间戳时刻全部数据的静止快照,处理完快照数据后对接上 CDC 里所有时间戳之后发生的 CDC event。在 Flink 的角度这就是一个**流批一体**的动态表,Flink 自身的机制能够保证流入到系统中事件计算结果的正确性。\n\n## TiDB x Flink 批流一体\n\n下面来了解在做 POC 过程中,我们在 TiDB 和 Flink 整合方面开展了哪些工作,以及这些整合工作带来的能力处于什么样的状态。\n\n### TiDB as MySQL\n\n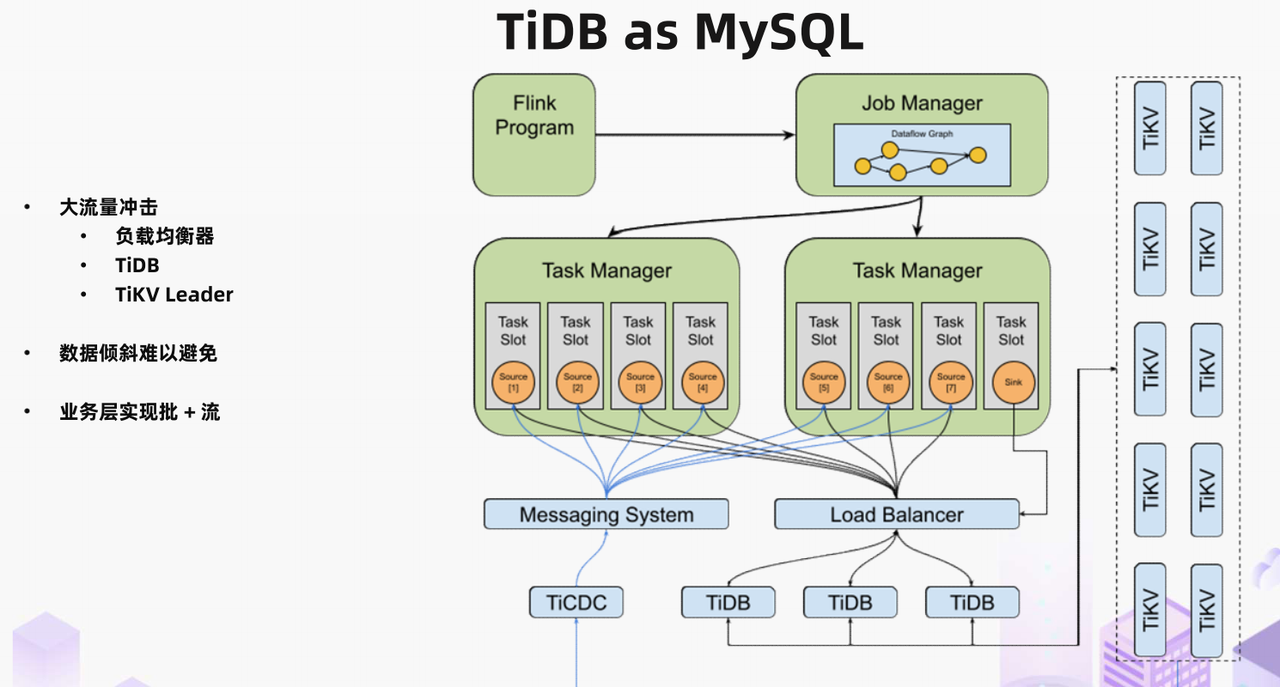\n\n作为一款和 **MySQL 兼容的分布式数据库**,即便我们不做 TiDB 到 Flink 的原生整合,我们仍然能够以图示的方式把 TiDB 当作一个大号的 MySQL 和 Flink 配合在一起使用。这个架构下所有批任务流量都需要先过 LB ,然后再经过 TiDB 最后根据读取的数据范围访问相应的 TiKV 节点。而流任务流量是利用 TiCDC 从 TiKV 抓取数据变更事件,经由消息系统交付给 Flink 进行处理。\n\n这种**非原生对接**的使用方式虽然能工作,但是在许多场景下无法充分利用 TiDB 架构的特点做更极致的成本优化和价值放大。比如在流量波动大的应用场景,由于所有的流量要在整个路径上,从 LB 到 TiDB 到 TiKV 的每一层走一遍。而流量会对每一个进程产生全量的冲击,为了保证在峰值流量冲击下的业务表现,我们不得不按照峰值流量去预备所有的资源,造成了极大的资源浪费。\n\n还有大数据场景经常遇到的**数据倾斜**问题。在没有业务知识的前提下,面对业务各种各样的表结构设计和业务数据分布特征,我们很难以统一的方式自动化地解决所有的数据倾斜问题。实际上在目前版本的 Flink JDBC connector 上,如果表主键不是整数类型且不存在分区表,那么 Flink 的 source 就只能以 1 个并行度去处理全部数据。这在面对 TiDB 上海量存储业务数据的场景是非常困难的。\n\n最后,我们无法直接利用为 MySQL 设计的 **flink-cdc-connector** 项目为 TiDB 提供流和批一体的 connector。那么在许多需要这个能力的应用场景中,业务方就需要自己去关注批和流数据统一处理的问题。\n\n### TiDB 适配\n\n为了解决在 Flink 中使用非原生 TiDB 支持遇到的这些缺陷,我们充分利用了 TiDB 架构的特点,为 TiDB 开发了原生的 Flink Connector,更好地服务于 Flink 的广泛计算场景。\n\n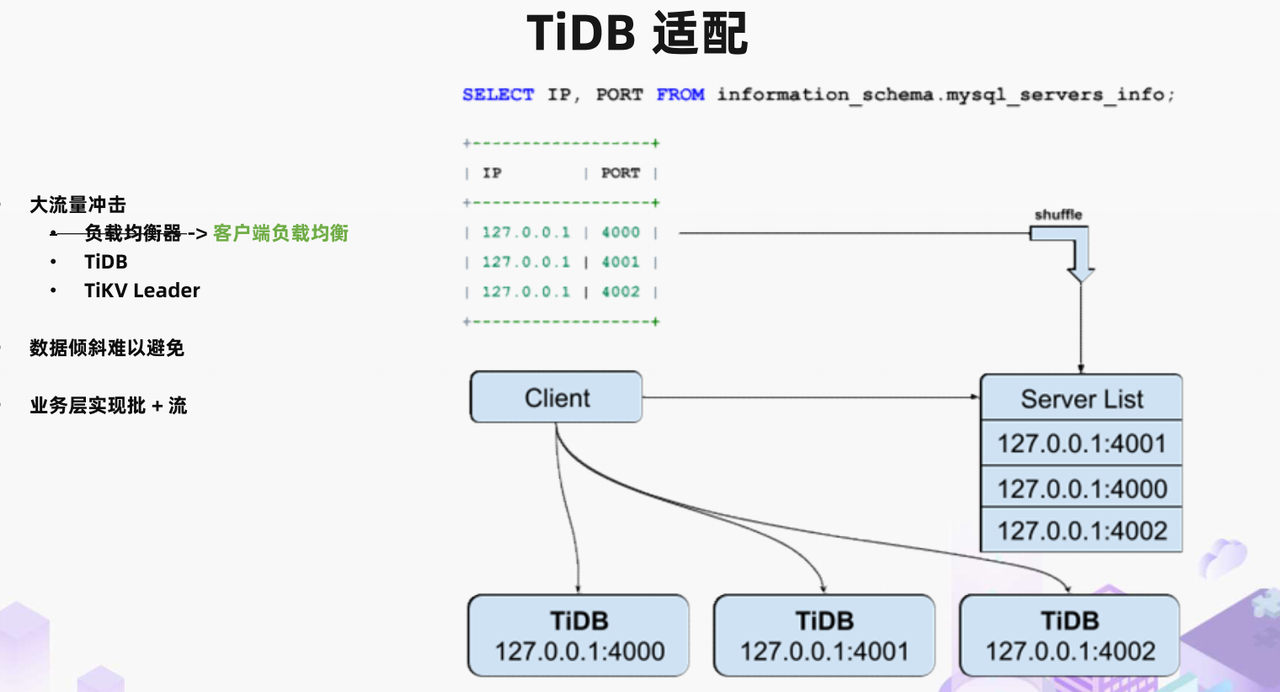\n\n首先是针对**大流量冲击场景的资源优化**。在 TiDB 中有系统表可以得知整个集群所有 TiDB 服务器的地址和端口。我们实现了一个非常薄的代理到原生 MySQL JDBC driver 的 JDBC driver,利用系统表中的集群拓扑信息直接在客户端实现了**负载均衡**。通过直连 TiDB-server 的方式我们实现了负载均衡器的流量绕行,只有初次和后续定期更新集群信息的小数据量请求会经过负载均衡器,真正的大流量数据读写请求都通过到 TiDB 的直接连接来承载。\n\n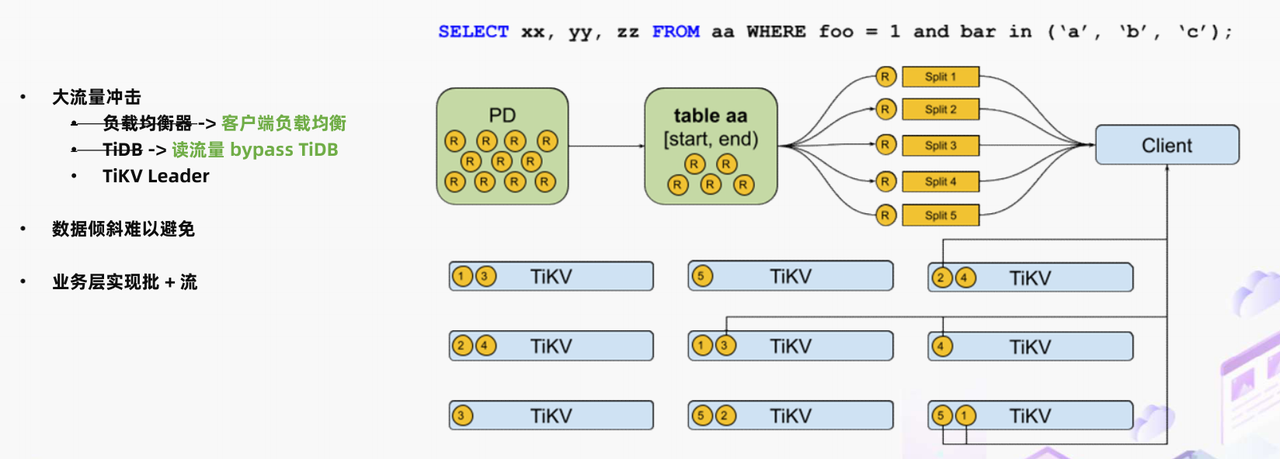\n\n接下来是避免 **TiDB-server 的流量冲击**。在对 TiDB 上的数据进行读取操作时,我们能够让客户端从 PD 上获取到需要读取数据范围内的所有 region 信息。通过直接连接 region 背后 TiKV 节点的方式,我们能够将所有读的流量绕行 TiDB,极大地降低 TiDB 层负载,**节约硬件资源成本**。在实现 TiDB 绕行方案时,我们实现了同 TiDB 一致的 **predicate 下推和 projection 下推能力**,TiDB connector 对 TiKV 产生的压力同真正的 TiDB 非常接近,不会对 TiKV 产生额外的负担。\n\n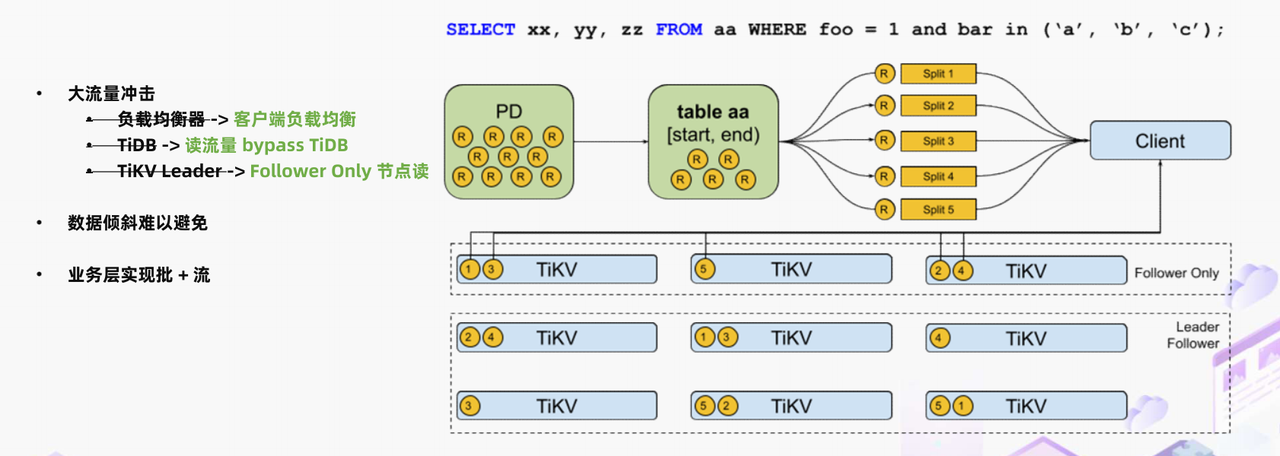\n\n下一个是利用 placement rules 让一批物理隔离的 TiKV 节点只承载 follower 角色的数据副本,再配合 follower read 能力我们能够在没有付出额外服务器成本的情况下将实时计算的大流量负载,同在线的业务负载物理隔离开。让大家能够放心的在一个 TiDB 集群上同时支撑在线业务和大数据业务。\n\n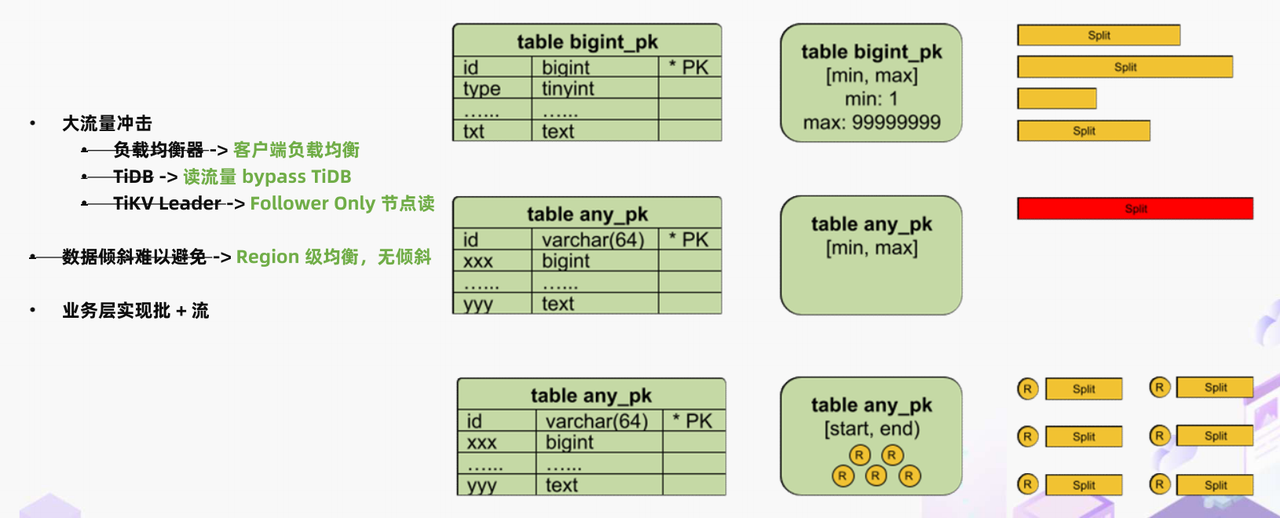\n\n接下来是**业务无关的数据均衡能力**。如前面所讲,在没有业务层领域知识和数据分布信息的情况下,JDBC 方式只能对整数主键的数据进行近似均衡的拆分,而对于非整数其它类型主键的非分区表就只能序列化的处理所有的数据。在 TiDB 这种海量数据存储的情况下,不论是单并发还是不均衡都会导致任务执行效率低的问题。而前面介绍 TiDB 绕行的时候大家也看到了,TiDB connector 的任务拆分粒度是 region 级别。