{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/how-does-chatgpt-revolutionize-the-database-interaction",
"result": {"pageContext":{"blog":{"id":"Blogs_471","title":"黄东旭:狂飙的 ChatGPT ,如何颠覆数据库交互形态?","tags":["ChatGPT","TiDB Cloud","Serverless","HTAP"],"category":{"name":"观点洞察"},"summary":"AI、Serverless 和 HTAP 的结合将是数据库发展的新里程碑,ChatGPT 只是个开始,接下来肯定会有更多更强的产品,在通向真正的 AGI 这条路上涌现。","body":"今天凌晨,OpenAI 发布了万众期待的多模态预训练大模型 GPT-4,它被称为迄今为止功能最强大的模型。自从问世以来,ChatGPT 在短短几个月间已经迅速引爆了整个科技领域。\n\n我在它刚发布的时候就开始用,现在几乎已经完全离不开它了,包括写文档、写邮件、写代码等工作,基本都在用 ChatGPT 辅助完成。\n\nChatGPT 可能是这个时代做出的第一次接近 AGI (Artificial general intelligence,通用人工智能)的产品。从 ChatGPT 的表现来看,它已经不是针对某一个具体细分领域的 AI 应用,而是拥有一些通识的系统。最令我惊讶的是,它其实已经具备了一些逻辑推理的能力,这是之前任何 AI 系统都没有达到的水平。\n\n目前基于 ChatGPT 提供的相关能力已经出现很多非常火的应用方向:\n\n第一个是最简单的翻译。ChatGPT 的翻译能力特别强,你丢给它一篇文章,或者丢给它一段文本,可以让它直接生成一段 summary,或者做特征关键字提取,这是目前一个很典型的应用;\n\n第二个应用是做数据清洗,比如你手上有一份 Excel 或者 CSV 文档,或其他任意的数据。过去做数据质量评估,需要很多文职人员手工去整理。现在,你丢给 ChatGPT 一个 CSV 文件,可以让它直接帮你去做类似纠错或者数据清洗的工作;\n\n第三类应用是我个人比较感兴趣的,是跟开发者相关的东西,比如代码生成,或者像 copilot 这样的应用;其他还有一些像比如帮你写文章或者帮你写邮件的应用。\n\n## ChatGPT 对于数据库技术的重大利好\n\n现在, ChatGPT 背后的这些能力其实都是构建在数据上,这对于数据库或数据存储技术来说,是一个特别大的利好。那它对数据库都提出了哪些新要求呢?我们首先来看下过去大家在使用数据这件事情上会有哪些特别痛苦的点:\n\n第一,数据存储。过去当你面向的是一堆单机数据库,而且是能力很弱的,比如 key value 或者一些支持的 workload 特别有限的数据存储技术,你就会发现很容易会造成一个个数据孤岛。而数据的价值只有在不断交叉或者不断交互的过程中,才能产生更高的价值。数据孤岛导致数据虽然存下来了,但是没有办法从中获取到更多的价值。\n\n假设有这样一个分布式 SQL 数据库,你能够很方便地与不同部分的数据,不同的表做关联交叉分析。这看起来很好,但它带来的挑战是数据存下来后,怎么快速地把数据或者 insight 变成一个在线的 service,这件事情其实过去是 OLTP 数据库干的。过去很长一段时间, OLTP 和 OLAP 是完全分开的两个系统。OLAP 当然可以做很复杂的 join 分析以及查询。但是你不可能直接拿一个数据仓库或者 OLAP Database 作为在线服务 ,对外实现数据变现。你还是得把它放到另外一个 OLTP 的 Database 里。\n\nHTAP 数据库的出现,解决了两个问题:一,数据能存下来,同时底层是打通的,不用担心会产生很多数据孤岛;二,这些复杂的 query、数据的 insight ,能够直接变成一个 OLTP 或者 online service 对外提供服务。ChatGPT 很难在一个分库分表的数据库上生成正确的 SQL,这有点像巧妇难为无米之炊。但是它可以直接生成 SQL,跑在 HTAP 的 database 上,这样整体的效率就能提升很多,完成一个这样的数据 insight 的应用门槛就会低很多。\n\n第二,数据变现。越来越多的公司都有一个叫做数据中台的部门, CEO 或者业务人员经常跑去跟数据分析师说,我想要某个数据,你帮我去跑 query 查询一下。但这里面又形成了一个矛盾, CEO 或者企业管理者是懂业务的,但是他不懂 SQL,数据分析师懂 SQL,但是又不太懂业务。ChatGPT 这种 AI 的出现,对于管理者来说,就相当于有了一个贴身的智能助理。你可以直接用自然语言和它说,我有一个决策要做,你先在 database 帮我把数据跑一遍,看看我问的问题的结果是什么。相当于直接将数据变现的门槛给降得很低,这对于数据中台或者数据分析师的行业可能会比较冲击。\n\n## 我们如何将 ChatGPT 融入 TiDB?\n\n对我来说,ChatGPT 最大的挑战其实是想象力。我们应该如何去使用它,怎么把它的能力尽可能地在不同行业里放大,这是我最近一直在想的事情。\n\nChatGPT 对我们这种基础软件公司来说最大的意义在于,原先很多普通人用不了这个软件,只能通过程序员或者 DBA 去操作。但现在 ChatGPT 一下把数据库的使用门槛变成了任何人都可以使用。你只要能够清楚地描述要干什么,它就能够在数据里帮你提取 insight。从这个角度看,ChatGPT 是一个具有非常深远意义的产品形态,所以我们第一时间就把它的能力集成到了 TiDB Cloud 服务里面——发布了一个自然语言转 SQL 工具 Chat2Query。\n\n\n\n现在,大家都在讨论 ChatGPT,但事实上你可以认为 ChatGPT 只是 OpenAI 的一个 Demo,其背后的模型应该是 GPT 3.5 的一个大语言模型。OpenAI 把这些不同的语言模型通过 Open API 的方式暴露给全世界所有的开发者,并根据你的调用收取费用。开发者就可以基于这些 API 去做自己的应用,我们就是把它的 API 用到了 TiDB Cloud 里,封装在我们的产品后面。\n\nChat2Query 一经推出就非常火,很多开发者在上面构建了一些非常有意思的应用。一方面,它帮助 engineer 提升了不止一个数量级的开发效率;另一方面,它结合了 ChatGPT 的能力能够自动帮你写出 SQL,这使得整个数据库软件的形态都发生了变化。\n\n熟悉我们的朋友大概都知道,我们去年做了一个叫 OSS Insight 的开源社区数据分析平台。它最近推出了一个新功能 Data Explorer。你可以用自然语言去向它问问题,系统会自动给你答案。比如你可以问能不能为某个具体的 GitHub ID 生成一个 summary 报告,看这个 ID 平时是在贡献代码还是在提交 issue,或是只点赞。\n\n\n\n过去通过写 SQL 当然也可以做这件事情,但是 Data Explorer 功能可以让你用自然语言去问这个问题。它通过 OpenAI 的 API 将自然语言转变成一个等价的 SQL,用这个 SQL 去背后的 TiDB 数据库中进行查询。\n\n其实,自然语言生成 SQL 也不是什么特别新鲜的事儿,以前就有过很多的相关研究论文。这件事最让我感到震惊的是,ChatGPT 并不是一个专门针对解决自然语言到 SQL 转换问题而设计的一套系统,但是它产生的结果出奇的好。\n\n你只要告诉它一些简单的 prompt 或是一些 hint,比如这张表大概长成什么样子,注意一些 rules 等。