{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/opening-speech-from-guangnan-ni",
"result": {"pageContext":{"blog":{"id":"Blogs_498","title":"倪光南院士在 PingCAP 用户峰会的现场致辞","tags":["PingCAP 用户峰会"],"category":{"name":"观点洞察"},"summary":"在 PingCAP 用户峰会 2023 上,中国工程院院士倪光南亲临现场,为大会致辞。","body":"## 导读\n\n在 PingCAP 用户峰会 2023 上,中国工程院院士倪光南亲临现场,为大会致辞。倪光南院士在致辞中表示 PingCAP 自主开源的创新模式已经在全球范围内得到广泛认可,并号召中国的企业和开发者加强知识产权保护和技术输出,提升中国开源数据库在国际市场的影响力和竞争力,在满足中国市场需求的同时,走向世界,服务全球用户。\n\n\n\n各位来宾,女士们、先生们\n\n大家上午好!\n\n非常荣幸受邀参加 2023 平凯星辰用户峰会。开源是科学开放精神的一种体现。开源经过近 40 年的发展历史,已经成为促进信息技术发展和技术创新的强大动力。开源代表着开放、合作和共享,它不仅是一种研发和商业模式,更是一种文化和思维方式。开源的力量可以打破传统的技术壁垒,促进知识的共享合作,加速技术的演进应用。国际上开源生态体系已经形成,越来越多的开发者加入到了开源大军当中,成为全球协同创新的中流砥柱。\n\n在开源数据库领域,中国的发展成就引人瞩目。中国企业和开发者们参与到开源数据库的研发和贡献中来,推动着中国开源数据库行业的快速崛起。我们看到了国内开源数据库项目的数量和质量都在不断提高,推出了众多优秀的开源数据库产品和解决方案。以平凯星辰为代表的开源数据库企业,一直致力于打造全球化的开源社区,其开源的数据库产品 TiDB 已经在全球范围内得到了广泛的认可和应用。他们多年来秉承开源文化理念,深耕开源创新之路,成功的探索出一条开源商业模式。在此,我也希望中国有更多的企业和开发者加入开源创新行列,加大对开源社区的投入和贡献,推出更多的高质量的中国开源创新项目,使开源在各领域取得更大的成就,推动中国从开源大国走向开源强国。\n\n今天,数据库作为核心的数据基础设施变得越发重要,我们看到了各种创新技术和产品不断涌现,大大促进了社会的数字化进程。在数据库技术的发展中,我们看到了一些重要的技术趋势,比如云原生、人工智能与数据库技术的结合等。这些数据库技术的前沿趋势和快速应用为国产化数据库生态的构建和创新的发展提供了重要的契机。为此,未来我们要注重加强数据库技术与云计算、人工智能等领域的融合,学习国际先进技术和经验,推动国产化数据库向云原生方向发展。同时,我们还要积极探索数据库技术与人工智能的深度融合,构建面向未来的智能数据处理技术。\n\n当前,发展国产化数据库具有重要的战略意义,在我国的各个领域,国产化进程正在加快推进,核心技术的自主创新能力正在全面提升。国产化数据库不仅要求技术的国产化,更要求我们构建起完整的国产化生态,包括研发、生产、销售、服务等各个环节。习近平总书记强调:“科学技术具有世界性,时代性,是人类共同的财富”。在当前新一轮科技革命和产业变革中,我们要顺应科技发展潮流,拥抱开源,与世界协同创新,要积极地参与和融入全球开源社区,共享知识,共谋发展,这既是为了获得更广泛的技术和市场资源,也是为了实现更高水平的科技自立自强。\n\n未来,我们希望中国的数据库技术与全球的技术协同发展,我们的数据库产品不仅能满足国内市场的需求,还能走向世界,服务全球的用户,为全球的协同创新贡献中国智慧,中国方案。\n\n最后,预祝峰会取得圆满成功!