而 region 尺寸是由 TiKV 按照一个最优的尺寸去自动保持的,所以对于**任意**一个表结构,我们都能够做到**任务单元的均衡性,在无任何业务知识的情况下完全避免数据倾斜问题**。\n\n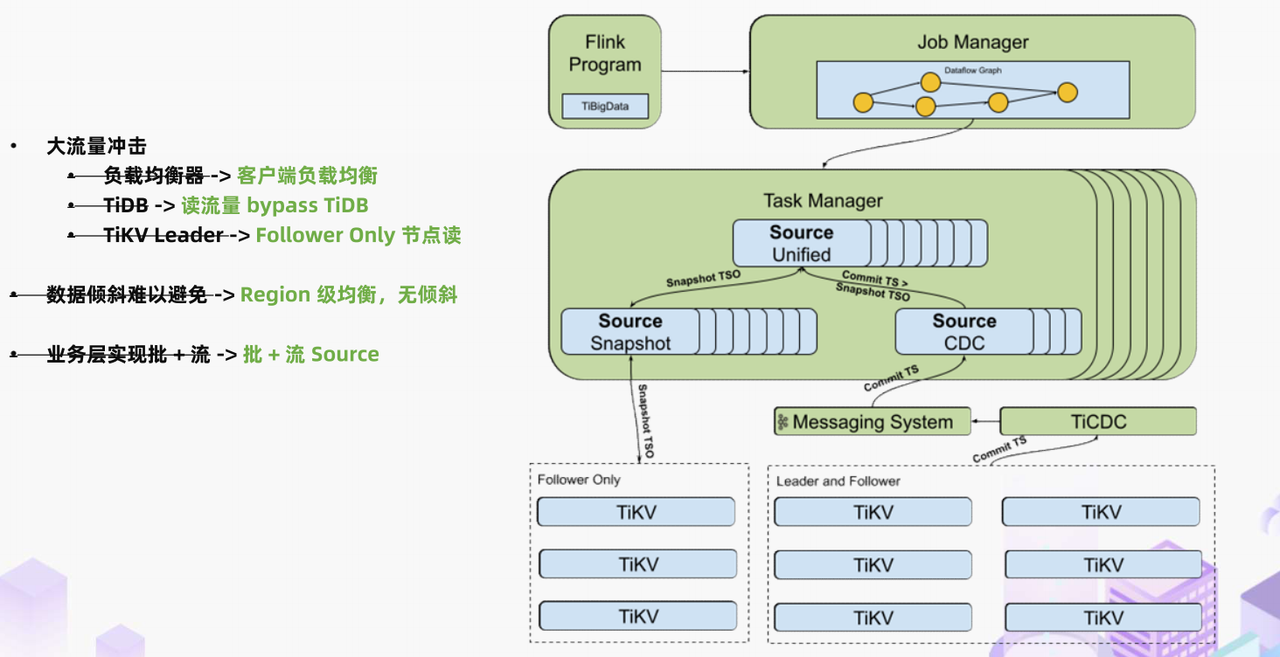\n\n接下来是 **TiDB connector 原生实现的批流一体能力**。它的原理是利用 TiDB 的快照隔离级别拿到一个数据的全局快照,在处理完这个快照数据后,再接入所有 commit 版本号大于快照版本号的 CDC 事件。通过这个**内嵌的流批一体能力**,在数据处理工作得到极大简化的同时,还能确保整个实时计算流水线的绝对正确性。\n\n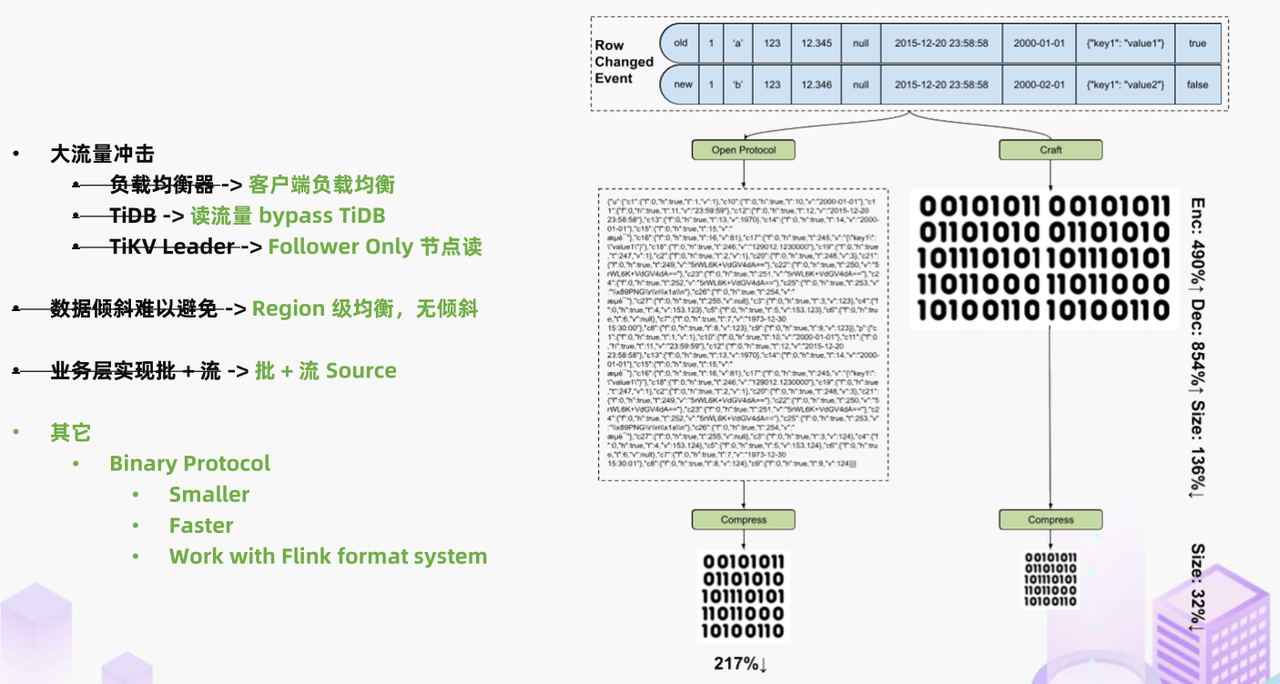\n\n最后为了进一步优化 TiDB 大流量写能力带来的 CDC 流量冲击。我们还对 TiCDC 的数据编解码格式做了**二进制编码优化**。大家经常在 TiCDC 中使用的 canel json 和 open protocol 都是 JSON 的格式,然而这些以 JSON 为物理格式的协议都倾向于尺寸更大和编解码 CPU 消耗过大的问题。而全新设计的 **binary protocol** 充分利用了 CDC 数据的一些特点,在典型场景下能够将数据尺寸压缩到 open protocol 的 42%,同时提升 encode 速度到接近原来的 6 倍,decode 速度到接近原来的 10 倍。\n\n以上就是我们在 TiDB 和 Flink 原生整合方面所做的工作,这些工作很好地解决了利用 TiDB 和 Flink 实现端到端实时计算时所遇到的一些问题。\n\n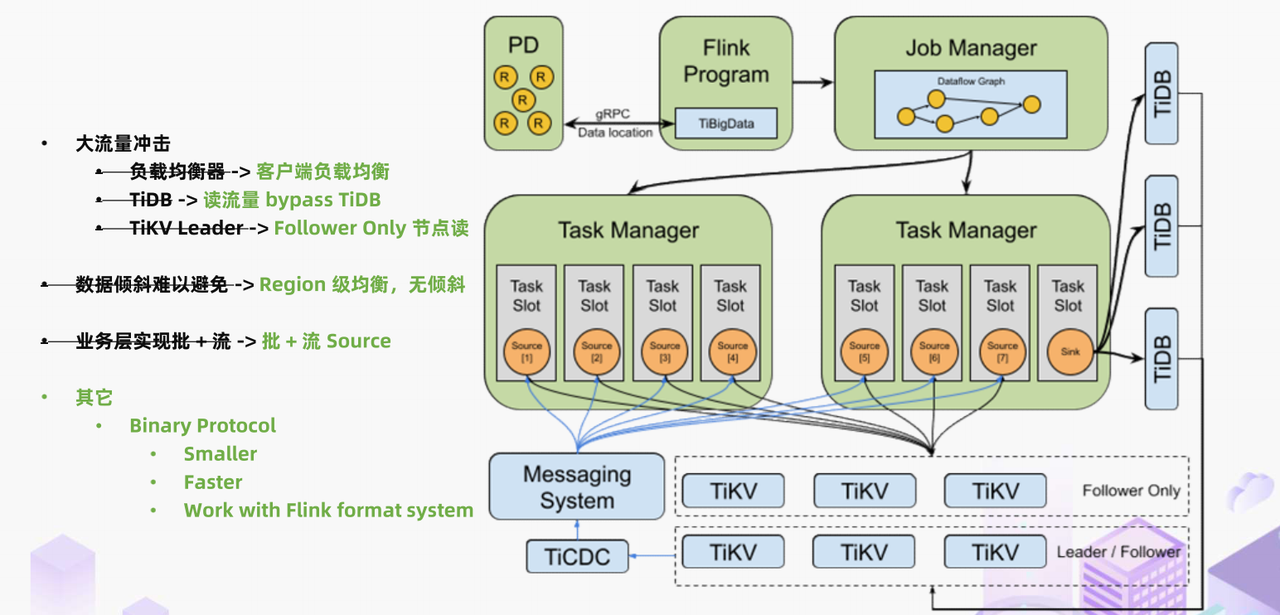\n\n在 TiDB connector 的帮助下,TiDB 和 Flink 配合的方式变成图上的这个样子。读的流量绕行负载均衡和 tidb-server,直接请求 TiKV 的 follower 节点上。写的流量目前是借助 JDBC 实现,但在客户端负载均衡能力的帮助下,我们仍然能够绕行负载均衡器,降低负载均衡器的成本。\n\n当前 Flink 已经在知乎拥有许多落地的应用场景了。我们基于 Flink 建设了数据集成平台,并利用 TiDB connector 提供了 TiDB to Hive 和 Hive to TiDB 的能力,**解决了 ODS 层数据同步以及离线计算的数据在线提供服务的同步问题**。在数据集成平台之外还有许其他的实时应用,比如商业团队的点击数据处理程序。再比如搜索里的时效性分析,还有关键指标的实时数仓。最后还有一些业务利用 Flink 将实时行为数据落到 TiDB 供在线查询。\n\n## 展望\n除了以上提到的这些进展,我们还有许多可以改善的方面,为 TiDB 和 Flink 的用户创造更多的价值。接下来就让我们看下未来还有哪些可以继续挖掘价值的方向。\n\n### TiDB x Flink 核心能力增强\n\n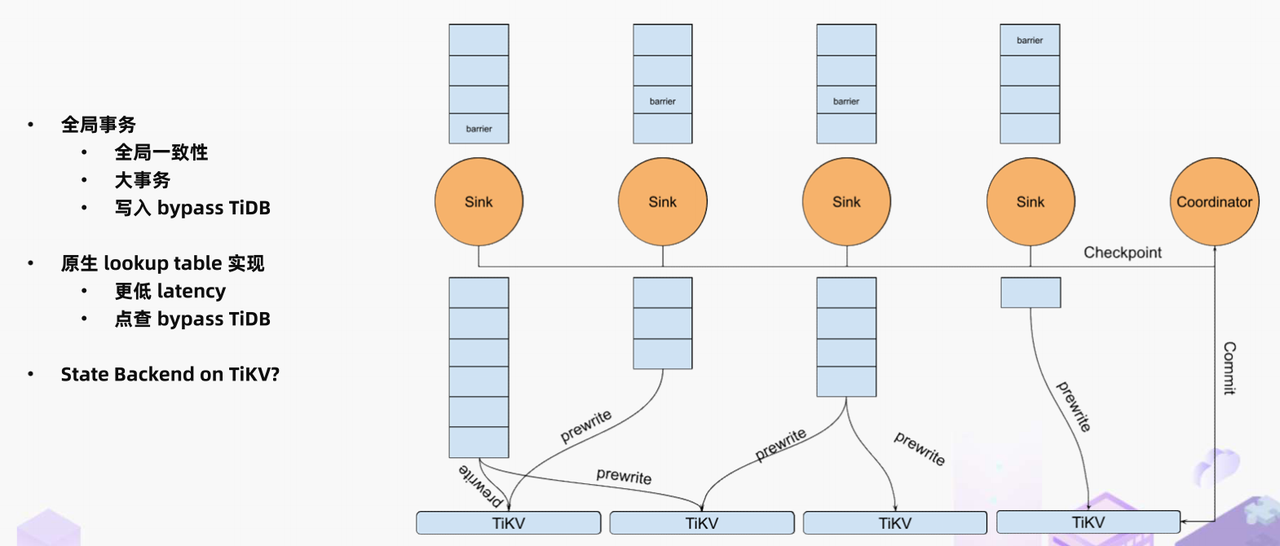\n\n首先是**全局事务支持**。目前基于 JDBC 实现的 Flink sink 存在同 JDBC connector 一样的局限,无法实现分布式的全局事务。此外使用 JDBC 连接 TiDB 的同时也带来了 TiDB 最大事务尺寸的限制,无法支持**超大事务的写入**。当我们遇到有全局可见性要求或类似银行跑批任务的需求时,目前的 TiDB connector 仍然无法提供理想的能力。我们希望接下来实现原生的写入能力,直接以分布式的方式向 TiKV 上进行两步提交,从而实现全局大事务写入能力。全局事务不仅仅能带来事务隔离和大事务的收益,我们还可以通过将所有大流量的请求绕行 TiDB 的方式,彻底释放 tidb-server 的压力,彻底杜绝没必要的资源浪费。\n\n还有一个**改进方向是原生 lookup table 的支持**,目前这一块儿也是基于 JDBC connector 实现的。虽然维表查询的吞吐通常不会特别大,但 bypass TiDB 仍然能够获得 latency 上的额外收益。而这个提升能够为流计算系统计算吞吐的提升和避免事件积压起到非常关键的正面作用。\n\n最后还有一个尚未明确收益的改进方向是基于 TiKV 的 state backend,可能会**解决一些场景下 checkpoint 慢的问题**。\n\n### 更多应用场景\n\n\n\n在拥有了 TiDB 原生支持具备了许多新的能力之后,我们可以畅想未来 TiDB x Flink 能够支撑更多的应用场景。\n\n比如当前的数据集成平台只支持**批模式的数据抽取任务**,在 TiDB 流批一体能力的帮助下,我们能够配合 Hudi 或 Iceberg 以非常低的成本完成所有 ODS 层数据的实时化。如果所有 ODS 层数据具备了实时的能力,数仓同学在考虑实时数仓的建设路径时就没有太多的前置依赖了。配合常见的实时埋点数据和实时 ODS 数据,完全按照业务价值的高低去安排数仓的实时化建设。\n\n在实时数仓之外,随着技术的成熟还会有**更多的实时应用场景诞生**。比如我们能够以极低的成本从站上现有内容产出实时的内容池。