::43222/trace/df6bfbff` 就能获得该 SQL 所经过的源码文件和代码块信息。\n\n```\n// http://localhost:43222/trace/df6bfbff\n\n{\n \"sql\": \"show databases\",\n \"trace\": [\n {\n \"file\": \"executor/batch_checker.go\",\n \"line\": null\n },\n {\n \"file\": \"infoschema/infoschema.go\",\n \"line\": [\n [\n 113,\n 113\n ],\n [\n 261,\n 261\n ],\n //....\n }\n ],\n}\n```\nline 字段输出的每个二元组都是一个基本块的起始与结束行号(左闭右闭)。基本块的定义是绝对不会产生分支的一个代码块,也是我们统计的最小粒度。那是如何识别出 Go 代码中基本块的呢?其实工作量还挺大的,幸好 Go 的源码中有这一段,我们又刚好看到过,就把它裁剪出来,成为 [go-blockscanner](https://github.com/DQinYuan/go-blockscanner)。\n\n因为主要目标是正确性诊断,所以我们限定系统不对 TiDB 并发执行 SQL,这样就可以认为从 `server/conn.go:handleQuery` 方法被调用开始,到 SQLDebug 模块访问 trace 接口的这段时间所有被执行的基本块都是这条 SQL 的执行路径。当 SQLDebug 模块访问 HTTP 接口,将会同时删除该 SQL 相关的 trace 信息,避免内存被撑爆。\n\n### 基本块统计\n\nSQLDebug 模块在获取到每条 SQL 经过的基本块信息后,会对每个基本块建立如下的可视化模型。\n\n**首先是颜色,经过基本块的失败用例比例越高,基本块的颜色就越深。**\n\n\n\n\n**然后是亮度,经过基本块的失败用例在总的失败用例中占的比例越高,基本块的亮度越高。**\n\n\n\n已经有了颜色指标,为什么还要一个亮度指标呢?其实亮度指标是为了弥补“颜色指标 Score”的一些偏见。比如某个代码路径只被一个错误用例经过了,那么它显然会获得 Score 的最高分 1,事实上这条路径不那么有代表性,因为这么多错误用例中只有一个经过了这条路径,大概率不是错误的真正原因。所以需要额外的一个亮度指标来避免这种路径的干扰,**只有颜色深,亮度高的代码块,才是真正值得怀疑的代码块。**\n\n上面的两个模型主要是依据之前提到的 Visualization 的论文,我们还自创了一个文件排序的指标,失败用例在该文件中的密度越大(按照基本块),文件排名越靠前:\n\n\n\n前端拿到这些指标后,按照上面计算出的文件排名顺序进行展示,越靠前的文件存在问题的风险就越高。\n\n\n\n当点击展开后可以看到染色后的代码块:\n\n\n\n**我们经过一些简单的实验,文件级别的诊断相对比较准确,对于基本块的诊断相对还有些粗糙,这跟没有实现 SQLMin 有很大关系,毕竟 SQLMin 能去除不少统计时的噪声。**\n\n## 还能不能做点别的?\n\n看到这里,你可能觉得这个项目不过是针对数据库系统的自动化测试。而实际上借助代码自动调试的思路,可以给我们更多的启发。\n\n### 源码教学\n\n阅读和分析复杂系统的源码是个头疼的事情,TiDB 就曾出过 [24 篇源码阅读系列文章](https://pingcap.com/blog-cn/#TiDB-%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB),用一篇篇文字为大家解读源码,江湖人称 “二十四章经”。那么是否可以基于源码的可视化跟踪做成一个通用工具呢?这样在程序执行的同时就可以直观地看到代码的运行过程,对快速理解源码一定会大有帮助。更进一步,配合源码在线执行有没有可能做成一个在线 web 应用呢?\n\n### 全链路测试覆盖统计\n\n语言本身提供的单测覆盖统计工具已经比较完备了,但一般测试流程中还要通过 e2e 测试、集成测试、稳定性测试等等。能否用本文的方法综合计算出各种测试的覆盖度,并且与 CI 系统和自动化测试平台整合起来。利用代码染色技术,还可以输出代码执行的热力图分析。结合 profiler 工具,是不是还可以辅助来定位代码的性能问题?\n\n\n\n### Chaos Engineering\n\n在 [PingCAP](https://pingcap.com/) 内部有诸多的 [Chaos](https://www.infoq.cn/article/EEKM947YbboGtD_zQuLw) 测试平台,用来验证分布式系统的鲁棒性,譬如像 [Jepsen](https://github.com/jepsen-io/jepsen) ,还有 PingCAP 自研的薛定谔稳定性测试系统等。混沌工程测试比较困扰的一点是,当跑出问题之后想再次复现就很难,只能通过当时的情形去猜代码可能哪里有问题。如果能在程序运行时记录代码的执行路径,根据问题发生时间点附近的日志和监控进一步缩小范围,再结合代码执行路径分析就能精确快速的定位到问题的原因。\n\n### 与分布式 Tracing 系统集成\n\nGoogle 有一篇论文是介绍其内部的 [分布式追踪系统 Dapper](https://ai.google/research/pubs/pub36356) ,同时社区也有比较出名的项目 [Open Tracing](https://opentracing.io/) 作为其开源实现,Apache 下面也有类似的项目 [Skywalking](https://skywalking.apache.org/)。一般的 Tracing 系统主要是跟踪用户请求在多个服务之间的调用关系,并通过可视化来辅助排查问题。但是 Tracing 系统的跟踪粒度一般是服务层面,如果我们把 `trace_id` 和 `span_id` 也当作标注传递给代码块进行打桩,那是不是可以在 Tracing 系统的界面上直接下钻到源码,听起来是不是特别酷?\n\n## 接下来的工作\n\n因为 Hackathon 时间有限,我们当时只完成了一个非常简单的原型,距离真正实现睡觉时程序自动查 bug 还有一段路要走,我们计划对项目持续的进行完善。\n\n接下来,首先要支持并行执行多个测试用例,这样才能在短时间得到足够多的实验样本,分析结果才能更加准确。另外,要将注入的代码对程序性能的影响降低到最小,从而应用于更加广泛的领域,比如性能压测场景,甚至在生产环境中也能够开启。\n\n看到这里可能你已经按耐不住了,附上 [项目的完整源码](https://github.com/fuzzdebugplatform/fuzz_debug_platform),Welcome to hack!","date":"2019-12-03","author":"我和我的 SQL 队","fillInMethod":"writeDirectly","customUrl":"sqldebug-automatically","file":null,"relatedBlogs":[]},{"id":"Blogs_154","title":"TiDB Hackathon 2019 — 流量和延迟减半!挑战 TiDB 跨数据中心难题","tags":["跨数据中心","Hackathon"],"category":{"name":"社区动态"},"summary":"我们针对 TiDB 跨数据中心方案做了一些优化,使得跨地域 SQL 查询延迟下降 50%,跨节点消息数减半,即网络流量减半。","body":">作者介绍:.* team(成员:庄天翼、朱贺天、屈鹏、林豪翔)参加了 [TiDB Hackathon 2019](https://pingcap.com/community-cn/hackathon2019/),他们项目「TiDB 跨数据中心方案的优化」斩获了二等奖。\n\n众所周知,在对可用性要求极高的行业领域(比如金融、通信),分布式数据库需要跨地域的在多个数据中心之间建立容灾以及多活的系统架构,同时需要保持数据完整可用。但这种方式同时也带来了一些问题:\n\n1. 跨地域的网络延迟非常高,通常在几十毫秒左右,洲际间更能达到几百毫秒。\n2. 跨地域的网络专线带宽昂贵、有限,且难于扩展。\n\n在今年 TiDB Hackathon 的比赛过程中,我们针对以上问题做了一些有趣的事情,并获得如下优化成果:\n\n1. 跨地域 SQL 查询,延迟下降 50%(图 1)。\n2. 跨节点消息数减半,即网络流量减半(图 2)。\n\n\n\n图 1 延迟对比
\n\n\n\n图 2 网络流量对比
\n\n>“Google Spanner 高性能事务和强一致特性(跨区域甚至跨洲),是每一个做多数据中心架构设计的工程师心中所向往的目标。虽然当前 TiDB 在多数据中心部署时的表现同 Google Spanner 还有明显的差距,但我们很高兴的看到“多数据中心读写优化”项目让 TiDB 向 Spanner 级别多数据中心能力迈出了坚实的一步。相信在社区小伙伴们的共同努力下,假以时日 TiDB 一定能够为大家带来 Google Spanner 级别的体验。”\n>\n>—— 孙晓光(知乎|技术平台负责人)\n>\n>“在官方推荐的具备同城多活能力的同城三中心五副本,以及两地三中心五副本的部署方案中,三个数据中心按照 2:2:1 的方式分配副本,网络租用成本是该架构的主要投入,我们在一次压力测试过程中,曾遇到过在极致的压力下占满网络带宽的情况。这个项目显著优化了两机房之间的带宽占用,可以为客户节约更多的成本。”\n>\n>—— 秦天爽(PingCAP|技术支持总监)\n\n接下来我们将从技术原理分析是如何做到以上优化效果的。以下内容需要读者具备 [Raft 一致性协议](https://raft.github.io/) 的一些预备知识,如果大家准备好了,就继续往下看吧~\n\n## 技术原理\n\n考虑一个两数据中心的部署方案(如图 3 所示),左半部分为主数据中心(Master DC,假设在北京)TiKV 和 PD 的多数副本都部署在这里,并且很重要的是 Leader 会被固定在这里;图 3 右半部分为从数据中心(Slave DC,假设在西安)里面有 TiKV 和 TiDB。用户只会在主数据中心进行数据写入,但会在两边都进行数据读取。\n\n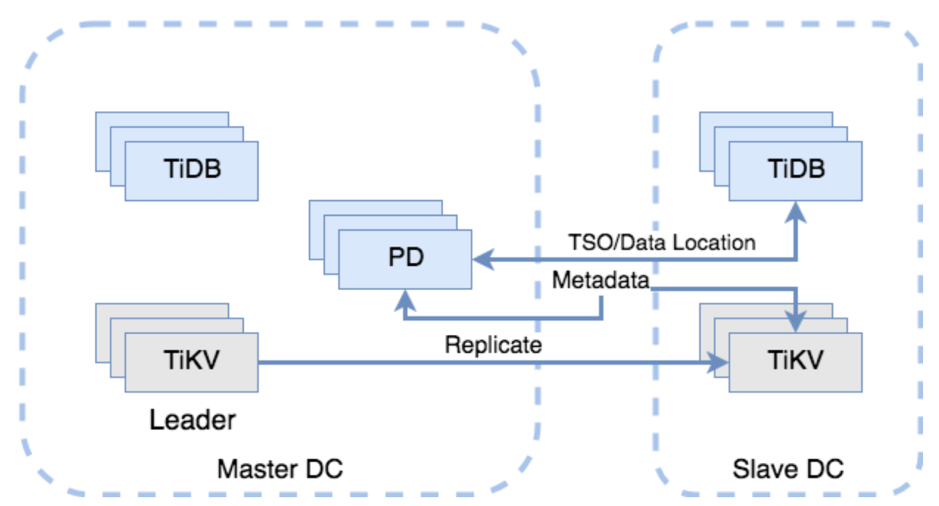\n\n图 3 主数据中心 & 从数据中心部署
\n\n### Follower Read Improvement\n\n在 TiDB 里面,当我们需要从西安这边读取数据的时候,一个典型的流程如下:\n\n1. 西安的 TiDB 向北京的 PD 发起获取 TSO 请求,得到一个 `start_ts`(事务开始阶段的 ID)。(1 RTT)\n\n2. 西安的 TiDB 为涉及到的每个 Region 向北京的 TiKV Leader 节点发起多个(并行)读请求(如图 4)。(1 RTT)\n\n>名词解释:\n>\n>* RTT(Round-Trip Time),可以简单理解为发送消息方从发送消息到得知消息到达所经过的时间。\n>* TSO(Timestamp Oracle),用于表示分布式事务开始阶段的 ID。\n\n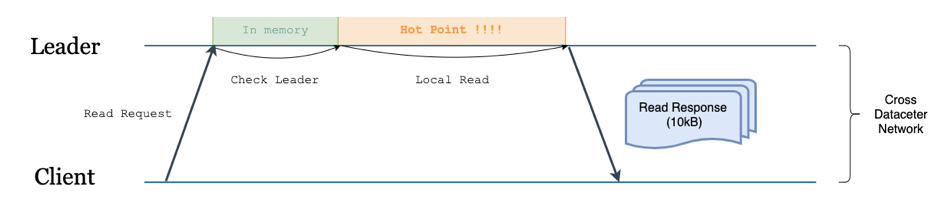\n\n图 4 不启用 Follower Read 的读流程
\n\n可以看到,虽然西安本地也有 TiKV 副本数据,但完全没有参与这个过程。该实现存在两个问题:\n\n* 跨地域网络宽带占用大。\n\n* 延迟高(2 RTT)。\n\n下面我们分别阐述对这两个问题的优化思路。\n\n#### 1. 跨地域网络宽带占用大\n\n其实针对这个问题,TiDB 已经在 3.1 版本引入了 [Follower Read](https://pingcap.com/blog-cn/follower-read-the-new-features-of-tidb/) 特性。开启该特性后,TiKV Leader 上的节点从必须处理整个读请求改为只用处理一次 read_index 请求(一次 read_index 通常只是位置信息的交互,不涉及数据,所以轻量很多),负载压力大幅降低,是一个很大的优化,如下图所示。\n\n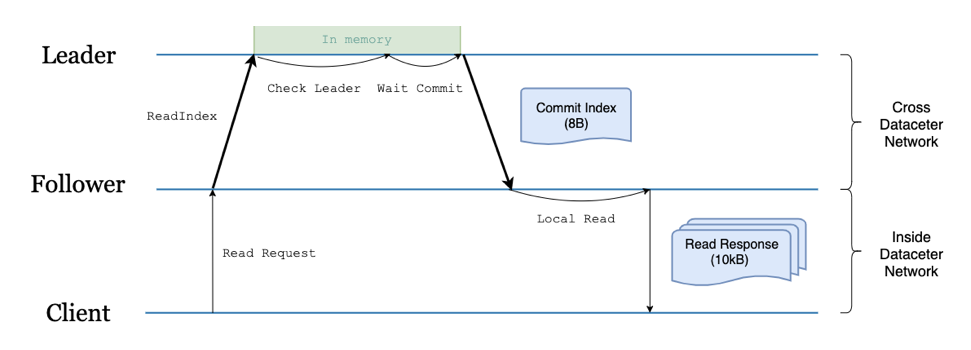\n\n图 5 开启 Follower Read 的读流程
\n\n#### 2. 延迟高\n\n在读延迟上,TiDB 仍然需要 2 个跨地域的 RTT。这两个 RTT 的延迟是由一次获取 TSO 请求和多次(并行的)`read_index` 带来的。简单观察后,我们不难发现,我们完全可以将上面两个操作并行一起处理,如下图所示。\n\n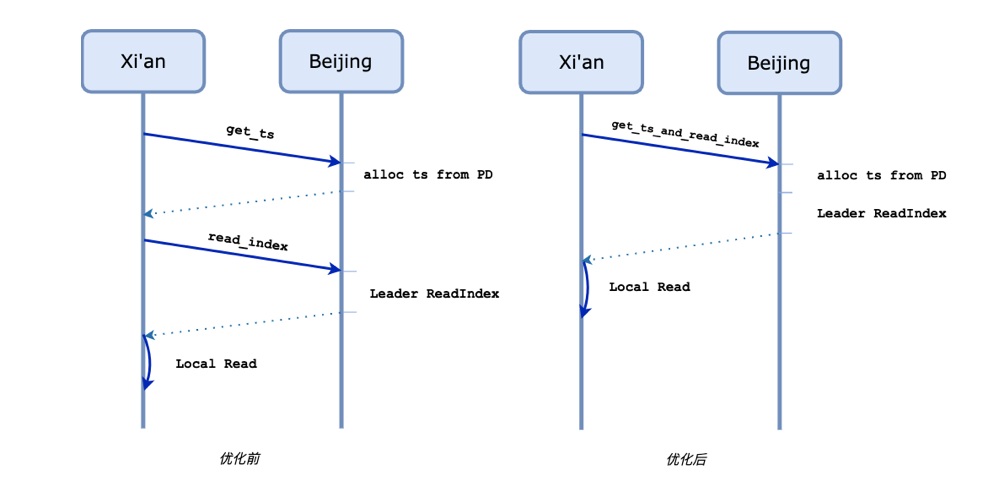\n\n图 6 Follower Read 流程优化
\n\n通过这种优化方式,我们实现了跨数据中心读请求 2RTT -> 1RTT 的提升,并且我们在模拟的高延迟网络环境中的 benchmark 证实了这一点:\n\n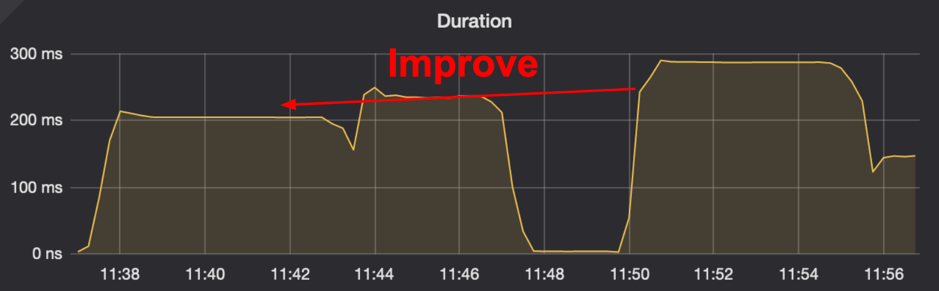\n\n图 7 benchmark
\n\n考虑到没有原子钟的情况下想要保证线性一致性,一次获取 TSO 的请求是无法避免的,因此可以认为 1RTT 已经是在目前的架构下最优的解决方案了。\n\n### 用 Follower Replication 减少带宽成本\n\n接下来谈一谈如何用 Follower Replication 这种方式,减少跨数据中心的带宽成本。\n\n众所周知 TiKV 集群中的一致性是依靠 Raft 协议来保证的。在 Raft 协议中,所需要被共识一致的数据可以用 Entry 来表示。一个 Entry 被共识,需要 Leader 在接收到请求之后,广播给其他 Follower 节点,之后通过不断的消息交互来使这个 Entry 被 commit。这里可能会遇到一个问题:有些时候 TiKV 被部署在世界各地不同的数据中心中,数据中心之间的网络传输成本和延迟比较高,然而 Leader 只有一个,可想而知会发生很多次跨数据中心的消息传输。\n\n举个例子,生产环境中可能需要 5 个副本来保证可用性,假设 3 个副本在北京分别是 A B C,2 个在西安分别是 D E,同时 Leader 为 A,那么一条 Entry 需要北京的 Leader A,广播给西安的 DE,那么这次广播至少需要两次跨数据中心的网络传输,如下图所示。\n\n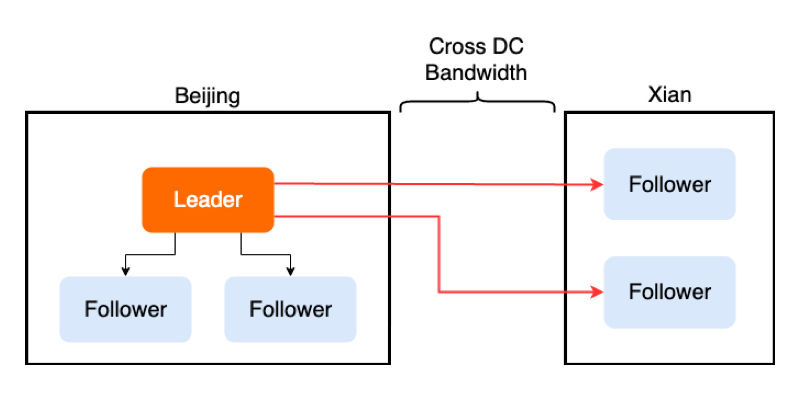\n\n图 8 正常的消息广播
\n\nFollower Replication 的目标是将这个多次的跨数据中心传输尽量减少。要实现 Follower Replication,最关键的是需要让 Leader 节点知道所有 Raft 节点与它所在的 数据中心的信息。这里我们引入了一个新概念 Group,每一个 Raft 节点都有一个对应的 Group ID,拥有相同 Group ID 的节点即在同一个数据中心中。既然有了每个 Raft 节点的 Group 信息,Leader 就可以在广播消息时在每一个 Group 中选择一个代理人节点(我们称为 Follower Delegate),将整个 Group 成员所需要的信息发给这个代理人,代理人负责将数据同步给 Group 内的其他成员,如下图所示。\n\n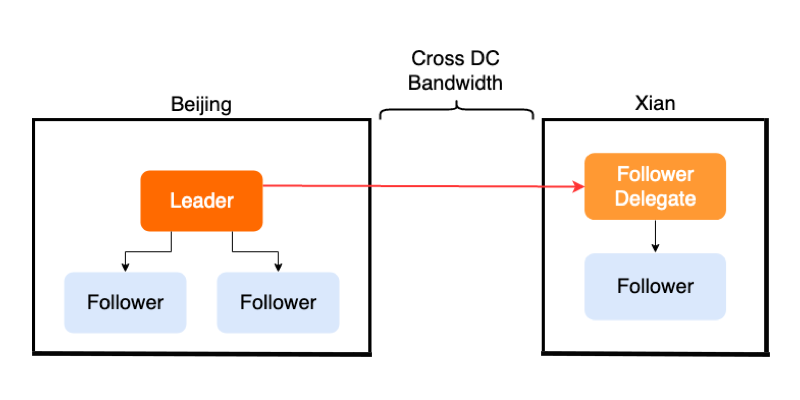\n\n图 9 选择代理人之后的消息广播
\n\n通过使用 Follower Replication,Leader 减少了一半的数据发送,既大大降低了跨数据中心带宽的压力,同时也减少了 Leader 在发送网络消息上的开销。当然,实际 Follower Replication 的实现还是很复杂的,我们后续会专门写一篇详细的文章来介绍。\n\n关于这个对 Raft 实现的改进,我们已经提交了 RFC 和实现的 PR,后续也会贡献给 etcd,感兴趣的同学可以参考:\n\n* [https://github.com/tikv/rfcs/pull/33](https://github.com/tikv/rfcs/pull/33)\n\n* [https://github.com/tikv/raft-rs/pull/249/](https://github.com/tikv/raft-rs/pull/249/)\n\n* [https://github.com/etcd-io/etcd/issues/11357](https://github.com/etcd-io/etcd/issues/11357)\n\n## 总结\n\n除了我们在 Hackathon 做的两个优化,跨数据中心的场景有更多需要解决的问题和可以优化的点,我们的优化也远非最终实现,一些不难想到的优化还有:\n\n1. Follower Read Improvement 能将一个非交互式的读事务从 2RTT 降到 1RTT,但对于交互式的读事务,由于事先不知道涉及到事务的 Region,无法预读整个读请求中所有 Region `read_index`,因此只有第一次读请求和 `get_tso` 可以并行,将 n+1 RTT 优化到了 n RTT(n 为交互式事务中读语句的数量),而如果我们能将 ts 和 committed index 的对应关系找到,并且定期维护每个 Region 的 safe ts(小于该 ts 的事务一定已经 committed or aborted),那么我们就可以将交互式读事务的延迟也降低到 1RTT。\n\n2. 跨数据中心的读请求一个很常见的场景是并不需要是最新的数据,应该提供怎么样的语义来让这种场景下的读请求完全在本地 0RTT 地读取数据,真正做到对主数据中心无依赖,做到数据中心级别的 scalability。\n\n有句话是这样说的,“对于基础架构方向的软硬件工程师而言,世界上最远的距离,是你在联通,我在电信 :D”软件工程师做得越好,秃顶的硬件工程师就越少。希望我们的项目在切实落地之后,能够大幅优化 TiDB 跨地域数据中心的延迟和网络流量,让 TiDB 能够满足更多用户的需求,成为分布式数据库领域的事实标准。","date":"2019-11-29","author":".* team","fillInMethod":"writeDirectly","customUrl":"geographic-data-distribution-traffic-and-latency-halved","file":null,"relatedBlogs":[]},{"id":"Blogs_144","title":"TiKV Engine SIG 成立,硬核玩家们看过来!","tags":["TiKV","社区","存储引擎"],"category":{"name":"社区动态"},"summary":"TiKV Engine SIG 主要职责是对 TiKV 的存储引擎的未来发展进行讨论和规划,并进行相关开发和维护。期待社区伙伴们的支持和贡献~","body":"TiKV 是一个开源项目,我们一直都欢迎和感激开源社区对 TiKV 所作出的贡献。