\n\n## 目前业界数据存储方案存在的问题?\n\n* 受限的 Scale 能力\n\n\t分库分表和一些「伪分库分表」的方案,仍然有天花板,带来了额外的运维和消耗。\n\n* 碎片化\n\n\t回想一下最近几年后端的技术栈,有 NoSQL、缓存、Kafka、 离线数据仓库、Hadoop、HBase……**不同的工具可能面对的是某些特定、甚至「狭窄」的场景,为了应对一个复杂的业务,大家必然就要多种技术方案组合来覆盖所有的应用场景。这个过程中自然会产生「数据孤岛」**,打通孤岛的成本也是巨大的,Kafka 最近几年这么火也是正因为存储方案的多样导致的「数据孤岛」的问题正在显现。\n\t\n* 在线业务与分析脱节\n\n\t现在大家构建存储系统的时候,默认会让在线业务与离线业务是分开的, 在线业务用 MySQL、MongoDB 等等,离线业务(或者分析系统)用 Hadoop 做数据分析,好像大家都是理所当然的认为:在线和离线就该这样,泾渭分明。\n\t\n\t**但目前有个趋势,分析的场景的需求越来越「实时」,或者说高时效的数据分析带来的业务价值受到重视**,这就与大家惯性认知产生了本质的冲突:业务需要当日甚至实时的数据分析结果,但后端只能说今天的数据明天才能导出。还有一个问题是,各个部分维护团队也是分开的,当业务发生变化时,很难灵活地调整和适应。\n\t\n**导致以上这些问题出现的深层共性是:变化永远比计划快**,你永远没法预测未来需要多少机器?业务会膨胀到多大?到底需要多“实时”的数据来做决策?\n\n**有没有可能存在一个应付更多变化、覆盖更多场景的系统**?从前可能是:我的工具箱里装了各种型号的锤子(工具软件),去应对不同场景、形状的钉子,现在可能追求用一个锤子,快速、低成本的解决不同的钉子(问题),**以不变应万变**。\n\n## Real-Time HTAP 是解药吗?\n\n聊到最近几年数据库领域的变化,申砾提到最近两年很多数据库打出了 HTAP 的标签,黄东旭分享了自己对“一个真正的 Real-Time HTAP 数据库”的理解:\n\n\n\n**那么 Real-Time HTAP 价值在何处?应该在于它是一个简单、灵活的方案——能够将各个系统/团队集中在一个 Real-Time HTAP 系统上,节省成本并灵活应对业务变化。**\n\n## Real-Time HTAP 之后?\n\nReal-Time HTAP 可能是当下厂商们能够看得到的努力方向,那么在 Real-Time HTAP 之后的未来是什么呢?\n\n或许五年之后有以下场景:\n\n\n\n基于这些场景,**未来数据库绕不开的核心能力应该是:智能、弹性调度能力**。\n\n最近有个新概念是 Serverless,Severless 是伴随云(Cloud)诞生的概念。当然 Severless 不是没有服务器,通俗地说,Serverless 就是会根据你的实际需求情况,调整数据库的形态,例如业务流量峰值的时候快速的采购弹性的计算资源进行扩容,低峰的时候自动的释放多余的资源。所以可以把 Severless 当做智能、弹性调度的落地形式来理解,同时未来的数据库一定是跑在云上的。","date":"2020-04-15","author":"PingCAP","fillInMethod":"writeDirectly","customUrl":"core-competence-of-future-database","file":null,"relatedBlogs":[]},{"id":"Blogs_128","title":"聊聊数据库的未来,写在 PingCAP 成立五周年之际","tags":["架构"],"category":{"name":"观点洞察"},"summary":"我们要造的是一个真正能作为整个系统的 Single Source of Truth 的基础软件。","body":">我还清楚记得,五年前的这个时候,当时还在豌豆荚,午后与刘奇和崔秋的闲聊关于未来数据库的想象,就像一粒种子一样,到了今天看起来也竟枝繁叶茂郁郁葱葱,有点感慨。按照惯例,五年是一个重要的节点,没有十年那么冗长,也没有一两年的短暂,是一个很好的回顾节点,就在此认真的回顾一下过去,展望一下未来。\n\n五年前创业的出发点其实很朴素:做一个更好的分布式数据库。从学术的角度上看起来,并不是提出了什么惊天地泣鬼神的神奇算法,我们选择的 Shared-nothing 的架构其实在当时的业界也不是什么新鲜的事情了,但真正令我激动的是:**我们要造的是一个真正能作为整个系统的 Single Source of Truth 的基础软件**。这句话怎么理解呢?我在后边会好好聊聊。\n\n## 数据是架构的中心\n\n作为一个互联网行业的架构师,几乎是天天都在和各种类型的数据打交道,这么多年的经验,不同行业不同系统,从技术层面来说,抽象到最高,总结成一句话就是:\n\n**数据是架构的中心。**\n\n仔细想想,我们其实做的一切工作,都是围绕着数据。数据的产生,数据的存储,数据的消费,数据的流动……只不过是根据不同的需求,变化数据的形态和服务方式。计算机系的同学可能还记得老师说过的一句话:程序 = 算法 + 数据结构,我这里斗胆模仿一下这个句式:**系统 = 业务逻辑 x 数据**。可以说很多架构问题都是出在数据层,例如常见的「烟囱式系统」带来的种种问题,特别是数据孤岛问题,其实本质上的原因就出在没有将数据层打通,如果不从数据架构去思考,就可能「头疼医头、脚疼医脚」,费了半天劲还是很别扭,反过来如果将数据层治理好,就像打通「任督二脉」一样,起到四两拨千斤的效果。\n\n但是理想通常很丰满,现实却很骨感。至少在我们五年前出来创业那会儿,我们觉得并没有一个系统能够很好的解决数据的问题。可能好奇的读者就要问了:不是有 Hadoop?还有 NoSQL?再不济关系型数据库也能分库分表啊?其实列出的这几个几乎就是当年处理存储问题的全部候选,这几个方案的共同特点就是:不完美。\n\n**具体一点来说,这几个解决方案对于数据应用的场景覆盖其实都不大,对于复杂一点的业务,可能需要同时使用 n 多个方案才能覆盖完整**。这就是为什么随着近几年互联网业务越来越复杂,类似 Kafka 这样的数据 Pipeline 越来越流行,从数据治理的角度其实很好理解:各种数据平台各负责各的,为了做到场景的全覆盖,必然需要在各个「岛」之间修路呀。\n\n**我们当年就在想,能不能有一个系统以一个统一的接口尽可能大的覆盖到更多场景。**\n\n**我们需要一个 Single Source of Truth**。数据应该是贯穿在应用逻辑各个角落,我理想中的系统中对于任意数据的存取都应该是可以不加限制的(先不考虑权限和安全,这是另一个问题),这里的“不加限制”是更广义的,例如:没有容量上限,只要有足够的物理资源,系统可以无限的扩展;没有访问模型限制,我们可以自由的关联、聚合数据;没有一致性上的限制;运维几乎不需要人工干预……\n\n## 以分布式数据库为统一中心的架构\n\n我当年特别着迷于一个美剧:Person of Interest (疑犯追踪),这个电视剧里面有一个神一样的人工智能 The Machine,收集一切数据加以分析,从而预测或是干预未来人们的行动。虽然这部美剧还是比较正统的行侠仗义之类的主题,但是更让我着迷的是,是否我们能设计一个 The Machine?虽然直到目前我还不是一个 AI 专家,但是给 The Machine 设计一个数据库似乎是可行的。这几年创业过程中,我们发现更令人兴奋的点在于:\n\n**以分布式数据库为统一中心的架构是可能的。**\n\n这个怎么理解呢?举个例子,就像在上面提到的分裂带来的问题,数据层的割裂必然意味着业务层需要更高的复杂度去弥补,其实很多工程师其实偏向于用线性的思维去思考维护系统的成本。但是实际的经验告诉我们,事情并不是这样的。一个系统只有一个数据库和有十个数据库的复杂程度其实并不是的简单的 10x,考虑到数据的流动,维护成本只可能是更多,这里还没有考虑到异构带来的其他问题。\n\n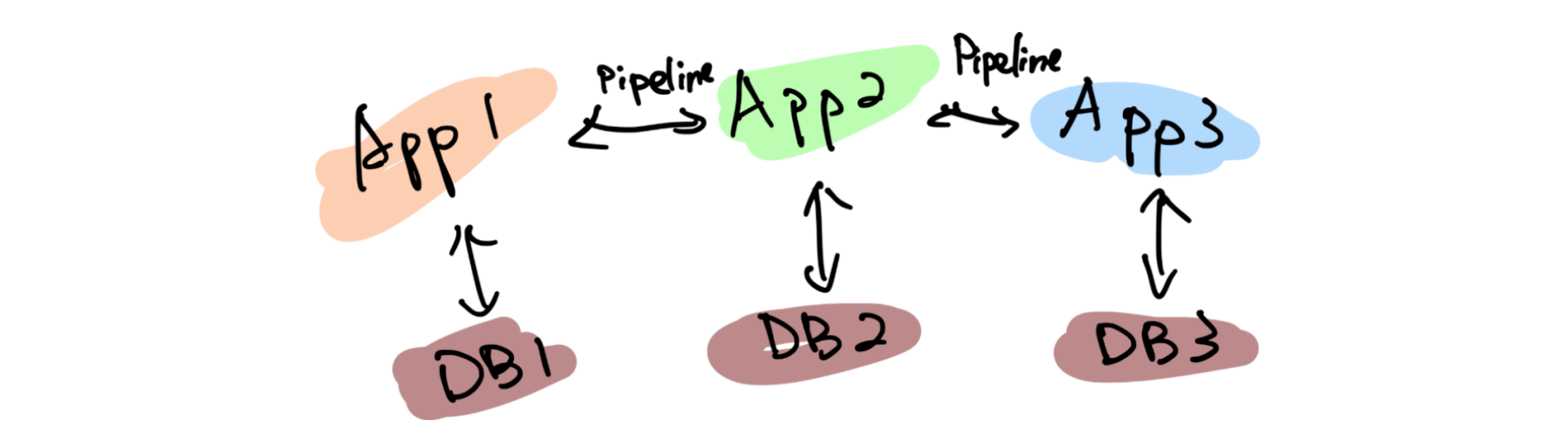\n\n以分布式数据库为中心的架构是什么样子的呢?**很好理解,整个架构的中心是一个场景覆盖度足够广,且具有无限的水平伸缩能力的存储系统。大部分数据的流动被限制在这个数据库内部,这样应用层就可以几乎做到无状态,因为这个中心的数据库负责了绝大部分状态,每个应用可以通过自己的缓存来进行加速。\n这里我想提醒的是,为什么我在上面强调水平扩展能力,是因为受限的扩展能力也是导致分裂的一个重要的原因。我们从来都没有办法准确的预测未来,我们很难想象甚至是一年后业务的变化(想想这次疫情),有句老话说的很好:唯一不变的就是变化。**\n\n另外一个经常被问到的问题,为什么要强调缓存层需要离业务层更近,或者说,为什么位于中心的这个巨型数据库不应该承担缓存的责任?我的理解是,只有业务更懂业务,知道应该以什么样的策略缓存什么样的数据,而且出于性能(低延迟)考虑,缓存离业务更近也是有道理的。\n\n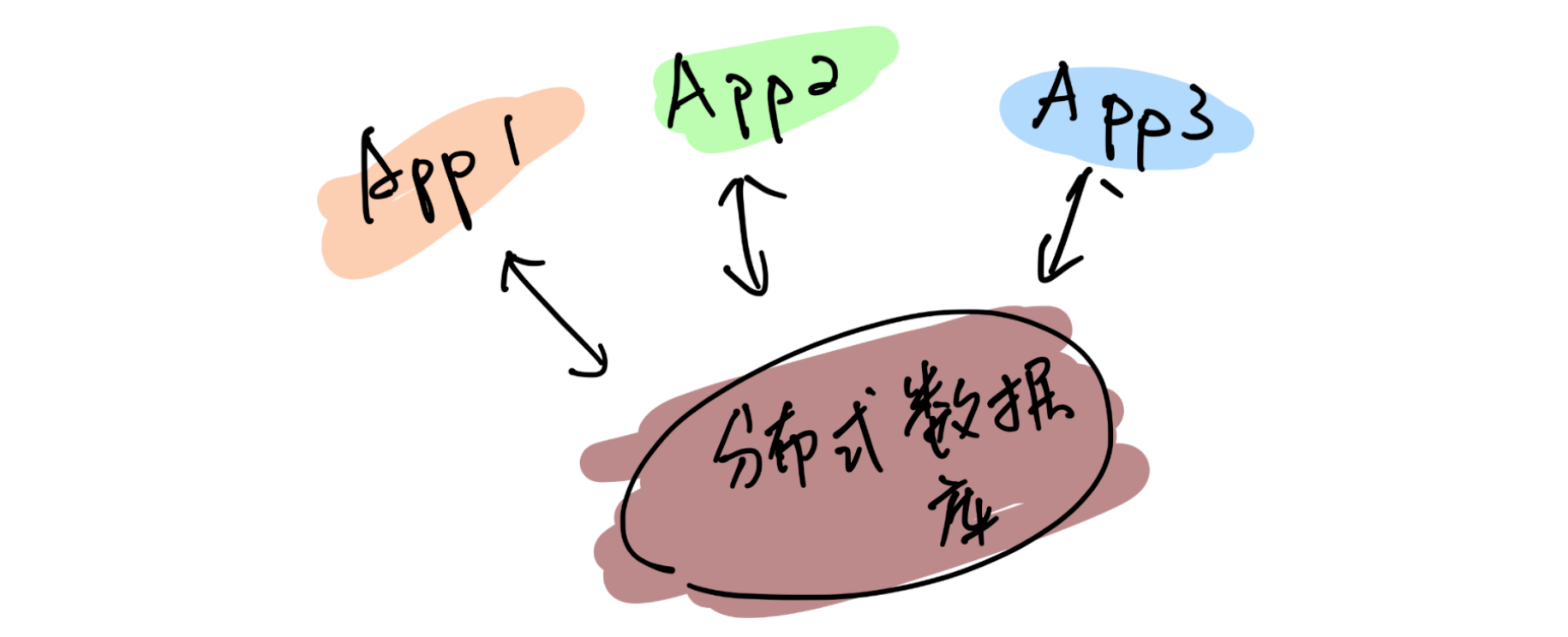\n\n对应上面那句话「唯一不变的就是变化」,这个架构带来最大的好处正是「以不变应万变」,或者更简单的一个词:**简洁**。Google 其实在很早就想清楚了这个问题,因为他们很早就明白什么是真正的复杂。\n\n另一个例子是 **HTAP**,如果关注的数据库的发展的话,最近一定对 HTAP 这个词很熟悉,其实在我看来的 HTAP 的本质在于上面提到的覆盖度,下面是一个典型的架构:\n\n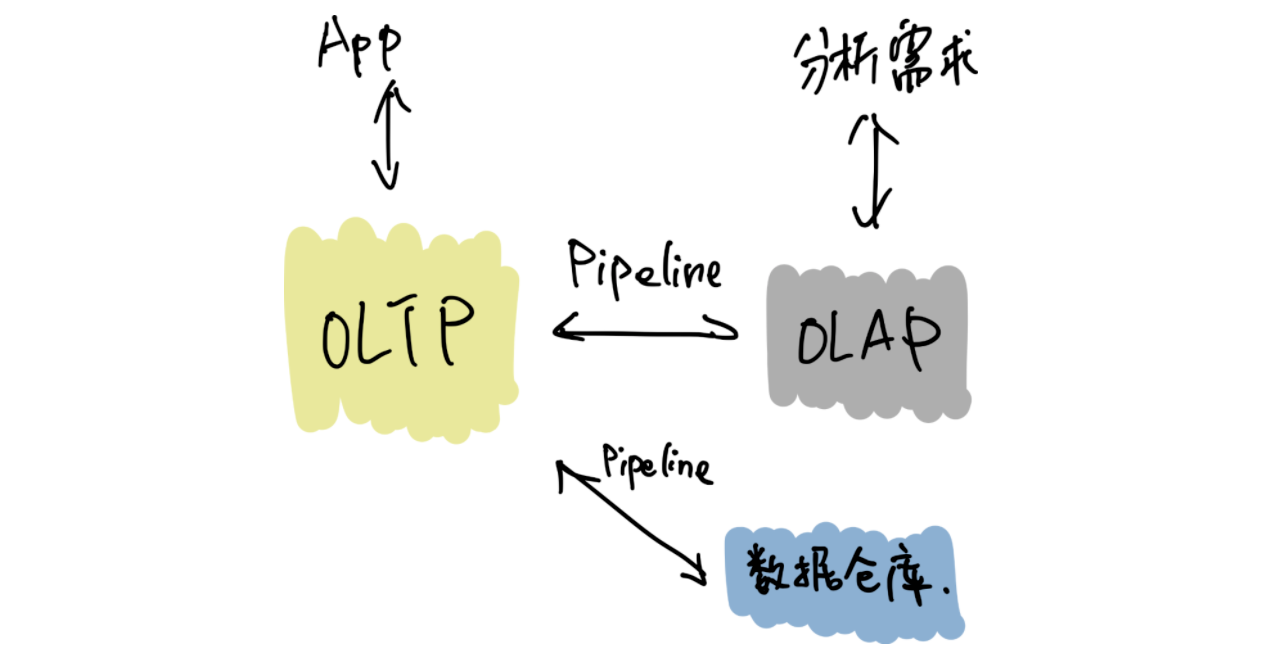\n\n传统的数据架构通常将 OLTP、OLAP、离线数仓分离,各个系统各司其职,中间通过独立的 Pipeline 进行同步(有时候还会加上 ETL)。\n\n**下面是一个 HTAP 的系统的样子:**\n\n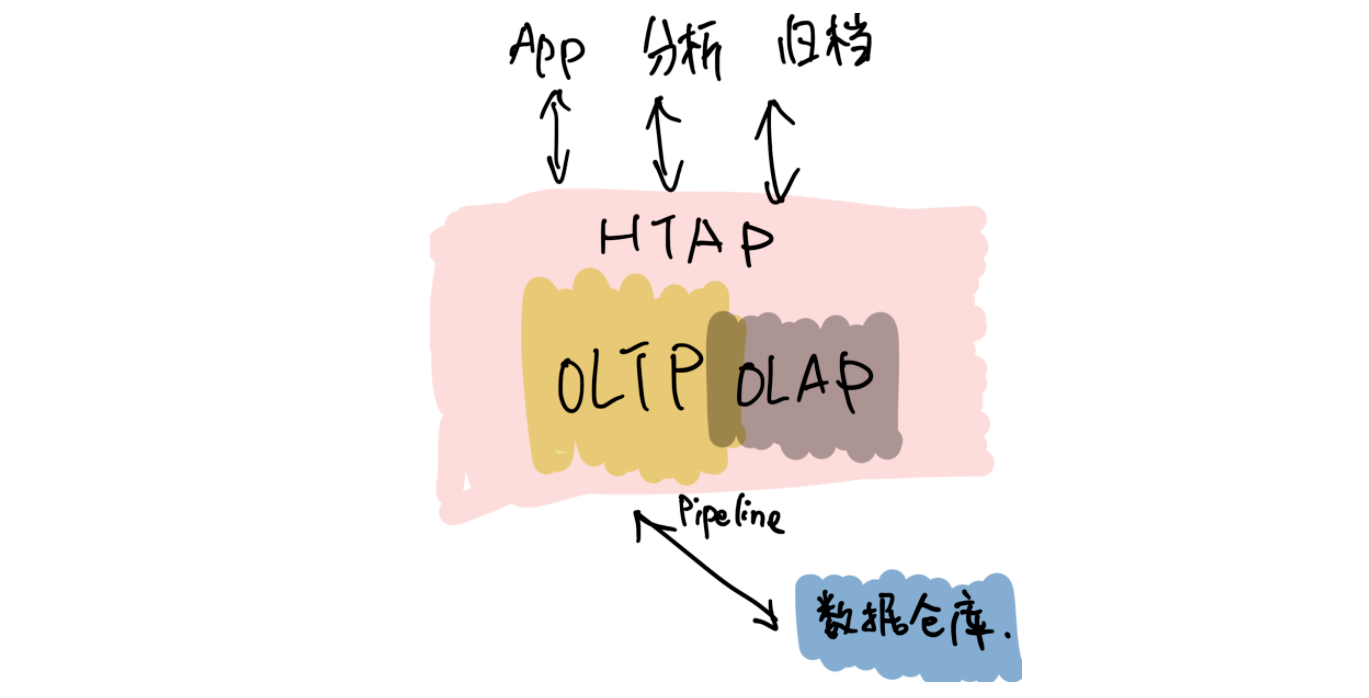\n\n虽然从表面上看,只是简单的将接口层进行整合,但是这个意义其实是深远的,首先数据同步的细节被隐藏了一起来,这意味着数据库层面可以自己决定通过何种方式同步数据,另外由于 OLTP 引擎和 OLAP 引擎在同一个系统内部,使得很多细节信息不会在同步的过程中丢失,比如:事务信息,这就意味着在内部的分析引擎能够做到传统的 OLAP 没办法做的事情。另外对于业务层的使用来说,少一个系统意味着更统一的体验和更小的学习和改造成本,**不要低估统一带来的力量**。\n\n## 未来在哪里?\n\n上面这些是过去五年发生的事情,也几乎按照我们创业时候的设想一步步的变为现实,那么接下来的五年会发什么?随着对于行业和技术的理解的加深,至少有一点我深信不疑的是:\n\n### 弹性调度会是未来的数据库的核心能力\n\n谁都不会否认,最近十年在 IT 技术上,最大的变革是由云带来的,这场革命还在进行时。云的核心能力是什么?我认为是弹性。计算资源分配的粒度变得越来越细,就像从只能买房变成可以租房,甚至可以像住酒店一样灵活。这意味着什么?**本质在于我们可以不用为「想象中」的业务峰值提前支付成本。**\n\n过去我们的采购服务器也好,租赁机柜也好,都是需要设定一个提前量的,当业务峰值没有到来之前,其实这些成本是已经提前支付的了。云的出现将弹性变成了基础设施的一个基础能力,我预计数据库也会发生同样的事情。\n\n可能有很多朋友会有疑问,现在难道不是几乎所有数据库都号称能够支持透明水平扩展嘛?其实这里希望大家不要将**「弹性调度」**狭隘的理解为扩展性,而且这个词的重点在**「调度」**上,我举几个例子以方便大家理解:\n\n1. **数据库能不能够自动识别 workload,根据 workload 进行自动伸缩**?例如:预感到峰值即将来临,自动的采购机器,对热数据创建更多副本并重分布数据,提前扩容。在业务高峰过去后,自动回收机器进行缩容。\n\n2. **数据库能不能感知业务特点,根据访问特点决定分布**?例如:如果数据带有明显的地理特征(比如,中国的用户大概率在中国访问,美国用户在美国),系统将自动的将数据的地理特征在不同的数据中心放置。\n\n3. **数据库能不能感知查询的类型和访问频度,从而自动决定不同类型数据的存储介质**?例如:冷数据自动转移到 S3 之类比较便宜的存储,热数据放在高配的闪存上,而且冷热数据的交换完全是对业务方透明的。\n\n这里提到的一切背后都依赖的是「弹性调度」能力。未来我相信物理资源的成本会持续的降低,计算资源的单价持续下降带来的结果是:当存储成本和计算资源变得不是问题的时候,问题就变成**「如何高效的分配资源」**。如果将高效分配作为目标的话,「能调度」就是显而易见的基础。\n当然就像一切事物发展的客观规律一样,学会跑步之前,先要学会走路,我相信在接下来的一段时间内,我们会看到第一批初步拥有这样能力的新型数据库,让我们拭目以待。\n\n### 下一个阶段是智能\n\n对于更远的未来是怎么样子的?我不知道,但是就像 The Machine 一样,只有足够数据才能诞生出智能,我相信就像我们不了解宇宙和海洋一样,我们现在对于数据的认识一定是肤浅的,甚至大量的数据我们都还没记录下来,一定有更大奥秘隐藏在这海量的数据中,从数据中能获取什么样的洞察,能够怎么样更好的改变我们的生活,我并不知道,但是做这件事情的主角我猜不会是人类。虽然在这个小节我们讨论的东西可能就有点像科幻小说了,不过我愿意相信这样的未来,从数据的海洋中诞生出新的智能体。\n\n## 尾声\n\n创业这五年的时间,回头看看那个最朴素的出发点:写一个更好的数据库彻底解决烦人的 MySQL 分库分表问题。似乎也算没有偏离初心,但是在这个旅途中一步步看到了更大的世界,也越来越有能力和信心将我们相信的东西变为现实:\n\n我有一个梦想,未来的软件工程师不用再为维护数据库加班熬夜,各种数据相关的问题都将被数据库自动且妥善的处理;\n\n我有一个梦想,未来我们对数据的处理将不再碎片化,任何业务系统都能够方便的存储和获取数据;\n\n我有一个梦想,未来的我们在面临数据的洪流时候,能从容地以不变应万变。\n\n最近我听到一句话,我个人很喜欢:**雄心的一半是耐心**。构建一个完美的数据库并不是一朝一夕的工作,但是我相信我们正走在正确的道路上。\n\n**凡所过往,皆为序章。**","date":"2020-04-08","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"talk-about-the-future-of-databese-on-5th-anniversary-of-pingcap","file":null,"relatedBlogs":[]},{"id":"Blogs_167","title":"我眼中的分布式系统可观测性","tags":["Key Visualizer","TiDB 4.0 新特性"],"category":{"name":"观点洞察"},"summary":"在 Cloud Native 和微服务的世界里,大家正在将“系统的可观测性”放在更高的位置。","body":"\n\n位于 M87 中心的特大质量黑洞示意图(© EHT Collaboration)\n\n今天的文章我想从这张模糊的照片说起。\n\n相信很多小伙伴对这张照片并不陌生,这是去年人类第一次拍摄的 M87 中心黑洞的照片,从1915年,爱因斯坦提出相对论预言黑洞的存在到 2019 年我们终于第一次「**看到**」了黑洞的样子,中间整整相隔了 100 多年,这对于人类认识黑洞乃至认识宇宙都是一个里程碑式的事件。人类是一个感性的动物,所谓「**一图胜千言**」很多时候一张图传达的信息超过千言万语。\n\n关于黑洞我不想展开太多,今天我们聊聊「**望远镜**」。\n\n前几天,在 TiDB 4.0 的开发分支中,我们引入了一个新功能叫做:Key Visualizer(下面简称 KeyViz),说起来这个小工具也并不复杂,就是用不同颜色的方框来显示整个数据库的不同位置数据访问频度和流量。一开始我们只是仅仅将它定位为一个给 DBA 用来解决数据库热点问题的调优辅助小工具,但是从昨晚开始我就一直在把玩这个小东西,突然觉得它对于分布式数据库来说背后的意义远不及此。\n\n**在 CNCF 对 Cloud Native 的定义中,有一条叫做「Observability」,通用的翻译叫系统的「可观测性」。过去我一直苦于寻找一个例子说明什么叫做一个「可观测」的系统,在 KeyViz 这个项目上,我找到了对这点绝佳的体现。**\n\n**举几个直观的小例子。你知道 TPC-C 测试「长」什么样子吗?请看下图:**\n\n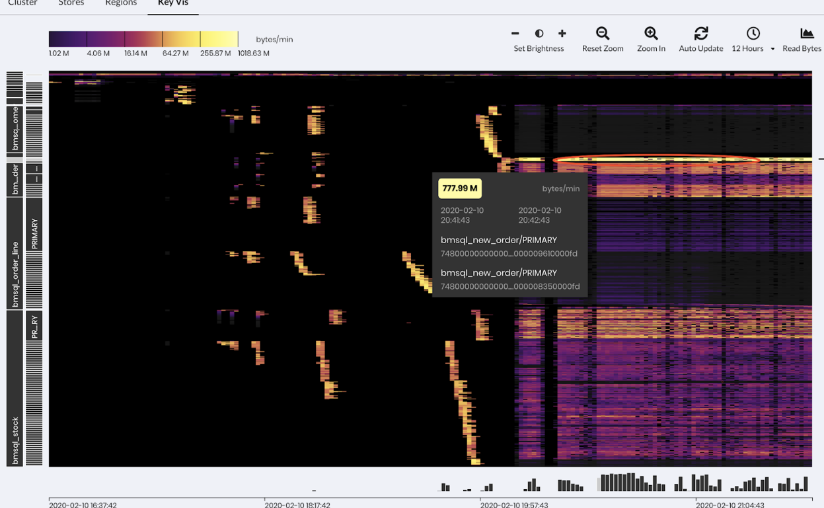\n\n图中横轴是时间,纵轴是数据的分布,左半部分是数据导入的过程,有零星的亮点,可以看到写入分散到多个区块;右边密集的色块是测试在运行时系统的实时读写状态,越暗表示流量越小,越亮表示流量越高。从密集的色块我们能够看得出来,workload 基本分布均匀,但是大概有两处是明显偏亮的区域,其中靠近最上方,有一个特别明显的**局部访问热点**(最亮的那条线)。\n\n**第二个例子,你见过 Sysbench 测试 「长」什么样子吗?看看下面。**\n\n\n\n左边比较密集的明亮黄块部分,是导入数据阶段;右半段明暗相间的部分是在进行 oltp_point_select 测试,因为选取的模式是 uniform 模式,并且导入的时候是 32 线程 32 张测试表,可以看到的数据和分布和访问都比较均匀。\n如果你看懂了上面两个小例子,下面是一个小作业:这是我们模拟的一个实际用户的生产环境的照片,**这个用户的系统遇到了一些瓶颈,你能看出问题吗?**\n\n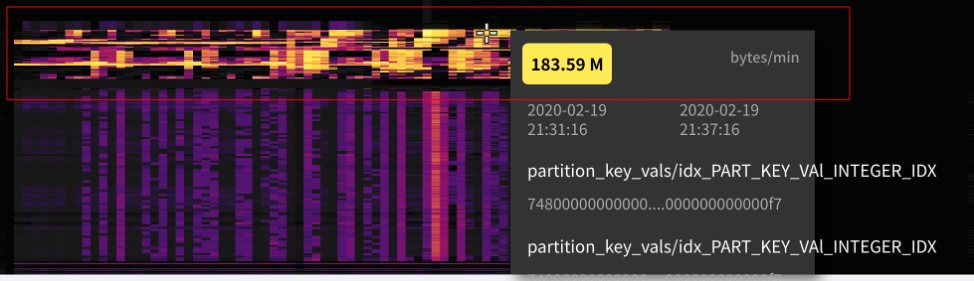\n \n上面几个小例子是让大家对 KeyViz 有个感性的认识,在介绍这个东西背后的意义之前,我想先介绍一下 TiDB 这类典型的分布式数据库的系统架构,方便大家更好的理解。\n\n\n\n一个典型的分布式数据库的数据分布策略\n\n分布式数据库,顾名思义,数据一定是分散在不同机器上的。对于一张表的数据,我们会在逻辑上切分成若干个连续的区间,将这些区间内的数据分给不同的机器存储,不管是写入还是读取,只需要知道目标数据属于哪个区间,就可以直接到那个机器上进行访问。然后加上对每一个区间的数据在物理上做多副本冗余,实现高可用。如下图所示,Region 在 TiDB 的内部就是一个个连续的数据区间。\n\n\n\n和很多分布式数据库不太一样的是,我们的 Region 的大小比较小(默认 96MB) ,另外数据的分布并不是静态的,而是动态的,Region 会像细胞一样分裂/合并,也会在不同机器之间移动进行动态的负载均衡。\n\n\n\n现在回头看这个设计,还是觉得无比的简洁和优雅。对用户而言再也不用去思考怎么分库,怎么分表,数据在最底层的细胞就像有生命一样繁衍和迁徙。\n\n**然后问题就来了,对于这样的数据库而言,有没有一种办法能够直观地描述系统的运行时状态?我怎么知道它是不是「生病」了?我能不能预测这个系统的未来?我能不能发现未知的风险?**\n\n过去,不管是业务开发者还是 DBA,衡量一个数据库的状态,来来回回就是几个指标,QPS 、TPS、查询时间、机器负载(CPU、网络、磁盘),但很多时候就像是盲人摸象一样对于系统的全局我们是不清楚的。再加上在一个分布式的架构下,很多时候,我们可能会被海量的数字蒙蔽了双眼。一些有经验的 DBA 或许可以通过自己的经验,从多个指标里模糊构建出业务全局状态,但是到底这个经验往往是不可描述的,这就是为什么一些老运维、老 DBA 那么值钱的原因,但是我认为这种做事方式是很难 scale 的。\n\nCT 、B 超、核磁共振,这些现代化的手段极大地促进了现代医学的发展,因为我们第一次能「看见」我们身体的内部状态,从而才能得出正确的判断。**在计算机的世界道理也是相通的,最好通过某些工具让人清晰地「看见」系统运行的健康状态、帮助诊断病灶,从而降低经验门槛和不确定性。**\n\n过去也经常有朋友问我:“你说我这个业务适不适合使用 TiDB?”这时我们只能问,你的 QPS 多少 TPS 多少,数据量多少?读写比?典型查询?数据分布怎么样?表结构是什么呀?等等一连串的灵魂拷问,而且很多术语都非常专业,不是在这个行业摸爬滚打很久的老司机可能都搞不太清楚。而且有些信息可能是敏感的,也不方便共享。所以「**预判** TiDB 到底适不适合某项业务」就成了一个玄学问题,这个问题困扰了我很久,很多时候也只能凭个人感觉和经验。其实这个问题也并不是 TiDB 特有,尤其是最近几年,几乎所有现代的分布式系统,都或多或少有类似的问题。\n\n**在过去,一个物理机器的状态确实可以通过几个监控指标描述,但是随着我们的系统越来越复杂,我们的观测对象正渐渐的从「Infrastructure」转到「应用」,观察行为本身从「Monitoring(监控)」到「Observability(观测)」。** 虽然看上去这两者只是文字上的差别,但是请仔细思考背后的含义。关于这个话题,我很喜欢引用下面这张图:\n\n\n\n上图坐标描述了我们对系统的理解程度和可收集信息之间的关系。在 X 轴的右侧(Known Knows 和 Known Unknowns)这些称为**确定性的已知和未知**,图中也给出了相对应的例子,这些信息通常是最基础的普适的事实,也就是在系统上线之前我们一定就能想到,一定能够监控起来的(CPU Load、内存、TPS、QPS 之类的指标),我们过去已有的大多数运维监控都是围绕这些确定的东西。\n\n但是有一些情况是这些基础信息很难描述和衡量的,例如这个坐标的左上角:**Unknown Knowns**,用通俗的话来说,叫做「**假设**」。举个数据库的例子:有经验的架构师在设计一个基于分布式数据库的应用时,通常不会将表的主键设成自增主键,会尽可能的用 UUID 或者其他方式打散数据,这样在即使有突发写入压力的时候,系统也能很好的扩展。\n\n注意在这个例子中,其实「**假设**」的事情(写入压力突然增大)并没有发生,如果在日常压力不大,数据量不多的情况下,即使使用自增主键,从已有的基础监控中,可能也很难看出任何问题。但是到出事的时候,这个设计失误就会变成 **Unknown Unkowns(意外)**,这是任何人都不想看到的。有经验的架构师能通过种种的蛛丝马迹证实自己的推测,也从无数次翻车的 Post-mortem 中将 Unknown Unknowns 的范围变小。**但是更合理的做法是通过技术手段描绘系统更全面的状态。在 Cloud Native 和微服务的世界里,最近几年一个行业的大趋势是将「系统的可观测性」放在一个更高的位置(监控只是可观测性的一个子集),这是有道理的。**\n\n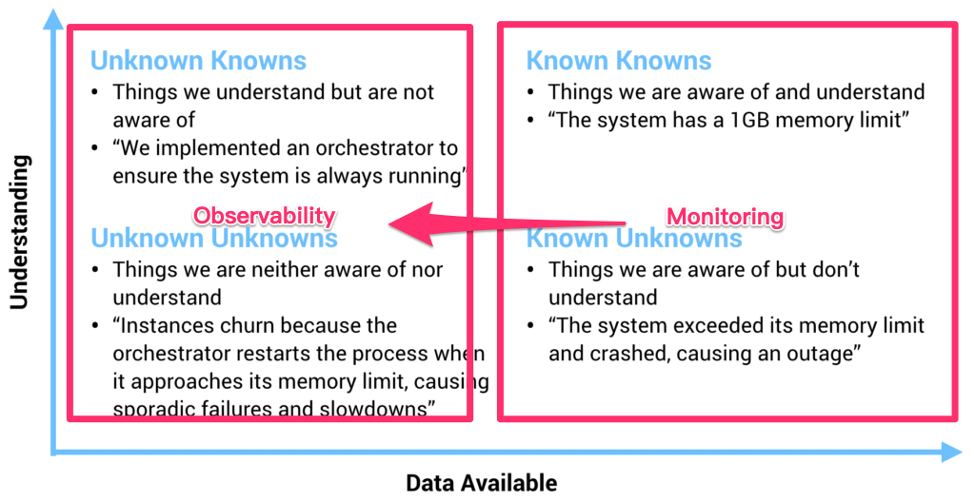\n\n回到数据库的世界,TiDB KeyViz 的意义在于,就像上面提到的,这个工具不仅仅是一个监控工具,而且**它能以一个非常低门槛且形象的方式让架构师具象化的看到自己对于业务的「假设」是否符合预期,这些「假设」不一定是能够通过监控反映的,以获得对业务更深刻的 Insight。**\n\n还是说回上面那个主键的小例子。对于两种不同的主键设计,KeyViz 这边是怎么表现的呢?看看下面两张图,是不是非常一目了然?\n\n\n\n\n\n所以现在如果有朋友问我,“这个业务适不适合 TiDB?”我只需要通过录制线上流量,或者搭建一个从集群,只需要把 KeyViz 的图给我看一眼,我甚至都不需要压力测试就能判断这个业务是否适合,而且即使不适合,我也能准确的给出修改建议,因为 KeyViz 的图对我的「假设」的可解释性有了很强的支持。\n\n我们不妨在此基础上再放飞一下想象力,为什么人类能够一眼就从这图片中理解这些信息,这说明这些图形背后有**模式**,有模式我们就可以识别——\n\n想象一下,如果所有的 TiDB 用户,都使用 KeyViz 将自己的系统具象化后分享出来(其实这些图片已经高度抽象,已经不具有任何的业务机密信息),**我们是不是可以通过机器学习,挖掘背后更深层次的价值?AI 能不能通过这种形式更加理解我们的业务?**\n\n最后,我想以我最喜欢的科幻小说《三体:黑暗森林》中的一段话结束这篇文章,大致是面壁人希恩斯在冬眠后被妻子唤醒后的一个场景:\n\n>……与此同时,希恩斯感觉到围绕着他们的白雾发生了变化,雾被粗化了,显然是对某一局部进行了放大。他这时发现所谓的雾其实是由无数发光的小微粒组成的,那月光般的光亮是由这些小微粒自身发出的,而不是对外界光源的散射。放大在继续,小微粒都变成了闪亮的星星。希恩斯所看到的,并不是地球上的那种星空,他仿佛置身于银河系的核心,星星密密麻麻,几乎没有给黑夜留出空隙。\n>\n>“每一颗星星就是一个神经元。”山杉惠子说,一千亿颗星星构成的星海给他们的身躯镀上了银边。\n\n> 延展阅读:[做出让人爱不释手的基础软件:可观测性和可交互性](https://pingcap.com/zh/blog/how-to-develop-an-infrasoft-observability-and-interactivity) \n> [TiDB 4.0 新特性前瞻(一)拍个 CT 诊断集群热点问题](https://pingcap.com/zh/blog/tidb-4.0-key-visualizer)","date":"2020-02-22","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"observability-of-distributed-system","file":null,"relatedBlogs":[]},{"id":"Blogs_61","title":"分布式系统 in 2010s :测试和运维","tags":["分布式系统前沿技术"],"category":{"name":"观点洞察"},"summary":"本文为「分布式系统 in 2010s」 系列最终篇,这次我们来聊一聊测试和运维。","body":"我觉得面对测试的态度是区分一个普通程序员和优秀程序员的重要标准。现如今我们的程序和服务越来越庞大,光是单元测试 TDD 之类的就已经很难保证质量,不过这些都是 baseline,所以今天聊点新的话题。\n\n说测试之前,我们先问下自己,为什么要测试?当然是为了找 Bug。看起来这是句废话,但是仔细想想,如果我们能写出 Bug-free 的程序不就好了吗?何必那么麻烦。不过 100% 的 Bug-free 肯定是不行的,那么我们有没有办法能够尽可能地提升我们程序的质量?举个例子,我想到一个 Raft 的优化算法,与其等实现之后再测试,能不能在写代码前就知道这个算法理论上有没有问题?办法其实是有的,那就是形式化证明技术,比较常用的是 TLA+。\n\n## TLA+\n\nTLA+ 背后的思想很简单,TLA+ 会通过一套自己的 DSL(符号很接近数学语言)描述程序的初始状态以及后续状态之间的转换关系,同时根据你的业务逻辑来定义在这些状态切换中的不变量,然后 TLA+ 的 TLC model checker 对状态机的所有可达状态进行穷举,在穷举过程中不断检验不变量约束是否被破坏。\n\n举个简单的例子,分布式事务最简单的两阶段提交算法,对于 TLA+ Spec 来说,需要你定义好初始状态(例如事务要操作的 keys、有几个并发客户端等),然后定义状态间跳转的操作( Begin / Write / Read / Commit 等),最后定义不变量(例如任何处于 Committed 状态的 write ops 一定是按照 commit timestamp 排序的,或者 Read 的操作一定不会读到脏数据之类的),写完以后放到 TLC Checker 里面运行,等待结果就好。\n\n但是,我们活在一个不完美的世界,即使你写出了完美的证明,也很难保证你就是对的。第一, Simulator 并没有办法模拟出无限多的 paticipants 和并发度, 一般也就是三五个;第二,聪明的你可能也看出来了,一般 TLA+ 的推广文章也不会告诉你 Spec 的关键是定义不变量,如果不变量定义不完备,或者定义出错,那么证明就是无效的。因此,我认为形式化验证的意义在于让工程师在写代码之前提高信心,在写证明的过程中也能更加深对算法的理解,此外,如果在 TLC Checker 里就跑出异常,那就更好了。\n\n目前 PingCAP 应该是国内唯一一个使用 TLA+ 证明关键算法,并且将证明的 Spec 开源出来的公司,大家可以参考 [pingcap/tla-plus](https://github.com/pingcap/tla-plus) 这个 Repo,以及我们的首席架构师唐刘的这篇[博客](https://www.jianshu.com/p/721df5b4454b)了解更多。\n\n## Chaos Engineering\n\n如果完美的证明不存在,那么 Deterministic 的测试存在吗?我记得大概 2015 年在 PingCAP 成立前,我看到了一个 FoundationDB 关于他们的 Deterministic 测试的[演讲](https://www.youtube.com/watch?v=4fFDFbi3toc)。简单来说他们用自己的 IO 处理和多任务处理框架 [Flow](https://apple.github.io/foundationdb/flow.html) 将代码逻辑和操作系统的线程以及 IO 操作解耦,并通过[集群模拟器](https://apple.github.io/foundationdb/testing.html)做到了百分之百重现 Bug 出现时的事件顺序,同时可以在模拟器中精确模拟各种异常,确实很完美。但是考虑到现实的情况,我们当时选择使用的编程语言主要是 Go,很难或者没有必要做类似 Flow 的事情 。所以我们选择了从另一个方向解决这个问题,提升分布式环境下 Bug 的复现率,能方便复现的 Bug 就能好解决,这个思路也是最近几年很火的 Chaos Engineering。 做 Chaos Engineering 的几个关键点:\n\n1. 定义稳态,记录正常环境下的 workload 以及关注的重要指标。\n\n2. 定义系统稳态后,我们分为实验组和对照组进行实验,确认在理想的硬件情况下,无论如何操作实验组,最后都会回归稳态。\n\n3. 开始对底层的操作系统和网络进行破坏,再重复实验,观察实验组会不会回归稳态。\n\n道理大家都懂,但是实际做起来最大的问题在于如何将整个流程自动化。原因在于:一是靠手动的效率很低;二是正统的 Chaos Engineering 强调的是在生产环境中操作,如何控制爆炸半径,这也是个比较重要的问题。\n\n先说第一个问题,PingCAP 在实践 Chaos Engineering 的初期,都是在物理机上通过脚本启停服务,所有实验都需要手动完成,耗时且非常低效,在资源利用上也十分不合理。这个问题我们觉得正好是 K8s 非常擅长的,于是我们开发了一个基于 K8s 的,内部称为 Schrodinger 的自动化测试平台,将 TiDB 集群的启停镜像化,另外将 TiDB 本身的 CI/CD,自动化测试用例的管理、Fault Injection 都统一了起来。这个项目还催生出一个好玩的子项目 Chaos Operator:我们通过 CRD 来描述 Chaos 的类型,然后在不同的物理节点上启动一个 DaemonSets,这个 DaemonSets 就负责干扰 Pod,往对应的 Pod 里面注入一个 Sidecar,Sidecar 帮我们进行注入错误(例如使用 Fuse 来模拟 IO 异常,修改 iptable 制造网络隔离等),破坏 Pod。近期我们也有计划将 Chaos Operator 开源。\n\n第二个问题,其实在我看来,有 Chaos Engineering 仍然还是不够的,我们在长时间的对测试和质量的研究中发现提升测试质量的关键是如何发现更多的测试 workload。在早期我们大量依赖了 MySQL 和相关社区的集成测试,数量大概千万级别,这个决定让我们在快速迭代的同时保证质量,但是即使这样还是不够的,我们也在从学术界寻求答案.例如引入并通过官方的 Jepsen Test ,再例如通过 SQLfuzz 自动生成合法 SQL 的语句加入到测试集中,这个思路在最近我们的一次 Hackathon 项目中有一个很完美的落地,可以看看这篇介绍这个项目的文章[《你呼呼大睡,机器人却在找 bug?》](https://pingcap.com/blog-cn/sqldebug-automatically/)。\n\n总之,比起写业务逻辑,在分布式环境下写测试 + 写测试框架花费的精力可能一点都不少,甚至可能多很多(如果就从代码量来说,TiDB 的测试相关的代码行数可能比内核代码行数多一个数量级),而且这是一个非常值得研究和投资的领域。另外一个问题是如何通过测试发现性能回退。我们的测试平台中每天运行着一个名为 benchbot 的机器人,每天的回归测试都会自动跑性能测试,对比每日的结果。这样一来我们的工程师就能很快知道哪些变更导致了性能下降,以及得到一个长期性能变化趋势。\n\n## eBPF\n\n说完测试,另外一个相关的话题是 profiling 和分布式 tracing。tracing 看看 Google 的 Dapper 和开源实现 OpenTracing 就大概能理解,所以,我重点聊聊 profiling。最近这几年我关注的比较多的是 eBPF(extended BPF)技术。想象下,过去我们如果要开发一个 TCP filter,要么就自己写一个内核驱动,要么就用 libpcap 之类的基于传统 BPF 的库,而传统 BPF 只是针对包过滤这个场景设计的虚拟机,很难定制和扩展。\n\n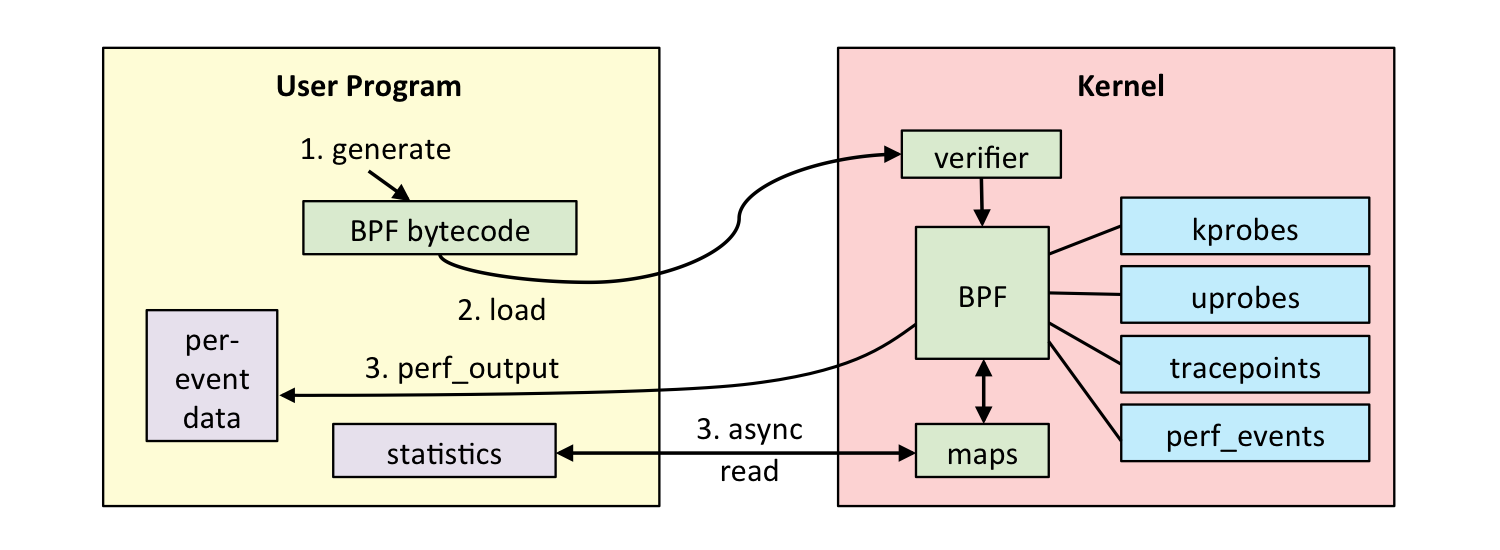\n\n 图 1 BPF 工作原理
\n\n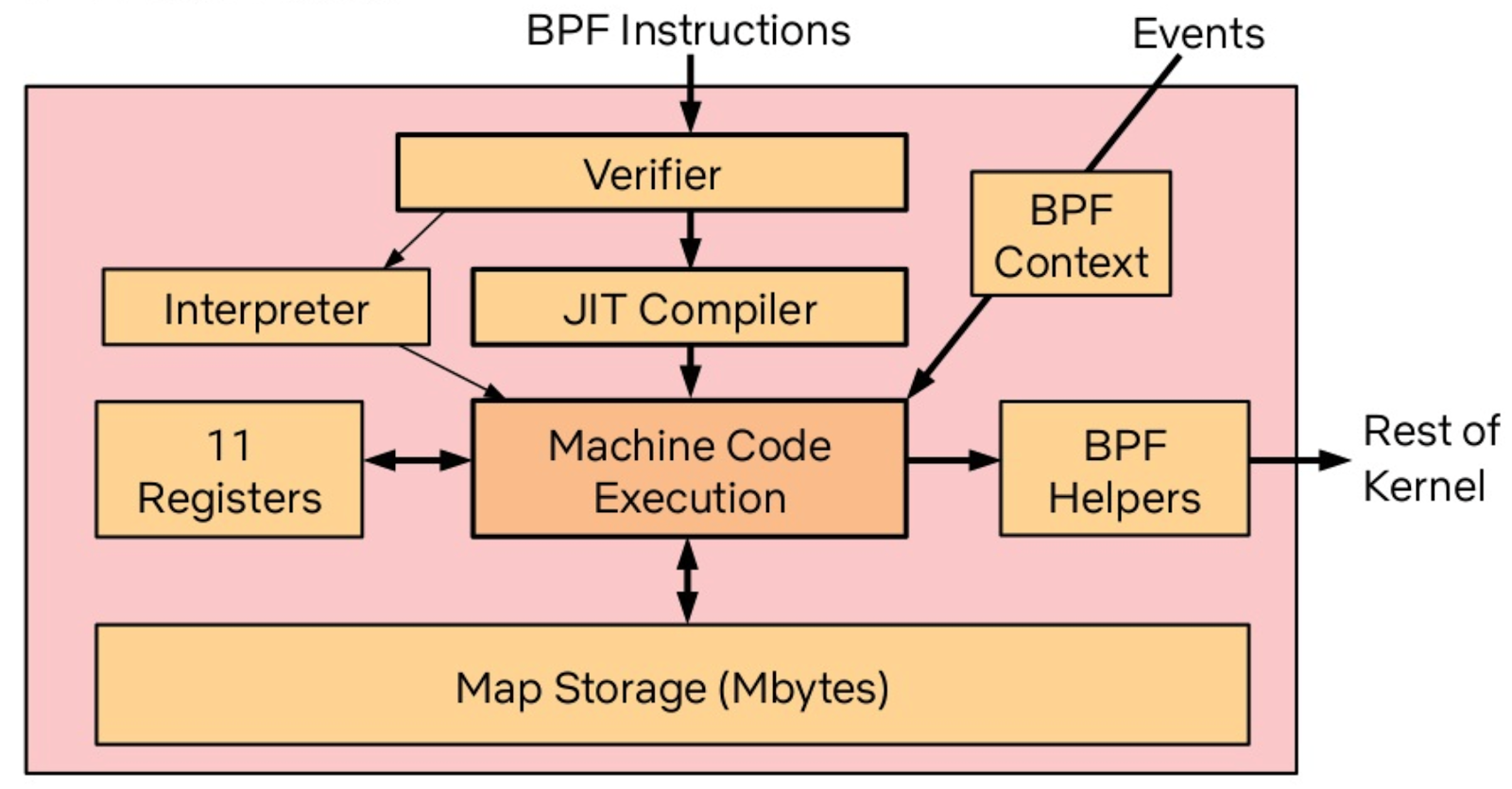\n\n 图 2 eBPF 架构图
\n\n\n在这个背景下,eBPF 应运而生,eBPF 引入了 JIT 和寄存器,将 BPF 的功能进一步扩充,这背后的意义是,我们在内核中有一个安全的、高性能的、基于事件的、支持 JIT 的字节码的虚拟机!这其实极大地降低了拓展内核能力的门槛,我们可以不用担心在驱动中写个异常把内核搞崩,我们也可以将给 llvm 用的 clang 直接编译成 eBPF 对象,社区还有类似 bcc 这样的基于 Python 的实用工具集……\n\n过去其实大家是从系统状态监控、防火墙这个角度认识 eBPF 的。没错,性能监控以及防火墙确实是目前 eBPF 的王牌场景,但是我大胆地预测未来不止于此,就像最近 Brendan Gregg 在他的 blog 里喊出的口号:BPF is a new type of software。可能在不久的未来,eBPF 社区能诞生出更多好玩的东西,例如我们能不能用 eBPF 来做个超高性能的 web server?能不能做个 CDN 加速器?能不能用 BPF 来重定义操作系统的进程调度?我喜欢 eBPF 的另一个重要原因是,第一次内核应用开发者可以无视内核的类型和版本,只要内核能够运行 eBPF bytecode 就可以了,真正做到了一次编译,各个内核运行。所以有一种说法是 BPF is eating Linux,也不是没有道理 。\n\nPingCAP 也已经默默地在 BPF 社区投入了很长时间,我们也将自己做的一些 bcc 工具开源了,详情可以参考 [pingcap/kdt](https://github.com/pingcap/kdt) 这个 repo。其中值得一提的是,我们的 bcc 工具之一 drsnoop 被 Brendan Gregg 的新书收录了,也算是为社区做出了一点微小的贡献。\n\n上面聊的很多东西都是具体的技术,技术的落地离不开部署和运维,分布式系统的特性决定了维护的复杂度比单机系统大得多。在这个背景之下,我认为解法可能是:不可变基础设施。\n\n云和容器的普及让 infrastructure as code 的理念得以变成现实,通过描述式的语言来创建可重复的部署体验,这样可重用的描述其实很方便在开源社区共享,而且由于这些描述几乎是和具体的云的实现无关,对于跨云部署和混合数据中心部署的场景很适合。有些部署工具甚至诞生出自己的生态系统,例如 Terraform / Chef / Ansible。有一种说法戏称现在的运维工程师都是 yaml 语言工程师,其实很有道理的:人总是会出错,且传统的基于 shell 脚本的运维部署受环境影响太大,shell 天然也不是一个非常严谨的语言。描述意图,让机器去干事情,才是能 scale 的正道。\n\n> 相关阅读: \n[分布式系统 in 2010s :存储之数据库篇](https://pingcap.com/zh/blog/distributed-system-in-2010s-1); \n[分布式系统 in 2010s :软件构建方式和演化](https://pingcap.com/zh/blog/distributed-system-in-2010s-2); \n> [分布式系统 in 2010s :硬件的进化](https://pingcap.com/zh/blog/distributed-system-in-2010s-3)。","date":"2020-01-14","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"distributed-system-in-2010s-4","file":null,"relatedBlogs":[]},{"id":"Blogs_237","title":"分布式系统 in 2010s :硬件的进化","tags":["分布式系统前沿技术"],"category":{"name":"观点洞察"},"summary":"本文为「分布式系统 in 2010s」 系列第三篇,这次我们来聊一聊硬件的进化。","body":"[上篇](https://pingcap.com/blog-cn/distributed-system-in-2010s-2/)我们聊了软件构建方式和演化,今天我们来聊聊硬件吧!\n\n## SSD 普及的深远影响\n\n如果说云的出现是一种商业模式的变化的话,驱动这个商业革命的推手就是最近十年硬件的快速更新。比起 CPU,存储和网络设备的进化速度更加迅速。最近五年,SSD 的价格 (包括 PCIe 接口) 的成本持续下降,批量采购的话已经几乎达到和 HDD 接近的价格。\n\n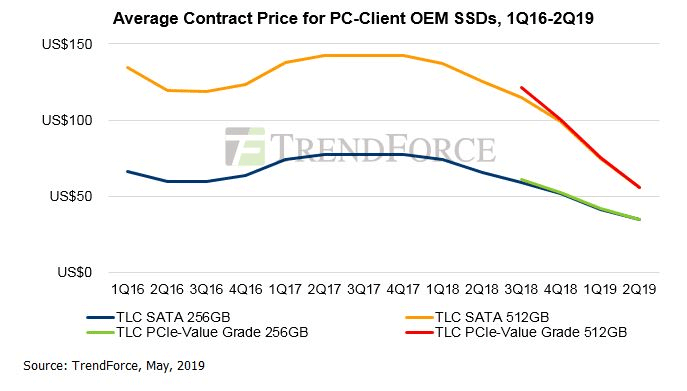\n\n 图 1 近 5 年 SSD 成本曲线
\n\nSSD 的普及,对于存储软件厂商的影响是深远的。\n\n其一,是极大地缓解了 IO 瓶颈。对于数据库厂商来说,可以将更多的精力花在其他事情,而不是优化存储引擎上。最近两年发生了一些更大的变化,NVMe 正在成为主流,我们很早就在 Intel Optane 进行实验和投资,类似这样的非易失内存的技术,正在模糊内存和存储的界限,但是同时对开发者带来挑战也是存在的。举一个简单的例子,对于 Optane 这类的非易失内存,如果你希望能够完全利用它的性能优势,最好使用类似 PMDK 这类基于 Page cache Bypass 的 SDK 针对你的程序进行开发,这类 SDK 的核心思想是将 NVM 设备真正地当做内存使用。如果仅仅将 Optane 挂载成本地磁盘使用,其实很大程度上的瓶颈不一定出现在硬件本身的 IO 上。\n\n下面这张图很有意思,来自 Intel 对于 Optane 的测试,我们可以看见在中间那一列,Storage with Optane SSD,随机读取的硬件延迟已经接近操作系统和文件系统带来的延迟,甚至 Linux VFS 本身会变成 CPU 瓶颈。其实背后的原因也很简单,过去由于 VFS 本身在 CPU 上的开销(比如锁)相比过去的 IO 来说太小了,但是现在这些新硬件本身的 IO 延迟已经低到让文件系统本身开销的比例不容忽视了。\n\n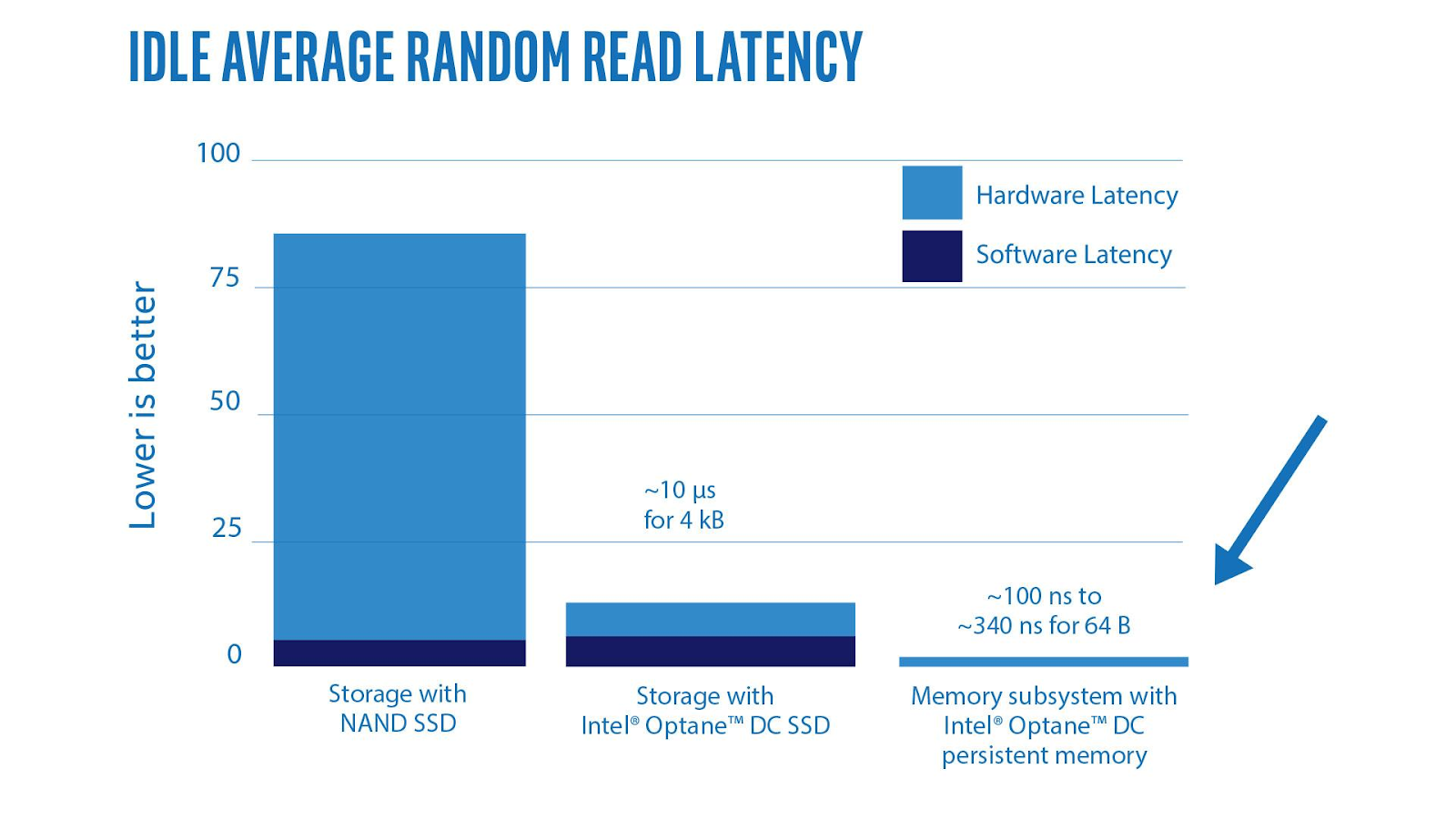\n\n 图 2 Intel 对于 Optane 的测试
\n\n其二,这个变化影响了操作系统和文件系统本身。例如针对 Persistent Memory 设计新的文件系统,其中来自 UCSD 的 NVSL 实验室 (名字很厉害, Non-Volatile Systems Laboratory) 的 [NovaFS](https://lwn.net/Articles/749009/) 就是一个很好的例子。简单来说是大量使用了无锁数据结构,减低 CPU 开销,NovaFS 的代码量很小很好读,有兴趣可以看看。另外 Intel 对 Persistent Memory 编程模型有很好的一篇[文章](https://software.intel.com/en-us/articles/introduction-to-programming-with-persistent-memory-from-intel),感兴趣的话可以从这里开始了解这些新变化。\n\n## 内核开销的挑战\n\n说完了存储设备,我们聊聊网络设备。我还记得我第一份工作的数据中心里甚至还有百兆的网卡,但现在,1GbE 已经都快淘汰光了,主流的数据中心基本上开始提供 10GbE 甚至 25GbE 的网络。为什么会变成这样?我们做一个简单的算术题就知道了。根据 Cisco 的[文档介绍](https://tools.cisco.com/security/center/resources/network_performance_metrics), 一块千兆网卡的吞吐大概是: [1,000,000,000 b/s / (84 B * 8 b/B)] == 1,488,096 f/s (maximum rate)。\n\n那么万兆网卡的吞吐大概是它的十倍,也就是差不多每秒 1488 万帧,处理一个包的时间在百纳秒的级别,基本相当于一个 L2 Cache Miss 的时间。所以如何减小内核协议栈处理带来的内核-用户态频繁内存拷贝的开销,成为一个很重要的课题,这就是为什么现在很多高性能网络程序开始基于 DPDK 进行开发。\n\n对于不了解 DPDK 的朋友,在这里[简单科普一下](https://www.dpdk.org/wp-content/uploads/sites/35/2016/10/Day02-Session05-JingjingWu-Userspace2016.pdf):\n\n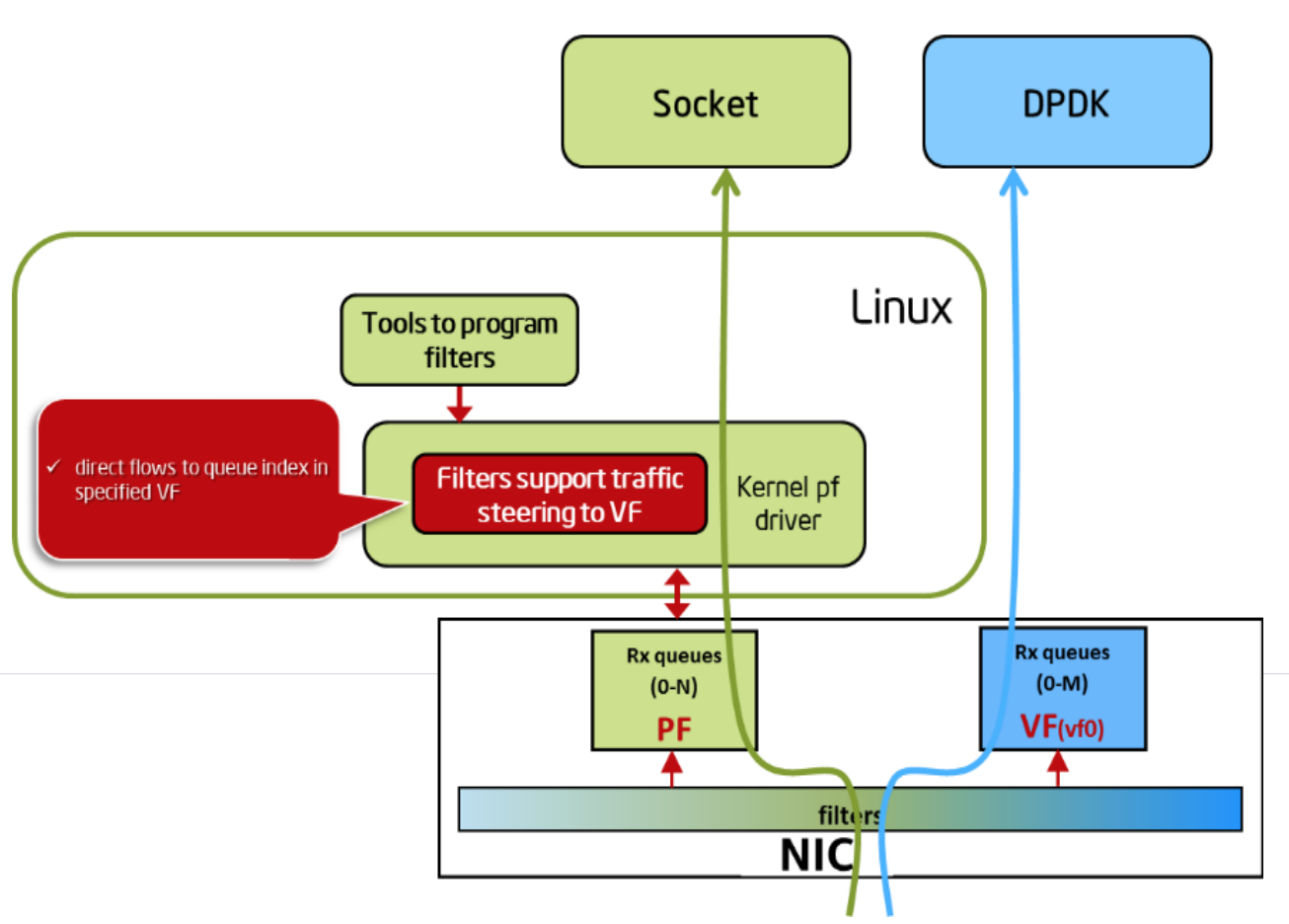\n\n 图 3 DPDK Flow Bifurcation
\n\n从上图可以看到,数据包直接从网卡到了 DPDK,绕过了操作系统的内核驱动、协议栈和 Socket Library。DPDK 内部维护了一个叫做 UIO Framework 的用户态驱动 (PMD),通过 ring queue 等技术实现内核到用户态的 zero-copy 数据交换,避免了 Syscall 和内核切换带来的 cache miss,而且在多核架构上通过多线程和绑核,极大提升了报文处理效率。如果你确定你的网络程序瓶颈在包处理效率上,不妨关注一下 DPDK。\n\n另外 RDMA 对未来体系结构的影响也会很大,它会让一个分布式集群向一个超级 NUMA 的架构演进(它的通信延时/带宽已经跟现在 NUMA 架构中连接不同 socket node 的 QPI 的延时/带宽在一个量级),但是目前受限于成本和开发模型的变化,可能还需要等很长一段时间才能普及。\n\n其实不管是 DPDK,SPDK,PMDK ,背后的主线都是 Bypass kernel,Linux 内核本身带来的开销已经很难适应现代硬件的发展,但是生态和兼容性依然是大的挑战,我对于一言不合就搞个 Bypass Kernel SDK 的做法其实是不太赞同的。大量的基础软件需要适配,甚至整个开发模型都要变化。\n\n我认为有关内核的问题,内核社区从长期来看一定会解决。一个值得关注的技术是 Linux 5.1 内核中引入的 io_uring 系列的新系统调用,io_uring 的原理简单来说就是通过两个内核/用户态共享的 ring buffer 来实现 IO 事件的提交以及收割,避免了 syscall 及内核<->用户态的内存拷贝,同时提供了 poll 的模式, 不用等待硬件中断,而是不断轮询硬件,这极大降低了 IO 延迟,提升了整体吞吐。 我认为 io_uring 的出现也代表了内核社区在各种 Bypass Kernel 技术涌现的当下,正在奋起直追。\n\n> 相关阅读: \n[分布式系统 in 2010s :存储之数据库篇](https://pingcap.com/zh/blog/distributed-system-in-2010s-1); \n[分布式系统 in 2010s :软件构建方式和演化](https://pingcap.com/zh/blog/distributed-system-in-2010s-2); \n> [分布式系统 in 2010s :测试和运维](https://pingcap.com/zh/blog/distributed-system-in-2010s-4)。","date":"2020-01-07","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"distributed-system-in-2010s-3","file":null,"relatedBlogs":[]},{"id":"Blogs_281","title":"分布式系统 in 2010s :软件构建方式和演化","tags":["分布式系统前沿技术"],"category":{"name":"观点洞察"},"summary":"本文为「分布式系统 in 2010s」系列第二篇,内容为软件构建的方式和演化。","body":"我上大学的时候专业是软件工程,当时的软件工程是 CMM、瀑布模型之类。十几年过去了,看看现在我们的软件开发模式,尤其是在互联网行业,敏捷已经成为主流,很多时候老板说业务下周上线,那基本就是怎么快怎么来,所以现代架构师对于可复用性和弹性会有更多的关注。我所知道业界对 SOA 的关注是从 Amazon 的大规模 SOA 化开始, 2002 年 Bezos 要求 Amazon 的工程团队将所有的业务 API 和服务化,[几条原则](https://www.cio.com/article/3218667/have-you-had-your-bezos-moment-what-you-can-learn-from-amazon.html)放在今天仍然非常适用:\n\n>- All teams will henceforth expose their data and functionality through service interfaces.\n>\n>- Teams must communicate with each other through these interfaces.\n>\n>- There will be no other form of inter-process communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.\n>\n>- It doesn’t matter what technology they use.\n>\n>- All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.\n\n尤其最后一条,我个人认为对于后来的 AWS 的诞生有直接的影响,另外这条也间接地对工程团队的软件质量和 API 质量提出了更高的要求。亚马逊在 SOA 上的实践是组件化在分布式环境中的延伸,尽可能地将业务打散成最细粒度的可复用单元(Services),新的业务通过组合的方式构建。这样的原则一直发展到今天,我们提到的微服务、甚至 Serverless,都是这个思想的延伸。\n\n## SOA 只是一个方法论\n\n很多人在思考 SOA 和微服务的区别时,经常有一些观点类似:「拆的粗就是 SOA,拆的细就是微服务 」,「使用 RESTful API 就是微服务,用 RPC 是 SOA」,「使用 XXX(可以是任何流行的开源框架) 的是微服务,使用 YYY 的是 SOA」... 这些观点我其实并不认可,我理解的 SOA 或者微服务只是一个方法论,核心在于有效地拆分应用,实现敏捷构建和部署,至于使用什么技术或者框架其实无所谓,甚至 SOA 本身就是反对绑定在某项技术上的。\n\n对于架构师来说, 微服务化也并不是灵丹妙药,有一些核心问题,在微服务化的实践中经常会遇到:\n\n1. 服务的拆分粒度到底多细?\n\n2. 大的单体服务如何避免成为单点,如何支持快速的弹性水平扩展?\n\n3. 如何进行流控和降级?防止调用者 DDoS?\n\n4. 海量服务背景下的 CI/CD (测试,版本控制,依赖管理),运维(包括 tracing,分布式 metric 收集,问题排查)\n\n … … \n \n上面几个问题都很大。熟悉多线程编程的朋友可能比较熟悉 Actor 模型,我认为 Actor 的思想和微服务还是很接近的,同样的最佳实践也可以在分布式场景下适用,事实上 Erlang OTP 和 Scala 的 Akka Framework 都尝试直接将 Actor 模型在大规模分布式系统中应用。其实在软件工程上这个也不是新的东西,Actor 和 CSP 的概念几乎在软件诞生之初就存在了,现在服务化的兴起我认为是架构复杂到一定程度后很自然的选择,就像当年 CSP 和 Actor 简化并发编程一样。\n\n## 服务化和云\n\n从服务化的大方向和基础设施方面来说,我们这几年经历了:本地单体服务 + 私有 API (自建数据中心,自己运维管理) -> 云 IaaS + 本地服务 + 云提供的 Managed Service (例如 EC2 + RDS) -> Serverless 的转变。其本质在于云的出现让开发者对于硬件控制力越来越低,算力和服务越来越变成标准化的东西。而容器的诞生,使得资源复用的粒度进一步的降低(物理机 -> VM -> Container),这无疑是云厂商非常希望看到的。对公有云厂商来说,资源分配的粒度越细越轻量,就越能精准地分配,以提升整体的硬件资源利用率,实现效益最大化。\n\n这里暗含着一个我的观点:公有云和私有云在价值主张和商业模式上是不一样的:对公有云来说,只有不断地规模化,通过不断提升系统资源的利用率,获取收益(比如主流的公有云几乎对小型实例都会超卖)。而私有云的模式可以概括成降低运维成本(标准化服务 + 自动化运维),对于自己拥有数据中心的企业来说,通过云技术提升硬件资源的利用率是好事,只是这个收益并没有公有云的规模化收益来得明显。\n\n在服务化的大背景下,也产生了另外一个趋势,就是基础软件的垂直化和碎片化,当然这也是和现在的 workload 变得越来越大,单一的数据库软件或者开发框架很难满足多变且极端的需求有关。数据库、对象存储、RPC、缓存、监控这几个大类,几乎每位架构师都熟悉多个备选方案,根据不同需求排列组合,一个 Oracle 包打天下的时代已经过去了。\n\n这样带来的结果是数据或状态在不同系统之间的同步和传递成为一个新的普遍需求,这就是为什么以 Kafka,Pulsar 为代表的分布式的消息队列越来越流行。但是在异构数据源之间的同步,暗含了异步和不一致(如果需要一致性,那么就需要对消费者实现幂等的语义),在一些对一致性有极端需求的场景,仍然需要交给数据库处理。 \n\n在这种背景下,容器的出现将计算资源分配的粒度进一步的降低且更加标准化,硬件对于开发者来说越来越透明,而且随着 workload 的规模越来越大,就带来的一个新的挑战:海量的计算单元如何管理,以及如何进行服务编排。既然有编排这里面还隐含了另外一个问题:服务的生命周期管理。\n\n## Kubernetes 时代开始了\n\n其实在 Kubernetes 诞生之前,很多产品也做过此类尝试,例如 Mesos。Mesos 早期甚至并不支持容器,主要设计的目标也是短任务(后通过 Marathon Framework 支持长服务),更像一个分布式的工作流和任务管理(或者是分布式进程管理)系统,但是已经体现了 Workload 和硬件资源分离的思想。\n\n在前 Kubernetes 时代,Mesos 的设计更像是传统的系统工程师对分布式任务调度的思考和实践,而 K8s 的野心更大,从设计之初就是要在硬件层之上去抽象所有类型的 workload,构建自己的生态系统。如果说 Mesos 还是个工具的话,那么 K8s 的目标其实是奔着做一个分布式操作系统去的。简单做个类比:整个集群的计算资源统一管控起来就像一个单机的物理计算资源,容器就像一个个进程,Overlay network 就像进程通信,镜像就像一个个可执行文件,Controller 就像 Systemd,Kubectl 就像 Shell……同样相似的类比还有很多。\n\n从另一方面看,Kubernetes 为各种 IaaS 层提供了一套标准的抽象,不管你底层是自己的数据中心的物理机,还是某个公有云的 VM,只要你的服务是构建在 K8s 之上,那么就获得了无缝迁移的能力。K8s 就是一个更加中立的云,在我的设想中,未来不管是公有云还是私有云都会提供标准 K8s 能力。对于业务来说,基础架构的上云,最安全的路径就是上 K8s,目前从几个主流的公有云厂商的动作上来看(GCP 的 GKE,AWS 的 EKS,Azure 的 AKS),这个假设是成立的。\n\n不选择 K8s 的人很多时候会从性能角度来攻击 K8s,理由是:多一层抽象一定会损害性能。对于这个我是不太同意的。从网络方面说,大家可能有个误解,认为 Overlay Network 的性能一定不好,其实这不一定是事实。下面这张图来自 ITNEXT 的工程师对几个流行的 CNI 实现的[评测](https://itnext.io/benchmark-results-of-kubernetes-network-plugins-cni-over-10gbit-s-network-36475925a560): \n\n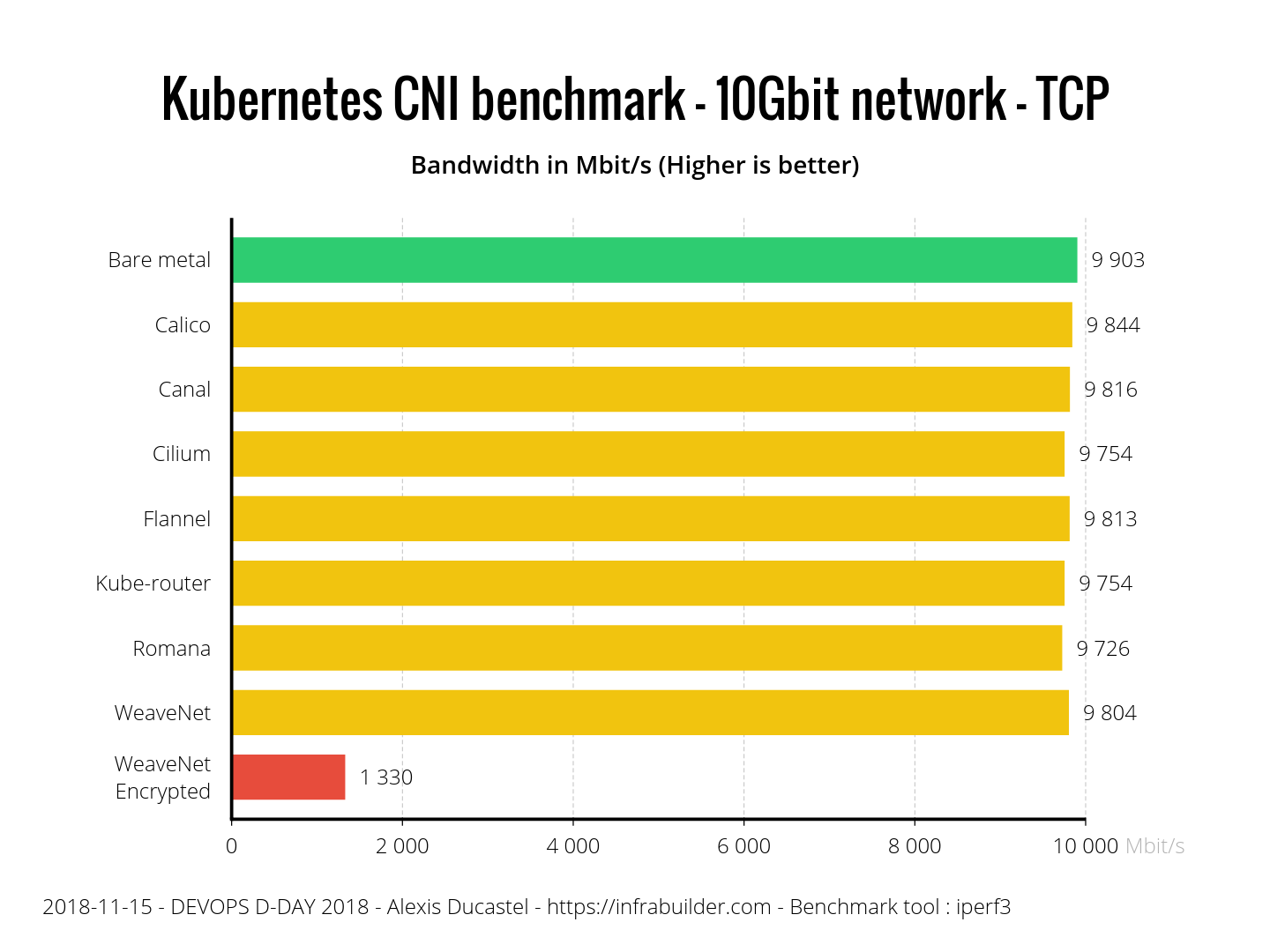\n\n Kubernetses CNI benchmark