再比如搜索引擎的实时索引更新,当然还有 demo 的内容交互数据实时统计等等。相信在知乎的 Flink SQL 平台建设完成后,一定会产生越来越多基于 TiDB x Flink 端到端的技术体系覆盖的应用场景。\n\n最后如果大家对 TiDB x Flink 的生态整合或者 TiDB 在整个大数据生态的能力,可以在 GitHub 上关注 **[TiBigData](https://github.com/tidb-incubator/TiBigData)** 项目。首先欢迎大家在实际场景中尝试使用这个项目,如果在使用中遇到问题或有意见建议可以随时给项目提 issue。最后也希望有更多的开发者参与到这个项目的开发,我们一起让它为 TiDB 在大数据领域提供成熟完善的一站式解决方案。","author":"孙晓光","category":4,"customUrl":"tidb-flink-best-practice","fillInMethod":"writeDirectly","id":305,"summary":"本篇文章主要分享了知乎在 TiDB x Flink 批流一体方面的部分工作,并以实际业务为例介绍如何充分利用两者的特点完成端对端实时计算的闭环交付。","tags":["TiDB + Flink"],"title":"端到端的实时计算:TiDB + Flink 最佳实践"}},{"relatedBlog":{"body":"随着互联网飞速发展,企业业务种类会越来越多,业务数据量会越来越大,当发展到一定规模时,传统的数据存储结构逐渐无法满足企业需求,实时数据仓库就变成了一个必要的基础服务。以维表 Join 为例,数据在业务数据源中以范式表的形式存储,在分析时需要做大量的 Join 操作,降低性能。如果在数据清洗导入过程中就能流式的完成 Join,那么分析时就无需再次 Join,从而提升查询性能。\n\n利用实时数仓,企业可以实现实时 OLAP 分析、实时数据看板、实时业务监控、实时数据接口服务等用途。但想到实时数仓,很多人的第一印象就是架构复杂,难以操作与维护。而得益于新版 Flink 对 SQL 的支持,以及 TiDB HTAP 的特性,我们探索了一个高效、易用的 Flink+TiDB 实时数仓解决方案。\n\n本文将首先介绍实时数仓的概念,然后介绍 Flink+TiDB 实时数仓的架构与优势,接着给出一些已经在使用中的用户场景,最后给出在 docker-compose 环境下的 Demo,用于读者进行尝试。\n\n## 实时数仓的概念\n\n数据仓库的概念在 90 年代由 Bill Inmon 提出,是指一个面向主题的、集成的、相对稳定的、反映历史变化的集合,用于支持管理决策。当时的数据仓库通过消息队列收集来自数据源的数据,通过每天或每周进行一次计算以供报表使用,也称为离线数仓。\n\n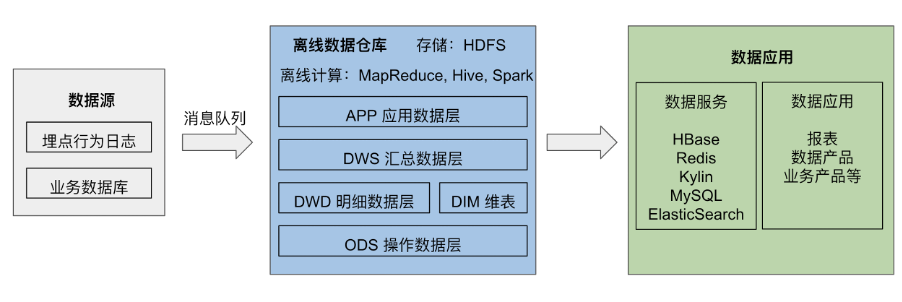\n\n离线数仓架构
\n\n进入 21 世纪,随着计算技术的发展、以及整体算力的提升,决策的主体逐渐从人工控制转变为计算机算法,出现了实时推荐、实时监控分析等需求,对应的决策周期时间由天级逐步变为秒级,在这些场景下,实时数仓应运而生。\n\n当前的实时数仓主要有三种架构:Lambda 架构、Kappa 架构以及实时 OLAP 变体架构:\n\n1. Lambda 架构是指在离线数仓的基础上叠加了实时数仓部分,使用流式引擎处理实时性较高的数据,最后将离线和在线的结果统一供应用使用。\n\n 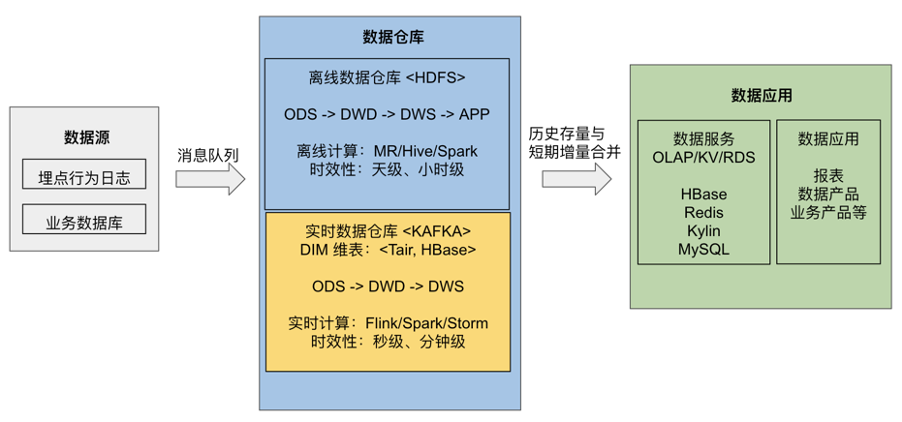\n \n 实时数仓的 Lambda 架构
\n\n2. Kappa 架构则移除了离线数仓部分,全部使用实时数据生产。这种架构统一了计算引擎,降低了开发成本。\n\n \n \n 实时数仓的 Kappa 架构
\n\n3. 随着实时 OLAP 技术的提升,一个新的实时架构被提出,暂时被称为“实时 OLAP 变体”。简单来说,就是将一部分计算压力从流式计算引擎转嫁到实时 OLAP 分析引擎上,以此进行更加灵活的实时数仓计算。\n\n 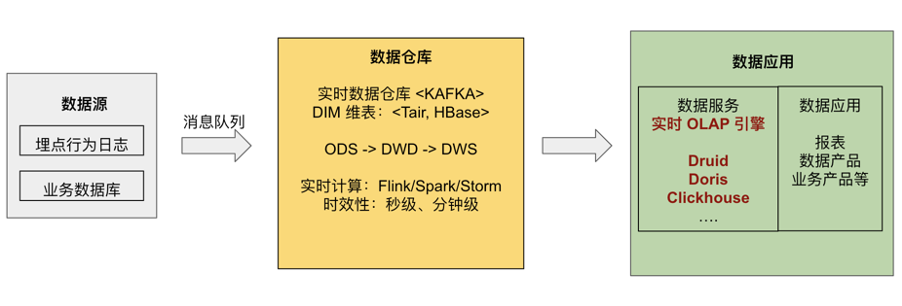\n \n 实时数仓的 OLAP 架构
\n\n总结一下,对于实时数仓,Lambda 架构需要维护流和批两套引擎,开发成本相较其它两者更高。相比于 Kappa 架构,实时 OLAP 变体架构可以执行更加灵活的计算,但需要依赖额外的实时 OLAP 算力资源。接下来我们将介绍的 Flink + TiDB 实时数仓方案,就属于实时 OLAP 变体架构。\n\n关于实时数仓及这些架构更加详细的对比说明,有兴趣的读者可以参考 Flink 中文社区的[这篇文章](https://mp.weixin.qq.com/s/l--W_GUOGXOWhGdwYqsh9A)。\n\n## Flink + TiDB 实时数仓\n\nFlink 是一个低延迟、高吞吐、流批统一的大数据计算引擎,被普遍用于高实时性场景下的实时计算,具有支持 exactly-once 等重要特性。\n\n在集成了 TiFlash 之后,TiDB 已经成为了真正的 HTAP(在线事务处理 OLTP + 在线分析处理 OLAP)数据库。