同时还要提醒它在写 SQL 时,最好用最佳实践。通过这些简单的 prompt ,就能让 ChatGPT 生成非常高质量的 SQL。它生成的 SQL 其实已经超越了很多专门为解决此类问题而设计的系统。\n\n而且你会发现,我告诉 ChatGPT、OpenAI 系统的这些 prompt 信息里,并没有提供更多的信息增量。这是什么意思呢?就像你教一个小朋友做数学题,你教他的并不是怎么解具体的问题,而是告诉他应该好好审题,并再仔细想一想,这一次解题需要先去解答哪些子问题。我们只是在告诉系统如何思考问题的方式,系统就能够以一个更高的成功率去回答你想要问的问题。\n\n未来,可能会产生一个新职业——Prompt engineering。在使用 OpenAI 的这些 ChatGPT 能力的时候,其实是有一定技巧的,很多人在使用 ChatGPT 的时候会觉得它经常胡说,但其实我们在用 OpenAI 根据表结构信息生成 SQL 时,不能简单地告诉它生成满足问题的 SQL,而应该在中间的上下文里提供很多的提示词。\n\n举个我用过的几个 Prompt 例子:第一,我让它想象一下自己是一个 Python 编译器,或者想象一下是一个程序员,“下面你的任务是把这个问题改写成一段 Python 的程序”;第二,让它想象一下自己是一个 Python 解释器,把刚才生成的代码放到自己假想的解释器里去运行,最后把解释器返回的结果返回来。最后你会发现,当你把上下文 Prompt 一列进去,它的回答正确率大大提升,这个就是 Prompt engineering 一个很有趣的例子。Prompt engineer 本质上是在教它一些思考方式,你只要告诉这个机器 let's think step by step,正确率就能提升很多。\n\n## AI+Serverless+HTAP,数据库发展新里程碑\n\n过去这几十年,数据库只有一种形态,就是增删改查,写 SQL。对于计算机软件来说,每一次人和软件的交互方式的变化都会促成一个巨大的革命,或者是一个变革,ChatGPT 的出现就像互联网的发明,或者蒸汽机的发明一样,必然会引发一次变革。AI+Serverless+HTAP,这几个东西融合在一起将成为数据库发展中非常重要的里程碑,它会改变接下来数据库软件本身的形态,甚至是商业模式。\n\nChatGPT 刚出来的时候,大家第一反应都会觉得它像搜索引擎,但我觉得不是,它并不是搜索引擎,它更像基础设施。ChatGPT 本身这个 demo 是用一个 chat board 的形式呈现在人们面前,但它真正有意义的是封装在这些应用之下的能力。未来几年,不管你做什么行业,你都要去想一想怎么去跟 AI 进行结合,不要觉得它只是 IT 圈的事,我觉得这是任何行业都有的机会。\n\n我们千万不要低估大语言模型在未来会对人类社会产生的影响,它不再是简简单单的一个聊天机器人,它会深刻地改变所有行业。比如给程序员做辅助,它能够让一个很强的程序员的生产力提升 10 倍、 20 倍。我现在用 ChatGPT+ Copilot 后,基本不再手写太多代码。我只要把问题描述清楚,它就能够把这些这些代码生成出来,我最多在上面再做一些微调。虽然它不是百分之百正确,但已经节省了我百分之七八十的工作时间。这里面最核心的一点就是我们要放弃掉一个执念—— AI 不如人类强的固有观念。过去很长一段时间一谈到 AI,可能就是调调参,做个推荐系统。但现在以 ChatGPT 为代表的产品已经能实现非常多的功能,我们不能再用传统的眼光去看待这个事物。\n\n**ChatGPT 只是个开始,接下来肯定会有更多更强的产品,在通向真正的 AGI 这条路上涌现**。\n\n[立即体验 Chat2Query 完整能力](https://tidbcloud.com/free-trial?utm_source=website-zh&utm_medium=referral&utm_campaign=chat2query_202301)\n\n","date":"2023-03-15","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"how-does-chatgpt-revolutionize-the-database-interaction","file":null,"relatedBlogs":[{"relatedBlog":{"body":"12 月 1 日,以\"去发现,去挑战\"为主题的 PingCAP DevCon 2022 主论坛在线上成功举办,为数万观众带来一场技术盛宴。PingCAP 联合创始人兼 CTO 黄东旭,在大会上分享了 “The Future of Database” 的主题演讲,分享了他对云原生、开发者生产力的理解,介绍了 Serverless HTAP 的意义以及未来的“技术无感化”发展方向。以下为演讲实录,全文约 7000 字。\n\n首先感谢所有用户,用户的使用是支撑 PingCAP 一直进步的最重要动力,每年看到 TiDB 越来越普及,用户越来越多,就感觉肩上的担子又重了。\n\n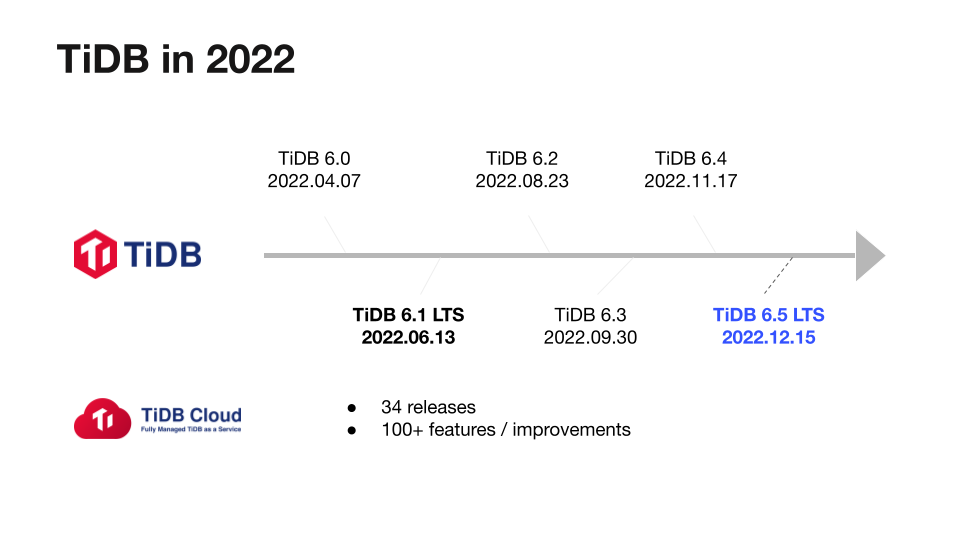\n\n在过去一年中,TiDB 有一个最重要的变化——发版节奏和模型发生了变化。今年,TiDB 第一次引入了 LTS 版本,以及形成了以两个月为周期的迭代发版节奏。此外,特别值得一提的是,今年 5 月 TiDB Cloud 正式 GA,去年我提到云的意义在于加速软件的迭代速度,短短大半年时间 **TiDB Cloud 已经进行了超过 34 次迭代,增加了上百个功能特性和改进**。这个迭代速度比 TiDB 内核本身的迭代速度更快,这也印证了之前我对于云的判断。\n\n## 数据库的“第一性原理”\n\n埃隆·马斯克有一个很有名的“第一性原理”,这些年我一直也在思考这个问题,对于一个数据库厂商或者数据库产品经理来说,数据库软件的第一性原理是什么?**对于数据库来说,一个很本质的问题是 developer 到底需要什么样的数据库**。这里说的 developer 并不是指数据库开发者,而是那些真正开发应用的开发者。为什么这么说呢?其实数字化转型也好,各种应用创新也好,其背后的驱动力到最后都是一行一行代码,而这些代码都是开发者写的。对于数据库软件来说,真正的用户其实就是开发者。\n\n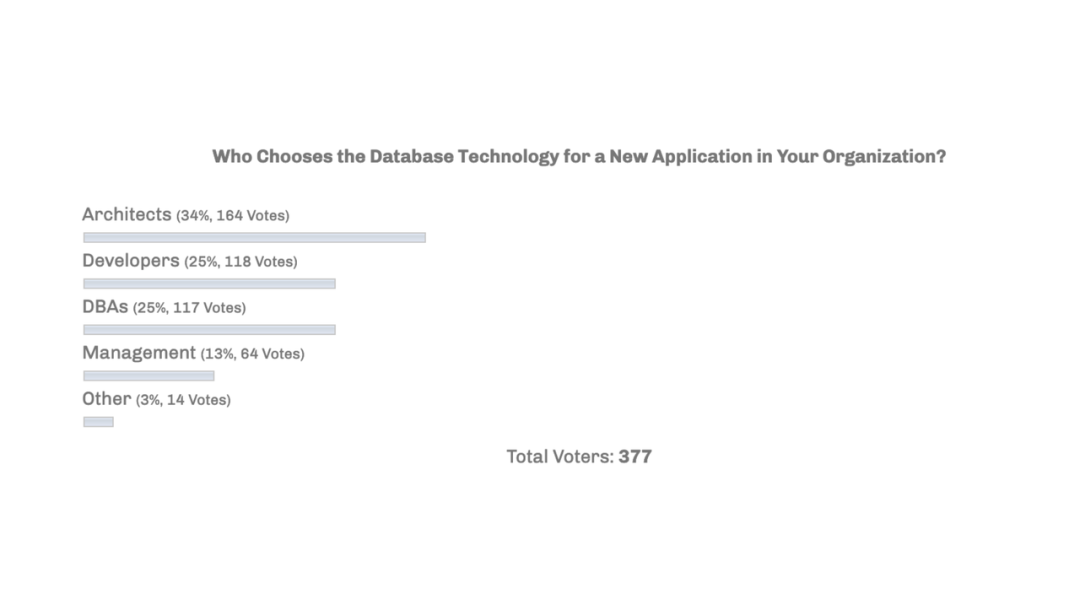\n\n上图是一项关于“在你的组织内部到底是谁在选择 Database”的调查,可以看到排名第一的是架构师、第二是开发者、第三是 DBA,三者加起来达到了超过 80% 的占比。这些人都是广义上的开发者,对于数据库软件来说真正的用户其实就是这些人。\n\n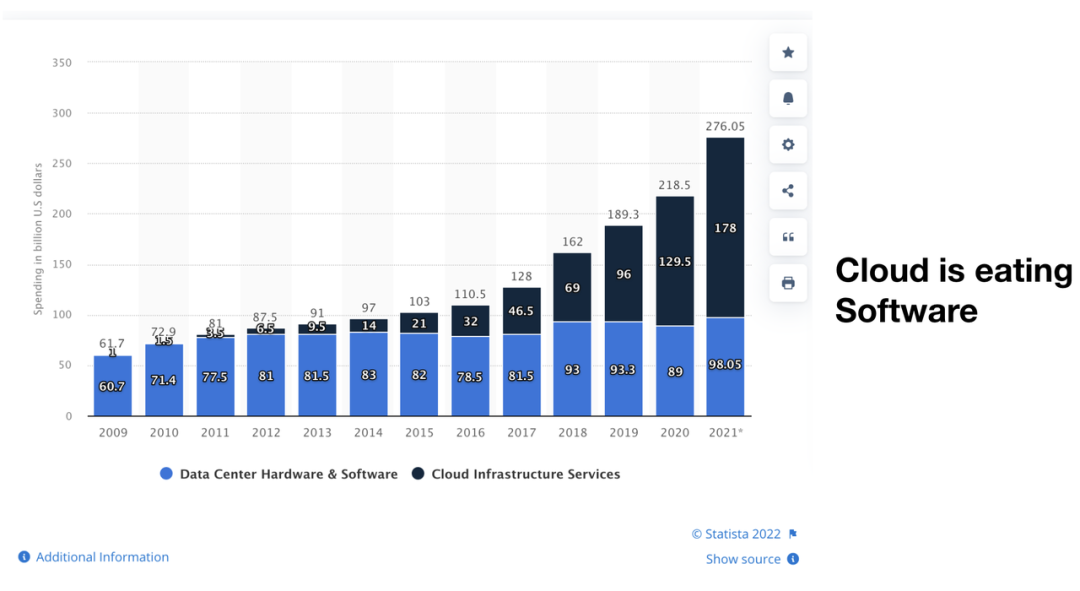\n\n数据库里另外一个大的趋势是 Cloud。我觉得今年已经不用再强调 Cloud is the future,从 Gartner 的报告可以看出,今年全球企业在 Cloud 上的投入已经超过了私有化数据中心的投入,并且每年的增速都非常快。\n\n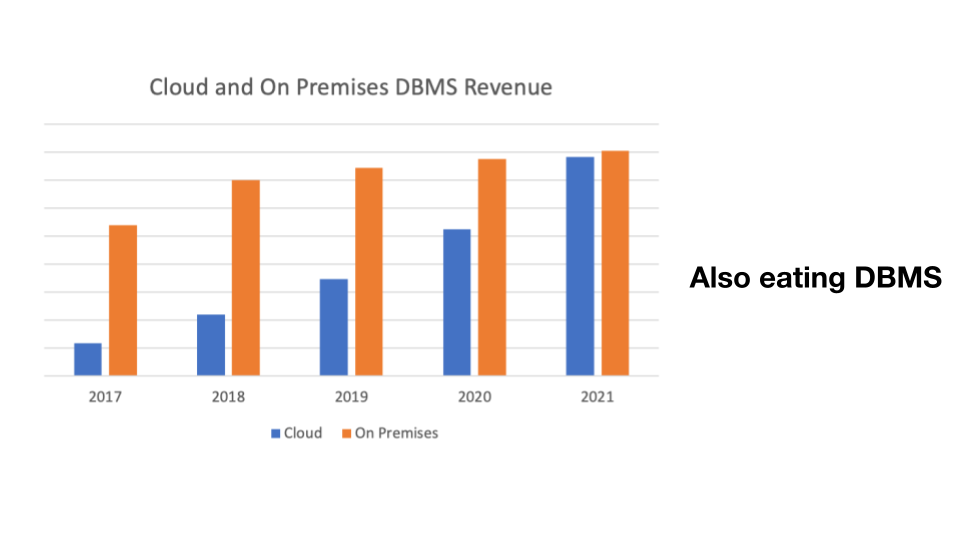\n\n在数据库领域中也有着同样的趋势,上图是云数据库和私有化部署的数据库软件的占比趋势。大家可以看到,2019年时,云上的数据库服务(Database as a Service)还不到传统数据库的一半,但今年几乎接近一样,可以预见明年一定会超过。所以,云是毋庸置疑的趋势,**在未来的数据库产品中,Cloud 一定会变成数据库服务的承载平台**。\n\n## 如何解放开发者的生产力?\n\n这次分享的主题依然是“The Future of Database”,要讲的是数据库的未来会是什么产品形态。