\n\n我们其实可以看到,除了 WaveNet Encrypted 因为需要额外的加密导致性能不佳以外,其它的 CNI 实现几乎已经和 Bare metal 的 host network 性能接近,出现异常的网络延迟大多问题是出现在 iptable NAT 或者 Ingress 的错误配置上面。 \n\n所以软件的未来在哪里?我个人的意见是硬件和操作系统对开发者会更加的透明,也就是现在概念刚开始普及起来的 Serverless。我经常用的一个比喻是:如果自己维护数据中心,采购服务器的话,相当于买房;使用云 IaaS 相当于租房;而 Serverless,相当于住酒店。长远来看,这三种方案都有各自适用的范围,并不是谁取代谁的关系。目前看来 Serverless 因为出现时间最短,所以发展的潜力也是最大的。\n\n从服务治理上来说,微服务的碎片化必然导致了管理成本上升,所以近年 Service Mesh (服务网格)的概念才兴起。 服务网格虽然名字很酷,但是其实可以想象成就是一个高级的负载均衡器或服务路由。比较新鲜的是 Sidecar 的模式,将业务逻辑和通信解耦。我其实一直相信未来在七层之上,会有一层以 Service Mesh 和服务为基础的「八层网络」,不过目前并没有一个事实标准出现。Istio 的整体架构过于臃肿,相比之下我更加喜欢单纯使用 Envoy 或者 Kong 这样更加轻量的 API Proxy。 不过我认为目前在 Service Mesh 领域还没有出现有统治地位的解决方案,还需要时间。\n\n> 相关阅读: \n[分布式系统 in 2010s :存储之数据库篇](https://pingcap.com/zh/blog/distributed-system-in-2010s-1); \n[分布式系统 in 2010s :硬件的进化](https://pingcap.com/zh/blog/distributed-system-in-2010s-3); \n> [分布式系统 in 2010s :测试和运维](https://pingcap.com/zh/blog/distributed-system-in-2010s-4)。","date":"2019-12-30","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"distributed-system-in-2010s-2","file":null,"relatedBlogs":[]},{"id":"Blogs_27","title":"分布式系统 in 2010s :存储之数据库篇","tags":["分布式系统前沿技术"],"category":{"name":"观点洞察"},"summary":"无论哪个时代,存储都是一个重要的话题,今天先聊聊数据库。","body":"回看这几年,分布式系统领域出现了很多新东西,特别是云和 AI 的崛起,让这个过去其实不太 sexy 的领域一下到了风口浪尖,在这期间诞生了很多新技术、新思想,让这个古老的领域重新焕发生机。站在 2010s 的尾巴上,我想跟大家一起聊聊分布式系统令人振奋的进化路程,以及谈一些对 2020s 的大胆猜想。\n\n无论哪个时代,存储都是一个重要的话题,今天先聊聊数据库。在过去的几年,数据库技术上出现了几个很明显的趋势。\n\n## 存储和计算进一步分离\n\n我印象中最早的存储-计算分离的尝试是 Snowflake,Snowflake 团队在 2016 年发表的论文[《The Snowflake Elastic Data Warehouse》](http://pages.cs.wisc.edu/~remzi/Classes/739/Spring2004/Papers/p215-dageville-snowflake.pdf)是近几年我读过的最好的大数据相关论文之一,尤其推荐阅读。Snowflake 的架构关键点是在无状态的计算节点 + 中间的缓存层 + S3 上存储数据,计算并不强耦合缓存层,非常符合云的思想。从最近 AWS 推出的 RedShift 冷热分离架构来看,AWS 也承认 Snowflake 这个搞法是先进生产力的发展方向。另外这几年关注数据库的朋友不可能不注意到 Aurora。不同于 Snowflake,Aurora 应该是第一个将存储-计算分离的思想用在 OLTP 数据库中的产品,并大放异彩。Aurora 的成功在于将数据复制的粒度从 Binlog降低到 Redo Log ,极大地减少复制链路上的 IO 放大。而且前端复用了 MySQL,基本做到了 100% 的应用层 MySQL 语法兼容,并且托管了运维,同时让传统的 MySQL 适用范围进一步拓展,这在中小型数据量的场景下是一个很省心的方案。\n\n虽然 Aurora 获得了商业上的成功,但是从技术上,我并不觉得有很大的创新。熟悉 Oracle 的朋友第一次见 Aurora 的架构可能会觉得和 RAC 似曾相识。Oracle 大概在十几年前就用了类似的方案,甚至很完美的解决了 Cache Coherence 的问题。另外,Aurora 的 Multi-Master 还有很长的路要走,从最近在 ReInvent 上的说法来看,目前 Aurora 的 Multi-Master 的主要场景还是作为 Single Writer 的高可用方案,本质的原因应该是目前 Multi-Writer 采用乐观冲突检测,冲突检测的粒度是 Page,在冲突率高的场合会带来很大的性能下降。\n\n我认为 Aurora 是一个很好的迎合 90% 的公有云互联网用户的方案:100% MySQL 兼容,对一致性不太关心,读远大于写,全托管。但同时,Aurora 的架构决定了它放弃了 10% 有极端需求的用户,如全局的 ACID 事务+ 强一致,Hyper Scale(百 T 以上,并且业务不方便拆库),需要实时的复杂 OLAP。这类方案我觉得类似 TiDB 的以 Shared-nothing 为主的设计才是唯一的出路。作为一个分布式系统工程师,我对任何不能水平扩展的架构都会觉得不太优雅。\n\n## 分布式 SQL 数据库登上舞台,ACID 全面回归\n\n回想几年前 NoSQL 最风光的时候,大家恨不得将一切系统都使用 NoSQL 改造,虽然易用性、扩展性和性能都不错,但是多数 NoSQL 系统抛弃掉数据库最重要的一些东西,例如 ACID 约束,SQL 等等。NoSQL 的主要推手是互联网公司,对于互联网公司的简单业务加上超强的工程师团队来说当然能用这些简单工具搞定。\n\n但最近几年大家渐渐发现低垂的果实基本上没有了,剩下的都是硬骨头。\n\n最好的例子就是作为 NoSQL 的开山鼻祖,Google 第一个搞了 NewSQL (Spanner 和 F1)。在后移动时代,业务变得越来越复杂,要求越来越实时,同时对于数据的需求也越来越强。尤其对于一些金融机构来说,一方面产品面临着互联网化,一方面不管是出于监管的要求还是业务本身的需求,ACID 是很难绕开的。更现实的是,大多数传统公司并没有像顶级互联网公司的人才供给,大量历史系统基于 SQL 开发,完全迁移到 NoSQL 上肯定不现实。\n\n在这个背景下,分布式关系型数据库,我认为这是我们这一代人,在开源数据库这个市场上最后一个 missing part,终于慢慢流行起来。这背后的很多细节由于篇幅的原因我就不介绍,推荐阅读 PingCAP TiFlash 技术负责人 maxiaoyu 的一篇文章《[从大数据到数据库](https://pingcap.com/zh/blog/from-big-data-to-databases)》,对这个话题有很精彩的阐述。\n\n## 云基础设施和数据库的进一步整合\n\n在过去的几十年,数据库开发者都像是在单打独斗,就好像操作系统以下的就完全是黑盒了,这个假设也没错,毕竟软件开发者大多也没有硬件背景。另外如果一个方案过于绑定硬件和底层基础设施,必然很难成为事实标准,而且硬件非常不利于调试和更新,成本过高,这也是我一直对定制一体机不是太感兴趣的原因。但是云的出现,将 IaaS 的基础能力变成了软件可复用的单元,我可以在云上按需地租用算力和服务,这会给数据库开发者在设计系统的时候带来更多的可能性,举几个例子:\n\n1. Spanner 原生的 TrueTime API 依赖原子钟和 GPS 时钟,如果纯软件实现的话,需要牺牲的东西很多(例如 CockroachDB 的 HLC 和 TiDB 的改进版 Percolator 模型,都是基于软件时钟的事务模型)。但是长期来看,不管是 AWS 还是 GCP 都会提供类似 TrueTime 的高精度时钟服务,这样一来我们就能更好的实现低延迟长距离分布式事务。\n\n2. 可以借助 Fargate + EKS 这种轻量级容器 + Managed K8s 的服务,让我们的数据库在面临突发热点小表读的场景(这个场景几乎是 Shared-Nothing 架构的老大难问题),比如在 TiDB 中通过 Raft Learner 的方式,配合云的 Auto Scaler 快速在新的容器中创建只读副本,而不是仅仅通过 3 副本提供服务;比如动态起 10 个 pod,给热点数据创建 Raft 副本(这是我们将 TiKV 的数据分片设计得那么小的一个重要原因),处理完突发的读流量后再销毁这些容器,变成 3 副本。\n\n3. 冷热数据分离,这个很好理解,将不常用的数据分片,分析型的副本,数据备份放到 S3 上,极大地降低成本。\n\n4. RDMA/CPU/超算 as a Service,任何云上的硬件层面的改进,只要暴露 API,都是可以给软件开发者带来新的好处。\n\n例子还有很多,我就不一一列举了。总之我的观点是云服务 API 的能力会像过去的代码标准库一样,是大家可以依赖的东西,虽然现在公有云的 SLA 仍然不够理想,但是长远上看,一定是会越来越完善的。\n\n所以,数据库的未来在哪里?是更加的垂直化还是走向统一?对于这个问题,我同意这个世界不存在银弹,但是我也并不像我的偶像,AWS 的 CTO,Vogels 博士那么悲观,相信未来是一个割裂的世界(AWS 恨不得为了每个细分的场景设计一个数据库)。过度地细分会加大数据在不同系统中流动的成本。解决这个问题有两个关键:\n\n1. 数据产品应该切分到什么粒度?\n\n2. 用户可不可以不用知道背后发生了什么?\n\n第一个问题并没有一个明确的答案,但是我觉得肯定不是越细越好的,而且这个和 Workload 有关,比如如果没有那么大量的数据,直接在 MySQL 或者 PostgreSQL 上跑分析查询其实一点问题也没有,没有必要非去用 Redshift。虽然没有直接的答案,但是我隐约觉得第一个问题和第二个问题是息息相关的,毕竟没有银弹,就像 OLAP 跑在列存储引擎上一定比行存引擎快,但是对用户来说其实可以都是 SQL 的接口。\n\nSQL 是一个非常棒的语言,它只描述了用户的意图,而且完全与实现无关,对于数据库来说,其实可以在 SQL 层的后面来进行切分,在 TiDB 中,我们引入 TiFlash 就是一个很好的例子。动机很简单:\n\n1. 用户其实并不是数据库专家,你不能指望用户能 100% 在恰当的时间使用恰当的数据库,并且用对。\n\n2. 数据之间的同步在一个系统之下才能尽量保持更多的信息,例如,TiFlash 能保持 TiDB 中事务的 MVCC 版本,TiFlash 的数据同步粒度可以小到 Raft Log 的级别。\n\n另外一些新的功能仍然可以以 SQL 的接口对外提供,例如全文检索,用 SQL 其实也可以简洁的表达。这里我就不一一展开了。\n\n我其实坚信系统一定是朝着更智能、更易用的方向发展的,现在都 21 世纪了,你是希望每天拿着一个 Nokia 再背着一个相机,还是直接一部手机搞定?\n\n> 相关阅读: \n[分布式系统 in 2010s :软件构建方式和演化](https://pingcap.com/zh/blog/distributed-system-in-2010s-2); \n[分布式系统 in 2010s :硬件的进化](https://pingcap.com/zh/blog/distributed-system-in-2010s-3); \n> [分布式系统 in 2010s :测试和运维](https://pingcap.com/zh/blog/distributed-system-in-2010s-4)。","date":"2019-12-26","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"distributed-system-in-2010s-1","file":null,"relatedBlogs":[]},{"id":"Blogs_123","title":"从大数据到数据库","tags":["大数据","数据库"],"category":{"name":"观点洞察"},"summary":"作为一个从大数据转行做数据库的人,我自以为能感受到两个世界的异同。本篇文章,斗胆聊下这个话题,以及对未来的看法。","body":"作为一个从大数据转行做数据库的人,我自以为能感受到两个世界的异同。在这里,斗胆聊下这个话题,以及对未来的看法。\n\n## 大数据兴起\n\n从 70 年代关系型数据库进入历史舞台,很长一段时间它几乎是包打天下的选择。你很可能可以用一套数据库玩转所有业务,你也不需要一个连的工程师来维护她。哪怕你也许业务复杂,需要不同的数据库,但她们终究是还是数据库,温柔体贴。\n\n这个黄金时代整整延续了 20 多年。\n\n上世纪 90 年代人们开始讨论「Big Data」。SGI 首席科学家 John Mashey 在一个名为「[Big Data… and the Next Wave of Infrastress](https://static.usenix.org/event/usenix99/invited_talks/mashey.pdf)」让这个词汇变得流行。那个时候,人们讨论着硬盘容量和网络带宽,在未来数据爆炸的阴影下瑟瑟发抖。那个时候,互联网公司是第一批真正尝试解决大数据问题的先行者。有别传统的运营方式让它们率先面对了大数据时代[著名的 3V 问题](https://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf)(By Gartner)。\n\n* 容量(Volumn):爆炸性的交易量带来爆炸性的数据容量。\n\n* 速度(Velocity):和在这个规模下仍提供高速的数据应用。\n\n* 多样性(Variety): 以及为了支持业务变更和复杂性所造成的数据多样性。\n\n与传统公司不同,互联网公司的数据单位价值偏低,但数据量极其庞大。而且它们并不一定是结构化的,并非完全能用 SQL 来处理。简而言之,它们已经超出了当时数据库的能力边界。而当时的互联网公司巨头们如 Google 和 Amazon,纷纷选择抛弃了传统手段,重起炉灶,由此拉开了「大数据」时代的大幕。\n\n有兴趣的童鞋,可以翻翻下面的论文:\n\n* [The Google File System](https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf) - 2003\n\n* [MapReduce: Simplified Data Processing on Large Clusters](https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf) - 2004\n\n* [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf) - 2006\n\n* [Dynamo: Amazon’s Highly Available Key-value Store](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf) - 2007\n\n也许你并不了解 GFS,Google 内的 MapReduce 或者 BigTable 具体是什么样子的。不过相信既然你看到了这里,你一定听说过 Apache Hadoop 和 NoSQL。Hadoop 加上属于 NoSQL 的 HBase,就是以上面 Google 的几篇论文为基础开发而成的。这是一个真正现象级的开源通用大规模分布式数据存储和处理套件。它的影响力是巨大的,稍具规模的互联网公司就不得不用,稍有经验的从业者就可以领取不菲的薪水,人人都以能向其提交一个补丁为荣,更不用提一个实打实的 Committer,你都可以从他脑后看到光环。不管现在多少人宣称 Hadoop 已死,XXX 是真理,但是以 Hadoop + NoSQL 为基础,所谓大数据基础架构所带来的想法变迁,一直延续到了今天,且并没有太大变化:\n\n* 选用白菜价的硬件组成集群,突出 Scale Out 而非 Scale Up。\n\n* 极度简化和粗暴的计算模型。\n\n* 几乎不经整理的存储格式,在多种引擎之间共享,所谓数据湖。\n\n* 忽略 / 弱化一致性,抛弃关系模型,简化甚至无视事务,所谓 NoSQL。\n\n你可以说这是开源社区的威力,但追根究底还是 Google,Amazon 这些先行者卓有远见的工作为大家铺平了道路。不过,有些反直觉的是:这些引用数几千几万的论文其实并没有提出巧夺天工的设计;相反,它们本质上是告诉了业界,把数据库换成设计如此粗糙狂野的架构,仍然可以解决问题:就算你没钱买超高端的软硬件,只要你放宽心,告诉自己,无视一致性,忘掉精巧的优化执行器和存储结构,忽略半结构化带来的混乱,干掉 SQL 语言,多雇几个码农,你仍然活的下去,而且可以活的还不错。\n\n这些到底为我们带来了什么?且看曾经非常著名的 Sort Benchmark。\n\n* 2004 年,NEC Express 5800 / 1320 Xd 单机,价格可能介于 200-600 万 USD 之间,1 分钟排序 34G。\n\n* 2006 年,Fujitsu PrimeQuest 480 单机,2 年将结果推高 6G,1 分钟排序 40G 数据;机器价格不可考。\n\n* 2007 年,麻省理工林肯国防实验室,Bradley C. Kuszmaul 使用 TX-2500 磁盘集群(550 万 + USD),440 节点用 Infiband 串联,使用了自制系统(文件系统,通信模块),在经历了无数硬件软件故障之后,一分钟内排序了 214GB 数据;该试验相比之前的超豪华服务器,已经开始使用「便宜硬件」,但是使用自制软件系统。\n\n* 2009年,Yahoo! 使用 Hadoop 以近似的总价(500 万 USD,以单价反推)但近 1/3 的单价串联了 1400 个白菜价节点集群,得到了一倍多的速度,排序了 500G。而这里 1400 的节点数是为了凑整 500G / 1 分钟,而非只能这么多或者必须这么多。\n\n请允许我用一句诗来总结它的意义:「旧时王谢堂前燕,飞入寻常百姓家」。\n\n## 王之蔑视\n\n与业界的欢腾不同,当时数据库研究者圈子对此的反应已经不是嗤之以鼻,而是痛心疾首了。这有点像,老师傅练了一辈子武艺,你突然告诉他,打架只要抡大锤就行了。\n\n[MapReduce: A major step backwards](https://homes.cs.washington.edu/~billhowe/mapreduce_a_major_step_backwards.html) by David DeWitt & Michael Stonebraker\n\n上面这篇文章是 DeWitt 和 Stonebraker 大神合写的对 MapReduce 的批评。这两尊是真神,DeWitt 是美国工程院院士,微软 Jim Gray 实验室老大,而石破天,则是图灵奖获得者。在他们看来,这破玩意抛弃了数据库所有美好的特点,实现也丑陋,还接不上数据库工具,简直臭不可闻。文末,老人家们「酸酸」地说,我们很高兴看到社区对这些技术感兴趣,但是也别把我们几十年的研究成果当 X 啊。\n\n\n\n两位的评论,哪怕延伸到整个大数据生态,就算放到时隔多年的今天,也还是套的上去。但这套糙快猛的理念催生的技术栈,已经无需赘述获得了多大的成功。哪怕是数据库圈内的人,也时有抱怨:老一辈的人有时候不够 Open-Minded。所以,他们说错了么?\n\n也许他们对业界面临的困扰不够感同身受,也许他们不够有包容心。不过,他们对技术的判断着实是精准到位的。\n\n事实上,没过多久,人们在大数据体系中引入了 SQL、MPP 引擎、列存,加入了向量化、JIT,实现了 CBO。对于数据库圈外的童鞋们,有时你看社区兴高采烈地宣称,他们实现了多么神奇的技术,仿佛普罗米修斯从天上带来了火种,其实他们只是从十几甚至几十年前的故纸堆中汲取了养分。\n\n是大数据社区的人无知无能因此重新「发明」数据库界玩烂的技术么?不,只是因为业界等不了数据库圈子慢慢悠悠匠心打磨:没有合适的工具,他们每分每秒都在损失 $。且不说大规模分布式交易型数据库一直是老大难,就算脱开交易型场景不谈,分布式的分析型数据库早已有之,却也因为包袱沉重,还没来得及跟上时代的步伐,就被大数据的浪头打的狼狈不堪。Pivotal 先是由 Greenplum 折腾了对接 Hadoop 的 HAWQ ,继而被迫双双开源;就连 Teradata 这样的巨擘也不得不支持 Hadoop。\n\n只是,一旦社区步入小康,虽是野蛮生长的生态,也还是阻挡不了人们追求小资生活的决心:用户希望友好、快速、高效、稳定的数据存储和处理手段,这是亘古不变的需求。而这些,恰恰是数据库领域多年积累所在。\n\n\n\n摘自 pramodgampa.blogspot.com
\n\n现今的大数据生态,如同哥斯拉,强大而难以驯服。不管什么场景,似乎都经不起它尾巴一扫。但若说干净灵巧地解决问题,却是难如登天。毕竟狂野粗放基因的产物,不管如何演化,都很难优雅起来。对数据湖而言,开放形态加上公共存储格式,能轻易串联多种引擎,但也几乎抹杀了精细整理数据的可能;而混沌的存储体系和不受控的数据入口,也限制了整个体系可以伸展腾挪的空间。对 NoSQL 而言,孱弱或者干脆不存在的事务,所谓最终一致性,小儿科的 SQL 支持,也都成为人们诟病的理由。而整个圈子野蛮生长的开放体系,在得到巨大动能的同时,也使得用户体验几乎不可能良好。这些种种,使得大数据生态很大程度上都只服务于工程师,而你需要一大票专家才能真的驯服大数据平台。从这个角度看,MapR 变卖家当给 HP,Hortonworks 被收购,Cloudera 巨亏股价狂泻,都是必然的:大数据生态基本不可能做成类似 Oracle 这样的标准件生意。\n\n也许,更偏向于数据库形态的方案,才是更友善的方案;也许,随着技术的成熟,我们还有机会回到黄金时代。\n\n## 回归数据库\n\n随着时间的推进,Google 这样的巨人自己也忍受不了自己创造的怪物,又开始了新的探索:哪怕是 Google 这样聪明脑袋汇聚的地方,也不想总是需要自己花心思处理一致性,或者用繁琐的代码实现 SQL 逻辑。\n\n[Spanner: Google’s Globally-Distributed Database](https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf) - 2012\n\nSpanner 是一个能像 NoSQL 一样延展(甚至横跨多个大陆),但却支持传统数据库事务的分布式交易型数据库。它创造性地用原子钟解决了以往分布式事务一致性需要依赖中心节点,因而无法大规模扩展的问题。这算是拉开了所谓 NewSQL 的大幕。这启发了很多项目,比如小强,比如我们的 TiDB。她们拥有对业务透明的 Sharding 设计和分布式事务,良好的可扩容性,又兼顾了一致性,这让分布式体系很大程度上拥有单机数据库近似的用户体验。不过有意思的是,哪怕论文最创新的点是基于原子钟的分布式事务,但是对很多人来说,它更大的意义仍然是:证明给一个类似 NoSQL 架构加上传统数据库特性,用来做传统数据库业务,是可行的(当然共识算法 Paxos / Raft 的应用也很重要)。天知道这背后经历了多少试错,这就是先行者的伟大。\n\n至此,业界也许可以说解决了整个体系中最难啃的问题:分布式交易型数据库。而随着技术不断成熟,人们也逐渐开始接受这个新鲜事物:光就 TiDB 而言,从第一个用户拿来做并不那么 TP 的边缘业务,到现在登上银行核心系统。也许你在刷二维码付费的时候,背后支撑你这笔交易的数据库就是 TiDB。\n\n对我们来说,现有的 Multi-Raft 体系,提供了可自由伸缩,对用户透明的分片体系,以及可均衡的并行复制机制。以这些为基础,通过 Raft Learner 将数据从 TP 行存到 AP 列存进行异步异构复制但提供一致性读取,我们得以整合了 TP 和 ODS 层,而且互相之间不影响,这就是今年我们折腾的 TiFlash。希望明年能尝试进一步同样通过 Raft 协议将列存引擎延伸到传统的数仓业务,而统一更多场景。很多人不相信最终数据库能做到一站式服务(Silver Bullet),能简化到一个产品,去除平台间数据的迁移。毕竟,有些设计的取舍很难兼顾。我个人的看法是,也许,但通过小心的设计,我们现在已经可以做到将不同的引擎无缝地整合到一个产品中。毕竟,经过这十多年的大数据浪潮,哪怕浪不再那么高,社区终究沉淀下了宝贵的财富,前人设计的得失也好,强大的开源引擎如 Spark 也好(Spark 已经慢慢脱离野蛮生态直通云霄了),甚至更多有经验的小伙伴也好,这都成为我们能借力的抓手,让我们能有勇气挑战似乎不切实际的目标:让用户从大数据生态复杂的技术栈解放出来,让数据平台收敛到单一一个产品,因为这才是数据处理应有的模样,哪怕这是一条很长很长的路。","date":"2019-12-18","author":"马晓宇","fillInMethod":"writeDirectly","customUrl":"from-big-data-to-databases","file":null,"relatedBlogs":[]},{"id":"Blogs_115","title":"高效编排有状态应用——TiDB 的云原生实践与思考","tags":["TiDB Operator","云原生"],"category":{"name":"观点洞察"},"summary":"本文将以 TiDB 与 Kubernetes 的“爱恨情仇”为例,总结有状态应用走向云原生的工程最佳实践。","body":"## 导语\n\n云原生时代以降,无状态应用以其天生的可替换性率先成为各类编排系统的宠儿。以 Kubernetes 为代表的编排系统能够充分利用云上的可编程基础设施,实现无状态应用的弹性伸缩与自动故障转移。这种基础能力的下沉无疑是对应用开发者生产力的又一次解放。 然而,在轻松地交付无状态应用时,我们应当注意到,状态本身并没有消失,而是按照各类最佳实践下推到了底层的数据库、对象存储等有状态应用上。那么,“负重前行”的有状态应用是否能充分利云与 Kubernetes 的潜力,复制无状态应用的成功呢?\n\n或许你已经知道,Operator 模式已经成为社区在 Kubernetes 上编排有状态应用的最佳实践,脚手架项目 KubeBuilder 和 operator-sdk 也已经愈发成熟,而对磁盘 IO 有严苛要求的数据库等应用所必须的 Local PV(本地持久卷)也已经在 1.14 中 GA。这些积木似乎已经足够搭建出有状态应用在平稳运行在 Kubernetes 之上这一和谐景象。然而,书面上的最佳实践与生产环境之间还有无数工程细节造就的鸿沟,要在 Kubernetes 上可靠地运行有状态应用仍需要相当多的努力。下面我将以 TiDB 与 Kubernetes 的“爱恨情仇”为例,总结有状态应用走向云原生的工程最佳实践。\n\n## TiDB 简介\n\n首先让我们先熟悉熟悉研究对象。TiDB 是一个分布式的关系型数据库,它采用了存储和计算分离的架构,并且分层十分清晰:\n\n\n\n图 1 TiDB 架构
\n\n其中 TiDB 是 SQL 计算层,TiDB 进程接收 SQL 请求,计算查询计划,再根据查询计划去查询存储层完成查询。\n\n存储层就是图中的 TiKV,TiKV 会将数据拆分为一个个小的数据块,比如一张 1000000 行的表,在 TiKV 中就有可能被拆分为 200 个 5000 行的数据块。这些数据块在 TiKV 中叫做 Region,而为了确保可用性, 每个 Region 都对应一个 Raft Group,通过 Raft Log 复制实现每个 Region 至少有三副本。\n\n\n\n图 2 TiKV Region 分布
\n\n而 PD 则是集群的大脑,它接收 TiKV 进程上报的存储信息,并计算出整个集群中的 Region 分布。借由此,TiDB 便能通过 PD 获知该如何访问某块数据。更重要的是,PD 还会基于集群 Region 分布与负载情况进行数据调度。比如,将过大的 Region 拆分为两个小 Region,避免 Region 大小由于写入而无限扩张;将部分 Leader 或数据副本从负载较高的 TiKV 实例迁移到负载较低的 TiKV 实例上,以最大化集群性能。这引出了一个很有趣的事实,也就是 TiKV 虽然是存储层,但它可以非常简单地进行水平伸缩。这有点意思对吧?在传统的存储中,假如我们通过分片打散数据,那么加减节点数往往需要重新分片或手工迁移大量的数据。而在 TiKV 中,以 Region 为抽象的数据块迁移能够在 PD 的调度下完全自动化地进行,而对于运维而言,只管加机器就行了。\n\n**了解有状态应用本身的架构与特性是进行编排的前提,比如通过前面的介绍我们就可以归纳出,TiDB 是无状态的,PD 和 TiKV 是有状态的,它们三者均能独立进行水平伸缩。我们也能看到,TiDB 本身的设计就是云原生的——它的容错能力和水平伸缩能力能够充分发挥云基础设施提供的弹性,既然如此,云原生“操作系统” Kubernetes 不正是云原生数据库 TiDB 的最佳载体吗?TiDB Operator 应运而生。**\n\n## TiDB Operator 简介\n\nOperator 大家都很熟悉了,目前几乎每个开源的存储项目都有自己的 Operator,比如鼻祖 etcd-operator 以及后来的 prometheus-operator、postgres-operator。Operator 的灵感很简单,Kubernetes 自身就用 Deployment、DaemonSet 等 API 对象来记录用户的意图,并通过 control loop 控制集群状态向目标状态收敛,那么我们当然也可以定义自己的 API 对象,记录自身领域中的特定意图,并通过自定义的 control loop 完成状态收敛。\n\n在 Kubernetes 中,添加自定义 API 对象的最简单方式就是 CustomResourceDefinition(CRD),而添加自定义 control loop 的最简单方式则是部署一个自定义控制器。自定义控制器 + CRD 就是 Operator。具体到 TiDB 上,用户可以向 Kubernetes 提交一个 TidbCluster 对象来描述 TiDB 集群定义,假设我们这里描述说“集群有 3 个 PD 节点、3 个 TiDB 节点和 3 个 TiKV 节点”,这是我们的意图。 而 TiDB Operator 中的自定义控制器则会进行一系列的 Kubernetes 集群操作,比如分别创建 3 个 TiKV、TiDB、PD Pod,来让真实的集群符合我们的意图。\n\n\n\n图 3 TiDB Operator
\n\nTiDB Operator 的意义在于让 TiDB 能够无缝运行在 Kubernetes 上,而 Kubernetes 又为我们抽象了基础设施。因此,TiDB Operator 也是 TiDB 多种产品形态的内核。对于希望直接使用 TiDB Operator 的用户, TiDB Operator 能做到在既有 Kubernetes 集群或公有云上开箱即用;而对于不希望有太大运维负载,又需求一套完整的分布式数据库解决方案的用户,我们则提供了打包 Kubernetes 的 on-premise 部署解决方案,用户可以直接通过方案中打包的 GUI 操作 TiDB 集群,也能通过 OpenAPI 将集群管理能力接入到自己现有的 PaaS 平台中;另外,对于完全不想运维数据库,只希望购买 SQL 计算与存储能力的用户,我们则基于 TiDB Operator 提供托管的 TiDB 服务,也即 DBaaS(Database as a Service)。\n\n\n\n图 4 TiDB Operator 的多种上层产品形态
\n\n多样的产品形态对作为内核的 TiDB Operator 提出了更高的要求与挑战——事实上,由于数据资产的宝贵性和引入状态后带来的复杂性,有状态应用的可靠性要求与运维复杂度往往远高于无状态应用,这从 TiDB Operator 所面临的挑战中就可见一斑。\n\n## 挑战\n\n描绘架构总是让人觉得美好,而生产中的实际挑战则将我们拖回现实。\n\n**TiDB Operator 的最大挑战就是数据库的场景极其严苛,大量用户的期盼都是我的数据库能够“永不停机”,对于数据不一致或丢失更是零容忍**。很多时候大家对于数据库等有状态应用的可用性要求甚至是高于承载线上服务的 Kubernetes 集群的,至少线上集群宕机还能补救,而数据一旦出问题,往往意味着巨大的损失和补救成本,甚至有可能“回天乏术”。这本身也会在很大程度上影响大家把有状态应用推上 Kubernetes 的信心。\n\n**第二个挑战是编排分布式系统这件事情本身的复杂性**。Kubernetes 主导的 level driven 状态收敛模式虽然很好地解决了命令式编排在一致性、事务性上的种种问题,但它本身的心智模型是更为抽象的,我们需要考虑每一种可能的状态并针对性地设计收敛策略,而最后的实际状态收敛路径是随着环境而变化的,我们很难对整个过程进行准确的预测和验证。假如我们不能有效地控制编排层面的复杂度,最后的结果就是没有人能拍胸脯保证 TiDB Operator 能够满足上面提到的严苛挑战,那么走向生产也就无从谈起了。\n\n**第三个挑战是存储**。数据库对于磁盘和网络的 IO 性能相当敏感,而在 Kubernetes 上,最主流的各类网络存储很难满足 TiDB 对磁盘 IO 性能的要求。假如我们使用本地存储,则不得不面对本地存储的易失性问题——磁盘故障或节点故障都会导致某块存储不可用,而这两种故障在分布式系统中是家常便饭。\n\n**最后的问题是,尽管 Kubernetes 成功抽象了基础设施的计算能力与存储能力,但在实际场景的成本优化上考虑得很少**。对于公有云、私有云、裸金属等不同的基础设施环境,TiDB Operator 需要更高级、特化的调度策略来做成本优化。大家也知道,成本优化是没有尽头的,并且往往伴随着一些牺牲,怎么找到优化过程中边际收益最大化的点,同样也是非常有意思的问题之一。\n\n其中,场景严苛可以作为一个前提条件,而针对性的成本优化则不够有普适性。我们接下来就从编排和存储两块入手,从实际例子来看 TiDB 与 TiDB Operator 如何解决这些问题,并推广到一般的有状态应用上。\n\n## 控制器——剪不断,理还乱\n\nTiDB Operator 需要驱动集群向期望状态收敛,而最简单的驱动方式就是创建一组 Pod 来组成 TiDB 集群。通过直接操作 Pod,我们可以自由地控制所有编排细节。举例来说,我们可以:\n\n* 通过替换 Pod 中容器的 image 字段完成原地升级。\n\n* 自由决定一组 Pod 的升级顺序。\n\n* 自由下线任意 Pod。\n\n事实上我们也确实采用过完全操作 Pod 的方案,但是当真正推进该方案时我们才发现,这种完全“自己造轮子”的方案不仅开发复杂,而且验证成本非常高。试想,为什么大家对 Kubernetes 的接受度越来越高, 即使是传统上较为保守的公司现在也敢于拥抱 Kuberentes?除了 Kubernetes 本身项目素质过硬之外,更重要的是有整个社区为它背书。我们知道 Kubernetes 已经在各种场景下经受过大量的生产环境考验,这种信心是各类测试手段都没法给到我们的。回到 TiDB Operator 上,选择直接操作 Pod 就意味着我们抛弃了社区在 StatefulSet、Deployment 等对象中沉淀的编排经验,随之带来的巨大验证成本大大影响了整个项目的开发效率。\n\n因此,在目前的 TiDB Operator 项目中,大家可以看到控制器的主要操作对象是 StatefulSet。StatefulSet 能够满足有状态应用的大部分通用编排需求。当然,StatefulSet 为了做到通用化,做了很多不必要的假设,比如高序号的 Pod 是隐式依赖低序号 Pod 的,这会给我们带来一些额外的限制,比如:\n\n+ 无法指定 Pod 进行下线缩容。\n+ 滚动更新顺序固定。\n+ 滚动更新需要后驱 Pod 全部 Ready。\n\nStatefulSet 和 Pod 的抉择,最终是灵活性和可靠性的权衡,而在 TiDB 面临的严苛场景下,我们只有先做到可靠,才能做开发、敢做开发。最后的选择自然就呼之欲出——StatefulSet。当然,这里并不是说,使用基于高级对象进行编排的方案要比基于 Pod 进行编排的方案更好,只是说我们在当时认为选择 StatefulSet 是一个更好的权衡。当然这个故事还没有结束,当我们基于 StatefulSet 把第一版 TiDB Operator 做稳定后,我们正在接下来的版本中开发一个新的对象来水平替换 StatefulSet,这个对象可以使用社区积累的 StatefulSet 测试用例进行验证,同时又可以解除上面提到的额外限制,给我们提供更好的灵活性。 假如你也在考虑从零开始搭建一个 Operator,或许也可以参考“先基于成熟的原生对象快速迭代,在验证了价值后再增强或替换原生对象来解决高级需求”这条落地路径。\n\n接下来的问题是控制器如何协调基础设施层的状态与应用层的状态。举个例子,在滚动升级 TiKV 时,每次重启 TiKV 实例前,都要先驱逐该实例上的所有 Region Leader;而在缩容 TiKV 时,则要先在 PD 中将待缩容的 TiKV 下线,等待待缩容的 TiKV 实例上的 Region 全部迁移走,PD 认为 TiKV 下线完成时,再真正执行缩容操作调整 Pod 个数。这些都是在编排中协调应用层状态的例子,我们可以怎么做自动化呢?\n\n大家也注意到了,上面的例子都和 Pod 下线挂钩,因此一个简单的方案就通过 container lifecycle hook,在 preStop 时执行一个脚本进行协调。这个方案碰到的第一个问题是缺乏全局信息,脚本中无法区分当前是在滚动升级还是缩容。当然,这可以通过在脚本中查询 apiserver 来绕过。更大的问题是 preStop hook 存在 grace period,kubelet 最多等待 .spec.terminationGracePeriodSeconds 这么长的时间,就会强制删除 Pod。对于 TiDB 的场景而言,我们更希望在自动的下线逻辑失败时进行等待并报警,通知运维人员介入,以便于最小化影响,因此基于 container hook 来做是不可接受的。\n\n第二种方案是在控制循环中来协调应用层的状态。比如,我们可以通过 partition 字段来控制 StatefulSet 升级进度,并在升级前确保 leader 迁移完毕,如下图所示:\n\n\n\n图 5 在控制循环中协调状态
\n\n在伪代码中,每次我们因为要将所有 Pod 收敛到新版本而进入这段控制逻辑时,都会先检查下一个要待升级的 TiKV 实例上 leader 是否迁移完毕,直到迁移完毕才会继续往下走,调整 partition 参数,开始升级对应的 TiKV 实例。缩容也是类似的逻辑。但你可能已经意识到,缩容和滚动更新两个操作是有可能同时出现在状态收敛的过程中的,也就是同时修改 replicas 和 image 字段。这时候由于控制器需要区分缩容与滚动更新,诸如此类的边界条件会让控制器越来越复杂。\n\n第三种方案是使用 Kubernetes 的 Admission Webhook 将一部分协调逻辑从控制器中拆出来,放到更纯粹的切面当中。针对这个例子,我们可以拦截 Pod 的 Delete 请求和针对上层对象的 Update 请求,检查缩容或滚动升级的前置条件,假如不满足,则拒绝请求并触发指令进行协调,比如驱逐 leader,假如满足,那么就放行请求。控制循环会不断下发指令直到状态收敛,因此 webhook 就相应地会不断进行检查直到条件满足,如下图所示:\n\n\n\n\n图 6 在 Webhook 中协调状态
\n\n这种方案的好处是我们把逻辑拆分到了一个与控制器垂直的单元中,从而可以更容易地编写业务代码和单元测试。当然,这个方案也有缺点,一是引入了新的错误模式,处理 webhook 的 server 假如宕机,会造成集群功能降级;二是该方案适用面并不广,只能用于状态协调与特定的 Kubernetes API 操作强相关的场景。在实际的代码实践中,我们会按照具体场景选择方案二或方案三,大家也可以到项目中一探究竟。\n\n**上面的两个例子都是关于如何控制编排逻辑复杂度的,关于 Operator 的各类科普文中都会用一句“在自定义控制器中编写领域特定的运维知识”将这一部分轻描淡写地一笔带过,而我们的实践告诉我们,真正编写生产级 的自定义控制器充满挑战与抉择。**\n\n## Local PV —— 想说爱你不容易\n\n接下来是存储的问题。我们不妨看看 Kubernetes 为我们提供了哪些存储方案:\n\n\n\n图 7 存储方案
\n\n其中,本地临时存储中的数据会随着 Pod 被删除而清空,因此不适用于持久存储。\n\n远程存储则面临两个问题:\n\n+ 通常来说,远程存储的性能较差,这尤其体现在 IOPS 不够稳定上,因此对于磁盘性能有严格要求的有状态应用,大多数远程存储是不适用的。\n\n+ 通常来说,远程存储本身会做三副本,因此单位成本较高,这对于在存储层已经实现三副本的 TiDB 来说是不必要的成本开销。\n\n因此,最适用于 TiDB 的是本地持久存储。这其中,hostPath 的生命周期又不被 Kubernetes 管理,需要付出额外的维护成本,最终的选项就只剩下了 Local PV。\n\nLocal PV 并非免费的午餐,所有的文档都会告诉我们 Local PV 有以下限制:\n\n+ 数据易失(相比于远程存储的三副本)。\n\n+ 节点故障会影响数据访问。\n\n+ 难以垂直扩展容量(相当一部分远程存储可以直接调整 volume 大小)。\n\n这些问题同样也是在传统的虚拟机运维场景下的痛点,因此 TiDB 本身设计就充分考虑了这些问题:\n\n+ 本地存储的易失性要求应用自身实现数据冗余。\n - TiDB 的存储层 TiKV 默认就为每个 Region 维护至少三副本。\n - 当副本缺失时,TiKV 能自动补齐副本数。\n+ 节点故障会影响本地存储的数据访问。\n - 节点故障后,相关 Region 会重新进行 leader 选举,将读写自动迁移到健康节点上。\n+ 本地存储的容量难以垂直扩展。\n - TiKV 的自动数据切分与调度能够实现水平伸缩。\n\n存储层的这些关键特性是 TiDB 高效使用 Local PV 的前提条件,也是 TiDB 水平伸缩的关键所在。当然,在发生节点故障或磁盘故障时,由于旧 Pod 无法正常运行,我们需要自定义控制器帮助我们进行恢复,及时补齐实例数,确保有足够的健康实例来提供整个集群所需的存储空间、计算能力与 IO 能力。这也就是自动故障转移。\n\n我们先看一看为什么 TiDB 的存储层不能像无状态应用或者使用远程存储的 Pod 那样自动进行故障转移。假设下图中的节点发生了故障,由于 TiKV-1 绑定了节点上的 PV,只能运行在该节点上,因此 在节点恢复前,TiKV-1 将一直处于 Pending 状态:\n\n\n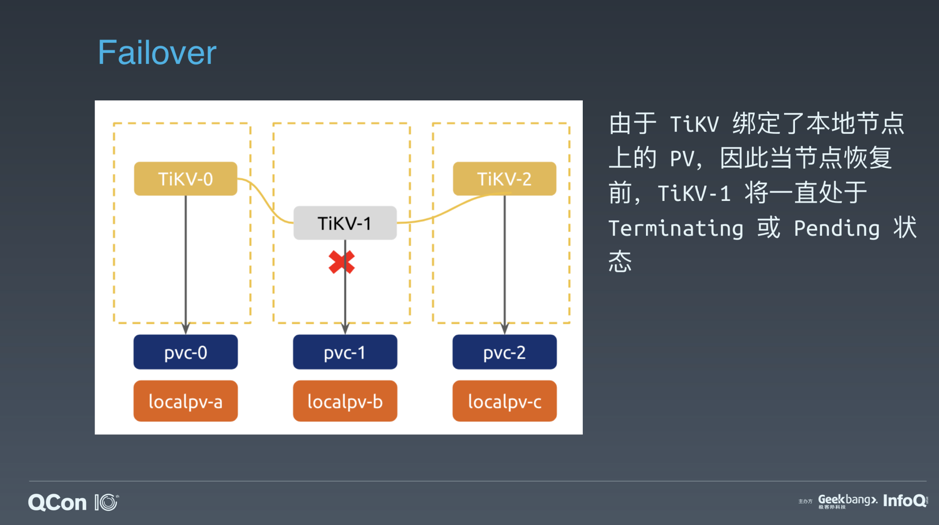\n\n图 8 节点故障
\n\n此时,假如我们能够确认 Node 已经宕机并且短期无法恢复,那么就可以删除 Node 对象(比如 NodeController 在公有上会查询公有云的 API 来删除已经释放的 Node)。此时,控制器通过 Node 对象不存在这一事实理解了 Node 已经无法恢复,就可以直接删除 pvc-1 来解绑 PV,并强制删除 TiKV-1,最终让 TiKV-1 调度到其它节点上。当然,我们同时也要做应用层状态的协调,也就是先在 PD 中下线 TiKV-1,再将新的 TiKV-1 作为一个新成员加入集群,此时,PD 就会通知 TiKV-1 创建 Region 副本来补齐集群中的 Region 副本数。\n\n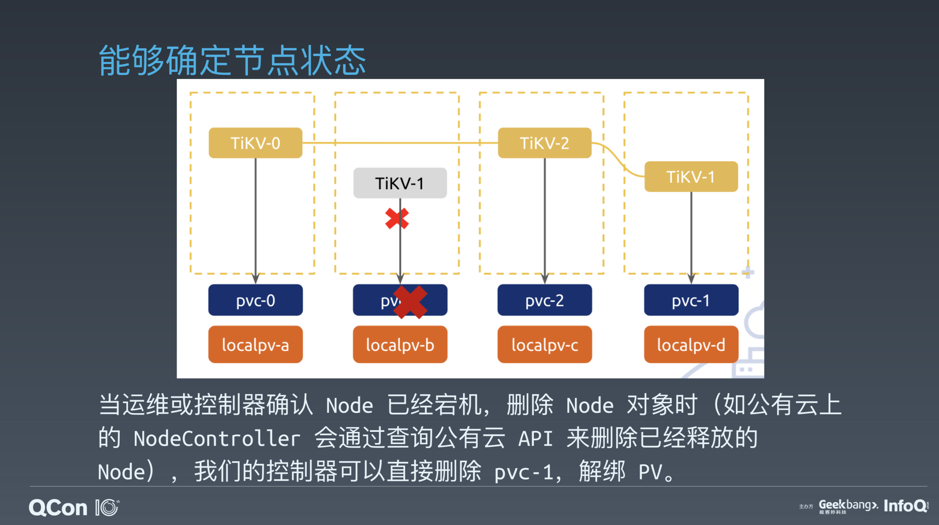\n\n图 9 能够确定节点状态时的故障转移
\n\n当然,更多的情况下,我们是无法在自定义控制器中确定节点状态的,此时就很难针对性地进行原地恢复,因此我们通过向集群中添加新 Pod 来进行故障转移:\n\n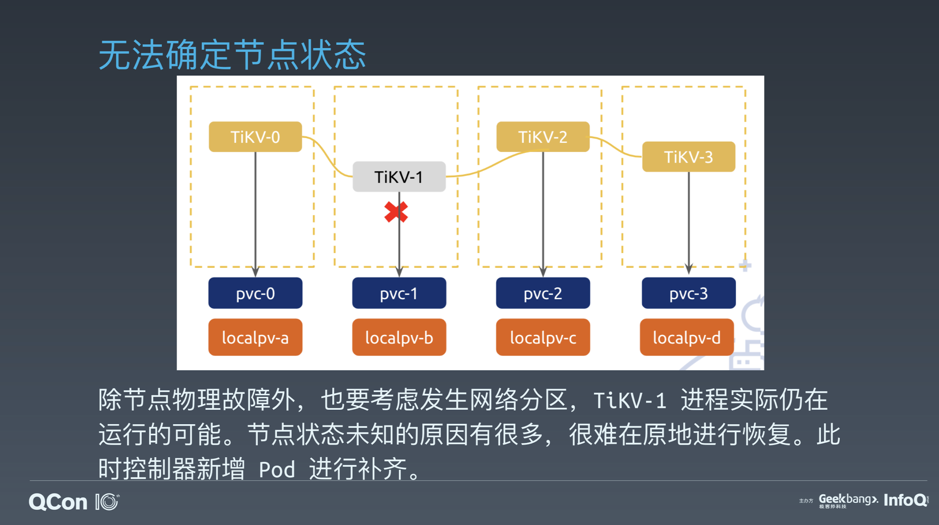\n\n图 10 无法确定节点状态时的故障转移
\n\n上面讲的是 TiDB 特有的故障转移策略,但其实可以类推到大部分的有状态应用上。比如对于 MySQL 的 slave,我们同样可以通过新增 slave 来做 failover,而在 failover 时,我们同样也要做应用层的一些事情, 比如说去 S3 上拉一个全量备份,再通过 binlog 把增量数据补上,当 lag 达到可接受的程度之后开始对外提供读服务。因此大家就可以发现,对于有状态应用的 failover 策略是共通的,也都需要应用本身支持某种 failover 形式。比如对于 MySQL 的 master,我们只能通过 M-M 模式做一定程度上的 failover,而且还会损失数据一致性。这当然不是 Kubernetes 或云原生本身有什么问题,而是说 Kubernetes 只是改变了应用的运维模式,但并不能影响应用本身的架构特性。假如应用本身的设计就不是云原生的,那只能从应用本身去解决。\n\n## 总结\n\n通过 TiDB Operator 的实践,我们有以下几条总结:\n\n* Operator 本身的复杂度不可忽视。\n\n* Local PV 能满足高 IO 性能需求,代价则是编排上额外的复杂度。\n\n* 应用本身必须迈向云原生(meets kubernetes part way)。\n\n最后,言语的描述总是不如代码本身来得简洁有力,TiDB Operator 是一个完全开源的项目,眼见为实,大家可以尽情到 [项目仓库](https://github.com/pingcap/tidb-operator) 中拍砖,也欢迎大家加入社区一起玩起来,期待你的 issue 和 PR!\n\n假如你对于文章有任何问题或建议,或是想直接加入 PingCAP 鼓捣相关项目,欢迎通过我的邮箱 wuyelei@pingcap.com 联系我。\n\n\n>本文为吴叶磊在 2019 QCon 全球软件开发大会(上海)上的专题演讲实录,Slides [下载地址](https://github.com/pingcap/presentations/blob/master/conference/%E5%90%B4%E5%8F%B6%E7%A3%8A-QCon-2019-%E9%AB%98%E6%95%88%E7%BC%96%E6%8E%92%E6%9C%89%E7%8A%B6%E6%80%81%E5%BA%94%E7%94%A8-TiDB%E7%9A%84%E4%BA%91%E5%8E%9F%E7%94%9F%E5%AE%9E%E8%B7%B5%E4%B8%8E%E6%80%9D%E8%80%83.pdf)。","date":"2019-10-29","author":"吴叶磊","fillInMethod":"writeDirectly","customUrl":"efficiently-orchestrating-stateful-application","file":null,"relatedBlogs":[]},{"id":"Blogs_279","title":"势高,则围广:TiDB 的架构演进哲学","tags":["TiDB","架构"],"category":{"name":"观点洞察"},"summary":"我们更多时候是站在哲学层面思考整个公司的运转和 TiDB 这个产品的演进的思路。这些思路很多时候是大家看不见的,因为不是一个纯粹的技术层面或者算法层面的事情。","body":"大家可能知道我是 PingCAP CEO,但是不知道的是,我也是 PingCAP 的产品经理,应该也是最大的产品经理,是对于产品重大特性具有一票否决权的人。中国有一类产品经理是这样的,别人有的功能我们统统都要有,别人没有的功能,我们也统统都要有,所以大家看到传统的国内好多产品就是一个超级巨无霸,功能巨多、巨难用。所以我在 PingCAP 的一个重要职责是排除掉“看起来应该需要但实际上不需要”的那些功能,保证我们的产品足够的专注、足够聚焦,同时又具有足够的弹性。\n\n## 一、最初的三个基本信念\n\n本次分享题目是《TiDB 的架构演进哲学》,既然讲哲学那肯定有故事和教训,否则哲学从哪儿来呢?但从另外的角度来说,一般大家来讲哲学就先得有信念。有一个内容特别扯的美剧叫做《美国众神》,里面核心的一条思路是“你相信什么你就是什么”。其实人类这么多年来,基本上也是朝这条线路在走的,人类对于未知的东西很难做一个很精确的推导,这时信念就变得非常重要了。\n\n\n\n图 1 最初的基本信念