换句话说,在实时数仓架构中,TiDB 既可以作为数据源的业务数据库,进行业务查询的处理;又可以作为实时 OLAP 引擎,进行分析型场景的计算。\n\n结合了 Flink 与 TiDB 两者的特性,Flink + TiDB 的方案的优势也体现了出来:首先是速度有保障,两者都可以通过水平扩展节点来增加算力;其次,学习和配置成本相对较低,因为 TiDB 兼容 MySQL 5.7 协议,而最新版本的 Flink 也可以完全通过 Flink SQL 和强大的连接器(connector)来编写提交任务,节省了用户的学习成本。\n\n对于 Flink + TiDB 实时数仓,下面是几种常用的搭建原型,可以用来满足不同的需求,也可以在实际使用中自行扩展。\n\n### 以 MySQL 作为数据源\n\n通过使用 Ververica 官方提供的 [flink-connector-mysql-cdc](https://github.com/ververica/flink-cdc-connectors),Flink 可以既作为采集层采集 MySQL 的 binlog 生成动态表,也作为流计算层实现流式计算,如流式 Join、预聚合等。最后,Flink 通过 JDBC 连接器将计算完成的数据写入 TiDB 中。\n\n\n\n以 MySQL 作为数据源的简便架构
\n\n这个架构的优点是非常简洁方便,在 MySQL 和 TiDB 都准备好对应数据库和表的情况下,可以通过只编写 Flink SQL 来完成任务的注册与提交。读者可以在本文末尾的【在 docker-compose 中进行尝试】一节中尝试此架构。\n\n### 以 Kafka 对接 Flink\n\n如果数据已经从其它途径存放到了 Kafka 中,可以方便地通过 [Flink Kafka Connector](https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/connectors/kafka.html) 使 Flink 从 Kafka 中获得数据。\n\n在这里需要提一下的是,如果想要将 MySQL 或其它数据源的变更日志存放在 Kafka 中后续供 Flink 处理,那么推荐使用 Canal 或 Debezium 采集数据源变更日志,因为 Flink 1.11 原生支持解析这两种工具格式的 changelog,无需再额外实现解析器。\n\n\n\n以 MySQL 作为数据源,经过 Kafka 的架构示例
\n\n### 以 TiDB 作为数据源\n\n[TiCDC](https://docs.pingcap.com/zh/tidb/stable/ticdc-overview) 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,可以利用其将 TiDB 的变更数据输出到消息队列中,再由 Flink 提取。\n\n\n\n以 TiDB 作为数据源,通过 TiCDC 将 TiDB 的增量变化输出到 Flink 中
\n\n在 4.0.7 版本,可以通过 [TiCDC Open Protocol](https://docs.pingcap.com/zh/tidb/stable/ticdc-open-protocol) 来完成与 Flink 的对接。在之后的版本,TiCDC 将支持直接输出为 canal-json 形式,以供 Flink 使用。\n\n## 案例与实践\n\n上个部分介绍了一些基础的架构,实践中的探索往往更加复杂和有趣,这一部分将介绍一些具有代表性和启发性的用户案例。\n\n### 小红书\n\n小红书是年轻人的生活方式平台,用户可以通过短视频、图文等形式记录生活点滴,分享生活方式,并基于兴趣形成互动。截至到 2019 年 10 月,小红书月活跃用户数已经过亿,并持续快速增长。\n\n在小红书的业务架构中,Flink 的数据来源和数据汇总处都是 TiDB,以达到类似于“物化视图”的效果:\n\n1. 左上角的线上业务表执行正常的 OLTP 任务。\n\n2. 下方的 TiCDC 集群抽取 TiDB 的实时变更数据,以 changelog 形式传递到 Kafka 中。\n\n3. Flink 读取 Kafka 中的 changelog,进行计算,如拼好宽表或聚合表。\n\n4. Flink 将结果写回到 TiDB 的宽表中,用于后续分析使用。\n\n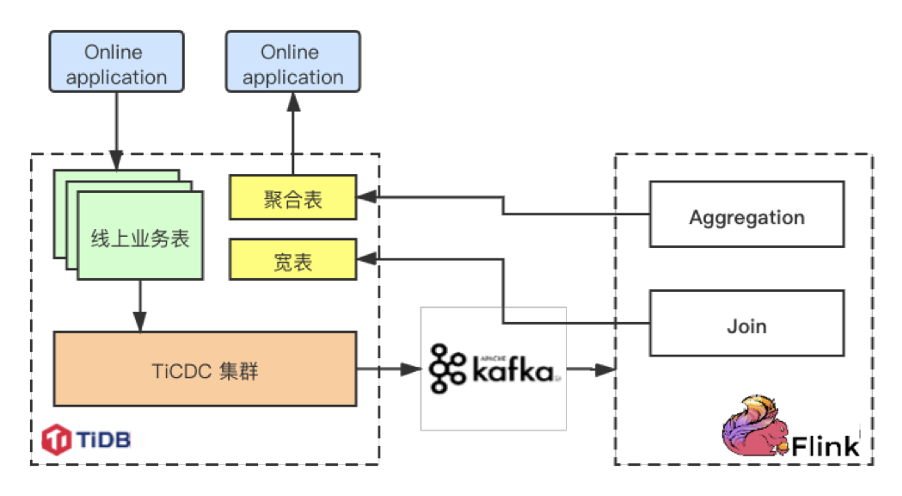\n\n小红书 Flink TiDB 集群架构