谈到这个话题,我的思考习惯是先关注现在数据库到底有哪些痛点,开发者到底在为什么烦恼。\n\n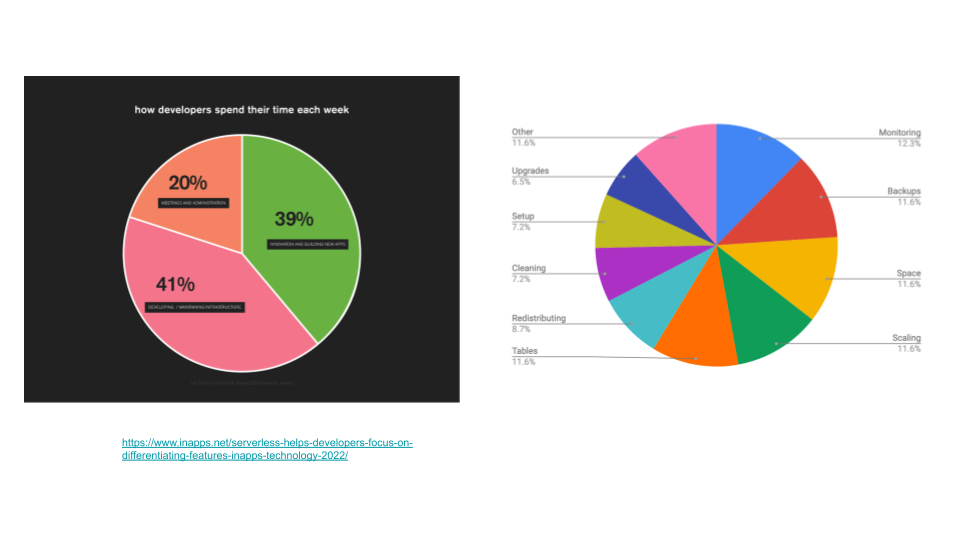\n\n从这张图可以看出,开发者、程序员、DBA 日常的时间都花在了什么地方。你会发现他们 39% 的时间在做业务创新、在 Coding,41% 的时间在做基础设施维护,如买服务器、部署服务器、运维等等。这其实非常符合一个开发者的日常体感。有时候作为一个程序员,我想要雄心勃勃地做一个新的东西、新的应用时,会发现真正开发那个应用的时间可能只占整个时间的 10%-20% 左右,**大量时间都花费在买服务器、部署数据库、数据的备份恢复、CI/CD 搭建上,而不是在开发应用上面**。\n\n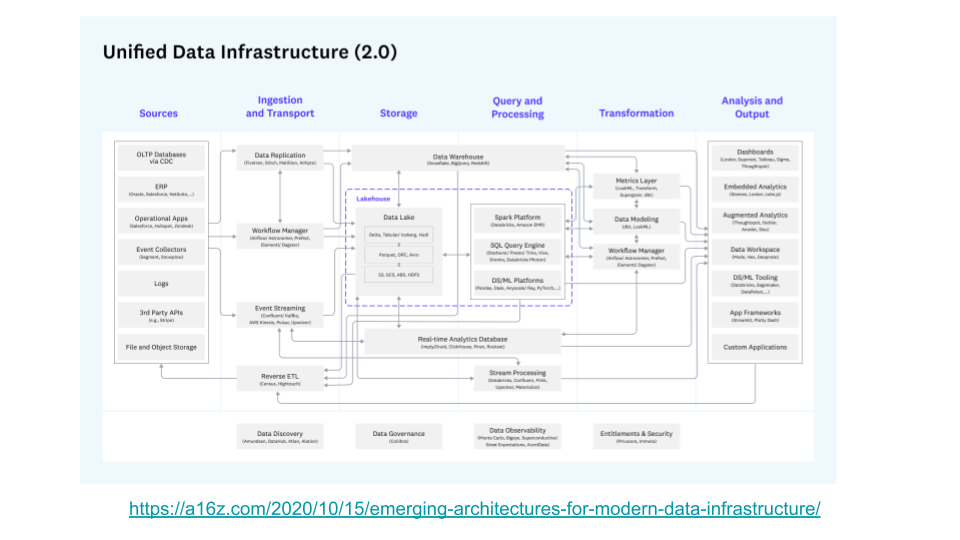\n\n这张图来自 a16z(美国一个特别著名的投资机构)在 2020 年底出的一份报告,他们提出了一套包治百病的数据架构“Unified Data Infrastructure”。当时看到这个架构的时候,我觉得它确实包含了我们遇到的各种各样的问题,这个架构确实能解决问题。**但另一方面,图中每个框其实都是一套非常复杂的软件**,这个架构的问题是框特别多、特别复杂,而且这些框之间互相的连接会把事情变得更加复杂。想象一下刚才提到的小例子,我在开发一个应用时要花很多时间去处理这些基础设施的问题,在这张图里,刚才这些不爽的体验要再乘十或二十倍,因为这些组件之间的连接会带来更多的复杂性。所以这个架构看起来很美,但实际上我们会花更多的时间去保障系统稳定运行。\n\n综上所述,**当今把开发者拖慢的最核心原因是开发者的生产力**,如果开发者的生产力提高了,业务创新、应用创新的速度就会变得更快。\n\n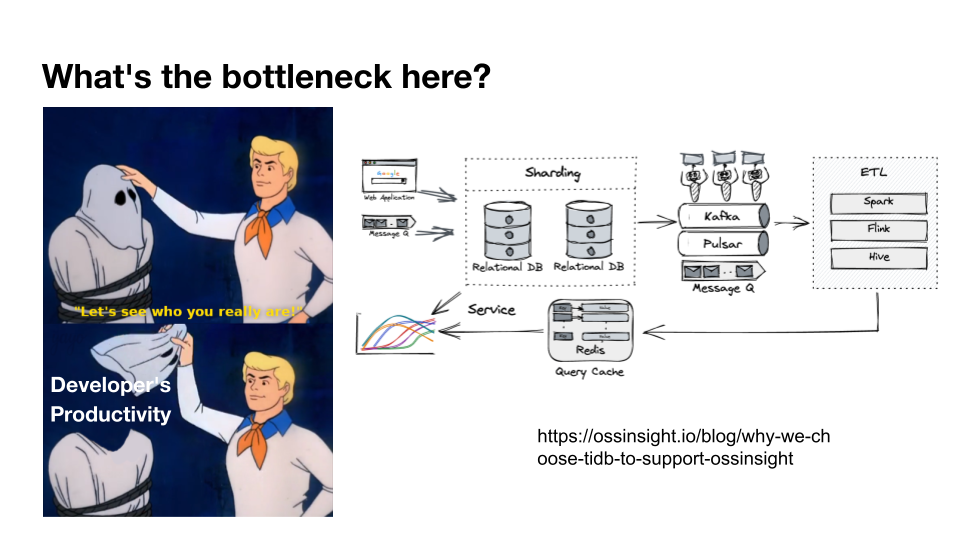\n\nOSS Insight 是 PingCAP 自己开发的一个很好玩的 GitHub 数据分析工具,它抓取了 GitHub 上所有的信息和实时的数据,提供一些数据的洞察服务。这样一个看起来很简单、很有意思的小应用,**如果用传统的思路去构建系统,你就会发现要用一大堆不同的技术栈串联在一起才能实现,并且每一个技术栈还有着自身复杂的运维成本**。\n\n过去 20 年我们发明了太多的技术,太多不同的 Database,每一种 Database 都有着自己复杂的概念与运维。作为一个开发者,要想把它用好,就需要把这些东西都学习一遍。业界有一句特别真实的笑话:别发布了,别做新的东西了,我真的学不动了……**这些复杂的概念现在都没有被隐藏起来,反而全都透传给了开发者**。举一个简单的例子,如果你想在云上选择机型,就会发现不同的公有云厂商会有好多机型推荐给你,如 i3.xlarge、i3.2xlarge、i3.4xlarge 等等,这些机型代号背后到底意味着什么?这都是系统架构的复杂性。\n\n更不要说背后的成本,**如果你在云上选错了机型或者选错了服务,就会发现最后的账单和你选了正确的机型或者服务有着天壤之别**。最近很火的 FinOps,说白了就是如何科学地利用云去省钱。这意味着什么呢?意味着就连计费方式以及筛选的策略对于用户来说都是非常复杂的事情,复杂到需要用另外一套工具来去做优化,以帮助用户作出正确的决策。\n\n\n\n**我们再往前看一下,今天的开发者到底是怎么去思考开发应用的?**这里我想分享一个最近特别喜欢的公司——Vercel,是一个非常偏向于开发者开发流程和体验的平台,在它的首页有三个英文单词:Develop(开发)、Preview(预览)和 Ship(上线),这其实就是一个开发者的视角。用过的同学就会知道,在 Vercel 这个平台上,一个应用开发者只需要关注网站怎么做,只需要去写 code。其他的事情,包括发布、部署、CDN、流量全都由 Vercel 帮忙封装好了,开发者只需要将 100% 的时间都放在业务逻辑开发上就可以了。这是一个很好的方向,这意味着应用的开发门槛在降低。**未来,应用开发者对数据库的关注点会从数据库变成 API,甚至在更长远的的未来只需要关注 web 前端开发就好了**。\n\n## 用“抽象”解决复杂性\n\n综上所述,从开发者的角度,或者新一代开发框架的角度来说,开发门槛正在变得越来越低,应用开发者变得越来越多,那数据库、数据技术、数据处理技术栈,怎么解决复杂性带来的矛盾呢?\n\n我觉得解决这个问题的思路可以用一个词来描述——**Abstraction(抽象)**。为什么抽象如此重要?抽象怎么帮我们解决问题?\n\n对于基础软件或者软件开发来说,概念的抽象程度提高,会带来什么样的结果?**第一,架构的复杂性会变得越来越低**。我们想象一下云,原来没有云的情况下你可能还要去考虑一下硬件、网络、磁盘、存储、数据中心的租赁,但有云了之后架构本身的复杂性是降低的,你不需要了解这么多东西,因为云底下的东西已经被隐藏掉了。这意味着作为一个开发者来说,他的心智负担在降低。就像用 Vercel 开发应用的时候你不需要关注 CDN,Vercel 已经解决了 CDN 的问题。心智负担降低意味着开发者能更快地开发出应用,能花更多的时间专注于业务创新,这就是商业的迭代速度。所以为了解决刚才说的矛盾,我们在数据技术上应该进一步去做抽象。\n\n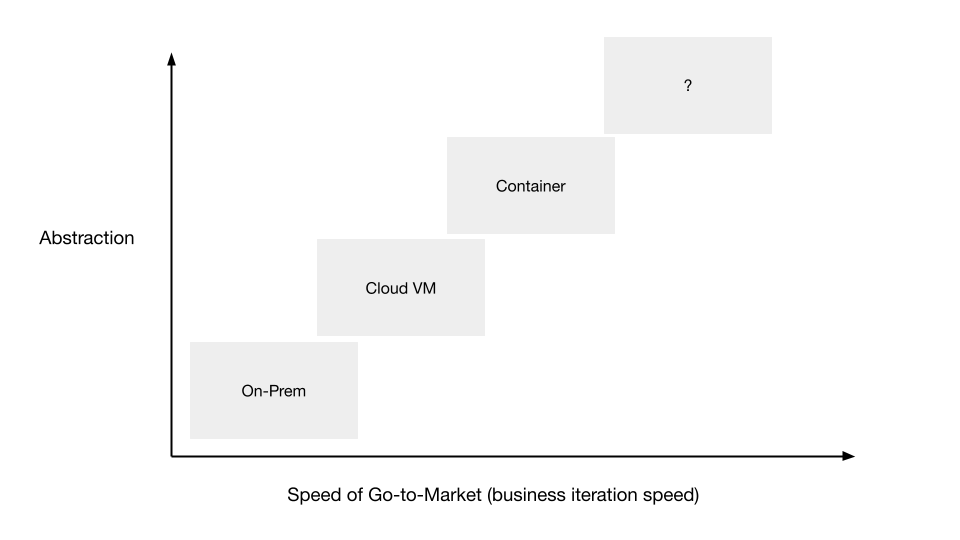\n\n在聊数据库的 Abstraction 前,我们可以看另外一个例子——**计算能力的抽象**。上面这个二维图示中,竖轴是技术的抽象程度,横轴是商业创新的迭代速度(Go-to-Market Speed),我们用它来看一下刚刚这个理论是不是成立。\n\n图中左下角是 On-Prem,意味着 20 年前要做一个网站,还要关心买服务器、租机房、网络租用等,抽象程度很低,**开发者要花大量时间在这些与业务无关的事情上,这也就意味着迭代速度是慢的**。\n\n后来人们是怎么解决的?**公有云的概念出现了,把刚才那些复杂的硬件、部署、网络等数据中心的复杂性抽象掉了**。你拿到就是一台机器,它到底是不是真实的机器你不用关心。这时,你要再开发一个应用,只需要在公有云上开个账号,把应用部署上去,按月给钱就行了。这比起自己去折腾数据中心来说,迭代速度又快了一步。\n\n**再往上看,云原生的概念出现了**。云原生的核心计算单元是 Container,Container 是更高层次的抽象。在虚拟机时代,你依然要去考虑 VM 挂了怎么办,但是在 Container 世界里,Container 以及底下云的调度器都不用你管,意味着迭代速度更快。\n\n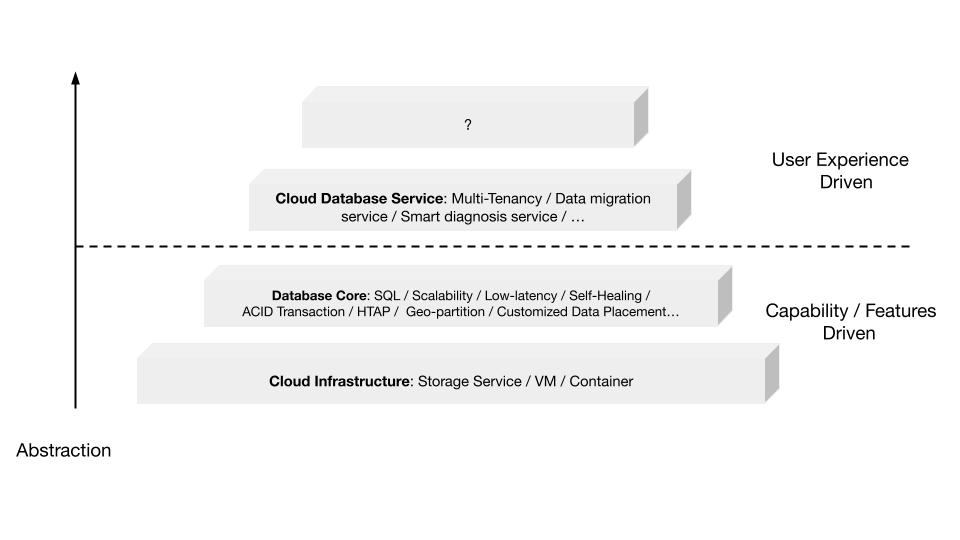\n\n在数据库的世界里“抽象”是如何去体现的?**抽象程度最低的是云本身的基础设施**,比如你要在云上私有化部署一个数据库,你需要自己去维护 MySQL 或者 VM。这时候你看到的是云的基础设施,它的抽象程度很低。**再往上一层,比如 PingCAP 几年前要基于云提供的基础设施如虚拟机、S3、容器,去开发出一个叫 TiDB 的数据库**。TiDB 提供了 SQL 能力,Scalability 能力,以及低延迟、高可用、分布式事务、HTAP、Geo-partition 等等一大堆数据库内核层面的能力。在这个阶段已经有很多用户说,“哇,TiDB 挺好用的”。\n\n**过去一年中,PingCAP 一直在把这个数据库技术变成一个数据库的云服务,也就是我们在做的 TiDB Cloud**。技术和服务的区别是什么呢?TiDB 技术本身就像一辆车里的发动机,或者一个火箭里的引擎。但是一个发动机跟一辆车肯定不一样,尤其在云上。