\n\n实际上,我们开始做 TiDB 这个产品的时候,第一个信念就是相信云是未来。当年 K8s 还没火,我们就坚定的拥抱了 K8s。第二是不依赖特定硬件、特定的云厂商,也就是说 TiDB 的设计方向是希望可以 Run 在所有环境上面,包括公有云私有云等等。第三是能支持多种硬件,大家都知道我们支持 X86、AMD64、ARM 等等,可能大家不清楚的是 MIPS,MIPS 典型代表是龙芯,除此之外,TiDB 未来还可以在 GPU 上跑(TiFlash 的后续工作会支持 GPU)。\n\n## 二、早期用户故事\n\n### 2.1 Make it work\n\n有一句话大概是“眼睛里面写满了故事,脸上没有一点沧桑”,其实现实是残酷的,岁月一定会给你沧桑的。我们早期的时候,也有相对比较难的时候,这时候就有一些故事关于我们怎么去经历、怎么渡过的。 \n\n首先大家做产品之前肯定先做用户调研,这是通用的流程,我们当初也做过这个事,跟用户聊。我们通常会说:“我们要做一个分布式数据库,自动弹性伸缩,能解决分库分表的问题,你会用吗?”用户说“那肯定啊,现在的分库分表太痛苦了。”这是最初我们获取需求最普通的方式,也是我们最容易掉入陷阱的方式,就好像“我有一百万,你要不要?肯定要。”“我有一瓶水,喝了之后就健康无比,延年益寿你要不要?肯定要。”很容易就得到类似的结论。\n\n所以这个一句话结论的代价是我们进行了长达两年的开发。在这两年的时间里,我们确定了很多的技术方向,比如最初 TiDB 就决定是分层的。很显然一个复杂的系统如果没有分层,基本上没有办法很好的控制规模和复杂度。TiDB 分两层,一层是 SQL 层,一层是 key-value 层,那么到底先从哪一个层开始写呢?其实从哪层开始都可以,但是总要有一个先后,如何选择?\n\n这里就涉及到 TiDB 的第一条哲学。我们做一个产品的时候会不断面临选择,那每次选择的时候核心指导思想是什么?核心思想是能一直指导我们持续往前去迭代,所以我们第一条哲学就是:**永远站在离用户更近的地方去考虑问题。**\n\n为什么我们会定义这样一条哲学?因为离用户越近越能更快的得到用户的反馈,更快的验证你的想法是不是可行的。显然 SQL 层离用户更近,所以我们选择从 SQL 层写起。其实一直到现在,绝大多数用户用 TiDB 的时候根本感受不到 KV 层的存在,用户写的都是 SQL,至于底层存储引擎换成了别的,或者底层的 RocksDB 做了很多优化和改进,这些变化对于用户关注的接口来说是不可见的。\n\n选择从 SQL 层开始写之后,接下来面临的问题就是怎么做测试,怎么去更好的做验证,怎么让整个架构,先能够完整跑起来。\n\n在软件开发领域有一条非常经典的哲学:**「Make it work, make it right, make it fast」**。我想大家每一个学软件开发的人,或者每一个学计算机的人可能都听过这样一句话。所以当时我们就做另外一个决定,先在已有的 KV 上面构建出一个原形,用最短的时间让整个系统能够先能 work。\n\n我们在 2015 年的 9 月份开源了第一个版本,当时是没有存储层的,需要接在 HBase 上。当这个系统能跑起来之后,我们的第一想法是赶紧找到当初调研时说要用的那些用户,看看他们是什么想法,尽快的去验证我们的想法是不是可行的。因为很多人做产品思维属于自嗨型,“我做的东西最厉害,只要一推出去肯定一群人蜂拥而至。”抱有这种想法的人太多了,实际上,只有尽快去验证才是唯一的解决之道,避免产品走入误区。\n\n\n\n图 2 与调研用户第二次对话
\n\n然而当我跟用户讲,你需要先装一个 Hadoop,可能还要装一组 Zookeeper,**但用户说:“我只想要一个更强大的 MySQL,但是让我装这一堆东西,你是解决问题还是引入问题?”**\n\n这个问题有什么解决办法呢?一个办法是你去解决用户,可以通过销售或者通过某些关系跟用户聊,显然这是一个不靠谱的思路。作为一个产品型的公司,我们很快就否了这个想法。用户的本质要求是:你不要给我装一堆的东西,要真正解决我的问题。所以我们马上开始启动分布式 KV 的开发工作,彻底解决掉这个问题,满足用户的要求。\n\n\n\n图 3 开发 TiKV 前的技术考量
\n\n开始开发 KV 层时候又会面临很多技术选择,我们有很多考量(如图 3)。\n\n**第一点,我们认为作为数据库最重要的是正确性。** 假设这个数据库要用在金融行业,用在银行、保险、证券,和其他一些非常关键的场合的时候,正确性就是无比重要的东西。没有人会用一个不正确的数据库。\n\n**第二点是实现简洁、易用。** 用户对于一个不简洁、不易用的东西是无法接受的,所以我们当时的一个想法是一定要做得比 HBase 更加易用,代码量也要比 HBase 小,所以时至今天 TiDB 代码量仍然是比 HBase 小得多,大约还不到 HBase 的十分之一。\n\n**第三点考虑是扩展性。** TiDB 不仅在整体上是分层的,在存储层 TiKV 内部也是分层的,所以有非常好的扩展性,也支持 Raw KV API、Transaction API,这个设计后来也收获了很多用户的支持,比如一点资讯的同学就是用的 Raw KV API。\n\n**第四点就是要求高性能低延迟。** 大家对于数据库的性能和延迟的追求是没有止境的,但是我们当时并没有把太多精力花在高性能低延迟上。刚才说到我们有一条哲学是「Make it work, make it right, make it fast」,大家可以看到这句话里面 「Fast」是放最后的,这一点也是 TiDB 和其他产品有非常大的差异的地方。作为一个技术人员,通常大家看一个产品好不好,就会想:“来,不服跑个分,产品架构、易用性、技术文档、Community 这些指标都不看,先跑个分让大家看看行不行”。这个思路真正往市场上去推时是不对的。很多事情的选择是一个综合的过程。你可以让你的汽车跑的巨快无比,上面东西全拆了就留一个发动机和四个轮子,那肯定也是跑得巨快,重量轻,而且还是敞篷车,但没有一个人会在路上用的。同样的,选择 Rust 也是综合考量的结果。我们看中了 Rust 这个非常具有潜力的语言。当时 Rust 没有发布 1.0,还不是一个 stable 版本,但我们相信它会有 1.0。大概过了几个月,Rust 就发布了 1.0 版本,证明我们的选择还是非常正确的。\n\n**最后一点就是稳定性。** 作为一个分布式数据库,每一层的稳定性都非常重要。最底下的一个存储引擎,我们选择了非常稳定的 RocksDB。不过后来我们也查到几个 RocksDB 掉数据的 Bug。这也是做数据库或者说做基础产品的残酷性,我们在做产品的过程中找到了 Rust 编译器的 Bug,XFS 掉数据的 Bug,RocksDB 掉数据的 Bug,好像几大基础组件的 Bug 都聚在这里开会。\n\n接着我们辛辛苦苦干了三个月,然后就开源了 TiKV,所以这时候看起来没有那么多的组件了。我们也不忘初心,又去找了我们当初那个用户,说我们做了一些改进,你要不要试一试。\n\n\n\n图 4 与调研用户第三次对话
\n\n但是用户这时候给了一个让我们非常伤心非常难受的回答:没有,我们不敢上线,虽然你们的产品听起来挺好的,但是数据库后面有很大的责任,心理上的担心确实是过不去。于是我们回去开始加班加点写 TiDB Binlog,让用户可以把 binlog 同步给 MySQL。**毕竟用户需要一个 Backup:万一 TiDB 挂了怎么办,我需要切回 MySQL,这样才放心,因为数据是核心资产。**\n\n\n\n图 5 第一个上线用户的架构图
\n\n所以最终我们第一个用户上线的时候,整个 TiDB 的架构是这样的(如图 5)。用户通过 Client 连上 TiDB,然后 TiDB 后面就通过 Binlog 同步到 MySQL。后来过了一段时间,用户就把后面的 MySQL 撤了。我们当时挺好奇为什么撤了,用户说,第一个原因是后面 MySQL 撑不起一个集群给它回吐 Binlog,第二就是用了一段时间觉得 TiDB 挺稳定的,然后就不需要 Binlog 备份了。\n\n其实第一个用户上线的时候,数据量并不算大,大概 800G 的数据,使用场景是 OLTP 为主,有少量的复杂分析和运算,但这少量的复杂分析运算是当时他们选择 TiDB 最重要的原因。因为当时他们需要每隔几分钟算一个图出来,如果是在 MySQL 上面跑,大约需要十几分钟,但他们需要每隔几分钟打一个点,后来突然发现第二天才能把前一天的点都打出来,这对于一个实时的系统来说就很不现实了。虽然这个应用实践只有少部分运算,但也是偏 OLAP,我记得 TiDB 也不算特别快,大概是十几秒钟,因为支持了一个并行的 Hash Join。\n\n**不管怎样,这个时候终于有第一个用户能证明我们做到了「Make it work」。**\n\n### 2.2 Make it right\n\n接下来就是「Make it right」。大家可能想象不到做一个保证正确性的数据库这件事情有多么难,这是一个巨大的挑战,也有巨大的工作量,是从理论到实践的距离。\n\n\n\n图 6 理论到实践的距离
\n\n#### 2.2.1 TLA+ 证明\n\n大家可能会想写程序跟理论有什么关系?其实在分布式数据库领域是有一套方法论的。这个方法论要求先实现正确性,而实现正确的前提是有一个形式化的证明。为了保证整个系统的理论正确,我们把所有的核心算法都用 TLA+ 写了一遍证明,并且把这个证明 [开源](https://github.com/pingcap/tla-plus) 出去了,如果大家感兴趣可以翻看一下。以前写程序的时候,大家很少想到先证明一下算法是对的,然后再把算法变成一个程序,其实今天还有很多数据库厂商没有做这件事。\n\n#### 2.2.2 千万级别测试用例\n\n在理论上保证正确性之后,下一步是在现实中测试验证。这时只有一个办法就是用非常庞大的测试用例做测试。大家通常自己做测试的时候,测试用例应该很少能达到十万级的规模,而我们现在测试用例的规模是以千万为单位的。当然如果以千万为单位的测试用例靠纯手写不太现实,好在我们兼容了 MySQL 协议,可以直接从 MySQL 的测试用例里收集一些。这样就能很快验证整个系统是否具备正确性。\n\n这些测试用例包括应用、框架、管理工具等等。比如有很多应用程序是依赖 MySQL,那直接拿这个应用程序在 TiDB 上跑一下,就知道 TiDB 跟 MySQL 的兼容没问题,如 Wordpress、无数的 ORM 等等。还有一些 MySQL 的管理工具可以拿来测试,比如 Navicat、PHP admin 等。另外我们把公司内部在用的 Confluence、Jira 后面接的 MySQL 都换成了 TiDB,虽然说规模不大,但是我们是希望在应用这块有足够的测试,同时自己「Eat dog food」。\n\n#### 2.2.3 7*24 的错误注入测试用例\n\n这些工作看起来已经挺多的了,但实际上还有一块工作比较消耗精力,叫 7*24 的错误注入测试。最早我们也不知道这个测试这么花钱,我们现在测试的集群已经是几百台服务器了。如果创业的时候就知道需要这么多服务器测试,我们可能就不创业了,好像天使轮的融资都不够买服务器的。不过好在这个事是一步一步买起来,刚开始我们也没有买这么多测试服务器,后来随着规模的扩大,不断的在增加这块的投入。\n\n大家可能到这儿的时候还是没有一个直观的感受,说这么多测试用例,到底是一个什么样的感受。我们可以对比看一下行业巨头 Oracle 是怎么干的。\n\n\n\n图 7 前 Oracle 员工的描述
\n\n这是一篇 [在 HackNews上面的讨论](https://news.ycombinator.com/item?id=18442941&utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website),讨论的问题是:你觉得这个最坏的、规模最大的代码是什么样子的?下面就有一个 Oracle 的前员工就介绍了 Oracle Database 12.2 这个版本的情况。他说这个整体的源代码接近 2500 万行 C 代码,可能大家维护 25 万行 C 代码的时候就会痛不欲生了,可以想想维护这么多代码的是一种什么样的感受。到现在为止,TiDB 的代码应该还不到 25 万行。当然 TiDB 的功能远远没有 Oracle 那么多,Oracle 的功能其实是很多的,历史积累一直往上加,加的很凶。\n\n这位 Oracle 前员工介绍了自己在 Oracle 的开发工作的流程,如下图:\n\n\n\n图 8 Oracle 开发者 fix bug 的过程
\n\n比如用户报了一个 Bug,然后他开始 fix。第一件事是花两周左右的时间去理解 20 个不同的 flag,看看有没有可能因为内部乱七八糟的原因来造成这个 Bug。大家可能不知道 MySQL 有多少变量,我刚做 TiDB 的时候也不知道,当时我觉得自己是懂数据库的,后来去看了一下 MySQL 的 flag 的变量数就惊呆了,但看到 Oracle 的 flag 变量数,那不是惊呆了,是绝望了。大家可能知道开启 1 个 flag 的时候会对什么东西有影响,但是要去理解 20 个 flag 开启时和另外几个 flag 组合的时候都有什么影响,可能会崩溃。所以其实精通 Oracle 这件事情,实际上可能比精通 C++ 这件事情更困难的。一个 Oracle 开发者在内部处理这件事情都这么复杂,更何况是外面的用户。但 Oracle 确实是功能很强大。\n\n说回这位前 Oracle 员工的描述,他接着添加了更多的 flag 处理一个新的用户场景的问题,然后加强代码,最后改完以后会提交一个测试。先在 100 到 200 台机器上面把这个 Oracle 给 build 出来,然后再对这个 Oracle 去做新的测试。他应该对 Oracle 的测试用例的实际数量了解不深刻,我猜他可能不知道 Oracle 有多少个测试,所以写的是 “millions of tests”,这显然太低估了 Oracle 的测试数量。通常情况下,只会看到挂了的测试,看不到全部的测试数量。\n\n下面的步骤更有意思了:Go home,因为整个测试需要 20-30 个小时,跑完之后测试系统反馈了一个报告:挂了 200 多个 test,更茫然的是这 200 tests 他以前都没见过,这也是 Oracle 非常强大的一个地方,如果一个开发者的代码提交过去挂掉一两百个测试,是很正常的事情,因为 Oracle 的测试能 Cover 东西非常多,是这么多年来非常强大的积累,不停的堆功能的同时就不停的堆测试,当然也不停的堆 flag。所以从另一个角度来看,限制一个系统的功能数量,对于维护来说是非常重要的。\n\n总之,看完这个回复之后,我对行业前辈们充满了敬畏之情。\n\n### 2.3 Make it fast\n\n#### 2.3.1 新问题\n\n随着 TiDB 有用户开始上线,用户的数量和规模越来越大,这时候就出现了一个很有意思的事情,一部分用户把 TiDB 当成了可以支持事务、拥有良好实时性的数据仓库在用,和我们说:我们把公司 Hadoop 换了,数据量十几 T。\n\n我们就一下开始陷入了深深的思考,因为 TiDB 本来设计的目的不是这个方向,我们想做一个分布式 OLTP 数据库,并没有想说我们要做一个 Data Warehouse。但是用户的理由让我们觉得也很有道理,无法反驳——TiDB 兼容 MySQL,会 MySQL 的人很多,更好招人,最重要的是 Hadoop 跑得还不够快。\n\n虽然我们自己也很吃惊,但这体现了 TiDB 另一方面的价值,所以我们继续问用户还有什么痛点。用户表示还有一部分查询不够快,数据没办法做到 shuffle,而且以前用 Spark,TiDB 好像没有 Spark 的支持。\n\n我们想了想,TiDB 直接连 Spark 也是可以的,但这样 Spark 对底下没有感知,事务跑得巨慢,就跟 Spark 接 MySQL 没什么差别。我们研究了一下,做出了一个新的东西——TiSpark。TiSpark 就开始能够同时在 TiDB 上去跑 OLAP 和 OLTP。\n\n\n\n图 9 出现的新问题
\n\n就在我们准备改进 TiDB 的数据分析能力的时候,突然又有一大批 TP 用户上线了,给我们报了一堆问题,比如执行计划不准确,选不到最优执行计划,数据热点分布不均匀,Raft store 单线程写入瓶颈,报表跑的慢等等……于是我们制定了 1.0 到 2.X 的计划,先把用户提的这些问题一一解决。\n\n**这里有另外一条哲学:将用户遇到的问题放在第一优先级。我们从产品最初设计和之后 Roadmap 计划永远是按照这个原则去做的。**\n\n**首先,执行计划不准确的问题。** 最简单有效的解决办法是加一个 Index Hint,就像是“你告诉我怎么执行,我就怎么执行,我自己不会自作聪明的选择”。但这不是长久之计,因为用户可能是在一个界面上选择各种条件、参数等等,最后拼成一个 SQL,他们自己没办法在里面加 Index Hint。我们不能决定用户的使用习惯,所以从这时开始,我们决定从 RBO(Rule Based Optimizer)演进到 CBO(Cost Based Optimizer),这条路也走了非常久,而且还在持续进行。\n\n**第二个是热点数据处理问题。** 我们推出了一个热点调度器,这个可能大家在分布式数据库领域第一次听说,数据库领域应该是 PingCAP 首创。 热点调度器会统计、监控整个系统热点情况,再把这些热点做一个快速迁移和平衡,比如整个系统有 10 个热点,某一个机器上有 6 个热点,这台机器就会很卡,这时热点调度器会开始将热点打散,快速分散到集群的其他机器上去,从而让整个集群的机器都处于比较正常的负载状态。\n\n**第三个就是解决 Raft store 单线程瓶颈的问题**。为了改变 Raft store 单线程,我们大概花了一年多的时间,目前已经在 TiDB 3.0 里实现了。我们将 Raft store 线程更多耗时的计算变成异步操作,offload 到其它线程。不知道有没有人会好奇为什么这个改进会花这么长时间?我们一直认为数据库的稳定性第一位的。分布式系统里面一致性协议本身也复杂,虽然说 Raft 是比 Paxos 要简单,但它实际做起来也很复杂,要在一个复杂系统里支持多线程,并且还要做优化,尽可能让这个 I/O 能 group 到一起,其实非常耗精力。\n\n**第四个就是解决报表跑得慢的问题**,这个骨头特别硬,我们也是啃到今天还在继续。首先要大幅提升 TiDB 在分析场景下的能力。大家都可以看到我们在发布每一个版本的时候,都会给出与上一个版本的 TPC-H 性能对比(TPC-H 是一个有非常多的复杂查询、大量运算的场景)。其次就是高度并行化,充分利用多核,并提供参数控制,这个特性可能很多用户不知道,我们可以配一下参数,就让 TiDB 有多个并发在底层做 Scan。\n\n解决完这些问题,我们终于觉得可以喘口气了,但喘气的时间就不到一个星期,很快又有很多用户的反馈开始把我们淹没了。因为随着用户规模的扩大,用户反馈问题的速度也变得越来越快,我们处理的速度不一定跟的上用户的增速。\n\n#### 2.3.4 新呼声\n\n这时候我们也听到了用户的一些「新呼声」。\n\n有用户说他们在跑复杂查询时 OLTP 的查询延迟变高了,跑一个报表的时候发现 OLTP 开始卡了。这个问题的原因是在跑复杂查询的时候,SQL 资源被抢占。我们又想有没有可能将 OLAP 和 OLTP 的 Workload 分开?于是我们搞了第一个实验版本,在 TiKV 里把请求分优先级,放到不同队列里面去,复杂 Query 放在第一优先级的队列, OLTP 放在高优先级。然后我们发现自己是对报表理解不够深刻,这个方案只能解决一部分用户的问题,因为有的报表跑起来需要几个小时,导致队列永远是满的,永远抢占着系统的资源。还有一部分用户的报表没有那么复杂,只是希望报表跑得更快、更加实时,比如一个做餐饮 SaaS 的用户,每天晚上需要看一下餐馆营收情况,统计一家餐馆时速度还行,如果统计所有餐馆的情况,那就另说了。\n\n另外,报表有一些必需品,比如 View 和 Window Function,没有这些的话 SQL 写起来很痛苦,缺乏灵活度。\n\n与此同时,用户关于兼容性和新特性的要求也开始变多,比如希望支持 MySQL 类似的 table partition,还有银行用户习惯用悲观锁,而 TiDB 是乐观锁,迁移过来会造成额外的改造成本(TiDB 3.0 已经支持了悲观锁)。\n\n还有用户有 400T 的数据,没有一个快速导入的工具非常耗时(当然现在我们有快速导入工具TiDB Lightning),这个问题有一部分原因在于用户的硬件条件限制,比如说千兆网导入数据。\n\n还有些用户的数据规模越来越大,到 100T 以上就开始发现十分钟已经跑不完 GC 了(TiDB 的 GC 是每十分钟一次),一个月下来 GC 已经整体落后了非常多。\n\n\n\n图 10 用户的新呼声
\n\n我们当时非常头痛,收到了一堆意见和需求,压力特别大,然后赶紧汇总了一下,如图 10 所示。\n\n面对这么多的需求,我们考虑了两个点:\n\n* 哪些是共性需求?\n\n* 什么是彻底解决之道?\n\n**把共性的需求都列在一块,提供一个在产品层面和技术层面真正的彻底的解决办法。**\n\n比如图 10 列举的那么多问题,其实真正要解决三个方面:性能、隔离和功能。性能和隔离兼得好像很困难,但是这个架构有非常独特的优势,也是可以做得到的。那可以进一步「三者兼得」,同时解决功能的问题吗?我们思考了一下,也是有办法的。TiDB 使用的 Raft 协议里有一个 Raft Learner 的角色,可以不断的从 Leader 那边复制数据,我们把数据同步存成了一个列存,刚才这三方面的问题都可以用一个方案去彻底解决了。\n\n首先复杂查询的速度变快了,众所周知分析型的数据引擎基本上全部使用的是列存。第二就是强一致性,整个 Raft 协议可以保证从 Learner 读数据的时候可以选择一致性的读,可以从 Leader 那边拿到 Learner 当前的进度,判断是否可以对外提供请求。第三个是实时性可以保证,因为是通过 streaming 的方式复制的。\n\n所以这些看上去非常复杂的问题用一个方案就可以解决,并且强化了原来的系统。这个「强化」怎么讲?从用户的角度看,他们不会考虑 Query 是 OLAP 还是 OLTP,只是想跑这条 Query,这很合理。**用一套东西解决用户的所有问题,对用户来说就是「强化」的系统。**\n\n## 三、关于成本问题的思考\n\n\n\n\n图 11 成本问题
\n\n很多用户都跟我们反馈了成本问题,用户觉得全部部署到 SSD 成本有点高。一开始听到这个反馈,我们还不能理解,SSD 已经很便宜了呀,而且在整个系统来看,存储机器只是成本的一小部分。后来我们深刻思考了一下,其实用户说得对,很多系统都是有早晚高峰的,如果在几百 T 数据里跑报表,只在每天晚上收工时统计今天营业的状况,那为什么要求用户付出最高峰值的配置呢?这个要求是不合理的,合不合理是一回事,至于做不做得到、怎么做到是另外一回事。\n\n于是我们开始面临全新的思考,这个问题本质上是用户的数据只有一部分是热的,但是付出的代价是要让机器 Handle 所有的数据,所以可以把问题转化成:我们能不能在系统里面做到冷热数据分离?能不能支持系统动态弹性的伸缩,伸展热点数据,用完就释放?\n\n如果对一个系统来说,峰值时段和非峰值时段的差别在于峰值时段多了 5% 的热点。我们有必要去 Handle 所有的数据吗?**所以彻底的解决办法是对系统进行合理的监控,检测出热点后,马上创建一个新的节点,这个新的节点只负责处理热点数据,而不是把所有的数据做动态的 rebalance,重新搬迁。在峰值时间过去之后就可以把复制出来的热点数据撤掉,占的这个机器可以直接停掉了,不需要长时间配备非常高配置的资源,而是动态弹性伸缩的。**\n\nTiDB 作为一个高度动态的系统,本身的架构就具有非常强的张力,像海绵一样,能够满足这个要求,而且能根据系统负载动态的做这件事。这跟传统数据库的架构有很大的区别。比如有一个 4T 的 MySQL 数据库,一主一从,如果主库很热,只能马上搞一个等配的机器重挂上去,然后复制全部数据,但实际上用户需要的只是 5% 的热数据。而在 TiDB 里,数据被切成 64MB 一个块,可以很精确的检测热数据,很方便的为热数据做伸展。这个特性预计在 TiDB 4.0 提供。\n\n这也是一个良好的架构本身带来的强大的价值,再加上基于 K8s 和云的弹性架构,就可以得到非常多的不一样的东西。同样的思路,如果我要做数据分析,一定是扫全部数据吗?对于一个多租户的系统,我想统计某个餐馆今天的收入,数据库里有成千上万个餐馆,我需要运算的数据只是其中一小块。如果我要快速做列存计算时,需要把数据全部复制一份吗?也不需要,只复制我需要的这部分数据就行。这些事情只有一个具有弹性、高度张力的系统才能做到。这是 TiDB 相对于传统架构有非常不一样的地方。时至今天,我们才算是把整个系统的架构基本上稳定了,基于这个稳定的架构,我们还可以做更多非常具有张力的事情。\n\n**所以,用一句话总结我们解决成本问题的思路是:一定要解决真正的核心的问题,解决最本质的问题。**\n\n## 四、关于横向和纵向发展的哲学\n\nTiDB 还有一条哲学是关于横向和纵向发展的选择。 \n\n通常业内会给创业公司的最佳建议是优先打“透”一个行业,因为行业内复制成本是最低的,可复制性也是最好的。**但 TiDB 从第一天开始就选择了相反的一条路——「先往通用性发展」,这是一条非常艰难的路,意味着放弃了短时间的复制性,但其实我们换取的是更长时间的复制性,也就是通用性。**\n\n因为产品的整体价值取决于总的市场空间,产品的广泛程度会决定产品最终的价值。早期坚定不移的往通用性上面走,有利于尽早感知整个系统是否有结构性缺陷,验证自己对用户需求的理解是否具有足够的广度。如果只往一个行业去走,就无法知道这个产品在其他行业的适应性和通用性。如果我们变成了某个行业专用数据库,那么再往其他行业去发展时,面临的第一个问题是自己的恐惧。这恐惧怎么讲呢?Database 应该是一个通用型的东西,如果在一个行业里固定了,那么你要如何确定它在其他场景和行业是否具有适应性?\n\n**这个选择也意味着我们会面临非常大的挑战,一上来先做最厉害的、最有挑战的用户。** 如果大家去关注整个 TiDB 发展的用户案例的情况,你会注意到 TiDB 有这样一个特点,TiDB 是先做百亿美金以上的互联网公司,这是一个非常难的选择。但大家应该知道,百亿美金以上的互联网公司,在选择一个数据库等技术产品的时候,是没有任何商业上的考量的,对这些公司来说,你的实力是第一位的,一定要能解决他们问题,才会认可你整个系统。但这个也不好做,因为这些公司的应用场景通常都压力巨大。数据量巨大,QPS 特别高,对稳定性的要求也非常高。我们先做了百亿美金的公司之后,去年我们有 80% 百亿美金以上的公司用 TiDB,除了把我们当成竞争对手的公司没有用,其他全部在用。然后再做 30 亿美金以上的公司,今年是 10 亿美金以上的用户,实际上现在是什么样规模的用户都有,甭管多少亿美金的,“反正这东西挺好用的,我就用了。”所以我们现在也有人专门负责在用户群里面回答大家的提问。\n\n**其实当初这么定那个目标主要是考虑数据量,因为 TiDB 作为一个分布式系统一定是要处理具有足够数据量的用户场景,** 百亿美金以上的公司肯定有足够的数据,30 亿美金的公司也会有,因为他们的数据在高速增长,当我们完成了这些,然后再开始切入到传统行业,因为在这之前我们经过了稳定性的验证,经过了规模的验证,经过了场景的验证。\n\n\n\n图 12 横向发展与纵向发展
\n\n**坚持全球化的技术视野也是一个以横向优先的发展哲学。** 最厉害的产品一定是全球在用的。这个事情的最大差异在于视野和格局,而格局最终会反映到人才上,最终竞争不是在 PingCAP 这两百个员工,也不是现在 400 多个 Contributors,未来可能会有上千人参与整个系统的进化迭代,在不同的场景下对系统进行打磨,所以竞争本质上是人才和场景的竞争。基于这一条哲学,所以才有了现在 TiDB 在新一代分布式数据库领域的全面领先,无论是从 GitHub Star 数、 Contributor 数量来看,还是从用户数据的规模、用户分布的行业来看,都是领先的。同样是在做一个数据库,大家的指导哲学不一样会导致产品最终的表现和收获不一样,迭代过程也会完全不一样。我们在做的方向是「携全球的人才和全球的场景去竞争」。\n\n关于横向和纵向发展,并不是我们只取了横向。\n\n**2019 年 TiDB 演进的指导思想是:稳定性排第一,易用性排第二,性能第三,新功能第四。** 这是我在 2018 年经过思考后,把我们发展的优先级做了排序。上半年我们重点关注的是前两个,稳定性和易用性。下半年会关注纵向发展,「Make it fast」其实是纵向上精耕细作、释放潜力的事情。这个指导思想看起来好像又跟其他厂商想法不太一样。\n\n我们前面讲的三条哲学里面,最后一条就是「Make it fast」,如果要修建五百层的摩天大楼,要做的不是搭完一层、装修一层,马上给第一层做营业,再去搭第二层。而一定要先把五百层的架构搭好,然后想装修哪一层都可以。**TiDB 就是「摩天大楼先搭架构后装修」的思路,所以在 TiDB 3.0 发布之后,我们开始有足够的时间去做「装修」的事情。**\n\n## 五、总结与展望\n\n说了这么多故事,如果要我总结一下 2015 - 2019 年外面的朋友对 TiDB 的感受,是下图这样的:\n\n\n\n图 13 2015-2019 小结
\n\n2015 年,当我们开始做 TiDB 的时候,大家说:啊?这事儿你们也敢干?因为写一个数据库本身非常难,写一个分布式数据库就是无比的难,然后还是国人自主研发。到 2016 年的时候,大家觉得你好像折腾了点东西,听到点声音,但也没啥。到 2017、2018 年,大家看到有越来越多用户在用。2019 年,能看到更多使用后点赞的朋友了。\n\n我昨天翻了一下 2015 年 4 月 19 日发的一条微博。\n\n\n\n图 14 刚创业时发的微博
\n\n当时我们正准备创业,意气风发发了一条这样微博。这一堆话其实不重要,大家看一下阅读量 47.3 万,有 101 条转发,44 条评论,然而我一封简历都没收到。当时大家看到我们都觉得,这事儿外国人都没搞,你行吗?折腾到今天,我想应该没有人再对这个问题有任何的怀疑。**很多国人其实能力很强了,自信也可以同步跟上来,毕竟我们拥有全球最快的数据增速,很多厂家拥有最大的数据量,对产品有最佳的打磨场景。**\n\n想想当时我也挺绝望的,想着应该还有不少人血气方刚,还有很多技术人员是有非常强大的理想的,但是前面我也说了,总有一个从理想到现实的距离,这个距离很长,好在现在我们能收到很多简历。所以很多时候大家也很难想象我们刚开始做这件事情的时候有多么的困难,以及中间的每一个坚持。**只要稍微有一丁点的松懈,就可能走了另外一条更容易走的路,但是那条更容易走的路,从长远上看是一条更加困难的路,甚至是一条没有出路的路。**\n\n\n\n图 15 对 2020 年的展望
\n\n最后再说一下 2020 年。在拥有行业复制能力的之后,在产品层面我们要开始向着更高的性能、更低的延迟、更多 Cloud 支持(不管是公有云还是私有云都可以很好的使用 TiDB)等方向纵向发展。同时也会支持我刚刚说的,热点根据 Workload 自动伸缩,用极小的成本去扛,仅仅需要处理部分热点的数据,而不是复制整个数据的传统主-从思路。\n\n大家去想一想,如果整个系统会根据 Workload 自动伸缩,本质上是一个 self-driving 的事情。现在有越来越多的用户把 TiDB 当成一个数据中台来用,有了 TiDB 行列混存,并且 TiDB 对用户有足够透明度,就相当于是握有了 database 加上 ETL,加上 data warehouse,并且是保证了一致性、实时性的。\n\n昨天我写完 slides 之后想起了以前看的一个电视剧《大秦帝国》。第一部第九集里有一段关于围棋的对话。商鞅执黑子先行,先下在了一个应该是叫天元位置,大约在棋盘的中间。大家知道一般下围棋的时候都是先从角落开始落子居多。商鞅的对手就说,我许你重下,意思就是你不要开玩笑,谁下这儿啊?于是商鞅说这样一句话,“中枢之地,辐射四极,雄视八荒”,这也是一个视野和格局的事情。然后对手说:“先生招招高位,步步悬空,全无根基实地”,就是看起来好像是都还挺厉害的,一点实际的基础都没有,商鞅说:“旦有高位,岂无实地?”,后来商鞅赢了这盘棋,他解释道:“**棋道以围地为归宿,但必以取势为根本。势高,则围广**”。\n\n**这跟我们做 TiDB 其实很像,我们一上来就是先做最难最有挑战的具有最高 QPS 和 TPS、最大数据量的场景,这就是一个「取势」的思路,因为「势高,则围广」。** 所以我们更多时候是像我前面说的那样,站在哲学层面思考整个公司的运转和 TiDB 这个产品的演进的思路。这些思路很多时候是大家看不见的,因为不是一个纯粹的技术层面或者算法层面的事情。\n\n我也听说有很多同学对 TiDB 3.0 特别感兴趣,不过今天没有足够的时间介绍,我们会在后续的 TechDay 上介绍 3.0 GA 的重大特性,因为从 2.0 到 3.0 产生了一个巨大的变化和提升,性能大幅提升,硬件成本也下降了一倍的样子,需要一天的时间为大家详细的拆解。\n\n\n\n>本文根据我司 CEO 刘奇在第 100 期 Infra Meetup 上的演讲整理。\n\n- END -
","date":"2019-05-30","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"guiding-ideologies-in-the-evolution-of-tidb","file":null,"relatedBlogs":[]},{"id":"Blogs_187","title":"The (Near) Future of Database — TiDB DevCon 2019","tags":["TiDB","架构"],"category":{"name":"观点洞察"},"summary":"在 TiDB DevCon 2019 上,我司联合创始人兼 CTO 黄东旭分享了对数据库行业大趋势以及未来数据库技术的看法。","body":">在 TiDB DevCon 2019 上,我司联合创始人兼 CTO 黄东旭分享了对数据库行业大趋势以及未来数据库技术的看法。以下是演讲实录,enjoy~ \n\n\n\n我司联合创始人兼 CTO 黄东旭
\n\n大家今天在这里看到了 TiDB 社区用户实践分享和我们自己的一些技术进展和展望,还有非常好玩的 Demo Show,正好在大会结束之前,我想跟大家聊一聊我心目中未来的 Database 应该是一个什么样子。\n\n其实我们并不是一个特别擅长发明名词的公司,我记得我们第一次去用 HTAP 这个词的时候,应该是 2016 左右。在使用 HTAP 这个词的时候,我们市场部同事还跟我们说 HTAP 这个词从来没人用过,都是论文里的词,大家都不知道,你把你们公司的产品定位改成这个别人都不知道怎么办?我们后来仔细想,还是觉得 HTAP 这个方向是一个更加适合我们的方向,所以还是选了 HTAP 这个词。现在很欣喜的看到现在各种友商、后来的一些数据库,都开始争相说 HTAP,就是说得到了同行的认可。\n\n那么在 HTAP 的未来应该是一个什么样子,我希望能够在今年这个 Talk 里面先说一说,但是这个题目起的有点不太谦虚,所以我特地加了一个「Near」, 分享一下这一年、两年、三年我们想做什么,和对行业大趋势的展望。\n\n\n\n图 1
\n\n**今天我们的分享的一个主题就是:「我们只做用户想要的东西,并不是要去做一个完美的东西」**。其实很多工程师包括我们自己,都会有一个小小的心理的洁癖,就是想要做一个超级快、超级牛的东西,但是做出来一个数据库,单机跑分一百万 TPS ,其实用户实际业务就需要 3000,然后所有的用户还会说我需要这些东西,比如需要 Scalability(弹性扩展), Super Large 的数据量,最好是我的业务一行代码都不用改,而且 ACID 能够完全的满足,怎么踹都踹不坏,机器坏了可以高可用,业务层完全不用动, 另外可以在跑 OLTP 的同时,完全不用担心任何资源隔离地跑 OLAP(这里不是要说大家的愿望不切实际,而是非常切实际,我们也觉得数据库本身就应该是这样的。所以大家记住这几个要点,然后慢慢看 TiDB 到底是不是朝着这个方向发展的)。**本质上来说用户的需求就是「大一统」。看过《魔戒》的同学都知道这句话 :ONE RING TO RULE THEM ALL,就是一套解决方案去解决各种问题**。\n\n过去很多,包括一些行业的大佬之前说在各种环境下都要出一个数据库来解决特定的一个问题,但是其实看上去我们想走的方案还是尽可能在一个平台里面,尽可能大范围去解决用户的问题。因为不同的产品之间去做数据的交互和沟通,其实是蛮复杂的。\n\n\n\n图 2 理想中的「赛道」
\n\n这张图(图 2)什么意思呢?就是很多人设计系统的时候,总是会陷入跑分思维,就是说这个东西在实验室或者说在一个特定的 Workload 下,跑得巨快无比。如果大家去看一下大概 2000 年以后关于数据库的论文,很多在做一个新的模型或者新的系统的时候,都会说 TPCC 能够跑到多大,然后把 Oracle 摁在地上摩擦,这样的论文有很多很多很多。但是大家回头看看 Oracle 还是王者。所以大多数实验室的产品和工程师自己做的东西都会陷入一个问题,就是想象中的我的赛道应该是一个图 2 那样的,但实际上用户的业务环境是下面这样的(图 3)。很多大家在广告上看到特别牛的东西,一放到生产环境或者说放到自己的业务场景里面就不对了,然后陷入各种各样的比较和纠结的烦恼之中。\n\n\n\n图 3 实际上用户的业务环境
\n\nTiDB 的定位或者说我们想做的事情,并不是在图 2 那样的赛道上,跑步跑得巨快,全世界没人在短跑上跑得过我,我们不想做这样。或者说,**我们其实也能跑得很快,但是并不想把所有优势资源全都投入到一个用户可能一辈子都用不到的场景之中。我们其实更像是做铁人三项的,因为用户实际应用场景可能就是一个土路。这就是为什么 TiDB 的设计放在第一位的是「稳定性」**。\n\n我们一直在想能不能做一个数据库,怎么踹都踹不坏,然后所有的异常的状况,或者它的 Workload 都是可预期的。我觉得很多人远远低估了这个事情的困难程度,其实我们自己也特别低估了困难程度。大概 4 年前出来创业的时候,我们就是想做这么一个数据库出来,我跟刘奇、崔秋三个人也就三个月做出来了。但是到现在已经 4 年过去了,我们的目标跟当年还是一模一样。不忘初心,不是忘不掉,而是因为初心还没达到,怎么忘?其实把一个数据库做稳,是很难很难的。\n\n\n\n\n图 4 近年来硬件的发展
\n\n**而且我们这个团队的平均年龄可能也就在二十到三十岁之间,为什么我们如此年轻的一个团队,能够去做数据库这么古老的一件事情。其实也是得益于整个 IT 行业这几年非常大的发展**。图 4 是这几年发展起来的 SSD,内存越来越大,万兆的网卡,还有各种各样的多核的 CPU,虚拟化的技术,让过去很多不可能的事情变成了可能。\n\n举一个例子吧,比如极端一点,大家可能在上世纪八九十年代用过这种 5 寸盘、3 寸盘,我针对这样的磁盘设计一个数据结构,现在看上去是个笑话是吧?因为大家根本没有人用这样的设备了。在数据库这个行业里面很多的假设,在现在新的硬件的环境下其实都是不成立的。比如说,为什么 B-Tree 就一定会比 LSM-Tree 要快呢?不一定啊,我跑到 Flash 或者 NVMe SSD 、Optane 甚至未来的持久化内存这种介质上,那数据结构设计完全就发生变化了。过去可能需要投入很多精力去做的数据结构,现在暴力就好了。\n\n\n\n图 5 近年来软件变革
\n\n同时在软件上也发生了很多很多的变革,图 5 左上角是 Wisckey 那篇论文里的一个截图,还有一些分布式系统上的新的技术,比如 2014 年 Diego 发表了 Raft 这篇论文,另外 Paxos 这几年在各种新的分布式系统里也用得越来越多。\n\n**所以我觉得这几年我们赶上了一个比较好的时代,就是不管是软件还是硬件,还是分布式系统理论上,都有了一些比较大突破,所以我们基础才能够打得比较好**。\n\n\n\n图 6 Data Type
\n\n除了有这样的新的硬件和软件之外,我觉得在业务场景上也在发生一些比较大变化。过去,可能十年前就是我刚开始参加工作的时候,线上的架构基本就是在线和离线两套系统,在线是 Oracle 和 MySQL,离线是一套 Hadoop 或者一个纯离线的数据仓库。**但最近这两年越来越多的业务开始强调敏捷、微服务和中台化,于是产生了一个新的数据类型,就是 warm data,它需要像热数据这样支持 transaction、支持实时写入,但是需要海量的数据都能存在这个平台上实时查询, 并不是离线数仓这种业务**。\n\n所以对 warm data 来说,过去在 TiDB 之前,其实是并没有太好的办法去很优雅的做一层大数据中台架构的,**「the missing part of modern data processing stack」,就是在 warm data 这方面,TiDB 正好去补充了这个位置,所以才能有这么快的增长**。当然这个增长也是得益于 MySQL 社区的流行。\n\n\n\n图 7 应用举例
\n\n想象一下,我们如果在过去要做这样很简单的业务(图 7),比如在美国的订单库跟在中国的订单库可能都是在不同的数据库里,用户库可能是另外一个库,然后不同的业务可能是操作不同的库。如果我想看看美国的消费者里面有哪些在中国有过消费的,就是这么一条 SQL。过去如果没有像 TiDB 这样的东西,大家想象这个东西该怎么做?\n\n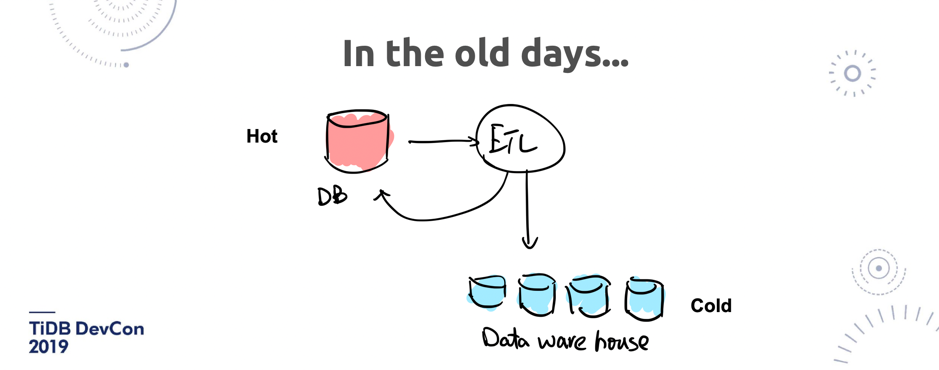\n\n图 8 过去的解决方案
\n\n假如说这两边的数据量都特别大,然后已经分库分表了。过去可能只能第二天才可以看到前一天的数据,因为中间比如说一个 T+1 要做一个 ETL 到一个 data ware house 里。或者厉害一点的架构师可能会说,我可以做一套实时的 OLAP 来做这个事情,怎么做呢?比如说 MySQL 中间通过一个 MQ 再通过 Hadoop 做一下 ETL,然后再导到 Hadoop 上做一个冷的数据存储,再在上面去跑一个 OLAP 做实时的分析。先不说这个实时性到底有多「实时」,大家仔细算一算,这套架构需要的副本数有多少,比如 M 是我的业务数,N 是每一个系统会存储的 Replica,拍脑袋算一下就是下面这个数字(图 9 中的 **R** )。\n\n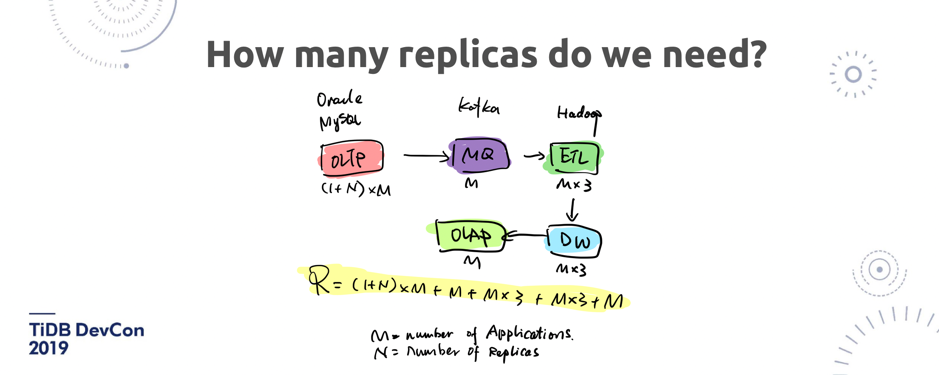\n\n图 9 过去解决方案里需要的 Replica 数量
\n\n所以大家其实一开始在过去说,TiDB 这个背后这么多 Replica 不好,但其实你想想,你自己在去做这个业务的时候,大家在过去又能怎么样呢?所以我觉得 TiDB 在这个场景下去统一一个中台,是一个大的趋势。今天在社区实践分享上也看到很多用户都要提到了 TiDB 在中台上非常好的应用。\n\n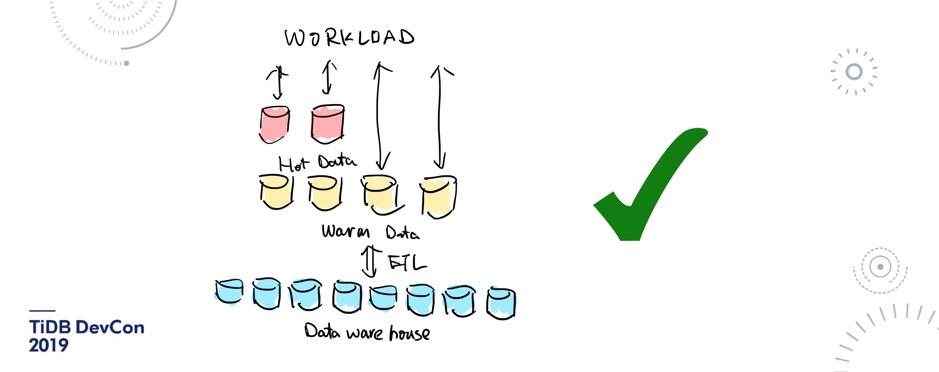\n\n图 10 现在的解决方案
\n\n**回顾完行业和应用场景近年来的一些变化之后,我们再说说未来。假设要去做一个面向未来的数据库,会使用哪些技术?**\n\n## 1. Log is the new database\n\n第一个大的趋势就是日志,「log is the new database」 这句话应该也是业界的一个共识吧。现在如果有一个分布式数据库的复制协议,还是同步一个逻辑语句过去,或者做 binlog 的复制,那其实还算比较 low 的。\n\n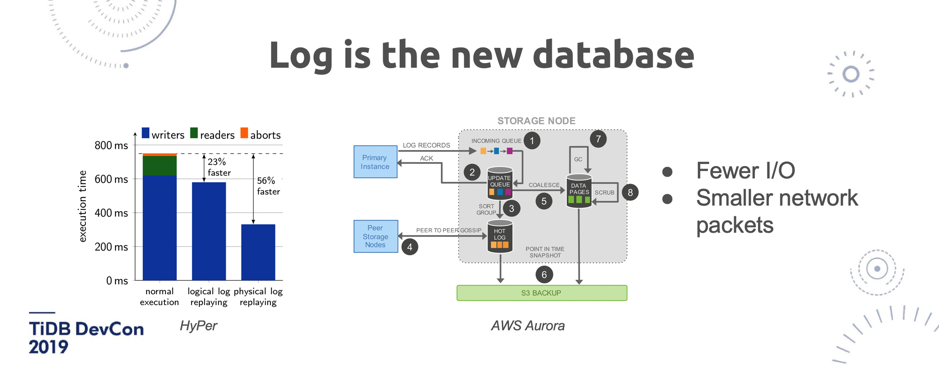\n\n图 11 Log is the new database
\n\n上面图 11 左半部分是 Hyper,它是慕尼黑工业大学的一个实验性数据库项目,它做了一些分析,第一个柱形是正常的 SQL 语句的执行时间,比如说直接把一语句放到另外一个库里去执行,耗时这么多。第二个柱形是用逻辑日志去存放,耗时大概能快 23%,第三个柱形能看到如果是存放物理日志能快 56%。所以大家仔细想想,**TiDB 的架构里的 TiFlash 其实同步的是 Raft 日志,而并不是同步 Binlog 或者其他的**。\n\n上面图 11 右半部分是 Aurora,它的架构就不用说了,同步的都是 redo log 。其实他的好处也很明显,也比较直白,就是 I/O 更小,网络传输的 size 也更小,所以就更快。\n\n然后在这一块 TiDB 跟传统的数据库有点不一样的就是,其实如果很多同学对 TiDB 的基础架构不太理解的话就觉得, Raft 不是一个一定要有 Index 或者说是一定强顺序的一个算法吗?那为什么能做到这样的乱序的提交?**其实 TiDB 并不是单 Raft 的架构,而是一个多 Raft 的架构,I/O 可以发生在任何一个 Raft Group 上**。传统的单机型数据库,就算你用更好的硬件都不可能达到一个线性扩展,因为无论怎么去做,都是这么一个架构不可改变。比如说我单机上 Snapshot 加 WAL,不管怎么写, 总是在 WAL 后面加,I/O 总是发生在这。但 TiDB 的 I/O 是分散在多个 Raft Group、多个机器上,这是一个很本质的变化,这就是为什么在一些场景下,TiDB 能够获取更好的吞吐。\n\n## 2. Vectorized\n\n第二个大趋势是全面的向量化。向量化是什么意思?我举个简单的例子。比如我要去算一个聚合,从一个表里面去求某一列的总量数据,如果我是一个行存的数据库,我只能把这条记录的 C 取出来,然后到下一条记录,再取再取再取,整个 Runtime 的开销也好,还有去扫描、读放大的每一行也好,都是很有问题的。但是如果在内存里面已经是一个列式存储,是很紧凑的结构的话,那会是非常快的。\n\n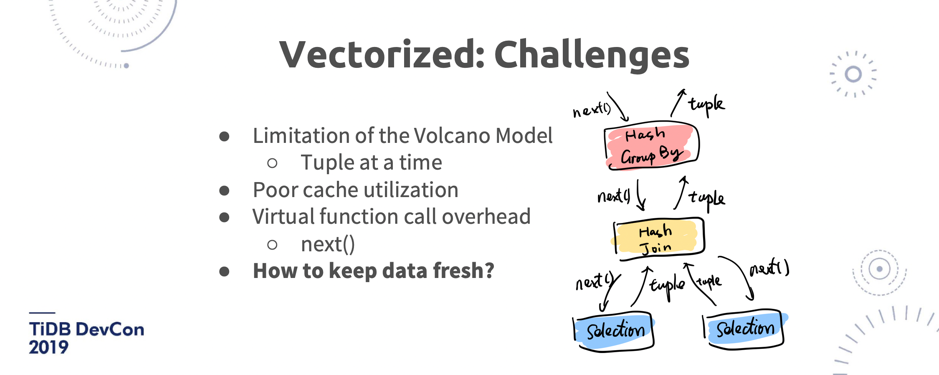\n\n图 12 TiDB 向量化面临的挑战
\n\n这里面其实也有一些挑战。我们花了大概差不多 2018 年一年的时间去做向量化的改造,其实还挺难的。为什么?首先 TiDB SQL 引擎是用了 Volcano 模型,这个模型很简单,就是遍历一棵物理计划的树,不停的调 Next,每一次 Next 都是调用他的子节点的 Next,然后再返回结果。这个模型有几个问题:第一是每一次都是拿一行,导致 CPU 的 L1、L2 这样的缓存利用率很差,就是说没有办法利用多 CPU 的 Cache。第二,在真正实现的时候,它内部的架构是一个多级的虚函数调用。大家知道虚函数调用在 Runtime 本身的开销是很大的,在[《MonetDB/X100: Hyper-Pipelining Query Execution》](http://cidrdb.org/cidr2005/papers/P19.pdf)里面提到,在跑 TPC-H 的时候,Volcano 模型在 MySQL 上跑,大概有 90% 的时间是花在 MySQL 本身的 Runtime 上,而不是真正的数据扫描。所以这就是 Volcano 模型一个比较大的问题。第三,如果使用一个纯静态的列存的数据结构,大家知道列存特别大问题就是它的更新是比较麻烦的, 至少过去在 TiFlash 之前,没有一个列存数据库能够支持做增删改查。那在这种情况下,怎么保证数据的新鲜?这些都是问题。\n\n\n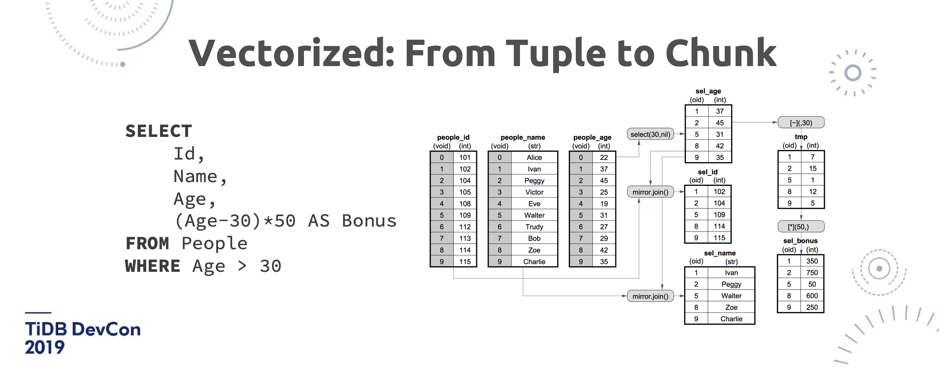\n\n图 13 TiDB SQL 引擎向量化
\n\nTiDB 已经迈出了第一步,我们已经把 TiDB SQL 引擎的 Volcano 模型,从一行一行变成了一个 Chunk 一个 Chunk,每个 Chunk 里面是一个批量的数据,所以聚合的效率会更高。而且在 TiDB 这边做向量化之外,我们还会把这些算子推到 TiKV 来做,然后在 TiKV 也会变成一个全向量化的执行器的框架。\n\n## 3. Workload Isolation\n\n另外一个比较大的话题,是 Workload Isolation。今天我们在演示的各种东西都有一个中心思想,就是怎么样尽可能地把 OLTP 跟 OLAP 隔离开。这个问题在业界也有不同的声音,包括我们的老前辈 Google Spanner,他们其实是想做一个新的数据结构,来替代 Bigtable-Like SSTable 数据结构,这个数据结构叫 Ressi,大家去看 2018 年 《Spanner: Becoming a SQL System》这篇 Paper 就能看到。它其实表面上看还是行存,但内部也是一个 Chunk 变成列存这样的一个结构。但我们觉得即使是换一个新的数据结构,也没有办法很好做隔离,因为毕竟还是在一台机器上,在同一个物理资源上。最彻底的隔离是物理隔离。\n\n\n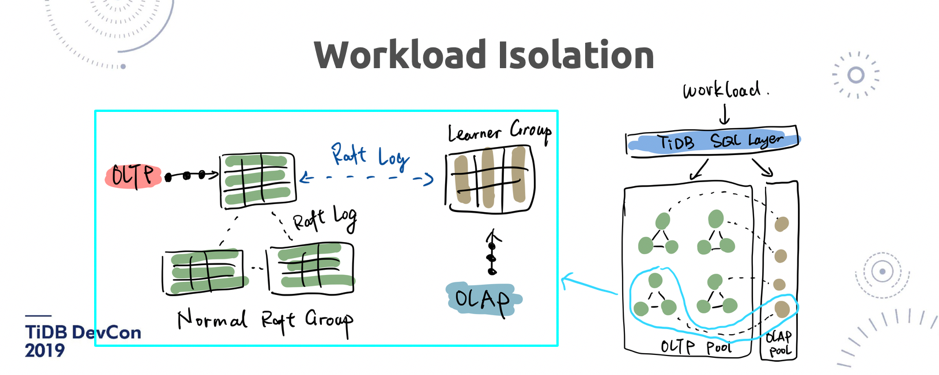\n\n图 14 TiFlash 架构
\n\n我们在 TiFlash 用了好几种技术来去保证数据是更新的。一是增加了 Raft Leaner,二是我们把 TiDB 的 MVCC 也实现在了 TiFlash 的内部。第三在 TiFlash 这边接触了更新(的过程),在 TiFlash 内部还有一个小的 Memstore,来处理更新的热数据结果,最后查询的时候,是列存跟内存里的行存去 merge 并得到最终的结果。**TiFlash 的核心思想就是通过 Raft 的副本来做物理隔离**。\n\n这个有什么好处呢?这是我们今天给出的答案,但是背后的思考,到底是什么原因呢?为什么我们不能直接去同步一个 binlog 到另外一个 dedicate 的新集群上(比如 TiFlash 集群),而一定要走 Raft log?**最核心的原因是,我们认为 Raft log 的同步可以水平扩展的**。因为 TiDB 内部是 Mult-Raft 架构,Raft log 是发生在每一个 TiKV 节点的同步上。大家想象一下,如果中间是通过 Kafka 沟通两边的存储引擎,那么实时的同步会受制于中间管道的吞吐。比如图 14 中绿色部分一直在更新,另一边并发写入每秒两百万,但是中间的 Kafka 集群可能只能承载 100 万的写入,那么就会导致中间的 log 堆积,而且下游的消费也是不可控的。**而通过 Raft 同步, Throughput 可以根据实际存储节点的集群大小,能够线性增长。这是一个特别核心的好处**。\n\n## 4. SIMD\n\n说完了存储层,接下来说一说执行器。TiDB 在接下来会做一个很重要的工作,就是全面地 leverage SIMD 的计算。我先简单科普一下 SIMD 是什么。\n\n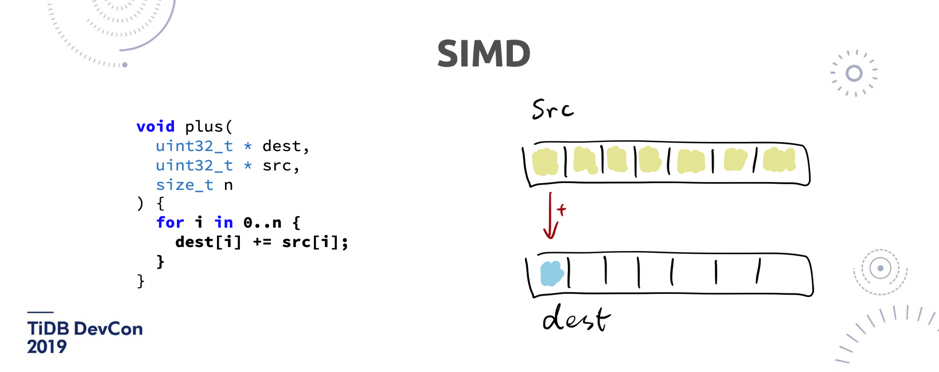\n\n\n图 15 SIMD 原理举例(1/2)
\n\n如图 15,在做一些聚合的时候,有这样一个函数,我要去做一个求和。正常人写程序,他就是一个 for 循环,做累加。但是在一个数据库里面,如果有一百亿条数据做聚合,每一次执行这条操作的时候,CPU 的这个指令是一次一次的执行,数据量特别大或者扫描的行数特别多的时候,就会很明显的感受到这个差别。\n\n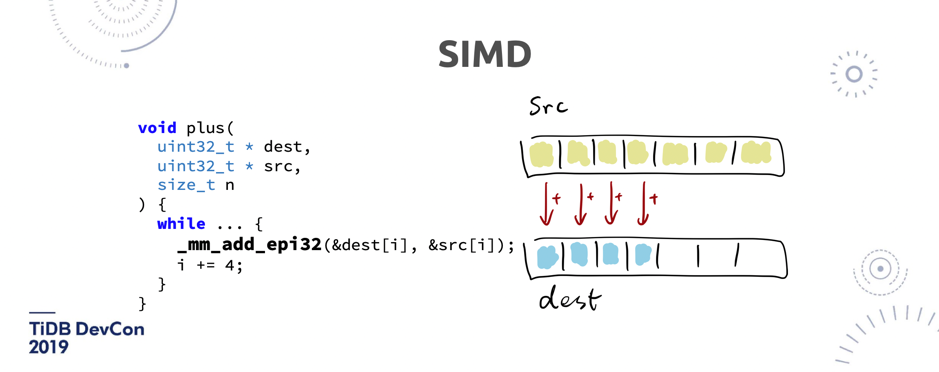\n\n图 16 SIMD 原理举例(2/2)