谢谢大家!","date":"2023-07-20","author":"倪光南","fillInMethod":"writeDirectly","customUrl":"opening-speech-from-guangnan-ni","file":null,"relatedBlogs":[{"relatedBlog":{"body":"## 导读\n\n在刚刚结束的 PingCAP 用户峰会 2023 上,PingCAP 创始人兼 CEO 刘奇分享了题为“创新涌动于先”的演讲,全面解析了 AI 时代 TiDB 的演进方向,宣布 TiDB Serverless 正式商用,并携手用户代表发布了面向中国企业级用户的平凯数据库。以下是演讲实录全文,阅读需约 8 分钟。 \n\n过去一段时间,我拜访了全球各地的客户,聆听他们的挑战和建议,以及 PingCAP 是如何帮助他们解决挑战的。在这个过程中,我们也看到一些新的技术发展趋势。当下,AI 技术非常火,到处都是各种各样的 AI Demo,每家企业都在思考这样一个问题:**AI 到底有没有可能重塑软件行业?我的答案是——AI 这次真的要重塑整个软件行业了**。\n\n\n\n## AI 重塑软件行业\n\n作为一家软件公司,我们思考的问题直接体感通常有两个:一个是代码,一个是数据。 \n\n先从代码说起,大家有没有意识到,很多人在过去一段时间不自觉地变成了程序员。今天,我们向 ChatGPT 提问题,它会给我们一个答案;向它提要求,它会给我们一个结果。比如我们可以让 ChatGPT 做总结、写文章,或者让它生成图片。大家可以回忆一下,在 AI 时代到来之前,所有这些工作都需要用程序去完成。我们需要用各种各样的辅助工具,那些东西都需要编程开发。而今天,我们没有写任何一行代码,只是提了个需求,结果就有了。以前,这需要很多程序员很长时间努力才能得到一样的结果。而现在,我们向 AI 发命令、提要求、提问题就能拿到结果,事实上就等于完成了编程工作。现在,自然语言已经成为最热门的编程语言。在过去七个月的时间里,GitHub 上新增代码中已经有超过 46% 是由 AI 生成的。如果从软件开发效率的角度看,AI 实际上已经完成差不多一半的人类工作。 \n\n再说数据,我们今年一月份发布了一个 AI 生成 SQL 的产品,叫 Chat2Query(前往 tidbcloud.com 立即注册体验),用户使用 Chat2Query 就不需要再写 SQL 了,只要用自然语言描述一下希望得到什么数据,希望做一个什么分析,SQL 便会自动生成,只要在数据库里运行一下,就能得到想要的结果,并且还能用图表化的形式自动展示出来。 \n\n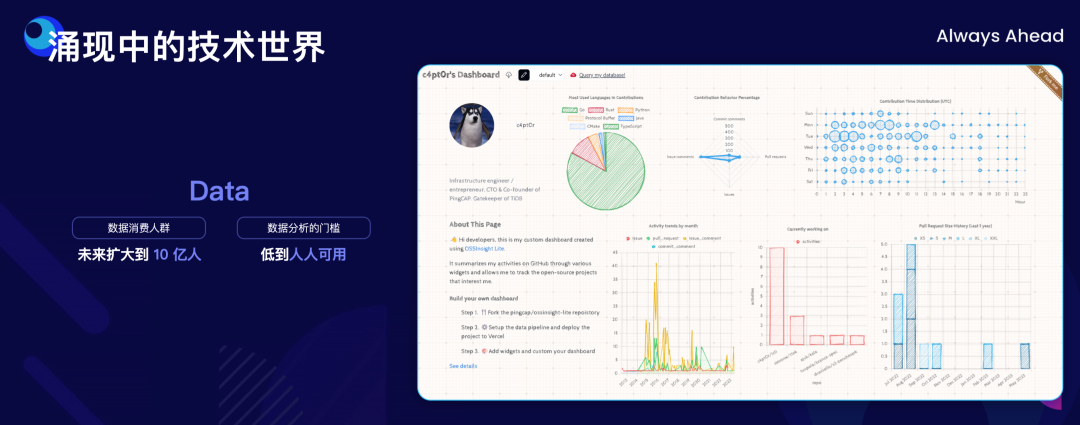\n\n上图右侧是 PingCAP CTO 黄东旭在 GitHub 上的个人数据看板。以前要实现这样一个数据看板,需要一个前端程序员、需要一个数据分析人员写 SQL 来分析数据,还需要一个后端程序员部署服务,甚至还需要知道一点云的知识,理解如何把应用部署在云上。到了今天,这变成一件非常简单的事情,只需十分钟,一行代码都不用写。这是一次巨大的生产力提升,**AI 带来的能力让数据消费的门槛变得极低**。以前,我们必须是一个 SQL 的专家,才能分析数据。有人曾经写过一万多行的 SQL 来处理一个分析需求,这个东西不是人类能轻易掌握的。如今,这个门槛已经降到人人都有可能做到。这意味着我们只要能够连接上电脑,能和 AI 交互,能接触到数据,就可以消费数据。这个数量级可能达到 10 亿人。在接下来的几年里,由数据消费门槛降低带来的数据消费人数的增加,数据消费频次的增长,将使数据呈 10-100 倍规模的增长,这是一个远超我们预期的增速。\n\n## AI 时代,我们需要怎样的数据库技术?