但我们之前对开源社区的合作主要是在代码审阅和散落在各种社交媒体的线下讨论,开发者并没有合适的途径去了解和影响 TiKV 的开发计划。怎么才能更好的帮助大家找到组织,更好地参与到 TiKV 的开发中来呢?我们的设想是搭建公开的平台,邀请对 TiKV 中特定领域感兴趣的开发者加入其中,与我们一起探讨和推进相应工作。Special Interest Group(SIG)就是这样的平台。\n\nTiKV Engine SIG 是继 [Coprocessor SIG](https://pingcap.com/blog-cn/tikv-coprocessor-sig/) 之后成立的第二个 TiKV SIG 社区组织,主要职责是对 TiKV 的存储引擎的未来发展进行讨论和规划,并进行相关开发和维护。\n\n目前 TiKV 仅支持默认存储引擎 RocksDB,但是通过扩展接口,希望未来 TiKV 可以支持更多的存储引擎,我们也期待这部分工作可以得到社区的支持,在社区的讨论和贡献中得到更好的完善。此外,Engine SIG 也会对已有的存储引擎进行相关的开发和完善工作。\n\nEngine SIG 的工作主要涉及的模块包括:\n\n* Engine Trait: TiKV 中存储引擎的抽象层。\n* RocksDB:包括维护 TiKV 所使用的 RocksDB 分支,以及 rust-rocksdb 封装。\n* Titan:提供 KV 分离支持的 RocksDB 存储引擎插件。\n* 未来 TiKV 对其它存储引擎的支持。\n\n## 如何加入 Engine SIG\n\n无论你是数据库开发新手,希望通过实战了解存储开发相关知识;还是 TiKV 资深用户,希望扩展 TiKV 的能力以应用到生产环境,Engine SIG 都欢迎你的加入!\n\n有兴趣的开发者可以浏览 Engine SIG 文档并加入 Engine SIG 的 Slack 频道。Engine SIG 希望能够帮助 Contributor 逐渐成长为 Reviewer,Committer 乃至 TiKV 的 Maintaner。\n\n* Engine SIG 主页:[https://github.com/tikv/community/tree/master/sig/engine](https://github.com/tikv/community/tree/master/sig/engine)\n\n* Engine SIG 章程:[https://github.com/tikv/community/blob/master/sig/engine/constitution-zh_CN.md](https://github.com/tikv/community/blob/master/sig/engine/constitution-zh_CN.md)\n\n* Engine SIG Slack:加入 tikv-wg.slack.com 并进入 [#engine-sig](https://tikv-wg.slack.com/?redir=%2Fmessages%2Fengine-sig) 频道。\n\n## 近期工作计划\n\n近期 Engine SIG 工作会围绕在对 TiKV 已有存储引擎的改进上面,但我们会尽量选取一些对以后引入其它存储引擎也有意义的工作。具体有以下几方面:\n\n* 使用 [Bindgen](https://rust-lang.github.io/rust-bindgen/) 对 [rust-rocksdb](https://github.com/tikv/rust-rocksdb) 进行重构,减少新增存储引擎接口的开发复杂度。\n* 扩展 [failpoint](https://pingcap.com/blog-cn/tikv-source-code-reading-5/) 接口,允许为不同的存储引擎开发相应的插件,使得 TiKV 测试能够对存储引擎内部进行错误注入。\n* [Titan](https://github.com/pingcap/titan) 存储引擎插件的性能和功能的改进。\n\n详细任务列表见:[https://github.com/tikv/tikv/projects/22](https://github.com/tikv/tikv/projects/22)。\n\n## 未来工作计划\n\n未来 Engine SIG 会更多关注于为 TiKV 引入新的存储引擎。这上面可以做的工作很多。比如说,我们可以考虑为 TiKV 引入针对不同硬件(纯内存、持久化内存、云盘等)的存储引擎,不同数据结构的存储引擎(B-Tree 引擎等),针对特殊场景的存储引擎(全文搜索等),或者单纯是不一样的存储引擎实现(LevelDB 等)。这些工作非常需要社区的参与。我们希望这些工作未来能够扩展 TiKV 的领域和可能。目前 TiKV 正在加紧对存储引擎抽象 Engine Trait 进行开发,使以上的设想成为可能。\n\n期待社区伙伴们的加入!欢迎在 Slack [#engine-sig](https://tikv-wg.slack.com/?redir=%2Fmessages%2Fengine-sig) 中与我们交流!如果对于流程或技术细节有任何疑问,都可在 channel 中讨论~","date":"2019-11-28","author":"Yi Wu","fillInMethod":"writeDirectly","customUrl":"tikv-engine-sig-introduction","file":null,"relatedBlogs":[]},{"id":"Blogs_149","title":"开源社区怎么玩?明星项目 TiKV 的 Maintainer 这样说……","tags":["社区","社区动态"],"category":{"name":"社区动态"},"summary":"“当你持续的认真投入到开源后,项目和社区就会产生双向的交流,不再只是你单向的投入,社区也会给予你反哺,这时就会形成正向循环,对项目发展会起到非常大的推动作用。”","body":"知乎技术平台团队负责人孙晓光有一个新的身份:开源分布式事务 Key-Value 数据库 TiKV项目的 Maintainer。Maintainer 是 TiDB/TiKV 开源社区的角色之一,是社区中较高级别的代码贡献者,项目的规划和设计者,拥有合并主干分支的权限。一般来说从开始贡献代码的 Contributor 成长为 Maintainer,最明显的变化是,对项目有更全局、深入的了解,对项目未来的发展也有独到、准确的见解。\n\n孙晓光觉得,其实从 Contributor 到 Committer 再到最后成为 Maintainer 这个过程,最大的感受是自己逐渐融入到了 TiKV 社区中,真正有了归属感。今天我们就带着 TiDB/TiKV 社区伙伴们的期待,和孙晓光聊了聊,打探了一下他成为 Maintainer 的经历,以及对 TiKV 社区未来的想法。\n\n## 初识:寻找原生的分布式存储方案\n\n***> 与 TiKV 项目初识,其实是带着明确的目标的。***\n\n孙晓光 2007 年毕业回国,当时国内刚开始做云,他进入一家做私有云的公司,从事私有云相关产品开发工作 7 年多时间,他坦言,这段工作经历让他个人积累了许多云相关底层系统的工作经验,这也是他对平台类技术比较感兴趣的核心原因。2017 年孙晓光加入知乎。\n刚到知乎时,他负责已读服务的开发,知乎的存储层采用的还是 MySQL 分库分表技术方案。“项目上线后,就我个人而言是难以接受这种方案的,于是我就开始寻找原生的分布式存储系统来替代它。借此机会我尝试了 TiKV,在测试的过程中我发现一些性能有改善的空间,于是我就边测试边上手做了一些优化工作,最后提了一个大 PR 上去。PR 提出后,PingCAP 首席架构师唐刘很快就跟我建立了联系,慢慢的我也进入到了 TiKV 社区当中。这就是我第一次接触 TiKV 的经历。”\n\n## 更加理解「开源社区」\n\n\n***> 我对开源社区的理解更加清晰了。***\n\n孙晓光以前也用过很多开源软件,但是当时并没有深刻理解开源的价值。**开源的第一目标应该是对别人有帮助、有价值,这个目标就已经拦住了无数的开源项目**。很多项目仅仅把代码开放出来,但是没有任何后续的支持与维护,在这样的情况下社区是无法发展的,自然也难以为他人创造价值。\n\n\n\n“**其实当你持续的认真投入到开源后,项目和社区就会产生双向的交流,不再只是你单向的投入,社区也会给予你反哺,这时就会形成正向循环,对项目发展会起到非常大的推动作用**。我对开源的理解正是在 TiKV 社区慢慢建立起来的,TiKV 有一个非常开放友好的社区,PingCAP 和社区伙伴们热心的帮助及鼓励让我切身感受到活跃的开源社区所具有的独特魅力。在参与共建社区的过程中,我不但学习到了如何同开源社区中众多优秀的贡献者更加高效的交流,同时也对开源的价值理念和开源在基础软件领域的重大意义有了更加深入的理解。”\n\n## 「持续贡献,长期活跃」的动力何在?\n\n***> 硬核的项目 + 开放的氛围***\n\n过去多年在云方向的工作经历让孙晓光坚定的相信,云是未来的趋势,而 TiKV 作为云原生架构中承载状态的基石组件,它的重要程度毋庸置疑。作为一个技术控,TiKV 这样一个既硬核口碑又很好的项目很自然地吸引着他。同时 TiKV 社区互帮互助、开放共赢的良好氛围也是孙晓光持续参与社区建设的重要动力。\n\n“之前也为其他开源项目做过贡献,可能是这些项目对社区建设并没有投入太多精力,大部分的 PR 合并完成就没有后续了。但是在 TiKV 社区,我感受到当我参与社区后,后续会有很多追踪的动作,这会激励我保持兴趣,持续在社区中去做贡献。同时在这个过程中,我也在社区中学习了很多知识,得到了很多帮助,这也是我长期坚持在 TiKV 社区中保持活跃的一个重要原因。”\n\n迄今为止,孙晓光已经为 TiDB/TiKV 项目贡献了 18 个 PR,[推动了 TiKV 重要功能 Follower Read 的开发和落地](https://pingcap.com/blog-cn/zhihu-the-story-of-contributing-to-tidb-community/),这个功能同时也解决了知乎业务场景中极端热点数据访问的吞吐问题。他在一年中完成了 Contributor -> Committer -> Maitainer 的角色升级,可谓是开挂式的速度,但他并没有就此止步,而是开启了一个新的挑战。\n\n## 新的挑战\n\n今天 TiKV Engine SIG(SIG = Special Interest Group)正式成立,这是 TiKV 项目成立的第二个 SIG 社区组织,孙晓光将作为第一个非 PingCAP 的 SIG TechLead,将与其他 TechLead 一起,组织大家推动 TiKV Engine 的相关开发和完善。\n\n对于 TiKV Engine SIG,孙晓光非常兴奋。\n\n“我认为 TiKV 非常适合 SIG 这个模式,因为 TiKV 是一个非常庞大且复杂的系统,进入的门槛很高,并且它还在以飞快的速度继续演进着。在这样一个庞大的系统里,想让大家参与进来其实是非常有难度的。**但 SIG 可以为大家创造一个更容易参与的小环境,且在这个小环境中是有组织有领导的,有人会帮助大家指方向,指导大家要做什么样的事情,这样一方面降低社区参与 TiKV 建设的门槛,另外一方面也可以更好的将对特定领域有经验且感兴趣的伙伴们聚集起来,高效的推进 TiKV 每一个关键方向的前进速度。**\n\n在我个人看来,存储引擎是 TiKV 中最关键的组件之一,它影响着整个系统的稳定性、功能特性以及性能表现。相信 Engine SIG 成立后,我们可以清晰的定义存储引擎同 TiKV 其它部分的契约,提供强大且易用的存储引擎抽象,借助 TiKV 完备的分布式能力,我们可以为 TiKV 拓展更多的领域和可能。”\n\nTiKV Engine SIG 是主要职责是对 TiKV 的存储引擎的未来发展进行讨论和规划,并进行相关开发和维护。目前 TiKV 仅支持默认存储引擎 RocksDB,但是通过扩展接口,希望未来 TiKV 可以支持更多的存储引擎。近期 Engine SIG 的工作会围绕在对 TiKV 已有存储引擎的改进上面。\n\n>*关于 TiKV Engine SIG 的更多信息,感兴趣的朋友们可以查看 [这篇文章](https://pingcap.com/blog-cn/tikv-engine-sig-introduction),也可以加入 Slack [#engine-sig](https://tikv-wg.slack.com/?redir=%2Fmessages%2Fengine-sig\n) 和孙晓光等社区伙伴们一起讨论。*\n\n## 期望\n\n作为 TiKV & TiDB 重度粉丝,孙晓光希望在未来能更好的促进「知乎」和 TiKV 社区的共建。一方面依托 TiKV 社区的进步为「知乎」的业务发展提供更好的支撑基础,同时希望能够基于「知乎」的业务场景为 TiKV 的发展提供足够大的施展空间。\n\n“我非常希望我们的团队也能够真正参与进来,成为社区的贡献者。相信未来 TiKV 能够保持开放共赢的风格,建设更成熟更大规模的社区。我们这些社区伙伴会一起推动 TiKV 的高速持续发展,让 TiKV 成为未来有状态系统基石的第一选择。” \n\n\n>\n>\n>TiKV 是一个开源的分布式事务 Key-Value 数据库,支持跨行 ACID 事务,同时实现了自动水平伸缩、数据强一致性、跨数据中心高可用和云原生等重要特性。作为一个基础组件,TiKV 可作为构建其它系统的基石。目前,TiKV 已用于支持分布式 HTAP 数据库—— TiDB 中,负责存储数据,并已被多个行业的领先企业应用在实际生产环境。2019 年 5 月,CNCF 的 TOC(技术监督委员会)投票决定接受 TiKV 晋级为孵化项目。\n>\n>源码地址:https://github.com/tikv/tikv\n>\n>更多信息:https://tikv.org","date":"2019-11-28","author":"PingCAP","fillInMethod":"writeDirectly","customUrl":"tikv-maintainer-sunxiaoguang","file":null,"relatedBlogs":[]},{"id":"Blogs_28","title":"十分钟成为 Contributor 系列 | 为 Cascades Planner 添加优化规则","tags":["TiDB","社区","Contributor","优化器"],"category":{"name":"社区动态"},"summary":"我们将这个系列再向着数据库的核心前进一步,挑战一下「为 TiDB 的优化器增加优化规则」,带大家初步体验一下可以对查询的执行时间产生数量级影响的优化器的魅力。","body":"到今天为止,“成为 Contributor 系列”已经推出了 “[支持 AST 还原为 SQL](https://pingcap.com/blog-cn/support-ast-restore-to-sql-text/)”,“[为 TiKV 添加 built-in 函数](https://pingcap.com/blog-cn/30mins-become-contributor-of-tikv/)”,“[向量化表达式](https://pingcap.com/blog-cn/10mins-become-contributor-of-tidb-20190916/)”等一列活动。**这一次借着 TiDB 优化器重构的契机,我们将这个系列再向着数据库的核心前进一步,挑战一下「为 TiDB 的优化器增加优化规则」,带大家初步体验一下可以对查询的执行时间产生数量级影响的优化器的魅力。**\n\n众所周知优化器是数据库的核心组件,需要在合理的时间内寻找到一个合理的执行计划,确保查询可以稳定快速地返回正确的结果。最初的优化器只有一些启发式的优化规则,随着数据量和业务的变化,业界设计出了 System R 优化器框架来处理越来越多的复杂 SQL 查询。它将查询优化分为逻辑优化和物理优化两个阶段,逻辑优化根据规则对执行计划做等价变形,物理优化则根据统计信息和代价计算将逻辑执行计划转化为能更快执行的物理计划。目前 TiDB 优化器采用的也是该优化器模型。\n\n虽然 System R 优化器框架大大提升了数据库处理复杂 SQL 的能力,但也存在一定缺陷,比如:\n\n1. 扩展性不好。每次添加优化规则都需要考虑新的规则和老的规则之间的关系,需要对优化器非常了解的同学才能准确判断出新的优化规则应该处在什么位置比较好。另外每个优化规则都需要完整的遍历整个逻辑执行计划,添加优化规则的心智负担和知识门槛非常高。\n\n2. 搜索空间有限。搜索空间一方面因为优化规则难以添加导致比较狭小,另一方面,逻辑优化要求该优化规则一定在各个场景下都有收益才行,但在数据库面临的各种场景中,总有一些优化规则在某种数据分布下有收益,在另一种数据分布下没有收益,需要根据数据的分布估算代价来判断是否启用这些优化规则,因为这个原因,进一步导致一些优化规则不能添加到这个搜索框架中,或者添加后需要人工的通过开关来开启或关闭该优化规则。\n\n为了解决上面的问题,更方便地添加优化规则,扩展优化器搜索空间,寻找更优的执行计划,我们基于 Cascades 优化器模型重新写了一个新的优化器,名字就叫 Cascades Planner。在这个优化器框架下,添加优化规则变得异常简单:\n\n1. 不用考虑优化规则之间的顺序关系,规则和规则之间完全解耦。\n\n2. 只针对特定的模式添加优化规则,不再需要遍历整个逻辑执行计划,不用熟知所有逻辑算子的功能,极大的降低了优化器的开发门槛。\n\n在这篇文章中,我们主要聚焦在一条优化规则是如何工作以及如何给新优化器添加规则上,先让大家对这个优化器有一个直观的感受——“优化器没什么难的,不过如此”。下一篇文章,我们将更加详细的介绍 TiDB Cascades Planner 的原理和框架,供感兴趣的同学深入研究,如果大家等不及的话,可以先阅读下面的参考文献,提前了解一下 Cascades 优化器模型:\n\n1. [The Cascades Framework for Query Optimization](https://15721.courses.cs.cmu.edu/spring2018/papers/15-optimizer1/graefe-ieee1995.pdf)\n\n2. [Orca: A Modular Query Optimizer Architecture for Big Data](https://15721.courses.cs.cmu.edu/spring2016/papers/p337-soliman.pdf)\n\n3. [CMU SCS 15-721 (Spring 2019) : Optimizer Implementation (Part II)](https://15721.courses.cs.cmu.edu/spring2019/slides/23-optimizer2.pdf)\n\n## Cascades 优化器简介\n\nCascades 优化器是 Goetz Graefe 在 [volcano optimizer generator](https://cs.uwaterloo.ca/~david/cs848/volcano.pdf) 的基础上优化调整之后诞生的一个搜索框架。