\n\n现代的 CPU 会支持一些批量的指令,比如像 _mm_add_epi32,可以一次通过一个32 位字长对齐的命令,批量的操作 4 个累加。看上去只是省了几个 CPU 的指令,但如果是在一个大数据量的情况下,基本上能得到 4 倍速度的提升。\n\n**顺便说一句,有一个很大的趋势是 I/O 已经不是瓶颈了**,大家一定要记住我这句话。再过几年,如果想去买一块机械磁盘,除了在那种冷备的业务场景以外,我相信大家可能都要去定制一块机械磁盘了。未来一定 I/O 不会是瓶颈,那瓶颈会是什么?CPU。**我们怎么去用新的硬件,去尽可能的把计算效率提升,这个才是未来我觉得数据库发展的重点**。比如说我怎么在数据库里 leverage GPU 的计算能力,因为如果 GPU 用的好,其实可以很大程度上减少计算的开销。所以,如果在单机 I/O 这些都不是问题的话,下一个最大问题就是怎么做好分布式,这也是为什么我们一开始就选择了一条看上去更加困难的路:我要去做一个 Share-nothing 的数据库,并不是像 Aurora 底下共享一个存储。\n\n## 5. Dynamic Data placement\n\n\n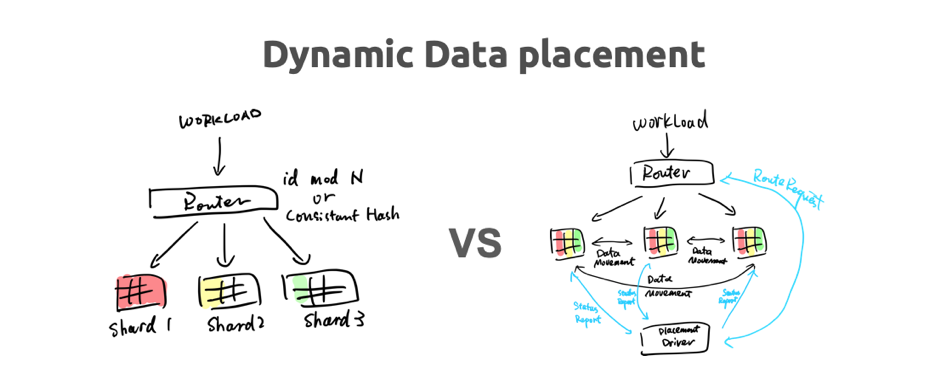\n\n图 17 Dynamic Data placement (1/2)分库分表方案与 TiDB 对比
\n\n在今天大家其实看不到未来十年数据增长是怎样的,回想十年前大家能想到现在我们的数据量有这么大吗?不可能的。所以新的架构或者新的数据库,一定要去面向我们未知的 Scale 做设计。比如大家想象现在有业务 100T 的数据,目前看可能还挺大的,但是有没有办法设计一套方案去解决 1P、2P 这样数据量的架构?**在海量的数据量下,怎么把数据很灵活的分片是一个很大的学问**。\n\n为什么分库分表在对比 TiDB 的时候,我们会觉得分库分表是上一代的方案。这个也很好理解,核心的原因是分库分表的 Router 是静态的。如果出现分片不均衡,比如业务可能按照 User ID 分表,但是发现某一地方/某一部分的 User ID 特别多,导致数据不均衡了,这时 TiDB 的架构有什么优势呢?就是 TiDB 彻底把分片这个事情,从数据库里隔离了出来,放到了另外一个模块里。**分片应该是根据业务的负载、根据数据的实时运行状态,来决定这个数据应该放在哪儿。这是传统的静态分片不能相比的,不管传统的用一致性哈希,还是用最简单的对机器数取模的方式去分片(都是不能比的)**。\n\n在这个架构下,甚至未来我们还能让 AI 来帮忙。把分片操作放到 PD 里面,它就像一个 DBA 一样,甚至预测 Workload 给出数据分布操作。比如课程报名数据库系统,系统发现可能明天会是报名高峰,就事先把数据给切分好,放到更好的机器上。这在传统方案下是都需要人肉操作,其实这些事情都应该是自动化的。\n\n\n\n图 18 Dynamic Data placement (2/2)
\n\n**Dynamic Data placement 好处首先是让事情变得更 flexible ,对业务能实时感知和响应**。另外还有一点,为什么我们有了 Dynamic Placement 的策略,还要去做 Table Partition([今天上午申砾也提到了](https://zhuanlan.zhihu.com/p/57749943))?Table Partition 在背后实现其实挺简单的。相当于业务这边已经告诉我们数据应该怎么分片比较好,我们还可以做更多针对性的优化。这个 Partition 指的是逻辑上的 Partition ,是可能根据你的业务相关的,比如说我这张表,就是存着 2018 年的数据,虽然我在底下还是 TiDB 这边,通过 PD 去调度,但是我知道你 Drop 这个 Table 的时候,一定是 Drop 这些数据,所以这样会更好,而且更加符合用户的直觉。\n\n但这样架构仍然有比较大的挑战。当然这个挑战在静态分片的模型上也都会有。比如说围绕着这个问题,我们一直在去尝试解决怎么更快的发现数据的热点,比如说我们的调度器,如果最好能做到,比如突然来个秒杀业务,我们马上就发现了,就赶紧把这块数据挪到好的机器上,或者把这块数据赶紧添加副本,再或者把它放到内存的存储引擎里。这个事情应该是由数据库本身去做的。所以为什么我们这么期待 AI 技术能够帮我们,是因为虽然在 TiDB 内部,用了很多规则和方法来去做这个事情,但我们不是万能的。\n\n## 6. Storage and Computing Seperation\n\n\n\n图 19 存储计算分离
\n\n还有大的趋势是存储计算分离。我觉得现在业界有一个特别大的问题,就是把存储计算分离给固化成了某一个架构的特定一个指代,比如说只有长的像 Aurora 那样的架构才是存储计算分离。那么 TiDB 算存储计算分离吗?我觉得其实算。**或者说存储计算分离本质上带来的好处是什么?就是我们的存储依赖的物理资源,跟计算所依赖的物理资源并不一样。这点其实很重要**。就用 TiDB 来举例子,比如计算可能需要很多 CPU,需要很多内存来去做聚合,存储节点可能需要很多的磁盘和 I/O,如果全都放在一个组件里 ,调度器就会很难受:我到底要把这个节点作为存储节点还是计算节点?其实在这块,可以让调度器根据不同的机型(来做决定),是计算型机型就放计算节点,是存储型机型就放存储节点。\n\n## 7. Everything is Pluggable\n\n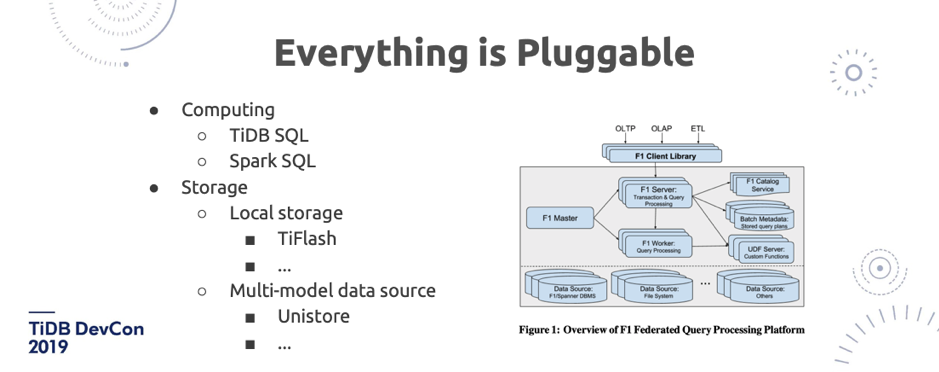\n\n图 20 Everything is Pluggable
\n\n今天由于时间关系没有给大家演示的**插件平台**。未来 TiDB 会变成一个更加灵活的框架,像图 20 中 TiFlash 是一个 local storage,我们其实也在秘密研发一个新的存储的项目叫 Unitstore,可能明年的 DevCon 就能看到它的 Demo 了。在计算方面,每一层我们未来都会去对外暴露一个非常抽象的接口,能够去 leverage 不同的系统的好处。今年我其实很喜欢的一篇 Paper 是 [F1 Query](https://mp.weixin.qq.com/s/PrX0yhGkoPzQUZFQ2EkIbw) 这篇论文,基本表述了我对一个大规模的分布式系统的期待,架构的切分非常漂亮。\n\n## 8. Distributed Transaction\n\n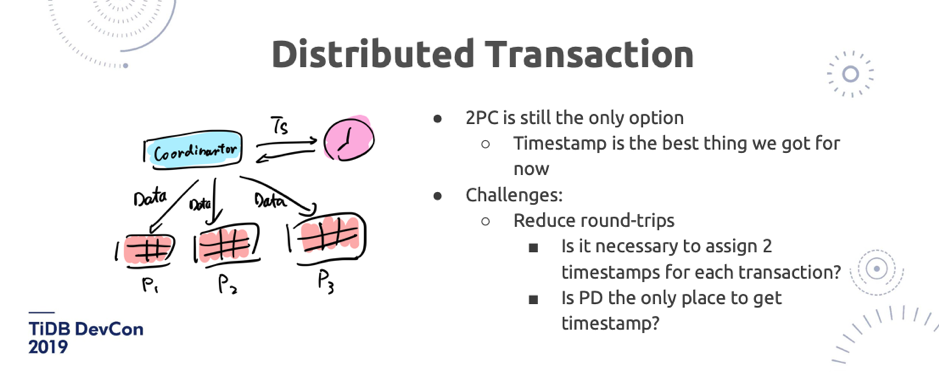\n\n图 21 Distributed Transaction(1/2)
\n\n说到分布式事务,我也分享一下我的观点。**目前看上去,ACID 事务肯定是必要的**。我们仍然还没有太多更好的办法,除了 Google 在这块用了原子钟,Truetime 非常牛,我们也在研究各种新型的时钟的技术,但是要把它推广到整个开源社区也不太可能。当然,时间戳,不管是用硬件还是软件分配,仍然是我们现在能拥有最好的东西, 因为如果要摆脱中心事务管理器,时间戳还是很重要的。**所以在这方面的挑战就会变成:怎么去减少两阶段提交带来的网络的 round-trips?或者如果有一个时钟的 PD 服务,怎么能尽可能的少去拿时间戳?**\n\n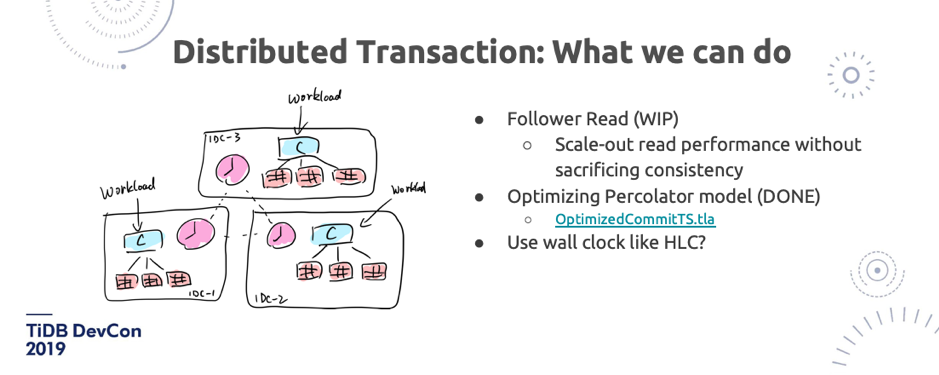\n\n图 22 Distributed Transaction(2/2)
\n\n我们在这方面的理论上有一些突破,我们把 Percolator 模型做了一些优化,能够在数学上证明,可以少拿一次时钟。虽然我们目前还没有在 TiDB 里去实现,但是我们已经把数学证明的过程已经开源出来了,我们用了 [TLA+ 这个数学工具去做了证明](https://github.com/pingcap/tla-plus/blob/master/OptimizedCommitTS/OptimizedCommitTS.tla)。此外在 PD 方面,我们也在思考是不是所有的事务都必须跑到 PD 去拿时间戳?其实也不一定,我们在这上面也已有一些想法和探索,但是现在还没有成型,这个不剧透了。另外我觉得还有一个非常重要的东西,就是 Follower Read。很多场景读多写少,读的业务压力很多时候是要比写大很多的,Follower Read 能够帮我们线性扩展读的性能,而且在我们的模型上,因为没有时间戳 ,所以能够在一些特定情况下保证不会去牺牲一致性。\n\n## 9. Cloud-Native Architecture\n\n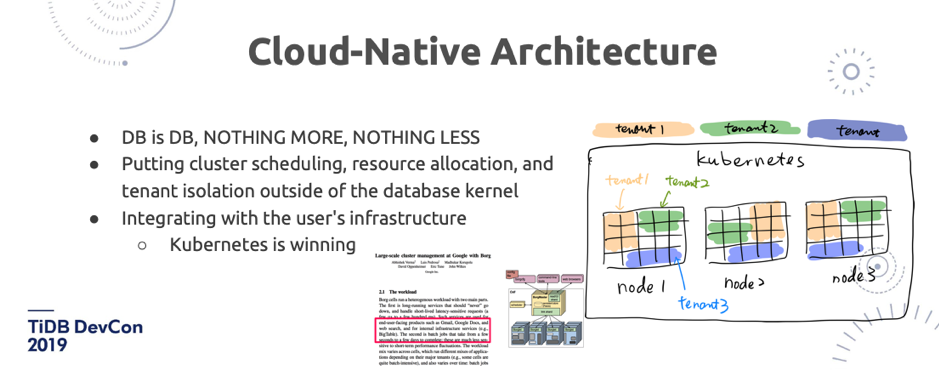\n\n图 23 Cloud-Native
\n\n另外一点就是 Cloud-Native。刚刚中午有一个社区小伙伴问我,你们为什么不把多租户做在 TiDB 的系统内部?**我想说「数据库就是数据库」,它并不是一个操作系统,不是一个容器管理平台。我们更喜欢模块和结构化更清晰的一个做事方式。**而且 Kubernetes 在这块已经做的足够好了 ,我相信未来 K8s 会变成集群的新操作系统,会变成一个 Linux。比如说如果你单机时代做一个数据库,你会在你的数据库里面内置一个操作系统吗?肯定不会。所以这个模块抽象的边界,在这块我还是比较相信 K8s 的。《Large-scale cluster management at Google with Borg》这篇论文里面提到了一句话,BigTable 其实也跑在 Borg 上。\n\n\n\n图 24 TiDB 社区小伙伴的愿望列表
\n\n当然最后,大家听完这一堆东西以后,回头看我们社区小伙伴们的愿望列表(图 24),就会发现对一下 TiDB 好像还都能对得上 :D \n\n谢谢大家。\n\n>1 月 19 日 TiDB DevCon 2019 在北京圆满落幕,超过 750 位热情的社区伙伴参加了此次大会。会上我们首次全面展示了全新存储引擎 Titan、新生态工具 TiFlash 以及 TiDB 在云上的进展,同时宣布 TiDB-Lightning Toolset & TiDB-DM 两大生态工具开源,并分享了 TiDB 3.0 的特性与未来规划,描述了我们眼中未来数据库的模样。此外,更有 11 位来自一线的 TiDB 用户为大家分享了实践经验与踩过的「坑」。同时,我们也为新晋 TiDB Committer 授予了证书,并为 2018 年最佳社区贡献个人、最佳社区贡献团队颁发了荣誉奖杯。","date":"2019-03-05","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"the-near-future-of-database","file":null,"relatedBlogs":[]},{"id":"Blogs_260","title":"十问 TiDB :关于架构设计的一些思考","tags":["TiDB","架构"],"category":{"name":"观点洞察"},"summary":"这篇文章是关于 TiDB 代表性“为什么”的 TOP 10,希望大家在了解了我们这些背后的选择之后,能更加纯熟的使用 TiDB,让它在适合的环境里更好的发挥价值。","body":">“我希望能够把 TiDB 的设计的一些理念能够更好的传达给大家,相信大家理解了背后原因后,就能够把 TiDB 用的更好。”\n\n\n做 TiDB 的缘起是从思考一个问题开始的:为什么在数据库领域有这么多永远也躲不开的坑?从 2015 年我们写下第一行代码,3 年以来我们迎面遇到无数个问题,一边思考一边做,尽量用最小的代价来快速奔跑。\n\n作为一个开源项目,TiDB 是我们基础架构工程师和社区一起努力的结果,TiDB 已经发版到 2.0,有了一个比较稳定的形态,大量在生产环境使用的伙伴们。可以负责任的说,我们做的任何决定都经过了非常慎重的思考和实践,是经过内部和社区一起论证产生的结果。它未必是最好的,但是在这个阶段应该是最适合我们的,而且大家也可以看到 TiDB 在快速迭代进化。\n\n**这篇文章是关于 TiDB 代表性“为什么”的 TOP 10,希望大家在了解了我们这些背后的选择之后,能更加纯熟的使用 TiDB,让它在适合的环境里更好的发挥价值。**\n\n这个世界有很多人,感觉大于思想,疑问多于答案。感恩大家保持疑问,我们承诺回馈我们的思考过程,毕竟有时候很多思考也很有意思。\n\n## 一、为什么分布式系统并不是银弹\n\n其实并没有什么技术是完美和包治百病的,在存储领域更是如此,如果你的数据能够在一个 MySQL 装下并且服务器的压力不大,或者对复杂查询性能要求不高,其实分布式数据库并不是一个特别好的选择。 选用分布式的架构就意味着引入额外的维护成本,而且这个成本对于特别小的业务来说是不太划算的,即使你说需要高可用的能力,那 MySQL 的主从复制 + GTID 的方案可能也基本够用,这不够的话,还有最近引入的 Group Replication。而且 MySQL 的社区足够庞大,你能 Google 找到几乎一切常见问题的答案。 \n\n**我们做 TiDB 的初衷并不是想要在小数据量下取代 MySQL,而是尝试去解决基于单机数据库解决不了的一些本质的问题。**\n\n有很多朋友问我选择分布式数据库的一个比较合适的时机是什么?我觉得对于每个公司或者每个业务都不太一样,我并不希望一刀切的给个普适的标准(也可能这个标准并不存在),但是有一些事件开始出现的时候:比如是当你发现你的数据库已经到了你每天开始绞尽脑汁思考数据备份迁移扩容,开始隔三差五的想着优化存储空间和复杂的慢查询,或者你开始不自觉的调研数据库中间件方案时,或者人肉在代码里面做 sharding 的时候,这时给自己提个醒,看看 TiDB 是否能够帮助你,我相信大多数时候应该是可以的。 \n\n而且另一方面,选择 TiDB 和选择 MySQL 并不是一刀切的有你没他的过程,我们为了能让 MySQL 的用户尽可能减小迁移和改造成本,做了大量的工具能让整个数据迁移和灰度上线变得平滑,甚至从 TiDB 无缝的迁移回来,而且有些小数据量的业务你仍然可以继续使用 MySQL。**所以一开始如果你的业务和数据量还小,大胆放心的用 MySQL 吧,MySQL still rocks,TiDB 在未来等你。**\n\n\n## 二、为什么是 MySQL\n\n和上面提到的一样,并不是 MySQL 不好我们要取代他,而是选择兼容 MySQL 的生态对我们来说是最贴近用户实际场景的选择:\n\n1. MySQL 的社区足够大,有着特别良好的群众基础,作为一个新的数据库来说,如果需要用户去学习一套新的语法,同时伴随很重的业务迁移的话,是很不利于新项目冷启动的。 \n\n2. MySQL 那么长时间积累下来大量的测试用例和各种依赖 MySQL 的第三方框架和工具的测试用例是我们一个很重要的测试资源,特别是在早期,你如何证明你的数据库是对的,MySQL 的测试就是我们的一把尺子。 \n\n3. 已经有大量的已有业务正在使用 MySQL,同时也遇到了扩展性的问题,如果放弃这部分有直接痛点的场景和用户,也是不明智的。\n\n另一方面来看,MySQL 自从被 Oracle 收购后,不管是性能还是稳定性这几年都在稳步的提升,甚至在某些场景下,已经开始有替换 Oracle 的能力,从大的发展趋势上来说,是非常健康的,所以跟随着这个健康的社区一起成长,对我们来说也是一个商业上的策略。\n\n## 三、为什么 TiDB 的设计中 SQL 层和存储层是分开的\n\n一个显而易见的原因是对运维的友好性。很多人觉得这个地方稍微有点反直觉,多一个组件不就会增加部署的复杂度吗?\n\n其实在实际生产环境中,运维并不仅仅包含部署。举个例子,如果在 SQL 层发现了一个 BUG 需要紧急的更新,如果所有部件都是耦合在一起的话,你面临的就是一次整个集群的滚动更新,如果分层得当的话,你可能需要的只是更新无状态的 SQL 层,反之亦然。 \n\n另外一个更深层次的原因是成本。存储和 SQL 所依赖的计算资源是不一样的,存储会依赖 IO,而计算对 CPU 以及内存的要求会更高,无需配置 PCIe/NVMe/Optane 等磁盘,而且这两者是不一定对等的,如果全部耦合在一起的话,对于资源调度是不友好的。 对于 TiDB 来说,目标定位是支持 HTAP,即 OLTP 和 OLAP 需要在同一个系统内部完成。显然,不同的 workload 即使对于 SQL 层的物理资源需求也是不一样的,OLAP 请求更多的是吞吐偏好型以及长 query,部分请求会占用大量内存,而 OLTP 面向的是短平快的请求,优化的是延迟和 OPS (operation per second),在 TiDB 中 SQL 层是无状态的,所以你可以将不同的 workload 定向到不同的物理资源上做到隔离。**还是那句话,对调度器友好,同时调度期的升级也不需要把整个集群全部升级一遍。**\n\n另一方面,底层存储使用 KV 对数据进行抽象,是一个更加灵活的选择。\n\n一个好处是简单。对于 Scale-out 的需求,对 KV 键值对进行分片的难度远小于对带有复杂的表结构的结构化数据,另外,存储层抽象出来后也可以给计算带来新的选择,比如可以对接其他的计算引擎,和 TiDB SQL 层同时平行使用,TiSpark 就是一个很好的例子。 \n\n从开发角度来说,这个拆分带来的灵活度还体现在可以选择不同的编程语言来开发。对于无状态的计算层来说,我们选择了 Go 这样开发效率极高的语言,而对于存储层项目 TiKV 来说,是更贴近系统底层,对于性能更加敏感,所以我们选择了 Rust,如果所有组件都耦合在一起很难进行这样的按需多语言的开发,对于开发团队而言,也可以实现专业的人干专业的事情,存储引擎的开发者和 SQL 优化器的开发者能够并行的开发。 另外对于分布式系统来说,所有的通信几乎都是 RPC,所以更明确的分层是一个很自然的而且代价不大的选择。\n\n## 四、为什么不复用 MySQL 的 SQL 层,而是选择自己重写\n\n这点是我们和很多友商非常不一样的地方。 目前已有的很多方案,例如 Aurora 之类的,都是直接基于 MySQL 的源码,保留 SQL 层,下面替换存储引擎的方式实现扩展,这个方案有几个好处:一是 SQL 层代码直接复用,确实减轻了一开始的开发负担,二是面向用户这端确实能做到 100% 兼容 MySQL 应用。\n\n但是缺点也很明显,MySQL 已经是一个 20 多年的老项目,设计之初也没考虑分布式的场景,整个 SQL 层并不能很好的利用数据分布的特性生成更优的查询计划,虽然替换底层存储的方案使得存储层看上去能 Scale,但是计算层并没有,在一些比较复杂的 Query 上就能看出来。另外,如果需要真正能够大范围水平扩展的分布式事务,依靠 MySQL 原生的事务机制还是不够的。\n\n自己重写整个 SQL 层一开始看上去很困难,但其实只要想清楚,有很多在现代的应用里使用频度很小的语法,例如存储过程什么的,不去支持就好了,至少从 Parser 这层,工作量并不会很大。 同时优化器这边自己写的好处就是能够更好的与底层的存储配合,另外重写可以选择一些更现代的编程语言和工具,使得开发效率也更高,从长远来看,是个更加省事的选择。\n\n## 五、为什么用 RocksDB 和 Etcd Raft\n\n很多工程师都有着一颗造轮子(玩具)的心,我们也是,但是做一个工业级的产品就完全不一样了,目前的环境下,做一个新的数据库,底层的存储数据结构能选的大概就两种:1. B+Tree, 2. LSM-Tree。\n\n但是对于 B+Tree 来说每个写入,都至少要写两次磁盘: 1. 在日志里; 2. 刷新脏页的时候,即使你的写可能就只改动了一个 Byte,这个 Byte 也会放大成一个页的写 (在 MySQL 里默认 InnoDB 的 Page size 是 16K),虽然说 LSM-Tree 也有写放大的问题,但是好处是 LSM-tree 将所有的随机写变成了顺序写(对应的 B+tree 在回刷脏页的时候可能页和页之间并不是连续的)。 另一方面,LSMTree 对压缩更友好,数据存储的格式相比 B+Tree 紧凑得多,Facebook 发表了一些关于 MyRocks 的文章对比在他们的 MySQL 从 InnoDB 切换成 MyRocks (Facebook 基于 RocksDB 的 MySQL 存储引擎)节省了很多的空间。所以 LSM-Tree 是我们的选择。\n\n选择 RocksDB 的出发点是 RocksDB 身后有个庞大且活跃的社区,同时 RocksDB 在 Facebook 已经有了大规模的应用,而且 RocksDB 的接口足够通用,并且相比原始的 LevelDB 暴露了很多参数可以进行针对性的调优。随着对于 RocksDB 理解和使用的不断深入,我们也已经成为 RocksDB 社区最大的使用者和贡献者之一,另外随着 RocksDB 的用户越来越多,这个项目也会变得越来越好,越来越稳定,可以看到在学术界很多基于 LSM-Tree 的改进都是基于 RocksDB 开发的,另外一些硬件厂商,特别是存储设备厂商很多会针对特定存储引擎进行优化,RocksDB 也是他们的首选之一。\n\n反过来,自己开发存储引擎的好处和问题同样明显,一是从开发到产品的周期会很长,而且要保证工业级的稳定性和质量不是一个简单的事情,需要投入大量的人力物力。好处是可以针对自己的 workload 进行定制的设计和优化,由于分布式系统天然的横向扩展性,单机有限的性能提升对比整个集群吞吐其实意义不大,把有限的精力投入到高可用和扩展性上是一个更加经济的选择。 另一方面,RocksDB 作为 LSM-Tree 其实现比工业级的 B+Tree 简单很多(参考对比 InnoDB),从易于掌握和维护方面来说,也是一个更好的选择。 当然,随着我们对存储的理解越来越深刻,发现很多专门针对数据库的优化在 RocksDB 上实现比较困难,这个时候就需要重新设计新的专门的引擎,就像 CPU 也能做图像处理,但远不如 GPU,而 GPU 做机器学习又不如专用的 TPU。\n\n选择 Etcd Raft 的理由也类似。先说说为什么是 Raft,在 TiDB 项目启动的时候,我们其实有过在 MultiPaxos 和 Raft 之间的纠结,后来结论是选择了 Raft。Raft 的算法整体实现起来更加工程化,从论文就能看出来,论文中甚至连 RPC 的结构都描述了出来,是一个对工业实现很友好的算法,而且当时工业界已经有一个经过大量用户考验的开源实现,就是 Etcd。而且 Etcd 更加吸引我们的地方是它对测试的态度,Etcd 将状态机的各个接口都抽象得很好,基本上可以做到与操作系统的 API 分离,极大降低了写单元测试的难度,同时设计了很多 hook 点能够做诸如错误注入等操作,看得出来设计者对于测试的重视程度。\n\n与其自己重新实现一个 Raft,不如借力社区,互相成长。现在我们也是 Etcd 社区的一个活跃的贡献者,一些重大的 Features 例如 Learner 等新特性,都是由我们设计和贡献给 Etcd 的,同时我们还在不断的为 Etcd 修复 Bug。\n\n没有完全复用 Etcd 的主要的原因是我们存储引擎的开发语言使用了 Rust,Etcd 是用 Go 写的,我们需要做的一个工作是将他们的 Raft 用 Rust 语言重写,为了完成这个事情,我们第一步是将 Etcd 的单元测试和集成测试先移植过来了(没错,这个也是选择 Etcd 的一个很重要的原因,有一个测试集作为参照),以免移植过程破坏了正确性。另外一方面,就如同前面所说,和 Etcd 不一样,TiKV 的 Raft 使用的是 Multi-Raft 的模型,同一个集群内会存在海量的互相独立 Raft 组,真正复杂的地方在如何安全和动态的分裂,移动及合并多个 Raft 组,我在我的 [《基于 Raft 构建弹性伸缩的存储系统的一些实践》](https://pingcap.com/blog-cn/building-distributed-db-with-raft/) 这篇文章里面描述了这个过程。\n\n## 六、为什么有这样的硬件配置要求\n\n我们其实对生产环境硬件的要求还是蛮高的,对于存储节点来说,SSD 或者 NVMe 或者 Optane 是刚需,另外对 CPU 及内存的使用要求也很高,同时对大规模的集群,网络也会有一些要求 (详见我们的官方文档推荐配置的 [相关章节](https://pingcap.com/docs-cn/FAQ/)),其中一个很重要的原因是我们底层的选择了 RocksDB 的实现,对于 LSM Tree 来说因为存在写放大的天然特性,对磁盘吞吐需求会相应的更高,尤其是 RocksDB 还有类似并行 Compaction 等特性。 而且大多数机械磁盘的机器配置倾向于一台机器放更大容量的磁盘(相比 SSD),但是相应的内存却一般来说不会更大,例如 24T 的机械磁盘 + 64G 内存,磁盘存储的数据量看起来更大,但是大量的随机读会转化为磁盘的读,这时候,机械磁盘很容易出现 IO 瓶颈,另一方面,对于灾难恢复和数据迁移来说,也是不太友好的。\n\n另外,TiDB 的各个组件目前使用 gRPC 作为 RPC 框架,gRPC 是依赖 [HTTP2](https://developers.google.com/web/fundamentals/performance/http2/) 作为底层协议,相比很多朴素的 RPC 实现,会有一些额外的 CPU 开销。TiKV 内部使用 RocksDB 的方式会伴随大量的 Prefix Scan,这意味着大量的二分查找和字符串比较,这也是和很多传统的离线数据仓库很不一样的 Pattern,这个会是一个 CPU 密集型的操作。在 TiDB 的 SQL 层这端,SQL 是计算密集型的应用这个自然不用说,另外对内存也有一定的需求。由于 TiDB 的 SQL 是一个完整的 SQL 实现,表达力和众多中间件根本不是一个量级,有些算子,比如 Hashjoin,就是会在内存里开辟一块大内存来执行 Join,所以如果你的查询逻辑比较复杂,或者 Join 的一张子表比较大的情况下(偏 OLAP 实时分析业务),对内存的需求也是比较高的,我们并没有像单机数据库的优化器一样,比如 Order by 内存放不下,就退化到磁盘上,我们的哲学是尽可能的使用内存。 如果硬件资源不足,及时的通过拒绝执行和失败通知用户,因为有时候半死不活的系统反而更加可怕。\n\n另外一方面,还有很多用户使用 TiDB 的目的是用于替换线上 OLTP 业务,这类业务对于性能要求是比较高的。 一开始我们并没有在安装阶段严格检查用户的机器配置,结果很多用户在硬件明显没有匹配业务压力的情况下上线,可能一开始没什么问题,但是峰值压力一上来,可能就会造成故障,尽管 TiDB 和 TiKV 对这种情况做了层层的内部限流,但是很多情况也无济于事。 所以我们决定将配置检查作为部署脚本的强制检查,一是减少了很多沟通成本,二是可以让用户在上线时尽可能的减少后顾之忧。\n\n## 七、为什么用 Range-based 的分片策略,而不是 Hash-based\n\nHash-based 的问题是实现有序的 Scan API 会比较困难,我们的目标是实现一个标准的关系型数据库,所以会有大量的顺序扫描的操作,比如 Table Scan,Index Scan 等。用 Hash 分片策略的一个问题就是,可能同一个表的数据是不连续的,一个顺序扫描即使几行都可能会跨越不同的机器,所以这个问题上没得选,只能是 Range 分片。 但是 Range 分片可能会造成一些问题,比如频繁读写小表问题以及单点顺序写入的问题。 在这里首先澄清一下,静态分片在我们这样的系统里面是不存在的,例如传统中间件方案那样简单的将数据分片和物理机一一对应的分片策略会造成:\n\n* 动态添加节点后,需要考虑数据重新分布,这里必然需要做动态的数据迁移;\n\n* 静态分片对于根据 workload 实时调度是不友好的,例如如果数据存在访问热点,系统需要能够快速进行数据迁移以便于将热点分散在不同的物理服务商上。\n\n回到刚才提到的基于 Range 分片的问题,刚才我说过,对于顺序写入热点的问题确实存在,但也不是不可解。对于大压力的顺序写入的场景大多数是日志或者类似的场景,这类场景的典型特点是读写比悬殊(读 << 写),几乎没有 Update 和随机删除,针对这种场景,写入压力其实可以通过 Partition Table 解决,这个已经在 TiDB 的开发路线图里面,今年之内会和大家见面。 \n\n另外还有一个频繁读写小表造成的热点问题。这个原因是,在底层,TiDB 的数据调度的最小单位是 Region,也就是一段段按字节序排序的键值 Key-Value Pairs (默认大小 96M),假设如果一个小表,总大小连 96M 都不到,访问还特别频繁,按照目前的机制,如果不强制的手动 Split,调度系统无论将这块数据调度到什么位置,新的位置都会出现热点,所以这个问题本质上是无解的。因此建议如果有类似的访问 pattern,尽可能的将通用的小表放到 Redis 之类的内存缓存中,或者甚至直接放在业务服务的内存里面(反正小)。 \n\n## 八、为什么性能(延迟)不是唯一的评价标准\n\n很多朋友问过我,TiDB 能替换 Redis 吗?大家对 Redis 和 TiDB 的喜爱之情我也很能理解,但是很遗憾,TiDB 并不是一个缓存服务,它支持跨行强一致事务,在非易失设备上实现持久化存储,而这些都是有代价的。\n\n简单来说,写磁盘的 IO 开销 (WAL,持久化),多副本高可用和保证分布式事务必然会牺牲延迟,更不用说做跨数据中心的同步了,在这点上,我认为如果需要很低延迟的响应速度(亚毫秒级)就需要在业务端做缓存了。TiDB 的定位是给业务提供一个可扩展的 The Source of Truth (真相之源),即使业务层的缓存失效,也有一个地方能够提供强一致的数据,而且业务不用关心容量问题。**另一方面,衡量一个分布式系统更有意义的指标是吞吐,这个观点我在很多文章里已经提到过,提高并发度,如果系统的吞吐能够随着集群机器数量线性提升,而且延迟是稳定的才有意义,而且这样才能有无限的提升空间。** 在实际的环境中,单个 TiDB 集群已经有一些用户使用到了百万级别的 QPS,这个在单机架构上是几乎不可能实现的。另外,这几年硬件的进步速度非常快,特别是 IO 相关的创新,比如 NVMe SSD 的普及,还有刚刚商用的持久化内存等新的存储介质。很多时候我们在软件层面上绞尽脑汁甚至牺牲代码的优雅换来一点点性能提升,很可能换块磁盘就能带来成倍的提升。\n\n**我们公司内部有一句话:Make it right before making it fast。正确性和可靠性的位置是在性能之前的,毕竟在一个不稳定的系统上谈性能是没有意义的。**\n\n\n## 九、为什么弹性伸缩能力如此重要\n\n在业务初期,数据量不大,业务流量和压力不大的时候,基本随便什么数据库都能够搞定,但很多时候业务的爆发性增长可能是没有办法预期的,特别是一些 ToC 端的应用。早期的 Twitter 用户一定对时不时的大鲸鱼(服务不可用)深恶痛绝,近一点还有前两年有一段时间爆红的足记 App,很短的时间之内业务和数据量爆发性增长,数据库几乎是所有这些案例中的核心瓶颈。 很多互联网的 DBA 和年轻的架构师会低估重构业务代码带来的隐形成本,在业务早期快速搞定功能和需求是最重要的。想象一下,业务快速增长,服务器每天都因为数据库过载停止服务的时候,DBA 告诉你没办法,先让你重新去把你的业务全改写成分库分表的形式,在代码里到处加 Sharding key,牺牲一切非 Sharding key 的多维关联查询和相关的跨 Shard 的强一致事务,然后数据复制好多份……这种时候是真正的时间等于金钱,决定这个公司生死存亡的时候不是去写业务和功能代码,而是因为基础设施的限制被迫重构,其实是非常不好的。 如果这个时候,有一个方案,能够让你几乎无成本的,不修改业务代码的时候对数据库吞吐进行线性扩展(无脑加机器其实是最便宜的),最关键的是为了业务的进化争取了时间,我相信这个选择其实一点都不难做。\n\n**其实做 TiDB 的初心正是如此,我们过去见到了太多类似的血和泪,实在不能忍了,分库分表用各种中间件什么的炫技是很简单,但是我们想的是真正解决很多开发者和 DBA 眼前的燃眉之急。**\n\n最近这段时间,有两个用户的例子让我印象很深,也很自豪,一个是 Mobike,一个是转转,前者是 TiDB 的早期用户,他们自己也在数据增长很快的时候就开始使用 TiDB,在快速的发展过程中没有因为数据库的问题掉链子;后者是典型的快速发展的互联网公司,一个 All-in TiDB 的公司,这个早期的技术选型极大的解放了业务开发的生产力,让业务能够更放开手脚去写业务代码,而不是陷入无休止的选择 Sharding key,做读写分离等等和数据库较劲的事情。\n\n为业务开发提供更加灵活便捷和低成本的智能基础存储服务,是我们做 TiDB 的出发点和落脚点,分布式/高可用/方便灵活的编程接口/智能省心,这些大的方向上也符合未来主流的技术发展趋势。对于CEO 、 CTO 和架构师这类的管理者而言,在解决眼前问题的同时,跟随大的技术方向,不给未来多变的业务埋坑,公司尽可能快速发展,这个才是核心要去思考的问题。\n\n## 十、如何根据自己的实际情况参考业内的使用案例\n\nTiDB 是一个通用的数据库,甚至希望比一般的数据库更加通用,TiDB 是很早就尝试融合 OLTP 和 OLAP 的边界的数据库产品,我们是最早将 HTAP 这个概念从实验室和论文里带到现实的产品之一。这类通用基础软件面临的一个问题就是我们在早期其实很难去指导垂直行业的用户把 TiDB 用好,毕竟各自领域都有各自的使用场景和特点,TiDB 的开发团队的背景大部分是互联网行业,所以天然的会对互联网领域的架构和场景更熟悉,但是比如在金融,游戏,电商,传统制造业这些行业里其实我们不是专家,不过现在都已经有很多的行业专家和开发者已经能将 TiDB 在各自领域用得很好。\n\n**我们的 Blog,公众号,官网等平台会作为一个案例分享的中心,欢迎各位正在使用 TiDB 的用户,将你们的思考和使用经验分享给我们,就像现在已有案例背后的许多公司一样,我们会将你们的经验变成一篇篇的用户案例,通过我们的平台分享给其他的正在选型的公司。**","date":"2018-06-19","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"10-questions-tidb-structure","file":null,"relatedBlogs":[]},{"id":"Blogs_59","title":"写在 TiDB 1.0 发布之际 | 预测未来最好的方式就是创造未来","tags":["GA","社区动态"],"category":{"name":"观点洞察"},"summary":"1.0 版本只是个开始,是新的起点,愿我们一路相扶,不负远途。","body":"如果只能用一个词来描述此刻的心情,我想说恍如隔世,这样说多少显得有几分矫情,或许内心还是想在能矫情的时候再矫情一次,毕竟当初做这一切的起因是为了梦想。还记得有人说预测未来最好的方式就是创造未来,以前看到这句话总觉得是废话,如今看到这一切在自己身上变成现实的一刻,感受是如此的真切,敲击键盘的手居然有点颤抖,是的,预测未来最好的方式就是创造未来。\n\n还记得刚开始做的时候,只有很少的几个人相信这个事情可以做,毕竟难度比较高,就像有些户外旅行,只有方向,没有路。从零开始到发布 1.0 版本,历时 2 年 6 个月,终于还是做出来了。这是开源精神的胜利,是真正属于工程师们的荣耀。这个过程我们一直和用户保持沟通和密切协作,从最早纯粹的为 OLTP 场景的设计,到后来迭代为 HTAP 的设计,一共经历了 7 次重构,许多看得见的汗水,看不见的心跳,也许这就是相信相信的力量,总有那么一群人顶着世俗的压力,用自己的信念和力量在改变世界。在这个过程中,质疑的声音变少了,越来越多的人从观望,到为我们鼓舞助威,帮助我们快速成长。特别感谢那些从 beta 版本开始一路相随的用户,没有你们的信任,耐心和参与,就没有今天的 PingCAP。\n\n开心的时刻总是特别想对很多帮助和支持我们的童鞋们说声谢谢,没有你们就没有 PingCAP,特别感谢每一位项目的贡献者。也许你已经知道了,我们专门为你们定制了一面[荣誉墙](http://gaday.pingcap.com/),那里的色彩记录了你们的每一次贡献,如果你仍在埋头工作,来不及知道,我想请你过去逛逛,不负好时光。\n\n这个世界还是有人相信未来是可以被创造的。感谢开源精神,让我们这样一个信仰创造未来的团队,可以站在未来的入口,因为相信和努力,获得源源不绝的正向的力量。面对未来,让我们可以摒弃对未知的恐惧和对不完美的妥协。\n\n也感谢那些曾经的诋毁和吐槽,让我们不敢懈怠,砥砺前行。\n\n然而 1.0 版本只是个开始,是新的起点,愿我们一路相扶,不负远途。","date":"2017-10-17","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"ga-1.0","file":null,"relatedBlogs":[]},{"id":"Blogs_239","title":"谈谈开源(一)","tags":["OpenSource"],"category":{"name":"观点洞察"},"summary":"很多人的『开源』是一个比较时髦且有情怀的词汇,不少公司也把开源当做 KPI 或者是技术宣传的手段。但是在我们看来,大多数人开源做的并不好,大多数开源项目也没有被很好的维护。比如前一段时间微博上流传关于 Tengine 的讨论,一个优秀的开源项目不止是公布源代码就 OK 了,还需要后续大量的精力去维护,包括制定 RoadMap、开发新功能、和社区交流、推动项目在社区中的使用、对使用者提供一定程度的支持,等等。","body":"> 源码面前,了无秘密\n> ---- 侯捷\n\n### 前言\n很多人的『开源』是一个比较时髦且有情怀的词汇,不少公司也把开源当做 KPI 或者是技术宣传的手段。但是在我们看来,大多数人开源做的并不好,大多数开源项目也没有被很好的维护。比如前一段时间微博上流传关于 Tengine 的讨论,一个优秀的开源项目不止是公布源代码就 OK 了,还需要后续大量的精力去维护,包括制定 RoadMap、开发新功能、和社区交流、推动项目在社区中的使用、对使用者提供一定程度的支持,等等。\n\n目前我们在国内没看到什么特别好的文章讲如何运营一个开源项目,或者是如何做一个顶级的开源项目。TiDB 这个项目从创建到现在已经有两年多,从开发之初我们就坚定地走开源路线,陆续开源了 TiDB、TiKV、PD 这三个核心组件,获得了广泛的关注,项目在 GitHub 的 Trending 上面也多次登上首页。在这两年中,我们在这方面积累了一些经验和教训,这里和大家交流一下我们做开源过程中的一些感受,以及参与开源项目(至少是指 TiDB 相关项目)的正确姿势。\n\n### 什么是开源\n\n> Open-source software (OSS) is computer software with its source code made available with a license in which\n> the copyright holder provides the rights to study, change, and distribute the software to anyone and for any\n> purpose.\n>\n> ---- From [Wikipedia](https://en.wikipedia.org/wiki/Open-source_software)\n\n本文讨论的开源是指开源软件,简而言之,开源就是拥有源代码版权的人,允许其他人在一定许可证所述范围内,访问源代码,并用于一些自己的目的。\n最基本的要求就是其他人可以访问源代码,另外获取代码后能做什么,就需要一个专门的许可证来规范(可以是自己写的,也可以用一个别人写好的)。里面一般会规定诸如对修改代码、新增代码、后续工作是否需要开源以及专利相关的事项。\nOK,我们写一个 `main.py` 里面有一行 `print \"Hello World!\"`,再和某个许可证文件一起扔到 GitHub 上,我们就有一个满足最低要求的开源项目了。\n\n### 为什么要开源\n很多人觉得代码是一个软件公司最宝贵的资产,把这些最宝贵的资产让别人免费获取,对你们有什么好处?如果对手拿走了你们的代码,另起炉灶和你们竞争怎么办?或者是用户直接获取源代码,用于自己的环境中,那你们如何收钱呢?\n对一个技术型公司来说,最宝贵的资产其实是人,对一个开源项目来说,最核心的资产是一个活跃的开源社区以及他人对这个项目的认可。\n我们从这两方面来看一下开源在这两方面的影响。\n\n* Branding\n很明显,开源是一种非常好的 PR、Branding 的手段,大多数大公司做开源也是这个目的,可以以一种成本几乎为零的方式宣传企业名,树立技术型企业形象。一个知名且良好的企业形象,对于各个方面都很有好处。比如国外有一个知名的技术媒体叫 HackNews,我司的产品曾经多次登上其首页,获得了大量的关注。其实那几次都不是我们自己发的帖子,而是其他人关注到我们的产品,自行做的传播。\n\n* 人才获取\n人才招聘最大的难处就是如何鉴别这个人的能力,他是否能干活、是否是靠刷题通过了面试。如何能和这个人工作一段时间,看到他是如何完成日常工作,那么对于这个人的能力了解会更进一步。为了实现这个目的,传统的手段是 Some How 找到和这个人共事过的人,听取他的意见。这样做首先要看运气,有的时候要转几层关系才能找到这样的人,并且不一定得到的是正确、真实的答案。\n但是如果这个人已经给你的项目贡献了一些代码,并且代码质量比较高、贡献过程中和你的沟通很顺畅,那么一方面说明这个人软硬实例都不错,另一方面说明这个人对你做的事情很有兴趣。TiDB 有大量的正式、实习员工都是从 Contributor 中转化来的,以至于我们担心别把所有的人都招进来,社区没了 :) 。\n\n* 社区贡献\n可以这么说,如果没有开源社区,整个互联网都不会是现在这样。想象一下如果没有 Linux、MySQL、GCC、Hadoop、Lucence 这些东西,那么整个互联网的基础技术栈将不复存在(当然,肯定会出现另外一套东西,但是可能不会像开源的这套这么完善)。无数的开源社区贡献者贡献自己的力量,共同维持这样一个互助互利的社区,支撑社会技术进步。\n我们也从开源社区中获得了很多支持,包括大家报的问题、提的建议以及来自全球一百四十多名贡献者提交的代码。随着项目的发展,我相信社区贡献代码的比例会持续提升。\n\n* 提升项目质量\n当一个项目以开源方式运营时,代码质量是项目的脸面,大家无论是在提交代码的时候,还是在 Comment 别人的 PR 的时候,都会非常谨慎,因为你的一举一动全世界都能看到,毕竟谁也不想人前露怯是吧。\n\n* 对基础软件的意义\n对于一个数据库这样的基础软件,最重要的就是正确性、稳定性和性能。前两点尤其重要,要保证这两点,一方面需要在开发和测试过程中尽可能提高质量,另一方面广泛的使用也非常重要。只有当你的产品有足够多的人试用,甚至用于生产环境,才可能有足够多的问题反馈以及产品建议。开发人员能做的测试毕竟是有限的,很多场景、环境或者是业务负载是我们想象不到的。来自实际用户的问题反馈有助于我们提升产品质量,来自用户的建议有利于我们提升产品易用性。只有长期在生产环境中运行过的基础软件的,才算是合格的基础软件的。\n\n所以我们认为开源是基础软件的大趋势,无论是 Hadoop、MySQL、Spark 这样的知名产品,或者是 Linux 基金会、Apache 基金会、CNCF 基金会这样的巨头,都证明了这个观点。国内目前大公司比较热门的开源项目,也都集中在基础软件领域,比如百度的 Brpc、Palo、Tera,以及腾讯的 PaxosStore。\n\n### PingCAP 开源了哪些项目\n这里简单讲一下我们开源的几个 Repo 都是做什么:\n\n* [TiDB](https://github.com/pingcap/tidb):数据库的 SQL 层\n* [TiKV](https://github.com/pingcap/tikv):数据库的分布式存储引擎\n* [PD](https://github.com/pingcap/pd):集群的管理节点\n* [Docs](https://github.com/pingcap/docs):项目的英文文档\n* [Docs-cn](https://github.com/pingcap/docs-cn):项目的中文文档\n\n大家可以在 GitHub 上浏览我们的代码,看到我们完整的开发过程。\n\n### 开源模式下的开发流程\nPingCAP 攻城狮小申典型的一天:\n\n8:00 起床,先登录 Slack 看一下昨晚定时跑的测试任务是否结果正常,然后关注一下 Slack 上各种 Channel 以及微信群、邮箱是否有什么重要的消息\n\n9:00 洗漱完+吃完早饭,逗一会可爱的女儿(也可能是被女儿逗),然后去上班\n\n9:30 到达公司,开始干活。\n\n\t* 打开电脑看看 GitHub 上面有什么新的 Issue\n\t* 看看自己的 PR 有没有被别人 Comment,如果有 Comment 的话,尽快解决;如果还没人看的话,at 一下相关的同学,求 Review\n\t* 看看有没有别人的 PR 需要自己 Review,特别是 at 自己的那些 PR\n\t* 带上耳机开始写点代码\n\t* Slack 有人 at 我,赶紧回复一下\n\t* Slack 上我关注的 Channel 中有人在讨论问题,我很感兴趣,加入进去讨论一会\n\t* 同事要做一个新的 Feature,写了设计文档,我点进去看了一遍提了几个 Comment\n\n12:00 肚子可耻的饿了,呼朋唤友去吃饭,路上顺便讨论讨论技术以及八卦\n\n13:00 吃饭归来,看看邮件、Slack、微信留言,处理一下紧急的事情\n\n13:30 小睡一会\n\n14:00 小睡结束,接一杯咖啡,开始下午的工作,键盘敲起来。。。。。\n\n15:30 参与同事的设计评审会议,通过视频会议系统和远程的同事一起讨论设计方案,拍板后开干\n\n16:30 休息一下,然后继续敲代码、Review PR\n\n18:00 大部分同事已经去吃饭了,我准备开车回家吃饭去\n\n20:30 吃完饭,收拾完,没什么事情,打开电脑看一会邮件、Issue、PR\n\n22:30 休息一会,准备洗澡睡觉\n\n### 如何做一个开源项目\n首先你需要根据自己的诉求、商业模式等选择一个开源协议,常见的有 GPL 、BSD、Apache 和 Mit ,这些开源协议的区别在阮一峰老师的 [如何选择开源许可证?](http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html) 这篇博客中解释的很清楚了,推荐大家阅读。\n\n协议选定之后,再选择一个代码托管平台,目前的标准选择是 GitHub,注册一个 GitHub 账号,申请一个 Orgnization 之后,就可以开始用了,如果不需要私有 Repo 的话,那么不需要交任何费用。\n\n开始代码开发,提交第一次 Commit,完成 Readme 的撰写(一个好的 Readme 真的很重要)。\n\n后续的开发都需要通过 Pull Request 进行,最好不要直接 Push Master。一个严肃的项目需要把 Master 加入 Protected Branch,禁止直接 Push。\n\n为了保证后续的代码提交都是 Work 的,最好在 GitHub 中集成至少一个 CI 服务,常用的有 TravisCI、CircleCI (最近一段时间 CircelCI 似乎总是出问题)。然后在 PR 的设置页面上要求 PR 通过了 CI 才能合并。\n\n如果有人试用项目时发现一些问题,会通过 Issue 反馈,所以需要关注 Issue ,尽快给予回复。另外将 Issue 通过 Label 分门别类是一个好的实践,便于大家快速搜索、分类 Issue。比如我们会将一部分简单些的 Issue 标记为 Help Wanted,如果有新加入社区的同学想要开始贡献代码,那么这些 Issue 就是不错的起点。\n\n当参与的人越来越多,那么会有一部分人开始贡献代码,Maintainer 需要 Review 其他人的 PR,保证能项目自身的代码质量要求、编码风格一致。\n\n最后一点,一个好的项目需要配备完善的文档,帮助大家使用项目。包括架构、简要介绍、详细介绍、FAQ、使用范例、接口文档、安装部署以及最佳实践等等。这点也是大多数项目所忽略的。\n\n### 如何参与开源项目\n\n#### 试用\n最简单的参与方式是试用开源项目,这也是开源最大的一个好处,所有人都可以随时试用,相当于有很多人帮助项目作者做测试。毕竟如果只有作者自己做测试,遇到的环境、场景、应用方式会比较单一,总有一些你想像不到的地方会出问题。所以每一个测试出来的问题都很宝贵,我们都会尽可能快的评估和回复。\n\n#### 报 Issue\n试用过程中大家可能会遇到各种问题,特别是文档中没有提及的问题,反馈问题的最佳方式是在 GitHub 上新建 Issue,这样所有的人都可以看到,而且通过 Issue 来反馈我们也会更重视一些,有人会定期扫一遍未处理的 Issue。当然,建立 Issue 之前先搜索是否和已有的 Issue 重复是个好习惯。\n\n在 Issue 中尽可能详细的描述清楚遇到的问题,以及一个可操作的复现步骤,包括所用 Binary 的版本、部署方式、客户端以及服务的日志、操作系统的日志(如 dmesg 的输出)。如果不能复现,也尽可能详细地提供 Log。这些对开发人员追踪 Bug 会非常有用。\n\n#### 提出建议\n如果对项目有什么建议,也可以通过新建 Issue 来反馈, 我们一般会给出是否会支持,如果要支持的话,大概会在什么时候支持。\n\n#### 提 PR\n当你使用 TiDB 遇到问题或者需要新的 Feature,而觉得自己有能力 Fix 或者是当前官方还没有精力 Fix 时,可以尝试自己修改代码,解决问题。\n\n目前 TiDB 项目的 Contributor 有 140 多个,分散在全球十几个国家。其中不乏深度参与的用户。\n\n如果是小的功能或者是简单的 Bug Fix,可以在相关的 Issue 下面吼一声,让大家知道你在做这个事情即可,这样不会有人做重复的工作。如果做的过程中遇到了什么问题,也可以在相关的 Issue 中和 Maintainer 讨论。\n\n如果要做的是比较大的功能,那么最好先和官方做一轮讨论,然后写一个尽可能详细的 Design,讨论 OK 后,开始开发。\n\n### 讲一点好玩的事情\n在开源项目中总能或多或少的发现奇葩的 [Issue](https://github.com/pingcap/tidb/issues/194),比如 [这个](https://github.com/pingcap/tidb/issues/194):\n\n\n\n\n\n看到这个 Issue 真的是震惊了。","date":"2017-09-25","author":"申砾","fillInMethod":"writeDirectly","customUrl":"talk-about-opensource","file":null,"relatedBlogs":[]},{"id":"Blogs_267","title":"来自 PingCAP CEO 的信:说在 B 轮融资完成之际","tags":["PingCAP"],"category":{"name":"观点洞察"},"summary":"平时技术说得多,今天说点走心的。","body":"平时技术说得多,今天说点走心的。\n\n从决定出来创业到现在,刚好两年多一点,如果把 PingCAP 比喻成一个孩子的话, 刚是过了蹒跚学步的时期,前方有更大更美好的世界等我们去探索。这两年时间,在一片质疑声之中 ,TiDB 还算顽强的从无到有成长了起来。其实这一切的初心也很简单,最开始只不过是几个不愿妥协的分布式系统工程师对心目中'完美'的数据库的探索。很欣喜的看到 TiDB 的日渐成熟,周边工具和社区渐渐壮大,我感到由衷的自豪,在这个过程中,也一次又一次的挑战着技术和各自能力的边界,很庆幸能和自己的产品一起成长。\n\n坚持做正确的事,哪怕这看起来是一条更困难的路。TiDB 从诞生的第一天起便决定开源,虽然更多的是商业上的考量,不过里面也有一点点读书人兼济天下的情怀和对传统 Hacker 精神的贯彻。在我们之前,很多人认为分布式 OLTP 和 OLAP 融合几乎是不可能的事情,也有无数的人,其中不乏亲朋好友,劝我们说在国内做这个事情几乎难于登天,而且没有成功的先例。不过我们还是相信一个朴素道理,有价值的技术一定会有它的舞台,另外,任何事情如果没有尝试就打退堂鼓也不是我们的风格。如果没有成功的先例,那就一起来创造先例,做开创者是我们每个人的梦想。说实话,从技术上来说,这个领域是一个非常前沿的领域,大多数时候我们面前是无人区,也很幸运,目前看来技术上和预想的没有出现大的偏差,整个产品和团队也在稳步的前进。\n\n整个团队也从一开始的 3 个人,到今天 63 个志同道合的伙伴结伴前行,又一次很幸运,能凑齐这么一个具有很强战斗力和国际视野的团队,挑战计算机领域最困难和最前沿的课题之一,前方还有无数个迷人的问题等待着被解决,有时候也只能摸索着前进,不过这正是这个事情有意思的地方。谢谢你们,和你们一同工作,是我的荣幸。\n\n到今天,我们很自豪的宣布,已经有数十家客户将 TiDB 使用在各自的生产环境中解决问题,感谢我们早期的铁杆用户和可爱的社区开发者,是你们让 TiDB 一点点的变得更加稳定成熟,随着社区的不断变大,TiDB 正以惊人的速度正向迭代,这就是开源的力量。\n\n最后,PingCAP 也刚顺利的完成了 1500 万美金的 B 轮融资,感谢这轮的领投方华创资本,以及跟投方经纬中国,云启资本,峰瑞资本,险峰华兴。我们的征途是星辰大海,感谢有你们的一路支持。\n\n刘奇、黄东旭、崔秋\n\nPingCAP\n\n2017-6-13","date":"2017-06-13","author":"刘奇 黄东旭 崔秋","fillInMethod":"writeDirectly","customUrl":"series-B-funding","file":null,"relatedBlogs":[]},{"id":"Blogs_6","title":"演讲实录|黄东旭:Cloud-Native 的分布式数据库架构与实践","tags":["TiDB","k8s"],"category":{"name":"观点洞察"},"summary":"4 月 19 日,我司 CTO 黄东旭同学在全球云计算开源大会上,发表了《Cloud-Native 的分布式数据库架构与实践》主题演讲,以下为演讲实录。","body":"4 月 19 日,我司 CTO 黄东旭同学在全球云计算开源大会上,发表了《Cloud-Native 的分布式数据库架构与实践》主题演讲,以下为演讲实录。\n\n## 实录\n\n\n\nPingCAP 的联合创始人兼 CTO 黄东旭
