{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/principle-analysis-of-partitioned-raft-kv",
"result": {"pageContext":{"blog":{"id":"Blogs_487","title":"TiKV 新架构:Partitioned Raft KV 原理解析","tags":["TiKV","Partitioned-Raft-KV"],"category":{"name":"产品技术解读"},"summary":"在上一篇文章中,我们介绍了 Partitioned Raft KV 这一新实验特性带来的性能和可伸缩性大幅提升。本文我们将为大家介绍这一功能的实现原理。","body":"## 导读\n\nTiKV 推出了名为“partitioned-raft-kv”的新实验性功能,该功能采用一种新的架构,不仅可以显著提高 TiDB 的可扩展性,还能提升 TiDB 的写吞吐量和性能稳定性。\n\n在[上一篇文章](/blog/partitioned-raft-kv)中,我们介绍了 partitioned-raft-KV 这一新实验特性带来的性能和可伸缩性大幅提升。本文我们将为大家介绍这一功能的实现原理。\n\n## 架构\n\n以下是 TiKV 的架构。\n\n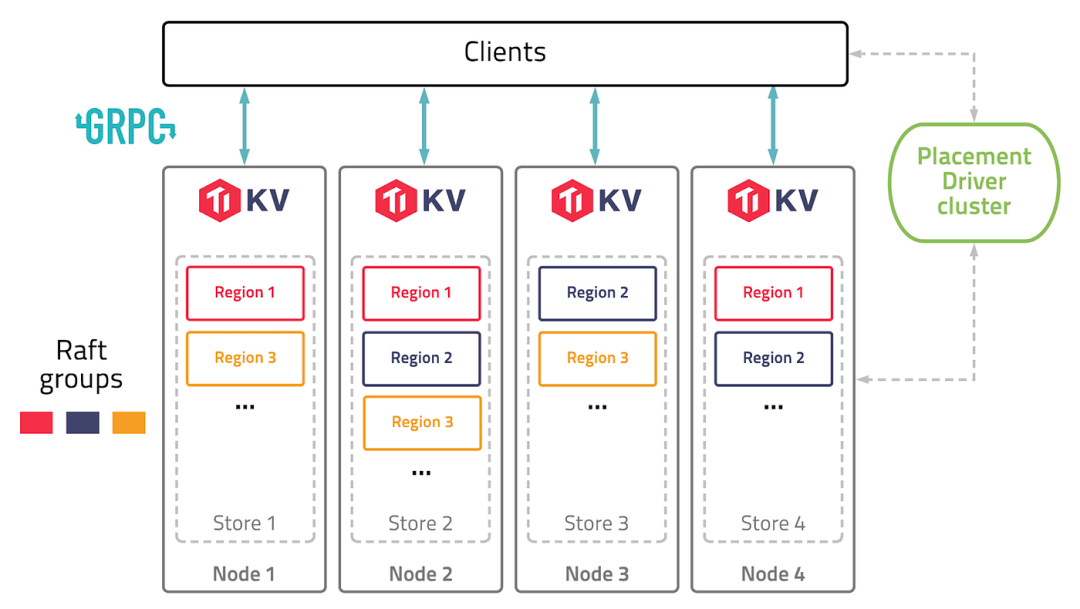\n图 1 TiKV 架构 —— 逻辑数据分区\n\n一个 TiKV 集群由许多数据分区(也称为 Region)组成。每个 Region 负责特定的数据片段,由其起始和结束键范围决定。它在不同的 TiKV 节点上拥有 3 个或更多的副本,并通过 raft 协议进行同步。在旧的 raft 引擎中,每个 TiKV 中只有一个 RocksDB 实例用于存储所有 Region 的数据。partitioned-raft-KV 特性引入了一个新的物理数据布局:每个 Region 都有自己的 RocksDB 实例。\n\n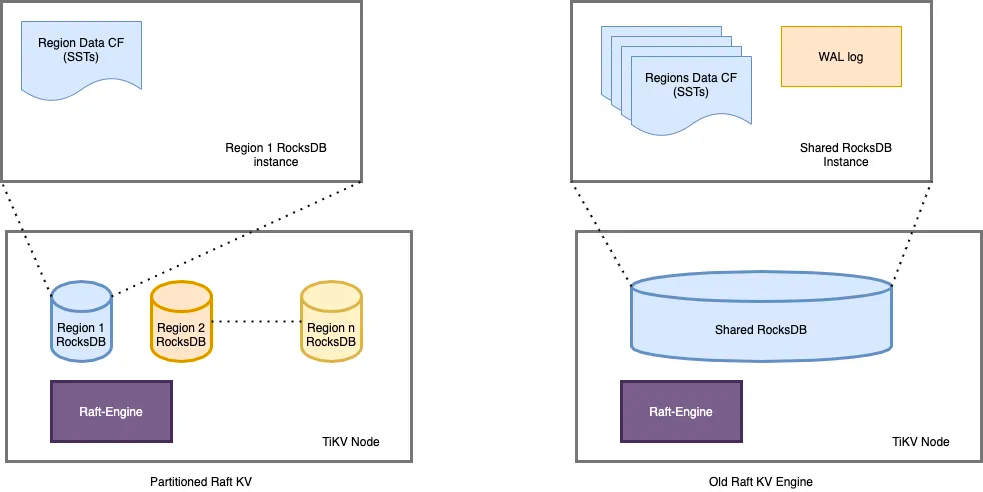\n图 2:物理数据布局比较\n\n## 旧 Raft KV 引擎面临的挑战\n\n\"Region\" 是 TiKV 中的逻辑规模单元。