对于一个在云上想要使用数据库服务的用户来说,他需要数据的导入、数据的导出、备份、智能诊断、多租户各种各样周边的东西,**把它们拼装在一起才是一个服务,而不是给用户一个发动机让你自己拼出一辆车**。\n\n这张图里有一条虚线,虚线之下作为一个数据库开发者或者一个数据库厂商来说,关注点其实是能力或者 feature ,就好比说发动机是不是稳定、是不是快、是不是省油,这些是能力驱动为主的一个抓手,但是在这条虚线之上整个驱动力会变成怎么去提升用户体验。你想要提供服务,就要从用户使用服务的全生命周期去考虑。比如他刚进来注册的环节、绑定信用卡的环节、数据导入的环节、使用、调优、备份的环节,同步到其他数据源的环节,每一个环节都要去考虑,这里面考虑的点就是用户体验,**用户体验是指引这个产品做得更好用的方向**。\n\n## 下一级别的“抽象”是什么?\n\n**“抽象”再往前一步是什么?我们给出的答案是“Serverless”**。一个月前 PingCAP 已经发布了 TiDB 的 Serverless 云服务。如果刚才那个理论是 OK 的,“抽象程度越高,开发的效率越高”,**Serverless 就会变成在云原生之后新的“抽象”**。对于数据库来说 Serverless HTAP 是一个更高级别的“抽象”,它意味着更高的开发效率。\n\n可能大家第一次听到 Serverless HTAP ,这到底是什么东西?意味着什么?\n\n\n\n第一,想象一下如果有这么一个数据库,它的**启动或者创建,你不需要关心任何部署细节**,也不用管有几个节点,而且它是召之即来,挥之即去的,几十秒之内就能准备好,一键就能创建出来;\n\n第二,这个系统虽然看不见底下的基础设施,但是它会**跟着业务的负载变化而自动匹配**。比如说你的吞吐大到一定程度,不用再停下来加服务器,系统会自动进行扩展。当你的业务峰值降下来了,比如说双十一过后业务流量下来了,这个系统还能够自动地缩回来,甚至缩到 0。能缩到 0 其实很重要,在没有业务负载的情况下,系统能变成 0 意味着系统不再收钱,而且当有业务流量再过来的时候它也能在很短的时间内又恢复提供服务;\n\n第三,**HTAP Database**。提供了一栈式的 SQL 能力,这是 HTAP 本身的能力;\n\n第四,**Pay-as-you-go**。有的人可能会说公有云不是也是 Pay-as-you-go 吗?Serverless 跟云有什么区别?我觉得二者当然都是 Pay-as-you-go,但是能不能以一个更细的粒度去提供 Pay-as-you-go 的能力?过去我们其实还是按照服务器、虚拟机这样的资源来去看待一个月多少钱,这个服务能不能粒度更细一些,只收业务流量的钱?尤其是对于偏分析的场景来说,有很多时候我们做大数据分析,比如每天半夜要去跑个报表,可能需要一千个虚拟机算,20 秒钟算完,然后再缩回来。每天可能就凌晨需要这么多 OLAP 的服务器,但是我不可能白天也买这么多服务器,就为了晚上算那一下,能不能更细粒度的 Pay-as-you-go,只算 20 秒的钱非常重要。\n\n第五,也是长期以来被各种硬核数据库开发商忽略的一点,但未来会越来越重要,**一个 Serverless 的 HTAP Database 一定要跟现代的开发者开发应用的过程体验深度整合**。举个例子,比如我们在笔记本上开发应用,现在如果有一个召之即来、挥之即去的数据库,我的开发体验其实是贯穿于整个开发流程里的。所以,过去我们其实一直在把数据库与开发者分开来看。数据库关注性能、稳定性,各种各样特别硬核的跑分,但是未来将是从开发者的角度考虑如何去使用数据库,让这个数据库帮助开发者更快、更流畅地构建应用。我觉得对于 Serverless 数据库来说,很重要的一个课题是从用户角度看,它应该融入到每天的、现代的开发体验中。\n\n## TiDB Serverless Tier\n\n\n\n听起来很美好,Does it even possible?**经过大半年的时间,我们终于把这个东西的第一个原型做出来了,并在 11 月 1 号上线公测,这就是刚才说的 [TiDB Serverless Tier](https://tidbcloud.com/free-trial)**。\n\n我自己写了一个小程序,在一个全新的环境下,通过代码启动一个 TiDB 的 Serverless Tier 实例。在这个过程里,我只是告诉这个程序,要启动一个集群,这个集群叫什么名字,然后把密码一输,20 秒之后可以直接拿一个 MySQL 客户端连上去了,这个时间未来会进一步缩短。想象一下,如果缩短到三五秒钟,这会极大地改变开发应用的使用流程和体验。而且你不用关心它的扩展性,即使上线以后,业务流量变得巨大无比的时候,它也能够很好地扩容上去,没有流量的时候,它还能缩回来。\n\n\n\n当然它背后其实有很多很多的技术细节,本文我们就不一一细说了。其中我们有一个原则,就是怎么利用好云提供的不同的服务,比如 Spot Instances、S3、EBS、弹性的 Load Balancer。TiDB 的 Serverless Tier 背后对于云上所有的弹性资源都进行了很好的整合,以及巧妙的调度,提供了一个极致弹性的用户体验。这个用户体验比原来的云原生数据库更往前跨越了一步,细节更少,抽象程度更高。\n\n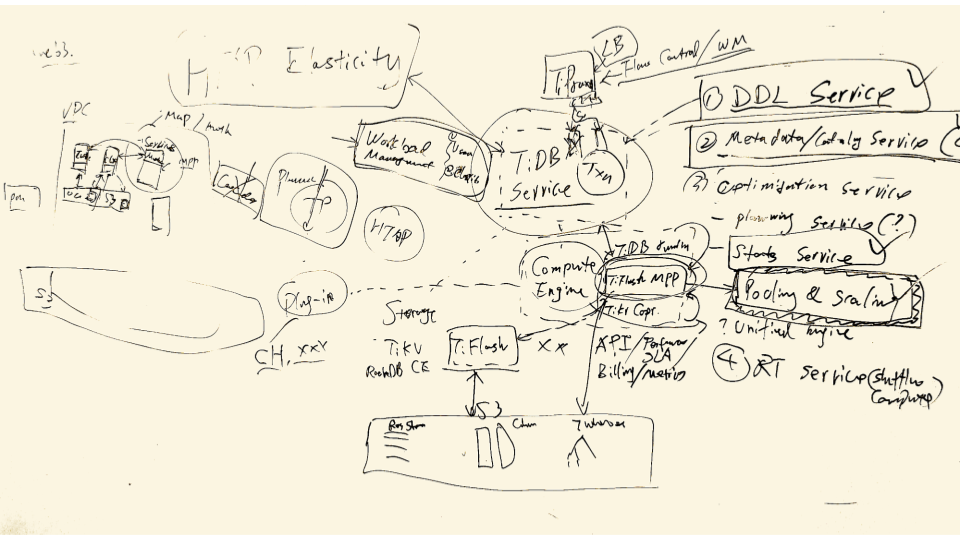\n\n这是系统的设计图,就不展开太多了,给大家展示一下这个东西还是挺厉害的。\n\n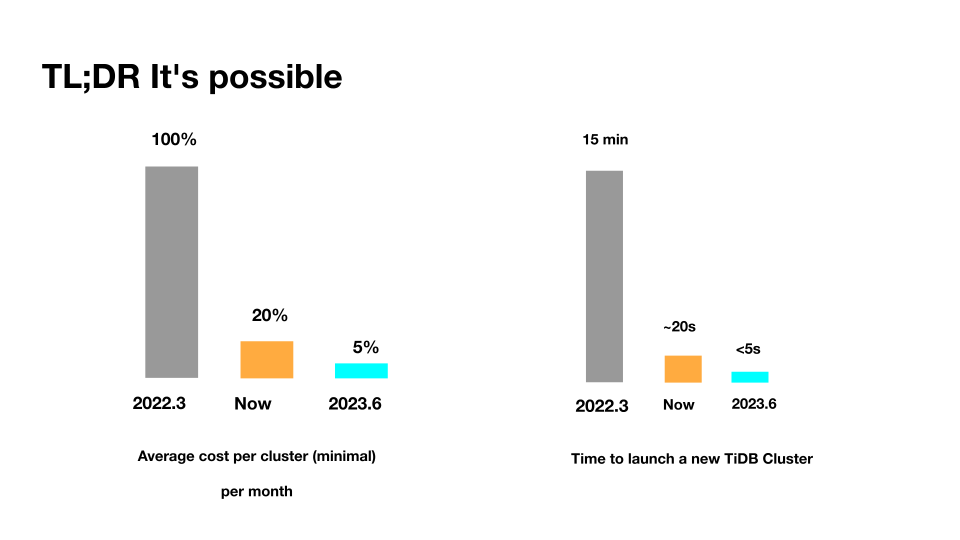\n\n所以,**TL;DR 是存在的,也是有可能被做出来的**。当 TiDB Serverless Tier 上线以后,我们发现它一上线就把整个 TiDB 在云上的 cost 降低了。拿最小集群来说,现在对比今年年初,成本降低到 1/5。而且在可见的未来,这个成本会变得更低;第二就是启动的时间,在今年 3 月份的时候,在云上启动一个新的 TiDB 集群需要 15 分钟,如果自己部署时间可能更长。现在只要 20 秒钟,不远的未来这个时间会缩短到更短。\n\n## 云端 Serverless HTAP 数据库服务,意味着什么?\n\n\n\n第一,**我们一开始花了很长时间去构建了一个稳定的数据库内核**,可以弹性扩展、自动 Failover、ACID Transaction 等非常硬核的基础能力。但这些都是基础能力,这些东西应该隐藏在发动机里。作为一个开车的人,不用关心变速箱里有哪些特性;\n\n第二,**HTAP 能够提供实时的一栈式数据服务**。用户不需要关心什么是 OLAP,什么是 OLTP。一套系统可以支撑所有负载,也不用担心 OLAP 负载影响 OLTP 的正常服务;\n\n第三,基础设施层面,**Serverless 部署的成本变得极低,极致的 Serverless 不用关心任何运维的细节**。你可以通过代码和 open API 控制这些集群的起停。在拥有更大规模的基础设施时,这点是非常重要的。Serverless 在处理更复杂或更大系统的时候,能显著减低复杂性;\n\n第四,**真正的按需计费**。Serverless 能够真正按照资源的消耗量来去计费。对于开发者来说,想用数据库的时候,只要招手它就来,不用的时候,也不用给钱,任何时候去访问它,数据都在那儿,也能对外提供服务。\n\n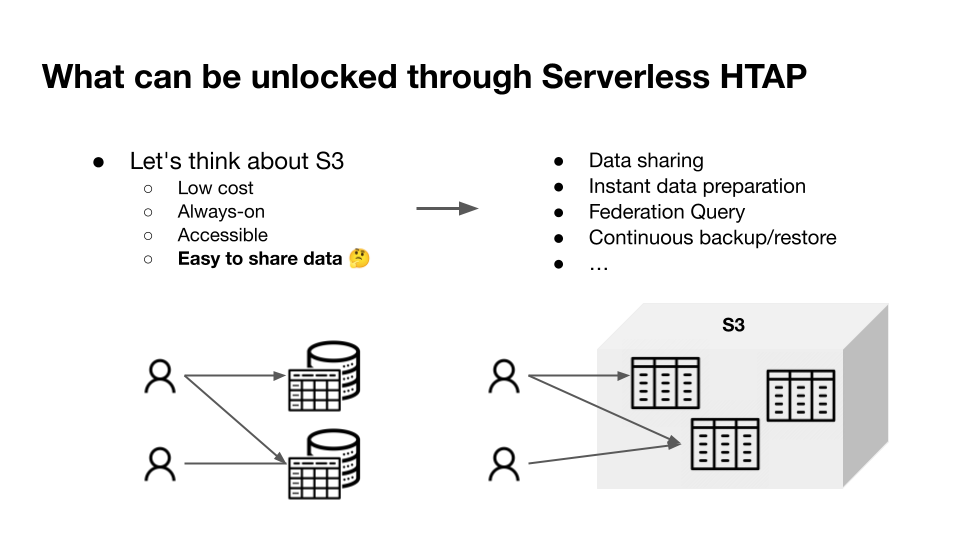\n\n**在这样的 Serverless 架构下,我们其实还能解锁更多的能力、更多的可能性**。\n\n举个例子,S3 是 TiDB Serverless Tier 底下重度依赖的云对象存储服务。用过 S3 的肯定都知道它便宜,可用性很高。更重要的一点是数据共享,比如大家都在用 AWS,A 用户用 S3,B 用户部分数据也在 S3 上,比如说我想把我的数据共享给另外一个用户的时候,既然都在 S3 上,那共享就变得很简单。