\n\n整个过程形成了 TiDB 的闭环,将后续分析任务的 Join 工作转移到了 Flink 上,并通过流式计算来缓解压力。目前这套方案已经支持起了小红书的内容审核、笔记标签推荐、增长审计等业务,经历了大吞吐量的线上业务考验且持续运行稳定。\n\n### 贝壳金服\n\n贝壳金服持续多年深耕居住场景,积累了丰富的中国房产大数据。贝壳金服以金融科技为驱动,利用AI算法高效应用多维海量数据以提升产品体验,为用户提供丰富、定制化的金融服务。\n\n在贝壳数据组的数据服务中,Flink 实时计算用于典型的维表 Join:\n\n1. 首先,使用 Syncer (MySQL 到 TiDB 的一个轻量级同步工具)采集业务数据源上的维表数据同步到 TiDB 中。\n\n\n2. 然后,业务数据源上的流表数据则通过 Canal 采集 binlog 存入 kafka 消息队列中。\n\n\n3. Flink 读取 Kafka 中流表的变更日志,尝试进行流式 Join,每当需要维表中的数据时,就去 TiDB 中查找。\n\n\n4. 最后,Flink 将拼合而成的宽表写入到 TiDB 中,用于数据分析服务。\n\n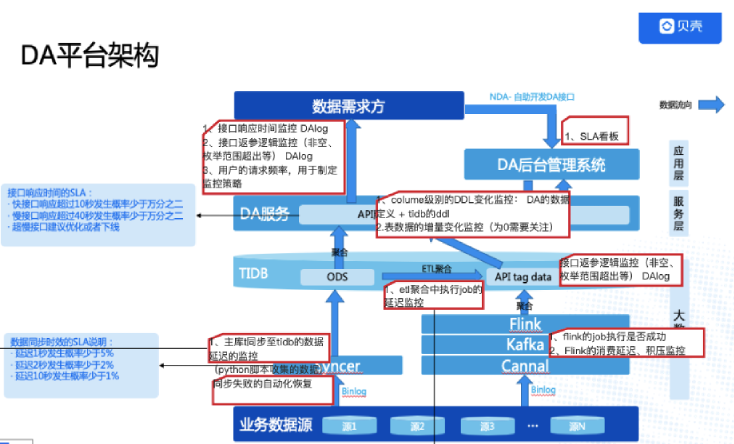\n\n贝壳金服数据分析平台架构
\n\n利用以上的结构,可以将数据服务中的主表进行实时 Join 落地,然后服务方只需要查询单表。这套系统在贝壳金服已经深入各个核心业务系统,跨系统的数据获取统一走数据组的数据服务,省去了业务系统开发 API 和内存聚合数据代码的开发工作。\n\n### 智慧芽\n\nPatSnap(智慧芽)是一款全球专利检索数据库,整合了 1790 年至今的全球 116 个国家地区 1.3 亿专利数据和 1.7 亿化学结构数据。可检索、浏览、翻译专利,生成 Insights 专利分析报告,用于专利价值分析、引用分析、法律搜索,查看 3D 专利地图。\n\n智慧芽使用 Flink + TiDB 替换了原有的 Segment + Redshift 架构。\n\n原有的 Segment + Redshift 架构,仅构建出了 ODS 层,数据写入的规则和 schema 不受控制。且需要针对 ODS 编写复杂的 ETL 来按照业务需求进行各类指标的计算来完成上层需求。Redshift 中落库数据量大,计算慢(T+1时效),并影响对外服务性能。\n\n替换为基于 Kinesis + Flink + TiDB 构建的实时数仓架构后,不再需要构建 ODS 层。Flink 作为前置计算单元,直接从业务出发构建出 Flink Job ETL,完全控制了落库规则并自定义 schema; 即仅把业务关注的指标进行清洗并写入 TiDB 来进行后续的分析查询,写入数据量大大减少。按用户/租户、地区、业务动作等关注的指标,结合分钟、小时、天等不同粒度的时间窗口等,在 TiDB 上构建出 DWD/DWS/ADS 层,直接服务业务上的统计、清单等需求,上层应用可直接使用构建好的数据,且获得了秒级的实时能力。\n\n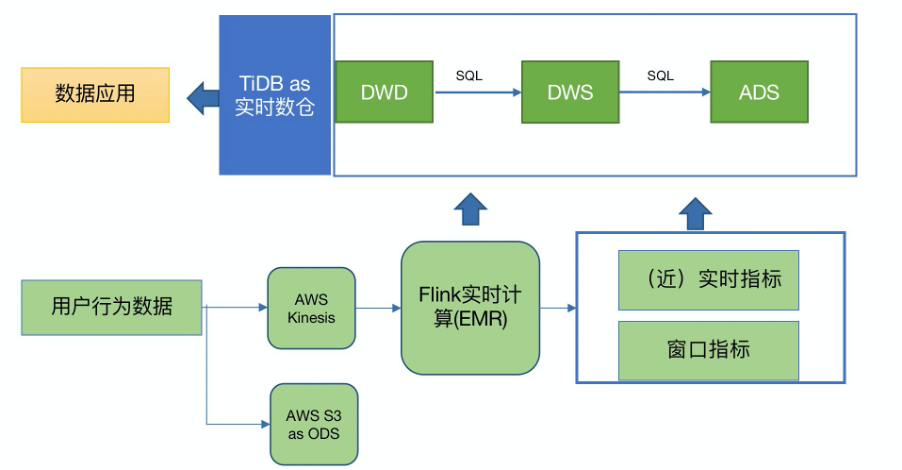\n\n智慧芽数据分析平台架构
\n\n用户体验:在使用了新架构后,入库数据量、入库规则和计算复杂度都大大下降,数据在 Flink Job 中已经按照业务需求处理完成并写入 TiDB,不再需要基于 Redshift 的 全量 ODS 层进行 T+1 ETL。基于TiDB构建的实时数仓,通过合理的数据分层,架构上获得了极大的精简,开发维护也变得更加简单;在数据查询、更新、写入性能上都获得大幅度提升;在满足不同的 adhoc 分析需求时,不再需要等待类似 Redshift 预编译的过程;扩容方便简单易于开发。\n目前这套架构正在上线,在智慧芽内部用来进行用户行为分析和追踪,并汇总出公司运营大盘、用户行为分析、租户行为分析等功能。\n\n### 网易互娱\n\n网易 2001 年正式成立在线游戏事业部,经过近20年的发展,已跻身全球七大游戏公司之一。在 App Annie 发布的“2020 年度全球发行商 52 强”榜单中,网易位列第二。\n\n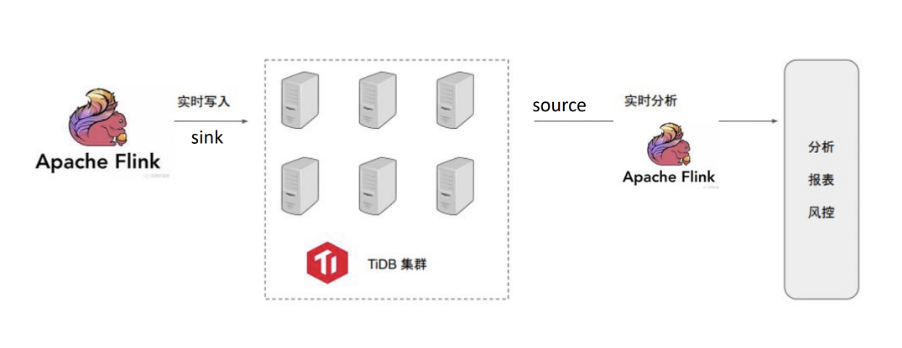\n\n网易互娱数据计费组平台架构
\n\n在网易互娱计费组的应用架构中,一方面使用 Flink 完成业务数据源到 TiDB 的实时写入;另一方面,以 TiDB 作为分析数据源,在后续的 Flink 集群中进行实时流计算,生成分析报表。此外,网易互娱现在内部开发了 flink 作业管理平台,用于管理作业的整个生命周期。\n\n### 知乎\n\n知乎是中文互联网综合性内容平台,以“让每个人高效获得可信赖的解答”为品牌使命和北极星。截至 2019 年 1 月,知乎已拥有超过 2.2 亿用户,共产出 1.3 亿个回答。\n\n知乎作为 PingCAP 的合作伙伴,同时也是 Flink 的深度用户,在自己的实践过程中开发了一套 TiDB 与 Flink 交互工具并贡献给了开源社区:[pingcap-incubator/TiBigData](https://github.com/pingcap-incubator/TiBigData),主要包括了如下功能:\n\n1. TiDB 作为 Flink Source Connector,用于批式同步数据。\n\n2. TiDB 作为 Flink Sink Connector,基于 JDBC 实现。\n\n3. Flink TiDB Catalog,可以在 Flink SQL 中直接使用 TiDB 的表,无需再次创建。