每个数据访问和管理操作,如负载均衡、扩展和缩小都由 Region 进行分区。然而,在当前架构中,它是一个纯逻辑概念,物理上没有清晰的区域边界。这意味着:\n\n1.当需要将一个 Region 的数据从一个 TiKV 移动到另一个 TiKV(也称为负载均衡)时,TiKV 需要在巨大的 RocksDB 实例中进行扫描以获取该 Region 的数据。这造成了读扩大。\n\n2.当几个 Region 具有大量的写流量时,如果它们的键范围分散,那么很可能会触发 RocksDB 中的大型压缩,其中包括其他空闲 Region 的数据。这引入了读和写扩大。例如,SST11 是一个 1MB 大小的 SST,只有 region1 的数据,但包含相当大的键范围。当它被选中合并到 L2 时,SST21、SST22 和 SST23 都参与了压缩,它们包含了 region2、3、4 的数据。TiKV 的规模越大,读写扩大越大。\n\n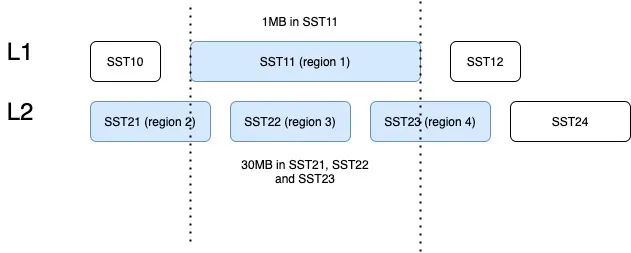\n图 3:不同 Region 之间的压缩数据\n\n3.没有 Region 隔离,因此少数热门 Region 可能会拖慢所有 Region 的性能。\n\n因此,在旧的 raft KV 引擎中,我们可能会遇到以下问题:\n\n1. 扩所容的速度很慢,因为需要多次数据扫描。\n\n2. 由于 RocksDB 的写组是单线程的,因此写吞吐量受到限制。\n\n3. 由于数据压缩会不时发生,当 RocksDB 的数据量很大时,用户流量的延迟不稳定。\n\n## Partitioned Raft KV 引擎的改进\n\n● 每个 Region 的数据都是一个专用的 RocksDB 实例,因此只需将 RocksDB 进行 x-copy 以进行 Region 间的负载均衡,避免了读放大的发生。\n\n● 热点 Region 的写入流量只会触发其自己的 RocksDB 的压缩,不涉及其他 Region 的数据。因此,它有效地减少了读和写放大。\n\n● 在将数据写入RocksDB时,写入线程之间并不会发生数据同步和锁争用,因为每个线程都在写一个不同的 RocksDB 实例。这样就消除了写入瓶颈。由于没有 WAL 日志,向 RocksDB 的写入是一个内存操作。\n\n● 一个 RocksDB 性能不好并不会影响其他 Region。