这个框架有如下一些概念:\n\n* Expression:原论文中,Expression 用来指代包括 Plan 节点(也就是大家常说的的 SQL 算子)以及各种函数表达式(例如 MySQL 支持的 200 多个内置函数)在内的所有表达式。在 TiDB 现有框架实现中,只将 Plan 节点视作 Expression。Expression 大多会包含子节点,但每个子节点并不是一个 Expression ,而是一组等价的 Expression 集合,也就是接下来要介绍的 Group。\n\n* Group:表示等价 Expression 的集合,即同一个 Group 中的 Expression 在逻辑上等价。Expression 的每个子节点都是以一个 Group 表示的。在下文图例中,Group `G0` 中包含谓词下推前后的两个等价 Expression。\n\n* Transformation Rule:是作用于 Expression 和 Group 上的等价变化规则,用来扩大优化器搜索空间,也是本次要重点介绍的模块。下图 Group `G0` 中的第二组 `Expression` 便是第一组 `Expression` 经过了一个谓词条件(Filter)下推过连接(Join)的 Transformation Rule 之后新产生的 `Expression`。\n\n* Pattern:描述一个执行计划的片段,注意这个 “片段” 不是 “子树”。这个片段可以是执行计划算子树中任意一段。每一个 Transformation Rule 都拥有自己的 Pattern,表示该 Rule 只作用于满足这个 Pattern 的 Expression。\n\n* Implementation Rule:将一个逻辑算子转换成物理算子的规则。如一个 Join 可以被转换成 HashJoin、MergeJoin、IndexNestedLoopJoin 等。每一个转换都由一个对应的 Implementation Rule 完成。\n\n以查询 `select * from t1 join t2 on t1.a = t2.a where t1.b > 1` 为例,在经过 Cascades 优化器的谓词下推这一 Transformation Rule 后,搜索空间中的 Group 和 Expression 会是如下:\n\n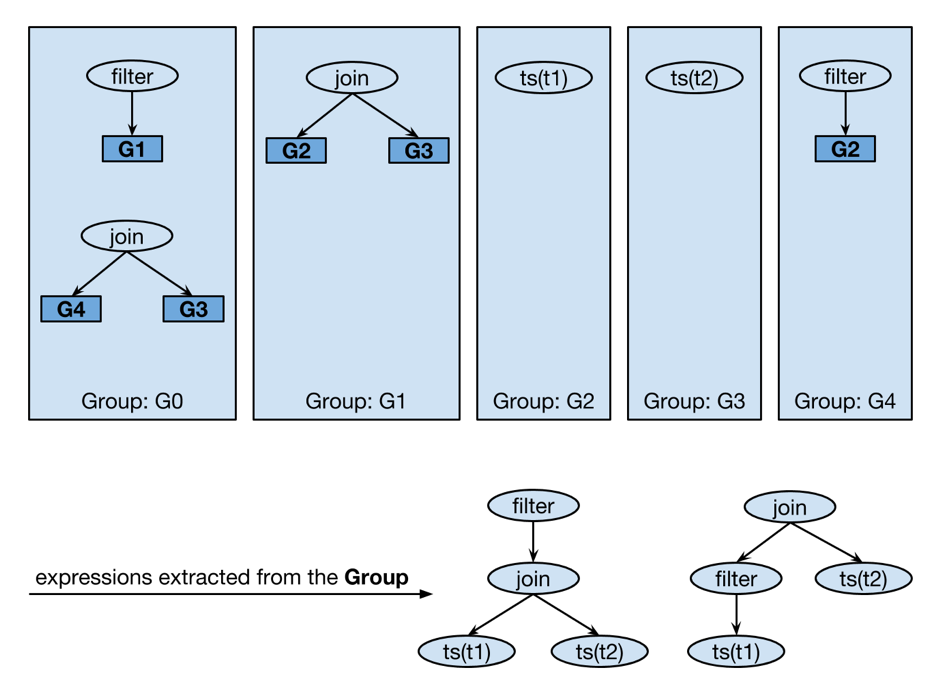\n\n目前 TiDB 中 Cascades 优化器的搜索过程大致如下:\n\n1. 首先将抽象语法树(AST)转换为初始的逻辑执行计划,也就是由 LogicalPlan 所表示的算子树。\n\n2. Cascades Planner 将这棵初始的 LogicalPlan 树等价地拆分到 `Group` 和 `GroupExpr` (Expression 在代码中对应的具体数据结构) 中,这样我们便得到了 Cascades Planner 优化器的初始输入。\n\n3. Cascades Planner 将搜索的过程分为了两个阶段,第一阶段是 Exploration ,该阶段不停地遍历整个 Group ,应用所有可行的 Transformation Rule,产生新的 Group 和 GroupExpr ,不停迭代直到没有新的 GroupExpr 诞生为止。\n\n4. 在第二个阶段 Implementation 中,Cascades Planner 通过对 GroupExpr 应用对应的 Implementation Rule,为每一个 Group 搜索满足要求的最佳(Cost 最低)物理执行计划。\n\n5. 第二阶段结束后,Cascades Planner 将生成一个最终的物理执行计划,优化过程到此结束,物理执行计划交给 TiDB 执行引擎模块继续处理。\n\n## 一条优化规则如何工作\n\n目前所有的 Transformation Rule 的实现代码都放在 `planner/cascades/transformation_rules.go` 文件中。我们以 `PushSelDownProjection` 为例,来简单介绍一条 Transformation Rule 的工作流程。\n\nTransformation Rule 是一个 interface,该接口的定义如下(省去注释部分):\n\n```\ntype Transformation interface {\n\tGetPattern() *memo.Pattern\n\tMatch(expr *memo.ExprIter) bool\n\tOnTransform(old *memo.ExprIter) (newExprs []*memo.GroupExpr, eraseOld bool, eraseAll bool, err error)\n}\n```\n\n在 Cascades 中,每个 rule 都会匹配一个局部的 Expression 子树,这里的 `GetPattern()` 就是返回这个 rule 所要匹配的 Pattern。Pattern 的具体结构如下(省去注释部分):\n\n```\ntype Pattern struct {\n\tOperand\n\tEngineTypeSet\n\tChildren []*Pattern\n}\n```\n\n这里需要提一下的是 `EngineTypeSet` 这个参数,因为有的算子比如 Selection ,既可以在 TiDB 执行,也可以在 TiKV 或者 TiFlash(一个列存引擎,目前尚未开源)Coprocessor 上执行。为了处理只在特定执行引擎上生效的规则,我们引入了这个参数。\n\nPattern 的构造可以借助 `BuildPattern()` 以及 `NewPattern()` 来完成。对于 `PushSelDownProjection` 这个规则来说,它起作用的执行计划 Pattern 是 `Projection -> Selection`。\n\n```\nfunc (r *PushSelDownProjection) GetPattern() *memo.Pattern {\n\treturn memo.BuildPattern(\n\t\tmemo.OperandSelection,\n\t\tmemo.EngineTiDBOnly,\n\t\tmemo.NewPattern(memo.OperandProjection, memo.EngineTiDBOnly),\n\t)\n}\n```\n\n`Match()` 函数是在命中 Pattern 后再做的一些更具体的判断,因为 Pattern 只包含了算子类型和算子树的结构信息。这时比如有一个 Rule 只对 inner join 生效,Pattern 只能判断到算子是 Join,要进一步判断它是否是 inner join 就需要依靠 `Match()` 函数了。对于大部分简单的 Transformation Rule,所以 `Match()` 函数只需要简单地返回 `true` 就行了。\n\n`OnTransform()` 函数是规则的主要逻辑所在,在函数内部我们会创造新的 Expression 并返回合适的 `eraseOld` 以及 `eraseAll` 的值。举例来说,谓词下推会让计算尽可能提前,减少后续计算量,因此新生成地 Expression 一定是更好的选择,这时 `eraseOld` 就可以返回 `true `。类似地,当一个 rule 返回的 Expression 一定比其他所有选择都更好时,比如某一个优化规则发现 `a > 1 and a < 1` 恒为假后,判断查询一定不会有结果产生所以生成了 `TableDual` 的新 Expression ,这时就可以让 `eraseAll` 返回 `true` 让优化器将同 Group 内的其他 Expression 全部清空。\n\n`PushSelDownProjection` 的 `OnTransform()` 的行为如下图所示,简单来说:\n\n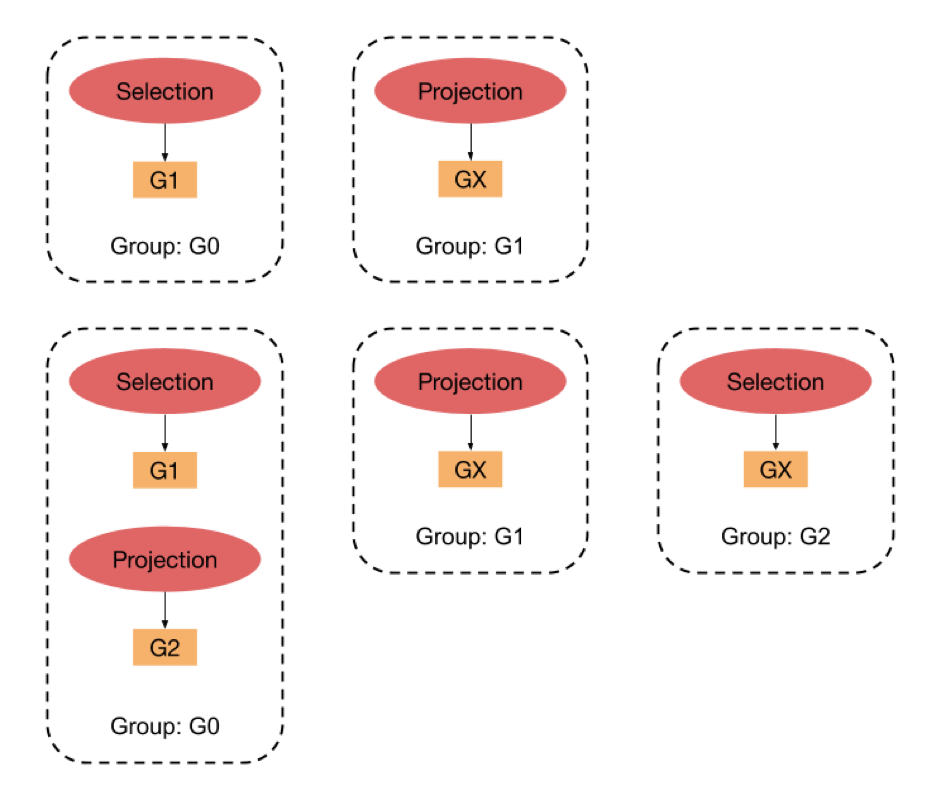\n\n1. 在初始时只有 `G0` 和 `G1` 两个相关的 Group。\n\n2. 这个优化规则会将 `Selection` 推到 `Projection` 下面去,产生新的 Group `G2`,同时在 `G0` 中新增了 `Projection->G2` 的 `GroupExpr`。\n\n\n## 如何添加一个 Transformation Rule\n\n添加一个 Transformation Rule 简单来说就是编写一个新的结构体,实现 `Transformation` 这个 interface 的三个接口。Cascades 架构的优势就是它做了足够的抽象,让添加 Rule 的工作不需要考虑太多繁杂的事情。如果你在添加 Rule 时觉得有些地方写起来不是那么顺手,可以立刻停下手中的键盘来 [#sig-planner](https://tidbcommunity.slack.com/messages/sig-planner) 中和我们做一些讨论。\n\n当然这里还是要列出一些注意事项方便大家在添加 Transformation Rule 时不走歪路:\n\n* `OnTransform()` 的函数头以及函数过程中添加充足的注释,说明自己的 Rule 做了一个什么样的变换,方便他人在读到这个 Rule 的代码时,能快速明白这个 Rule 做了哪些工作。\n\n* `OnTransform()` 函数中不要对原有的 Expression 做任何修改,因为原有 Expression 可能之后会继续触发其他的行为,如果做了修改,那么在下一次触发规则时,就可能产生一些意想不到的化学反应。\n\n* 要在 `defaultTransformationRuleMap` 中注册这个 Rule,这个 Map 是 TiDB 目前默认的 `RuleSet`。使用 `RuleSet` 的好处很多,比如针对 TP 和 AP 查询使用不同的 Rule 集合,使得优化器在处理 TP 查询时能快速做出不差的执行计划,在处理 AP 查询时多应用一些优化规则做出执行时间更短的执行计划等。\n\n* 单元测试必不可少。目前,Transformation Rule 的测试在 `transformation_rules_test.go` 中。测试函数的编写可以参考文件下的其他函数,主要是以跑一个完整的 SQL 进行测试。为了减轻修改测试输出的工作量,我们将测试输入输出单独记录在文件中,并可以通过命令行快捷更新输出。在添加了测试函数后,需要修改 testdata 目录下的 `transformation_rules_suite_in.json` 文件添加测试的输入,然后用 `go test github.com/pingcap/tidb/planner/cascades --record` 即可生成对应的 `xxx_out.json` 文件。记得要检查测试的输出是否符合预期,确保测试结果是自己想要的等价变换。\n\n* 目前 Cascades 优化器仍在早期阶段,偶尔会有一些框架性的改动可能会制造一些需要解决的代码冲突,还请大家理解。\n\n## 如何成为 Contributor\n\n为了方便和社区讨论 Planner 相关事情,我们在 [TiDB Community Slack](https://pingcap.com/tidbslack/) 中创建了[#sig-planner](https://tidbcommunity.slack.com/messages/sig-planner) 供大家交流讨论,之后还将成立优化器的专项兴趣小组,不设门槛,欢迎感兴趣的同学加入。大家在添加规则时遇到一些问题时,可以毫不犹豫的来 channel 里和我们吐槽~\n\n**参与流程:**\n\n1. 在 [Cascades Tracking Issue](https://github.com/pingcap/tidb/issues/13709) 中 `porting the existing rules in the old planner` 选择感兴趣的函数并告诉大家你会完成它。\n\n2. 添加一个 rule 并为其增加单元测试。\n\n3. 运行 `make dev`,保证所有 test 都能通过。\n\n4. 发起 Pull Request 并完成 merge 到主分支。\n\n如果你有任何疑问,也欢迎到 [#sig-planner](https://tidbcommunity.slack.com/messages/sig-planner) 中提问和讨论。 \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2019-11-26","author":"崔一丁","fillInMethod":"writeDirectly","customUrl":"10mins-become-contributor-20191126","file":null,"relatedBlogs":[]},{"id":"Blogs_273","title":"Unified Thread Pool | TiDB Hackathon 2019 优秀项目介绍","tags":["TiKV","社区","Hackathon"],"category":{"name":"社区动态"},"summary":"Unified Thread Pool 项目实现了在 TiKV 中使用一个统一的自适应线程池处理读请求,能够显著提升性能,并可预测性地限制大查询对小请求的干扰,最终在 TiDB Hackathon 2019 中斩获一等奖。","body":">本文由逊馁队的成员夏锐航同学主笔,介绍 Unified Thread Pool 项目的设计与实现过程。该项目实现了在 TiKV 中使用一个统一的自适应线程池处理读请求,能够显著提升性能,并可预测性地限制大查询对小请求的干扰,最终在 [TiDB Hackathon 2019](https://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247490046&idx=1&sn=962bb8aa4619c3815fcc561ed96331d7&chksm=eb163e94dc61b7826b7e73a057f4c9823261c1a79005104dd41dbd6ef4276c01bd6e41a69d14&scene=21&token=1896003006&lang=zh_CN#wechat_redirect) 中斩获一等奖。\n\n距离 TiDB Hackathon 落幕已经过去了半个多月,回忆这次比赛、获奖的经历,依然让我感到非常兴奋。我目前是华南理工大学大三的学生,我和正在 PingCAP 实习的学长奕霖一起组队参加了这次 TiDB Hackathon,比赛的主题为 “Improve”,即提升 TiDB 及相关项目的性能、易用性等。我们项目设计的切入点是: \n\n* TiKV 现有的线程池在大小查询混合场景下的表现不太优秀。\n\n* 需要针对不同的环境、场景配置线程池数量,使用和学习成本较高。\n\n于是我和奕霖尝试为 TiKV 重新实现一个线程池来解决这个问题,以达到 Improve 整体表现的效果。除了优化读请求的线程池外,我们计划将这个线程池来代替 TiKV 中其他线程池,最后就产生了我们本次的参赛作品 Unified Thread Pool。\n\n## 项目设计\n\n在 TiKV 现行的线程池方案中有 Coprocessor、Storage 和 Scheduler 三套线程池。这些线程池原本是设计来分隔不同的任务,减少它们之间的相互影响。这种方式简单粗暴,缺点也很明显,如:\n\n* 由于多个线程池共存,每个线程池都被限制至无法使用系统的全部资源。\n\n* 每套任务中又对应二至三个不同优先级的线程池,但是从实际效果来讲这个隔离也没能很好的发挥用处。\n\n* 在目前的 TiKV 中需要对每个线程池单独配置,如 [Scheduler](https://pingcap.com/docs-cn/v3.0/reference/configuration/tikv-server/configuration-file/#scheduler-worker-pool-size)、[Storage](https://pingcap.com/docs-cn/v3.0/reference/configuration/tikv-server/configuration-file/#readpoolstorage)、[Coprocessor](https://pingcap.com/docs-cn/v3.0/reference/configuration/tikv-server/configuration-file/#readpoolcoprocessor)。\n\n我们的 Unified Thread Pool 是一个在用户态模拟多级反馈队列调度的线程池,能较好的解决上述现行线程池方案的几个缺点。两者具体的对比如下表所示:\n\n| 现行线程池方案 | 我们的改进 |\n|:--------|:--------| \n| 多个线程池共存,每个线程池都不能分配所有的资源 | 一个统一的线程池,可以分配尽量多的资源|\n| 通过分配到不同的线程池来实现优先级,但效果不佳 | 内部实现按时间的调度 |\n| 大请求对小请求的影响不可控 | 可预测的大请求对系统的影响 |\n\n表 1 与现行线程池的对比
\n\nUnified Thread Pool 的调度方案参考自多级反馈队列算法,在 Unified Thread Pool 中一共有三个队列,worker 每次以不同的数量从不同的队列里面拿任务执行来表示优先级。不同于 OS 场景下的调度是以每个任务为单位,在这里一个 TiDB query 可能因为跨越多个 Region 而产生多个 TiKV task,如图 1 所示:\n\n\n\n图 1 TiDB query 与 TiKV task 的关系
\n\n因此在这里我们需要以 TiDB 的 query 为单位进行调度。为了实现这一点我们让 TiDB 在发送 query 的时候带上一个 token 来作为标识,在线程池内我们也以 token(query)为整体来调整优先级。\n\n另一点很重要的改动是,现在 TiKV 中可能会出现一些大的 Coprocessor 请求,这些请求按 batch 执行,一个请求可能包含数百个 batches,执行一次就需要秒级的时间,使得对它们的调度无法进行。关于 Coprocessor 向量化执行的内容 PingCAP 后续也会有相关文章进行介绍。因此我们使用 Rust 最新的 async/await 协程机制,在 Coprocessor batches 之间手动埋点移交执行权,如下图所示,一个原本需要约一秒钟,包含约 500 个 batch 的任务在现在将会变为许多个时间约为一毫秒的小任务,在每个小任务之间会主动移交执行权。\n\n\n\n图 2 将请求分成多次执行