\n\n大家好,今天我的题目是 Cloud-Native 与分布式数据库的实践。先简单的介绍一下自己,我是 PingCAP 的联合创始人和 CTO,过去一直在做基础软件领域的工程师,基本上做的所有的东西都是开源。在分享之前我想说一下为什么现在各行各业或者整个技术软件社区一直在重复的再造数据库,现在数据库到底怎么了,为什么这么百花齐放?\n\n\n+ 首先随着业务的多种多样,还有不管是传统行业还是互联网行业,业务的迭代速度越来越互联网化,使得整个数据量其实是一直在往上走的;\n\n\n+ 第二就是随着 IOT 的设备还有包括像手机、移动互联网蓬勃的发展,终端其实也不再仅仅是传统的 PC 客户端的数据的接入;\n\n\n+ 第三方面随着现在 AI 或者大数据分析一些模型或者理论上的突破,使得在大数据上进行计算的手段越来越多样,还有在物理上一些硬件的新的带有保护的内存,各种各样新的物理的设备,越来越多的硬件或者物理上的存储成本持续的降低,使得我们的数据库需要要面对更多的挑战。\n\n\n关联数据库理论是上世纪七十年代做出来的东西,现在四十年过去不管是物理的环境还是计算模型都是完全不一样的阶段,还抱着过去这种观念可能并不是一个面向未来的设计。而且今天我的题目是 Cloud-Native,有一个比较大胆的假设,大家在过去三十年的计算平台基本都是在一台 PC 或者一个服务器或者一个手机这样的独立的计算平台,但是未来我觉得一切的服务都应该是分布式的。因为我觉得摩尔定律已经失效了,所以未来的操作系统会是一个大规模分布式的操作系统,在上面跑的任何的进程,任何的服务都应该是分布式的,在这个假设下怎么去做设计,云其实是这个假设最好的载体。怎么在这个假设上去设计面向云的技术软件,其实是最近我一直在思考的一个问题。其实在这个时代包括面向云的软件,对业务开发来说尽量还是不要太多的改变过去的开发习惯。你看最近大数据的发展趋势,从最传统的关系数据库到过去十年相比,整个改变了用户的编程模型,但是改变到底是好的还是不好的,我个人觉得其实并不是太好。最近这两年大家会看到整个学术圈各种各样的论文都在回归,包括 DB 新时代的软件都会把扩展性和分布式放在第一个要素。\n\n\n大家可能听到主题会有点蒙,叫 Cloud-Native,Cloud-Native 是什么?其实很早的过去也不是没有人做过这种分布式系统的尝试,最早是 IBM 提出面向服务的软件架构设计,最近热门的 SOA、Micro Service 把自己的服务拆分成小的服务,到现在谷歌一直对外输出一个观点就是 Cloud-Native,就是未来大家的业务看上去的分布式会变成一个更加透明的概念,就是你怎么让分布式的复杂性消失在云的基础设施后,这是 Cloud-Native 更加关心的事情。\n\n\n\nCNCF 基金会
\n\n这个图是 CNCF 的一个基金会,也是谷歌支持的基金会上扒过来的图。这里面有一个简单的定义,就是 SCALE 作为一等公民,面向 Cloud-Native 的业务必须是弹性伸缩的,不仅能伸也得能缩;第二就是在对于这种 Cloud-Native 业务来说是面向 Micro service 友好;第三就是部署更加的去人工化。\n\n\n最近大家可能也看到很多各种各样容器化的方案,背后代表的意义是什么?就是整个运维和部署脱离人工,大家可以想象过去十几二十年来,一直以来运维的手段是什么样的。我找了一个运维,去买服务器,买服务器装系统,在上面部署业务。但是现在 Cloud-Native 出现变得非常的自动化,就相当于把人的功能变得更低,这是很有意义的,因为理想中的世界或者未来的世界应该怎么样,一个业务可能会有成百上千的物理节点,如果是人工的去做运维和部署是根本不可能做得到的,所以其实构建整个 Cloud-Native 的基础设施的两个条件:第一个就是存储本身的云化;第二就是运维要和部署的方式必须是云化的。\n\n**我就从这两个点说一下我们 TiDB 在上面的一些工作和一些我的思考。**\n\n\n存储本身的云化有几个基本条件,大家过去认为是高可用,主要停留在双活。其实仔细去思考的话,主备的方案是很难保证数据在完全不需要人工的介入情况下数据的一致性可用性的,所以大家会发现最近这几年出来的分布式存储系统的可用性的协议跟复制协议基本都会用类似 Raft/Paxos 基于选取的一致性算法,不会像过去做这种老的复制的方案。\n\n第二就是整个分片的策略,作为分布式系统数据一定是会分片的,数据分片是来做分布式存储唯一的思路,自动分片一定会取代传统的人工分片来去支撑业务。比如传统分片,当你的数据量越来越大,你只能做分库分表或者用中间件,不管你分库分表还是中间件都必须制订自己人工的分辨规则,但是其实在一个真正面向 Cloud 的数据库设计里,任何一种人的介入的东西都是不对的。\n\n第三,接入层的去状态化,因为你需要面对 Cloud-Native 做设计,你的接入层就不能带有状态,你可以相当于是前端的接入层是一层无状态的或者连接到任何一个服务的接入的入口,对你来说应该都是一样的,就是说你不能整个系统因为一个关键组件的损坏或者说磁盘坏掉或者机器的宕机,整个系统就不能服务了,整个测试系统应该具有自我愈合和自我维护的能力。\n其实我本身是架构师,所以整个我们数据库的设计都是围绕这些点来做思考的,就是一个数据库怎么能让他自我的生长,自我的维护,哪怕出现任何的灾难性的物理故障(有物理故障是非常正常的,每天在一个比较大的集群的规模下,网络中断、磁盘损坏甚至是很多很诡异的问题都是很正常的),所以怎么设计这种数据库。\n\n我们的项目是 TiDB,我不知道在座的有没有听说过这个项目,它其实是一个开源实现。当你的业务已经用了数据库,数据量一大就有可能遇到一些问题,一个是单点的可靠性的问题,还有一个数据容量怎么去弹性伸缩的问题。TiDB 就能解决这个问题,它本身对外暴露了一个接口,你可以用客户端去连接,你可以认为你下面面对的是一个弹性动态伸缩完全没有容量限制,同时还可以在上面支持复杂的子查询的东西。底层存储的话,相当于这一层无状态的会把这个请求发到底层的节点上,这个存储里面的数据都是通过协议做高可用和复制的,这个数据在底层会不停的分裂和移动,你可以认为这个数据库是一个活的数据库,你任何一个节点的宕机都不会影响整个数据库对业务层的使用,包括你可以跨数据中心部署,甚至你在跨数据中心的时候,整个数据中心网络被切断,机房着火,业务层都几乎完全是透明的,而且这个数据比如副本丢失会自己去修复,自己去管理或者移动数据。\n\n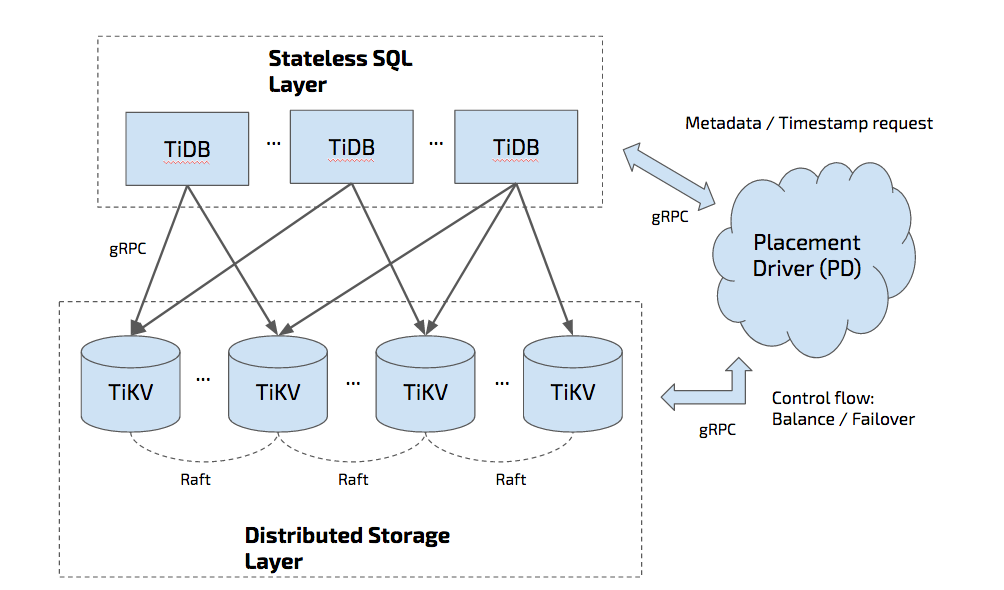\n\n集群
\n\n上图右边是一个集群的调度模块,你可以认为它是整个集群的大脑,是一个 7×24 小时不眠的 DBA,你任何的业务可以接上来。NewSQL 这个词大家听的都烂了,但是我还是想提,首先它是一个面向扩展的数据库,同时它还结合的传统管理数据库的强一致事务,必须得是 SSI 隔离级别的,并不是非常弱根本没法用的隔离级别,而是需要提供最强一致性的隔离级别的数据库。扩展性其实是通过在 TiKV 层面做完全自动分片,可用性是通过 Raft 为保证,我们整个数据库没有主从的概念,每一个节点既可以是主又可以是从,然后整个数据复制通过 Raft 为保证,对外的是一个强一致性的事务层,其实背后的算法是用两阶段提交的算法,比如一个最简单的例子,我一百个并发过来很快,每个平均十毫秒访问数据,一百个并发,一百万个并发,你还能保证每一个请求都是十毫秒返回数据吗?那我可以简单的通过添加机器把系统的吞吐加上去,每一个吞吐的响应延迟会更大一些,在论文里提到过,谷歌数据库写的每一个平均延迟是 150 到 100 毫秒,可以做到线性扩展。所以终于有一个数据库可以 scable。刚才说的是存储层面的云化,刚才提到了 Cloud-Native 还有一个重要的点就是部署和运维方式的云化,我们其实选的这个 Kubernetes 就是用来承载背后数据库大规模集群上的部署,其实大家都知道这个是什么东西,这是最出名的开源项目之一,谷歌开源的,大家也知道 borg,就是他们用了这么多年的集群调度服务,主要做的事情就是服务的编排、部署、自动化的运维,一台物理机挂掉了,他会很好的让这个业务不中断,像集群调度器,它就是整个数据中心的操作系统,但是面临最大的问题就是所有的业务一旦是有状态的,那你这个就非常恶心。举个案例,比如我在跑一个数据库,如果你这台物理机宕机,按照 Kubernetes 会开一个服务器在那边展开,但是这一台老的宕机服务器数据是存在上面的,你不能只是把进程在新的服务器那启起来而数据不带过去,相当于这种业务是带状态的,这在 Kubernetes 过去是一个老大难的问题,其实整个应用层,因为它的特性被分成了四个大的阵营,如果想上可以看一下自己的业务到底属于哪一个阵营。\n\n第一个就是完全无状态的业务,比如这是一个简单的 CRUD 业务层的逻辑,其实是无状态的应用层。第二种就是单点的带状态的 applications,还有任何单机的数据库其实都有属于 applications。第三个就是 Static distributed,比如高可用的分布式服务,大家也不会做扩容什么的,这种是静态的分布式应用。还有最难的一个问题,就是这种集群型的 applications,clustered 是没有办法很好的调度服务的。这是刚才说的,其实对于 Single point,其实是很好解决的,对于静态的其实也是用 Static distributed 来解决带状态的持续化的方案。\n\n刚才我说最难的那个问题,我们整个架构中引入了 Operational,调度一套有状态服务的方案,其实它思路也很简单,就是把运维分布人员系统的领域知识给嵌入到了系统中,Knowledge 发布调度任务之前都会相当于被 CoreOS 提供的接口以后再调度业务,这套方案依赖了 HtirdPartyResources 调度,因为这个里面我的状态我自己才知道,这个时候你需要通过把你的系统领域知识放到 operator 里。很简单,就是 Create 用 TiDB Operator 来实现,还有 Rollingupdate 和 Scale Out 还有 Failover 等。使用 Kubemetes 很重要的原因就是它只用到了很毛的一层 API,内部大量的逻辑是在 Operator 内部,而且像 PV/Statefulset 中并不是一个很好的方案,比如 PV 实现你可以用分布式文件系统或者快存储作为你持久化的这一层,但是数据库的业务,我对我底层的 IO 或者硬件有很强的掌控力的,我在我的业务层自己做了三副本和高可用,我其实就不需要在存储层面上比如我在一个裸盘上跑的性能能比其他上快十倍,这个时候你告诉我不好意思下面只支持 statefulset 那这是不适合跑数据库的,也就是数据库集群是跟它的普通的云盘或者云存储的业务是分开的。\n\n分布式数据库也不是百分之百所有的业务场景都适合,特别是大规模的分布式数据库来说,比如自增 ID,虽然我们支持,但是自增 IT 高压力写入的时候它的压力会集中在表的末尾,其实是我不管怎么调度总会有一块热点,当然你可以先分表,最后我们聚合分析也没有问题,像秒杀或者特别小的表,其实是完全不适合在这种分布式数据库上做的,比较好的一些实践业务的读写比较平均,数据量比较大,同时还有并发的事务的支持,需要有事务的支持,但并不是冲突特别大的场景,并不是秒杀的场景,同时你又可以需要在上面做比较复杂的分析,比如现在我们的一些线上的用户特别好玩,过去它的业务全都是跑在 MySQL 上,一主多从,他发现我一个个 MySQL 成为了信息的孤岛,他并没有办法做聚合地分析,过去传统的方案就是我把 MySQL 或者数据通过一个 ETL 流程导到数据仓库里,但是开发者不会用各种琳琅满目大数据的东西,他只会用 MySQL,一般他做的数据分析都会把 MySQL 倒腾到一个库上再做分析,数据量一大堆分析不出来,这个时候他把所有他自己的 MySQL 总库连到了一个 TiDB上,过去是一主多从,先多主多从,把所有的从都打通,做 MySQL 的分析,所以我觉得 TiDB 打造了新的模型,可以读写高并发的事务,所以未来的数据库会是一个什么样子的,我觉得可能是至少我们觉得沿着这条路走下去应该会有一条新的路,谢谢大家。","date":"2017-04-22","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"talk-cloud-native","file":null,"relatedBlogs":[]},{"id":"Blogs_165","title":"Spanner - CAP, TrueTime and Transaction","tags":["Cloud","Spanner","CAP"],"category":{"name":"观点洞察"},"summary":"最近大家非常关注的一件事情就是 Google Spanner Cloud 的发布,这应该算是 NewSQL 又一个里程碑的事件。在本篇文章中,唐刘同学与大家分享了他自己对 Spanner 的理解,Spanner 的一些关键技术的实现以及与 TiDB 的相关对比。","body":"最近非常关注的一件事情就是 Google Spanner Cloud 的发布,这应该算是 NewSQL 又一个里程碑的事件。NewSQL 的概念应该就是在 12 年 Google Spanner 以及 F1 的论文发表之后,才开始慢慢流行,然后就开始有企业尝试根据 paper 做自己的 NewSQL,譬如国外的 CockroachDB 以及国内我们 PingCAP。\n\nSpanner 的论文在很早就发布了,国内也有很多中文翻译,这里笔者只是想聊聊自己对 Spanner 的理解,以及 Spanner 的一些关键技术的实现,以及跟我们自己的 TiDB 的相关对比。\n\n## CAP\n\n在分布式领域,CAP 是一个完全绕不开的东西,大家应该早就非常熟悉,这里笔者只是简单的再次说明一下:\n\n+ C:一致性,也就是通常说的线性一致性,假设在 T 时刻写入了一个值,那么在 T 之后的读取一定要能读到这个最新的值。\n+ A:完全 100% 的可用性,也就是无论系统发生任何故障,都仍然能对外提供服务。\n+ P:网络分区容忍性。\n\n在分布式环境下面,P 是铁定存在的,也就是只要我们有多台机器,那么网络隔离分区就一定不可避免,所以在设计系统的时候我们就要选择到底是设计的是 AP 系统还是 CP 系统,但实际上,我们只要深入理解下 CAP,就会发现其实有时候系统设计上面没必要这么纠结,主要表现在:\n\n1. 网络分区出现的概率很低,所以我们没必要去刻意去忽略 C 或者 A。多数时候,应该是一个 CA 系统。\n2. CAP 里面的 A 是 100% 的可用性,但实际上,我们只需要提供 high availability,也就是仅仅需要满足 99.99% 或者 99.999% 等几个 9 就可以了。\n\nSpanner 是一个 CP + HA 系统,官方文档说的可用性是优于 5 个 9 ,稍微小于 6 个 9,也就是说,Spanner 在系统出现了大的故障的情况下面,大概 31s+ 的时间就能够恢复对外提供服务,这个时间是非常短暂的,远远比很多外部的系统更加稳定。然后鉴于 Google 强大的自建网络,P 很少发生,所以 Spanner 可以算是一个 CA 系统。\n\nTiDB 在设计的时候也是一个 CP + HA 系统,多数时候也是一个 CA 系统。如果出现了 P,也就是刚好对外服务的 leader 被隔离了,新 leader 大概需要 10s+ 以上的时间才能选举出来对外提供服务。当然,我们现在还不敢说系统的可用性在 6 个 9 了,6 个 9 现在还是我们正在努力的目标。\n\n当然,无论是 Spanner 还是 TiDB,当整个集群真的出现了灾难性的事故,导致大多数节点都出现了问题,整个系统当然不可能服务了,当然这个概率是非常小的,我们可以通过增加更多的副本数来降低这个概率发生。据传在一些关键数据上面,Spanner 都有 7 个副本。\n\n## TrueTime\n\n最开始看到 Spanner 论文的时候,我是直接被 TrueTime 给惊艳到了,这特么的完全就是解决分布式系统时间问题的一个核弹呀(银弹我可不敢说)。\n\n在分布式系统里面,时间到底有多么重要呢?之前笔者也写过一篇文章来聊过[分布式系统的时间](http://www.jianshu.com/p/8500882ab38c)问题,简单来说,我们需要有一套机制来保证相关事务之间的先后顺序,如果事务 T1 在事务 T2 开始之前已经提交,那么 T2 一定能看到 T1 提交的数据。\n\n也就是事务需要有一个递增序列号,后开始的事务一定比前面开始的事务序列号要大。那么这跟时间又有啥关系呢,用一个全局序列号生成器不就行呢,为啥还要这么麻烦的搞一个 TrueTime 出来?笔者觉得有几个原因:\n\n1. 全局序列号生成器是一个典型的单点,即使会做一些 failover 的处理,但它仍然是整个系统的一个瓶颈。同时也避免不了网络开销。但全局序列号的实现非常简单,Google 之前的 Percolator 以及现在 TiDB 都是采用这种方式。\n2. 为什么要用时间?判断两个事件的先后顺序,时间是一个非常直观的度量方式,另外,如果用时间跟事件关联,那么我们就能知道某一个时间点整个系统的 snapshot。在 TiDB 的用户里面,一个非常典型的用法就是在游戏里面确认用户是否谎报因为回档丢失了数据,假设用户说在某个时间点得到某个装备,但后来又没有了,我们就可以直接在那个特定的时间点查询这个用户的数据,从而知道是否真的有问题。\n3. 我们不光可以用时间来确定以前的 snapshot,同样也可以用时间来约定集群会在未来达到某个状态。这个典型的应用就是 schema change。虽然笔者不清楚 Spanner schema change 的实现,但 Google F1 有一篇 [Online, Asynchronous Schema Change in F1](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41376.pdf) 论文提到了相关的方法,而 TiDB 也是采用的这种实现方式。简单来说,对于一个 schema change,通常都会分几个阶段来完成,如果集群某个节点在未来一个约定的时间没达到这个状态,这个节点就需要自杀下线,防止因为数据不一致损坏数据。\n\n使用 TrueTime,Spanner 可以非常方便的实现笔者提到的用法,但 TrueTime 也并不是万能的:\n\n+ TrueTime 需要依赖 atomic clock 和 GPS,这属于硬件方案,而 Google 并没有论文说明如何构造 TrueTime,对于其他用户的实际并没有太多参考意义。\n+ TrueTime 也会有误差范围,虽然非常的小,在毫秒级别以下,所以我们需要等待一个最大的误差时间,才能确保事务的相关顺序。\n\n## Transaction\n\nSpanner 默认将数据使用 range 的方式切分成不同的 splits,就跟 TiKV 里面 region 的概念比较类似。每一个 Split 都会有多个副本,分布在不同的 node 上面,各个副本之间使用 Paxos 协议保证数据的一致性。\n\nSpanner 对外提供了 read-only transaction 和 read-write transaction 两种事务,这里简单的介绍一下,主要参考 Spanner 的[白皮书](https://cloud.google.com/spanner/docs/whitepapers/LifeCloudSpannerReadWrite.pdf)。\n\n### Single Split Write\n\n假设 client 要插入一行数据 Row 1,这种情况我们知道,这一行数据铁定属于一个 split,spanner 在这里使用了一个优化的 1PC 算法,流程如下:\n\n1. API Layer 首先找到 Row 1 属于哪一个 split,譬如 Split 1。\n2. API Layer 将写入请求发送给 Split 1 的 leader。\n3. Leader 开始一个事务。\n4. Leader 首先尝试对于 Row 1 获取一个 write lock,如果这时候有另外的 read-write transaction 已经对于这行数据上了一个 read lock,那么就会等待直到能获取到 write lock。\n\t+ 这里需要注意的是,假设事务 1 先 lock a,然后 lock b,而事务 2 是先 lock b,在 lock a,这样就会出现 dead lock 的情况。这里 Spanner 采用的是 `wound-wait` 的解决方式,新的事务会等待老的事务的 lock,而老的事务可能会直接 abort 掉新的事务已经占用的 lock。\n5. 当 lock 被成功获取到之后,Leader 就使用 TrueTime 给当前事务绑定一个 timestamp。因为用 TrueTime,我们能够保证这个 timestamp 一定大于之前已经提交的事务 timestamp,也就是我们一定能够读取到之前已经更新的数据。\n6. Leader 将这次事务和对应的 timestamp 复制给 Split 1 其他的副本,当大多数副本成功的将这个相关 Log 保存之后,我们就可以认为该事务已经提交(注意,这里还并没有将这次改动 apply)。\n7. Leader 等待一段时间确保事务的 timestamp 有效(TrueTime 的误差限制),然后告诉 client 事务的结果。这个 `commit wait` 机制能够确保后面的 client 读请求一定能读到这次事务的改动。另外,因为 `commit wait` 在等待的时候,Leader 同时也在处理上面的步骤 6,等待副本的回应,这两个操作是并行的,所以 `commit wait` 开销很小。\n8. Leader 告诉 client 事务已经被提交,同时也可以顺便返回这次事务的 timestamp。\n9. 在 Leader 返回结果给 client 的时候,这次事务的改动也在并行的被 apply 到状态机里面。\n\t+ Leader 将事务的改动 apply 到状态机,并且释放 lock。\n\t\t- Leader 同时通知其他的副本也 apply 事务的改动。\n\t\t- 后续其他的事务需要等到这次事务的改动被 apply 之后,才能读取到数据。对于 read-write 事务,因为要拿 read lock,所以必须等到之前的 write lock 释放。而对于 read-only 事务,则需要比较 read-only 的 timestamp 是不是大于最后已经被成功 apply 的数据的 timestamp。\n\nTiDB 现在并没有使用 1PC 的方式,但不排除未来也针对单个 region 的 read-write 事务,提供 1PC 的支持。\n\n### Multi Split Write\n\n上面介绍了单个 Split 的 write 事务的实现流程,如果一个 read-write 事务要操作多个 Split 了,那么我们就只能使用 2PC 了。\n\n假设一个事务需要在 Split 1 读取数据 Row 1,同时将改动 Row 2,Row 3 分别写到 Split 2,Split 3,流程如下:\n\n1. client 开始一个 read-write 事务。\n2. client 需要读取 Row 1,告诉 API Layer 相关请求。\n3. API Layer 发现 Row 1 在 Split 1。\n4. API Layer 给 Split 1 的 Leader 发送一个 read request。\n5. Split1 的 Leader 尝试将 Row 1 获取一个 read lock。如果这行数据之前有 write lock,则会持续等待。如果之前已经有另一个事务上了一个 read lock,则不会等待。至于 deadlock,仍然采用上面的 `wound-wait` 处理方式。\n6. Leader 获取到 Row 1 的数据并且返回。\n7. . Clients 开始发起一个 commit request,包括 Row 2,Row 3 的改动。所有的跟这个事务关联的 Split 都变成参与者 participants。\n8. 一个 participant 成为协调者 coordinator,譬如这个 case 里面 Row 2 成为 coordinator。Coordinator 的作用是确保事务在所有 participants 上面要不提交成功,要不失败。这些都是在 participants 和 coordinator 各自的 Split Leader 上面完成的。\n9. Participants 开始获取 lock\n\t+ Split 2 对 Row 2 获取 write lock。\n\t+ Split 3 对 Row 3 获取 write lock。\n\t+ Split 1 确定仍然持有 Row 1 的 read lock。\n\t+ 每个 participant 的 Split Leader 将 lock 复制到其他 Split 副本,这样就能保证即使节点挂了,lock 也仍然能被持有。\n\t+ 如果所有的 participants 告诉 coordinator lock 已经被持有,那么就可以提交事务了。coordinator 会使用这个时候的时间点作为这次事务的提交时间点。\n\t+ 如果某一个 participant 告诉 lock 不能被获取,事务就被取消\n10. 如果所有 participants 和 coordinator 成功的获取了 lock,Coordinator 决定提交这次事务,并使用 TrueTime 获取一个 timestamp。这个 commit 决定,以及 Split 2 自己的 Row 2 的数据,都会复制到 Split 2 的大多数节点上面,复制成功之后,就可以认为这个事务已经被提交。\n11. Coordinator 将结果告诉其他的 participants,各个 participant 的 Leader 自己将改动复制到其他副本上面。\n12. 如果事务已经提交,coordinator 和所有的 participants 就 apply 实际的改动。\n13. Coordinator Leader 返回给 client 说事务已经提交成功,并且返回事务的 timestamp。当然为了保证数据的一致性,需要有 `commit-wait`。\n\n TiDB 也使用的是一个 2PC 方案,采用的是优化的类 Google Percolator 事务模型,没有中心的 coordinator,全部是靠 client 自己去协调调度的。另外,TiDB 也没有实现 `wound-wait`,而是对一个事务需要操作的 key 顺序排序,然后依次上 lock,来避免 deadlock。\n\n### Strong Read\n\n上面说了在一个或者多个 Split 上面 read-write 事务的处理流程,这里在说说 read-only 的事务处理,相比 read-write,read-only 要简单一点,这里以多个 Split 的 Strong read 为例。\n\n假设我们要在 Split 1,Split 2 和 Split 3 上面读取 Row 1,Row 2 和 Row 3。\n\n1. API Layer 发现 Row 1,Row 2,和 Row 3 在 Split1,Split 2 和 Split 3 上面。\n2. API Layer 通过 TrueTime 获取一个 read timestamp(如果我们能够接受 Stale Read 也可以直接选择一个以前的 timestamp 去读)。\n3. API Layer 将读的请求发给 Split 1,Split 2 和 Split 3 的一些副本上面,这里有几种情况:\n\t+ 多数情况下面,各个副本能通过内部状态和 TrueTime 知道自己有最新的数据,直接能提供 read。\n\t+ 如果一个副本不确定是否有最新的数据,就向 Leader 问一下最新提交的事务 timestamp 是啥,然后等到这个事务被 apply 了,就可以提供 read。\n\t+ 如果副本本来就是 Leader,因为 Leader 一定有最新的数据,所以直接提供 read。\n4. 各个副本的结果汇总然会返回给 client。\n\n当然,Spanner 对于 Read 还有一些优化,如果我们要进行 stale read,并且这个 stale 的时间在 10s 之前,那么就可以直接在任何副本上面读取,因为 Leader 会每隔 10s 将最新的 timestamp 更新到其他副本上面。\n\n现在 TiDB 只能支持从 Leader 读取数据,还没有支持 follower read,这个功能已经实现,但还有一些优化需要进行,现阶段并没有发布。\n\nTiDB 在 Leader 上面的读大部分走的是 lease read,也就是只要 Leader 能够确定自己仍然在 lease 有效范围里面,就可以直接读,如果不能确认,我们就会走 Raft 的 ReadIndex 机制,让 Leader 跟其他节点进行 heartbeat 交互,确认自己仍然是 Leader 之后再进行读操作。\n\n## 小结\n\n随着 Spanner Cloud 的发布,我们这边也会持续关注 Spanner Cloud 的进展,TiDB 的原始模型就是基于 Spanner + F1 搭建起来,随着 Spanner Cloud 更多资料的公布,TiDB 也能有更多的参考。\n\n另外,我们一直相信,我们走在正确的道路上面,如果你对我们的东西感兴趣,欢迎联系我。\n\n+ 邮箱:tl@pingcap.com\n+ 微信:siddontang","date":"2017-02-21","author":"唐刘","fillInMethod":"writeDirectly","customUrl":"Spanner-cap-truetime-transaction","file":null,"relatedBlogs":[]},{"id":"Blogs_88","title":"分布式系统测试那些事儿 - 信心的毁灭与重建","tags":["TiDB","分布式系统测试","测试工具"],"category":{"name":"观点洞察"},"summary":"本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为下篇。","body":"> 本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为下篇。\n\n##### -接中篇-\n\nScyllaDB 有一个开源的东西,是专门用来给文件系统做 Failure Injection 的, 名字叫做 CharybdeFS。如果你想测试你的系统,就是文件系统在哪不断出问题,比如说写磁盘失败了,驱动程序分配内存失败了,文件已经存在等等,它都可以测模拟出来。\n\n**CharybdeFS: A new fault-injecting file system for software testing**\n\nSimulate the following errors:\n\n- disk IO error (EIO)\n- driver out of memory error (ENOMEM)\n- file already exists (EEXIST)\n- disk quota exceeded (EDQUOT)\n\n再来看看 Cloudera,下图是整个 Cloudera 的一个 Failure Injection 的结构。\n\n\n\n一边是 Tools,一边是它的整个的 Level 划分。比如说整个 Cluster, Cluster 上面有很多 Host,Host 上面又跑了各种 Service,整个系统主要用于测试 HDFS, HDFS 也是很努力的在做有效的测试。然后每个机器上部署一个 AgenTEST,就用来注射那些可能出现的错误。\n\n看一下它们作用有多强大。\n\n**Cloudera: Simulate the following errors:**\n\n+ Packets loss/corrupt/reorder/duplicate/delay\n+ Bandwidth limit: Limit the network bandwidth for the specified address and port.\n+ DNSFail: Apply an injection to let the DNS fail.\n+ FLOOD: Starts a DoS attack on the specified port.\n+ BLOCK: Blocks all the packets directed to 10.0.0.0/8 (used internally by EC2).\n+ SIGSTOP: Pause a given process in its current state.\n+ BurnCPU/BurnIO/FillDISK/RONLY/FIllMEM/CorruptHDFS\n+ HANG: Hang a host running a fork bomb.\n+ PANIC: Force a kernel panic.\n+ Suicide: Shut down the machine.\n\n数据包是可以丢的,可以坏的,可以 reorder 的,比如说你发一个 A,再发一个 B,它可以给你 reorder,变成先发了 B 再发了 A,然后看你应用程序有没有正确的处理这种行为。接着发完一次后面再给你重发,然后可以延迟,这个就比较简单。目前这个里面的大部分,TiKV 都有实现,还有带宽的限制,就比如说把你带宽压缩成 1M。以前我们遇到一个问题很有意思,发现有人把文件存到 Redis 里面,但 Redis 是带多个用户共享的,一个用户就能把整个 Redis 带宽给打满了,这样其他人的带宽就很卡,那这种很卡的时候 Redis 可能出现的行为是什么呢?我们并不需要一个用户真的去把它打满,只要用这种工具,瞬间就能出现我把你的带宽限制到原来的 1%,假设别人在跟你抢带宽,你的程序行为是什么?马上就能出来,也不需要配很复杂的环境。这极大的提高了测试效率,同时能测试到很多 corner case。\n\n然后 DNS fail。那 DNS fail 会有什么样的结果?有测过吗?可能都没有想过这个问题,但是在一个真正的分布式系统里面,每一点都是有可能出错的。还有 FLOOD,假设你现在被攻击了,整个系统的行为是什么样的?然后一不小心被这个 IP table 给 block 了,该怎么办。这种情况我们确实出现过。我们一上来并发,两万个连接一打出去,然后发现大部分都连不上,后来一看 IP table 自动启用了一个机制,然后把你们都 block。当然我们后面查了半个小时左右,才把问题查出来。但这种实际上应该是在最开始设计的时候就应该考虑的东西。\n\n如果你的进程被暂停了,比如说大家在云上跑在 VM 里面,整个 VM 为了升级,先把你整个暂停了,升级完之后再把你恢复的时候会怎么样?那简单来讲,就是如果假设你程序是有 GC 的,GC 现在把我们的程序卡了五秒,程序行为是正常的吗?五十秒呢?这个很有意思的就是,BurnCPU,就是再写一个程序,把 CPU 全占了,然后让你这个现在的程序只能使用一小部分的 CPU 的时候,你程序的行为是不是正常的。正常来讲,你可能说我 CPU 不是瓶颈啊,我瓶颈在 IO,当别人跟你抢 CPU,把你这个 CPU 压的很低的时候,到 CPU 是瓶颈的时候,正常你的程序的这个行为是不是正常的?还有 IO,跟你抢读的资源,跟你抢写的资源,然后 filedisk 把磁盘写满,写的空间很少。比如说对数据库而言,你创建你的 redo log 的时候,都已经满了会怎么样?然后我突然把磁盘设为只读,就你突然一个写入会出错,但是你接下来正常的读写行为是不是对的?很典型的一个例子,如果一个数据库你现在写入,磁盘满了,那外面读请求是否就能正常响应。 Fill memory,就是瞬间把这个 memory 给压缩下来,让你下次 malloc 的时候可能分布不到内存。这个就和业务比较相关了,就是破坏 HDFS 的文件。其它的就是 Hang、Panic,然后还有自杀,直接关掉机器,整个系统的行为是什么样的?\n\n现在比较痛苦的一点是大家各自为政,每一家都做一套,但是没有办法做成一个通用的东西给所有的人去用。包括我们自己也做了一套,但是确实没有办法和其他的语言之间去 share,最早提到的那个 libfu 库实际上是在 C 语言写的,那所有 C 相关的都可以去 call 那个库。\n\n**Distributed testing**\n\n+ Namazu\n\t+ ZooKeeper:\n\t\t- Found ZOOKEEPER-2212, ZOOKEEPER-2080 (race): (blog article)\n\t+ Etcd:\n\t\t- Found etcdctl bug #3517 (timing specification), fixed in #3530. The fix also resulted a hint of #3611, Reproduced flaky tests {#4006, #4039}\n\t+ YARN: Found YARN-4301 (fault tolerance), Reproduced flaky tests{1978, 4168, 4543, 4548, 4556}\n\n然后 Namazu。大家肯定觉得 ZooKeeper 很稳定呀, Facebook 在用、阿里在用、京东在用。大家都觉得这个东西也是很稳定的,直到这个工具出现了,然后轻轻松松就找到 bug 了,所有的大家认为的这种特别稳定的系统,其实 bug 都还挺多的,这是一个毁三观的事情,就是你觉得东西都很稳定,都很 stable,其实不是的。从上面,我们能看到 Namazu 找到的 Etcd 的几个 bug,然后 YARN 的几个 bug,其实还有一些别的。\n\n**How TiKV use namazu**\n\n+ Use nmz container / non-container mode to disturb cluster.\n\t- Run container mode in CI for each commit. (1 hour)\n\t- Run non-container mode for a stable version. (1 week+)\n+ Use `extreme` policy for process inspector\n\t- Pick up some processes and execute them with SCHED_RR scheduler. others are executed with SCHED_BATCH scheduler\n+ Use [0, 30s] delay for filesystem inspector\n\n接下来说一下 TiKV 用 Namazu 的一些经验。因为我们曾经在系统上、在云上面出现过一次写入磁盘花了五十几秒才完成的情况,所以我们需要专门的工具模拟这个磁盘的抖动。有时候一次写入可能确实耗时比较久,那这种时候是不是 OK 的。大家如果能把这种东西统统用上,我觉得还能为很多开源系统找出一堆 bug。\n\n稍微介绍一下我们现在运行的基本策略,比如说我们会用 0 到 30 秒的这个 delay (就是每一次你往文件系统的交互,比如说读或者写,那么我们会给你产生随机的 0 到 30 秒的 delay ),但我们正常应该还是需要去测三十秒到几分钟的延迟的情况,是否会让整个系统崩掉了。\n\n**How TiKV simulate network transport**\n\n+ Drop/Delay messages randomly\n+ Isolate Node\n+ Partition [1, 2, 3, 4, 5] -> [1, 2, 3] + [4, 5]\n+ Out of order messages\n+ Filter messages\n+ Duplicate and send redundant messages\n\n怎么模拟网络呢?假设你有网络,里面有五台机器,那我现在想做一个脑裂怎么做?不能靠拔网线对吧?比如在 TiKV 的测试框架中,我们就可以直接通过 API 把 5 个节点脑裂成两部分,让 1, 2, 3 号节点互相联通,4, 5 号节点也能联通,这两个分区彼此是隔离的,非常的方便。其实原理很简单,这种情况是用程序自己去模拟,假如是你发的包,自动给你丢掉,或者直接告诉你 unreachable,那这个时候你就知道这个网络就脑裂了,然后你怎么做?就是只允许特定类型的消息进来,把其他的都丢掉,这样一来你可以保证有些 bug 是必然重现的。这个框架给了我们极大的信心用来模拟并重现各种 corner case,确保这些 corner case 在单元测试中每次都能被覆盖到。\n\n**How to test Rocksdb**\n\n+ Treat storage as a black box.\n+ Three steps(7*24):\n\t- Fill data, Random kill -9\n\t- Restart\n\t- Consistent check.\n+ Results:\n\t- Found 2 bugs. Both fixed\n\n然后说说我们怎么测 RocksDB。 RocksDB 在大家印象中是很稳定的,但我们最近发现了两个 bug。测的方法是这样的:我们往 RocksDB 里面填数据,然后随机的一段时间去把它 kill 掉,kill 掉之后我们重启,重新启动之后去检测我们刚才 fail 的 data 是不是一致的,然后我们发现两个可能造成数据丢失的 bug,但是官方的响应速度非常快,几天就都 fix 了。可是大家普遍运行的是这么 stable 的系统,为什么还会这么容易找到 bug?就说这个测试,如果是一直有这个测试的 cover,那么这两个 bug 可能很快就能够被发现。\n\n这是我们一个基本的,也就是当成一个纯黑盒的测。大家在测数据库的时候,基本也是当黑盒测。比如说 MySQL 写入数据,kill 掉,比如说我 commit 一个事务,数据库告诉我们 commit 成功,我把数据库 kill 掉,我再去查我刚才提交的数据一样能查到。这是一个正常的行为,如果查不到,说明整个系统有问题。\n\n**More tools**\n\n+ american fuzzy lop\n\n\n\n\n其实还有一些更加先进的工具,大家平时觉得特别稳定的东西,都被摧残的不行。Nginx 、NGPD、tcpdump 、LibreOffice ,如果有用 Linux 的同学可能知道,还有 Flash、sqlite。这个东西一出来,当时大家很兴奋,说怎么一下子找了这么多 bug,为什么以前那么稳定的系统这么不堪一击,会觉得这个东西它还挺智能的。就比如说你程序里面有个 if 分支,它是这样的,假如你程序有一百条指令,它先从前面一直走,走到某条分支指令的时候,它是一直持续探索,一个分支走不下去,它会一直在这儿持续探索,再给你随机的输入,直到我探索进去了,我记下来了下次我知道我用这个输入可以进去特定的分支。那我可以再往下走,比如说你 if 分支进去之后里面还有 if ,那你传统手段可能探测不进去了但它可以,它记录一下,我这个可以进去,然后我重来,反正我继续输入这个,我再往里面走,一旦我探测到一个新的分支,我再记住,我再往里面走。所以它一出来的时候大家都说这个真厉害,一下发现这么多 bug。但最激动的不是这些人,最激动的是黑客,为什么?因为突然有很多栈溢出、堆溢出漏洞被发现了,然后就可以写一堆工具去攻击线上的这么多系统。所以很多的技术的推进在早期的时候是黑客做出来,但是他们的目的当然不一定是为了测试 bug,而是为了怎么黑一个系统进去,这是他们当时做的,所以这个工具也是非常强大、非常有意思的,大家可以拿去研究一下自己的系统。\n\n大家印象里面各种文件系统是很稳定的,可是当用 American fuzzy lop 来测试的时候,被惊呆了。 Btrfs 连 5 秒都没有坚持到就跪了,大家用的最多的 Ext4 是最坚挺的,也才抗了两个小时!!!\n\n\n\n再来说说 Google,Google 怎么做测试对外讲的不多,最近 Chrome team 开源了他们的 Fuzz 测试工具 OSS-Fuzz,这个工具强大的地方在于自动化做的极好:\n\n+ 发现 bug 后自动创建 issue\n+ bug 解决后自动 verify\n\n更惊人的是 OSS-Fuzz 集群一周可以跑 ~4 trillion test cases 更多细节大家可以看这篇文章:[Announcing OSS-Fuzz: Continuous Fuzzing for Open Source Software](https://opensource.googleblog.com/2016/12/announcing-oss-fuzz-continuous-fuzzing.html)\n\n另外有些工具能让分布式系统开发人员的生活变得更美好一点。\n\n**Tracing tools may help you**\n\n+ Google Dapper\n+ Zipkin\n+ OpenTracing\n\n还有 Tracing,比如说我一个 query 过来,然后经过这么多层,经过这么多机器,然后在不同的地方,不同环节耗时多久,实际上这个在分布式系统里面,有个专门的东西做 Tracing ,就是 distribute tracing tools。它可以用一条线来表达你的请求在各个阶段耗时多长,如果有几段,那么分到几个机器,分别并行的时候好了多长时间。大体的结构是这样的:\n\n\n\n\n这里是一个具体的例子:\n\n\n\n很清晰,一看就知道了,不用去看 log,这事其实一点也不新鲜,Google 十几年前就做了一个分布式追踪的工具。然后开源社区要做一个实现叫做 Zipkin,好像是 java 还是什么写的,又出了新的叫 OpenTracing,是 Go 写的。我们现在正准备上这个系统,用来追踪 TiDB 的请求在各个阶段的响应时间。\n\n最后想说一下,大家研究系统发现 bug 多了之后,不要对系统就丧失了信心,毕竟 bug 一直在那里,只是从前没有发现,现在发现得多了,总体上新的测试方法让系统的质量比以前好了很多。好像有点超时了,先聊到这里吧,还有好多细节没法展开,下次再聊。\n\n##### -本系列完结-\n\n> 相关阅读: \n[分布式系统测试那些事儿 - 理念](https://pingcap.com/zh/blog/distributed-system-test-1); \n> [分布式系统测试那些事儿 - 错误注入](https://pingcap.com/zh/blog/distributed-system-test-2)。","date":"2016-12-07","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"distributed-system-test-3","file":null,"relatedBlogs":[]},{"id":"Blogs_140","title":"分布式系统测试那些事儿 - 错误注入","tags":["TiDB","分布式系统测试"],"category":{"name":"观点洞察"},"summary":"本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为中篇。","body":"> 本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为中篇。\n\n##### -接上篇-\n\n当然测试可能会让你代码变得没有那么漂亮,举个例子:\n\n\n\n这是知名的 Kubernetes 的代码,就是说它有一个 DaemonSetcontroller,这 controller 里面注入了三个测试点,比如这个地方注入了一个 handler ,你可以认为所有的注入都是 interface。比如说你写一个简单的 1+1=2 的程序,假设我们写一个计算器,这个计算器的功能就是求和,那这就很难注入错误。所以你必须要在你正确的代码里面去注入测试逻辑。再比如别人 call 你的这个 add 的 function,然后你是不是有一个 error?这个 error 的问题是它可能永远不会返回一个 error,所以你必须要人肉的注进去,然后看应用程序是不是正确的行为。说完了加法,再说我们做一个除法。除法大家知道可能有处理异常,那上面是不是能正常处理呢?上面没有,上面写着一个比如说 6 ÷ 3,然后写了一个 test,coverage 100%,但是一个除零异常,系统就崩掉了,所以这时候就需要去注入错误。大名鼎鼎的 Kubernetes 为了测试各种异常逻辑也采用类似的方式,这个结构体不算长,大概是十几个成员,然后里面就注入了三个点,可以在里面注入错误。\n\n那么在设计 TiDB 的时候,我们当时是怎么考虑 test 这个事情的?首先一个百万级的 test 不可能由人肉来写,也就是说你如果重新定义一个自己的所谓的 SQL 语法,或者一个 query language,那这个时候你需要构建百万级的 test,即使全公司去写,写个两年都不够,所以这个事情显然是不靠谱的。