\n\n以上改变,将给数据库带来巨大的挑战,数据消费的门槛降到人人可用的程度,需要每个人都有一个数据库可用。早在四五年前,我和 CTO 黄东旭探讨过一个话题——如果 PingCAP 要为全世界所有开发者提供一个免费的数据库,那这个数据库的架构应该是什么样? \n\n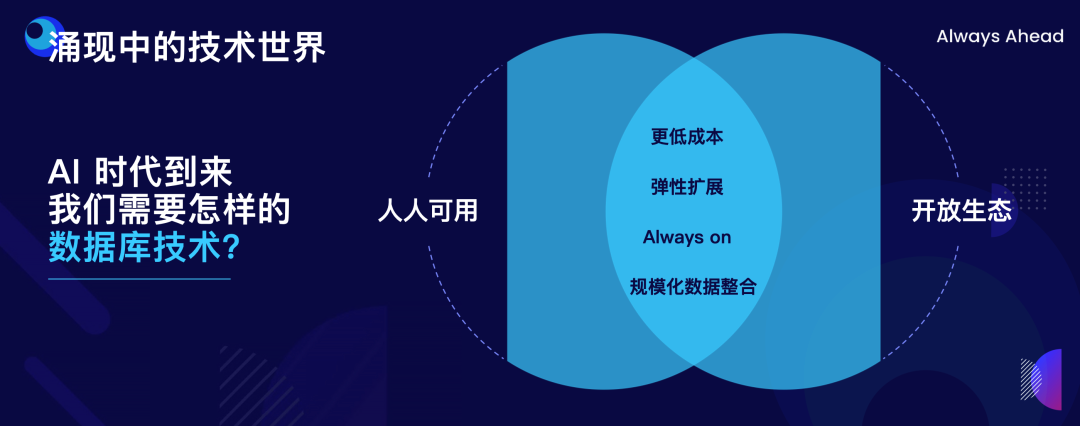\n\n我们希望这个数据库能够做到实时在线,随时都可以访问,随时都可以用;我们也希望它是一个开放的生态,因为我们不仅仅有存在数据库里面的数据,还有很多存在其他地方的数据,我们需要有一个生态能够和所有数据消费端做更好的对接。 \n\n后来,我们形成了一个结论,起码它应该是个云原生的架构。如果不是云原生的架构,我们就没有办法去应对各种各样弹性的需求;今天,一个用户相对容易预测,那为全球所有开发者都提供一个免费的数据库,就意味着我们会有数千万甚至数亿的用户,这个数据库怎么才能做得到?它需要很强的数据整合能力;其次,因为不同用户的需求是不一样的,数据量也不同,我们需要它有非常强的弹性扩展能力。 \n\n\n\n过去这两年的变化特别快,大家感知最直观的可能是宏观经济变化很快,其实除此之外,AI 技术的进步速度也非常快。从 ChatGPT 在去年 11 月底推出,到今天才过去短短八个月的时间。这八个月中已经创造了无数新的纪录,包括一个新的项目在 GitHub 上面获得 Star 的数据、ChatGPT 用户增长的速度等等。 \n\n大家在面对大量新技术的时候,都做出了最直观的选择,那就是拥抱先进性。过去一段时间我在与美国、日本的客户交流时,最直接的感受是每个人都在讨论两个方向,一个是成本,另一个是效率。在当前经济环境下,这几乎成了所有人的共同选择。\n\n## 客户的关注点就是 TiDB 的焦点 \n\n如果仔细观察 TiDB 发展的轨迹,你就会发现用户对数据库的关注点,其实和 TiDB 实际解决的问题是高度一致的。TiDB 在稳定性、性能、高可用性、易用性、工具生态的提升等方面付出了巨大努力。但我们认为这件事光努力还不够,我们还需要有一个非常好的演进策略以及分层的架构设计。 \n\n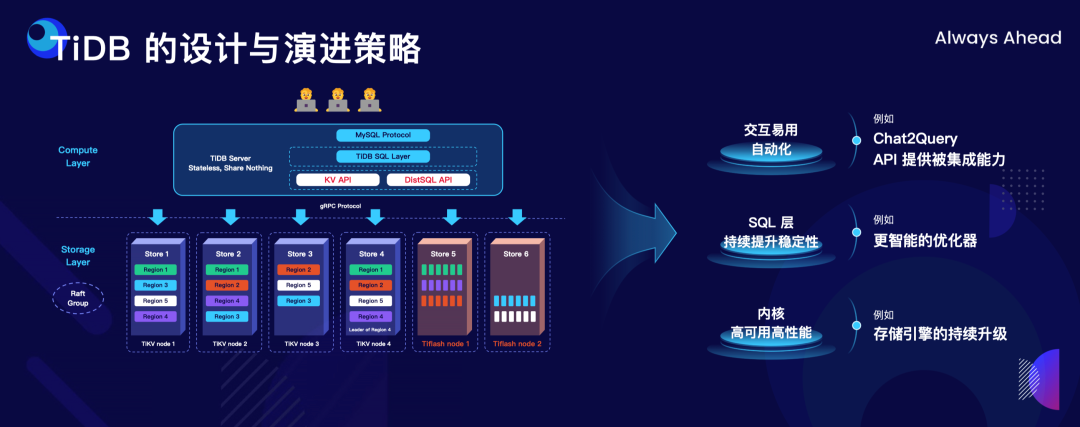\n\n在内部,我们有一个说法叫做 API First,各个模块之间优先设计 API(接下来我们也会推出更多基于 Open API 规范的 API 测试),有了 API 之后系统就很容易被其他各种各样的业务系统集成。举个例子,各大型用户基于 TiDB 都有自己公司内部的运维平台,通过我们提供的 API 能更好地融合到客户内部的平台里。在日本我和一个客户交流的时候,对方专门提到过这一点。过去他们需要花几天时间才能完成新版本的集成,但有 API 之后只要花几分钟就能做到。 \n\nTiDB 整个系统除了模块化的切分,也做了很好的纵向切割,从上到下分成三层。比如 Chat2Query 在最上面一层,这层会更关注整个系统的交互性、易用性,如何让系统更加自动化、更加智能;在 SQL 层主要关注如何提升它的稳定性,让它变得更加智能。比如 TiDB 的优化器如何更智能地选择,到底使用行存还是列存,还是让行列同时使用;最下面是内核层,所有人对此的关注点都一样,就是高可用、高性能。 \n\n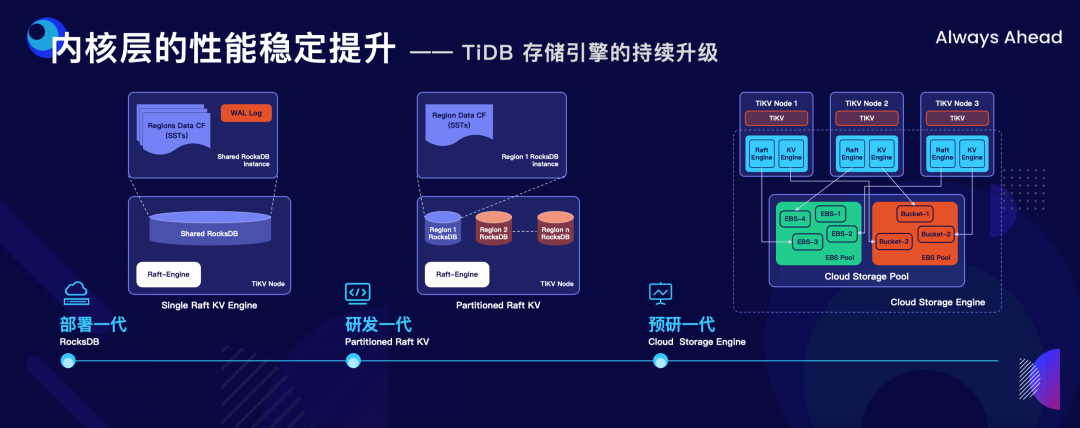\n\n在内核层,TiDB 的存储引擎使用了一个持续升级的策略——部署一代、研发一代、预研一代。今天我们听到的所有关于 TiDB 的讨论,其实都是基于部署一代的体感,不少用户还使用着 TiDB 3.0、4.0,而这已经是四五年前的版本了。当然我们也希望用户能更快升级到最新版本,享受到新版本带来的优势,每一个新版本都会带来巨大的性能和稳定性提升。7.0 版本发布的实验特性 Partitioned Raft KV 就带来了巨大的性能提升。