\n\n至此,Unified Thread Pool 已经基本能够通过动态调节队列的参数来实现资源对大小任务的分配,并且需要设置的参数非常简单,仅有一个表示当出现大小任务混杂的情形时小任务应占的计算资源的百分数。通过测试我们看到这个的分配的效果比较精确,如下图所示。\n\n\n\n图 3 Configurable
\n\n## 比赛过程\n\n### Hacking Time\n\n在 10 月 26 日上午拿到 UCloud 提供的机器(8C16G)后,我们开始部署 TiDB 集群便于测试。第一次部署方案是 3TiDB + 3TiKV,但是当集群运行起来之后我们发现当请求压来时瓶颈似乎在 TiDB 上,于是我们将 TiKV 集群 down 掉一台,情况虽然有所好转但还是无法将 TiKV 跑到满负荷。一番挣扎无果后我们将整个集群铲掉重新部署,第二次按照 4TiDB + 1TiKV + 1Tester 部署完之后终于让瓶颈出现在 TiKV 上。\n\n详细的测试方案是使用 Tester 机器向四台 TiDB 发送请求然后检测延时和 QPS,sysbench 测试数据 32 张表,每张 10,000,000 条数据,总计容量约 80G。我们模拟了大小两种规格的请求,小请求是使用 sysbench 的 `point_selec t` 和 `read_only`,大请求则是使用四个 clients 不断地 `SELECT COUNT(*) FROM ..` 来扫表。下图是我们在上述测试环境中对 Unified Thread Pool 与 TiKV master 版本所做的对比,可以看到在单纯的小请求情况下吞吐量提高了 20%~50%。\n\n\n\n图 4 fully utilize
\n\n### 睁眼吃喝闭眼睡\n\n众所周知 Hackathon 不变的主题就是吃吃喝喝,这一次也一样。PingCAP 为选手们提供了丰富的三餐,配上广州 office 的装潢简直像在度假。午餐有超多口味可以选,到了晚上一会议桌的虾蟹的确是太有视觉冲击力。除了正餐之外,还有不限量供应的零食咖啡快乐水,实在是太幸福了。\n\n在比赛开始之前就有一件非常好奇的事情,就是据说现场晚上有三张床垫,不知道会出现怎样难上加难的场景。结果真的到了犯困的时候才发现原来其他人是根本不睡的……\n\n晚上两点左右感觉刚跑完的测试效果还行,就找了间放了床的小会议室准备做梦。可是充气床垫的气已经漏完了,在茶水间里面翻到充气装置之后打算给它重启,但是插头插上之后气泵的声音在深夜里面真是大得不行,不知道之前工作人员是怎样悄无声息地把三个床垫给充起来的。为了防止噪音扰民,我们把床垫卷到大楼下一层(洗手间旁边)的小房间里面充气,期间还引来了两位像是保安的叔叔来看看发生了什么。接下来和奕霖两个人扛着两米的床垫走过会议室走过茶水间走过工位,走进小卧室的那一段路,实在是令人印象非常深刻。\n\n这栋楼的空调效果真是非常强劲,虽然不是第一次在贵司被冷到,但是这一回来的时候依旧没有带外套。即使睡觉之前已经把空调关掉了,还是和带了外套但没拿出来的奕霖在床上缩成了两团。\n\n## 写在 Hackathon 之后\n\n比赛最后 Demo Time 的时候看别人的项目都好优秀,看得有点想提前跑路了,还好不是我上去做 presentation,能夺魁事实上挺让我感到意外的,现在 Hackathon 虽然已经结束了,但还想继续完善这个作品。现在它虽然能提升最大吞吐量,但是在延时方面的表现还能更进一步。在比赛时我们的线程池是基于比较简单的 juliex 来设计的,后续计划参考一些比如 tokio 之类的成熟的线程池来进行优化,希望能够将它完善合进 master。大家可以在 [TiDB 性能挑战赛](https://pingcap.com/community-cn/tidb-performance-challenge/) 中继续一起鼓捣这个项目,该项目对应的 [链接](https://github.com/tikv/tikv/issues/5765)。\n\n最后感谢奕霖老师这么强还愿意带我玩,感谢 PingCAP 让我蹭吃蹭喝的辛苦付出 :D \n\n>附:[逊馁队 Demo Show 视频(0:00 - 10:35)](https://v.qq.com/x/page/s30152xwbyj.html)","date":"2019-11-14","author":"夏锐航","fillInMethod":"writeDirectly","customUrl":"unified-thread-pool","file":null,"relatedBlogs":[]},{"id":"Blogs_283","title":"TiDB-Wasm 原理与实现 | TiDB Hackathon 2019 优秀项目介绍","tags":["Hackathon","社区","WebAssembly"],"category":{"name":"社区动态"},"summary":"TiDB-Wasm 项目实现了将 TiDB 编译成 Wasm 运行在浏览器里,让用户无需安装就可以使用 TiDB,最终获得了 TiDB Hackathon 2019 的二等奖。","body":">上周我们推送了《[让数据库运行在浏览器里?TiDB + WebAssembly 告诉你答案](https://pingcap.com/blog-cn/tidb-in-the-browser-running-a-golang-database-on-wasm/)》,向大家展示了 TiDB-Wasm 的魅力:TiDB-Wasm 项目是 TiDB Hackathon 2019 中诞生的二等奖项目,实现了将 TiDB 编译成 Wasm 运行在浏览器里,让用户无需安装就可以使用 TiDB。\n>\n>本文由 Ti-Cool 队成员主笔,为大家详细介绍 TiDB-Wasm 设计与实现细节。\n\n\n\n10 月 27 日,为期两天的 Hackathon 落下帷幕,我们用一枚二等奖为此次上海之行画上了圆满的句号,不枉我们风尘仆仆跑去异地参赛(强烈期待明年杭州能作为赛场,主办方也该鼓励鼓励杭州当地的小伙伴呀 :D )。\n\n我们几个 PingCAP 的小伙伴找到了 Tony 同学一起组队,组队之后找了一个周末进行了“秘密会晤”——Hackathon kick off。想了 N 个 idea,包括使用 unikernel 技术将 TiDB 直接跑在裸机上,或者将网络协议栈做到用户态以提升 TiDB 集群性能,亦或是使用异步 io 技术提升 TiKV 的读写能力,这些都被一一否决,原因是这些 idea 不是和 Tony 的工作内容相关,就是和我们 PingCAP 小伙伴的日常工作相关,做这些相当于我们在 Hackathon 加了两天班,这一点都不酷。本着「与工作无关」的标准,我们想了一个 idea:把 TiDB 编译成 Wasm 运行在浏览器里,让用户无需安装就可以使用 TiDB。我们一致认为这很酷,于是给队伍命名为 Ti-Cool(太酷了)。\n\n## WebAssembly 简介\n\n这里插入一些 WebAssembly 的背景知识,让大家对这个技术有个大致的了解。\n\nWebAssembly 的 [官方介绍](https://webassembly.org/) 是这样的:WebAssembly(缩写为 Wasm)是一种为基于堆栈的虚拟机设计的指令格式。它被设计为 C/C++/Rust 等高级编程语言的可移植目标,可在 web 上部署客户端和服务端应用程序。\n\n从上面一段话我们可以得出几个信息:\n\n1. Wasm 是一种可执行的指令格式。\n2. C/C++/Rust 等高级语言写的程序可以编译成 Wasm。\n3. Wasm 可以在 web(浏览器)环境中运行。\n\n### 可执行指令格式\n\n看到上面的三个信息我们可能又有疑问:什么是指令格式?\n\n我们常见的 [ELF 文件](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format) 就是 Unix 系统上最常用的二进制指令格式,它被 loader 解析识别,加载进内存执行。同理,Wasm 也是被某种实现了 Wasm 的 runtime 识别,加载进内存执行,目前常见的实现了 Wasm runtime 的工具有各种主流浏览器,nodejs,以及一个专门为 Wasm 设计的通用实现:Wasmer,甚至还有人给 Linux 内核提 feature 将 Wasm runtime 集成在内核中,这样用户写的程序可以很方便的跑在内核态。\n\n各种主流浏览器对 WebAssembly 的支持程度:\n\n\n\n图 1 主流浏览器对 WebAssembly 的支持程度
\n\n### 从高级语言到 Wasm \n\n有了上面的背景就不难理解高级语言是如何编译成 Wasm 的,看一下高级语言的编译流程:\n\n\n\n图 2 高级语言编译流程
\n\n我们知道高级编程语言的特性之一就是可移植性,例如 C/C++ 既可以编译成 x86 机器可运行的格式,也可以编译到 ARM 上面跑,而我们的 Wasm 运行时和 ARM,x86_32 其实是同类东西,可以认为它是一台虚拟的机器,支持执行某种字节码,这一点其实和 Java 非常像,实际上 C/C++ 也可以编译到 JVM 上运行(参考:[compiling-c-for-the-jvm](https://stackoverflow.com/questions/4221605/compiling-c-for-the-jvm))。\n\n### 各种 runtime 以及 WASI\n\n再啰嗦一下各种环境中运行 Wasm 的事,上面说了 Wasm 是设计为可以在 web 中运行的程序,其实 Wasm 最初设计是为了弥补 js 执行效率的问题,但是发展到后面发现,这玩意儿当虚拟机来移植各种程序也是很赞的,于是有了 nodejs 环境,Wasmer 环境,甚至还有内核环境。\n\n这么多环境就有一个问题了:各个环境支持的接口不一致。比如 nodejs 支持读写文件,但浏览器不支持,这挑战了 Wasm 的可移植性,于是 WASI (WebAssembly System Interface) 应运而生,它定义了一套底层接口规范,只要编译器和 Wasm 运行环境都支持这套规范,那么编译器生成的 Wasm 就可以在各种环境中无缝移植。如果用现有的概念来类比,Wasm runtime 相当于一台虚拟的机器,Wasm 就是这台机器的可执行程序,而 WASI 是运行在这台机器上的系统,它为 Wasm 提供底层接口(如文件操作,socket 等)。\n\nExample or Hello World?\n\n程序员对 Hello World 有天生的好感,为了更好的说明 Wasm 和 WASI 是啥,我们这里用一个 Wasm 的 Hello World 来介绍(例程来源:[chai2010-golang-wasm.slide#27](https://talks.godoc.org/github.com/chai2010/awesome-go-zh/chai2010/chai2010-golang-wasm.slide#27)):\n\n```lisp\n(module\n ;; type iov struct { iov_base, iov_len int32 }\n ;; func fd_write(id *iov, iovs_len int32, nwritten *int32) (written int32)\n (import \"wasi_unstable\" \"fd_write\" (func $fd_write (param i32 i32 i32 i32) (result i32)))\n\n (memory 1)(export \"memory\" (memory 0))\n\n ;; The first 8 bytes are reserved for the iov array, starting with address 8\n (data (i32.const 8) \"hello world\\n\")\n\n ;; _start is similar to main function, will be executed automatically\n (func $main (export \"_start\")\n (i32.store (i32.const 0) (i32.const 8)) ;; iov.iov_base - The string address is 8\n (i32.store (i32.const 4) (i32.const 12)) ;; iov.iov_len - String length\n\n (call $fd_write\n (i32.const 1) ;; 1 is stdout\n (i32.const 0) ;; *iovs - The first 8 bytes are reserved for the iov array\n (i32.const 1) ;; len(iovs) - Only 1 string\n (i32.const 20) ;; nwritten - Pointer, inside is the length of the data to be written\n )\n drop ;; Ignore return value\n )\n)\n```\n\n\n具体指令的解释可以参考 [这里](https://pengowray.github.io/wasm-ops/html/wasm-opcodes.html)。\n\n这里的 test.wat 是 Wasm 的文本表示,wat 之于 Wasm 的关系类似于汇编和 ELF 的关系。\n\n然后我们把 wat 编译为 Wasm 并且使用 Wasmer(一个通用的 Wasm 运行时实现)运行:\n\n\n\n图 3 Hello World
\n\n## 改造工作\n\n恐惧来自未知,有了背景知识动起手来才无所畏惧,现在可以开启 TiDB 的浏览器之旅。\n\n### 浏览器安全限制\n\n我们知道,浏览器本质是一个沙盒,是不会让内部的程序做一些危险的事情的,比如监听端口,读写文件。而 TiDB 的使用场景实际是用户启动一个客户端通过 MySQL 协议连接到 TiDB,这要求 TiDB 必须监听某个端口。\n\n**考虑片刻之后,我们认为即便克服了浏览器沙盒这个障碍,真让用户用 MySQL 客户端去连浏览器也并不是一个优雅的事情,我们希望的是用户在页面上可以有一个开箱即用的 MySQL 终端,它已经连接好了 TiDB。**\n\n于是我们第一件事是给 TiDB 集成一个终端,让它启动后直接弹出这个终端接受用户输入 SQL。所以我们需要在 TiDB 的代码中找到一个工具,它的输入是一串 SQL,输出是 SQL 的执行结果,写一个这样的东西对于我们几个没接触过 TiDB 代码的人来说还是有些难度,于是我们想到了一个捷径:TiDB 的测试代码中肯定会有输入 SQL 然后检查输出的测试。那么把这种测试搬过来改一改不就是我们想要的东西嘛?然后我们翻了翻 TiDB 的测试代码,发现了大量的这样的用法:\n\n```go\nresult = tk.MustQuery(\"select count(*) from t group by d order by c\")\nresult.Check(testkit.Rows(\"3\", \"2\", \"2\"))\n```\n\n所以我们只需要看看这个 `tk` 是个什么东西,借来用一下就行了。这是 `tk` 的主要函数:\n\n```go\n// Exec executes a sql statement.\nfunc (tk *TestKit) Exec(sql string, args ...interface{}) (sqlexec.RecordSet, error) {\n var err error\n if tk.Se == nil {\n tk.Se, err = session.CreateSession4Test(tk.store)\n tk.c.Assert(err, check.IsNil)\n id := atomic.AddUint64(&connectionID, 1)\n tk.Se.SetConnectionID(id)\n }\n ctx := context.Background()\n if len(args) == 0 {\n var rss []sqlexec.RecordSet\n rss, err = tk.Se.Execute(ctx, sql)\n if err == nil && len(rss) > 0 {\n return rss[0], nil\n }\n return nil, errors.Trace(err)\n }\n stmtID, _, _, err := tk.Se.PrepareStmt(sql)\n if err != nil {\n return nil, errors.Trace(err)\n }\n params := make([]types.Datum, len(args))\n for i := 0; i < len(params); i++ {\n params[i] = types.NewDatum(args[i])\n }\n rs, err := tk.Se.ExecutePreparedStmt(ctx, stmtID, params)\n if err != nil {\n return nil, errors.Trace(err)\n }\n err = tk.Se.DropPreparedStmt(stmtID)\n if err != nil {\n return nil, errors.Trace(err)\n }\n return rs, nil\n}\n```\n\n\n剩下的事情就非常简单了,写一个 Read-Eval-Print-Loop (REPL) 读取用户输入,将输入交给上面的 Exec,再将 Exec 的输出格式化到标准输出,然后循环继续读取用户输入。\n\n### 编译问题\n\n**集成一个终端只是迈出了第一步,我们现在需要验证一个非常关键的问题:TiDB 能不能编译到 Wasm,虽然 TiDB 是 Golang 写的,但是中间引用的第三方库没准哪个写了平台相关的代码就没法直接编译了**。\n\n我们先按照 [Golang 官方文档](https://github.com/golang/go/wiki/WebAssembly#getting-started) 编译:\n\n\n\n图 4 按照 Golang 官方文档编译(1/2)
\n\n\n果然出师不利,查看 goleveldb 的代码发现,storage 包下面的代码针对不同平台有各自的实现,唯独没有 Wasm/js 的:\n\n\n\n图 5 按照 Golang 官方文档编译(2/2)