因此,Region 的性能在存储层面上是隔离的。\n\n● 现在每个 Region 都支持更大的容量, 默认情况下为 15 GB。和过去 96MB 的 Region 大小限制相比,心跳和内存占用这一类的 Region 开销降幅高达 99%。\n\n因此,使用 partitioned-raft-KV,TiDB 在扩展或缩小数据方面的速度大约快 5 倍,并且由于压缩的影响要小得多,其性能总体上更加稳定。\n\n## 未来展望\n\n一切看起来都很好。但是还有一个问题。现在我们有更多的 RocksDB 实例,因此它们的 memtable 的内存消耗要多得多,这意味着您可能需要额外的 5GB〜10GB 的内存开销才能在内存消耗和性能之间达到平衡。因此,当内存资源已经非常紧张时,通常不建议打开此功能。但是,当您在 TiKV 中有额外的内存并关心可扩展性和写入性能时,这个功能可能会对您有所帮助。\n\n## 写在最后\n\n一些客户可能会说当前版本的 TiDB 已经足够好了。所以新功能对他们来说似乎并不重要。但是,如果他们可以在一个集群中用于多个工作负载,而且每个工作负载都可以得到良好的隔离和 QoS 保证呢?这就是 7.0 版本中的“资源管控”功能。partitioned-raft-KV 功能旨在最大化硬件性能,与“资源管控”一起使用,我们的客户将能够充分利用其硬件资源,并通过将多个工作负载合并到一个集群中来降低成本。","date":"2023-05-12","author":"徐奇","fillInMethod":"writeDirectly","customUrl":"principle-analysis-of-partitioned-raft-kv","file":null,"relatedBlogs":[{"relatedBlog":{"body":"## 导读\n\nTiKV 推出了名为“partitioned-raft-kv”的新实验性功能,该功能采用一种新的架构,不仅可以显著提高 TiDB 的可扩展性,还能提升 TiDB 的写吞吐量和性能稳定性。TiDB 6.6 之前的版本已经成功容纳超过 200 TB 的数据,甚至有客户将超过 500 TB 的数据放入 TiDB 集群中;开启新功能后,TiDB 的可扩展性能够提高到 PB 级别。