前面预测未来几年数据会扩大 10 倍,部分领域会扩大 100 倍,在如此大的数据规模下面我们的数据库能力是不是也能同步扩大 10 倍、100 倍?这是 Partitioned Raft KV 解决的问题。我们预研一代的存储引擎 Cloud Storage Engine 已经在后面要提到的 TiDB Serverless 中应用,我们的 CTO 黄东旭在后面的演讲和 Blog 中都有详细的解读。 \n\n如果大家留心就会注意到,过去一年时间里 TiDB 的 Online DDL 的速度提升了 10 倍。设想一下,我们有一个 100TB 的表,加一个索引要多久?对系统资源的消耗又是什么样的?除了 DDL,还有一点是 TiDB 的扩缩容的速度在这个引擎里面提升了 5 倍,这也意味着数据丢失的风险降低 5 倍,业务中断的风险降低 5 倍。\n\n## 平替还是跃迁?TiDB 产品家族的协同演进\n\n经过多年发展,TiDB 目前已经拥有三大产品家族:一是面向企业级市场的 TiDB 企业版,服务于企业级关键业务场景;二是全托管的 TiDB Cloud,提供云端一栈式 HTAP 数据库服务,已经成为欧洲、北美、日本、亚太地区众多数字原生企业的选择;三是刚刚正式商用的 TiDB Cloud Serverless,一个 AI Ready 的数据库,以极简架构、极致体验和超低门槛为云上开发者、创业公司提供低至零成本的选择,较 TiDB 社区版和 MySQL RDS 更具成本优势。 \n\n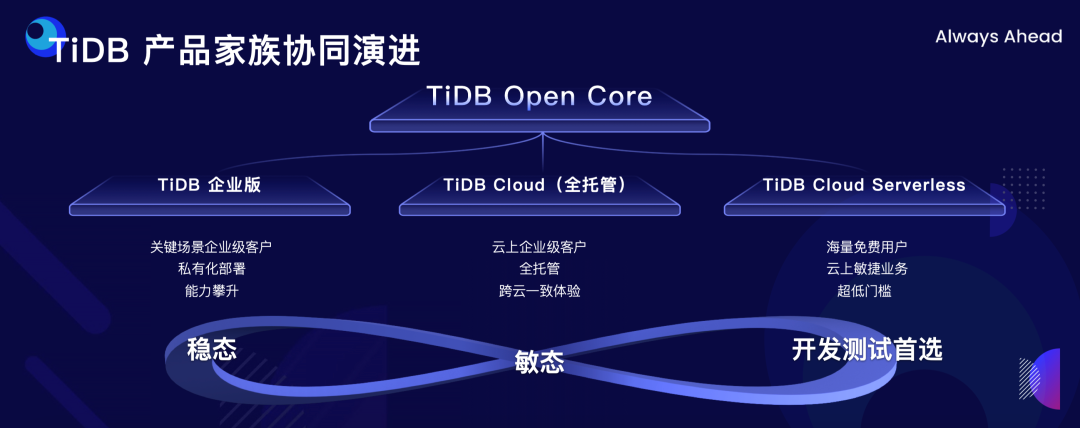\n\nTiDB 是如何在多个版本间协同演进的?从上图可以看出,最上面有一个 TiDB 的 Open Core,TiDB 的所有这些版本都是基于共同的 Root 生长出来,去适应不同的客户和不同的使用场景。 \n\n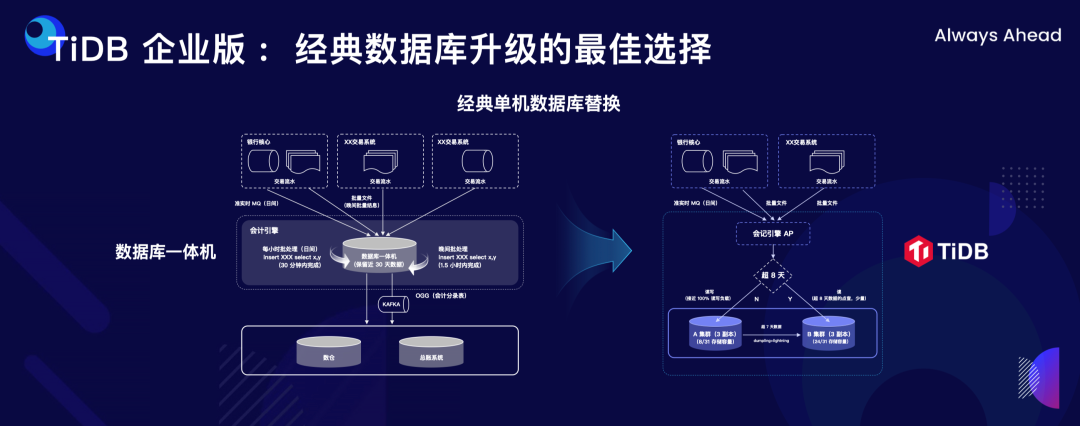\n\nTiDB 企业版已经拥有很多大行、大型企业的使用经验,他们有些是从数据库一体机迁移过来的,在迁移过程中和 TiDB 一起积累了大量的迁移经验。最近 MySQL 5.7 马上就要结束产品生命周期(End of Life)了,用户应该怎么办?换一个数据库平替一下?我们的思路不一样,我们希望的是用户不仅仅是从 MySQL5.7 迁移到 TiDB,更要关注的是他迁移过来之后的获得的价值到底是什么。 \n\n我们希望 TiDB 提供的价值是“可持续、可扩展、可整合”。很多企业都有大量的 MySQL 5.7 ,有成百上千个 instance,管理和维护它们都是非常复杂的事情。TiDB 提供了资源共享的多租户能力,我们可以把更多的 MySQL 实例整合到一个或者多个 TiDB 集群,极大提升资源利用率,从而降低硬件成本,同步降低管理集群的成本。最近我们和一个客户交流,他们有很多 MySQL 实例,有的利用率不高,就直接降级,从原来的 8C 配置,直接降成 4C 或 2C 配置。过了一段时间,业务这边有个流量把系统卡死了,再给升级一下。过一段时间流量又下来了,再降级。这就很头疼,运维和开发的关系就很难处,降本增效的压力很大。这么多的 MySQL instance 一旦迁到 TiDB 上面,基于 TiDB 本身的资源共享能力,流量超了几倍都没问题,这就可以带来非常显著的降本增效。 \n\n\n\n接下来是 TiDB Cloud,它在过去几年里得到了全球客户的认可,包括欧洲最大的移动出行公司 Bolt,北美新锐的 SaaS 公司 Catalyst,印度最大的电商 Flipkart,日本著名的游戏公司 CAPCOM 等等。 \n\n\n\n最后是 TiDB Serverless。四年前,我亲手写下第一行源代码,探索新一代云上 Serverless 架构,这是预研一代的成果。