但是除非说我的 query language 特别简单,比如像 MongoDB 早期的那种,那我一个“大于多少”的这种,或者 equal 这种条件查询特别简单的,那你确实是不需要构建这种百万级的 test。但是如果做一个 SQL 的 database 的话,那是需要构建这种非常非常复杂的 test 的。这时候这个 test 又不能全公司的人写个两年,对吧?所以有什么好办法呢?MySQL 兼容的各种系统都是可以用来 test 的,所以我们当时兼容 MySQL 协议,那意味着我们能够取得大量的 MySQL test。不知道有没有人统计过 MySQL 有多少个 test,产品级的 test 很吓人的,千万级。然后还有很多 ORM, 支持 MySQL 的各种应用都有自己的测试。大家知道,每个语言都会 build 自己的 ORM,然后甚至是一个语言的 ORM 都有好几个。比如说对于 MySQL 可能有排第一的、排第二的,那我们可以把这些全拿过来用来测试我们的系统。\n\n但对于有些应用程序而言,这时候就比较坑了。就是一个应用程序你得把它 setup 起来,然后操作这个应用程序,比如 WordPress,而后再看那个结果。所以这时候我们为了避免刚才人肉去测试,我们做了一个程序来自动化的 Record---Replay。就是你在首次运行的时候,我们会记录它所有执行的 SQL 语句,那下一次我再需要重新运行这个程序的时候怎么办?我不需要运行这个程序了,我不需要起来了,我只需要把它前面记录的 SQL record 重新回放一遍,就相当于是我模拟了程序的整个行为。所以我们在这部分是这样做的自动化。\n\n那么刚刚说了那么多,实际上做的是什么?实际上做的都是正确路径的测试,那几百万个 test 也都是做的正确的路径测试,但是错误的路径怎么办?很典型的一个例子就是怎么做 Fault injection。硬件比较简单粗暴的模拟网络故障可以拔网线,比如说测网络的时候可以把这个网线拔掉,但是这个做法是极其低效的,而且它是没法 scale 的,因为这个需要人的参与。\n\n然后还有比如说 CPU,这个 CPU 的损坏概率其实也挺高的,特别是对于过保了的机器。然后还有磁盘,磁盘大概是三年百分之八点几的损坏率,这是一篇论文里面给出的数据。我记得 Google 好像之前给过一个数据,就是 CPU、网卡还有磁盘在多少年之内的损坏率大概是什么样的。\n\n还有一个大家不太关注的就是时钟。先前,我们发现系统时钟是有回跳的,然后我们果断在程序里面加个监测模块,一旦系统时钟回跳,我们马上把这个检测出来。当然我们最初监测出这个东西的时候,用户是觉得不可能吧,时钟还会有回跳?我说没关系,先把我们程序开了监测一下,然后过段时间就检测到,系统时钟最近回跳了。所以怎么配 NTP 很重要。然后还有更多的,比如说文件系统,大家有没有考虑过你写磁盘的时候,磁盘出错会怎么办?好,写磁盘的时候没有出错,成功了,然后磁盘一个扇区坏了,读出来的数据是损坏的,怎么办?大家有没有 checksum ?没有 checksum 然后我们直接用了这个数据,然后直接给用户返回了,这个时候可能是很要命的。如果这个数据刚好存的是个元数据,而元数据又指向别的数据,然后你又根据元数据的信息去写入另外一份数据,那就更要命了,可能数据被进一步破坏了。\n\n**所以比较好的做法是什么?**\n\n+ **Fault injection**\n\t- Hardware\n\t\t- disk error\n\t\t- network card\n\t\t- cpu\n\t\t- clock\n\t- Software\n\t\t- file system\n \t\t- network & protocol\n+ **Simulate everything**\n\n**模拟一切东西。**就是磁盘是模拟的,网络是模拟的,那我们可以监控它,你可以在任何时间、任何的场景下去注入各种错误,你可以注入任何你想要的错误。比如说你写一个磁盘,我就告诉你磁盘满了,我告诉你磁盘坏了,然后我可以让你 hang 住,比如 sleep 五十几秒。我们确实在云上面出现过这种情况,就是我们一次写入,然后被 hang 了为 53 秒,最后才写进去,那肯定是网络磁盘,对吧?这种事情其实是很吓人的,但是肯定没有人会想说我一次磁盘写入然后要耗掉 53 秒,但是当 53 秒出现的时候,整个程序的行为是什么?TiDB 里面用了大量的 Raft,所以当时出现一个情况就是 53 秒,然后所有的机器就开始选举了,说这肯定是哪儿不对,重新把 leader 都选出来了,这时候卡 53 秒的哥们说“我写完了”,然后整个系统状态就做了一次全新的迁移。这种错误注入的好处是什么?就是知道当出错的时候,你的错误能严重到什么程度,这个事情很重要,就是 predictable,整个系统要可预测的。如果没有做错误路径的测试,那很简单的一个问题,现在假设走到其中一条错误路径了,整个系统行为是什么?这一点不知道是很吓人的。你不知道是否可能破坏数据;还是业务那边会 block 住;还是业务那边会 retry?\n\n以前我遇到一个问题很有意思,当时我们在做一个消息系统,有大量连接会连这个,一个单机大概是连八十万左右的连接,就是做消息推送。然后我记得,当时的 swap 分区开了,开了是什么概念?当你有更多连接打进来的时候,然后你内存要爆了对吧?内存爆的话会自动启用 swap 分区,但一旦你启用 swap 分区,那你系统就卡成狗了,外面用户断连之后他就失败了,他得重连,但是重连到你正常程序能响应,可能又需要三十秒,然后那个用户肯定觉得超时了,又切断连接又重连,就造成一个什么状态呢?就是系统永远在重试,永远没有一次成功。那这个行为是不是可以预测?这种错误当时有没有做很好的测试?这都是非常重要的一些教训。\n\n硬件测试以前的办法是这样的(Joke):\n\n\n\n假设我一个磁盘坏了,假设我一个机器挂了,还有一个假设它不一定坏了也不一定挂了,比如说它着火了会怎么样?前两个月吧,是瑞士还是哪个地方的一个银行做测试,那哥们也挺逗的,人肉对着服务器这样吹气,来看监控数据那个变化,然后那边马上开始报警。这还只是吹气而已,那如果更复杂的测试,比如说你着火从哪个地方开始烧,先烧到硬盘、或者先烧到网卡,这个结果可能也是不一样的。当然这个成本很高,然后也不是能 scale 的一种方案,同时也很难去复制。\n\n这不仅仅是硬件的监控,也可以认为是做错误的注入。比如说一个集群我现在烧掉一台会怎么样?着火了,很典型的嘛,虽然重要的机房都会有这种防火、防水等各种的策略,但是真的着火的时候怎么办?当然你不能真去烧,这一烧可能就不止坏一台机器了,但我们需要使用 Fault injection 来模拟。\n\n我介绍一下到底什么是 Fault injection。给一个直观的例子,大家知道所有人都用过 Unix 或者 Linux 的系统,大家都知道,很多人习惯打开这个系统第一行命令就是 ls 来列出目录里面的文件,但是大家有没有想过一个有意思的问题,如果你要测试 ls 命令实现的正确性,怎么测?如果没有源代码,这个系统该怎么测?如果把它当成一黑盒这个系统该怎么测?如果你 ls 的时候磁盘出现错误怎么办?如果读取一个扇区读取失败会怎么办?\n\n这个是一个很好玩的工具,推荐大家去玩一下。就是当你还没有做更深入的测试之前,可以先去理解一下到底什么是 Fault injection,你就可以体验到它的强大,一会我们用它来找个 MySQL 的 bug。\n\n**libfiu - Fault injection in userspace**\n\nIt can be used to perform fault injection in the **POSIX API** without having to modify the application's source code, that can help to test failure handling in an easy and reproducible way.\n\n那这个东西主要是用来 Hook 这些 API 的,它很重要的一点就是它提供了一个 library ,这个 library 也可以嵌到你的程序里面去 hook 那些 API。就比如说你去读文件的时候,它可以给你返回这个文件不存在,可以给你返回磁盘错误等等。最重要的是,它是可以重来的。\n\n举一个例子,正常来讲我们敲 ls 命令的时候,肯定是能够把当前的目录显示出来。\n\n\n\n这个程序干的是什么呢?就是 run,指定一个参数,现在是要有一个 enable_random,就是后面所有的对于 IO 下面这些 API 的操作,有 5% 的失败率。那第一次是运气比较好,没有遇到失败,所以我们把整个目录列出来了。然后我们重新再跑一次,这时候它告诉我有一次读取失败了,就是它 read 这个 directory 的时候,遇到一个 Bad file descriptor,这时候可以看到,列出来的文件就比上面的要少了,因为有一条路径让它失败了。接下来,我们进一步再跑,发现刚列出来一个目录,然后下次读取就出错了。然后后面再跑一次的时候,这次运气也比较好,把这整个都列出来了,这个还只是模拟的 5% 的失败率。就是有 5% 的概率你去 read、去 open 的时候会失败,那么这时候可以看到 ls 命令的行为还是很 stable 的,就是没有什么常见的 segment fault 这些。\n\n大家可能会说这个还不太好玩,也就是找找 ls 命令是否有 bug 嘛,那我们复现 MySQL bug 玩一下。\n\n**Bug #76020**\n\n**InnoDB does not report filename in I/O error message for reads**\n\nfiu-run -x -c \"enable_random name=posix/io/*,probability=0.05\" bin/mysqld --\n\nbasedir=/data/ushastry/server/mysql-5.6.24 --datadir=/data/ushastry/server/mysql-5.6.24/76020 --core-file --socket=/tmp/mysql_ushastry.sock --port=15000\n\n2015-05-20 19:12:07 31030 [ERROR] InnoDB: Error in system call pread(). The operating system error number is 5.\n\n2015-05-20 19:12:07 7f7986efc720 InnoDB: Operating system error number 5 in a file operation.\n\nInnoDB: Error number 5 means 'Input/output error'.\n\n2015-05-20 19:12:07 31030 [ERROR] InnoDB: File (unknown):\n\n'read' returned OS error 105. Cannot continue operation\n\n这是用 libfiu 找到的 MySQL 的一个 bug,这个 bug 是这样的,bug 编号是 76020,是说 InnoDB 在出错的时候没有报文件名,那用户给你报了错,你这时候就傻了对吧?这个到底是什么地方出错了呢?然后这个地方它怎么出来的?你可以看到它还是用我们刚才提到的 fiu-run,然后来模拟,模拟的失败概率还是这么多,可以看到,我们的参数一个没变,这时把 MySQL 启动,然后跑一下,出现了,可以看到 InnoDB 在报的时候确实没有报 filename ,File : 'read' returned OS error,然后这边是 auto error,你不知道是哪一个文件名。\n\n换一个思路来看,假设没有这个东西,你复现这个 bug 的成本是什么?大家可以想想,如果没有这个东西,这个 bug 应该怎么复现,怎么让 MySQL 读取的东西出错?正常路径下你让它读取出错太困难了,可能好多年没出现过。这时我们进一步再放大一下,这个在 5.7 里面还有,也是在 MySQL 里面很可能有十几年大家都没怎么遇到过的,但这种 bug 在这个工具的辅助下,马上就能出来。所以 Fault injection 它带来了很重要的一个好处就是让一个东西可以变得更加容易重现。这个还是模拟的 5% 的概率。这个例子是我昨天晚上做的,就是我要给大家一个直观的理解,但是分布式系统里面错误注入比这个要复杂。而且如果你遇到一个错误十年都没出现,你是不是太孤独了? 这个电影大家可能还有印象,威尔史密斯主演的,全世界就一个人活着,唯一的伙伴是一条狗。\n\n\n\n实际上不是的,比我们痛苦的人大把的存在着。\n\n举 Netflix 的一个例子,下图是 Netflix 的系统。\n\n\n\n\n他们在 2014 年 10 月份的时候写了一篇博客,叫《 Failure Injection Testing 》,是讲他们整个系统怎么做错误注入,然后他们的这个说法是 Internet Scale,就是整个多数据中心互联网的这个级别。大家可能记得 Spanner 刚出来的时候他们叫做 Global Scale,然后这地方可以看到,蓝色是注射点,黑色的是网络调用,就是所有这些请求在这些情况下面,所有这些蓝色的框框都有可能出错。大家可以想一想,在 Microservice 系统上,一个业务调用可能涉及到几十个系统的调用,如果其中一个失败了会怎么样?如果是第一次第一个失败,第二次第二个失败,第三次第三个失败是怎么样的?有没有系统做过这样的测试?有没有系统在自己的程序里面去很好的验证过是不是每一个可以预期的错误都是可预测的,这个变得非常的重要。这里以 cache 为例,就说每一次访问 Cassandra 的时候可能出错,那么也就给了我们一个错误的注入点。\n\n然后我们谈谈 OpenStack.\n\n**OpenStack fault-injection library:**\n\n***https://pypi.org/project/os-faults/***\n\n大名鼎鼎的 OpenStack 其实也有一个 Failure Injection Library,然后我把这个例子也贴到这里,大家有兴趣可以看一下这个 OpenStack 的 Failure Injection。这以前大家可能不太关注,其实大家在这一点上都很痛苦, OpenStack 现在还有一堆人在骂,说稳定性太差了,其实他们已经很努力了。但是整个系统确实是做的异乎寻常的复杂,因为组件太多。如果你出错的点特别多,那可能会带来另外一个问题,就是出错的点之间还能组合,就是先 A 出错,再 B 出错,或者 AB 都出错,这也就几种情况,还好。那你要是有十万个错误的点,这个组合怎么弄?当然现在还有新的论文在研究这个,2015 年的时候好像有一篇论文,讲的就是会探测你的程序的路径,然后在对应的路径下面去注入错误。\n\n再来说 Jepsen.\n\n**Jepsen: Distributed Systems Safety Analysis**\n\n\n\n\n大家所有听过的知名的开源分布式系统基本上都被它找出来过 bug。但是在这之前大家都觉得自己还是很 OK 的,我们的系统还是比较稳定的,所以当新的这个工具或者新的方法出现的时候,就比如说我刚才提到的那篇能够线性 Scale 的去查错的那篇论文,那个到时候查错力就很惊人了,因为它能够自动帮你探测。另外我介绍一个工具 Namazu,后面讲,它也很强大。这里先说Jepsen, 这货算是重型武器了,无论是 ZooKeeper、MongoDB 以及 Redis 等等,所有这些全部都被找出了 bug,现在用的所有数据库都是它找出的 bug,最大的问题是小众语言 closure 编写的,扩展起来有点麻烦。我先说说 Jepsen 的基本原理,一个典型使用 Jepsen 的测试通过会在一个 control node上面运行相关的 clojure 程序,control node 会使用 ssh 登陆到相关的系统 node(jepsen 叫做 db node)进行一些测试操作。\n\n当我们的分布式系统启动起来之后,control node 会启动很多进程,每一个进程都能使用特定的 client 访问到我们的分布式系统。一个 generator 为每一个进程生成一系列的操作,比如 get/set/cas,让其执行。每一个操作都会被记录到 history 里面。在执行操作的同时,另一个 nemesis 进程会尝试去破坏这个分布式系统,譬如使用 iptable 断开网络连接等,当所有操作执行完毕之后,jepsen 会使用一个 checker 来分析验证系统的行为是否符合预期。PingCAP 的首席架构师唐刘写过两篇文章介绍我们实际怎么用 Jepsen 来测试 TiDB,大家可以搜索一下,我这里就不详细展开了。\n\n+ FoundationDB\n\t- It is difficult to be deterministic\n\t\t- Random\n\t\t- Disk Size\n\t\t- File Length\n\t\t- Time\n\t\t- Multithread\n\nFoundationDB 这就是前辈了,2015 年被 Apple 收购了。他们为了解决错误注入的问题,或者说怎么去让它重现的这个问题,做了很多事情,很重要的一个事情就是 deterministic 。如果我给你一样的输入,跑几遍,是不是能得到一样的输出?这个听起来好像很科学、很自然,但是实际上我们绝大多数程序都是做不到的,比如说你们有判断程序里面有随机数吗?有多线程吗?有判断磁盘空间吗?有判断时间吗?你再一次判断的时候还是一样的吗?你再跑一次,同样的输入,但行为已经不一样了,比如你生了一个随机数,比如你判断磁盘空间,这次判断和下次判断可能是不一样的。\n\n所以他们为了做到“我给你一样的输入,一定能得到一样的输出”,花了大概两年的时间做了一个库。这个库有以下特性:它是个单线程的,然后是个伪并发的。为什么?因为如果用多线程你怎么让它这个相同的输入变成相同的输出,谁先拿到锁呢?这里面的问题很多,所以他们选择使用单线程,但是单线程本身有单线程的问题。而且比如你用 Go 语言,那你单线程它也是个并发的。然后它的语言规范就告诉我们说,如果一个 select 作用在两个 channel 上,两个 channel 都 ready 的时候,它会随机的一个,就是在语言定义的规范上面,就已经不可能让你得到一个 deterministic 了。但还好 FoundationDB 是用 C++ 写的。\n\n+ FoundationDB\n\t- Single-threaded pseudo-concurrency\n\t- Simulated the implementation of all the external communication\n\t- Determinism\n\t- Disasters happen more frequently here than in the real world.\n\n另外 FoundationDB 模拟了所有的网络,就是两个之间认为通过网络通讯,对吧?实际上是通过它自己模拟的一套东西在通讯。它里面有一个很重要的观点就是说,如果磁盘损坏,出现的概率是三年百分之八的话,那么在用户那出现的概率是三年百分之八。但是在用户那一旦出现了,那证明就很严重了,所以他们对待这个问题的办法是什么?就是我通过自己的模拟系统让它每时每刻都在产生。它们大概是每两分钟产生一次磁盘损坏,也就是说它比现实中的概率要高几十万倍,所以它就觉得它调的技术 more frequently,就是我这种错误出现的更加频繁,那网卡损坏的概率是多少?这都是极低的,但是你可以用这个系统让它每分每秒都产生,这样一来你就让你的系统遇到这种错误的概率是比现实中要大非常非常多。那你重现,比如说现实中跑三年能重现一次,你可能跑三十秒就能重现一次。\n\n但对于一个 bug 来说最可怕的是什么?就是它不能重现。发现一个 bug,后来说我 fix 了,然后不能重现了,那你到底 fix 了没有?不知道,这个事情就变得非常的恐怖。所以通过 deterministic 肯定能保证重现,我只要把我的输入重放一次,我把它录下来,每一次我把它录下来一次,然后只要是曾经出现过,我重放,一定能出现。当然这个代价太大了,所以现在学术界走的是另外一条路,不是完全 deterministic,但是我只需要它 reasonable。比如说我在三十分钟内能把它重现也是不错的,我并不需要在三秒内把它重现。所以,每前一步要付出相应的成本代价。\n\n##### 未完待续...\n\n> 相关阅读: \n[分布式系统测试那些事儿 - 理念](https://pingcap.com/zh/blog/distributed-system-test-1); \n> [分布式系统测试那些事儿 - 信心的毁灭与重建](https://pingcap.com/zh/blog/distributed-system-test-3)。","date":"2016-11-10","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"distributed-system-test-2","file":null,"relatedBlogs":[]},{"id":"Blogs_182","title":"分布式系统测试那些事儿 - 理念","tags":["TiDB","分布式系统测试","自动化测试"],"category":{"name":"观点洞察"},"summary":"本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为上篇。","body":"> 本话题系列文章整理自 PingCAP NewSQL Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为上篇。\n\n今天主要是介绍分布式系统测试。对于 PingCAP 目前的现状来说,我们是觉得做好分布式系统测试比做一个分布式系统更难。就是你把它写出来不是最难的,把它测好才是最难的。大家肯定会觉得有这么夸张吗?那我们先从一个最简单的、每个人都会写的 Hello world 开始。\n\n### A simple “Hello world” is a miracle\n\nWe should walk through all of the bugs in:\n\n+ Compiler\n+ Linker\n+ VM (maybe)\n+ OS\n\n其实这个 Hello world 能够每次都正确运行已经是一个奇迹了,为什么呢?首先,编译器得没 bug,链接器得没 bug ;然后我们可能跑在 VM 上,那 VM 还得没 bug;并且 Hello world 那还有一个 syscall,那我们还得保证操作系统没有 bug;到这还不算吧,我们还得要硬件没有 bug。所以一个最简单程序它能正常运行起来,我们要穿越巨长的一条路径,然后这个路径里面所有的东西都不能出问题,我们才能看到一个最简单的 Hello world。\n\n但是分布式系统里面呢,就更加复杂了。比如大家现在用的很典型的微服务。假设你提供了一个微服务,然后在微服务提供的功能就是输出一个 Hello world ,然后让别人来 Call。\n\n### A RPC “Hello world” is a miracle\n\nWe should walk through all of the bugs in:\n\n+ Coordinator (zookeeper, etcd)\n+ RPC implementation\n+ Network stack\n+ Encoding/Decoding library\n+ Compiler for programming languages or [protocol buffers, avro, msgpack, capn]\n\n那么我们可以看一下它的路径。我们起码需要依赖 Coordinator 去做这种服务发现,比如用 zookeeper,etcd ,大家会感觉是这东西应该很稳定了吧?但大家可以去查一下他们每一次 release notes,里边说我们 fix 了哪些 bug,就是所有大家印象中非常稳定的这些东西,一直都在升级,每一次升级都会有 bug fix。但换个思路来看,其实我们也很幸运,因为大部分时候我们没有碰到那个 bug,然后 RPC 的这个实现不能有问题。当然如果大家深度使用 RPC,比如说 gRPC,你会发现其实 bug 还是挺多的,用的深一点,基本上就会发现它有 bug。还有系统网络协议栈,去年 TCP 被爆出有一个 checksum 问题,就是 Linux 的 TCP 协议栈,这都是印象中永远不会出问题的。再有,编解码,大家如果有 Go 的经验的话,可以看一下 Go 的 JSON 历史上从发布以来更新的记录,也会发现一些 bug。还有更多的大家喜欢的编解码,比如说你用 Protocol buffers、Avro、Msgpack、Cap'n 等等,那它们本身还需要 compiler 去生成一个代码,然后我们还需要那个 compiler 生成的代码是没有 bug 的。然后这一整套下来,我们这个程序差不多是能运行的,当然我们没有考虑硬件本身的 bug。\n\n其实一个正确的运行程序从概率上来讲(不考虑宇宙射线什么的这种),已经是非常幸运的了。当然每一个系统都不是完善的,那通常情况下,为什么我们这个就运行的顺利呢?因为我们的测试永远都测到了正确的路径,我们跑一个简单的测试一定是把正确的路径测到了,但是这中间有很多错误路径其实我们都没有碰到。然后我不知道大家有没有印象,如果写 Go 程序的时候,错误处理通常写成 if err != nil,然后 return error ,不知道大家写了多少。那其它程序、其它的语言里就是 try.catch,然后里面各种 error 处理。就是一个真正完善的系统,最终的错误处理代码实际上通常会比你写正常逻辑代码还要多的,但是我们的测试通常 cover 的是正确的逻辑,就是实际上我们测试的 cover 是一小部分。\n\n那先纠正几个观念,关于测试的。就是到底怎么样才能得到一个好的、高质量的程序,或者说得到一个高质量的系统?\n\n### Who is the tester ?\n\n+ Quality comes from solid engineering.\n+ Stop talking and go build things.\n+ Don’t hire too many testers.\n\t- Testing is owned by the entire team. It is a culture, not a process.\n+ Are testers software engineers? Yes.\n+ Hiring good people is the first step. And then keep them challenged.\n\n我们的观念是说先有 solid engineering 。我觉得这个几乎是勿庸置疑的吧,不知道大家的经验是什么?然后还有一个就是不扯淡,尽快去把东西 build 起来,然后让东西去运转起来。我前一段时间也写了一个段子,就是:“你是写 Rust 的,他是写 Java 的,你们这聊了这么久,人家 Rust (编译速度慢) 的程序已经编译过了,你 Java 还没开始写。”原版是这样的:“你是砍柴的,他是放羊的,你们聊了一天,他的羊吃饱了,你的柴呢?”然后最近还有一个特别有争议的话题:CTO 应该干嘛。就是 CTO 到底该不该写代码,这个也是众说纷纭。因为每一个人都受到自己环境的局限,所以每个人的看法都是不一样的。那我觉得有点像,就是同样是聊天,然后不同人有不同的看法。\n\n### Test automation\n\n+ Allow developers to get a unit test results immediately.\n+ Allow developers to run all unit tests in one go.\n+ Allow code coverage calculations.\n+ Show the testing evolution on the dashboards.\n+ Automate everything.\n\n我们现在很有意思的一个事情是,迄今为止 PingCAP 没有一个测试人员,这是在所有的公司看来可能都是觉得不可思议的事情,那为什么我们要这么干?因为我们现在的测试已经不可能由人去测了。究竟复杂到什么程度呢?我说几个基本数字大家感受一下:我们现在有六百多万个 Test,这是完全自动化去跑的。然后我们还有大量从社区收集到的各种 ORM Test,一会我会提到这一点。就是这么多 Test 已经不可能是由人写出来的了,以前的概念里面是 Test 是由人写的,但实际上 Test 不一定是人写的,Test 也是可以由机器生成的。举个例子,如果给你一个合法的语法树,你按照这个语法树去做一个输出,比如说你可以更换变量名,可以更换它的表达式等等,你可以生成很多的这种 SQL 出来。\n\nGoogle Spanner 就用到这个特性,它会有专门的程序自动生成符合 SQL 语法的语句,然后再交给系统去执行。如果执行过程中 crash 了,那说明这个系统肯定有 bug。但是这地方又蹦出另外一个问题,就是你生成了合法的 SQL 语句,但是你不知道它语句执行的结构,那你怎么去判断它是不是对的?当然业界有很聪明的人。我把它扔给几个数据库同时跑一下,然后取几个大家一致的结果,那我就认为这个结果基本上是对的。如果一个语句过来,然后在我这边执行的结果和另外几个都不一样,那说明我这边肯定错了。就算你是对的,可能也是错的,因为别人执行下来都是这个结果,你不一样,那大家都会认为你是错的。\n\n所以说在测试的时候,怎么去自动生成测试很重要。去年,在美国那边开始流行一个新的说法,叫做 “怎么在你睡觉的时候发现 bug”。那么实际上测试干的很重要的事情就是这个,就是自动化测试是可以在你睡觉的时候发现 bug。好像刚才我们还提到 fault injection ,好像还有 fuzz testing。然后所有测试的人都是工程师,因为只有这样你才不会甩锅。\n\n这是我们现在坚信的一个事情,就是所有的测试必须要高度的自动化,完全不由人去干预。然后很重要的一个就是雇最优秀的人才,同时给他们挑战,就是如果没有挑战,这些人才会很闲,精力分散,然后很难合力出成绩。因为以现在这个社会而言,很重要一个特性是什么?就是对于复杂性工程需要大量的优秀人才,如果优秀的人才力不往一处使力的话,这个复杂性工程是做不出来的。我今天看了一下龙芯做了十年了,差不多是做到英特尔凌动处理器的水平。他们肯定是有很优秀的人才,但是目前还得承认,我们在硬件上面和国外的差距还比较大,其实软件上面的差距也比较大,比如说我们和 Spanner 起码差了七年,2012 年 Spanner 就已经大规模在 Google 使用了,对这些优秀的作品,我们一直心存敬仰。\n\n我刚才已经反复强调过自动化这个事情。不知道大家平时写代码 cover 已经到多少了?如果 cover 一直低于 50%,那就是说你有一半的代码没有被测到,那它在线上什么时候都有可能出现问题。当然我们还需要更好的方法去在上线之前能够把线上的 case 回放。理论上你对线上这个回放的越久你就越安全,但是前提是线上代码永远不更新,如果业务方更新了,那就又相当于埋下了一个定时炸弹。比如说你在上面跑两个月,然后业务现在有一点修改,然而那两个又没有 cover 住修改,那这时候可能有新的问题。所以要把所有的一切都自动化,包括刚才的监控。比如说你一个系统一过去,然后自动发现有哪些项需要监控,然后自动设置报警。大家觉得这事是不是很神奇?其实这在 Google 里面是司空见惯的事情,PingCAP 现在也正在做。\n\n### Well… still not enough ?\n\n+ Each layer can be tested independently.\n+ Make sure you are building the right tests.\n+ Don’t bother great people unless the testing fails.\n+ Write unit tests for every bug.\n\n这么多还是不够的,就是对于整个系统测试来讲,你可以分成很多层、分成很多模块,然后一个一个的去测。还有很重要的一点,就是早期的时候我们发现一个很有意思的事情。就是我们 build 了大量 Test,然后我们的程序都轻松的 pass 了大量的 Test,后来发现我们一个 Test 是错的,那意味着什么?意味着我们的程序一直是错的,因为 Test 会把你这个 cover 住。所以直到后来我们有一次觉得自己写了一个正确的代码,但是跑出来的结果不对,我们这时候再去查,发现以前有一个 Test 写错了。所以一个正确的 Test 是非常重要的,否则你永远被埋在错误里面,然后埋在错误里面感觉还特别好,因为它告诉你是正确的。\n\n还有,为什么要自动化呢?就是你不要去打扰这些聪明人。他们本身很聪明,你没事别去打扰他们,说“来,你过来给我做个测试”,那这时候不断去打扰他们,是影响他们的发挥,影响他们做自己的挑战。\n\n这一条非常重要,所有出现过的 bug,历史上只要出现过一次,你一定要写一个 Test 去 cover 它,那这个法则大家应该已经都清楚了。我看今天所在的人的年龄,应该《圣斗士星矢》是看过的,对吧?这个圣斗士是有一个特点的,所有对他们有效的招数只能用一次,那这个也是一样的,就保证你不会被再次咬到,就不会再次被坑到。我印象中应该有很多人 fix bug 是这样的:有一个 bug 我 fix 了,但没有 Test,后来又出现了,然后这时候就觉得很奇怪,然后积累的越多,最后就被坑的越惨。\n\n这个是目前主流开源社区都在坚持的做法,基本没有例外。就是如果有一个开源社区说我发现一个 bug,我没有 Test 去 cover 它,这个东西以后别人是不敢用的。\n\n### Code review\n\n+ At least two LGTMs (Looks good to me) from the maintainers.\n+ Address comments.\n+ Squash commit logs.\n+ Travis CI/Circle CI for PRs.\n\n简单说一下 code review 的事情,它和 Test 还是有一点关系,为什么?因为在 code review 的时候你会提一个新的 pr,然后这个 pr 一定要通过这个 Test。比如说典型的 Travis CI,或者 CircleCI 的这种 Test。为什么要这样做呢?因为要保证它被 merge 到 master 之前你一定要发现这个问题,如果已经 merge 到 master 了,首先这不好看,因为你要 revert 掉,这个在 commit 记录上是特别不好看的一个事情。另外一个就是它出现问题之前,你就先把它发现其实是最好的,因为有很多工具会根据 master 自动去 build。比如说我们会根据 master 去自动 build docker 镜像,一旦你代码被 commit 到 master,然后 docker 镜像就出来了。那你的用户就发现,你有新的更新,我要马上使用新的,但是如果你之前的 CI 没有过,这时候就麻烦了,所以 CI 没过,一定不能进入到 CD 阶段。\n\n### Who to blame in case of bugs?\n\nThe entire team.\n\n另外一个观念纠正一下,就是出现 bug 的时候,责任是谁的?通常我见过的很多人都是这样,就说“这个 bug 跟我没关系,他的模块的 bug”。那 PingCAP 这边的看法不一样,就是一旦出现 bug,这应该是整个 team 的责任,因为你有自己的 code review 机制,至少有两个以上的人会去看它这个代码,然后如果这个还出现问题,那一定不是一个人的问题。\n\n除了刚才说的发现一些 bug,还有一些你很难定义,说这是不是 bug,怎么系统跑的慢,这算不算 bug,怎么对 bug 做界定呢?我们现在的界定方式是用户说了算。虽然我们觉得这不是 bug,这不就慢一点吗,但是用户说了这个东西太慢了,我们不能忍,这就是 bug,你就是该优化的就优化。然后我们团队里面出现过这样的事情,说“我们这个已经跑的很快了,已经够快了”,对不起,用户说慢,用户说慢就得改,你就得去提升。总而言之,标准不能自己定,当然如果你自己去定这个标准,那这个事就变成“我这个很 OK 了,我不需要改了,可以了。”这样是不行的。\n\n### Profiling\n\n+ Profile everything, even on production\n\t- once-in-a-lifetime chance\n+ Bench testing\n\n另外,在 Profile 这个事情上面,我们强调一个,即使是在线上,也需要能做 Profile,其实 Profile 的开销是很小的。然后很有可能是这样的,有一次线上系统特别卡,如果你把那个重启了,你可能再也没有机会复现它了,那么对于这些情况它很可能是一辈子发生一次的,那一次你没有抓住它,你可能再也没有机会抓住它了。当然我们后面会介绍一些方法,可以让这个能复现,但是有一些确实是和业务相关性极强的,那么可能刚好又碰到一个特别的环境才能让它出现,那真的可能是一辈子就那么一次的,你一定要这次抓住它,这次抓不住,你可能永远就抓不住了。因为有些犯罪它一辈子只犯一次,它犯完之后你再也没有机会抓住它了。\n\n### Embed testing to your design\n\n+ Design for testing or Die without good tests\n+ Tests may make your code less beautiful\n\n再说测试和设计的关系。测试是一定要融入到你的设计里面,就是在你设计的时候就一定要想这个东西到底应该怎么去测。如果在设计的时候想不到这个东西应该怎么测,那这个东西就是正确性实际上是没法验证的,这是非常恐怖的一件事情。我们把测试的重要程度看成这样的:你要么就设计好的测试,要么就挂了,就没什么其它的容你选择。就是说在这一块我们把它的重要性放到一个最高的程度。\n\n##### 未完待续...\n\n> 相关阅读: \n[分布式系统测试那些事儿 - 错误注入](https://pingcap.com/zh/blog/distributed-system-test-2); \n> [分布式系统测试那些事儿 - 信心的毁灭与重建](https://pingcap.com/zh/blog/distributed-system-test-3)。","date":"2016-11-01","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"distributed-system-test-1","file":null,"relatedBlogs":[]},{"id":"Blogs_90","title":"Building a Reliable Large-Scale Distributed Database - Principles and Practice","tags":["TiDB","NewSQL","Test"],"category":{"name":"观点洞察"},"summary":"日前,PingCAP Engineering VP 申砾受邀参加 2016 中国开源年会,并发表了《Building a Reliable Large-Scale Distributed Database - Principles and Practice》主题演讲。本文为演讲实录。","body":"大家好,我叫申砾,是 PingCAP Tech Leader,负责 TiDB 技术相关的工作。我曾就职网易有道、360 搜索,主要在做垂直搜索相关的事情,现在主要关注分布式计算/存储领域。过去的一年半时间我在 PingCAP 做分布式关系数据库 TiDB。目前我们的整个项目已经开源了大概一年时间,获得了不少关注。在 Github 上 Star 数量超过 5k,并且 Contributor 数量为 50+,拥有一个活跃的社区,在国内和国际上都有一定的知名度。\n今天主要想和大家分享一下我们在做一款开源的分布式数据库产品过程中得到的一些经验和体会,包括技术上、产品上以及开源社区方面的内容,不会涉及太多技术上的细节。\n\n## 数据库现状\n\n近年来,随着移动互联网、物联网、人工智能等技术的兴起,我们已经进入了一个信息爆炸的大数据时代,需要处理和分析的数据越来越多,这些数据如何保存、如何应用是一个重要的问题。\n\n传统的 SQL 数据库一般通过中间件、分库分表等方案获得 Scale 的能力。但是这些方案仍然很难做到对应用透明且保证数据均匀分布,同时也无法支持一致性的跨节点事务、JOIN 等操作。在进行扩容的时候往往需要人工介入,随着集群规模的增大,维护和扩展的复杂度呈指数级上升。\n\n以 Google 的 BigTable 论文为开端,涌现出了一大批 NoSQL 方案。这些方案致力于解决扩展性,而牺牲一致性。如果采用 NoSQL 方案替换原有关系型数据库,往往要涉及大规模的业务重构,这相当于将数据库层的计算逻辑复杂度转嫁给业务层,同时还要损失掉事务等特性。\n\n以上两种方案都没有完美地解决高可用的问题,跨机房多活、故障恢复、扩容经常都需要繁重的人工介入。\n\n最近几年,人们希望有一种既有 SQL/NoSQL 的优点,又能避免他们的不足的新型数据库,于是提出了 NewSQL 的概念。Google 发布的 Spanner/F1,算是第一个真正在大规模业务上验证过的分布式数据库,向业界证明了 NewSQL 这条道路的正确性。TiDB 作为 Google Spanner/F1 的开源实现,正是业界盼望已久的 NewSQL 开源数据库。\n\n## 什么是 NewSQL\n\n并不是所有号称 NewSQL 的数据库都是 NewSQL。我们认为作为 NewSQL 数据库需要有下面几点特性:\n\n**首先是 Scale。**这点上我想大家都深有体会,不管什么数据解决方案,最基本的要求就是能有足够的能力,保存用户所有的数据。\n\n**第二是事务。**ACID Transaction,这个东西如果业务不需要,就感觉不到;一旦你的业务有这种需求,就能体会到它的重要性了。事实证明这个需求是广泛存在的,Google 的 BigTable 没有提供事务,结果内部很多业务都有需求,于是各个组造了一堆轮子,Jeff Dean 看不下去,出来说他最大的错误就是没有给 BigTable 提供事务。\n\n**第三是 SQL。**SQL 作为一门古老的语言,在现在的技术领域内依然有强大的生命力,基本是流行的各种 NoSQL 上面都会有人来做一套 SQL-on-X。最近刚看到一个 2016 最佳编程语言榜单,SQL 依然能上榜。我想 SQL 在业界的应用还会延续很多很多年。\n\n**第四是 Auto-failover / Self recovery / Survivability。**\n\nSpanner 能够做到任何一个数据中心宕机,底层可以完全的 Auto-Failover,上层的业务甚至是完全无感知的。这个 Failover 的过程是完全不需要人工介入的。国内很多互联网公司也都在做这个,但是还没有那一家能做的特别好,比如光纤被挖断之后,大家发现支付工具无法支付了。除了业务不被中断这一好处之外,Auto-failover 还会极大地降低运维的成本,如 Google 这么牛的公司,在维护一百多个节点的 MySQL Sharding 的数据库的时候,都已经非常痛苦,宁可重新去写一个数据库,也不想去维护这个 database cluster。\n\n为了给业界提供 NewSQL 数据库,我们开发了 TiDB,提供如下特性:\n\n+ 无限水平扩展\n+ 分布式 ACID 事务\n+ 强一致\n+ 高可靠\n+ 提供 SQL 并且支持 MySQL 协议\n\nTiDB 目前是世界上最受欢迎的开源 NewSQL 数据库之一,可能是国人发起和主要维护的最大也是 stars 数最多的开源的数据库项目。\n\n## 我们在开发 TiDB 过程中学到的东西\n\n下面就和大家分享一下我们在开发这个项目过程中学到的一些东西。\n\n### Always believe shit is about to happen\n\n大家写程序的时候,总会做一些错误检查,处理异常情况,但是很多情况可能大家普遍不会想到,比如光纤被挖断、IDC 整个 down 掉,还有前几天的阿里云 IO 问题。这说明即使以这些顶级大厂的技术能力,依然不能保证基础设施不出问题。所以我们会特别强调 Auto-failover 的作用。我们的整个设计始终会考虑容灾。其中最重要的就是如何保存多副本,一份数据写足够多的副本并且使用健壮的副本分布策略,才能保证安全。Spanner 默认使用 5 副本,重要的数据使用 7 副本。\n\n传统的保存副本的方案是 Master-slave 模式。但是这并不是一个完美的方案。如果要在 master 和 slave 之间保持强一致,那么不但要担心效率问题 (速度取决于最慢的那个 slave),还需要考虑各种容错。比如如果写 Slave 失败了,如何处理,是否要回滚 Master?所以依靠 master-slave 实现可靠复制对性能和复杂度都有比较大的挑战。而如果不要做到强一致,那么就面临 master 挂掉之后,slave 和 master 之间数据还没有同步完成,造成丢数据的问题。\n\nMulti-Paxos / Raft 是一个更好的选择,采用这种方案,多数节点写成功即可成功,在保证可靠性的同时,尽可能的提升了复制效率。\n\n### Don't rely on humans\n\n面对容灾,我们需要尽可能的将工作自动化,因为人会累,会犯错,但是机器不会。我们希望能提供一套自动的方案,来支撑业务的需求,抵御各种异常情况。比如做 Scale 的时候,只需要点击几下即可增加新节点,然后系统自动将部分数据迁移到新节点。发生灾难时,系统能够自动下线 down 掉的节点,并将数据迁移到其他的节点。\n\n### Talk is cheap, show me the tests\n\n其实做数据库这么长时间,我认为最难的事情是测试。首先我们做的是一个支持 SQL 的数据库,想一下 SQL 的各种语法、操作符、函数,如何进行测试?同时我们是一个分布式的数据库,做测试就更难了。一直困扰我们的问题就是如何对我们的产品进行测试,比如一个 PR 上来后,如何检查逻辑是否正确,是否影响性能,是否支持容错?我们不断的探索和实践,有了一些自己的方案:\n\n**首先是单元测试。**我们的 Code Review 规范明确的写了,如果改了逻辑、bug,没有单测不予 Review。\n\n**第二是集成测试。**我们为了验证逻辑正确性,引入了大量的集成测试,其中一大块是 MySQL 源代码中的 test,因为我们支持 MySQL 语法和协议,所以可以直接拿过来用,省掉了我们大量的时间,很难想象没有这些测试,代码会变成什么样子。\n\n**除此之外还有大量的 ORM 框架自带的 Test,我们也会运行。**我们精选出一批集成测试 case,每次提交 PR 之前必需要跑过。当 PR merge 后,我们内部的 CI 会自动运行,跑更多更耗时的测试。\n\n**为了测试分布式场景下的系统容错能力,我们也引入了一些工具,**比如 Jepson/Namazu,可以进行错误注入。很多知名的分布式系统都被这些工具找出来过 bug,比如 etcd/zookeeper。\n\n### \"All problems in computer science can be solved by another level of indirection\"\n\n在一年半的时间里,TiDB 从零开始,成长为一个庞大的项目。首先我们是实现了一个内存的数据库,在一个简单的 memkv 基础上,做了一个小的 SQL 层,然后慢慢的替换 memkv 为持久化存储。我们将 SQL 和存储引擎之间的接口进行了抽象。后续的分布式存储引擎,也依赖于这个接口。这样就屏蔽了下层存储引擎的差别。无论是 TiDB 还是 TiKV 我们在开发过程中始终遵循良好的分层+抽象的原则,有效的降低了开发的复杂度和耦合度,另外对测试也有很大的帮助,我们可以更容易的 mock 某一层,做更精细的控制。抽象是对抗大系统复杂性的有效武器。\n\n### Don't try to teach your user, just follow them\n\n想要做一款成功的数据库产品,就需要让用户觉得方便好用。在这一点上,中间件或者 Sharding 方案往往需要侵入用户代码、或者是修改用户逻辑,在做扩容的时候,也要消耗用户大量的精力。我们要求 TiDB 能够尽可能的减少用户工作,可以一行代码都不用修改就能从单机 MySQL 迁移到 TiDB 上。并且要尽可能的和行业标准贴近,减少用户的工作量。\n\n### Make it right, and then make it fast\n\n我们大概用了一个月的时间,做了一个可以用的数据库,在接下来的工作中,我们准备了整套测试框架,然后不断的完善功能,保证每次都是对的,与此同时,我们还会调整架构,最终做出一个还算不错的数据库,但是初期性能并不好,比如我们和第一家客户去聊,然后测试一下,发现一个简单的 SQL 跑了 600s,但是我们并不气馁,经过半个月的优化,我们将这个 SQL 优化到了 60ms。之所以能这么快优化到这么好,是因为我们有良好的架构,清晰的分层,完善的测试。所以这里并不是说我们不需要做优化,而是不要过早优化。这种大型系统,应该在早期关注架构的正确性以及弹性,为后面的优化留下足够的操作空间,保证每个模块可以单独的去优化。\n\n### Embrace the community\n\nTiDB 是一个开源的数据库,我们从第一天起就坚定的走拥抱社区的路线,希望能够成为整个大数据生态的一部分。我们通过开源社区获得了大量高质量的第三方库,提高开发进度。与此同时,我们也向开源社区贡献了很多代码,比如 Etcd、Rocksdb、go-hbase、go-mysql 等。客户在进行数据库技术选型时,如果使用一些闭源的产品,那么就很容易被绑死在某一个厂商,或者是某一个云上。而使用 TiDB 不会有这方面的困扰,无论是迁移过来还是从 TiDB 迁移到其他的产品,都很容易,也不会被某个特定的云厂商绑死。\n\n**如果一个公司符合如下任何一种情况,TiDB 或许是一个很好的解决方案:**\n\n1. 项目选型阶段。为了快速开发,简化生产力和运维,使用 TiDB,再也不用对数据库进行分库分表或者选用数据库中间件,TiDB 帮你搞定所有底层的跨节点的分布式事务、聚合查询难点,开发人员专注于业务设计,维护人员运维非常容易。\n\n2. 目前使用 MySQL 且数据量很大,但是查询速度特别慢。TiDB 是 MySQL 兼容的,且在大数据量性能大大优于 MySQL。\n\n3. 有跨数据中心数据强一致性需求或者自动运维需求。\n\n\n## Q&A\n\n### 提问:TiDB 是否和其他的数据库(比如 MySQL、Oracle) 进行过性能对比?\n\n申砾:我们内部用 Sysbench 做过对比,单套 TiDB 在写入能力上超过 MySQL,读取方面比 MySQL 略低。从整体上看,延迟会大于 MySQL,但是吞吐可以远高于 MySQL。我们正在不断提高性能,不久之后会对外发布性能测试结果。\n\n### 提问:TiDB 是如何支持跨机房容灾?\n\n申砾:TiDB 使用 Raft 做复制,PD 是整个集群的管理节点。PD 会自动根据存储节点的 IDC 位置指定副本存放策略,保证同一个 Raft Group 中的副本分布在多个机房。\n\n### 提问:TiDB 是否会出商业版本?\n\n申砾:是的,PingCAP 会提供 TiDB 的商业版。(含监控、部署、数据处理、调度及支持服务等)","date":"2016-10-21","author":"申砾","fillInMethod":"writeDirectly","customUrl":"talk-principles-practice","file":null,"relatedBlogs":[]},{"id":"Blogs_252","title":"How do we build TiDB","tags":["架构","Raft","MVCC","分布式事务","PD","Go"],"category":{"name":"观点洞察"},"summary":"首先我们聊聊 Database 的历史,在已经有这么多种数据库的背景下我们为什么要创建另外一个数据库;以及说一下现在方案遇到的困境,说一下 Google Spanner 和 F1,TiKV 和 TiDB,说一下架构的事情,在这里我们会重点聊一下 TiKV。因为我们产品的很多特性是 TiKV 提供的,比如说跨数据中心的复制,Transaction,auto-scale...","body":"首先我们聊聊 Database 的历史,在已经有这么多种数据库的背景下我们为什么要创建另外一个数据库;以及说一下现在方案遇到的困境,说一下 Google Spanner 和 F1,TiKV 和 TiDB,说一下架构的事情,在这里我们会重点聊一下 TiKV。因为我们产品的很多特性是 TiKV 提供的,比如说跨数据中心的复制,Transaction,auto-scale。\n\n再聊一下为什么 TiKV 用 Raft 能实现所有这些重要的特性,以及 scale,MVCC 和事务模型。东西非常多,我今天不太可能把里面的技术细节都描述得特别细,因为几乎每一个话题都可以找到一篇或者是多篇论文。但讲完之后我还在这边,所以详细的技术问题大家可以单独来找我聊。\n\n后面再说一下我们现在遇到的窘境,就是大家常规遇到的分布式方案有哪些问题,比如 MySQL Sharding。我们创建了无数 MySQL Proxy,比如官方的 MySQL proxy,Youtube 的 Vitess,淘宝的 Cobar、TDDL,以及基于 Cobar 的 MyCAT,金山的 Kingshard,360 的 Atlas,京东的 JProxy,我在豌豆荚也写了一个。可以说,随便一个大公司都会造一个MySQL Sharding的方案。\n\n## 为什么我们要创建另外一个数据库?\n\n昨天晚上我还跟一个同学聊到,基于 MySQL 的方案它的天花板在哪里,它的天花板特别明显。有一个思路是能不能通过 MySQL 的 server 把 InnoDB 变成一个分布式数据库,听起来这个方案很完美,但是很快就会遇到天花板。因为 MySQL 生成的执行计划是个单机的,它认为整个计划的 cost 也是单机的,我读取一行和读取下一行之间的开销是很小的,比如迭代 next row 可以立刻拿到下一行。实际上在一个分布式系统里面,这是不一定的。\n\n\n另外,你把数据都拿回来计算这个太慢了,很多时候我们需要把我们的 expression 或者计算过程等等运算推下去,向上返回一个最终的计算结果,这个一定要用分布式的 plan,前面控制执行计划的节点,它必须要理解下面是分布式的东西,才能生成最好的 plan,这样才能实现最高的执行效率。\n\n比如说你做一个 sum,你是一条条拿回来加,还是让一堆机器一起算,最后给我一个结果。 例如我有 100 亿条数据分布在 10 台机器上,并行在这 10 台 机器我可能只拿到 10 个结果,如果把所有的数据每一条都拿回来,这就太慢了,完全丧失了分布式的价值。聊到 MySQL 想实现分布式,另外一个实现分布式的方案是什么,就是 Proxy。但是 Proxy 本身的天花板在那里,就是它不支持分布式的 transaction,它不支持跨节点的 join,它无法理解复杂的 plan,一个复杂的 plan 打到 Proxy 上面,Proxy 就傻了,我到底应该往哪一个节点上转发呢,如果我涉及到 subquery sql 怎么办?所以这个天花板是瞬间会到,在传统模型下面的修改,很快会达不到我们的要求。\n\n另外一个很重要的是,MySQL 支持的复制方式是半同步或者是异步,但是半同步可以降级成异步,也就是说任何时候数据出了问题你不敢切换,因为有可能是异步复制,有一部分数据还没有同步过来,这时候切换数据就不一致了。前一阵子出现过某公司突然不能支付了这种事件,今年有很多这种类似的 case,所以微博上大家都在说“说好的异地多活呢?”……\n\n为什么传统的方案在这上面解决起来特别的困难,天花板马上到了,基本上不可能解决这个问题。另外是多数据中心的复制和数据中心的容灾,MySQL 在这上面是做不好的。\n\n\n\n数据库演进