以前在私有环境下,你还需要把数据下载出来拷给他,再上传进去,然后才能做分析。如果是在数据量比较大的情况下,这几乎是不可想象的。这种新架构的**一种可能性就是真正能够做到 Data Sharing**,当然这里面肯定还涉及到包括隐私计算,各种各样的安全性问题。但从技术底层来说,这种产品形态并非不可能了。\n\n另一种场景,比如说我想做一个区块链的数据分析应用,但做这样的应用,第一步你得把数据准备好。区块链的数据其实也不小,经常是大几百 GB 或几个 TB 的数据。但如果在 S3 上有一个公共的数据集已经准备好了,那**在云上 Serverless 用户只需要在启动的时候,加载这部分数据就好了**。这些能力在云下是根本不可能完成的任务。\n\n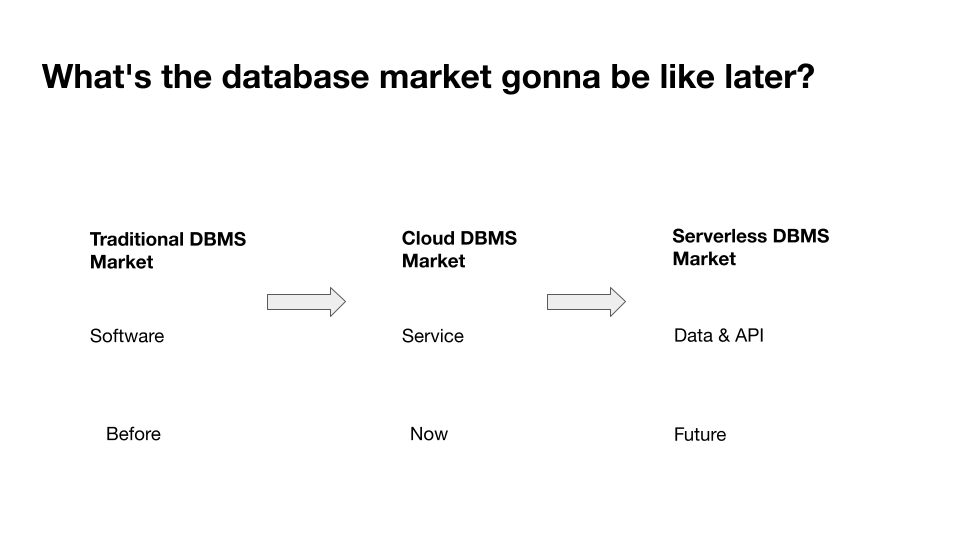\n\n这些能力具备后,数据库的商业模式会变成什么样子?在去年的 DevCon 上,我提出了一个猜想,“数据库作为一个软件形态本身会消亡,而数据库的平台化、微服务化会取代原来的数据库软件形式”。这个理论正在变成现实,今天,我们可以看到几乎所有的数据库厂商,都在云上提供服务。\n\n## 更进一步\n\n未来再往前一步,会发展成什么样子?\n\n**Serverless 其实是云上 Database Service 更进一步产品形态的体现**。现在我可能还需要去关注买多少个数据库节点,买多少个集群,但是在未来,真正从开发者的角度来说,他所关心的应该只有数据操作的 API ,这一层才是离业务更近的东西。另一方面,**当 Serverless 在云上被提供后,数据共享、交换就变成了一个很自然或者很简单的事情,那时候我觉得会出现一个叫做 Data market 的新商业模式**。\n\n记得我在上大学学数据库课程的时候,我的老师告诉我,这个东西很简单,你只要会写 SQL 就 OK 了。但我工作以后,发现还有 OLTP、OLAP、时序数据库、图数据库,以及各种各样稀奇古怪的数据库,你得学习一大堆东西,这些东西里面有无数的细节。\n\n**我们想把它做得很简单,把开发者的体验带回从前**。数据库本来就应该是很简单的东西,我们应该花更多的时间关注于业务的创新、关注于真正重要的事情,这些复杂的东西,就让它简单起来好了。\n\n未来真正重要的东西是什么?**是流畅的开发体验。这就是我们终极的前进方向**,也是作为一个基础软件提供商的担当。虽然前面说了这么多很技术的东西,但其实 Serverless 很简单,现在它已经变得触手可及,大家可以通过 TiDB Cloud 就可以立刻体验它。","author":"黄东旭","category":2,"customUrl":"frictionless-developer-experience-with-the-serverless-htap-database","fillInMethod":"writeDirectly","id":440,"summary":"12 月 1 日,以\"去发现,去挑战\"为主题的 PingCAP DevCon 2022 主论坛在线上成功举办,为数万观众带来一场技术盛宴。PingCAP 联合创始人兼 CTO 黄东旭,在大会上分享了 “The Future of Database”的主题演讲,分享了他对云原生、开发者生产力的理解,介绍了 Serverless HTAP 的意义以及未来的”技术无感化“发展方向。","tags":["HTAP","Serverless"],"title":"黄东旭:开发者的“技术无感化”时代,从 Serverless HTAP 数据库开始 | PingCAP DevCon 2022"}},{"relatedBlog":{"body":"> 本文基于 TiDB Cloud 生态服务团队负责人张翔在 PingCAP DevCon 2022 的演讲内容整理而成。\n\n\n数据库不是单一软件,而是一个生态体系。成为一款好用的数据库,除了产品自身的能力外,繁荣的技术生态体系也至关重要,既可以提升使用体验,又可以降低使用门槛。\n\nPingCAP 在 2022 年 11 月 1 日正式发布了 TiDB Cloud Serverless Tier,本次分享在介绍 Serverless Tier 的技术细节之余,全面解析 TiDB 的技术生态全景和在生态构建中所做的努力。阅读本文,了解有关 Serverless 的更多信息,以及 PingCAP 在技术领域的最新进展。 \n\n## 云时代开发者面临的机遇和挑战\n\n现在云已经不再是一个新鲜的事物,我们已经处在云的时代,与之前相比,云时代的开发者面临着与之前不同的机遇和挑战。在云时代,我们有着新的技术设施,我这里举几个例子,每个云厂商都会提供块存储服务、对象存储服务和弹性计算服务。块存储服务有高吞吐、低时延和高持久的特性。对象存储服务,比如 AWS 的 S3、国内阿里云的 OSS,提供了低成本的海量存储空间,并且这些存储还有着超高的可用性,甚至可以跨地域复制来进行容灾。而弹性计算服务,可以给我们提供多种规格的计算实力,而且还提供了不同的计费模式,当然,根据用户的诉求进行弹性伸缩,也是一个基本的能力。\n\n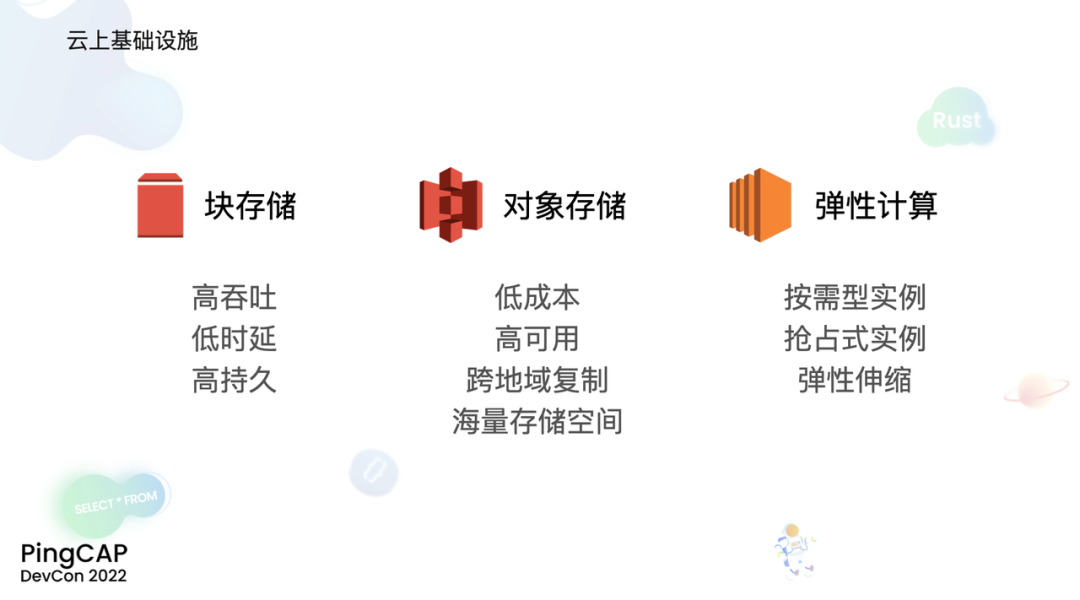\n\n有了新的基础设施,当然也有新的挑战。云厂商给我们提供了许多的云服务,并且云的初衷之一,就是让使用者可以减少很多的运维工作。但是如果你现在深度地使用云,仍然需要运维大量的云上基础设施。这些运维工作使得我们开发者的精力被分散,没法完全专注于业务本身。除了运维工作之外,如何使用好云也是一门学问,前不久我刚刚参加了 AWS 的架构师培训,其实如何多快好省地用好云,不是一件简单的事儿。云服务的使用者,很容易就会造成云上资源的浪费,产生不必要的高额费用,特别是在现在许多的云服务,仍然是按时间来收费的情况下。对于有多套环境需求的场景,比如说公司内部有多个团队,不同的业务有各自的环境诉求,或者在 CICD 的场景下,我们可能会有 preview、stage、product 的多套环境需求,购买多套的云服务会产生高额的费用,但是共享一套云服务则可能会产生资源的竞争,甚至出现测试环境影响生产业务的情况。云上的服务,比如说云上的数据库服务,现在的使用方式仍然是提前规划容量,然后始终按照购买的时候的容量进行工作和计费,如果后期需要调整,仍然需要人工介入,手动去进行扩缩容。\n\n\n\n这个是我们目前在使用云的时候,遇到的一些挑战。那么为了解决这些挑战,PingCAP 推出了 TiDB Cloud Serverless Tier。Serverless Tier 是世界上首款的 Serverless HTAP 数据库,PingCAP 推出它,希望能够帮助开发者解决刚才所说的那些挑战,成为云时代的新的 HTAP 数据库解决方案。TiDB Cloud Serverless Tier 目前是一个 Beta 的状态。下面,我就给大家介绍一下 TiDB Cloud Serverless Tier。\n\n## TiDB Cloud Serverless Tier(Beta) 世界上首款 Serverless HTAP 数据库\n\n当然在之前,我们还是先来看一下传统的TiDB集群。这是一个经典的 TiDB 集群架构,可以看到这是一个非常典型的分层架构,计算层是 TiDB Server,每个 TiDB Server 都是一个无状态的计算节点,可以非常容易的进行横向扩容,存储层是 TiKV 和 TiFlash。TiKV 是我们的分布式行存储引擎,TiFlash 是列存储引擎,整个存储层通过分布式协议实现了一致分布式存储。在计算层和存储层之外,我们还有一个调度单元 PD,这里存储了整个 TiDB 集群的元信息。