\n\n所以在 Wasm/js 环境下编译找不到一些函数。所以这里的方案就是添加一个 `file_storage_js.go`,然后给这些函数一个 unimplemented 的实现:\n\n```go\npackage storage\n\nimport (\n\t\"os\"\n\t\"syscall\"\n)\n\nfunc newFileLock(path string, readOnly bool) (fl fileLock, err error) {\n\treturn nil, syscall.ENOTSUP\n}\n\nfunc setFileLock(f *os.File, readOnly, lock bool) error {\n\treturn syscall.ENOTSUP\n}\n\nfunc rename(oldpath, newpath string) error {\n\treturn syscall.ENOTSUP\n}\n\nfunc isErrInvalid(err error) bool {\n\treturn false\n}\n\nfunc syncDir(name string) error {\n\treturn syscall.ENOTSUP\n}\n```\n\n\n然后再次编译:\n\n\n\n图 6 再次编译的结果
\n\nemm… 编译的时候没有函数可以说这个函数没有 Wasm/js 对应的版本,没有 body 是个什么情况?好在我们有代码可以看,到 `arith_decl.go` 所在的目录看一下就知道怎么回事了:\n\n\n\n图 7 查看目录
\n\n然后 `arith_decl.go` 的内容是一些列的函数声明,但是具体的实现放到了上面的各个平台相关的汇编文件中了。\n\n看起来还是和刚刚一样的情况,我们只需要为 Wasm 实现一套这些函数就可以了。但这里有个问题是,这是一个代码不受我们控制的第三方库,并且 TiDB 不直接依赖这个库,而是依赖了一个叫 `mathutil` 的库,然后 `mathutil` 依赖这个 `bigfft`。悲催的是,这个 `mathutil` 的代码也不受我们控制,因此很直观的想到了两种方案:\n\n1. 给这两个库的作者提 PR,让他们支持 Wasm。\n\n2. 我们将这两个库 clone 过来改掉,然后把 TiDB 依赖改到我们 clone 过来的库上。\n\n方案一的问题很明显,整个周期较长,等作者接受 PR 了我们的 Hackathon 都凉凉了(而且还不一定会接受);方案二的问题也不小,这会导致我们和上游脱钩。那么有没有第三种方案呢,即在编译 Wasm 的时候不依赖这两个库,在编译正常的二进制文件的时候又用这两个库?经过搜索发现,我们很多代码都用到了 `mathutil`,但是基本上只用了几个函数:`MinUint64`,`MaxUint64`,`MinInt32`,`MaxInt32` 等等,我们想到的方案是:\n\n1. 新建一个 `mathutil` 目录,在这个目录里建立 `mathutil_linux.go` 和 `mathutil_js.go`。\n\n2. 在 `mathutil_linux.go` 中 reexport 第三方包的几个函数。\n\n3. 在 `mathutil_js.go` 中自己实现这几个函数,不依赖第三方包。\n\n4. 将所有对第三方的依赖改到 `mathutil` 目录上。\n\n这样,`mathutil` 目录对外提供了原来 `mathutil` 包的函数,同时整个项目只有 `mathutil` 目录引入了这个不兼容 Wasm 的第三方包,并且只在 `mathutil_linux.go` 中引入(`mathutil_js.go` 是自己实现的),因此编译 Wasm 的时候就不会再用到 `mathutil` 这个包。\n\n再次编译,成功了!\n\n\n\n图 8 编译成功
\n\n### 兼容性问题\n\n编译出 main.Wasm 按照 Golang 的 Wasm 文档跑一下,由于目前是直接通过 os.Stdin 读用户输入的 SQL,通过 os.Stdout 输出结果,所以理论上页面上会是空白的(我们还没有操作 dom),但是由于 TiDB 的日志会打向 os.Stdout,所以在浏览器的控制台上应该能看到 TiDB 正常启动的日志才对。然而很遗憾看到的是异常栈:\n\n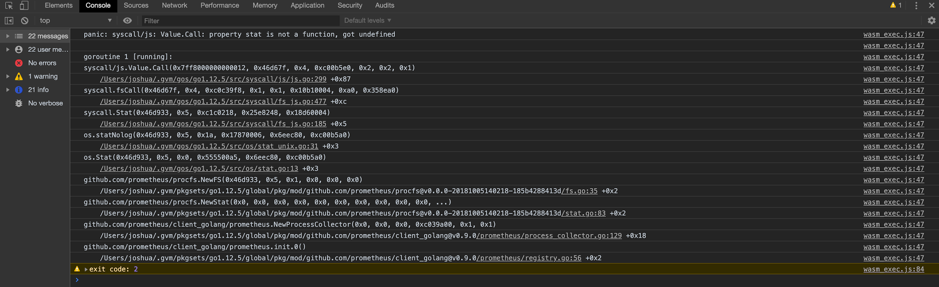\n\n图 9 异常栈
\n\n可以看到这个错是运行时没实现 os.stat 操作,这是因为目前的 Golang 没有很好的支持 WASI,它仅在 `wasm_exec.js` 中 mock 了一个 `fs`:\n\n```js\nglobal.fs = {\n writeSync(fd, buf) {\n ...\n },\n write(fd, buf, offset, length, position, callback) {\n ...\n },\n open(path, flags, mode, callback) {\n ...\n },\n ...\n}\n```\n\n而且这个 mock 的 `fs` 并没有实现 `stat`, `lstat`, `unlink`, `mkdir` 之类的调用,那么解决方案就是我们在启动之前在全局的 `fs` 对象上 mock 一下这几个函数:\n\n```js\nfunction unimplemented(callback) {\n const err = new Error(\"not implemented\");\n err.code = \"ENOSYS\";\n callback(err);\n}\nfunction unimplemented1(_1, callback) { unimplemented(callback); }\nfunction unimplemented2(_1, _2, callback) { unimplemented(callback); }\n\nfs.stat = unimplemented1;\nfs.lstat = unimplemented1;\nfs.unlink = unimplemented1;\nfs.rmdir = unimplemented1;\nfs.mkdir = unimplemented2;\ngo.run(result.instance);\n```\n\n然后再刷新页面,在控制台上出现了久违的日志:\n\n\n\n图 10 日志信息
\n\n到目前为止就已经解决了 TiDB 编译到 Wasm 的所有技术问题,剩下的工作就是找一个合适的能运行在浏览器里的 SQL 终端替换掉前面写的终端,和 TiDB 对接上就能让用户在页面上输入 SQL 并运行起来了。\n\n### 用户接口\n\n通过上面的工作,我们现在有了一个 Exec 函数,它接受 SQL 字符串,输出 SQL 执行结果,并且它可以在浏览器里运行,我们还需要一个浏览器版本 SQL 终端和这个函数交互,两种方案:\n\n1. 使用 Golang 直接操作 dom 来实现这个终端。\n\n2. 在 Golang 中把 Exec 暴露到全局,然后找一个现成的 js 版本的终端和这个全局的 Exec 对接。\n\n对于前端小白的我们来说,第二种方式成本最低,我们很快找到了 jquery.console.js 这个库,它只需要传入一个 SQL 处理的 callback 即可运行,而我们的 Exec 简直就是为这个 callback 量身打造的。\n\n因此我们第一步工作就是把 Exec 挂到浏览器的 window 上(暴露到全局给 js 调用):\n\n```go\njs.Global().Set(\"executeSQL\", js.FuncOf(func(this js.Value, args []js.Value) interface{} {\n go func() {\n\t // Simplified code\n\t sql := args[0].String()\n\t args[1].Invoke(k.Exec(sql))\n }()\n return nil\n}))\n```\n\n这样就能在浏览器的控制台运行 SQL 了:\n\n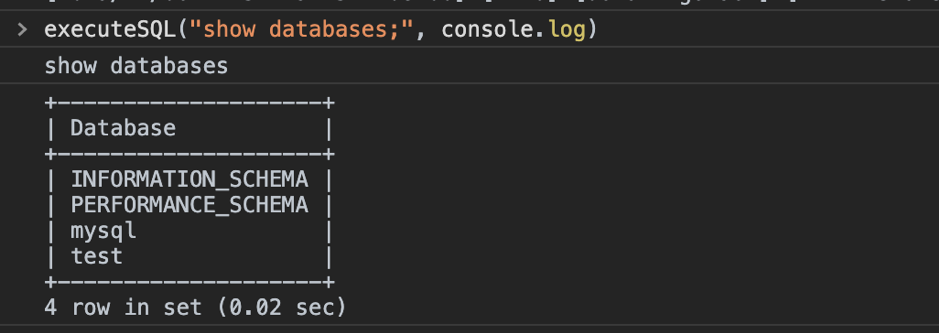\n\n图 11 在浏览器控制台运行 SQL
\n\n然后将用 jquery.console.js 搭建一个 SQL 终端,再将 executeSQL 作为 callback 传入,大功告成:\n\n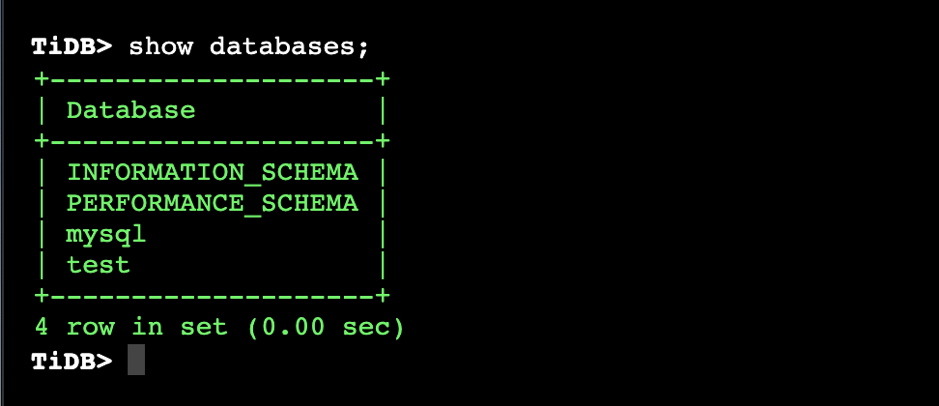\n\n图 12 搭建 SQL 终端
\n\n现在算是有一个能运行的版本了。\n\n### 本地文件访问\n\n还有一点点小麻烦要解决,那就是 TiDB 的 load stats 和 load data 功能。load data 语法和功能详解可以参考 [TiDB 官方文档](https://pingcap.com/docs-cn/v3.0/reference/sql/statements/load-data/),其功能简单的说就是用户指定一个文件路径,然后客户端将这个文件内容传给 TiDB,TiDB 将其加载到指定的表里。我们的问题在于,浏览器中是不能读取用户电脑上的文件的,于是我们只好在用户执行这个语句的时候打开浏览器的文件上传窗口,让用户主动选择一个这样的文件传给 TiDB:\n\n```go\njs.Global().Get(\"upload\").Invoke(js.FuncOf(func(this js.Value, args []js.Value) interface{} {\n go func() {\n fileContent := args[0].String()\n _, e := doSomething(fileContent)\n c <- e\n }()\n return nil\n}), js.FuncOf(func(this js.Value, args []js.Value) interface{} {\n go func() {\n c <- errors.New(args[0].String())\n }()\n return nil\n}))\n```\n\nload stats 的实现也是同理。\n\n**此外,我们还使用同样的原理 “自作主张” 加入了一个新的指令:source,用户执行这个命令可以上传一个 SQL 文件,然后我们会执行这个文件里的语句。我们认为这个功能的主要使用场景是:用户初次接触 TiDB 时,想验证其对 MySQL 的兼容性,但是一条一条输入 SQL 效率太低了,于是可以将所有用户业务中用到的 SQL 组织到一个 SQL 文件中(使用脚本或其他自动化工具),然后在页面上执行 source 导入这个文件,验证结果。**\n\n以一个 test.sql 文件为例,展示下 source 命令的效果,test.sql 文件内容如下:\n\n```sql\nCREATE DATABASE IF NOT EXISTS samp_db;\n\nUSE samp_db;\n\nCREATE TABLE IF NOT EXISTS person (\n number INT(11),\n name VARCHAR(255),\n birthday DATE\n);\n\nCREATE INDEX person_num ON person (number);\n\nINSERT INTO person VALUES(\"1\",\"tom\",\"20170912\");\n\nUPDATE person SET birthday='20171010' WHERE name='tom';\n```\n\nsource 命令执行之后弹出文件选择框:\n\n\n\n图 13 source 命令执行(1/2)
\n\n选中 SQL 文件上传后自动执行,可以对数据库进行相应的修改:\n\n\n\n图 14 source 命令执行(2/2)
\n\n## 总结与展望\n\n总的来说,这次 Hackathon 为了移植 TiDB 我们主要解决了几个问题:\n\n1. 浏览器中无法监听端口,我们给 TiDB 嵌入了一个 SQL 终端。\n\n2. goleveldb 对 Wasm 的兼容问题。\n\n3. bigfft 的 Wasm 兼容问题。\n\n4. Golang 自身对 WASI 支持不完善导致的 fs 相关函数缺失。\n\n5. TiDB 对本地文件加载转换为浏览器上传文件方式加载。\n\n6. 支持 source 命令批量执行 SQL。\n\n**目前而言我们已经将这个项目作为 TiDB Playground ([https://play.pingcap.com/](https://play.pingcap.com/)) 和 TiDB Tour ([https://tour.pingcap.com/](https://tour.pingcap.com/)) 开放给用户使用。由于它不需要用户安装配置就能让用户在阅读文档的同时进行尝试,很大程度上降低了用户学习使用 TiDB 的成本,社区有小伙伴已经基于这些自己做数据库教程了,譬如:[imiskolee/tidb-wasm-markdown](https://github.com/imiskolee/tidb-wasm-markdown)([相关介绍文章](https://mp.weixin.qq.com/s/0Vo4apK4VdBfOs0-KyWXZA))。**\n\n\n\n图 15 TiDB Playground
\n\n由于 Hackathon 时间比较紧张,其实很多想做的东西还没实现,比如:\n\n1. 使用 indexedDB 让数据持久化:需要针对 indexedDB 实现一套 Storage 的 interface。\n\n2. 使用 P2P 技术(如 webrtc)对其他浏览器提供服务:未来必定会有越来越多的应用迁移到 Wasm,而很多应用是需要数据库的,TiDB-Wasm 恰好可以扮演这样的角色。\n\n3. 给 TiDB 的 Wasm 二进制文件瘦身:目前编译出来的二进制文件有将近 80M,对浏览器不太友好,同时运行时占用内存也比较多。\n\n欢迎更多感兴趣的社区小伙伴们加入进来,一起在这个项目上愉快的玩耍([github.com/pingcap/tidb/projects/27](https://github.com/pingcap/tidb/projects/27)),也可以通过 [info@pingcap.com](mailto:info@pingcap.com) 联系我们。","date":"2019-11-12","author":"Ti-Cool","fillInMethod":"writeDirectly","customUrl":"tidb-wasm-introduction","file":null,"relatedBlogs":[]},{"id":"Blogs_163","title":"如何玩转 TiDB 性能挑战赛?本文教你 30 分钟快速上手拿积分!","tags":["TiKV","社区","性能挑战赛"],"category":{"name":"社区动态"},"summary":"本文以 TiKV 性能挑战赛 Easy 级别任务“PCP:Migrate functions from TiDB”为例,教大家如何快速又正确地完成这个任务。","body":"上周我们正式宣布了 [TiDB 性能挑战赛](https://pingcap.com/community-cn/tidb-performance-challenge/)。在赛季内,通过向 TiDB、TiKV、PD 贡献代码完成指定类别任务的方式,你可以获得相应的积分,最终你可以使用积分兑换礼品或奖金。在性能挑战赛中,你首先需要完成几道 Easy 的题目,积累一定量积分后,才能开始挑战 Medium / Hard 难度的题目。\n\n活动发布后,大家向我们反馈 TiKV 任务的资料比较少,上手难度比较高。因此本文以 TiKV 性能挑战赛 Easy 级别任务 [PCP: Migrate functions from TiDB](https://github.com/tikv/tikv/issues/5751) 为例,教大家如何快速又正确地完成这个任务,从而玩转“TiDB 性能挑战赛”。这个任务中每项完成后均可以获得 50 分,是积累分数从而挑战更高难度任务的好机会。既能改进 TiKV 为性能提升添砖加瓦、又能参与比赛得到积分,还能成为 Contributor,感兴趣的小伙伴们一起来“打怪”吧!\n\n## 背景知识\n\nTiKV Coprocessor(协处理)模块为 TiDB 提供了在存储引擎侧直接进行部分 SQL 计算的功能,支持按表达式进行过滤、聚合等,这样不仅利用起了 TiKV 机器的 CPU 资源,还能显著减少网络传输及相应的 RPC 开销,显著提升性能。大家可以阅读 [《TiKV 源码解析系列文章(十四)Coprocessor 概览》](https://pingcap.com/blog-cn/tikv-source-code-reading-14/)一文进一步了解 Coprocessor 模块。\n\n表达式计算是 Coprocessor 非常重要的一个功能,例如用户输入了这样的 SQL:\n\n```sql\nSELECT * FROM t WHERE sqrt(col_area) > 10;\n```\n\nTiKV Coprocessor 使用表达式 `sqrt(col_area) > 10` 对每一行进行求值,并根据结果对数据进行过滤,最后将过滤后的结果返回给 TiDB。为了能计算这个表达式,TiKV 必须实现与 TiDB 行为一致的 `Sqrt` 函数,当然 `>` 运算符也要提供对应的实现,这些统称为内置函数(built-in function)。\n\nTiDB 和 MySQL 有非常多的内置函数,但 TiKV 目前只实现了一部分,只有当用户输入的表达式完全被 TiKV 支持并已经进行充分测试时,对应的表达式才会被下推到 Coprocessor 执行,否则 TiDB 只能从 TiKV 捞完整数据上来,达不到加速目的。\n\n另外,TiKV 从 3.0 版本开始就包含两套 Coprocessor 执行框架,一套是老的框架,基于火山模型(推荐阅读 paper: [Volcano - An Extensible and Parallel Query Evaluation System](https://paperhub.s3.amazonaws.com/dace52a42c07f7f8348b08dc2b186061.pdf))实现,另一套是 3.0 的新框架,基于向量化模型(推荐阅读 paper:[MonetDB/X100: Hyper-Pipelining Query Execution](http://cidrdb.org/cidr2005/papers/P19.pdf))实现。火山模型中每个算子和函数都按行一个一个计算,向量化模型中则按列批量计算。由于在向量化模型中一个批次进行的处理操作是一样的,因此它可以规避条件分支,且能更好地利用流水线与缓存,从而具有更高的计算效率,差距可达 10 倍以上。\n\n既然两个模型中函数处理的数据单位是不一样的,它们自然也有不一样的函数签名及实现,因此还有一大批内置函数虽然在 TiKV 侧已经实现了,但只有火山模型的实现,而没有向量化模型的实现。这类函数虽然 TiDB 已下推计算,但 TiKV 会回退到使用火山模型而不是向量化模型,无法达成最优计算效率。