\n\n## 在 docker-compose 中进行尝试\n\n为了方便读者更好的理解,我们在 [https://github.com/LittleFall/flink-tidb-rdw](https://github.com/LittleFall/flink-tidb-rdw) 中提供了一个基于 docker-compose 的 MySQL-Flink-TiDB 测试环境,供大家测试使用。\n\n[Flink TiDB 实时数仓 Slides](https://www.slidestalk.com/TiDB/FlinkTidbRdw) 中提供了该场景下一个简单的教程,包括概念解释、代码示例、简单原理以及一些注意事项,其中示例包括:\n\n1. Flink SQL 简单尝试\n\n2. 利用 Flink 进行从 MySQL 到 TiDB 的数据导入\n\n3. 双流 Join\n\n4. 维表 Join\n\n在启动 docker-compose 后,可以通过 Flink SQL Client 来编写并提交 Flink 任务,并通过 localhost:8081 来观察任务执行情况。\n\n如果大家对 Flink+TiDB 实时数仓方案有兴趣、疑惑,或者在探索实践过程中积累了想要分享的经验,欢迎到 TiDB 社区(如 [AskTUG](https://asktug.com))、Flink 社区(如 [Flink 中文邮件](http://apache-flink.147419.n8.nabble.com))或通过我的邮件(qizhi@pingcap.com)进行探讨。\n\n## 参考阅读\n\n1. [基于 Flink 的典型 ETL 场景实现方案](https://mp.weixin.qq.com/s/l--W_GUOGXOWhGdwYqsh9A),Flink 中文社区关于实时数仓概念及流上 Join 的讨论。\n\n2. [How We Use a Scale-Out HTAP Database for Real-Time Analytics and Complex Queries](https://en.pingcap.com/case-studies/how-we-use-a-scale-out-htap-database-for-real-time-analytics-and-complex-queries/),小红书使用 TiDB 的实践分享文章。\n\n3. [How We Build an HTAP Database That Simplifies Your Data Platform](https://dzone.com/articles/how-we-build-an-htap-database-that-simplifies-your),TiDB 的 HTAP 架构以及在数据平台上的应用。\n\n4. [TiDB: A Raft-based HTAP Database](http://www.vldb.org/pvldb/vol13/p3072-huang.pdf),TiDB 原理论文。\n\n5. [Flink SQL CDC 上线!我们总结了 13 条生产实践经验](https://zhuanlan.zhihu.com/p/243187428),Flink 中文社区,关于 Flink SQL CDC 的运维生产经验。","author":"齐智","category":1,"customUrl":"when-tidb-and-flink-are-combined","fillInMethod":"writeDirectly","id":10,"summary":"本文将向大家介绍 Flink 和 TiDB 的联合实时数仓方案。","tags":["TiDB","Flink"],"title":"当 TiDB 与 Flink 相结合:高效、易用的实时数仓"}},{"relatedBlog":{"body":"Flink 是一个低延迟、高吞吐、流批统一的大数据计算引擎,作为大数据处理领域最近冉冉升起的一颗新星,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能,被普遍用于高实时性场景下的实时计算。2020 年 TiDB 与 Flink 正式开始合作,探索将 Flink 与 TiDB 结合的解决方案。令人开心的是,在今年 TiDB Hackathon 上我们就看到出现了 3 个基于 Flink 的项目。**其中,TiFlink 队伍的项目为 Flink 实现了更好的 TiKV Source、Sink 和 TiDB Catalog Reader,支持 Snapshot 读取和 Change Log 增量读取和 2 Phase Commit 写入,以实现在 TiDB 里快速创建 Materialized View 和在 Flink 里方便编写读写 TiKV 数据的批/流处理任务。** 该项目凭借超高的人气一举夺得本届大赛最佳人气奖。我们在赛后采访了 TiFlink 团队部分队员与评委李钰老师,邀请他们分享自己的 Hackathon 经验。\n\n## 项目背景:当 TiKV 遇上 Flink\n\n提起 TiFlink 项目的灵感,还得从队长张茄子去年在公司内部的尝试说起。他的公司有一些数据实时分析的需求,但原有的数据分析工具在单表查询时很快,一旦到 join 时就不是很好搞。