本文将深入介绍 TiKV “partitioned-raft-kv”功能的用户价值、应用实践以及使用方式。\n\nTiDB 是一种高度可扩展的分布式 HTAP 数据库,而 TiKV 是 TiDB 基于行的存储层。TiDB 的优势之一在于它的 OLTP 可扩展性:在 TiDB 6.6 之前,TiDB 集群可以轻松容纳超过 200 TB 的数据;有些客户正在将超过 500 TB 的数据放入 TiDB 集群中。相比之下,像 Aurora 这样的传统数据库则很难处理超过 100 TB 的数据。\n\n在 TiDB 6.6 及后续的版本中,TiKV 的一个名为“partitioned-raft-kv”的新实验性功能可以将 TiDB 的可扩展性带到 PB 级别。它利用了一种新的架构,不仅可以提高可扩展性,还可以显著提高 TiDB 的写吞吐量和性能稳定性。\n\n## 用户价值\n\n- 更高效:更好地利用硬件能力,消除写入流程中的瓶颈\n- 更快:更好的写入性能和 QoS,特别是在大数据集下\n- 更安全:每个表的物理隔离。\n\nPartitioned-Raft-KV 的主要改进之一是将写放大显著降低,最高可降低 80%,从而可以释放更多的 IO 资源用于用户的实际读写流量。另一个主要改进是通过每个区域的专用 RocksDB 实例,消除了单个巨大 RocksDB 实例的逻辑瓶颈,因而在生成和应用快照时对用户流量没有逻辑影响。快照的唯一影响是 IO / CPU 资源消耗,但因为降低了读放大,所以总的资源消耗仍然小于旧版本。\n\n## 性能测试\n\n在 AWS m5.2xlarge 上运行 Sysbench 的批量插入:\n\n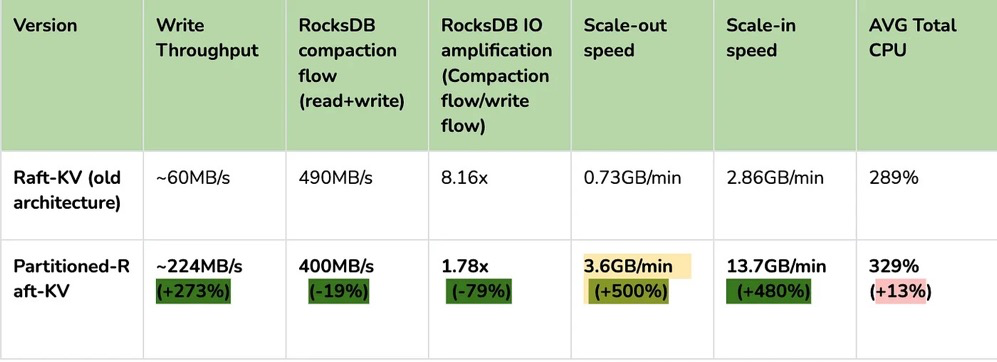\n\n在这里,我们可以看到其写入吞吐量要高得多。I/O 吞吐越大,提升越明显。因此,该特性对大宽表(行大小> 4KB)的插入操作性能提升要比小表更明显。\n\n另一个重要的改进是更快的扩缩容速度(即增加/减少 tikv 节点)。这意味着 TiKV 现在可以更快地响应用户流量的增长或下降。更重要的是,可以看到在扩缩容操作时,gRPC 的延迟和吞吐量不会受到影响,如下图所示。\n\n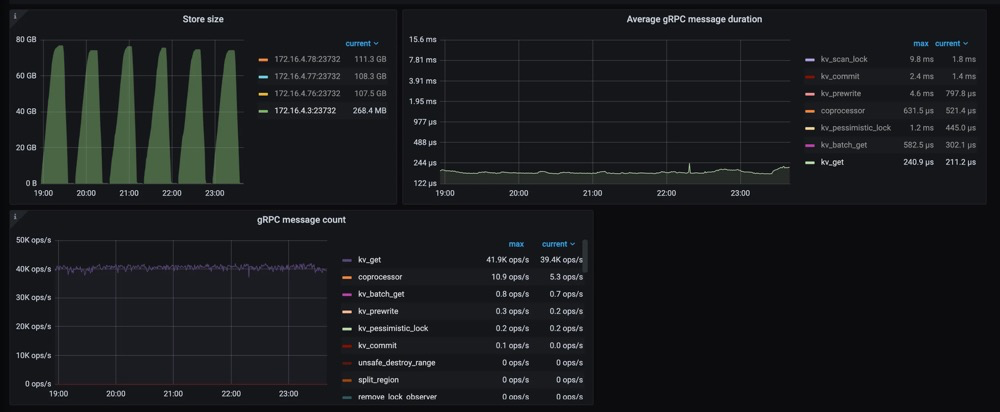\n\n关于 CPU 使用率,Partitioned-Raft-KV 的 CPU 使用率即使在写入吞吐量更高的情况下也没有显著增加。