\n\n综上,TiDB 内置函数在 TiKV 侧有几种实现状态:\n\n1. 完全没有实现,如 `FromDays` 函数。\n\n2. 已有火山模型的实现,没有向量化模型的实现,如 `BitLength` 函数。\n\n3. 火山模型和向量化都已实现,如 `LTReal` 函数。\n\n[PCP: Migrate functions from TiDB](https://github.com/tikv/tikv/issues/5751) 这个任务就是希望大家能帮助我们在 TiKV 侧实现更多 TiDB 所支持的内置函数,并支持向量化计算。这个 issue 中 Non-Vectorize 打钩意味着函数已有火山模型的实现,Vectorized 打钩意味着函数已有向量化模型的实现。因此你可以:\n\n* 选择一个完全没有实现的函数,如 `FromDays`,从 TiDB 侧迁移它的代码到 TiKV 并实现在火山模型(Non-Vectorize)上,提个 PR +50 积分,再迁移到向量化模型(Vectorize)上,从而再提个 PR +50 积分。\n\n* 或选择一个已有火山模型但没有向量化实现的函数,如 `BitLength` 函数,为它适配向量化模型(Vectorize)接口,提个 PR +50 积分。\n\n**实现一个完全没有在 TiKV 侧实现的内置函数一般来说具有更高难度,因此能获得更高回报!**\n\n## 如何从 TiDB 迁移内置函数在火山模型上实现\n\n这部分在 [《三十分钟成为 Contributor | 为 TiKV 添加 built-in 函数》](https://pingcap.com/blog-cn/30mins-become-contributor-of-tikv) 中有所介绍,大家可以照着这个教程来,这里就不再赘述。\n\n>注:由于 Coprocessor 框架实现的是 Fallback 机制,不允许函数只有向量化实现而没有火山模型实现。因此,若一个内置函数完全没有在 TiKV 侧实现,请先将它在火山模型上进行实现,再迁移至向量化模型。\n\n## 如何为函数适配向量化模型接口\n\n**以下本文的重点!**\n\n如果一个内置函数在 TiKV 中已经有了火山模型的实现,但没有向量化模型的实现,则可以迁移它。以 LogicalXor 内置函数为例,它之前并没有向量化的实现(当然现在 [有了](https://github.com/tikv/tikv/pull/5826))。可以遵循以下步骤:\n\n### 1. 找到火山模型的实现\n\n在 `components/tidb_query/src/expr/scalar_function.rs` 中搜索 `LogicalXor`,可以发现这个函数的实现位于 `logical_xor` 函数:\n\n```rust\nLogicalXor => logical_xor,\n```\n\n接下来搜索 `fn logical_xor` 就可以定位到函数具体内容,位于 `builtin_op.rs`(PS:不同内置函数会在不同文件中,不要照搬):\n\n```rust\npub fn logical_xor(&self, ctx: &mut EvalContext, row: &[Datum]) -> Result> {\n let arg0 = try_opt!(self.children[0].eval_int(ctx, row));\n let arg1 = try_opt!(self.children[1].eval_int(ctx, row));\n Ok(Some(((arg0 == 0) ^ (arg1 == 0)) as i64))\n}\n```\n\n### 2. 翻译为向量化实现\n\n阅读理解上面的代码,可知 `LogicalXor` 是一个二元内置函数。其中,第一个参数 `children[0]` 和第二个参数 `children[1]` 都是通过 `eval_int` 方式访问的,因此 `LogicalXor` 接受的两个参数都是 int 类型。最后,这个函数返回值是 `Result>` 代表它计算结果也是 int 类型。可以由这些信息翻译为以下向量化计算代码,实现在 `components/tidb_query/src/rpn_expr/impl_op.rs` 文件中:\n\n \n```rust\n#[rpn_fn]\n#[inline]\npub fn logical_xor(arg0: &Option, arg1: &Option) -> Result> {\n // TODO\n}\n```\n\n\n> 注:`Int` 是 `i64` 的 Type Alias。你既可以写 `Int` 也可以写 `i64`,不过更推荐 `Int` 一些。你可以从[这里](https://github.com/tikv/tikv/blob/d019ccecefc260ff760a53b7b8742fb84ffca9b5/components/tidb_query/src/codec/data_type/mod.rs#L10)找到所有的 Type Alias。`eval_xxx` 函数与类型的对应关系如下表所示。\n\n| 火山模型函数名 | 对应参数类型 | 参数类型别名 |\n|:-- |:-- |:----- | \n| `eval_int` | `Int` | `i64`|\n| `eval_real` | `Real` | `ordered_float::NotNan`|\n|`eval_decimal` | `Decimal` | \n|`eval_bytes` | `Bytes` | `Vec`|\n|`eval_time` | `DateTime` | \n|`eval_duration` | `Duration` | \n|`eval_json` | `Json` | \n\n换句话说就是:向量化版本的 `logical_xor` 是一个接受两个参数且两个参数都是 Int 类型的函数,返回 Int,是不是非常直观呢?另外我们使用 `None` 来代表 SQL 中的 `NULL` 值,因此函数参数及返回值都是 `Option` 类型。\n\n最后照搬原来的内部实现(注意处理好 `None` / `Some` 的情况),这个函数就算完成了:\n\n```rust\n#[rpn_fn]\n#[inline]\npub fn logical_xor(arg0: &Option, arg1: &Option) -> Result> {\n Ok(match (arg0, arg1) {\n (Some(arg0), Some(arg1)) => Some(((*arg0 == 0) ^ (*arg1 == 0)) as i64),\n _ => None,\n })\n}\n```\n\n你可能会问,不是说好了向量化计算是批量计算的吗,为什么向量化计算版本的代码没有接受数组,而只是接受单个值呢?原因在于 TiKV 向量化计算框架会自动基于你的这个基本实现,在编译期生成向量化计算版本,伪代码类似于这样:\n\n```rust\nfn logical_xor_vector_scalar(arg0: []Int, arg1: Int) -> []Int {\n let r = vec![];\n for i in 0..n {\n r.push( logical_xor(arg0[i], arg1) );\n }\n return r;\n}\n \nfn logical_xor_scalar_vector(arg0: Int, arg1: []Int) -> []Int {\n let r = vec![];\n for i in 0..n {\n r.push( logical_xor(arg0, arg1[i]) );\n }\n return r;\n}\n \nfn logical_xor_vector_vector(arg0: []Int, arg1: []Int) -> []Int {\n let r = vec![];\n for i in 0..n {\n r.push( logical_xor(arg0[i], arg1[i]) );\n }\n return r;\n}\n \nfn logical_xor_scalar_scalar(arg0: Int, arg1: Int) -> []Int {\n let r = vec![];\n for i in 0..n {\n r.push( logical_xor(arg0, arg1) );\n }\n return r;\n}\n```\n\n\n你只需要关注内置函数本身的逻辑实现,其他的全部自动搞定!这些所有的奥秘都隐藏在了 `#[rpn_fn]` 过程宏中。\n\n当然,上面的伪代码只是便于你进行理解。这个过程宏的实际实现并不是像上面这样粗暴地组装代码。它巧妙地利用了 Rust 的泛型机制,让编译器去生成不同个数参数情况下的最优实现。这里有点偏题就不继续展开细说了,我们后续的源码阅读文章对这个机制会有进一步分析,感兴趣的同学可以阅读代码自行学习。\n\n### 3. 增加函数入口\n\n目前只是提供了向量化版本的函数实现,但还需要告诉向量化计算框架,在遇到 LogicalXor 这个内置函数的时候,使用上向量化版本 `logical_xor` 的实现。这一步很简单,修改 `components/tidb_query/src/rpn_expr/mod.rs` 文件中的 `map_expr_node_to_rpn_func` 函数,增加一个对应关系即可:\n \n```rust\nScalarFuncSig::LogicalXor => logical_xor_fn_meta(),\n```\n\n注意,此处要为函数名加上 `_fn_meta` 后缀,从而用上 `#[rpn_fn]` 过程宏自动生成的向量化版本函数实现。不要问为什么,问就是约定 :D \n\n### 4. 撰写单元测试\n\n搜索 `ScalarFuncSig::LogicalXor` 可以找到火山模型下的该函数单元测试:\n\n \n```rust\n#[test]\nfn test_logic_op() {\n let tests = vec![\n ...\n (\n ScalarFuncSig::LogicalXor,\n Datum::I64(1),\n Datum::I64(1),\n Some(0),\n ),\n (\n ScalarFuncSig::LogicalXor,\n Datum::I64(1),\n Datum::I64(0),\n Some(1),\n ),\n (\n ScalarFuncSig::LogicalXor,\n Datum::I64(0),\n Datum::I64(0),\n Some(0),\n ),\n (\n ScalarFuncSig::LogicalXor,\n Datum::I64(2),\n Datum::I64(-1),\n Some(0),\n ),\n (ScalarFuncSig::LogicalXor, Datum::I64(0), Datum::Null, None),\n (ScalarFuncSig::LogicalXor, Datum::Null, Datum::I64(1), None),\n ];\n let mut ctx = EvalContext::default();\n for (op, lhs, rhs, exp) in tests {\n let arg1 = datum_expr(lhs);\n let arg2 = datum_expr(rhs);\n ……\n }\n}\n```\n\n\n这个测试覆盖挺完备的,因此可以直接拿样例来复用,作为向量化版本的单元测试。向量化版本单元测试中不再使用 Datum 等结构,而是可以直接用最原始的基础数据结构 `Option`,配上 `RpnFnScalarEvaluator` 进行执行,代码如下:\n\n \n```rust\n#[test]\nfn test_logical_xor() {\n let test_cases = vec![\n (Some(1), Some(1), Some(0)),\n (Some(1), Some(0), Some(1)),\n (Some(0), Some(0), Some(0)),\n (Some(2), Some(-1), Some(0)),\n (Some(0), None, None),\n (None, Some(1), None),\n ];\n for (arg0, arg1, expect_output) in test_cases {\n let output = RpnFnScalarEvaluator::new()\n .push_param(arg0)\n .push_param(arg1)\n .evaluate(ScalarFuncSig::LogicalXor)\n .unwrap();\n assert_eq!(output, expect_output);\n }\n}\n```\n\n如果原来火山模型实现的单元测试不完备,那么请在你的向量化实现中的单元测试中补充更多测试样例,尽可能覆盖所有分支条件。你也可以从 TiDB 的实现中迁移测试样例。注意,测试的目标是要检测实现是否符合预期,预期的是 TiKV 实现与 TiDB 实现能输出一样的结果,因此 TiDB 的输出是标准输出,不能由你自己来决定这个函数的标准输出。\n\n不过,有些情况下 TiDB 的输出可能与 MySQL 不一致,你可以选择与 TiDB 行为保持一致,也可以选择与 MySQL 行为保持一致,但都需要在 TiDB 中开 issue 汇报这个行为不一致情况。\n\n### 5. 运行测试\n\n至此,这个函数已经可以工作起来了,可以运行单元测试看一下:\n\n```\nmake dev\n```\n\n或者干脆只跑刚才写的这个测试:\n\n```\nEXTRA_CARGO_ARGS=\"test_logical_xor\" make dev\n```\n\n**测试通过就可以提 PR 了。注意要在 PR 的开头写上 `PCP #5751` 指明这个 PR 对应的性能挑战赛题目,不然合了是得不到积分的。另外我们鼓励每个 PR 都专注于做一件事情,所以请尽量不要在同一个 PR 内迁移或实现多个内置函数,否则只能得到一次 50 积分。**\n\n### 6. 运行下推测试\n\n众所周知,手工编写的测试样例往往会遗漏一些考虑欠缺的边缘情况,并且可能由于犯了一些错误,测试的预期输出实际与 TiDB 不一致。为了能覆盖这些边缘情况,进一步确保 TiKV 中的内置函数实现与 TiDB 的实现一致,我们有一批使用 [randgen](https://github.com/MariaDB/randgen) 自动生成的下推测试,位于 [https://github.com/tikv/copr-test](https://github.com/tikv/copr-test)。不管你是在 TiKV 中引入一个新的函数实现,还是迁移一个现有实现,都需要确保能跑过这个测试。流程如下:\n\n1. 需要确保你新实现的函数在 [copr-test](https://github.com/tikv/copr-test) 项目的 [push-down-test/functions.txt](https://github.com/tikv/copr-test/blob/master/push-down-test/functions.txt) 文件中,如果没有的话需要往 [copr-test](https://github.com/tikv/copr-test) 项目提 PR 将函数加入测试列表中。你需要将 SQL 里的函数名追加在文件中,或者可以参考 [all_functions_reference.txt](https://github.com/tikv/copr-test/blob/master/push-down-test/all_functions_reference.txt) 文件,这个文件里列出了所有可以写的函数名,从中挑出你的那个函数名,加入 [push-down-test/functions.txt](https://github.com/tikv/copr-test/blob/master/push-down-test/functions.txt)。\n\n2. 假设 [copr-test](https://github.com/tikv/copr-test) 中提的 PR 是 #10,则在你之前提的 TiKV PR 中回复 `@sre-bot /run-integration-copr-test copr-test=pr/10` 运行下推测试。如果你的函数之前已经在 [push-down-test/functions.txt](https://github.com/tikv/copr-test/blob/master/push-down-test/functions.txt) 列表中了,可以直接回复 `@sre-bot /run-integration-copr-test` 运行下推测试。\n\n当然,我们更推荐你能直接往 [copr-test](https://github.com/tikv/copr-test) 中添加人工编写的测试,更准确地覆盖边缘情况,具体方式参见 [copr-test](https://github.com/tikv/copr-test) 的 README。\n\n### 7. 在 TiDB 中增添签名映射\n\n如果上一步 copr-test 的测试挂了,一般来说有两种情况,一种情况是内置函数的实现有问题,被 copr-test 测了出来,另一种情况是你新实现的内置函数在 TiDB 侧还未建立函数签名与下推枚举签名 `ScalarFuncSig` 之间的映射关系。后者会在测试中产生 “unspecified PbCode” 错误,非常容易辨别。如果出现了这种情况,大家可以参考 [https://github.com/pingcap/tidb/pull/12864](https://github.com/pingcap/tidb/pull/12864) 的做法,为 TiDB 提 PR 增添相应内置函数的 PbCode 映射。添加完毕之后,可以在 TiKV PR 中回复 `@sre-bot /run-integration-copr-test copr-test=pr/X tidb=pr/Y`(其中 `X` 是你提的 copr-test PR 号,`Y` 是你提的 TiDB PR 号)进行联合测试。\n\n## 完成!\n\n至此,你新实现的内置函数有了单元测试,也有了与 TiDB 的集成下推测试,是一个合格的 PR 了,可以接受我们的 review。在 merge 后,你就能拿到相应的积分,积分可以在赛季结束后兑换 [TiDB 限量周边礼品](https://pingcap.com/community-cn/tidb-performance-challenge/)!\n\n最后欢迎大家加入 [TiDB Community Slack Workspace](https://join.slack.com/t/tidbcommunity/shared_invite/enQtNzc0MzI4ODExMDc4LWYwYmIzMjZkYzJiNDUxMmZlN2FiMGJkZjAyMzQ5NGU0NGY0NzI3NTYwMjAyNGQ1N2I2ZjAxNzc1OGUwYWM0NzE) 和 [tikv-wg Slack Workspace](http://tikv.org/chat),参赛过程中遇到任何问题都可以直接通过 **#performance-challenge-program** channel 与我们取得联系。","date":"2019-11-11","author":"Wish","fillInMethod":"writeDirectly","customUrl":"how-to-join-in-the-tidb-performance-challenge-program","file":null,"relatedBlogs":[]},{"id":"Blogs_186","title":"让数据库运行在浏览器里?TiDB + WebAssembly 告诉你答案","tags":["WebAssembly","SQL","Go","MySQL","TiDB"],"category":{"name":"社区动态"},"summary":"今天的 TiDB 可以直接运行在浏览器本地。打开浏览器,你可以直接创建数据库,对数据进行增删改查。关掉浏览器,一切都消失了,干净绿色环保。","body":"一直以来都有个梦想:\n\n希望有一个数据库能够弹性扩展(分布式)到成百上千节点的规模,易于学习和理解,可以运行在私有云、公有云、Multi-Cloud、Kubernetes,也能够跑在嵌入式设备(比如树莓派)上,更酷的是也能够直接运行在浏览器里,而且不需要任何浏览器扩展(Extension),变成「口袋数据库」,就像那部电影《蚁人》。\n\n**今天,这一切都变成了现实:[TiDB](https://github.com/pingcap/tidb) 可以直接运行在浏览器本地。打开浏览器,你可以直接创建数据库,对数据进行增删改查。关掉浏览器,一切都消失了,干净绿色环保——**\n\n首先在笔记本浏览器打开 [play.pingcap.com](https://play.pingcap.com)(这里用的是 MacOS 上面的 Chrome,不确定其它浏览器是否正常),可能需要几秒来加载页面,然后就能看到熟悉的 Shell 了。现在来试试几个 SQL 语句吧!由于 TiDB 基本兼容 MySQL 协议和语法,因此我们可以用熟悉的 MySQL 风格操作,如下图所示:\n\n\n\n图 1 在浏览器上运行 TiDB