\n\n在前面三十年基本上是关系数据库的时代,那个时代创建了很多伟大的公司,比如说 IBM、Oracle、微软也有自己的数据库,早期还有一个公司叫 Sybase,有一部分特别老的程序员同学在当年的教程里面还可以找到这些东西,但是现在基本上看不到了。\n\n另外是 NoSQL。NoSQL 也是一度非常火,像 Cassandra,MongoDB 等等,这些都属于在互联网快速发展的时候创建这些能够 scale 的方案,但 Redis scale 出来比较晚,所以很多时候大家把 Redis 当成一个 Cache,现在慢慢大家把它当成存储不那么重要的数据的数据库。因为它有了 scale 支持以后,大家会把更多的数据放在里面。\n\n然后到了 2015,严格来讲是到 2014 年到 2015 年之间,Raft 论文发表以后,真正的 NewSQL 的理论基础终于完成了。我觉得 NewSQL 这个理论基础,最重要的划时代的几篇论文,一个是谷歌的 Spanner,是在 2013 年初发布的,再就是 Raft 是在 2014 年上半年发布的。这几篇相当于打下了分布式数据库 NewSQL 的理论基础,这个模型是非常重要的,如果没有模型在上面是堆不起来东西的。说到现在,大家可能对于模型还是可以理解的,但是对于它的实现难度很难想象。\n\n前面我大概提到了我们为什么需要另外一个数据库,说到 Scalability 数据的伸缩,然后我们讲到需要 SQL,比如你给我一个纯粹的 key-value 系统的 API,比如我要查找年龄在 10 岁到 20 岁之间的 email 要满足一个什么要求的。如果只有 KV 的 API 这是会写死人的,要写很多代码,但是实际上用 SQL 写一句话就可以了,而且 SQL 的优化器对整个数据的分布是知道的,它可以很快理解你这个 SQL,然后会得到一个最优的 plan,他得到这个最优的 plan 基本上等价于一个真正理解 KV 每一步操作的人写出来的程序。通常情况下,SQL 的优化器是为了更加了解或者做出更好的选择。\n\n另外一个就是 ACID 的事务,这是传统数据库必须要提供的基础。以前你不提供 ACID 就不能叫数据库,但是近些年大家写一个内存的 map 也可以叫自己是数据库。大家写一个 append-only 文件,我们也可以叫只读数据库,数据库的概念比以前极大的泛化了。\n\n另外就是高可用和自动恢复,他们的概念是什么呢?有些人会有一些误解,因为今天还有朋友在现场问到,出了故障,比如说一个机房挂掉以后我应该怎么做切换,怎么操作。这个实际上相当于还是上一代的概念,还需要人去干预,这种不算是高可用。\n\n未来的高可用一定是系统出了问题马上可以自动恢复,马上可以变成可用。比如说一个机房挂掉了,十秒钟不能支付,十秒钟之后系统自动恢复了变得可以支付,即使这个数据中心再也不起来我整个系统仍然是可以支付的。Auto-Failover 的重要性就在这里。大家不希望在睡觉的时候被一个报警给拉起来,我相信大家以后具备这样一个能力,5 分钟以内的报警不用理会,挂掉一个机房,又挂掉一个机房,这种连续报警才会理。我们内部开玩笑说,希望大家都能睡个好觉,很重要的事情就是这个。\n\n说完应用层的事情,现在很有很多业务,在应用层自己去分片,比如说我按照 user ID 在代码里面分片,还有一部分是更高级一点我会用到一致性哈希。问题在于它的复杂度,到一定程度之后我自动的分库,自动的分表,我觉得下一代数据库是不需要理解这些东西的,不需要了解什么叫做分库,不需要了解什么叫做分表,因为系统是全部自动搞定的。同时复杂度,如果一个应用不支持事务,那么在应用层去做,通常的做法是引入一个外部队列,引入大量的程序机制和状态转换,A 状态的时候允许转换到 B 状态,B 状态允许转换到 C 状态。\n\n举一个简单的例子,比如说在京东上买东西,先下订单,支付状态之后这个商品才能出库,如果不是支付状态一定不能出库,每一步都有严格的流程。\n\n## Google Spanner / F1\n\n说一下 Google 的 Spanner 和 F1,这是我非常喜欢的论文,也是我最近几年看过很多遍的论文。Google Spanner 已经强大到什么程度呢?Google Spanner 是全球分布的数据库,在国内目前普遍做法叫做同城两地三中心,它们的差别是什么呢?以 Google 的数据来讲,谷歌比较高的级别是他们有 7 个副本,通常是美国保存 3 个副本,再在另外 2 个国家可以保存 2 个副本,这样的好处是万一美国两个数据中心出了问题,那整个系统还能继续可用,这个概念就是比如美国 3 个副本全挂了,整个数据都还在,这个数据安全级别比很多国家的安全级别还要高,这是 Google 目前做到的,这是全球分布的好处。\n\n现在国内主流的做法是两地三中心,但现在基本上都不能自动切换。大家可以看到很多号称实现了两地三中心或者异地多活,但是一出现问题都说不好意思这段时间我不能提供服务了。大家无数次的见到这种 case,我就不列举了。\n\nSpanner 现在也提供一部分 SQL 特性。在以前,大部分 SQL 特性是在 F1 里面提供的,现在 Spanner 也在逐步丰富它的功能,Google 是全球第一个做到这个规模或者是做到这个级别的数据库。事务支持里面 Google 有点黑科技(其实也没有那么黑),就是它有 GPS 时钟和原子钟。大家知道在分布式系统里面,比如说数千台机器,两个事务启动先后顺序,这个顺序怎么界定(事务外部一致性)。这个时候 Google 内部使用了 GPS 时钟和原子钟,正常情况下它会使用一个 GPS 时钟的一个集群,就是说我拿的一个时间戳,并不是从一个 GPS 上来拿的时间戳,因为大家知道所有的硬件都会有误差。如果这时候我从一个上拿到的 GPS 本身有点问题,那么你拿到的这个时钟是不精确的。而 Google 它实际上是在一批 GPS 时钟上去拿了能够满足 majority 的精度,再用时间的算法,得到一个比较精确的时间。同时大家知道 GPS 也不太安全,因为它是美国军方的,对于 Google 来讲要实现比国家安全级别更高的数据库,而 GPS 是可能受到干扰的,因为 GPS 信号是可以调整的,这在军事用途上面很典型的,大家知道导弹的制导需要依赖 GPS,如果调整了 GPS 精度,那么导弹精度就废了。所以他们还用原子钟去校正 GPS,如果 GPS 突然跳跃了,原子钟上是可以检测到 GPS 跳跃的,这部分相对有一点黑科技,但是从原理上来讲还是比较简单,比较好理解的。\n\n最开始它 Spanner 最大的用户就是 Google 的 Adwords,这是 Google 最赚钱的业务,Google 就是靠广告生存的,我们一直觉得 Google 是科技公司,但是他的钱是从广告那来的,所以一定程度来讲 Google 是一个广告公司。Google 内部的方向先有了 Big table ,然后有了 MegaStore ,MegaStore 的下一代是 Spanner ,F1 是在 Spanner 上面构建的。\n\n## TiDB and TiKV\n\nTiKV 和 TiDB 基本上对应 Google Spanner 和 Google F1,用 Open Source 方式重建。目前这两个项目都开放在 GitHub 上面,两个项目都比较火爆,TiDB 是更早一点开源的, 目前 TiDB 在 GitHub 上 有 4300 多个 Star,每天都在增长。\n\n另外,对于现在的社会来讲,我们觉得 Infrastructure 领域闭源的东西是没有任何生存机会的。没有任何一家公司,愿意把自己的身家性命压在一个闭源的项目上。举一个很典型的例子,在美国有一个数据库叫 FoundationDB,去年被苹果收购了。 FoundationDB 之前和用户签的合约都是一年的合约。比如说,我给你服务周期是一年,现在我被另外一个公司收购了,我今年服务到期之后,我是满足合约的。但是其他公司再也不能找它服务了,因为它现在不叫 FoundationDB 了,它叫 Apple了,你不能找 Apple 给你提供一个 enterprise service。\n\n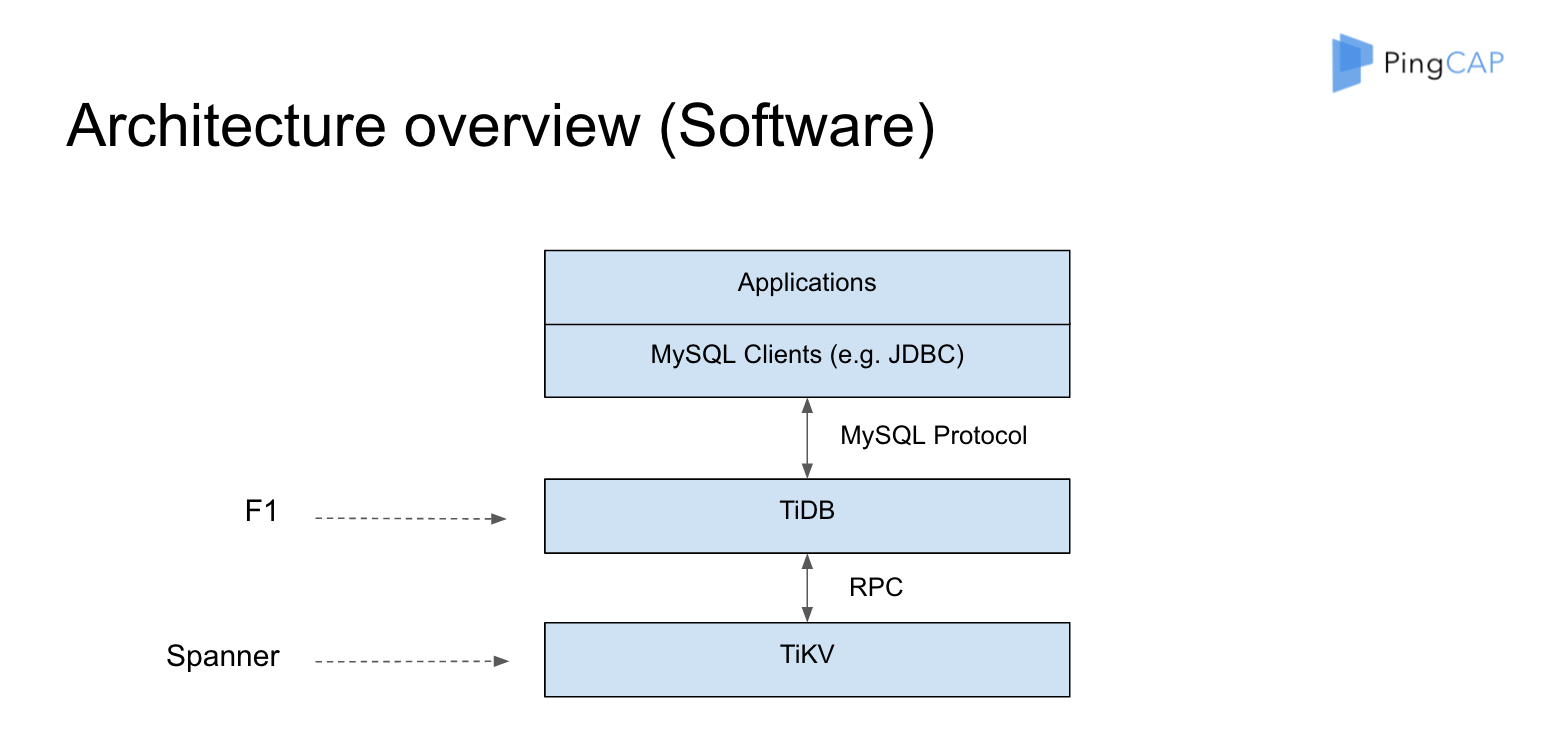\n\nArchitecture Overview Software
\n\nTiDB 和 TiKV 为什么是两个项目,因为它和 Google 的内部架构对比差不多是这样的:TiKV 对应的是 Spanner,TiDB 对应的是 F1 。F1 里面更强调上层的分布式的 SQL 层到底怎么做,分布式的 Plan 应该怎么做,分布式的 Plan 应该怎么去做优化。同时 TiDB 有一点做的比较好的是,它兼容了 MySQL 协议,当你出现了一个新型的数据库的时候,用户使用它是有成本的。大家都知道作为开发很讨厌的一个事情就是,我要每个语言都写一个 Driver,比如说你要支持 C++,你要支持 Java,你要支持 Go 等等,这个太累了,而且用户还得改他的程序,所以我们选择了一个更加好的东西兼容 MySQL 协议,让用户可以不用改。一会我会用一个视频来演示一下,为什么一行代码不改就可以用,用户就能体会到 TiDB 带来的所有的好处。\n\n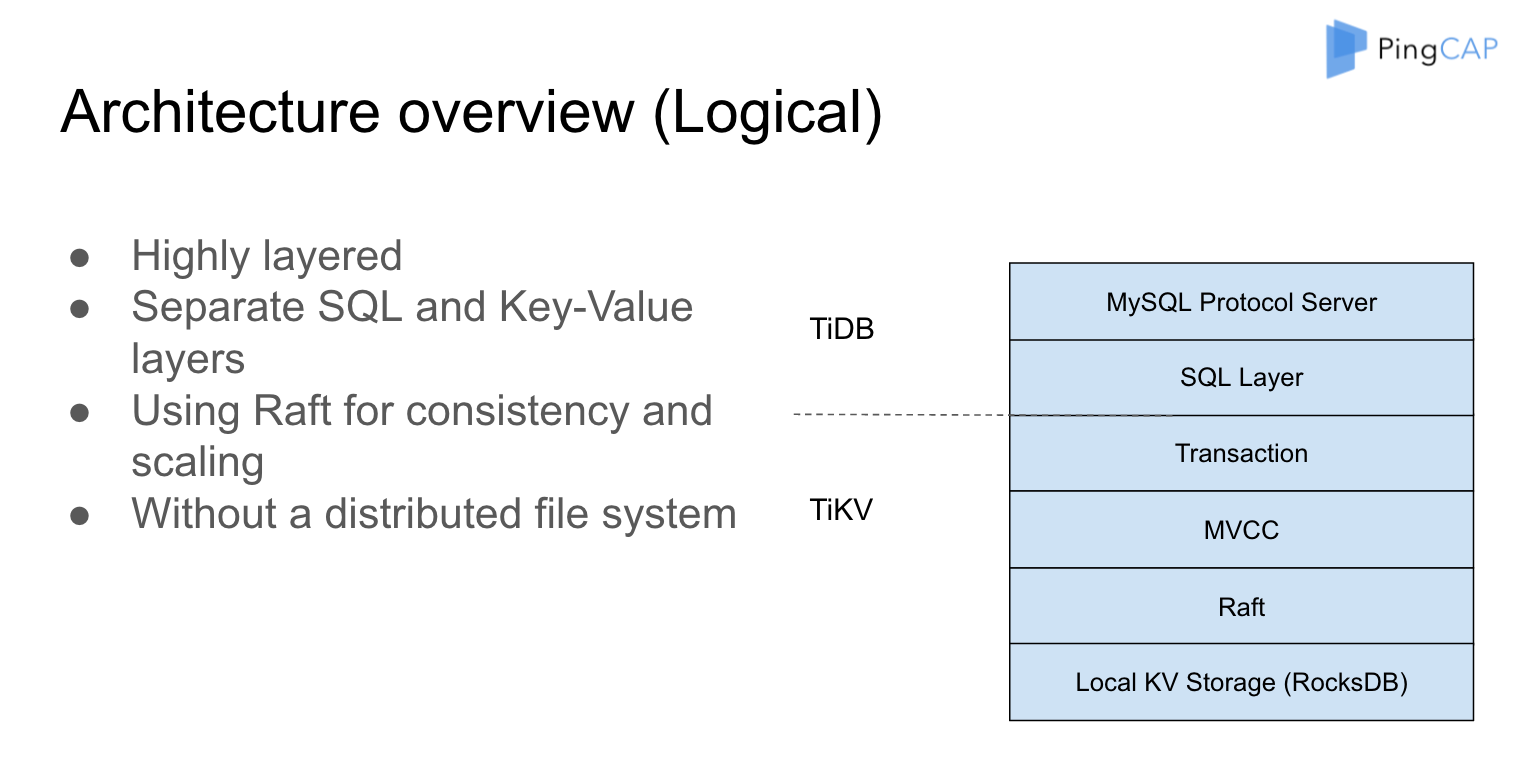\n\nArchitecture Overview Logical
\n\n这个图实际上是整个协议栈或者是整个软件栈的实现。大家可以看到整个系统是高度分层的,从最底下开始是 RocksDB ,然后再上面用 Raft 构建一层可以被复制的 RocksDB,在这一层的时候它还没有 Transaction,但是整个系统现在的状态是所有写入的数据一定要保证它复制到了足够多的副本。也就是说只要我写进来的数据一定有足够多的副本去 cover 它,这样才比较安全,在一个比较安全的 Key-value store 上面, 再去构建它的多版本,再去构建它的分布式事务,然后在分布式事务构建完成之后,就可以轻松的加上 SQL 层,再轻松的加上 MySQL 协议的支持。然后,这两天我比较好奇,自己写了 MongoDB 协议的支持,然后我们可以用 MongoDB 的客户端来玩,就是说协议这一层是高度可插拔的。TiDB 上可以在上面构建一个 MongoDB 的协议,相当于这个是构建一个 SQL 的协议,可以构建一个 NoSQL 的协议。这一点主要是用来验证 TiKV 在模型上面的支持能力。\n\n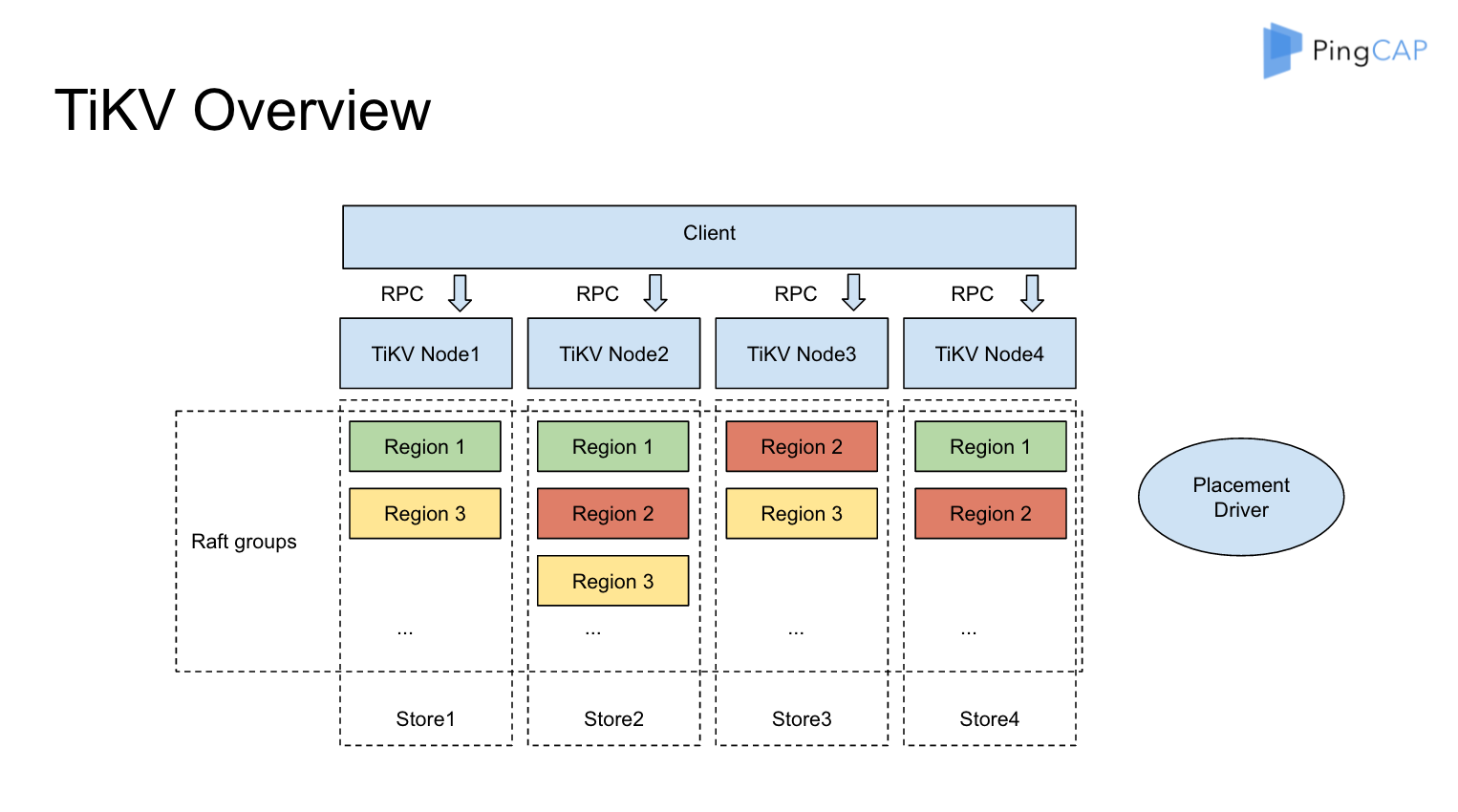\n\nTiKV 架构图
\n\n这是整个 TiKV 的架构图,从这个看来,整个集群里面有很多 Node,比如这里画了四个 Node,分别对应了四个机器。每一个 Node 上可以有多个 Store,每个 Store 里面又会有很多小的 Region,就是说一小片数据,就是一个 Region 。从全局来看所有的数据被划分成很多小片,每个小片默认配置是 64M,它已经足够小,可以很轻松的从一个节点移到另外一个节点,Region 1 有三个副本,它分别在 Node1、Node 2 和 Node4 上面, 类似的Region 2,Region 3 也是有三个副本。每个 Region 的所有副本组成一个 Raft Group, 整个系统可以看到很多这样的 Raft groups。\n\nRaft 细节我不展开了,大家有兴趣可以找我私聊或者看一下相应的资料。\n\n因为整个系统里面我们可以看到上一张图里面有很多 Raft group 给我们,不同 Raft group 之间的通讯都是有开销的。所以我们有一个类似于 MySQL 的 group commit 机制 ,你发消息的时候实际上可以 share 同一个 connection , 然后 pipeline + batch 发送, 很大程度上可以省掉大量 syscall 的开销。\n\n另外,其实在一定程度上后面我们在支持压缩的时候,也有非常大的帮助,就是可以减少数据的传输。对于整个系统而言,可能有数百万的 Region,它的大小可以调整,比如说 64M、128M、256M,这个实际上依赖于整个系统里面当前的状况。\n\n比如说我们曾经在有一个用户的机房里面做过测试,这个测试有一个香港机房和新加坡的机房。结果我们在做复制的时候,新加坡的机房大于 256M 就复制不过去,因为机房很不稳定,必须要保证数据切的足够小,这样才能复制过去。\n\n如果一个 Region 太大以后我们会自动做 SPLIT,这是非常好玩的过程,有点像细胞的分裂。\n\n然后 TiKV 的 Raft 实现,是从 etcd 里面 port 过来的,为什么要从 etcd 里面 port 过来呢?首先 TiKV 的 Raft 实现是用 Rust 写的。作为第一个做到生产级别的 Raft 实现,所以我们从 etcd 里面把它用 Go 语言写的 port 到这边。\n\n\n\nTiKV 在 Raft 官网里的状态
\n\n这个是 Raft 官网上面列出来的 TiKV 在里面的状态,大家可以看到 TiKV 把所有 Raft 的 feature 都实现了。 比如说 Leader Election、Membership Changes,这个是非常重要的,整个系统的 scale 过程高度依赖 Membership Changes,后面我用一个图来讲这个过程。后面这个是 Log Compaction,这个用户不太关心。\n\n\n\n细胞分裂图
\n\n这是很典型的细胞分裂的图,实际上 Region 的分裂过程和这个是类似的。\n\n我们看一下扩容是怎么做的。\n\n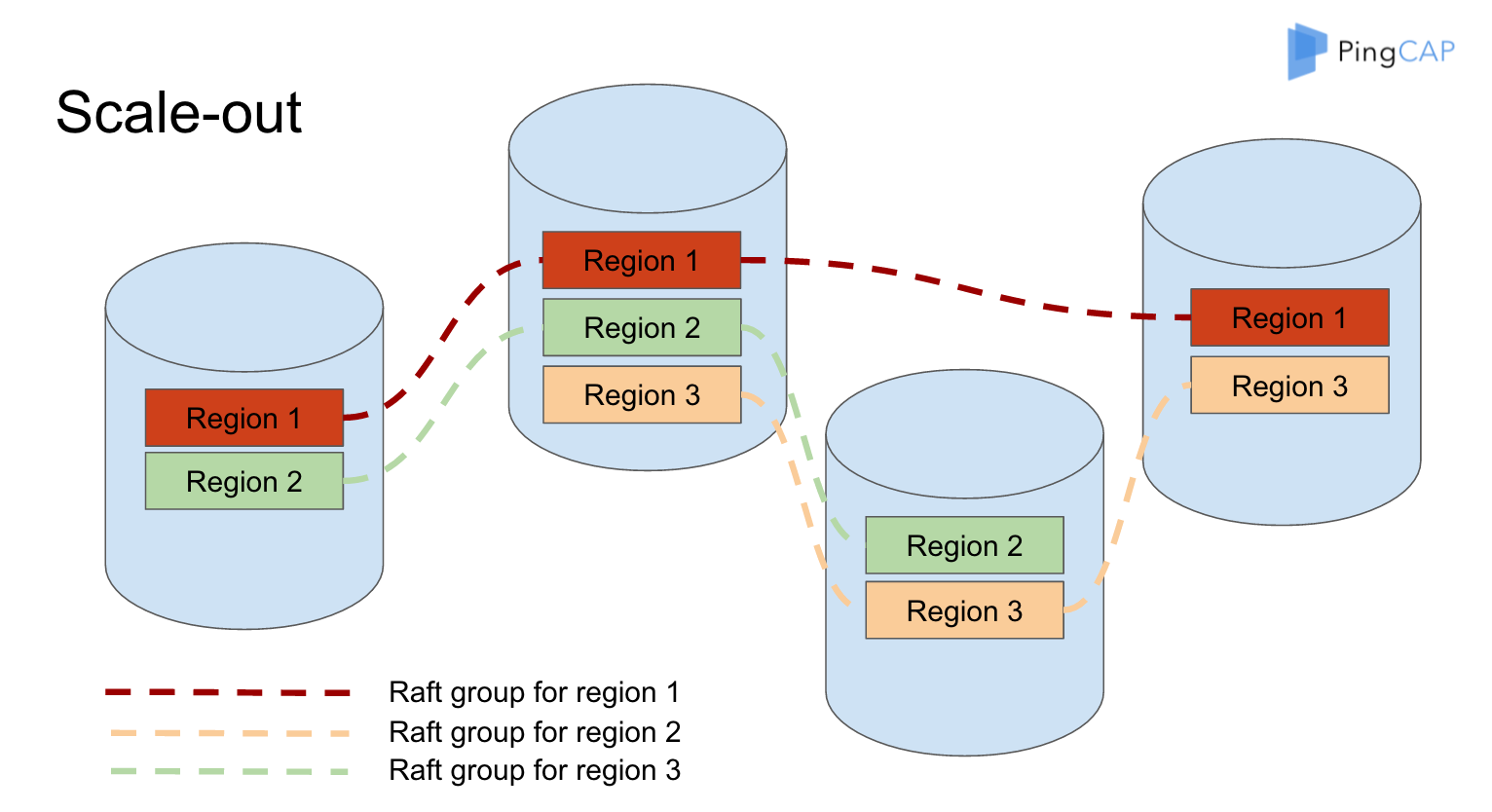\n\nScale out
\n\n比如说以现在的系统假设,我们刚开始说只有三个节点,有 Region1 分别是在 1 、2、4,我用虚线连接起来代表它是 一个 Raft group ,大家可以看到整个系统里面有三个 Raft group,在每一个 Node 上面数据的分布是比较均匀的,在这个假设每一个 Region 是 64M ,相当于只有一个 Node 上面负载比其他的稍微大一点点。\n\n这是一个在线的视频。默认的时候,我们都是推荐 3 个副本或者 5 个副本的配置。Raft 本身有一个特点,如果一个 leader down 掉之后,其它的节点会选一个新的 leader,那么这个新的 leader 会把它还没有 commit 但已经 reply 过去的 log 做一个 commit ,然后会再做 apply,这个有点偏 Raft 协议,细节我不讲了。\n\n复制数据的小的 Region,它实际上是跨多个数据中心做的复制。这里面最重要的一点是永远不丢失数据,无论如何我保证我的复制一定是复制到 majority,任何时候我只要对外提供服务,允许外面写入数据一定要复制到 majority。很重要的一点就是恢复的过程一定要是自动化的,我前面已经强调过,如果不能自动化恢复,那么中间的宕机时间或者对外不可服务的时间,便不是由整个系统决定的,这是相对回到了几十年前的状态。\n\n## MVCC\n\nMVCC 我稍微仔细讲一下这一块。MVCC 的好处,它很好支持 Lock-free 的 snapshot read ,一会儿我有一个图会展示 MVCC 是怎么做的。isolation level 就不讲了,MySQL 里面的级别是可以调的,我们的 TiKV 有 SI,还有 SI+lock,默认是支持 SI 的这种隔离级别,然后你写一个 select for update 语句,这个会自动的调整到 SI 加上 lock 这个隔离级别。这个隔离级别基本上和 SSI 是一致的。还有一个就是 GC 的问题,如果你的系统里面的数据产生了很多版本,你需要把这个比较老的数据给 GC 掉,比如说正常情况下我们是不删除数据的, 你写入一行,然后再写入一行,不断去 update 同一行的时候,每一次 update 会产生新的版本,新的版本就会在系统里存在,所以我们需要一个 GC 的模块把比较老的数据给 GC 掉,实际上这个 GC 不是 Go 里面的GC,不是 Java 的 GC,而是数据的 GC。\n\n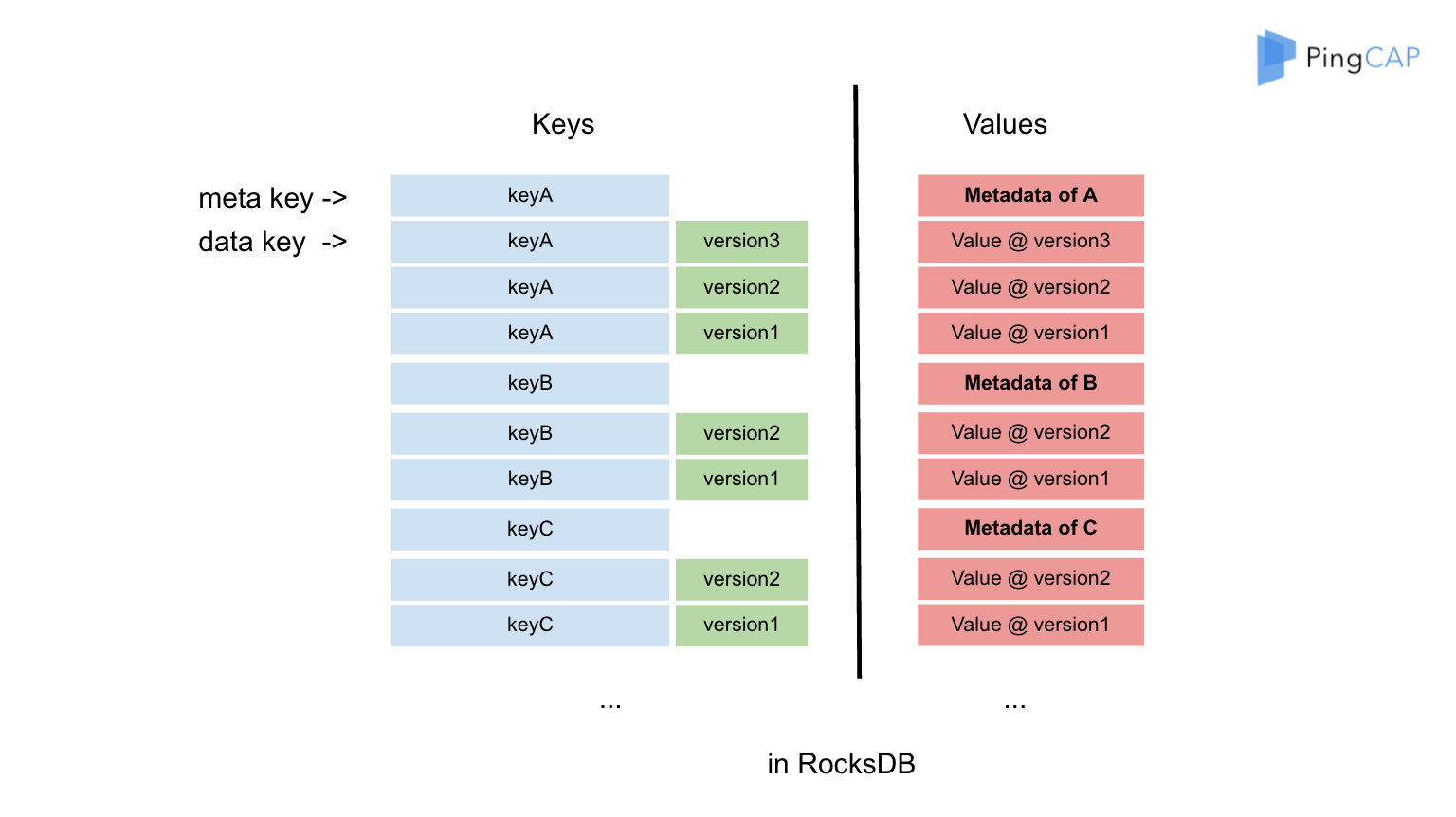\n\n数据版本
\n\n这是一个数据版本,大家可以看到我们的数据分成两块,一个是 meta,一个是 data。meta 相对于描述我的数据当前有多少个版本。大家可以看到绿色的部分,比如说我们的 meta key 是 A,keyA 有三个版本,是 A1、A2、A3,我们把 key 自己和 version 拼到一起。那我们用 A1、A2、A3 分别描述 A 的三个版本,那么就是 version 1/2/3。meta 里面描述,就是我的整个 key 相对应哪个版本,我想找到那个版本。比如说我现在要读取 key A 的版本 10,但显然现在版本 10 是没有的,那么小于版本 10 最大的版本是 3,所以这时我就能读取到 3,这是它的隔离级别决定的。关于 data,我刚才已经讲过了。\n\n## 分布式事务模型\n\n接下来是分布式事务模型,其实是基于 Google Percolator,这是 Google 在 2006 发表的一篇论文,是 Google 在做内部增量处理的时候发现了这个方法,本质上还是二阶段提交的。这使用的是一个乐观锁,比如说我提供一个 transaction ,我去改一个东西,改的时候是发布在本地的,并没有马上 commit 到数据存储那一端,这个模型就是说,我修改的东西我马上去 Lock 住,这个基本就是一个悲观锁。但如果到最后一刻我才提交出去,那么锁住的这一小段的时间,这个时候实现的是乐观锁。乐观锁的好处就是当你冲突很小的时候可以得到非常好的性能,因为冲突特别小,所以我本地修改通常都是有效的,所以我不需要去 Lock ,不需要去 roll back 。本质上分布式事务就是 2PC 或者是 2+xPC,基本上没有 1PC,除非你在别人的级别上做弱化。比如说我允许你读到当前最新的版本,也允许你读到前面的版本,书里面把这个叫做幻读。如果你调到这个程度是比较容易做 1PC 的,这个实际上还是依赖用户设定的隔离级别的,如果用户需要更高的隔离级别,这个 1PC 就不太好做了。\n\n这是一个路由,正常来讲,大家可能会好奇一个 SQL 语句怎么最后会落到存储层,然后能很好的运行,最后怎么能映射到 KV 上面,又怎么能路由到正确的节点,因为整个系统可能有上千个节点,你怎么能正确路由到那一个的节点。我们在 TiDB 有一个 TiKV driver , 另外 TiKV 对外使用的是 Google Protocol Buffer 来作为通讯的编码格式。\n\n## Placement Driver\n\n来说一下 Placement Driver 。Placement Driver 是什么呢?整个系统里面有一个节点,它会时刻知道现在整个系统的状态。比如说每个机器的负载,每个机器的容量,是否有新加的机器,新加机器的容量到底是怎么样的,是不是可以把一部分数据挪过去,是不是也是一样下线, 如果一个节点在十分钟之内无法被其他节点探测到,我认为它已经挂了,不管它实际上是不是真的挂了,但是我也认为它挂了。因为这个时候是有风险的,如果这个机器万一真的挂了,意味着你现在机器的副本数只有两个,有一部分数据的副本数只有两个。那么现在你必须马上要在系统里面重新选一台机器出来,它上面有足够的空间,让我现在只有两个副本的数据重新再做一份新的复制,系统始终维持在三个副本。整个系统里面如果机器挂掉了,副本数少了,这个时候应该会被自动发现,马上补充新的副本,这样会维持整个系统的副本数。这是很重要的 ,为了避免数据丢失,必须维持足够的副本数,因为副本数每少一个,你的风险就会再增加。这就是 Placement Driver 做的事情。\n\n同时,Placement Driver 还会根据性能负载,不断去 move 这个 data 。比如说你这边负载已经很高了,一个磁盘假设有 100G,现在已经用了 80G,另外一个机器上也是 100G,但是他只用了 20G,所以这上面还可以有几十 G 的数据,比如 40G 的数据,你可以 move 过去,这样可以保证系统有很好的负载,不会出现一个磁盘巨忙无比,数据已经多的装不下了,另外一个上面还没有东西,这是 Placement Driver 要做的东西。\n\nRaft 协议还提供一个很高级的特性叫 leader transfer。leader transfer 就是说在我不移动数据的时候,我把我的 leadership 给你,相当于从这个角度来讲,我把流量分给你,因为我是 leader,所以数据会到我这来,但我现在把 leader 给你,我让你来当 leader,原来打给我的请求会被打给你,这样我的负载就降下来。这就可以很好的动态调整整个系统的负载,同时又不搬移数据。不搬移数据的好处就是,不会形成一个抖动。\n\n## MySQL Sharding\n\nMySQL Sharding 我前面已经提到了它的各种天花板,MySQL Sharding 的方案很典型的就是解决基本问题以后,业务稍微复杂一点,你在 sharding 这一层根本搞不定。它永远需要一个 sharding key,你必须要告诉我的 proxy,我的数据要到哪里找,对用户来说是极不友好的,比如我现在是一个单机的,现在我要切入到一个分布式的环境,这时我必须要改我的代码,我必须要知道我这个 key ,我的 row 应该往哪里 Sharding。如果是用 ORM ,这个基本上就没法做这个事情了。有很多 ORM 它本身假设我后面只有一个 MySQL。但 TiDB 就可以很好的支持,因为我所有的角色都是对的,我不需要关注 Sharding、分库、分表这类的事情。\n\n这里面有一个很重要的问题没有提,我怎么做 DDL。如果这个表非常大的话,比如说我们有一百亿吧,横跨了四台机器,这个时候你要给它做一个新的 Index,就是我要添加一个新的索引,这个时候你必须要不影响任何现有的业务,实际上这是多阶段提交的算法,这个是 Google 和 F1 一起发出来那篇论文。\n\n简单来讲是这样的,先把状态标记成 delete only ,delete only 是什么意思呢?因为在分布式系统里面,所有的系统对于 schema 的视野不是一致的,比如说我现在改了一个值,有一部分人发现这个值被改了,但是还有一部分人还没有开始访问这个,所以根本不知道它被改了。然后在一个分布系统里,你也不可能实时通知到所有人在同一时刻发现它改变了。比如说从有索引到没有索引,你不能一步切过去,因为有的人认为它有索引,所以他给它建了一个索引,但是另外一个机器他认为它没有索引,所以他就把数据给删了,索引就留在里面了。这样遇到一个问题,我通过索引找的时候告诉我有, 实际数据却没有了,这个时候一致性出了问题。比如说我 count 一个 email 等于多少的,我通过 email 建了一个索引,我认为它是在,但是 UID 再转过去的时候可能已经不存在了。\n\n比如说我先标记成 delete only,我删除它的时候不管它现在有没有索引,我都会尝试删除索引,所以我的数据是干净的。如果我删除掉的话,我不管结果是什么样的,我尝试去删一下,可能这个索引还没 build 出来,但是我仍然删除,如果数据没有了,索引一定没有了,所以这可以很好的保持它的一致性。后面再类似于前面,先标记成 write only 这种方式, 连续再迭代这个状态,就可以迭代到一个最终可以对外公开的状态。比如说当我迭代到一定程度的时候,我可以从后台 build index ,比如说我一百亿,正在操作的 index 会马上 build,但是还有很多没有 build index ,这个时候后台不断的跑 map-reduce 去 build index ,直到整个都 build 完成之后,再对外 public ,就是说我这个索引已经可用了,你可以直接拿索引来找,这个是非常经典的。在这个 Online, Asynchronous Schema Change in F1 paper 之前,大家都不知道这事该怎么做。\n\nProxy Sharding 的方案不支持分布式事务,更不用说跨数据中心的一致性事务了。 TiKV 很好的支持 transaction,刚才提到的 Raft 除了增加副本之外,还有 leader transfer,这是一个传统的方案都无法提供的特性。以及它带来的好处,当我瞬间平衡整个系统负载的时候,对外是透明的, 做 leader transfer 的时候并不需要移动数据, 只是个简单的 leader transfer 消息。\n\n然后说一下如果大家想参与我们项目的话是怎样的过程,因为整个系统是完全开源的,如果大家想参与其中任何一部分都可以,比如说我想参与到分布式 KV,可以直接贡献到 TiKV。TiKV 需要写 Rust,如果大家对这块特别有激情可以体验写 Rust 的感觉 。\n\nTiDB 是用 Go 写的,Go 在中国的群众基础是非常多的,目前也有很多人在贡献。整个 TiDB 和TiKV 是高度协作的项目,因为 TiDB 目前还用到了 etcd,我们在和 CoreOS 在密切的合作,也特别感谢 CoreOS 帮我们做了很多的支持,我们也为 CoreOS 的 etcd 提了一些 patch。同时,TiKV 使用 RocksDB ,所以我们也为 RocksDB 提了一些 patch 和 test,我们也非常感谢 Facebook RocksDB team 对我们项目的支持。\n\n另外一个是 PD,就是我们前面提的 Placement Driver,它负责监控整个系统。这部分的算法比较好玩,大家如果有兴趣的话,可以去自己控制整个集群的调度,它和 k8s 或者是 Mesos 的调度算法是不一样的,因为它调度的维度实际上比那个要更多。比如说磁盘的容量,你的 leader 的数量,你的网络当前的使用情况,你的 IO 的负载和 CPU 的负载都可以放进去。同时你还可以让它调度不要跨一个机房里面建多个副本。","date":"2016-10-01","author":"刘奇","fillInMethod":"writeDirectly","customUrl":"how-do-we-build-tidb","file":null,"relatedBlogs":[]},{"id":"Blogs_201","title":"演讲实录 | 黄东旭:分布式数据库模式与反模式","tags":["TiDB","分布式数据库"],"category":{"name":"观点洞察"},"summary":"日前,PingCAP 联合创始人兼 CTO 黄东旭在「2016中国数据分析师行业峰会(CDAS)」 “数据库与技术实战”分论坛上,分享了《分布式数据库模式与反模式》的主题演讲。本文为演讲实录。","body":"我叫黄东旭,是 PingCAP 的联合创始人兼 CTO,也是本场论坛的主持人。我原来在 MSRA,后来到了网易、豌豆荚。跟在座的大部分数据分析师不太一样的是,我是一个数据库开发,虽然是 CTO,但是还在写代码。\n\n同时,我也是一些用的比较广泛的分布式的开源软件的作者。比如说我们做的 TiDB、TiKV 这些大型的分布式关系型数据库的项目。\n\n我们现在正在做一个 OLTP 的数据库,主要 focus 在大数据的关系型数据库的存储和可扩展性,还有关系的模型,以及在线交易型数据库上的应用。\n\n所以,今天整个数据库的模式和反模式,我都会围绕着如何在一个海量的并发,海量的数据存储的容量上,去做在线实时的数据库业务的一些模式来讲。并从数据库的开发者角度,来为大家分享怎样写出更加适合数据库的一些程序。\n\n## 基础软件的发展趋势\n\n一开始我先简单介绍一下,现在我认为的一些基础软件上的发展趋势。\n\n### 开源\n\n第一点,开源是一个非常大的趋势。大家可以看到一些比较著名的基础软件,基本都是开源的,比如 Docker,比如 k8s。甚至在互联网公司里面用的非常多的软件,像 MySQL、Hadoop 等这种新一代的大数据处理的数据库等基础软件,也大多是开源的。其实这背后的逻辑非常简单:在未来其实你很难去将你所有的技术软件都用闭源, 因为开源会慢慢组成一个生态,而并不是被某一个公司绑定住。比如国家经常说去 IOE,为什么?很大的原因就是基本上你的业务是被基础软件绑死的,这个其实是不太好的一个事情。而且现在跟过去二十年前不一样,无论是开源软件的质量,还是社区的迭代速度,都已经是今非昔比,所以基本上开源再也不是低质低量的代名词,在互联网公司已经被验证很多次了。\n\n### 分布式\n\n第二,分布式会渐渐成为主流的趋势。这是为什么?这个其实也很好理解,因为随着数据量越来越大,大家可以看到,随着现在的硬件发展,我感觉摩尔定律有渐渐失效的趋势。所以单个节点的计算资源或者计算能力,它的增长速度是远比数据的增长速度要慢的。在这种情况下,你要完成业务,存储数据,要应对这么大的并发,只有一种办法就是横向的扩展。横向的扩展,分布式基本是唯一的出路。scale-up 和 scale-out 这两个选择其实我是坚定的站在 scale-out 这边。当然传统的关系数据库都会说我现在用的 Oracle,IBM DB2,他们现在还是在走 scale-up 的路线,但是未来我觉得 scale-out 的方向会渐渐成为主流。\n碎片化\n\n### 碎片化\n\n第三,就是整个基础软件碎片化。现在看上去会越来越严重。但是回想在十年前、二十年前,大家在写程序的时候,我上面一层业务,下面一层数据库。但是现在你会发现,随着可以给你选择的东西越来越多,可以给你在开源社区里面能用到的组件越来越多,业务越来越复杂,你会发现,像缓存有一个单独的软件,比如 redis,队列又有很多可以选择的,比如说 zeromq, rabbitmq, celery 各种各样的队列;数据库有 NoSQL、HBase,关系型数据库有 MySQL 、PG 等各种各样的基础软件都可以选。但是就没有一个非常好东西能够完全解决自己的问题。所以这是一个碎片化的现状。\n\n### 微服务\n\n第四,是微服务的模式兴起。其实这个也是最近两年在软件架构领域非常火的一个概念。这个概念的背后思想,其实也是跟当年的 SOA 是一脉相承的。就是说一个大的软件项目,其实是非常难去 handle 复杂度的,当你业务变得越来越大以后,维护成本和开发成本会随着项目的代码量呈指数级别上升的。所以现在比较流行的就是,把各个业务之间拆的非常细,然后互相之间尽量做到无状态,整个系统的复杂度可以控制,是由很多比较简单的小的组件组合在一起,来对外提供服务的。\n\n这个服务看上去非常美妙,一会儿会说有什么问题。最典型的问题就是,当你的上层业务都拆成无状态的小服务以后,你会发现原有的逻辑需要有状态的存储服务的时候你是没法拆的。我所有的业务都分成一小块,每一小块都是自己的数据库或者数据存储。比如说一个简单的 case,我每一个小部分都需要依赖同一个用户信息服务,这个信息服务会变成整个系统的一个状态集中的点,如果这个点没有办法做弹性扩展或者容量扩展的话,就会变成整个系统很致命的单点。\n\n所以现在整个基础软件的现状,特别在互联网行业是非常典型的几个大的趋势。我觉得大概传统行业跟互联网行业整合,应该在三到五年,这么一个时间。所以互联网行业遇到的今天,可能就是传统行业,或者其他的行业会遇到的明天。所以,通过现在整个互联网里面,在数据存储、数据架构方面的一些比较新的思想,我们就能知道如何去做这个程序的设计,应对明天数据的量级。\n\n## 现有存储系统的痛点\n\n其实今天主要的内容是讲存储系统,存储系统现在有哪些痛点?其实我觉得在座的各位应该也都能切身的体会到。\n\n### 弹性扩展\n\n首先,大数据量级下你如何实现弹性扩展?因为我们今天主要讨论的是 OLTP ,是在线的存储服务,并不是离线分析的服务。所以在线的存储服务,它其实要做到的可用性、一致性,是要比离线的分析业务强得多的。但是在这种情况下,你们怎样做到业务无感知的弹性扩展,你的数据怎么很好的满足现有的高并发、大吞吐,还有数据容量的方案。\n\n### 可用性\n\n第二,在分布式的存储系统下,你的应用的可用性到底是如何去定义,如何去保证?其实这个也很好理解,因为在大规模的分布式系统里面,任何一个节点,任何一个数据中心或者支架都有可能出现硬件的故障,软件的故障,各种各样的故障,但这个时候你很多业务是并没有办法停止,或者并没有办法去容忍 Down time 的。所以在一个新的环境之下,你如何对你系统的可用性做定义和保证,这是一个新的课题。一会儿我会讲到最新的研究方向和成果。\n\n### 可维护性\n\n第三,对于大规模的分布式数据库来说它的可维护性,这个怎么办?可维护性跟单机的系统是明显不同的,因为单机的数据库,或者传统的单点的数据库,它其实做到主从,甚至做到一主多从,我去维护 master ,别让它挂掉,这个维护性主要就是维护单点。在一个大规模的分布式系统上,你去做这个事情是非常麻烦的。可以简单说一个案例,就是 Google 的 Spanner。Spanner 是 Google 内部的一个大规模分布式系统,整个谷歌内部只部署了一套,在生产环节中只部署了一套。这一套系统上有上万甚至上数十万的物理节点。但是整个数据库的维护团队,其实只有很小的一组人。想像一下,上十万台的物理节点,如果你要真正换一块盘、做一次数据恢复或者人工运维的话,这是根本不可能做到的事情。但是对于一个分布式系统来说,它的可维护性或者说它的维护应该是转嫁给数据库自己。\n\n### 开发复杂度\n\n还有,就是对于一个分布式数据库来说,它在开发业务的时候复杂度是怎么样的。大家其实可能接触的比较多的,像 Hbase、 Cassandra、Bigtable 等这种开源的实现,像 NoSQL 数据库它其实并没有一个很好的 cross-row transaction 的 support。\n\n另外,对于很多的 NoSQL 数据库并没有一个很好的 SQL 的 interface,这会让你写程序变得非常麻烦。比如说对于一些很普通的业务,一个表,我需要去 select from table,然后有一个fliter 比如一个条件大于 10,小于 100,这么简单的逻辑,如果在 HBase 上去做的话,你要写十行、二十行、三十行;如果你在一个关系的数据库,或者支持 SQL 的数据库,其实一行就搞定了。\n\n其实这个对于很多互联网公司来说,在过去的几年之内基本上已经完成了这种从 RDBMS 到 NoSQL 的改造,但是这个改造的成本和代价是非常非常高的。比如我原来的业务可能在很早以前是用 MySQL 已经写的稳定运行好久了,但是随着并发、容量、可扩展性的要求,我需要迁移 Bigtable、Hbase、Cassandra、MongoDB 这种 NoSQL 数据库上,这时基本上就要面临代码的完整重写。这个要放在互联网公司还可以,因为它们有这样的技术能力去保证迁移的过程。反正我花这么多钱,招这么牛的工程师,你要帮我搞定这个事情。但是对于传统的行业,或者传统的机构来说,这个基本上是不可能的事情。你不可能让他把原来用 Oracle 用SQL 的代码改成 NoSQL 的 code。\n\n因为 NoSQL 很少有跨行事务,首先你要做一个转账,你如果不是一个很强的工程师,你这个程序基本写不对,这是一个很大的问题。这也是为什么一直以来像这种 NoSQL 的东西并没有很好的在传统行业中去使用的一个最核心的原因,就是代价实在太大。\n\n## 存储系统的扩展模型\n\n所以其实在去讲这些具体到底该怎么解决,或者未来数据库会是什么样的之前,我想简单讲一下扩展的模型。对于一个关系型数据库也好,对于存储的系统本身也好,它的扩展模型有哪些。\n\n### Sharding 模式\n\n第一种模式是 Sharding 模式。如果在座的各位有运维过线上的 MySQL 的话,对这个模型会非常熟悉。最简单的就是分库、分表加中间件,就是说我不同的业务可能用不同的库,不同的表。当一个单表太大的时候,我通过一些 Cobar、Mycat 等这样的数据库中间件来去把它分发到具体的数据库的实例上。这种模型是目前用的最普遍的模型,它其实也解决了很大部分的问题。为什么这十年在关系型数据库上并没有很好的扩展方案,但是大家看上去这种业务还没有出现死掉的情况,就是因为后面有各种各样 Sharding 的中间件或者分库分表这种策略在硬扛着。像这种中间件 Sharding 第一个优势就是实现非常简单。你并不需要对数据库内做任何的改造,你也并不需要去比如说从你原来的 SQL 代码转到 NoSQL 的代码。\n\n**但是它也有自己的缺点。首先,对你的业务层有很强的侵入性。** 这是没有办法的,比如你想用一个中间件,你就需要给它指定一个 Sharding key。另外,原来比如你的业务有一些 join ,有一些跨表跨行的事务,像这种事务你必须得改掉,因为很多中间件并没有办法支持这个跨 shard 的分布式 join。\n**第二个比较大的缺陷是它的分片基本是固定的,自动化程度、扩展性都非常,** 你必须得有一个专职的 DBA 团队给你的 MySQL 或者 PG 的 Sharding 的集群去做运维。我之前在豌豆荚做过一段时间 MySQL cluster 的分片的维护工作。当时我记得是一个 16 个节点的 MySQL 的集群,我们需要扩展到 32 个节点的规模,整整提前演练了一个月,最后上线了一个礼拜。上线那个礼拜,晚上基本上没有办法睡觉,所以非常痛苦。\n\n再说一个 Google 的事情,Google 在刚才我说的 Spanner 和 F1 这两个数据库没有上线之前,Google 的广告系统的业务是由 100 多个节点的 MySQL 的集群对外提供服务的。如 Google 这么牛的公司,在维护一百多个节点的 MySQL Sharding 的数据库的时候,都已经非常痛苦,宁可重新去写一个数据库,也不想去维护这个 database cluster。其实大家可以看到,像这种 Sharding 的方案,它比较大的问题就是它的维护代价或者维护集群的复杂度,并不是随着节点数呈线性增长,而是随着节点的增加非线性的增长上去。比如你维护 2 个节点的还好,维护 4 个节点的也还可以,但是你维护 16 个、64 个、128 个基本就是不可能的事情。\n\n**第三**就是一些复杂的查询优化,并没有办法在中间件这一层,去帮你产生一个足够优化的执行计划,因此,对于一些复杂查询来说,Sharding 的方案是没法做的。所以对你的业务层有很高的要求。\n\n这是一种思路,是目前来说互联网公司里边用的最多的一种 MySQL 或者 PG 这种关系型数据库的扩展方案。\n\n### Region Base 模型\n\n第二种扩展模型是 Region Base。这张图是我项目里面扒出来的图。\n\n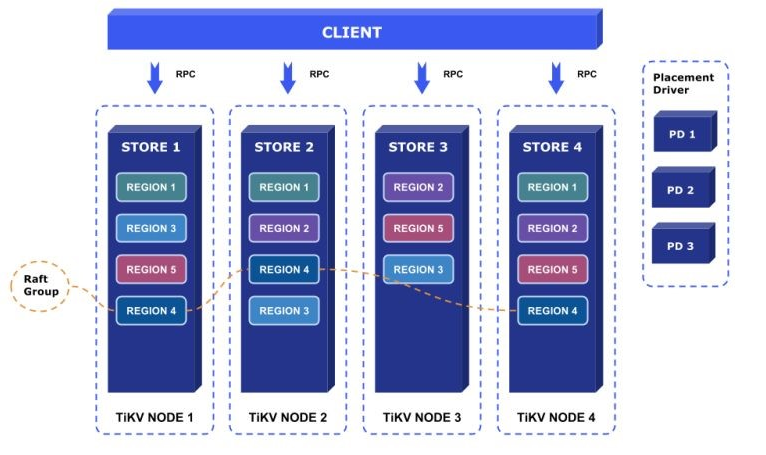\n\nRegion Base
\n\n它整个思路有点像 Bigtable,它相当于把底下的存储层分开,数据在最底层存储上已经没有表、行这样结构的划分,每一块数据都由一个固定的 size 比如 64 M、128 M 连续的 Key-value pairs 组成。其实这个模型背后最早的系统应该是谷歌在 06 年发表的 Bigtable 这篇论文里面去描述的。这个模型有什么好处呢?一是它能真正实现这种弹性的扩展。第二个,它是一个真正高度去中心化。去中心化这个事情,对于一个大的 Cluster 来说是一个非常重要的特性。\n\n**还有一个优势,在 KV 层实现真正具有一定的自动 Failover 的能力。** Failover指的是什么呢?比如说在一个集群比较大的情况下,或者你是一个 cluster ,你任何一个节点,任何一个数据损坏,如果能做到业务端的透明,你就真正实现了 Auto-Failover 的能力。其实在一些对一致性要求不那么高的业务里面,Auto-Failover 就是指, 比如在最简单的一个 MySQL 组从的模型里,当你的组挂掉了以后,我监控的程序自动把 slave 提上来,这也是一种 Failover 的方式。但是这个一致性或者说数据的正确性并不能做到很好的保证。你怎么做到一致性的 Auto-Failover,其实背后需要做非常非常多的工作。\n\n这是 Region 模型的一些优势。**但是它的劣势也同样明显,这种模型的实现非常复杂。** 我一会儿会说到背后的关键技术和理论,但是它比起写中间件真的复杂太多了。你要写一个能用的 MySQL 或者 PG 的中间件,可能只需要一两个工程师,花一两周的时间就能写出一个能用的数据库中间件;但是你如果按照这个模型做一个弹性扩展的数据库的话,你的工作量就会是数量级的增加。\n\n**第二个劣势就是它业务层的兼容性。** 像 Region Base 的模型,最典型的分布式存储系统就是 HBase。HBase 它对外的编程接口和 SQL 是千差万别,因为它是一个 Key Value 的数据库。你的业务层的代码兼容性都得改,这个对于一些没有这么强开发能力的用户来说,是很难去使用的,或者它说没有 SQL 对于用户端这么友好。\n\n## 可用性级别\n\n我一会儿会讲一下,刚才我们由 Region Base 这个模型往上去思考的一些东西,在此之前先说一些可用性。高可用。其实说到高可用这个词,大多数的架构师都对它非常熟悉。我的系统是高可用的,任何一个节点故障业务层都不受影响,但是真的不受影响吗?我经过很多的思考得到的一个经验就是主从的模型是不可能保证同时满足强一致性和高可用性的。可能这一点很多人觉得,我主从,我主挂了,从再提起来就好,为什么不能保护这个一致性呢?就是因为在一个集群的环境下,有一种故障叫脑裂。脑裂是什么情况?整个集群是全网络联通的,但是出现一种情况,就是我只是在集群内部分成了两个互不联通的一个子集。这两个子集又可以对外提供服务,其实这个并不是非常少见的状况,经常会发生。像这种情况,你贸然把 slave 提起来,相当于原来的 master 并没有完全的被 shutdown,这个时候两边可能都会有读写的情况,造成数据非常严重的不一致,当然这个比较极端了。所以你会发现阿里或者说淘宝,年年都在说我们有异地多活。但是去年甚至前几个月,杭州阿里的数据中心光纤被挖断,支付宝并没有直接切到重复层,而是宁可停止服务,完全不动,也不敢把 slave 数据中心提起来。所以其实任何基于主从模型的异地多活方案都是不行的。这个问题有没有办法解决呢?其实也是有的。\n\n还是说到 Google,我认为它才是全世界最大的数据库公司,因为它有全世界最大的数据量。你从来没有听说过 Google 哪一个业务因为哪一个数据中心光纤挖断,哪一个磁盘坏了而对外终止服务的,几乎完全没有。因为 Google 的存储系统大多完全抛弃了基于主从的一致性模型。它的所有数据都不是通过主从做复制的,而是通过类似 Raft 或者 Paxos 这种分布式选举的算法做数据的同步。这个算法的细节不展开了,总体来说是一个解决在数据的一致性跟自动的数据恢复方面的一个算法。同时,它的 latency 会比多节点强同步的主从平均表现要好的一个分布式选举的算法。\n\n在 Google 内部其实一直用的 Paxos,它最新的 Spanner 数据库是用 Paxos 做的 replication 。在社区里面,跟 Paxos 等价的一个算法就是 Raft。Raft 这个算法的性能以及可靠性都是跟 Paxos 等价的实现。这个算法就不展开了。我认为这才是新一代的强一致的数据库应该使用的数据库复制模型。\n\n## 分布式事务\n\n说到事务。对于一个数据库来说,我要做传统的关系型数据库业务,事务在一个分布式环境下,并不像单机的数据库有这么多的方法,这么多的优化。其实在分布式事务这个领域只有一种方法,并且这么多年了从分布式事务开始到现在,在这个方法上并没有什么突破,基本只有一条出路就是两阶段提交。其实可以看一下 Google 的系统。对于我们做分布式系统的公司来说,Google 就是给大家带路的角色。Google 最新的数据库系统上它使用的分布式事务的方法仍然是两阶段提交。其实还有没有什么优化的路呢?其实也是有的。两阶段提交最大的问题是什么呢?一个是延迟。因为第一阶段先要把数据发过去,第二阶段要收到所有参与的节点的 response 之后你才能去 commit 。这个过程,相当于你走了很多次网络的 roundtrip,latency 也会变得非常高。所以其实优化的方向也是有的,但是你的 latency 没法优化,只能通过吞吐做优化,就是 throughput 。比如说我在一万个并发的情况下,每个用户的 latency 是 100 毫秒,但是一百万并发,一千万并发的时候,我每个用户的 latency 还可以是 100 毫秒,这在传统的单点关系型数据库上,是没有办法实现的。第二就是去中心化的事务管理器。另外没有什么东西是银弹,是包治百病的,你要根据你的业务的特性去选择合适的一致性算法。\n\n## NewSQL\n\n其实刚刚这些 pattern 会发展出一个新的类别,我们能不能把关系数据库上的一些 SQL、Transaction 跟 NoSQL 跟刚才我说到的 Region Base 的可扩展的模型融合起来。这个思想应该是在 2013 年左右的时候,学术界提出来比较多的东西,NewSQL。NewSQL 首先要解决 Scalability 的问题, 刚给我们说过 scalability 是一个未来的数据库必须要有的功能,第二个就是 SQL,SQL 对于业务开发者来说是很好的编程的接口。第三,ACID Transaction,我希望我的数据库实现转帐和存钱这种强一致性级别的业务。第四,就是整个 cluster 可以支持无穷大的数据规模,同时任何数据节点的宕机、损坏都需要集群自己去做监控,不需要 DBA 的介入。\n\n## 案例:Google Spanner / F1\n\n有没有这样的系统?其实有的。刚才一直提到 Google 的 Spanner 系统。Spanner 系统是在 2012 年底于 OSDI 的会议上发布了论文; F1 这篇论文在 2013 年的 VLDB 发布的,去描述了整个 Google 内部的分布式关系型数据库的实现。首先,根据 Spanner 的论文 Spanner 和 F1 在生产环境只有一个部署,上万物理节点遍布在全球各种数据中心内,通过 Paxos 进行日志复制。第二,整个架构是无状态的 SQL 层架在一个 NoSQL 的基础之上。第三,它对外提供的是一个跨行事务的语义,这个跨行事务是透明的跨行事务,我不需要对我的业务层做修改,它是通过 一个硬件支持的 Truetime API,GPS 时钟和原子钟去实现事务的隔离级别。这个系统是最早用来支撑 Google 的在线广告业务,在线广告业务大家知道,其实对于扣费、广告计费、点击记录,广告活动等一致性的级别要求非常高。首先这个钱不能多扣,也不能少扣,实时性要求非常高。而且业务逻辑相当复杂,这个时候需要一个 SQL 数据库,需要一个支持事务的数据库,需要一个支持 Auto-Failover 的数据库,所以就有了 Google Spanner/F1 这个系统。\n\n## 典型业务场景\n\n最典型的业务场景是什么呢?对于这种高吞吐、大容量的数据量级对于 NoSQL 系统来说,典型的应用的 Pattern 就是高吞吐大容量,还有就是 Workload 相对比较分散的情况。比较典型的反例是秒杀,秒杀这个场景其实非常不适合这种 NewSQL。另外就是一致性、可用性和 latency 之间怎么做取舍。在这种分布式数据库上面,第一个要丢弃的就是延迟,在这么大规模的量级上做强一致性,延迟是首先是不能保证的。你去看谷歌的 F1 和 Spanner 的论文里面,它提到它们的 latency 基本都是 10 毫秒、20 毫秒、甚至50 毫秒、100 毫秒的量级,但是它并不会太关心 latency 。