这是因为工作负载本身并不是 CPU 密集型,并且 Partitioned-Raft-KV 的 compaction 相关操作占用的 CPU 较小,其内部消息编码也进行了优化。因此,单位吞吐量 (MB)的 CPU 使用率要低得多。\n\n## 使用限制\n\n- 工作负载是 CPU 密集型的情况下,例如大量小的读写请求\n- 工作负载是读密集型。\n\n虽然“partitioned-raft-kv”可以节省一些压缩相关的 CPU 资源,但减少的 CPU 资源通常不到一个单独的核心。因此,如果工作负载是 CPU 密集型的,“partitioned-raft-kv”帮助不大,当然它也不会使情况变得更糟。然而,在重读取方案下,“partitioned-raft-kv”可能会有一定的性能退步,因为它在内存表上消耗更多的内存,而在范围查询工作负载中不是很有用,这些内存可以被页面缓存使用以实现更好的读取性能。在未来的版本中,这将通过刷新空闲内存表来进行优化。在接下来的章节中,我们将探讨它如何实现这些改进,并使用一个真实的用户案例来展示它在 Web3 场景中的好处。\n\n## 应用实践\n\nB 公司是一个 Web3 服务提供商,同步多个区块链的数据,然后向其客户提供查询/分析服务。它每月处理约 40TB 的数据。查询负载主要在最近的新数据上,而旧数据大多处于空闲状态。\n\n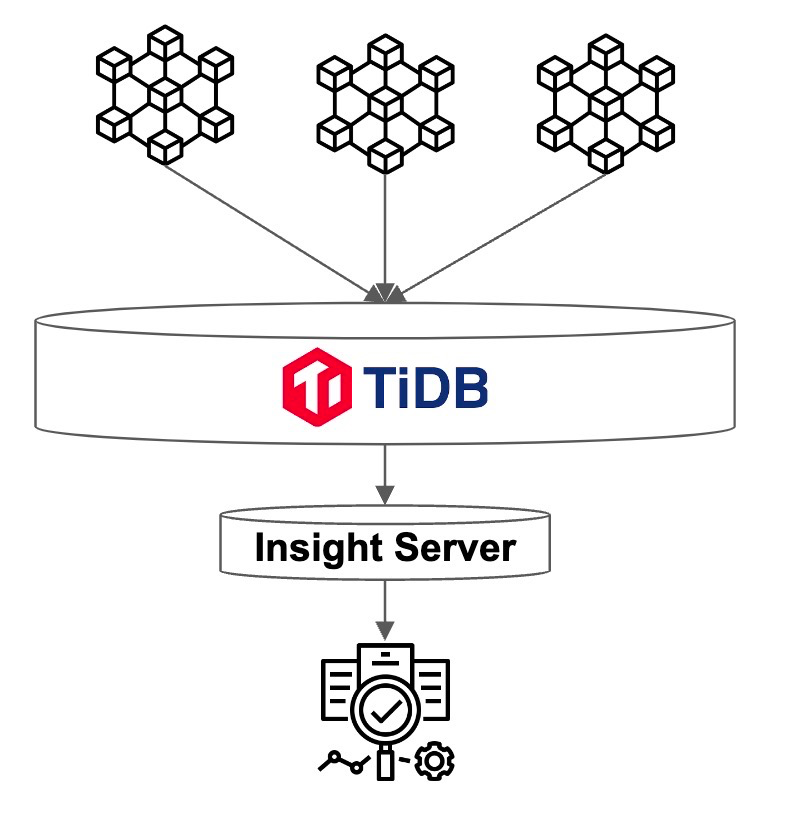\n\n**服务概述**\n\n当每个 TiKV 节点有 2TB+ 数据时,由于读/写放大的影响,性能稳定性会受到影响。因此,为了跟上快速增长的数据量,即使查询流量保持稳定,B 公司也必须每月添加 TiKV 节点来匹配数据大小。为了解决这个问题,B 公司想出了一个解决方案 - 冷热数据分离。\n\n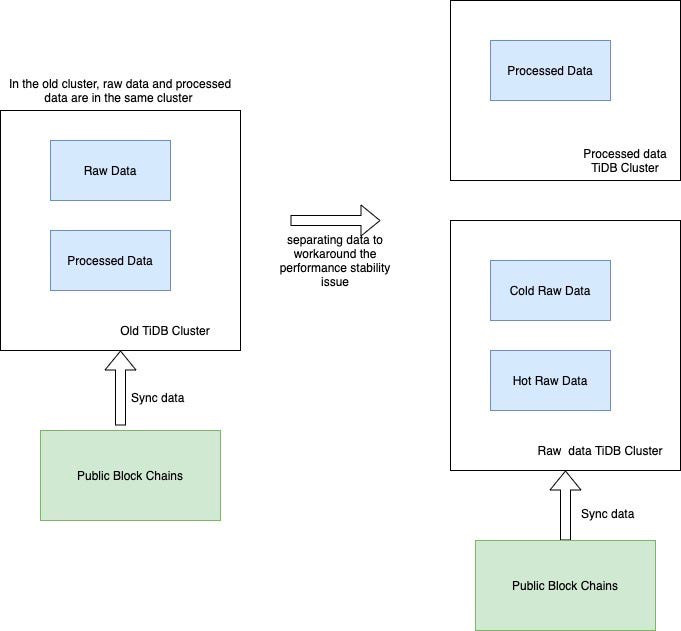\n\n首先,为了减少已处理数据的影响,他们必须将其与原始数据分开,现在他们有两个集群,一个用于存放已处理数据,另一个用于存放原始数据。其次,为了减少热原始数据的影响,公司 B 使用了放置规则(Placement Rules),通过主键中嵌入的时间戳将冷数据和热数据分开。