\n\n**是不是很酷?无痛体验 SQL 的时代到了。**\n\n**更酷的是,这一切都运行在浏览器本地,删库再也不用跑路了 😈**\n\n有了这些,那么是时候给在线学习 SQL 教程的网站加点功能了,比如在文字教程时,同步运行 SQL 语句。这里有个简单的 [演示](https://tour.pingcap.com/):\n\n\n\n图 2 SQL 教程网站演示
\n\n**那么在浏览器里面运行数据库还有哪些好处呢?**\n\n还记得你安装配置数据库的痛苦吗?从此以后,每个人随时随地都可以拥有一个数据库,再也没有痛苦的安装过程,再也不用痛苦的配置参数,随时享受写 SQL 的快感。也许我们不再需要 indexdb 了,SQL 是更高级的 API,TiDB 使得「一次编写、到处运行」变成了现实。\n\n当然,你一定很好奇这一切是怎么实现的:\n\n+ 首先要感谢 Go team 让 Go 语言支持了 WebAssembly(Wasm),这是近期最让我兴奋的特性之一,它让在浏览器里运行 Go 语言编写的应用程序成为了现实;\n\n+ 然后感谢 PingCAP 的开源分布式数据库 TiDB。我们把 TiDB 编译成 Wasm,在浏览器里直接运行生成的 Wasm 文件,这就使得在浏览器里运行一个数据库成为了现实。如果没有记错,TiDB 好像是 Go 语言编写的第一个可以在浏览器里面运行的 SQL 数据库;\n\n+ 特别感谢参加 [TiDB Hackathon 2019](https://github.com/pingcap/presentations/blob/master/hackathon-2019/hackathon-2019-projects.md) 的选手和大家各种有趣的想法,尤其感谢 Ti-cool 团队,在他们的努力下这一切变成了现实,该项目获得了 Hackathon 二等奖,现场评委团老师们也感到眼前一亮,对它的快速落地充满了期待!\n\n>“TiDB-Wasm 极大降低了用户体验 TiDB 能力和初步验证 SQL 兼容性的门槛,使用体验就像 golang playground 一样流畅,Wasm 的出现也为 TiDB 文档中心的建设提出了新的思路,也许不久的将来,TiDB 用户可以像 golang 一样,在阅读文档的同时,就能够在页面上尝试实际操作的体验。我们也期待 Wasm 能够持续发展,实现 TiKV 的沙箱化运行,提供更贴近真实运行场景的 playground,甚至在自动化运维管理方向上贡献更新奇思路。”\n>\n>——李凯(美团 | 数据库团队负责人)\n>\n>“刚看到这个项目的时候真的眼前一亮,这是一个非常酷的创意,而且真的对 DBA 运维管理 TiDB 有非常大的帮助,个人强烈希望这个项目能尽快落地支持!\n>\n>目前我们公司使用 TiDB 时,有很大一部分是由现在业务改造接入,但是面临的一个很重要的问题是 应用原来都是基于 MySQL 开发,虽然 TiDB 在 SQL 语法兼容上做了很多的工作,但是仍然未能 100% 覆盖,所以业务切换前我们都必须要进行 SQL 语法兼容性测试及数据准确性校验。由于 TiDB 的部署都是在线上服务器,基于数据安全,我们的生产和办公网环境是隔离的,要实现上面的需求,目前我们有如下几种方式:a) 研发同学自己写脚本连接查看;b)DBA 登录集群协助验证;c)开发专用查询平台支持。目前这这几种方式都不够安全且效率低下。随着我们维护的 TiDB 集群越来越多,DBA 的对这种低效工作不堪其烦,急需相关工具支持,而 TiDB-Wasm 无疑会解决这种问题,所以希望官方能够重视这个项目,并尽快落地实现。”\n>\n>——于伯伟(58集团 | 数据库高级经理)\n>\n>\n>“Wasm 是一个神奇的技术,也许诞生初期的目的只是为了解决 js 运行速度以及其他语言如何操作 html 的问题,但现在大家在用这种技术广泛尝试各种可能。TiDB-Wasm 就是一个很好的尝试,不仅大幅度降低了新人使用 TiDB 的难度、也给文档展示提供了神奇的操作环境、还能大幅度降低应用开发者本机调试环境的构建难度。相信这个思路能给其他服务端的软件一个很好的启发。”\n>\n>——李道兵(京东云 | 高级总监)\n>\n>“很多用户希望初步了解 TiDB 但是苦于找不到简单即用的线下环境,这导致他们还未入门就已经放弃。TiDB-Wasm 有望彻底解决这个问题。基于 TiDB-Wasm,用户可以方便的开启 session 来探索 TiDB 的特性和功能,调试 TiDB 的行为,以及对比 TiDB 与 MySQL 等数据库在 SQL 语法、加锁行为、事务隔离等级等细节上的差异,从而帮助用户更深入的理解 TiDB。对官方而言,甚至可以把路由、计算、存储层的扩容缩容、迁移等最佳实践集成到该平台并可视化该过程,从而给用户更真实、直观的感受。这将是一款令人激动的产品,它将促进 TiDB 社区更加繁荣,也将让所有 TiDB 用户受益!”\n>\n>——赵应钢(美团点评 | 分布式数据库平台开发和运维负责人,研究员)\n>\n>“TiDB-Wasm 这个项目成功地将 TiDB 移植到了 Wasm,证明了 TiDB 编译到 Wasm 的可行性,同时也反映了 WebAssembly 已走向成熟,相信后面会有更多项目移植到浏览器里运行。目前项目还处于 demo 阶段,后续如果将项目继续落地,在上面添加更多功能,比如使用 indexedDB 让数据持久化,比如使用 webrtc 之类的技术让不同浏览器中的 TiDB 可以进行 P2P 通讯,实现分布式浏览器数据库,我非常期待这些实现。”\n>\n>——侯圣文(贝壳找房 | 数据技术总监)\n>\n>“TiDB-Wasm 让我看到了 TiDB 的更多可能性。Wasm 本身是一个很有野心和想象力的技术,极大的扩展了前端的能力,可能大家都玩过类似 go playgound, rust playground 这类 web 的可交互体验平台,TiDB-Wasm 更进一步让用户甚至在离线环境下就能直接体验,可谓最极致的易用。从实用角度上来看,除了能成为一个浏览器中的 REPL 供配合文档快速体验和实验之外,TiDB-Wasm 甚至未来还可以作为 js 的 localStorage API 的很好的补充,为 js 生态提供一个 SQLite 之外的高性能本地数据库……当然,在体验上仍然有很多可以优化的地方,例如给 binary 瘦身,加入集群模式支持等。总体来说这是一个很好玩的项目。”\n>\n>——黄东旭(PingCAP | 联合创始人兼 CTO)\n>\n>“这个项目可以说集新颖性和实用性于一身,用一种很巧妙的方式,将数据库这样硬核的基础架构和炫酷的前端领域搭上关系,接下来二者就可以碰撞出各种火花。最直接的用法是大大降低用户体验 TiDB 的成本,只需要一个浏览器页面和等待下载 Binary 的时间,完全不需要安装部署,就可以体验 TiDB 基本的功能,无论是嵌入到文档中快速运行实例还是作为 Playgroud 网站让用户自由发挥,都非常合适。再扩展想一下,TiDB 可以看作 MySQL 的替代品,那么很多 MySQL 的教学网站也可以用这个 Wasm 来提升教学体验。当然,Demo 中演示的 SQL 教学只是最基本的玩法,有了这个东西,我们可以说:恭喜前端圈有了一个 JS 版本的 MySQL。相信前端的同学能把它玩出花来。一句话总结:这绝对是一个叫好又叫座的项目。”\n>\n>——申砾(PingCAP | Engineering VP)\n\n**接下来我们可以试试更多有趣的想法:**\n\n+ 让更多的在线 SQL 教程都可以直接运行。\n+ 让 TiDB 运行在 Go Playground 上,或许需要 Go team 的帮助。\n+ 支持持久化数据库,我们已经有了云计算、边缘计算,为什么不能有浏览器计算呢?\n+ ……\n\n还有好多想法我们将在接下来的文章里介绍。如果你有新的、有趣的想法,欢迎 [联系我们](mailto:info@pingcap.com)。\n\n**下一篇文章将由 Ti-cool 团队成员介绍整个项目的实现原理和后续改进工作,敬请期待!如果你已经等不及了,可以在这里直接看 [源码实现](https://github.com/pingcap/tidb/pull/13069),祝大家玩得开心!**","date":"2019-11-05","author":"Max","fillInMethod":"writeDirectly","customUrl":"tidb-in-the-browser-running-a-golang-database-on-wasm","file":null,"relatedBlogs":[]},{"id":"Blogs_44","title":"TiKV 项目首个 SIG 成立,一起走上 Contributor 进阶之路吧!","tags":["社区","社区动态"],"category":{"name":"社区动态"},"summary":"今天是 1024 程序员节,我们正式成立 TiKV 项目的首个 SIG —— Coprocessor SIG,希望对 TiKV 项目感兴趣的小伙伴们都能加入进来,探索硬核的前沿技术,交流切磋,一起走上 Contributor 的进阶之路!","body":"社区是一个开源项目的灵魂,随着 TiDB/TiKV [新的社区架构升级](https://pingcap.com/blog-cn/tidb-community-upgrade/), TiKV 社区也计划逐步成立更多个 Special Interest Group(SIG )吸引更多社区力量,一起来改进和完善 TiKV 项目。SIG 将围绕着特定的模块进行开发和维护工作,并对该模块代码的质量负责。\n\n今天是 1024 程序员节,我们正式成立 TiKV 项目的首个 SIG —— Coprocessor SIG,希望对 [TiKV 项目](https://github.com/tikv/tikv) 感兴趣的小伙伴们都能加入进来,探索硬核的前沿技术,交流切磋,一起走上 Contributor 的进阶之路!\n\n## Coprocessor 模块是什么?\n\n为了提升数据库的整体性能,TiDB 会将部分计算下推到 TiKV 执行,即 TiKV 的 Coprocessor 模块。本次成立的 Coprocessor SIG 就聚焦在 TiKV 项目 Coprocessor 模块。本 SIG 的主要职责是对 Coprocessor 模块进行未来发展的讨论、规划、开发和维护。\n\n## 如何加入 Coprocessor SIG?\n\n**社区的 Reviewer 或更高级的贡献者(Committer,Maintainer)将提名 Active Contributor 加入 Coprocessor SIG。Active Contributor 是对于 TiKV Coprocessor 模块或者 TiKV 项目有浓厚兴趣的贡献者,在过去 1 年为 TiKV 项目贡献超过 8 个 PR。**\n\n加入 SIG 后,Coprocessor SIG Tech Lead 将指导成员完成目标任务。在此过程中,成员可以从 Active Contributor 逐步晋升为 Reviewer、Committer 角色,解锁更多角色权利&义务。\n\n+ Reviewer:从 Active Contributor 中诞生,当 Active Contributor 对 Coprocessor 模块拥有比较深度的贡献,并且得到 2 个或 2 个以上 Committer 的提名时,将被邀请成为该模块的 Reviewer,主要权利&义务:\n - 参与 Coprocessor PR Review 与质量控制;\n - 对 Coprocessor 模块 PR 具有有效的 Approve / Request Change 权限;\n - 参与项目设计决策。\n+ Committer:资深的社区开发者,从 Reviewer 中诞生。当 Reviewer 对 Coprocessor 模块拥有非常深度的贡献,或者在保持 Coprocessor 模块 Reviewer 角色的同时,也在别的模块深度贡献成为了 Reviewer,这时他就在深度或者广度上具备了成为 Committer 的条件,只要再得到 2 个或 2 个以上 Maintainer 的提名时,即可成为 Committer,主要权利及义务:\n - 拥有 Reviewer 具有的权利与义务;\n - 整体把控项目的代码质量;\n - 指导 Contributor 与 Reviewer。\n\n## 工作内容有哪些?\n\n1. 完善测试\n\n\t* 为了进一步提高 Coprocessor 的集成测试覆盖率,TiKV 社区开源了 copr-test 集成测试框架(github.com/tikv/copr-test),便于社区为 Coprocessor 添加更多集成测试;\n\t\n\t* 从 TiDB port 的函数需要同时 port 单元测试,如果 TiDB 的单元测试没有覆盖所有的分支,需要补全单元测试;\n\t\n\t* Expression 的集成测试需要构造使用这个 Expression 的算子进行测试。\n\n2. 提升代码质量\n\n\t* Framework: 计算框架改进,包括表达式计算框架、算子执行框架等;\n\t\n\t* Executor: 改进现有算子、与 TiDB 协作研发新算子;\n\t\n\t* Function: 维护现有的 UDF / AggrFn 实现或从 TiDB port 新的 UDF / AggrFn 实现;\n\t\n\t* 代码位置:[https://github.com/tikv/tikv/tree/master/components/tidb_query](https://github.com/tikv/tikv/tree/master/components/tidb_query)\n\n3. 设计与演进 Proposal\n\n4. Review 相关项目代码\n\n## 如何协同工作?\n\n1. 为了协同效率,我们要求 SIG 成员遵守一致的代码风格、提交规范、PR Description 等规定。具体请参考 [文档](https://github.com/tikv/tikv/blob/master/CONTRIBUTING.md)。\n\n\n2. 任务分配方式\n\n\t* SIG Tech Lead 在 github.com/tikv/community 维护公开的成员列表与任务列表链接;\n\t\n\t* 新加入的 SIG 成员可有 2 周时间了解各个任务详情并认领一个任务,或参与一个现有任务的开发或推动。若未能在该时间内认领任务则会被移除 SIG;\n\t\n\t* SIG 成员需维持每个月参与开发任务,或参与关于现有功能或未来规划的设计与讨论。若连续一个季度不参与开发与讨论,视为不活跃状态,将会被移除 SIG。作为 acknowledgment,仍会处于成员列表的「Former Member」中。\n\n3. 定期同步进度,定期周会\n\n\t* 每 2 周以文档形式同步一次当前各个项目的开发进度;\n\t\n\t* 每 2 周召开一次全组进度会议,时间依据参会人员可用时间另行协商。目前没有项目正在开发的成员可选择性参加以便了解各个项目进度。若参与开发的成员不能参加,需提前请假且提前将自己的月度进度更新至文档;\n\t\n\t* 每次会议由一名成员进行会议记录,在会议结束 24 小时内完成会议记录并公开。会议记录由小组成员轮流执行;\n\t\n\t* Slack:[https://tikv-wg.slack.com](https://tikv-wg.slack.com/join/shared_invite/enQtNTUyODE4ODU2MzI0LWVlMWMzMDkyNWE5ZjY1ODAzMWUwZGVhNGNhYTc3MzJhYWE0Y2FjYjliYzY1OWJlYTc4OWVjZWM1NDkwN2QxNDE)(Channel #copr-sig-china)\n\t\n4. 通过更多线上、线下成员的活动进行交流合作。\n\n## Coprocessor SIG 运营制度\n\n1. 考核 & 晋升制度\n\n\ta. Coprocessor SIG Tech Lead 以月为单位对小组成员进行考核,决定成员是否可由 Active Contributor 晋升为 Reviewer:\n\t\n + 熟悉代码库;\n + 获得至少 2 位 TiKV Committer 的提名;\n + PR 贡献满足以下任意一点:\n - Merge Coprocessor PR 总数超过 10 个;\n - Merge Coprocessor PR 总行数超过 1000 行;\n - 已完成一项难度为 Medium 或以上的任务;\n - 提出设计想法并得到采纳成为可执行任务超过 3 个。