在这样的一个架构下面, TiDB 已经有了很好的表现。比如 TiDB 有着非常好的扩展性,无论是计算还是存储,能力都可以随节点数线性扩展。\n\n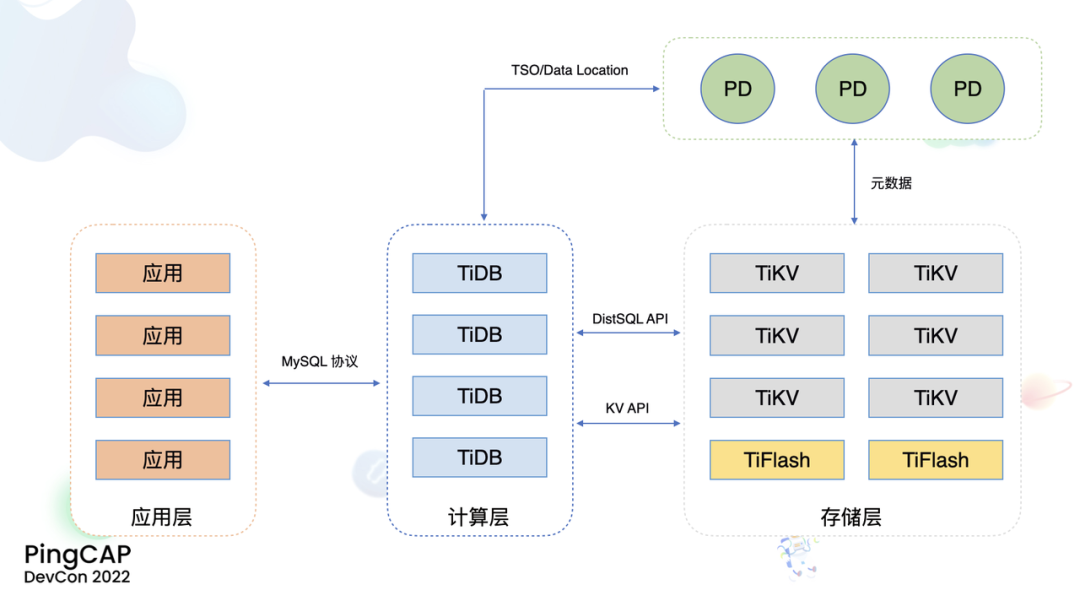\n\nTiDB 已经在生产场景经历了数百 TB 规模的数据和百万级 QPS 的流量的考验。TiDB 还有着非常好的弹性,系统规模可以随着业务的需求进行伸缩。而且伸缩是完全在线进行的,不会影响已有的数据和请求。同时,对于系统中的热点,TiDB 也有能力自动发现,自动调度。TiDB 也有着非常好的容灾和高可用的能力,如果节点出现故障,上面的数据可以自动的进行转移,并且配合 PingCAP 推出的 TiCDC 工具,还能够做到实时的 CDC 同步,实现异地容灾。\n\n\n\n但是这样的一个经典架构在云的时代,面对着完全不同的基础设施,存在一些问题。第一,share-nothing,刚才我们提到云厂商提供的基础设施,无论是块存储,还是对象存储,天然就有着高可用,高持久的特性,云厂商已经帮我们做了数据复制,但是 TiKV,TiDB 的存储层,仍然做的自己的数据复制。这在云上其实是多余的,数据的复制不仅仅是存储资源的浪费,同时还需要消耗大量的带宽,在云上,网络也是会造成非常高额的费用。第二,存储层状态重。这是因为每个存储节点,其实都存储着一些数据的副本,扩容转移一个故障节点都需要对这些副本进行同步,导致横向扩展的速度仍然不够快,也进一步导致难以利用云厂商提供的竞价实例,从而能够进一步的去降低成本。第三,TiDB 之前是一个非常经典的计算、存储、调度分离的架构。但是在云时代,这样划分的颗粒度仍然过大,每一个节点承担的责任过多,导致 TiDB 整体的弹性仍然不够,其实我们可以在云上,将更多的功能拆分出来形成单独的微服务,这些微服务可以独立的去进行扩容和部署,甚至这些微服务可以被多个集群去共享。如果拆分出更多的微服务,TiDB 集群整体的弹性会进一步上升。\n\n\n\n基于这些问题,其实 PingCAP 做了很多的努力,也都做了相应的改进,大家可以看到这是现在 TiDB Cloud Serverless Tier 的一个新架构。首先在存储层开发了 Cloud Storage Engine 一个新的存储引擎,图中 Shared Storage Layer 和 Shared Storage Pool 这两层组合起来就是新的 Cloud Storage Engine。现在新的存储引擎融合使用了云上的块存储和对象存储,并且消除了原来存储层冗余的数据复制,彻底的解决了之前所说的 share-nothing 和状态重的问题。这样的改造使得存储层的节点扩展非常容易,而且非常迅速,而且大幅度地降低了成本。\n\n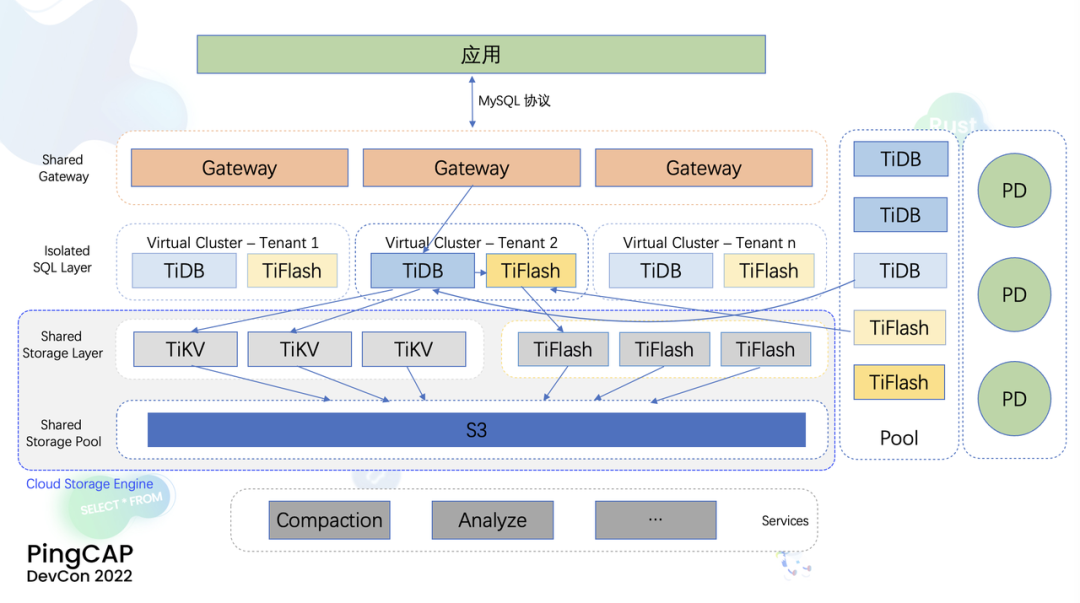\n\n在计算层我们进一步地拆分了 TiFlash,TiFlash 现在它的计算存储已经可以去分离,TiFlash 的计算部分可以像 TiDB Server 一样,作为一个独立的组件去进行管理,去扩容。第二,我们引入了新的一层,叫做 Gateway。Gateway 代替了 TiDB Server 与用户去进行交互,它负责诸如连接管理、唤醒节点,这样的功能。它的出现使得我们所说的多租户成为一个可能。第三,我们池化了计算节点,在图上右边的部分,有多个 TiDB 和 TiFlash。我们将计算节点进行了池化,这样的设计进一步降低了计算层的成本,以及提升了计算节点唤醒的速度。计算层和存储层的改动,使得 TiDB Cloud Serverless Tier 支持了多租户。现在一套 TiDB Cloud Serverless Tier 集群,可以支持多个租户,每个租户都是完全隔离的。在用户看来,他们拥有的就是一套独立的 TiDB 集群。\n\n最后,我们还拆分了一些相对独立的功能,做成微服务,比如数据压缩服务,降低了计算节点以及存储节点的复杂性,提升了 TiDB Cloud Serverless Tier 的整体的弹性,后续我们还会继续对更多的微服务进行拆分。\n\n\n\n做完相应的改进,新的架构解决了之前所说的传统架构在云上的问题,更好地适应了云上的基础设施。这边总结一下,一是推出了 Cloud Storage Engine,可以融合地使用块存储和对象存储,并且消除了多余的复制,解决了两类问题,一是冗余的复制,二是高额的网络费用。第二,拆分出了更多的微服务,更好地使用了云上的弹性算力。整体的改动使得 TiDB Cloud 可以支持多租户。\n\n技术上的努力使得 TiDB Cloud Serverless Tier 拥有了非常新颖的能力。TiDB Cloud Serverless Tier 拥有全部的 TiDB 的 HTAP 能力,是世界上第一款 Serverless HTAP 数据库。我们优化了 TiFlash 的架构,使其更好地适应了云上多租户的场景。从刚才介绍的 TiDB Cloud Serverless Tier 的架构上可以看到,我们对计算节点进行了池化,多租户也共享了存储。所以,TiDB Cloud Serverless Tier 目前可以做到秒级创建一个 TiDB 集群,并且如果你长时间不使用,再次连接的时候也仅需数百毫秒的时间就可以恢复完整的集群。这个操作对于用户来说,是完全透明的,用户甚至感知不到。未来,我们会进一步优化这个时间,集群创建时间会持续缩短,唤醒时间也会从数百毫秒缩短到数十毫秒。\n\n作为一款真正的 Serverless 云数据库,当然,TiDB Cloud Serverless Tier 是完全无需用户去运维的。在使用方式上,不需要像传统的云数据库那样,提前去规划容量,在需要的时候进行扩缩容,TiDB Cloud Serverless Tier 会根据流量自动地进行伸缩,无需任何手动的操作。具备了这么强大的能力,TiDB Cloud Serverless Tier 的计费方式也是真正的按使用量付费,用户只需要为自己真正使用的资源进行付费,不使用,即使这些集群仍然在运行当中,你也无需支付任何的费用,这也是 TiDB Cloud Serverless Tier 区别于传统云数据库甚至于其他 Serverless 数据库的不同之处,这些数据库即使你不使用,但只要集群被创建出来,仍然会按照创建时的规格进行收费,这其实会造成极大的资源浪费。\n\n同时 TiDB Cloud 是支持多云厂商的,Serverless Tier 也将会继承这一点。目前 TiDB Cloud Serverless Tier 仅支持在 AWS 上创建,但未来一定会支持更多的云厂商,同时 Serverless Tier 还支持多个区域,满足用户时延和数据存储区域选择的诉求。\n\n\n\n讲了这么多,接下来我们来展示一个 Demo,这个 Demo 就是我们从无到有来创建一个 TiDB Cloud Serverless Tier 集群,这个其实也是基本上是所有用户唯一需要与 TiDB Cloud Serverless Tier 打交道的一个动作,因为刚才我们说了,一旦创建之后其实你不需要去运维,你也不需要去进行手动扩缩容,TiDB Cloud Serverless Tier 会根据你的流量自动进行扩缩容,我们开始看一下集群创建的过程。\n\n\nDemo 视频\n\n我们只需要点击创建,如果你需要可以选择名字以及供应商以及 region,这里我们都是使用默认的。然后就进入了创建的一个过程,可以看到大概在 20 秒的时候整个集群其实就已经从 creating 的状态变成了 avaliable 的状态,TiDB Cloud Serverless Tier 现在整个创建时间大概就是在 20 秒左右,可能会上下有一定波动,基本是在这样一个量级。