这是通过每月更新放置规则来完成的。\n\n这种方法的问题是:它增加了管理复杂性,现在公司 B 有两个集群,而不是一个集群。同时,每月更新放置规则也是一个容易出错的操作。冷原始数据和热原始数据的资源分配很棘手。它们不共享,这意味着冷原始数据的 TiKV 大多数时间都处于空闲状态,然后当它们被使用时,资源很可能不足够。但是,有了 v6.6 的“partitioned-raft-kv”,我们可以继续使用一个集群,因为我们从不担心冷数据会影响热数据的查询。冷数据只是静静地坐在那里,不会消耗内存或 CPU。因此,单个 TiKV 可以通过混合冷热数据支持大量数据(4TB +)。因此,我们能够使用完全相同的 TiKV 节点来存储冷热数据。热数据应该分散在不同的 TiKV 节点中,这要归功于热点平衡,而冷数据也应该因为区域平衡而分布均匀在每个 TiKV 节点中。\n\n## 开启方式\n\n该功能只能在设置新集群时启用,之后不能更改,因为存在数据兼容性问题。我们将在后续版本中解决此问题。要启用新功能,只需将 storage.engine 的参数配置为 `partitioned-raft-kv`,另外,还可以通过调整一些其他的配置项来让该特性能更好适应您的工作负载。您可以参考[分区 Raft KV](https://docs.pingcap.com/zh/tidb/v6.6/partitioned-raft-kv) 获取详细信息。\n\n在下一篇文章中,我们将探索新功能的内部机制,介绍为什么它能具有如此大的优势。\n","author":"徐奇","category":1,"customUrl":"partitioned-raft-kv","fillInMethod":"writeDirectly","id":484,"summary":"TiDB 6.6 之前已经成功容纳超过 200 TB 的数据,开启新功能后,TiDB 的可扩展性能够提高到 PB 级别。本文将深入介绍 TiKV “partitioned-raft-kv”功能的用户价值、应用实践以及使用方式。","tags":["TiKV"],"title":"TiDB Raft KV 新引擎:更高级别的可扩展性和写性能"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}