非常幸运,预研一代的速度远远超出我们的预期,它现在已经正式商用了。过去几个月的时间里,TiDB Serverless beta 版已经拥有超过 1 万个活跃的集群。 \n\nServerless 带来了什么样的价值和能力呢?第一,低成本零元起步。TiDB Serverless 完成了 PingCAP 的一个梦想,我们有能力为全球每一个开发者提供一个免费的数据库。 \n\n我想稍微分享一个内部的小故事,最早 TiDB Cloud 的 free tier 成本是现在的 100 多倍。我们内部有个笑话,自己总是调侃说我们是“贵司”。“贵司”是什么意思呢?TiDB “贵”。因为比较的对象是 MySQL,作为一个分布式系统,TiDB 跟一般的系统比成本肯定高,起步就三个副本,还有计算层、调度层,跟单机比肯定是贵了。很幸运的是, TiDB Serverless 出来之后“贵司”终于不“贵”了。得益于 TiDB Serverless 采用的完全分离式的架构,不仅仅做到了存算分离,我们还做到了算算分离、存存分离,整个系统的弹性非常强,同时它的使用异常简单,用户体验非常好。我们收到大量用户的赞誉,超出了自己的预期。 \n\n大家都希望把自己的时间精力投资在自己的创新上面,投资在自己的业务上面,尽量不想再花时间在数据库上面,将所有复杂的事情都交给系统,交给 PingCAP 完全自动化处理。过去,大家可能会很好奇,这听起来好得有点过了,能做到吗?凭什么? \n\n## TiDB Serverless 为什么比社区版更便宜?\n\n今天我们在云上面使用数据库或者使用传统的 RDS,不管是什么数据库,本质上都是买一个虚拟机,按照最高的峰值要求配置,不管你的业务现在跑的是什么量,哪怕 CPU 利用率是 1%,你也必须为它的 100% 利用率付费。这就是一个传统的计费模式,永远为最高的峰值付费。 \n\nTiDB Serverless 的创新在于,你永远只为你正在使用的资源付费。举个例子,你现在假设有 10 TB 的数据跑在 TiDB Serverless 上面,你没有任何访问,那所有的计算节点全部会被自动 shutdown,但你可以在百毫秒的时间内就马上让它启动提供服务。这是一个巨大的进步,用户仅仅为使用付费,使用曲线长什么样,TiDB 的计费就会长什么样。这就是为什么 TiDB Serverless 能够做到比现在的 RDS,比云上面部署社区版还要便宜,只要这个 CPU 的利用率低于 20%,全自动的弹性就会带来巨大的成本优势。 \n\n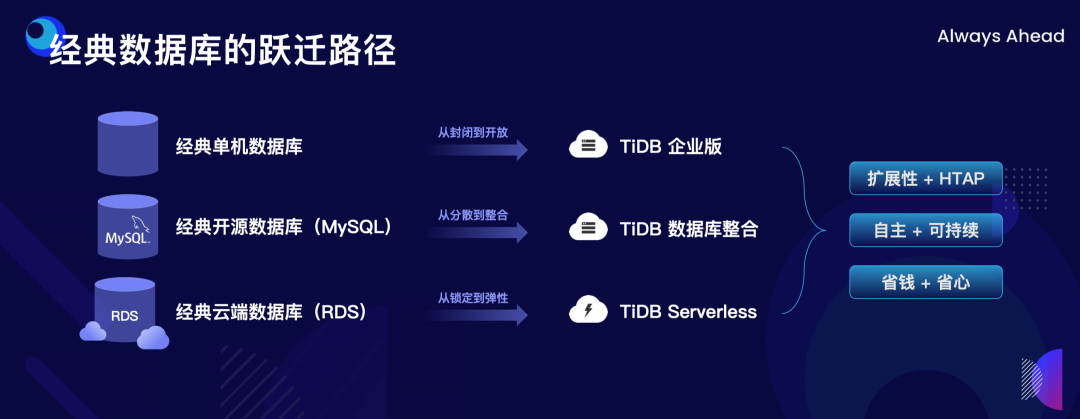\n\n今天,不管你使用的是经典的单机数据库、开源数据库还是云端的数据库,TiDB 都提供了成本更低,扩展性更强,更加省心的选择。 \n\n## 面向中国企业级用户,发布平凯数据库 \n\nTiDB 源于中国,很多关键特性也来自于中国复杂的用户场景,毫无疑问中国市场就是 TiDB 的根据地和大本营。最近我们和很多中国用户沟通交流,他们给了我们非常多的反馈,很多反馈都非常有价值,特别是对于 TiDB 未来发展的预期和展望。我们发现,TiDB 企业版经过五年的打磨,更多是面向全球用户提供通用性的功能,但是这些功能对于中国企业级用户来说还远远不够。 \n\n当下,随着 TiDB 逐步进入中国用户的核心场景以及 TiDB 规模化进入国产化生态,面向中国企业级用户的“平凯数据库”正式发布了。 \n\n\n\n简单来说,平凯数据库主要包含 TiDB Open Core 的稳定内核以及满足中国企业用户的增强级企业功能。第一,提供国产化需求的企业级功能,包括图形化管控平台、全链路数据迁移平台、安全特性等等;第二,提供更完善的国产化生态系统的接入功能,包括国产软硬件的适配,比如操作系统、服务器等等;第三,提供更完善的国产化企业级服务支持能力。 \n\n未来,我们希望平凯数据库站在 TiDB LTS(长期支持版)的基础上能为中国的客户带来更好的价值,我们希望这个过程是开放的,会定期在国内各个区域组织用户讨论交流的活动,我们希望大家能一起参与到未来平凯数据库的建设中来。","author":"刘奇","category":5,"customUrl":"always-ahead-by-max-liu","fillInMethod":"writeDirectly","id":496,"summary":"在刚刚结束的 PingCAP 用户峰会 2023 上,PingCAP 创始人兼 CEO 刘奇全面解析了 AI 时代 TiDB 的演进方向,宣布 TiDB Serverless 正式商用,并发布了面向中国企业级用户的平凯数据库。","tags":["PingCAP 用户峰会"],"title":"刘奇:经典数据库亟需跃迁,TiDB 不是“平替”"}},{"relatedBlog":{"body":"## 导读\n\n在 PingCAP 用户峰会 2023 上,PingCAP 研发副总裁唐刘、PingCAP 首席科学家丁岩,共同带来了“携手中国用户,打造世界级产品”主题分享。分别从 TiDB 7.x 版本内核的演进方向、面向中国企业级用户的新品平凯数据库的发版策略和产品路线图两个角度,解析 TiDB 产品家族协同演进路径。以下为分享实录。\n\n## 携手中国用户,打造世界级产品 \n\n\nPingCAP 研发副总裁 唐刘\n\n我是 PingCAP 唐刘,负责 TiDB 的产研工作。首先请容我对在座的各位以及在线收看直播的用户报以最诚挚的敬意,因为有你们八年多不断的坚持、陪伴和信任,才有了我们现在源源不断的动力去打磨、去不断完善我们的产品,给客户带来更大的价值。 \n\n我们先来探讨一个话题,为什么中国企业以及中国的用户对 PingCAP 非常重要?从 TiDB 诞生的第一天起我们就致力于解决企业用户在规模化负载下的稳定性和性能问题。熟悉 TiDB 的用户应该都知道,我们最开始就是解决的 是 MySQL 分库分表的问题。经过八年多的发展,在各行各业无论衣食住行,还是金融保险都有了 TiDB 的身影。鉴于中国这样庞大的用户基数,大家可以想象这些规模化场景对整个数据库的稳定性和性能都提出了世界级的挑战。毫不夸张地说,如果我们能满足中国用户这些天花板级别的要求,我们就非常有信心地将产品推广到全世界,让全世界的用户享受到 TiDB 带给他们的价值。所以,中国对我们来说非常重要。 \n\n\n\n过去一年,PingCAP 投入了大量资源去解决 TiDB 在规模化场景下的稳定性和性能问题,也取得了不小的成果。首先在国内的某头部大行,通过我们的跑批优化,在该行的反洗钱业务、客户详单查询业务跑批场景上有 2-3 倍的性能提升。在国内某头部城商行,我们通过悲观事务的优化,在他们的互联网核心交易场景,实现了延迟降低 4 倍,7*24 小时延迟抖动控制在 2% 以内的目标。在国内某互联网零售企业,我们通过多业务整合和资源管控的方式,不仅使得用户节省了成本,同时也让业务的整体延迟下降了将近 50%。这些是我们在过去一年中取得成绩的一部分,非常感谢这些用户对我们的选择和信任。 \n\n\n\n当然不限于此,TiDB 的产品核心能力也有很多方面的重要提升。首先,在线 DDL 的性能提升了 10 倍。对于老版本中用户关注的 OOM 问题,经过我们一年多的努力,TiDB 最新的版本中的 OOM 较之前的版本下降了 99%,实现了质的飞跃。目前,TiDB 已经能做到单表 50TB 数据的小时级别导入,让用户非常顺滑、快速地将大批数据导入到 TiDB,满足用户对极致的 RPO 和 RTO 的述求,数据同步输出的延时也降低至了秒级。这些性能提升大家可以在最新的 TiDB 7.1 LTS 版本中享受到。