只需要 20 秒你就可以拥有一个完全工作的 HTAP 云数据库,并且后续不需要你进行任何操作以及与它有任何运维上的交互。\n\n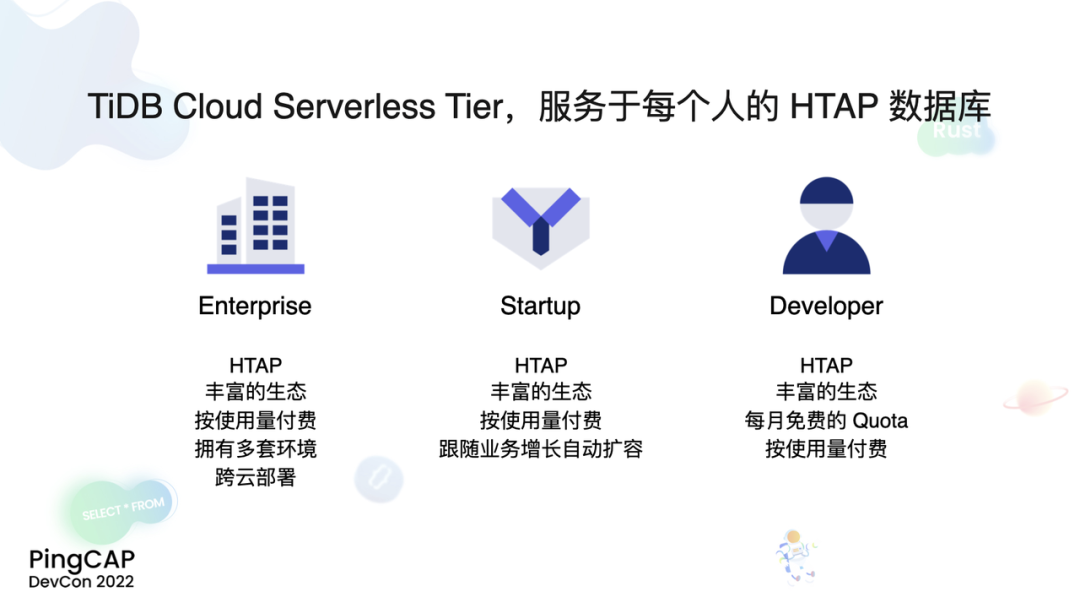\n\n希望经过我们的努力,TiDB Cloud Serverless Tier 可以成为一个服务于每个人的 HTAP 数据库,TiDB Cloud Serverless Tier 现在拥有了完整的 HTAP 能力,可以处理复杂的工作负载,并且真正地按使用量付费,对于任何人都只需要为自己使用的计算资源和存储资源付费,不存在资源浪费的情况,具有非常高的性价比。对于个人开发者,TiDB Cloud Serverless Tier 每个月其实都提供了一定量免费的 Quota,只要不超过这个 Quota,对于个人开发者而言,TiDB Cloud Serverless Tier 就是一个完全免费的触手可及的 HTAP 数据库,对于 Startup 来说,TiDB Cloud Serverless Tier 可以跟随业务增长自动进行扩容,而且这个扩容完全是自动的,不需要手动介入。Startup 可以专注于他的业务本身去发展自己的业务,不需要为数据基础设施去操心。对于大公司而言,因为 TiDB Cloud Serverless Tier 超高的性价比以及非常迅速的创建恢复时间,使得云上资源不再成为一个限制,每个部门、每个环境都可以拥有自己独立的数据库,未来我们还会推出 data branching 更好地帮助企业客户,当然如果公司有跨云部署的诉求,TiDB Cloud Serverless Tier 也是一个非常完美的选择。\n\n## 数据库不是单一软件,而是一个生态体系,除了产品自身的能力,繁荣的技术生态体系也至关重要\n\n当然,对于任何一个数据库的使用者不可能仅仅与数据库软件本身打交道,同时需要使用大量的数据库生态软件,TiDB Cloud Serverless Tier 拥有非常丰富的生态,接下来我们就来看一下 TiDB 的生态。数据库不是单一软件,而是一个生态体系,除了产品自身的能力,繁荣的技术生态体系也至关重要。TiDB 从出生起就非常重视生态,所以选择了与 MySQL 兼容,并且在这个上面做了许多努力。\n\n因为 TiDB 是 100% 兼容 MySQL 协议的,所以 TiDB 与所有的主流语言都是兼容的,比如 Go、Ruby、Java 、Python、JavaScript 等等,还有更多。TiDB 兼容的远远不只这些语言,这里列了一些比较流行的语言,只要一个语言拥有 MySQL driver,它就可以使用 TiDB,使用 TiDB Cloud Serverless Tier,不管这个语言多么小众。\n\n\n\n在语言之上,TiDB 还与基本上所有的流行的 ORM 框架兼容,与语言的 driver 不同,除了协议层的兼容之外,ORM 往往在功能上对 MySQL 的兼容性有着更高的要求,TiDB 的一些扩展能力也需要去进行补齐。TiDB 在这个方面做了很多努力,首先针对一些 ORM 开发了自己的插件,比如对于 django 和HIBERNATE,我们开发了django-tidb 和 hibernate-tidb 插件。TiDB 也在产品本身的 MySQL 兼容性的能力上做了很多增强,比如,可能在应用中我们可以不用,但是对于许多 ORM 框架都非常重要的两个功能 savepoint 和外键。这两个功能对于很多的 ORM 框架来说都非常重要,很多 ORM 框架对他的依赖都非常重。在最近两个 TiDB 的版本中发布了savepoint 功能和实验版本的外键功能,这使得 TiDB 进一步提升了与许多 ORM 框架的兼容性。\n\n\n\n除了语言的 driver 和 ORM 框架之外,TiDB 以及 TiDB Cloud 还可以集成许多流行的平台,我们这里罗列了一些主要的,比如在数据处理领域,TiDB 可以与 Spark、Flink、Databricks 这些流行的大数据处理框架以及平台结合使用,来构建企业的 ETL pipeline,形成统一的数据处理平台。同时除了传统的 ELT 平台,TiDB 还可以与海外非常流行的 modern data stack 体系进行集成,我们给 Airbyte 贡献了 tidb-source-connector 和 tidb-destination-connector,开发了 dbt-tidb adapter,使得 TiDB、TiDB cloud 可以完美地与 Airbyte、dbt 进行集成。\n\n当然 TiDB 还支持类似于 Metabase 这样的 BI 平台,分析 TiDB 中存储的数据。在 CDC 的领域 TiCDC 支持了 avro 格式以及 kafka sink,使得 TiCDC 可以支持将数据导出到 confluent 平台,同时我们还测试了与 arcion 平台的兼容性,可以使用 arcion 平台来做 TiDB 或者 TiDB Cloud 的 CDC。\n\n\n\nTiDB 和 TiDB Cloud 很早就支持了使用 prometheus 和 grafana 作为监控平台,我们还支持将监控的 metrics 导出到 datadog 平台,还可以实现与 Serverless 部署平台 Vercel、Netlify 的集成,以及与 no-code workflow automation 平台,像 zapier、n8n 的集成,以及与 IaC 工具 Terraform 的集成等等。接下来深入到一些领域来仔细看下。\n\n首先来看 modern data stack 领域也就是我们所说的 ELT pipeline,注意,这里不是传统的 ETL pipeline,是 ELT pipeline。首先介绍一下 Airbyte 和 dbt,Airbyte 是一个 data pipeline 平台,它可以连接数百种数据源和数据汇,将数据源中的数据导出到数据汇中,然后在数据汇中对数据进行整理。基于此,用户可以通过 Airbyte 实现任意的数据迁移,它的口号就是 data from any source to any destination。dbt 是一个 data transformation 工具,借助 dbt 用户可以非常灵活地在数据库或者数据仓库中操作数据,进行数据变换。结合使用 Airbyte、dbt 和 TiDB Cloud,用户可以将任意数据源中的数据,比如在 salesforce 中的 CRM 数据,google sheets 中的表格数据,甚至是像 Instagram 这样 2C 应用中的企业运营数据导入到 TiDB Cloud 中。有了数据,我们可以利用 BI 工具进行数据分析,因为 TiDB 以及 TiDB Cloud Serverless Tier 是一个 HTAP 数据库,在面对分析型负载的时候,有着更好的表现。甚至,如果说用户有数据归档的诉求,可以继续将 TiDB 作为 Airbyte 的数据源,将数据导入到像 Snowflake、Databricks、Google Big Query 这样的数据仓库或者说数据湖中去。\n\n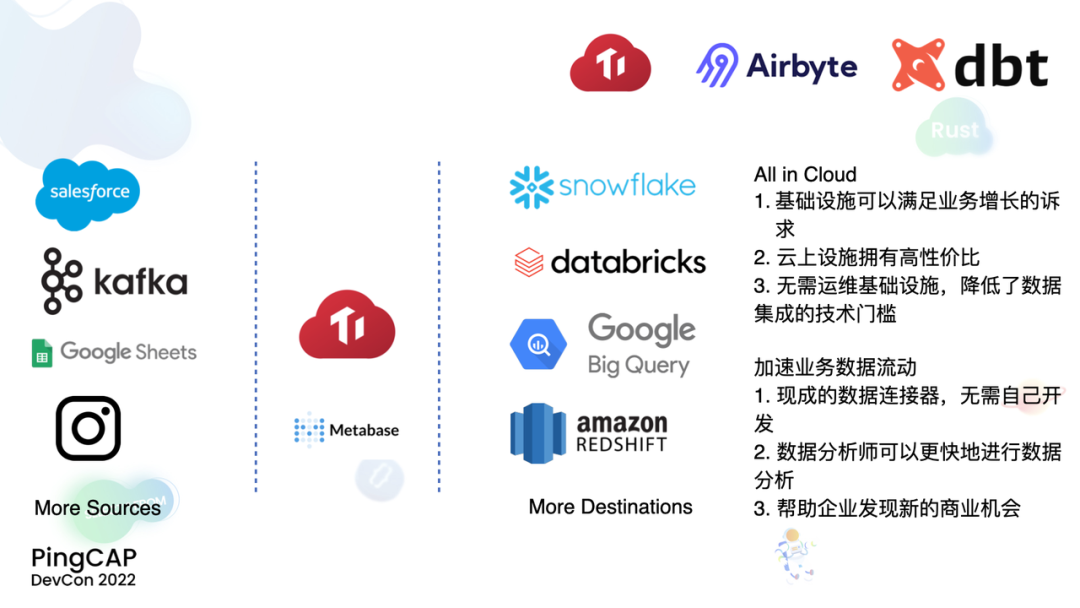\n\n总的来说,用户如果结合使用 TiDB Cloud、Airbyte 和 dbt 建立一条 ELT data pipeline,一是可以使自己的数据设施 all in Cloud,整条流水线都可以拥有非常好的弹性,可以满足业务增长的诉求。同时云上的基础设施拥有很高的性价比,可以降低数据基础设施的成本,而且因为 all in Cloud,你无需运维,降低了数据集成的技术、费用门槛。