当时这个项目最终没能在内部成功做出来,但想法一直都在,直到今年 Hackathon 期间,张茄子和队友们一起重新探讨了可能的方案。目前,TiDB/TiKV 提供的 Flink 集成和 Java 客户端具有如下缺陷:\n\n- Java 客户端不支持抓取 CDC 日志,使用 TiCDC 需要通过 Kafka 转发,比较笨重和繁琐,延迟较高;\n \n- Flink 集成的 Source 只支持批量读入,不支持批流结合(即先批量读入,后拉取 CDC 日志进行增量更新);\n \n- Flink 集成的 Sink 尚不支持 TwoPhaseCommit 协议,正在开发中的版本只支持各个节点单独 TwoPhaseCommit ,不支持全局同步 TwoPhaseCommit 。\n \n\n\n\n张茄子观察到 Flink 有着很完善的系统,在 Flink 里有一个 Flink CDC connector,但是只有 MySQL 的,没有 TiDB 的。所以队员们就想借助这次比赛做出一个 TiDB 的 CDC connector,将其贡献到 Flink 和 TiDB 社区,这样就可以打通 TiDB 社区和 Flink 社区的合作,借助 TiKV + Flink 打造出一个 TiDB 的批流一体库。**这就是 TiFlink 的由来,通过它可以实现更好的 Flink 集成(Connector)以及提供物化视图(Materialized View)功能,显著提高 TiDB/TiKV 生态环境的 OLAP 能力。**\n\n## 项目设计:TiFlink 流批一体库诞生了\n\n在比赛中,为了将设想中的 TiFlink 流批一体库实现落地,队员们做出了一系列尝试:\n\n- 为 TiKV 的 Java 客户端添加直接拉取 CDC 日志的功能,从而为实现批流一体数据处理的 Flink Source 创造条件;\n \n- 为 Flink 开发 TiKV 兼容批读取和增量读取的 DynamicTableSource ,实现不同隔离级别的读取功能;\n \n- 为 Flink 开发兼容 TiKV 事务模型并支持 TwoPhaseCommit 接口的 DynamicTableSink ,实现跨节点(切片,Region)一致的数据写入;\n \n- 在上述组件的基础上,尝试实现 TiDB 上基于 Flink 的物化视图功能。\n \n\n\n\n经过紧张的开发,在比赛答辩中 TiFlink 终于初见雏形,并顺利通过 DEMO 演示,TiFlink 团队为 TiKV 写了一个 DynamicTableSource,让 Flink 直接读取 TiKV snapshot 数据以及 CDC 流式变更数据,同时支持了 DynamicTableSink,能让 Flink 通过 TiKV 事务的方式将数据重新写回到 TiKV 里面。**通过这种方式,让大数据处理在 TiDB 以及 Flink 之间高效的流转。同时,TiFlink 也构建了一个 global snapshot coordinator,可以让分布式执行的 Flink 任务在以 snapshot isolation 的强一致方式来维护物化视图。**\n\n## 因为 Hackathon 走到一起的 TiFlink\n\n令人惊讶的是,在比赛的短短几天时间里就能做出如此完备功能的 TiFlink,其 4 名队员可以说来自天南海北。队长张茄子来自全球领先的招聘网站 Indeed ,在日本做新项目孵化;乘蜗牛追乌龟本名徐哲,在大唐电信从事流媒体服务端研发,是多届天池大赛数据库比赛骨灰级获奖选手;jiangplus 在一家 AI 和算法驱动的药物研发公司 Xtalpi,从事内部云原生机器学习平台的构建工作;SteNicholas (蒋晓峰(子懿))则在阿里云 Apache Flink 做生态相关工作。若在平时,看似分属于不同行业不同地区的四人可能永远都不会产生任何联系,但出于同样对 Hackathon 的热爱,将他们串联到了一起。\n\nHackathon 对张茄子来说,最大的吸引是可以将自己的 idea 讲出来,同时能够认识到拥有各种各样 idea 的朋友,大家一起分享自己的想法是一件非常开心的事情。\n\nSteNicholas 认为 Hackathon 带来的最大收获莫过于可以用自己熟悉的 Flink 或 TiDB 做任何想做的事情,只要能把它实现,就是一件特别 cool 的事情。\n\n而对于队伍中年纪最小的徐哲而言, Hackathon 是一次开拓自己视野的好机会,不但可以看到其他队伍提出了一些自己从未想过的 idea ,还能逼着自己在很短的时间内完成一个非常有意思的点子,完成对自我的挑战。\n\n与以前参加过的 Hackathon 不同,TiDB Hackathon 以「∞」作为本次大赛主题,参赛队伍只要有创新的 idea ,都可以拿出来参赛,在两天的编程里疯狂 coding,将自己的 idea 落地分享。对四人来说,这样的机会怎能错过?\n\n在进行了一番探讨和交流后,张茄子和队友们决定将 TiKV + Flink 打造流批一体库作为自己的参赛项目。\n\n今年由于疫情原因,大家都通过线上方式进行远程协作, 2 人负责 Flink 开发工作,2 人负责 TiDB 开发工作,每隔几个小时便会沟通项目进度。