因为它必须保证通过 Paxos 去做跨机房、多机房的复制,光速你肯定没法超越,所以这个时间是省不了的,它整个系统是面向吞吐设计的,而不是面向低延迟设计的,但是它要求非常强的一致性。\n\n### MySQL Sharding\n\n一个典型的场景就是替换 MySQL Sharding 的业务。它的业务典型的特点,就是高吞吐,海量并发的小事务,并不是特别大的 transection,模型也相对简单,没有复杂的 join 的程序。但是痛点刚才提到了非常明显,首先就是对于 MySQL Sharding 方案 scale 能力很差,对于表结构变更的方案并没有太多;再者,cross shard transaction,目前 Sharding 的方案并没有办法很好支持,但 NewSQL 面向的场景和 MySQL Sharding 面向的场景是非常的像的。\n\n### Cross datacenter HA\n\n第二种场景是 Cross datacenter HA(跨数据中心多活),这种场景简直是数据开发者追求的圣杯。因为像 Oracle、DB2,它在最关键,最核心的业务上,比如说像银行这种业务,它必须要求实现这种跨数据中心的高可用。但是在一个分布式的数据库上,或者说是 Open-source solution 里,有没有人有办法实现这个 Cross datacenter HA 呢?完全没有。目前来说并没有任何一个数据库能去解决这个问题。因为刚才提到了主从的模型根本是不可靠的。像这种业务的数据极端的重要,任何一点数据的丢失都不能容忍。另外即使整个数据中心宕机也不能影响线上的业务,很典型的像支付宝,这种涉及钱相关的,甚至有些比如你的银行卡,你肯定不能容忍说你吃完饭,告诉你不好意思数据中心挂了,你的钱我刷不了。但是并没有开源的数据库能解决这个问题,如果你真的自己做同步复制的方案的话,特别两地三中心的情况,你请求的延迟是取决于离你最远的数据中心,所以大部分业务来说延迟过大。 另外就是这些系统重度依赖人工运维。我认为一旦任何系统有人工的介入一定是会出错的。因为人是最难自动化的一个因素。\n\n## 反模式\n\n### 滥用传统关系模型\n\n对于这种大规模的分布式 NewSQL 来说,比较大的反模式就是,大量的使用存储过程 foreign key,视图等操作。因为首先存储过程是没有办法 scale 的。另外,大表与大表的 JOIN ,在线上的 OLTP 数据库上最大的开销并不是优化器的开销,而是网络通信的开销。比如两个表去做一个笛卡儿积,算起来可能并不是这么慢,但是要把数据一条一条在网络中传输代价是非常大的,这种情况下用 OLAP 的数据库是比较适合。\n没有利用好并发\n\n### 没有利用好并发\n\n刚才我一直强调对于新型的 OLTP 或者分布式关系型数据库来说,并发或者说吞吐才是应该追求的优化点。在架构设计时,不应该把对延迟非常敏感的业务去使用分布式数据库来实现。所以其实在延迟跟吞吐之间,数据库永远去选择吞吐。所以写程序会遇到的一个很典型的问题,就是我的查询是一行一行,上下之间有这种强依赖关系的模式。其实在这种模式下,对于分布式关系型数据库来说是非常不合适的。所以你应该用并发的思想去做,比如说我的请求,我可以把吞吐打到整个集群上,我的 Database,我的 cluster 会自动 balance 一些 workload,如果一行行查询之间是有依赖的话,那么每一条查询之间的 latency 是会叠加起来。所以这个其实并不是一个太好的 pattern。\n\n### 不均匀的设计\n\n数据库其实经常会被大家滥用。比如说我看到很多传统行业数据库使用的方法,其实真的是非常痛苦。无论什么业务我全都直接上 Oracle,不管这个业务是否真的需要 Database 来去支持;比如有人用 MySQL 做计数器,有些有 MySQL 做队列或者做秒杀,这个并不是太 scale 的东西。特别像秒杀的业务,特别高的并发打到同一个 key 上,workload 没办法去分拆到好多个节点来帮你去处理,所以整个分布式的集群就会退化成一个单点,这是非常不合理的。第二,当你的索引设计的不太好的时候,涉及到的过多全表扫描是非常不划算的。刚刚也说过,在一个分布式集群里面,最大的开销是网络的开销,你做全表扫描的时候并不是在一台机器上,而是在好多机器上做全表扫描,同时经过很大的网络传输,当你的索引设计不合理的时候会出现这样的问题。还有是过多的无效索引,会导致整个系统在写入的时候有延迟也好或者吞吐也好,会变得更慢。主要注意的就是不要存在任何可以把你的系统退化成单点的机会。\n\n### 错误的一致性模型\n\n还有一种最容易犯的问题,就是在没有好好思考你的业务适合的场景情况下,就去使用很强的一致性模型。因为当你要求一个非常高的强一致性的时候,你的分布式事务的 latency 一定比不这么强的一致性的业务要高得多的。其实,很多业务并不需要那么强的一致性,我的数据库虽然给你了这个能力,但如果你去滥用的话,你会说这个数据库好慢,或者为什么我这个请求100 毫秒才给我返回。但其实很多场景下,你并不是这么强的依赖强一致性 。这个跟数据库本身提不提供这个机制是没有关系的。作为一个 Database 开发者来说,我还是需要给你能实现这个功能的机制,但是不要滥用。\n\n另外根据你业务的冲突的频繁程度选择不同的锁策略。你知道这个业务就是一个很高的冲突的场景,比如说可能像类似发工资,一个集团的账号发到成千上万的小账号。如果你是一个乐观事务的话,可能涉及到的冲突就会很大。因为所有的事务的发起者都要去修改这个公共账号,这种情况下一般可以使用悲观事务,因为你已经预知到你业务的 conflict 级别会很高。但当我知道我的业务的冲突很小,我要追求整个系统的吞吐,我可能会选用乐观的事务的模型。\n\n我的演讲就到这儿,谢谢。\n\n## Q&A\n\n### 提问:您好,我简单问一下对于秒杀这个场景,什么样的数据库设计是合适的?\n\n黄东旭:其实秒杀这个业务是一个比较系统的工程,并不是一个简单的我用什么数据库就可以做的东西。我之前给一些朋友做秒杀的架构设计的时候,从最上层,甚至你可能从 JS 这边就要去做排队,一层一层的排队。比如在缓存这边我可以用 redis,我可以用一些缓存的数据库再去进行二级的排队,因为每一次排队你都会丢掉很多,最后到底下的队列,在数据库这一层,比如库存就十个,你只要在前面放十个进来就行了。就是说,你在上层把流量用排队的方式做更好。最典型的例子就是大家看 12306 卖火车票的时候经常会有排队。基本没有什么数据库能去应对,像淘宝,像京东这种秒杀的业务,它从上到下是整个系统的过程。谢谢。\n\n### 提问:您好,我问一下,你说的是分布式的 OLTP 数据库,历史数据怎么清理,如果后续还需要分析数据的话。\n\n黄东旭:其实在谷歌 Spanner 包括像 TiDB 、TiKV 这个系统之上,是通过一种 MVCC 的技术,每一条数据都会有一个版本号。比如说你不停的 update,它可能会产生好多版本。我背后会有一个 GC 的逻辑,去选定一个 safe point,在这个 safe point 之前的所有数据全都删掉也好,还是挪到冷的存储上也好,我们是通过这种方式实现的。另外随着数据量的膨胀,整个系统设计的时候,我们是通过 Raft 算法,比如说这个数据慢慢长大,我会把它切成两块,再慢慢 Auto-balance 到其它的节点上,然后新的那一块会再长大......这相当于一个细胞一样,一个细胞分裂成两个细胞,成千上万的细胞会均匀的分布在整个集群里面。如果你要删数据可以直接删,如果你不想删的话,你的数据可以全都留下,你自己随便往集群里增加新的节点。这个集群很大,它会自动帮你把数据均匀的分到这儿。所有的历史数据是通过 GC 的模块把历史的版本拿出来,丢到冷的存储上。\n\n在 Google 几乎是完全不删数据的,因为存储的成本是很低的,但是数据未来说不定什么时候就用了。大概是这样,我需要有一个办法能把它存下来。\n\n### 提问:当前做的交易要使用历史的参考数据,可能量不是很大,有这样的例子吗?\n\n黄东旭:当然有。像 MVCC 在访问历史,它其实提供了一个 Lock-free 的 Snapshot Read, 它在读历史版本的时候是不会读线上的正在进行的读写事务,所以它是有一个无所读的机制,这也是为什么它要去采用每一个数据都要有版本号的机制去实现。它是有这个需求,而且在实现的时候也非常漂亮,不会阻塞其他的请求。\n\n### 提问:你们的 TiDB 是怎么考虑用 MySQL 或者 PG 的?当时是怎么考虑的?\n\n黄东旭:首先我们没有用 MySQL 或者 PG,刚才说的 TiDB 这个模型是谷歌的 Spanner 跟 F1 的模型。用传统的单机数据库做改造的话,有一个比较大的误区,整个 SQL 的查询优化器跟存储的数据结构,并不知道你底层是分布式的存储,它还是假设你生成 SQL 的方案都是单机的。比如最简单的例子,我需要去 count *,如果是一个单机的 MySQL 优化器,没有建索引的话会一行一行把数据拉过来计一个数,这样算下去;但是如果对一个分布式系统来说,我只要把 count * 这个逻辑推到所有存储表的数据节点上,算法再 reduce 回来就可以,更像一个 Mapreduce 这种分布式框架的 SQL 优化器。如果你没有从底到上完整的去实现 Database 的话,你很难对分布式的场景或者分布式数据存储的这些性质来去对数据库做优化。没有办法,这是一条很难的道路,但是我们也得去下走。","date":"2016-09-12","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"talk-tidb-pattern","file":null,"relatedBlogs":[]},{"id":"Blogs_135","title":"云时代数据库的核心特点","tags":["Database"],"category":{"name":"观点洞察"},"summary":"最近几年,随着云计算相关技术的发展,各种不同类型的云层出不穷,服务越来越多不同类型的企业业务,传统企业也渐渐开始探索上云的道路。在云上,作为业务最核心的数据库,相比之前的传统方案会有哪些变化呢?在正式聊云时代的数据库特点之前,我们需要了解一下目前云时代架构发生的变化","body":"## 引言\n\n最近几年,随着云计算相关技术的发展,各种不同类型的云层出不穷,服务越来越多不同类型的企业业务,传统企业也渐渐开始探索上云的道路。在云上,作为业务最核心的数据库,相比之前的传统方案会有哪些变化呢?在正式聊云时代的数据库特点之前,我们需要了解一下目前云时代架构发生的变化。\n\n畅想一下,未来的服务都跑在云端,任何的服务资源都可以像水电煤一样按需选购。从 IaaS 层的容器/虚拟机,到 PaaS 层的数据库,缓存和计算单元,再到 SaaS 层的不同类型的应用,我们只需要根据自身业务特点进行资源选配,再也不用担心应用服务支撑不住高速的业务增长,因为在云上一切都是弹性伸缩的。有了可靠的基础软件架构,我们就可以把更多精力放到新业务的探索,新模式的创新,就有可能产生更多不一样的新场景,从而催生更强大能力的云端服务,这是一件多么 cool 的事情。\n\n当然,理想要一步一步实现,未来的基础软件栈到底会怎样呢?社区在这方面正在进行积极地探索,其中最有代表性的就是基于容器(以 Docker 为代表)的虚拟化技术和微服务(Microservice)。\n\n在云时代,一切都应该是可伸缩的,使用 k8s(Kubernetes)在保证资源平衡的前提下,通过 Docker 部署我们依托于容器的微服务模块,我们不用关心服务到底跑在哪里,只需要关心我们需要多少服务资源。Docker 提供了极大的便利性,一次构建,到处运行,我们可以很好地解决开发、测试和上线的环境一致性问题。(如果不能很好地保证测试和实际上线环境的一致性,则很有可能需要花费远超过开发的时间去发现和修复问题。)k8s 更是在 Docker 构建的基础上增加了更多的云特性,包括 Docker 的升级,高可用和弹性伸缩等等。 关于 Docker/k8s 相关的讨论已经很多了,因为时间关系,关于具体的细节就不再展开。我们只需要了解,有了它,可以很轻松地解决服务的安装和部署。\n\n下面再聊聊微服务,微服务将一个服务拆分成相对独立的更小的子服务单元,不同的子服务单元之间通过统一的接口(HTTP/RPC 等)进行数据交互。\n\n相比于传统的解决方案,这种架构有很多的优点。\n\n - 更好的开发效率和可维护性。微服务将一个单独的服务进行更细力度的拆分,每一个子服务单元专注于更小的功能模块,可以更好地根据业务建立对应的数据模型,降低复杂度,使得开发变得更轻松,维护和部署变得更加友好.\n - 更好的可扩展性。每个不同的子服务单元相互独立,彼此之间没有任何依赖,所以可以根据业务的具体需要,灵活地部署多个子服务单元进行水平扩展。\n - 更强的容错性。当其中一个子服务出现故障的时候,可以通过辅助的负载均衡工具,自动路由到其他的子服务,不会影响整体服务的可用性.\n\n当然,微服务也不是一个银弹,相对来说,这种方案会使整体系统的设计更加复杂,同时也加大了网络的延迟,对整个系统测试的复杂度也会更高。\n\nDocker 提供的隔离型和可移植性,与微服务是一种天然的契合,微服务将整个软件进行拆分和解耦,而通过 Docker/k8s 可以很自然地做到独立的部署,高可用和容错性,似乎一切都可以完美地运转起来。但是真的是这样么?我们是不是忽略了什么?\n\n是的,我们在讨论前面的问题的时候忽略了一个很重要的东西:状态。\n\n从整个技术发展的角度来看,微服务是一个非常有意义的探索。每个人都期望着每个微服务的子服务都是无状态的,这样我可以自由地启停和伸缩,没有任何的心智负担,但是现实的业务情况是什么样的呢?比如一个电商网站,用户正在下单购买一件商品,此时平台是通过订单子服务的 A 应用来提供服务的,突然,因为机器故障,订单子服务的 A 应用不可用了,改由订单子服务的 B 应用提供服务,那么它是必须要知道刚才用户的订单信息的,否则正在访问自己订单页面的用户会发现自己的订单信息突然不见了。虽然我们尽量想把子服务设计成无状态的,但是很多时候状态都是不可避免的,我们不得不通过存储层保存状态,业界最主要的还是各种数据库,包括 RDBMS 和 NoSQL,比如使用 MySQL、MongoDB、HBase、Cassandra 等,特别是有些场景还要考虑数据一致性问题的时候,更加重了对存储层的依赖。\n\n由此可见,云计算时代系统的架构发生了巨大的变化,这一方面为用户提供了更优秀的特性,另一方面也对云计算的组件提出了更高的要求。数据库作为云计算最基础的组件之一,也需要适应这种架构的变化。(这里我们主要关注 SQL 数据库,云时代的数据库以下简称云数据库。)\n\n## 那么云数据库主要有一些什么样的特点呢?我认为主要有以下几点。\n\n### 弹性伸缩\n\n传统的数据库方案,常见的会选用 Oracle,MySQL,PostgreSQL。在云时代,数据量的规模有爆发性的增长,传统的数据库很容易遇到单机的存储瓶颈,不得不选用一些集群方案,常见的比如 Oracle RAC、 MySQL Sharding 等,而这些集群方案或多或少都有一些不令人满意的地方。\n\n比如说,Oracle RAC 通过共享存储的硬件方案解决集群问题,这种方式基本上只能通过停机换用更大的共享内存硬件来解决扩容问题,RAC 节点过多会带来更多的并发问题,同样也会带来更高的成本。\n\n以 MySQL Sharding 为代表的数据分片方案,很多时候不得不提前对数据量进行规划,把扩容作为很重要的一个计划来做,从 DBA 到运维到测试到开发人员,很早之前就要做相关的准备工作,真正扩容的时候,为了保证数据安全,经常会选择停服务来保证没有新的数据写入,新的分片数据同步后还要做数据的一致性校验。当然业界大公司有足够雄厚的技术实力,可以采用更复杂的方案,将扩容停机时间尽量缩短(但是很难缩减到 0),但是对于大部分中小互联网公司和传统企业,依然无法避免较长时间的停服务。\n\n在云时代,理想中所有的资源都是根据用户业务需求按需分配的,服务器资源,应用容器资源,当然也包括数据库资源。添加或者减少新的数据库资源,完全就像日常吃饭那样稀疏平常,甚至用户基本感知不到。比如作为一个电商用户,在双 11 促销活动之前,可以通过增加数据库节点的方式,扩大更多的资源池,用来部署相应的容器服务,当活动结束之后,再将多余的资源移除去支持其他的服务,这样可以极大地提高资源的利用率,同样可以弹性地支撑各种峰值业务。\n\n### 高可用\n\n传统的 MySQL 方案,数据复制的时候默认采用异步的方式,对于一个写入的请求,主库写入成功后就会返回成功信息给客户端,但是这个时候数据可能还没有同步给从库,一旦主库这个时候挂掉了,启动从库的时候就会有丢失数据的风险。当然,也有人会选择半同步的复制方式,这种方式在正常情况下是同步的,但是在遇到数据压力比较大的时候,依然会退化为异步的方式,所以本质上来说,同样有丢失数据的风险。其他也有一些多主的同步方案,比如在应用层做数据同步,但是这种方式一是需要应用层的配合,二是在对网络超时的处理非常复杂,增加心智负担。\n\n在云时代,因为所有的数据库资源都是分布式存储的,每个数据库节点出现问题都是很正常的事情,所以就必须有一种可以实现数据一致性的数据复制方式来保证服务的高可用,业界给出的答案就是:Paxos/Raft(关于 Paxos 和 Raft 的实现细节我们不在这里展开)。PingCAP 在做的 TiDB 就是选择了 Raft 协议,Raft 协议看起来更像是一个多副本的自适应的主从复制协议,对于每次写请求,Raft 都会保证大多数写成功才会返回客户端,即使 Raft Group的Leader 挂掉了,在一个有限的时间范围内,会很快地选出一个新的 Leader 出来,继续提供服务。同样,对于一个 3 副本的 Raft Group,只要 2 个写入成功,就可以保证成功,而大多数情况下,最先写入成功的往往是与 Leader 网络情况最好的那个副本,所以这种 Majority 写的方式,可以很自然地选择速度最快的副本进行数据同步复制。另外,Raft 协议本身支持 Config Change,增加一个新的节点,可以很容易地做副本数据分布的变更,而不需要停止任何服务。\n\n同样,在云时代,数据库的 DDL 操作也会是一个非常有趣的事情。以一个常见的 Add Column 操作为例,在表规模已经很大的情况下,在传统的实现方案中,比较有参考意义的是,通过一些工具,创建类似表级别的触发器,将原表的数据同步到一个新的临时表中,当数据追平的时候,再进行一个锁表操作,将临时表命名为原表,这样一个 Add Column 操作就完成了。但是在云时代,分布式的数据存储方式决定了这种方案很难实现,因为每个数据库节点很难保证 Schema 状态变更的一致性,而且当数据规模增长到几十亿,几百亿甚至更多的时候,很短的阻塞时间都有可能会导致很大的负载压力变化,所以 DDL 操作必须是保证无阻塞的在线操作。值得欣慰的是,Google 的 F1 给我们提供了很好的实现参考,TiDB 即是根据 F1 的启发进行的研发,感兴趣的同学可以看下相关的内容。\n\n### 易用透明\n我们可以将云数据库想象成一个提供无限大容量的数据库,传统数据库遇到单机数据存储瓶颈的问题将不复存在。已有的程序基本上不怎么需要修改已有的代码,就可以很自然地接入到云数据库中来获得无限 Scale 的能力。增减数据库节点,或者节点的故障恢复,对于应用层来说完全透明。另外,云数据库的监控、运维、部署、备份等等操作都可以在云端通过高效的自动化工具来自动完成,极大地降低了运维成本。\n\n### 多租户\n云数据库本身应该是可以弹性伸缩的,所以很自然的,从资源利用率的角度来考虑,多个不同用户的数据库服务底层会跑在一个共享的云数据库中。因此多租户技术会成为云数据库的标配。但是这里面就有一个不得不面对的问题,如何做到不同用户的隔离性?用户数据隔离是相对比较容易的,比如还是以电商用户(这里说的是电商企业,不是顾客客户)为例,每个用户都有一个唯一的 ID,这样在云数据库的底层存储中,可以保证每个用户数据都带有自己 ID 前缀,用户登陆进来的时候可以根据这个前缀规则,获取他对应的数据,同时他看不到其他用户的数据。\n\n在一个真实的多租户环境下面,纯粹的数据隔离往往是不够的,你还需要做到资源公平性的隔离。比如有的用户写一个 SQL,这个 SQL 没有做优化,主要做的事情是一个全表描扫,这个表的数据量特别特别大,这样他会吃掉很多的 CPU、Memory、IO 等资源,导致其他用户很轻量级的 SQL 操作都可能会变得很慢,影响到其他用户实际的体验。那么针对这种情况怎么做隔离?与此类似的还有,网络带宽怎么做隔离?大家都是跑在一个云数据库上面的,如果一个用户存放的数据特别大,他把带宽都吃掉了,别人就显得非常慢了。\n\n还有一种情况,如果我本身作为一个租户,内部又怎么做隔离,大家知道 MySQL 可以建很多 Database,不同的 Database 给不同的团队来用,那么他们之间内部隔离又怎么做,这个问题就进一步更加复杂了。\n\n目前来讲没有特别好的方法,在一个分布式的环境下面去做很好的隔离,有两个方向可以考虑:\n\n第一种是最简单也是有效的方法,制定一些规则,把某些用户特别大的数据库表迁移到独享的服务器节点上面,这样就不会影响其他用户的服务,但是这里面就涉及到定制化的事情了,本身理念其实与云数据库并不相符。\n\n第二种就是依靠统计信息,做资源隔离和调度,但是这里面对技术的要求就比较高了。因为云数据库是分布式的,所以一般的统计都要横跨很多的机器,因为网络原因,不可能做到完全准确的统计,所有统计都是有延迟的。比如说对于某个用户,现在统计到的流量是 1 个 G,他可能突然就有一次峰值的网络访问,可能下一次统计消耗的流量是 5 个 G(这里面只是举例说明问题),如果你给他流量限制是 1 个 G,中间统计的间隔是多少比较合适,如果间隔比较小,那么这个对整个系统的压力就比较大,可能影响正常的用户 SQL 访问,另外本身这个流量限制的系统也是很复杂的系统。\n\n调度算法一直是整个分布式系统领域很困难的一个问题,如何做到隔离性和公平调度也是未来云数据库非常有挑战的一个事情。\n\n### 低成本\n低成本应该是云时代基础设施最明显的特点。首先,云数据库的高可用和容错能力,使得我们不再需要昂贵的硬件设备,只需要普通的 X86 服务器就可以提供服务。然后,受益于 Docker 的虚拟化技术,使得不同类型的应用容器可以跑在同一个物理机上,这样可以极大地提高资源的利用率。其次,多租户的支持,使得不同的用户可以共用一套底层的数据库存储系统,在数据库层面再一次提高了资源的利用效率。再次,云数据库的自动化运维工具,降低了整个核心数据库的运维成本。最后,云数据库资源是按需分配的,用户完全可以根据自身的业务特点,选购合适的服务资源。\n\n### 高吞吐\n\n云数据库虽然可以做到弹性扩容,但是本身是分布式存储的,虽然可以通过 Batch Write、Pipeline 和 Router Cache 等方式加快访问 SQL 请求的数据,但是相对传统单机的数据库来说,在数据访问链路上至少也要多走一次网络,所以大部分并发量不大的小数据量请求,都会比单机延迟要高一些。也就是说,当没有足够高的并发 SQL 访问的话,其实不能完全体现云数据库的性能优势,所以这也是我们在选用云数据库的时候需要认识到的问题,云数据库更多的是追求高吞吐,而不是低延迟。当并发大到一定规模,云数据库高吞吐特性就显现出来了,即使在很高的并发下,依然可以维持相当稳定的延迟,而不会像单机数据库那样,延迟线性增长。当然,延迟的问题,在合理的架构设计方案下,可以通过缓存的方式得到极大的缓解。\n\n### 数据安全\n云数据库的物理服务器分布在多个机房,这就为跨数据库中心的数据安全提供了最基础的硬件支持。谈到金融业务,大家耳熟能详的可能就是两地三中心,比如北京有两个机房,上海有一个。未来一切服务都跑在云上,金融类的业务当然也不例外。相比其他业务,金融类业务对数据安全要求就要高得多。当然,每个公司内部都有核心的业务,所以如果上云的话,也会有同样的强烈需要。这样,对云数据库来说,数据的一致性、分布式事务、跨数据中心的数据安全等更高端的需求有可能会日益强烈。常见的数据备份也有可能会被其他新的模式所取代或者弱化,比如基于 Paxos/Raft 的多副本方案,本身就保证了会有多份备份。\n\n### 自动负载平衡\n对于云数据库来说,负载平衡是一个很重要的问题,它直接决定了整个云数据库系统性能的好坏,如果一个数据库节点的数据访问过热的话,就需要考虑把数据迁移到其他的数据库节点来分担负载,不然就很容易出现性能瓶颈。整个负载平衡是一个动态的过程,调度算法需要保证资源配比的最大平衡,还有保证数据迁移的过程对系统整体的负载影响最小。这在未来也是云数据库需要解决的一个核心问题。\n\n## 小结\n从目前已有的 SQL 数据库实现方案来看,NewSQL 应该是最贴近于云数据库理念的实现。NewSQL 本身具有 SQL、ACID 和 Scale 的能力,天然就具备了云数据库的一些特点。但是,从 NewSQL 到云数据库,依然有很多需要挑战的难题,比如多租户、性能等。\n\n上面提到的一些云数据库的特点,也是 PingCAP 目前在着力实现的部分,TiDB 作为国内第一个 NewSQL 的开源项目,在与社区的共同努力下,我们在上月底刚刚发布了 Beta 版本,欢迎各位上 GitHub 了解我们。\n\n随着整个社区技术水平的发展和云时代新的业务需求的驱动,除了 PingCAP 的 TiDB,相信会有更多的团队在这方面进行探索, 期待早日看到云数据库成熟的那一天。\n\n## Q&A\n**问:由于客户数据环境复杂多样,在迁移到云端的时候怎么怎么做规划,以便后期统一运维管理?或者说,怎么把用户 SQL Server 或者 MongoDB 逐渐迁移到 TiDB 之类的分布式数据库?**\n**崔秋**:因为每个业务场景都不太相同,所以在选用云端服务的时候,首先要了解自身业务和云服务具体的优缺点。\n如果你的业务本身比较简单,比如你之前用的 MongoDB,现在很多云服务厂商都会提供云端的 MongoDB 服务。这个时候你就要根据业务特点来做判断,如果 MongoDB 本身容量不大,远期的业务数据不会增长过快的话,这个时候其实你可以直接使用 MongoDB 的服务的。但是如果你本身的数据量比较大,或者数据增长比较快的话,就可能要考虑数据的扩容问题,MongoDB 在这方面做的不是太好。\n你可以考虑 SQL 数据库的集群方案。比如 TiDB,它本身是支持弹性扩容,高并发高吞吐和跨数据库中心数据安全的,另外有一点明显的好处是 TiDB 兼容 MySQL 协议,所以如果你的应用程序是使用 MySQL,就基本上可以无缝地迁移到 TiDB,这方面是非常方便的。后续我们会提供常用的数据库迁移工具,帮用户把数据从 MongoDB/SQL Server 等平滑迁移到 TiDB 上面。\n还是那个原则,不要为了上云而上云,一定要了解清楚自己的业务特点,云数据库会帮助你提供很多特性,如果真的很适用你的业务的话,就可以考虑。\n\n**问:但从产品的角度来看,云厂商提供的 RDS 产品是 Copy 客户数据库的思路,或者说是为了支持不同的数据库而支持。请问这种局面以后会有什么改变吗?**\n**崔秋**:现在确实蛮多云数据库服务其实就是在传统的 RDS 上面包了一层自动化的监控,运维和部署工具,就卖给用户提供服务了,但是实际上本身解决的仅仅是自动化管控的问题,云服务提供的数据库特性还是单机的 RDS,或者 RDS Sharing 的特性。如果本身底层的数据库满足不了你的需求的话,云服务也是满足不了的。\n如果你需要不停服务的弹性扩容,单机的 RDS 服务肯定是搞不定的,RDS Sharing 也很难帮助你做到,这就对底层的数据库有了更高的要求,当然这方面是 TiDB 的强项了。\n现在很多云上的 RDS 产品还远远没有达到理想中的云数据库的要求,不过随着社区的发展和业务需求的推动,我个人觉得,这方面最近几年会有更多的变化。如果对于这方面感兴趣的话,可以关注下 TiDB。\n\n**问:从 Oracle 分流数据到 TiDB、Oracle 增量修改、Update 的记录,如何同步到 TiDB?有没有工具推荐,比如类似 Ogg?**\n**崔秋**:目前 TiDB 还没有相应的工具。如果真的需要在线从 Oracle 这边分流的话,可以考虑使用 Oracle 的触发器,将数据的变化记录下来,然后转化为 SQL,同步到 TiDB,当然这需要一定开发的工作量。","date":"2016-08-02","author":"崔秋","fillInMethod":"writeDirectly","customUrl":"cloud-native-db","file":null,"relatedBlogs":[]}],"blogCategories":[{"name":"产品技术解读"},{"name":"公司动态"},{"name":"社区动态"},{"name":"案例实践"},{"name":"观点洞察"}],"blogRecommend":[{"blog":{"author":"黄东旭","summary":"PingCAP 联合创始人兼 CTO 黄东旭分介绍了 TiDB Serverless 作为未来一代数据库的核心设计理念,同时探讨了 TiDB Serverless 对于中国用户的价值。","title":"黄东旭:The Future of Database,掀开 TiDB Serverless 的引擎盖","date":"2023-07-24","customUrl":"the-future-of-database-2023"}},{"blog":{"author":"张翔","summary":"本次分享在介绍 Serverless Tier 的技术细节之余,全面解析了 TiDB 的技术生态全景和在生态构建中所做的努力。阅读本文,了解有关 Serverless 的更多信息,以及 PingCAP 在技术领域的最新进展。","title":"TiDB Serverless 和技术生态全景","date":"2023-02-20","customUrl":"tidb-serverless-and-technology-ecology-overview"}},{"blog":{"author":"韩锋","summary":"本文转载自公众号:韩锋频道(hanfeng_channel)。文章从金融用户角度入手,对如何选择分布式数据库及选型后的最优实践进行了阐述。","title":"金融业分布式数据库选型及 HTAP 场景实践","date":"2022-05-19","customUrl":"distributed-database-selection-and-htap-practice-in-financial-industry"}},{"blog":{"author":"黄东旭","summary":"很多时候「品味」之所以被称为「品味」,就是因为说不清道不明,这固然是软件开发艺术性的一种体现,但是这也意味着它不可复制,不易被习得。本系列文章会试着总结一下好的基础软件体验到底从哪里来。作为第一篇,本文将围绕可观测性和可交互性两个比较重要的话题来谈。","title":"做出让人爱不释手的基础软件:可观测性和可交互性","date":"2021-10-15","customUrl":"how-to-develop-an-infrasoft-observability-and-interactivity"}},{"blog":{"author":"刘奇","summary":"我们更多时候是站在哲学层面思考整个公司的运转和 TiDB 这个产品的演进的思路。这些思路很多时候是大家看不见的,因为不是一个纯粹的技术层面或者算法层面的事情。","title":"势高,则围广:TiDB 的架构演进哲学","date":"2019-05-30","customUrl":"guiding-ideologies-in-the-evolution-of-tidb"}}],"blogMostPopular":[{"blog":{"author":"申砾","customUrl":"tidb-internal-1","date":"2017-05-15","summary":"数据库、操作系统和编译器并称为三大系统,可以说是整个计算机软件的基石。其中数据库更靠近应用层,是很多业务的支撑。这一领域经过了几十年的发展,不断的有新的进展。很多人用过数据库,但是很少有人实现过一个数据库,特别是实现一个分布式数据库。了解数据库的实现原理和细节,一方面可以提高个人技术,对构建其他系统有帮助,另一方面也有利于用好数据库。研究一门技术最好的方法是研究其中一个开源项目,数据库也不例外。单机数据库领域有很多很好的开源项目,其中 MySQL 和 PostgreSQL 是其中知名度最高的两个,不少同学都看过这两个项目的代码。但是分布式数据库方面,好的开源项目并不多。 TiDB 目前获得了广泛的关注,特别是一些技术爱好者,希望能够参与这个项目。由于分布式数据库自身的复杂性,很多人并不能很好的理解整个项目,所以我希望能写一些文章,自顶向下,由浅入深,讲述 TiDB 的一些技术原理,包括用户可见的技术以及大量隐藏在 SQL 界面后用户不可见的技术点。","title":"三篇文章了解 TiDB 技术内幕 - 说存储"}},{"blog":{"author":"申砾","customUrl":"tidb-internal-2","date":"2017-05-24","summary":"上一篇介绍了 TiDB 如何存储数据,也就是 TiKV 的一些基本概念。本篇将介绍 TiDB 如何利用底层的 KV 存储,将关系模型映射为 Key-Value 模型,以及如何进行 SQL 计算。","title":"三篇文章了解 TiDB 技术内幕 - 说计算"}},{"blog":{"author":"申砾","customUrl":"tidb-internal-3","date":"2017-06-06","summary":"任何一个复杂的系统,用户感知到的都只是冰山一角,数据库也不例外。前两篇文章介绍了 TiKV、TiDB 的基本概念以及一些核心功能的实现原理,这两个组件一个负责 KV 存储,一个负责 SQL 引擎,都是大家看得见的东西。在这两个组件的后面,还有一个叫做 PD(Placement Driver)的组件,虽然不直接和业务接触,但是这个组件是整个集群的核心,负责全局元信息的存储以及 TiKV 集群负载均衡调度。本篇文章介绍一下这个神秘的模块。这部分比较复杂,很多东西大家平时不会想到,也很少在其他文章中见到类似的东西的描述。我们还是按照前两篇的思路,先讲我们需要什么样的功能,再讲我们如何实现,大家带着需求去看实现,会更容易的理解我们做这些设计时背后的考量。","title":"三篇文章了解 TiDB 技术内幕 - 谈调度"}},{"blog":{"author":"PingCAP","customUrl":"introduction-of-open-source-license","date":"2021-10-20","summary":"PingCAP 从第一行代码开源,六年里积累了一些经验和教训,在《开源知识科普》栏目中,我们将与大家分享和交流在开源成长路径中的思考和感受,以及参与开源项目的正确姿势。本期话题就从开源的基础——开源许可证开始,希望对大家了解开源、参与开源有一定帮助。","title":"一文看懂开源许可证丨开源知识科普"}},{"blog":{"author":"唐刘","customUrl":"grpc","date":"2017-06-18","summary":"经过很长一段时间的开发,TiDB 终于发了 RC3。RC3 版本对于 TiKV 来说最重要的功能就是支持了 gRPC,也就意味着后面大家可以非常方便的使用自己喜欢的语言对接 TiKV 了。gRPC 是基于 HTTP/2 协议的,要深刻理解 gRPC,理解下 HTTP/2 是必要的,这里先简单介绍一下 HTTP/2 相关的知识,然后再介绍下 gRPC 是如何基于 HTTP/2 构建的。","title":"深入了解 gRPC:协议"}}],"allTags":[{"name":"TiDB","count":179},{"name":"社区","count":103},{"name":"TiKV","count":30},{"name":"社区动态","count":29},{"name":"TiDB 源码阅读","count":24},{"name":"TiKV 源码解析","count":21},{"name":"HTAP","count":20},{"name":"Release","count":17},{"name":"TiFlash","count":16},{"name":"Chaos Mesh","count":15},{"name":"TiDB Hackathon 2021","count":13},{"name":"Raft","count":11},{"name":"TiCDC","count":11},{"name":"TiDB 4.0 新特性","count":11},{"name":"DM 源码阅读","count":10},{"name":"Contributor","count":9},{"name":"TiDB Binlog 源码阅读","count":9},{"name":"TiFlash 源码阅读","count":9},{"name":"TiDB Hackathon 2022","count":8},{"name":"技术出海","count":8},{"name":"Serverless","count":7},{"name":"TiDB Hackathon 2020","count":7},{"name":"TiDB 性能调优","count":7},{"name":"分布式数据库","count":7},{"name":"DM","count":6},{"name":"SQL","count":6},{"name":"最佳实践","count":6},{"name":"架构","count":6},{"name":"Hackathon","count":5},{"name":"PD","count":5},{"name":"Rust","count":5},{"name":"TiDB Binlog","count":5},{"name":"TiDB Cloud","count":5},{"name":"TiDB Operator","count":5},{"name":"TiDB Operator 源码阅读","count":5},{"name":"TiSpark","count":5},{"name":"事务","count":5},{"name":"事务前沿研究","count":5},{"name":"新经济 DTC 转型","count":5},{"name":"DevCon","count":4},{"name":"Linux","count":4},{"name":"MySQL","count":4},{"name":"TiDB 易用性挑战赛","count":4},{"name":"TiKV 功能介绍","count":4},{"name":"分布式系统前沿技术","count":4},{"name":"备份恢复","count":4},{"name":"大促背后的数据库","count":4},{"name":"工具","count":4},{"name":"性能","count":4},{"name":"数据迁移","count":4},{"name":"Committer","count":3},{"name":"Go","count":3},{"name":"Kubernetes","count":3},{"name":"Percolator","count":3},{"name":"PingCAP 用户峰会","count":3},{"name":"Prometheus","count":3},{"name":"RocksDB","count":3},{"name":"TiDB Ecosystem Tools","count":3},{"name":"TiDB Serverless","count":3},{"name":"TiKV 源码阅读","count":3},{"name":"云原生","count":3},{"name":"分布式系统测试","count":3},{"name":"基础软件","count":3},{"name":"BR","count":2},{"name":"Cloud-TiDB","count":2},{"name":"Dumpling","count":2},{"name":"Flink","count":2},{"name":"K8s","count":2},{"name":"Key Visualizer","count":2},{"name":"MVCC","count":2},{"name":"PingCAP","count":2},{"name":"PingCAP 用户峰会","count":2},{"name":"Spanner","count":2},{"name":"TiDB 性能挑战赛","count":2},{"name":"TiDB-4.0","count":2},{"name":"TiUP","count":2},{"name":"WebAssembly","count":2},{"name":"gRPC","count":2},{"name":"优化器","count":2},{"name":"升级","count":2},{"name":"多业务融合","count":2},{"name":"带着问题读 TiDB 源码","count":2},{"name":"性能优化","count":2},{"name":"性能调优","count":2},{"name":"数据同步","count":2},{"name":"版本","count":2},{"name":"资源管控","count":2},{"name":"集群调度","count":2},{"name":"2PC","count":1},{"name":"AI","count":1},{"name":"Ansible","count":1},{"name":"CAP","count":1},{"name":"Chat2Query","count":1},{"name":"ChatGPT","count":1},{"name":"Cloud","count":1},{"name":"DNB","count":1},{"name":"Data Platform","count":1},{"name":"Database","count":1},{"name":"Database Branching","count":1},{"name":"Elasticsearch","count":1},{"name":"Failpoint","count":1},{"name":"Fintech","count":1},{"name":"Flink TiDB 物化视图","count":1},{"name":"GA","count":1},{"name":"Grafana","count":1},{"name":"HAProxy","count":1},{"name":"HTAP TiFlash","count":1},{"name":"Hadoop","count":1},{"name":"Horoscope","count":1},{"name":"Jepsen","count":1},{"name":"Kudu","count":1},{"name":"LSM-tree","count":1},{"name":"Lease Read","count":1},{"name":"Libbpf-tools","count":1},{"name":"Linearizability","count":1},{"name":"MPP","count":1},{"name":"Multi-Raft","count":1},{"name":"MySQL 架构演进","count":1},{"name":"NewSQL","count":1},{"name":"OpenAI","count":1},{"name":"OpenSource","count":1},{"name":"Oracle 迁移","count":1},{"name":"Partitioned Raft KV","count":1},{"name":"Partitioned-Raft-KV","count":1},{"name":"PiTR","count":1},{"name":"Redis","count":1},{"name":"Resource Control","count":1},{"name":"SMP","count":1},{"name":"SQL Plan Management","count":1},{"name":"SaaS","count":1},{"name":"Spark","count":1},{"name":"Syncer","count":1},{"name":"THP","count":1},{"name":"Talent Plan","count":1},{"name":"Test","count":1},{"name":"The Future of Database","count":1},{"name":"TiDB + Flink","count":1},{"name":"TiDB 4.0","count":1},{"name":"TiDB 4.0 捉虫竞赛","count":1},{"name":"TiDB Dashboard","count":1},{"name":"TiDB DevCon 2020","count":1},{"name":"TiDB Hackathon 2023","count":1},{"name":"TiDB 工具","count":1},{"name":"TiDB-DM","count":1},{"name":"TiDB-Lightning","count":1},{"name":"TiEM","count":1},{"name":"TiKV 性能优化","count":1},{"name":"TiPocket","count":1},{"name":"Tile","count":1},{"name":"Titan","count":1},{"name":"Tools","count":1},{"name":"futures","count":1},{"name":"java","count":1},{"name":"k8s","count":1},{"name":"knossos","count":1},{"name":"一致性","count":1},{"name":"主从","count":1},{"name":"全文检索","count":1},{"name":"内建函数","count":1},{"name":"分布式","count":1},{"name":"分布式SQL","count":1},{"name":"分布式事务","count":1},{"name":"分布式计算","count":1},{"name":"历史读","count":1},{"name":"可串行化","count":1},{"name":"合作伙伴生态","count":1},{"name":"在线 DDL","count":1},{"name":"垃圾回收","count":1},{"name":"备份","count":1},{"name":"多版本并发控制","count":1},{"name":"多租户","count":1},{"name":"大数据","count":1},{"name":"存储","count":1},{"name":"存储引擎","count":1},{"name":"安装部署","count":1},{"name":"容灾机制","count":1},{"name":"工程实践","count":1},{"name":"平凯数据库","count":1},{"name":"应用场景","count":1},{"name":"开源","count":1},{"name":"开源知识科普","count":1},{"name":"异构复制","count":1},{"name":"性能挑战赛","count":1},{"name":"悲观锁","count":1},{"name":"持续性能分析","count":1},{"name":"数字化转型","count":1},{"name":"数据分片","count":1},{"name":"数据库","count":1},{"name":"无锁快照","count":1},{"name":"智能制造","count":1},{"name":"服务可观察","count":1},{"name":"机器学习","count":1},{"name":"查询优化","count":1},{"name":"核心批量核算","count":1},{"name":"水平扩展","count":1},{"name":"测试","count":1},{"name":"测试工具","count":1},{"name":"混沌工程","count":1},{"name":"源码分析","count":1},{"name":"版本迁移","count":1},{"name":"用户实践","count":1},{"name":"监控","count":1},{"name":"线性一致","count":1},{"name":"自动化","count":1},{"name":"自动化测试","count":1},{"name":"计算","count":1},{"name":"调优","count":1},{"name":"调度","count":1},{"name":"跨数据中心","count":1},{"name":"运维","count":1},{"name":"金融","count":1},{"name":"隔离级别","count":1},{"name":"高并发","count":1}],"hotTags":[{"name":"TiDB","count":179},{"name":"社区","count":103},{"name":"TiKV","count":30},{"name":"社区动态","count":29},{"name":"TiDB 源码阅读","count":24},{"name":"TiKV 源码解析","count":21},{"name":"HTAP","count":20},{"name":"Release","count":17},{"name":"TiFlash","count":16},{"name":"Chaos Mesh","count":15},{"name":"TiDB Hackathon 2021","count":13},{"name":"Raft","count":11},{"name":"TiCDC","count":11},{"name":"TiDB 4.0 新特性","count":11},{"name":"DM 源码阅读","count":10},{"name":"Contributor","count":9},{"name":"TiDB Binlog 源码阅读","count":9},{"name":"TiFlash 源码阅读","count":9},{"name":"TiDB Hackathon 2022","count":8},{"name":"技术出海","count":8}]}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}