二是可以加速企业内业务数据的流动,Airbyte 拥有上百种的数据连接器,用户可以直接去使用,无需自己设计、开发,从而企业内的数据分析师可以更快地进行数据分析,帮助企业发现新的商业机会,而不是把精力浪费在基础设施的重复建设当中。\n\n接下来看 Vercel,Vercel 是海外领先的前端部署平台。使用 Vercel 开发者可以非常迅速地将自己的 web 应用进行部署、分发给全球的访问者,在这个过程当中 Vercel 还可以加入到开发者的 CICD 流程当中,使开发者可以轻松地预览效果。同时借助 Vercel 遍布全球的边端网络,访问者可以以极低的时延访问 web 应用,获得极佳的用户体验。\n\n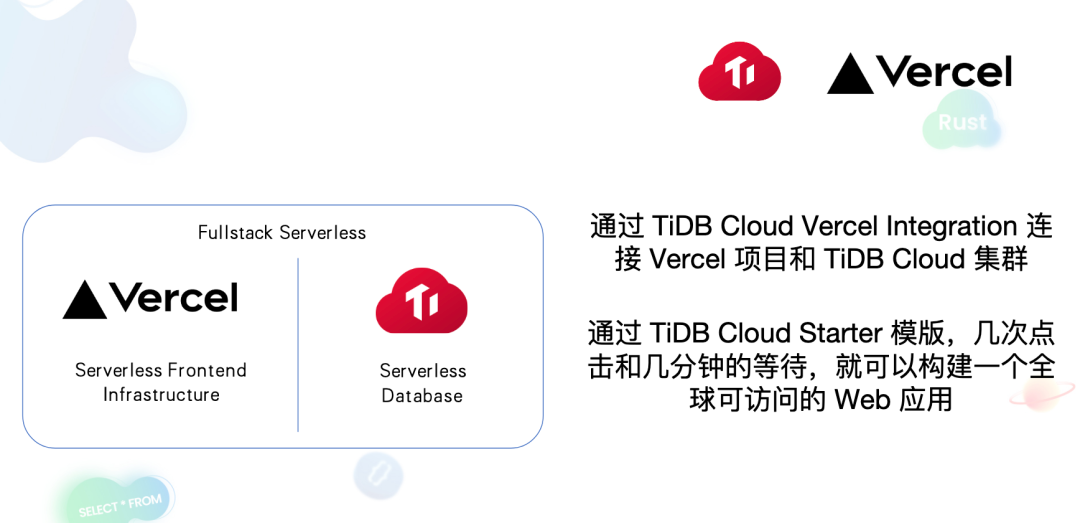\n\nVercel 本身作为一个 Serverless Frontend Infrastructure,它不具备持久化数据存储的能力,这也就意味着如果仅仅使用 Vercel 的能力,没办法去开发一个复杂的 web 应用。所以我们可以结合 Vercel 和TiDB Cloud Serverless Tier,从而获得一套完整的 web 开发的 Fullstack Serverless Infrastructure,和前面的 all in Cloud 的 data pipeline 一样,这套 Web App Develop Infrastructure 也是 all in Cloud,用户无需运维,基础设施可以自动扩展,并且具有很高的性价比。\n\n为了让用户更好地使用 Vercel 和 TiDB Cloud Serverless Tier,我们开发了 TiDB Cloud Vercel Integration ,你可以在 Vercel 的 Integration 市场中找到它,通过这个 integration,只需要简单的几次点击就可以连接 TiDB Cloud Serverless Tier 集群和 Vercel 项目。同时我们还开发了 TiDB Cloud Starter 模板,这个模板可以让用户通过几次点击和几分钟的等待,就从无到有地构建一个全球可访问的 web 应用。以下是一个简单的 demo 让大家来体验这套 Fullstack Serverless Infrastructure。\n\n\nVercel Demo 视频\n\n> 这是 Vercel 的 template 列表,先找到我们的 TiDB Cloud Starter 模板,进入模板的详情页,点击 deploy 进到一个流程页。首先因为这是一个模板,所以我们要基于这个模板来创建一个我们自己应用的代码仓库,这里选择 starter,你只要简单的一次点击就可以。 \n> 在这个过程当中集成了 TiDB Cloud Vercel Integration,这个页面就是 integration 的页面。这里选择我们想要的 Vercel 项目以及想要的 TiDB Cloud Serverless Tier 的集群,选择之后点击 integrate,这个 integrate 的过程就结束了。到这里我们需要操作的过程已经完全结束了,现在处在等待 Vercel 帮你构建项目以及部署项目的一个阶段。大家可以看到,创建我们自己的代码仓库点击了一次,进行 integrate 点击了大概一到两次,我们就完成了所有的操作。 \n> 接下来稍微等待一下,大家可以看到现在大概过了两分钟,整个部署和构建过程就完成了。我们到 Vercel 项目的详情页去点击 visit,可以看到这时候这里展示的页面就是通过模板构建出来的一个项目的主页,大家可以看到这上面的 URL 是一个所有人都可以访问的 URL,现在这个项目已经对全球可以访问了。任何人在地球上的任何角落现在都可以来访问 bookstore 这个项目,整个的耗时也就大概两三分钟。这个项目前端整个的代码应用逻辑是部署在 Vercel 的 Serverless 的架构上面,后端数据存储是存储在 TiDB Cloud Serverless Tier 集群中。 \n\n我们进入下一个生态 Terraform,Terraform 是业界默认的跨云 IaC 工具,使用 Terraform 可以使用代码来管理云基础设施,将它集成到我们的 CICD 流程当中,我们在前不久开发了 TiDB Cloud Terraform Provider,使得用户可以通过 Terraform 来管理 TiDB Cloud 的资源。像图上展示的,我们可以通过这样的一个 Terraform 文件来创建一个 TiDB Cloud Serverless Tier 集群。Terraform Core 会解析这个文件,将 TiDB Cloud 资源的相关定义都发给我们开发的 TiDB Cloud Terraform Provider,TiDB Cloud Provider 会调用 TiDB Cloud Go SDK 来操作 TiDB Cloud 的资源。PingCAP 已经和 HashiCorp 成为了技术合作伙伴,TiDB Cloud Terraform Provider 也已经是 HashiCorp 认证的 Partner Provider,欢迎大家使用 Terraform 来操作 TiDB Cloud 的资源。\n\n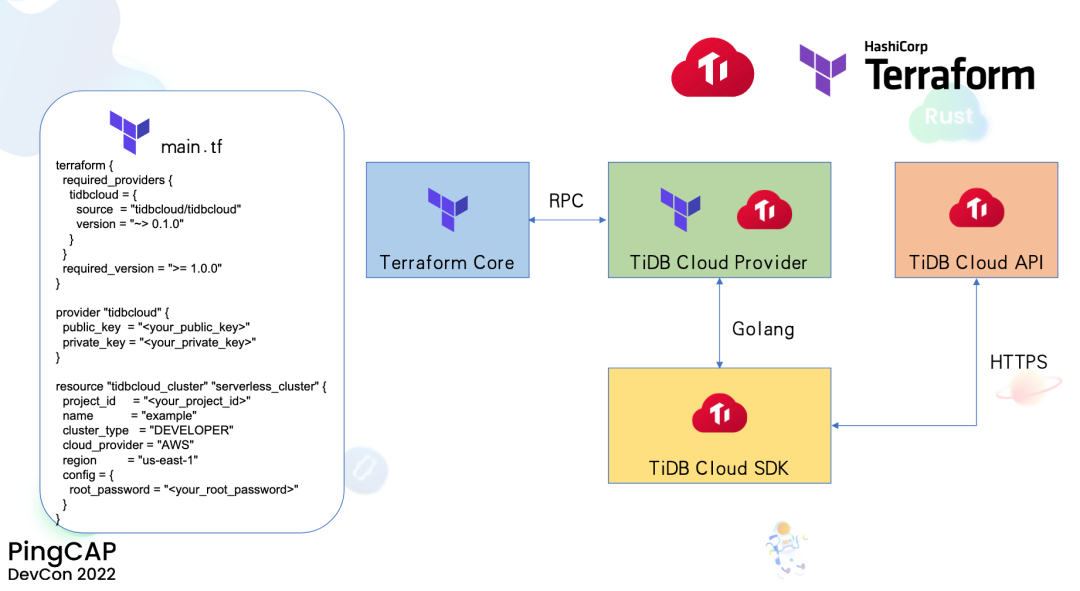\n\n## 展望未来\n\n最后,我们一起展望一下未来,TiDB Cloud Serverless Tier 才刚刚发布,我们仍然有很长的路要走。\n\n目前因为刚刚推出,Serverless Tier 还没有向用户开放诸如像备份、恢复、监控、报警这样的能力,我们很快就会添加这些能力并对用户进行开放。我们还会开发 PiTR 和 Branching 这些功能,方便用户进行数据共享,将数据库纳入CICD。我们还会进一步地去降低创建时间和成本,期望 Serverless Tier 集群的创建时间能从现在的 20 秒降低到 5 秒,唤醒时间从数百毫秒降低到数十毫秒。后续会推出 Data API,Data API 是通过 RESTful API 的形式提供数据库的 CRUD 能力,未来除了 RESTful 之外还可能推出 GraphQL API。通过 Data API 希望 Serverless Tier 可以更好地与 Serverless 生态结合,服务边缘请求。现在很多的 Serverless 的部署平台加速从中心化的托管能力向边缘进行扩张。当我们使用边缘的一些托管 runtime 是根本无法发出像传统的 TCP 请求的,所以 Data API 的推出可以让 Serverless Tier 更好地与这些平台进行结合。\n\n\n\n在生态方面,我们会进一步提升 MySQL 兼容性,对接更多平台,给用户提供更多选择。PingCAP 始终坚持开源开放的路线,TiDB 社区从诞生开始就开放并包,我们期望大家加入,共建 TiDB 的繁荣生态。","author":"张翔","category":1,"customUrl":"tidb-serverless-and-technology-ecology-overview","fillInMethod":"writeDirectly","id":466,"summary":"本次分享在介绍 Serverless Tier 的技术细节之余,全面解析了 TiDB 的技术生态全景和在生态构建中所做的努力。阅读本文,了解有关 Serverless 的更多信息,以及 PingCAP 在技术领域的最新进展。","tags":["TiDB","Serverless"],"title":"TiDB Serverless 和技术生态全景"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}