队长张茄子认为对远程协作来说保持一定频次的沟通至关重要,需要确保每个人的工作内容都朝着同一个方向,不至于最后走歪。\n\nSteNicholas 作为 TiFlink 唯一到现场参赛的队员,还通过线上向其他队员做起了现场直播,引得大家直呼羡慕。对 Hackathon 来说不能一起面对面奋斗,始终是一件非常遗憾的事情,大家都表示如果明年继续参赛,希望还能够在现场相聚。\n\n评委李钰老师是来自 Apache Flink & Apache HBase 的 PMC,出于职业敏感,对 Flink 这类生态结合的项目特别关注:“ **今年与 Flink 相结合的项目一共有三个,有通过 Flink 给 TiDB 做联邦查询的、有用 Flink 做物化视图的,但我觉得与 Flink 集成最深的还是 TiFlink** 。比如他们做了一个原生的 Java 的 CDC,利用 Flink 本身机制实现物化视图的 Snapshot 的全局性。我个人觉得这些方面再往后走都具备落地的价值,这也是我最喜欢这个项目的原因。”\n\n在李钰看来,如果能将 TiDB 联邦查询的项目与 TiFlink 项目结合在一起,对用户而言会产生更好的效果。现在有很多业务场景既有实时计算大数据相关的需求,又有数据库查询的需求,在这种情况下,将 TiDB+Flink 联合起来形成解决方案非常具有实用价值。例如, Flink 其实可以直接给 TiDB 提供访问 Hive 的能力。如果你既想查一个数据库里的数据,又想查一个 Hive 里的数据,就可以通过 TiDB 的这种标准 SQL 查询实现,屏蔽掉底层复杂的细节,这对于客户而言是非常具有现实价值的方案。\n\n## 未来期待:找到初期用户\n\n2 天的比赛时间非常有限,队员们希望在未来几个月找到一些初期用户,在用户反馈中不断完善 TiFlink 项目。队员们对此都很期待:“毕竟我们自己的想法和用户的想法还是有很多不一样的地方,比如说在一些选型、设计上的问题,我们自己没有办法解答,需要知道对用户来说哪种方式比较方便使用。**理想情况下,我们当然希望这个项目可以变成 TiDB 的一部分 ,作为一个整体被 TiDB 的用户非常方便地使用起来。**”\n\n李钰老师特别补充道:“其实 Flink 也一直在提批流一体数仓,在用户有实时需求的情况下,批流一体数仓能够极大地节省整体 TCO 。类似的方案之前在阿里内部也有过一些技术实现,但 TiKV+Flink 是首次以开源解决方案的形式予以实现,这可以为广大用户提供更普惠的解决方案。”\n\n除了 TiFlink ,本届大赛中也涌现出不少令人激动的项目,除了自己的队伍,还有哪些是最感兴趣的呢?几位队员明显有着自己的偏爱:\n\n张茄子:“我比较喜欢的是几个大佬们做的那个 Index 的项目,非常具有想象力,把一些比较新的想法都融合进来了,我感觉这也是最有前景的项目之一。”\n\n徐哲:“我最感兴趣的是 UDF 和 TiGraph 两个队伍的项目。UDF 在演示期间的展示非常酷, TiGraph 在展示期间有一个和原生的 TiDB 的性能对比,效果也非常好。他们的项目都是非常实用的想法,最后都获得了奖项,说明大家对他们也非常认可。”\n\n## Hackathon 建议:参赛,享受比赛\n\n作为经常参加 Hackathon 的老手,队员们也给对 Hackathon 活动感兴趣的萌新们分享了一些个人经验:张茄子建议新人一定要大胆来参赛。很多参赛选手其实也有好的点子和想法,但是他不太敢来参赛,害怕在众人面前露怯。其实大可不必,即使最终答辩效果不好,被淘汰也没什么不好意思的。不要太执着于比赛成绩,享受比赛过程就好了。你可以在这个过程中学习到很多东西,这才是最重要的收获。此外,如果想取得好成绩的话,需要提前对 TiDB 和 TiKV 进行了解和学习,获奖队伍中有很多人都是社区中的长期贡献者,事先做一些准备会更有胜算。\n\n李钰老师认为 Hackathon 活动是一个锻炼人的好机会,对于技术人员而言非常具有价值。就像马拉松长跑一样,在平时纷繁复杂的工作之外给自己一个机会来发泄一下。**马拉松是一种对自我体力极限的锻炼, Hackathon 则是一个脑力上的锻炼。** 最简单的建议就是要先来参加,在参赛的过程中享受比赛。\n\n> 点击查看更多 [TiDB Hackathon 2020 优秀项目分享](https://pingcap.com/zh/blog/?tag=TiDB%20Hackathon%202020)","author":"PingCAP","category":3,"customUrl":"tikv-and-flink-is-best","fillInMethod":"writeDirectly","id":118,"summary":"本篇文章将介绍 TiFlink 团队赛前幕后的精彩故事。","tags":["TiDB Hackathon 2020"],"title":"TiKV + Flink = 最佳人气流批一体库|TiDB Hackathon 2020 优秀项目分享"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}