未来,我们在后续的 TiDB 7.X 版本中,将继续致力于稳定性与性能的提升。 \n\n\n\n下面我给大家简单介绍 TiDB 7.X 版本中的三个重要新特性。 \n\n第一个特性是 Partitioned Raft KV,它带来的用户价值非常显著。我们能让用户相比之前用更少的机器,挂更大的盘,存更多的数据,还能提供更好的性能。在当前数据规模不断膨胀和多变的经济环境下,对用户来说这是一个非常具有吸引力的特性。使用 Partitioned Raft KV 这个特性之后,TiDB 无论是在性能还是在成本上面相比之前都有了质的飞跃,希望大家尽快使用 TiDB 的最新版本来体验这个功能。 \n\n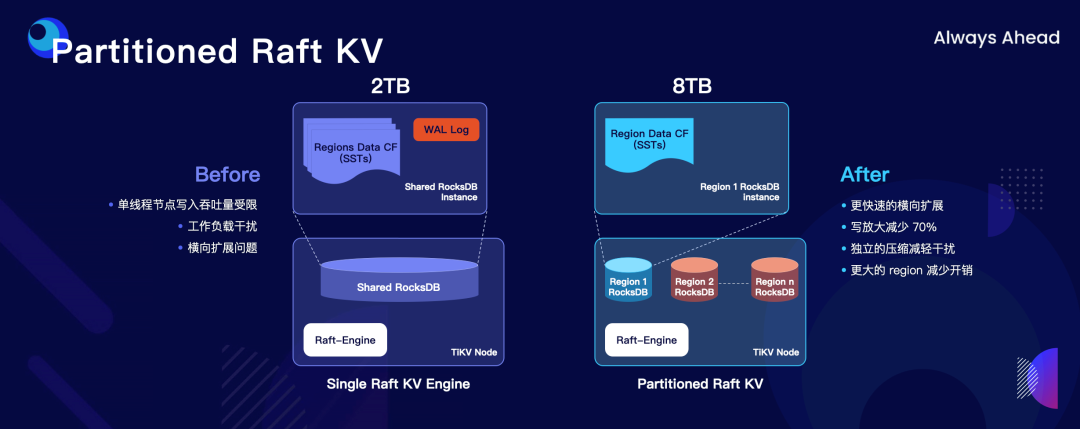\n\n第二个重要新特性就是资源管控(Resource Control),之前有很多用户反馈在使用和维护多套 MySQL 集群上面精疲力尽,将多套 MySQL 集群归集到一个 TiDB 里面又担心跑在数据库里面的业务相互影响。TiDB 7.1 LTS 版本已经提供了一个非常好的解决方案,就是通过 Resource Control 让用户非常方便地将多个 MySQL 实例汇聚到一个 TiDB 集群里面,一方面能够极大降低用户对于多套 MySQL 集群的运维成本,降低了运维复杂度,另一方面通过多合一的业务汇聚能够帮助用户节省成本。在实际的用户场景中,我们发现使用多合一的汇聚能帮用户节省 40% 左右的成本,在当前经济环境的压力下和降本增效的背景下,基于 TiDB 资源管控的数据库整合方案无疑是理想的选择。 \n\n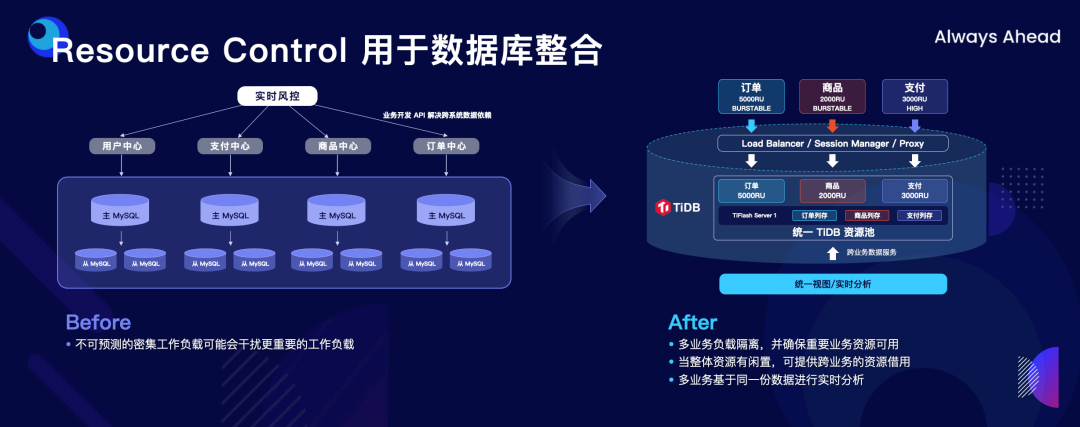\n\n第三个重要特性就是在线 DDL。在今天敏捷迭代的商业环境中,数据库需要跑得更快,但是我们不可能一开始就设计出一个完美的表结构。随着业务不断地快速变化,我们势必会对原始设计的表结构进行频繁的变更。运维过 MySQL 的同学应该都知道,当 MySQL 的集群规模非常大的时候(或者一些传统数据库集群规模非常大的时候),如果你要做一个 DDL 变更,这是多么痛苦的一件事情,不仅耗时会非常长,而且可能会造成停机维护、业务中断,甚至造成业务损失。然而,这一切在 TiDB 里面都不是问题,我们从第一天就支持了在线 DDL。在 TiDB 新版本中,在线 DDL 的性能提升了 10 倍,意味着你可以比竞争对手更快地进行表结构的变更,更敏捷地支撑业务迭代,以更快的速度在竞争中胜出。 \n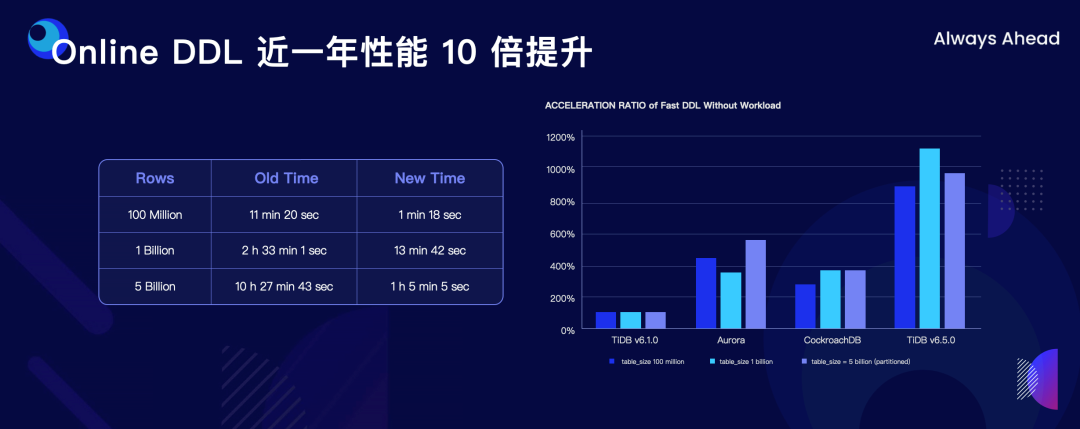\n\n后续的 TiDB 7.X 版本中将会推出 DDL 并行执行框架。如果你想要 DDL 执行得更快,只需要不断地添加节点,就能够实现性能的水平扩展,可以在 10 倍提升的基础上再乘以 N 个框架并行。这套框架不仅会用于当前的 DDL 处理,未来 TiDB 大批量的数据导入、大规模的数据统一分析、甚至一些重型查询的并行执行,我们都会通过这套框架进行统一的收敛。未来,我们希望通过这套并行框架给用户提供一套极致的性能体验。 \n\n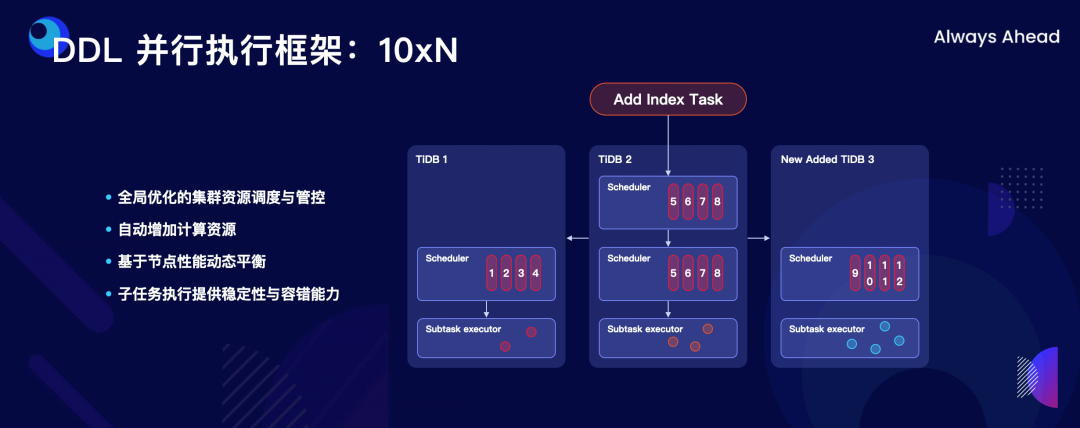\n\n这一系列新特性将会在 TiDB 7.5 LTS 中和大家见面。TiDB 7.5 版本将会提供更强大的资源管控能力,Partitioned Raft KV 将正式 GA,TiDB 也将全面兼容 MySQL 8.0。大家知道 MySQL 5.7 将在今年 10 月 End of Life,PingCAP 承诺我们会持续拥抱 MySQL 生态,不断地兼容 MySQL 5.7 和 MySQL 8.0,同时会带来顺畅的迁移体验,方便用户把数据库从 MySQL 迁移到 TiDB,实现无缝地迁移和使用。 \n\n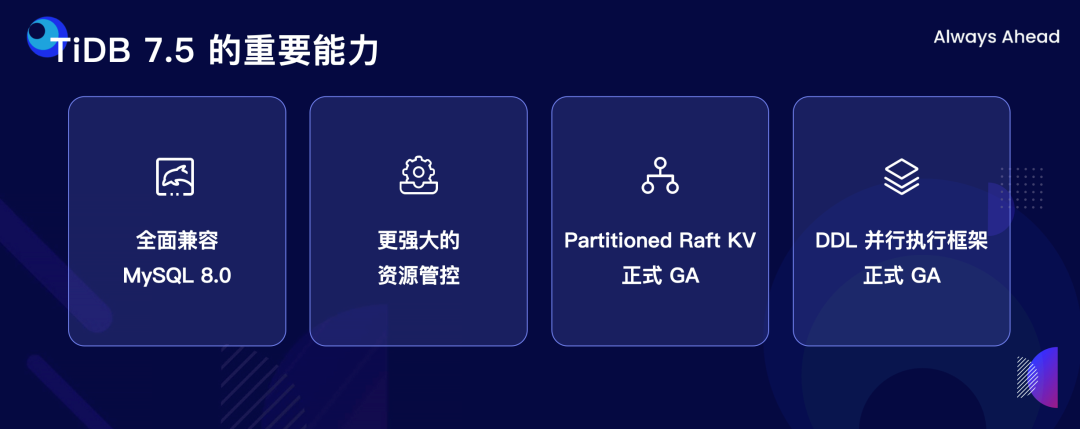\n\n从第一天开始 TiDB 就致力于成为一款全球化的数据库,从第一天开始我们坚信中国用户一直是 TiDB 持续创新的核心发动机。据我们内部统计,TiDB 新版本中有 50% 的功能需求来自中国用户,TiDB 70% 的外部贡献者来自于中国,有 30,000 多名中国的 AskTUG 用户在体验产品并给出反馈。今年,我们启动了用户之声活动,来到各个区域倾听用户的声音,希望通过我们的努力携手中国用户打造一款世界级的数据库产品。 \n\n\n\n## 平凯数据库,为中国企业用户需求量身定制 \n\n\nPingCAP 首席科学家 丁岩\n\n我是平凯数据库的研发负责人丁岩。刚才唐刘介绍了很多 TiDB 的内核新特性,非常惊艳。对于中国企业用户来讲还有一个惊喜,一个专属的福利就是平凯数据库,我来介绍一下平凯数据库的发版策略和产品路线图。 \n\n我们锚定 TiDB 在每个 LTS 版本发布之后三个月左右,随着增强型企业级功能一起发布平凯数据库的新版本,节奏是每半年发布一个版本。平凯数据库是中国企业用户专属的一个福利,它有哪些吸引人的特性? \n\n前面研究院付平老师介绍过,中国正在加速制定数据库的标准规范,涵盖方方面面。平凯数据库定位于全面地遵守国标、行标,兼容国产化生态,在安全合规方面让用户用得放心、用得安全。我们有很多大客户,例如国有大行的 TiDB 集群已经达到上百个,服务器达到上千台的规模,这个时候管理和运维就成为一个难题。平凯数据库适时地推出可视化管控平台(TEM),轻松管理上千台服务器、上百个 TiDB 集群,为用户节省管理运维的成本,提升管理效率。 \n\n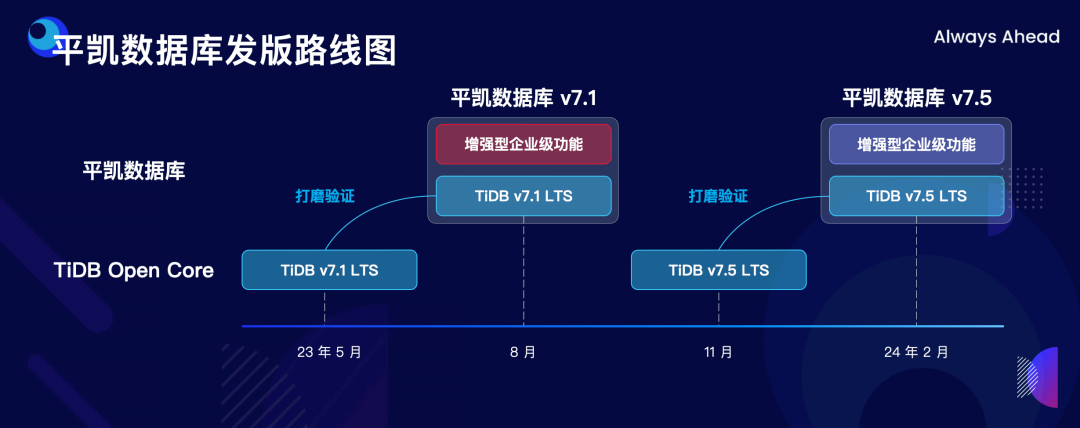\n\n中国市场上很多客户正在计划或者已经在把 Oracle 上的业务迁移到 TiDB,这个时候迁移成本包括迁移过程中的风险在所难免,我们也急客户所需,想客户所想,推出了全链路数据迁移平台(TMS),从数据库的对象,到 SQL 的兼容分析,到迁移前后 SQL 执行性能的对比,再到存量数据的迁移,提供一套全流程的迁移工具和解决方案,降低客户的迁移成本和迁移风险。此外,平凯数据库还提供存储过程的兼容,存储级的备份恢复,高级安全功能等。平凯数据库 7.1 版本将在今年 8 月底正式 GA。 \n\n\n\n半年之后,我们将发布平凯数据库 7.5 版本。7.5 版本将在符合国标、行标最新的规范标准,在安全方面持续发力。在生态方面,TEM 支持 K8s 集群的管理;大数据生态兼容方面,7.5 版本支持 ORC 格式数据的导入;自动化部署支持 IPv6。7.5 版本将持续提升存储过程的执行效率。我们收到的中国企业用户的迫切需求,都会在后续版本中做规划和交付,更多惊艳的企业级新特性正在路上,敬请期待。 \n\n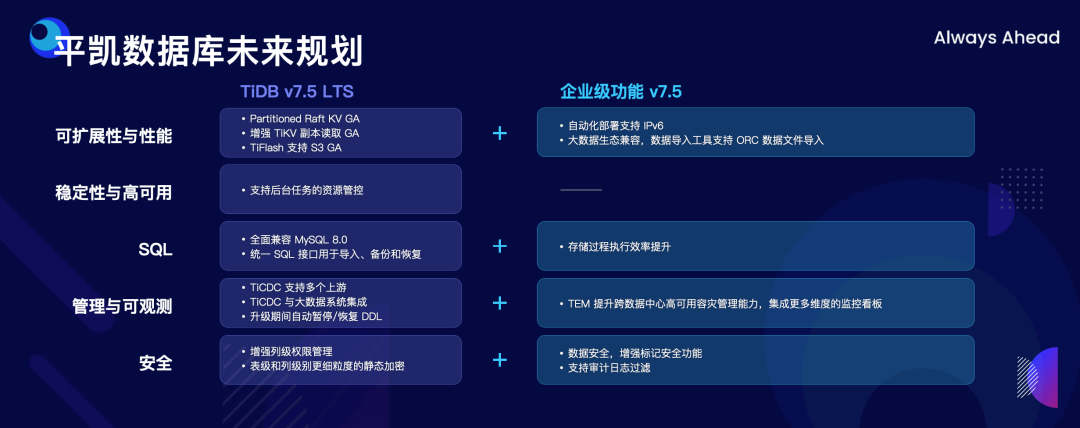\n\n","author":"唐刘 丁岩","category":5,"customUrl":"build-world-class-products","fillInMethod":"writeDirectly","id":497,"summary":"PingCAP 研发副总裁唐刘、PingCAP 首席科学家丁岩分别从 TiDB 7.x 版本内核的演进方向、面向中国企业级用户的新品平凯数据库的发版策略和产品路线图两个角度,解析 TiDB 产品家族协同演进路径。","tags":["PingCAP 用户峰会"],"title":"PingCAP 唐刘:携手中国用户,打造世界级产品"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}