\n\t\n\tb. Coprocessor SIG Tech Lead 和 TiKV Maintainer 以季度为单位对小组成员进行考核,决定成员是否可由 Reviewer 晋升为 Committer:\n\t\n\t+ 表现出良好的技术判断力;\n\t+ 在 TiKV / PingCAP 至少两个子项目中是 Reviewer;\n\t+ 获得至少 2 位 TiKV Maintainer 的提名;\n\t+ 至少完成两项难度为 Medium 的任务,或一项难度为 High 的任务;\n\t+ PR 贡献满足以下至少两点:\n\t - 半年内 Merge Coprocessor PR 总行数超过 1500 行;\n\t - 有效 Review Coprocessor PR 总数超过 10 个;\n\t - 有效 Review Coprocessor PR 总行数超过 1000 行。\n\n2. 退出制度\n\n\ta. SIG 成员在以下情况中会被移除 SIG,但保留相应的 Active Contributor / Reviewer / Committer 身份:\n\t\n\t + 作为新成员未在指定时间内认领任务;\n\t + 连续一个季度处于不活跃状态。\n\t\n\tb. Reviewer 满足以下条件之一会被取消 Reviewer 身份且收回权限(后续重新考核后可恢复):\n\t\n\t + 超过一个季度没有 review 任何 Coprocessor 相关的 PR;\n\t + 有 2 位以上 Committer 认为 Reviewer 能力不足或活跃度不足。\n\n3. Tech Lead 额外承担的职责\n\n + SIG 成员提出的问题需要在 2 个工作日给出回复;\n + 及时 Review 代码;\n + 定时发布任务(如果 SIG 成员退出后,未完成的任务需要重新分配)。\n\n## 小结\n\n通过上文相信大家对于 Coprocessor SIG 的工作内容、范围、方式以及运营制度有了初步的了解。如果你是一个开源爱好者,想要参与到一个工业级的开源项目中来,或者想了解社区的运行机制,想了解你的代码是如何从一个想法最终发布到生产环境中运行,那么加入 Coprocessor SIG 就是一个绝佳的机会!\n\n**如果你仍对 SIG 有些疑问或者想要了解更多学习资料,欢迎加入 [tikv-wg.slack.com](https://tikv-wg.slack.com/join/shared_invite/enQtNTUyODE4ODU2MzI0LWVlMWMzMDkyNWE5ZjY1ODAzMWUwZGVhNGNhYTc3MzJhYWE0Y2FjYjliYzY1OWJlYTc4OWVjZWM1NDkwN2QxNDE) 哦~**","date":"2019-10-24","author":"Long Heng","fillInMethod":"writeDirectly","customUrl":"tikv-coprocessor-sig","file":null,"relatedBlogs":[]},{"id":"Blogs_62","title":"新架构、新角色:TiDB Community Upgrade!","tags":["社区","社区动态"],"category":{"name":"社区动态"},"summary":"TiDB 社区已经逐渐成熟,但是随着社区的发展壮大,我们逐渐感受到了现在社区架构上的一些不足。经过一系列的思考和总结,我们决定升级和调整目前社区组织架构,引入更多的社区角色和社区组织,以便更好的激发社区活力,维护积极健康的社区环境。","body":"经过几年的发展,TiDB 社区已经逐渐成熟,但是随着社区的发展壮大,我们逐渐感受到了现在社区架构上的一些不足。经过一系列的思考和总结,我们决定升级和调整目前社区组织架构,引入更多的社区角色和社区组织,以便更好的激发社区活力,维护积极健康的社区环境。\n\n## 老社区架构\n\n下图是之前官网上的社区架构图:\n\n\n\n图 1 老社区架构
\n\n老社区架构主要面向 TiDB 开发者社区(Developer Group),主要角色有 Maintainer、Committer、Contributor 等,其中:\n\n* Committer:由 Maintainer 或 PMC 推荐,是对 TiDB 有突出贡献的 Contributor。需要独立完成至少一个 feature 或修复重大 bug。\n\n* Maintainer:项目的规划和设计者,拥有合并主干分支的权限,从 Committer 中产生。他们必须对子项目的健康表现出良好的判断力和责任感。维护者必须直接或通过委派这些职责来设置技术方向并为子项目做出或批准设计决策。\n\n可以看到老社区架构屏蔽了日益壮大的、对产品打磨升级至关重要的 TiDB 用户群体,并且老架构中对于开发者社区角色的职责、角色之间关系的表述都比较简单,所以我们在新社区架构中做了一些加法,将 TiDB 用户社区纳入进来的同时,对 TiDB 开发者社区的每个角色定义、权责又做了明确的界定,同时也增加了一些新角色、新组织,下面让我们来详细地看一看。\n\n## 新社区架构\n\n### 变化 1:将 TiDB 用户社区纳入整体社区架构\n\n随着 TiDB 产品的成熟,TiDB 用户群体愈发壮大,用户在使用过程中遇到的问题反馈及实践经验,对于 TiDB 产品的完善及应用推广有着不可忽视的重要作用。因此我们此次正式将 TiDB 用户社区(TiDB User Group,简称 TUG)纳入新的社区架构中来,希望用户与开发者有更好的交流互动,一起推动 TiDB 社区的健康发展。\n\n\n\n图 2 新社区架构之 User Group
\n\nTiDB User Group(TUG)是由 TiDB 用户发起的独立、非盈利的第三方组织,用户实行自我管理,旨在加强 TiDB 用户之间的交流和学习。TUG 的形式包括但不限于线上问答和技术文章分享、线下技术沙龙、走进名企、官方互动活动等等。TUG 成员可以通过线上、线下的活动,学习前沿技术知识,发表技术见解,共同建设 TiDB 项目。更多信息可以登陆 TUG 问答论坛 [asktug.com](https://asktug.com) 查看。\n\n### 变化 2:Active Contributor 和 Reviewer\n\n\n\n图 3 新社区架构之 Active Contributor、Reviewer
\n\n上图反映了这次社区架构升级的第 2 个变化:在开发者社区中,新增了 Reviewer 和 Active Contributor 的角色。\n\nActive Contributor 是一年贡献超过 8 个 PR 的 Contributor。Reviewer 从 Active Contributor 中诞生,具有 Review PR 的义务,并且对 TiDB 或者 TiKV 某个子模块的 PR 的点赞(LGTM)有效。关于这些角色,我们将在后文介绍 Special Interest Group 时更详细地介绍。\n\n### 变化 3:Special Interest Group\n\n让我们把开发者社区架构图放大再看看:\n\n\n\n图 4 新社区架构之 Special Interest Group
\n\n上图展示了以垂直的视角来细看开发者社区的整体架构,反映了这次社区架构升级的第 3 个变化:引入了 “专项兴趣小组”(Special Interest Group,简称 SIG)。\n\n专项兴趣小组主要负责 TiDB/TiKV 某个模块的开发和维护工作,对该模块代码的质量负责。我们将邀请满足条件的 Active Contributor 加入专项兴趣小组,开发者们将在专项兴趣小组中获得来自 Tech Lead 们的持续指导,一边锻炼技术能力,一边优化和完善该模块。社区开发者们可通过专项兴趣小组逐渐从初始的 Active Contributor 成长为受到社区认可的 Reviewer、Committer 和 Maintainer。一般而言每个专项兴趣小组都会周期性的组织会议,讨论最近进展和遇到的问题,所有的会议讨论都公开在社区上,方便感兴趣的同学一起参与和讨论。\n\n具体可参考目前我们正在运营的表达式专项兴趣小组:[Expression Special Interest Group](https://github.com/pingcap/community/tree/master/special-interest-groups/sig-exec)(注:该 SIG 在 2020 年升级为 Execution Special Interest Group,即 Exec SIG)。\n\n另外这张图也反映了社区角色和专项兴趣小组的关系,我们来仔细看看 SIG 中的社区角色:\n\n1. Active Contributor\n + 即一年贡献超过 8 个 PR 的 Contributor。\n + 如果要加入某个 SIG,某个 Contributor 需要在 1 年内为该 SIG 所负责的模块贡献超过 8 个以上的 PR,这样即可获得邀请,加入该 SIG 进行针对性的学习和贡献。\n\n2. Reviewer\n + 隶属于某个 SIG,具有 Review PR 的义务。\n + Reviewer 从 Active Contributor 中诞生,当 Active Contributor 对该模块拥有比较深度的贡献,并且得到 2 个或 2 个以上 Committer 的提名时,将被邀请成为该模块的 Reviewer。\n + Reviewer 对该模块代码的点赞(LGTM)有效(注:TiDB 要求每个 PR 至少拥有 2 个 LGTM 后才能够合并到开发分支)。\n\n3. Tech Lead\n + 即 SIG 的组织者,负责 SIG 的日常运营,包括组织会议,解答疑问等。\n + Tech Lead 需要为 SIG 的管理和成长负责,责任重大。目前暂时由 PingCAP 内部同事担任,将来可由社区开发者一起担任,和 PingCAP 同事一起为 SIG 的进步而努力。\n\n再来看看另外两个角色:\n\n1. Committer\n + 资深的社区开发者,从 Reviewer 中诞生。\n + 当 Reviewer 对该模块拥有非常深度的贡献,或者在保持当前模块 Reviewer 角色的同时,也在别的模块深度贡献成为了 Reviewer,这时他就在深度或者广度上具备了成为 Committer 的条件,只要再得到 2 个或 2 个以上 Maintainer 的提名时,即可成为 Committer。\n\n2. Maintainer\n + 重度参与 TiDB 社区的开发者,从 Committer 中诞生,对代码 repo 拥有写权限。\n\n>以上社区角色的详细的定义和权责内容可以在 [这里](https://pingcap.com/community-cn/developer-group/) 查看。\n\n### 变化 4:Working Group\n\n\n\n\n图 5 新社区架构之 Working Group
\n\n第 4 个变化是开发者社区架构中引入了 “工作小组”(Working Group,简称 WG)。工作小组是由为了完成某个特定目标而聚集在一起的社区开发者与 PingCAP 同事一起成立。为了完成目标,有些工作小组可能跨越多个 SIG,有些小组可能只会专注在某个具体的 SIG 中做某个具体的事情。\n\n工作小组具有生命周期,一旦目标完成,工作小组即可解散。工作小组运营和管理的唯一目标是确保该小组成立时设置的目标在适当的时间内完成。一般而言,工作小组也会有周期性的会议,用于总结目前项目进展,确定下一步实施方案等。\n\n可参考目前我们正在运营的表达式工作小组:[Vectorized Expression Working Group](https://github.com/pingcap/community/blob/master/working-groups/wg-vec-expr.md)。\n\n## 总结和未来的工作\n\n总的来说,这次社区架构升级主要有如下改进:\n\n1. 引入了 TiDB 用户社区(TiDB User Group)。\n\n2. 引入了 Active Contributor、Reviewer 的社区角色。\n\n3. 引入了 Special Interest Group(SIG)。\n\n4. 引入了 Working Group(WG)。\n\n在社区运营方面,我们未来还将继续:\n\n1. 完善社区成员晋级的指导机制,让社区同学从 Contributor 成长到 Committer 或 Maintainer 有路可循。\n\n2. 让社区上的事情更加成体系,做事不乱。\n\n3. 让社区同学更有归属感,加强和其他社区成员的沟通。\n\n在未来,我们将陆续开放更多的专项兴趣小组和工作小组。在专项兴趣小组中,还将持续发放更多数据库相关的资料,帮助成员在专项兴趣小组中逐渐深度参与 TiDB 的开发工作。希望大家都能够多多参与进来,一起将 TiDB 打造成开源分布式关系型数据库的事实标准!","date":"2019-10-22","author":"Jian Zhang","fillInMethod":"writeDirectly","customUrl":"tidb-community-upgrade","file":null,"relatedBlogs":[]},{"id":"Blogs_153","title":"十分钟成为 Contributor 系列 | TiDB 向量化表达式活动第二弹","tags":["TiDB","社区","Contributor"],"category":{"name":"社区动态"},"summary":"在上篇文章中,我们介绍了 TiDB 如何实现表达式的向量化优化,以及社区同学如何参与这项工程。两周过去了,我们收到了很多来自社区小伙伴们的建议和反馈,今天在这里和大家分享一下活动进展和这些建议及反馈。","body":"在 [上篇文章](https://pingcap.com/blog-cn/10mins-become-contributor-of-tidb-20190916/) 中,我们介绍了 TiDB 如何实现表达式的向量化优化,以及社区同学如何参与这项工程。两周过去了,我们收到了很多来自社区小伙伴们的建议和反馈,今天在这里和大家分享一下活动进展和这些建议及反馈。\n\n## 活动进展\n\n**先来看看这两周的活动进展吧。截至 9 月 30 日中午,所有 Issue 中需要向量化的函数签名总共有 517 个,目前已完成 89 个,占总体的 17%。其中绝大多数的函数签名向量化都是由社区开发者们完成的,感谢大家的贡献!**\n\n各类型函数签名的完成度如下,我们通过这几个 Issue 来追踪向量化的工作进展,欢迎大家去里面挑选感兴趣的,还未被其他人认领的函数签名去实现:\n\n* [Date/Time builtin functions](https://github.com/pingcap/tidb/issues/12101) (7/65)\n\n* [Decimal builtin functions](https://github.com/pingcap/tidb/issues/12102) (7/31)\n\n* [Int builtin functions](https://github.com/pingcap/tidb/issues/12103) (22/187)\n\n* [JSON builtin functions](https://github.com/pingcap/tidb/issues/12104) (1/27)\n\n* [Real builtin functions](https://github.com/pingcap/tidb/issues/12105) (28/49)\n\n* [String builtin functions](https://github.com/pingcap/tidb/issues/12106) (19/113)\n\n* [Duration builtin functions](https://github.com/pingcap/tidb/issues/12176) (5/45)\n\n## FAQ\n\n**Q1:前期开发过程中,PR 很容易和主干代码冲突,如何解决?**\n\nA1:在前期的开发过程中,我们发现大家的 PR 冲突比较多,抱歉给大家的开发带来了不便。目前该问题已由 [PR/12395](https://github.com/pingcap/tidb/pull/12395) 解决。经过这个 PR 以后,所有表达式的开发接口和测试接口都被预先定义好了,避免了不同 PR 修改同一行代码造成频繁的冲突。大家后续开发时,可以直接修改这些预先定义好的接口的内部实现,参考:[PR/12400](https://github.com/pingcap/tidb/pull/12400)。\n\n**Q2:如何让测试框架只测试某个具体函数签名?**\n\nA2:我们在 [PR/12153](https://github.com/pingcap/tidb/pull/12153) 中,支持了以命令行变量的方式,如 -args \"builtinLog10Sig\",让测试框架只跑被指定的函数,方便大家进行测试,更具体的使用方法请见此 PR 内的说明。\n\n**Q3:如何计算结果向量的 Null Bitmap?**\n\nA3:在 TiDB 中,我们使用一个 Bitmap 来标记 Column(也就是我们的“向量”) 中某个元素是否为 `NULL`,在向量化计算的函数中,经常会有如下处理 `NULL` 的需求: \n\n```\nfor rowID := range rows {\n if child1.IsNull(rowID) || child2.IsNull(rowID) {\n col.SetNull(rowID)\n continue\n }\n // do something\n}\n\n```\n\n上面的计算逻辑没有正确性问题,但是不够高效。在 [PR/12034](https://github.com/pingcap/tidb/pull/12034) 里面,我们为 Column 添加了一个 `MergeNulls()` 的接口,用于快速完成上面这段计算 NULL Bitmap 的过程。出于性能考虑,建议大家尽可能使用这一接口来计算结果向量的 NULL Bitmap,示例如下:\n\n```\ncol.MergeNulls(child1, child2)\nfor rowID := range rows {\n if col.IsNull(rowID) {\n continue\n }\n // do something\n}\n```\n\n## 开发者社区\n\n如上面所说,在表达式向量化优化过程中的代码绝大多数都是由社区开发者们贡献的,具体来说是以下 Contributor(按照 PR 数排序,“*” 表示这次活动中新晋的 TiDB Contributor):\n\n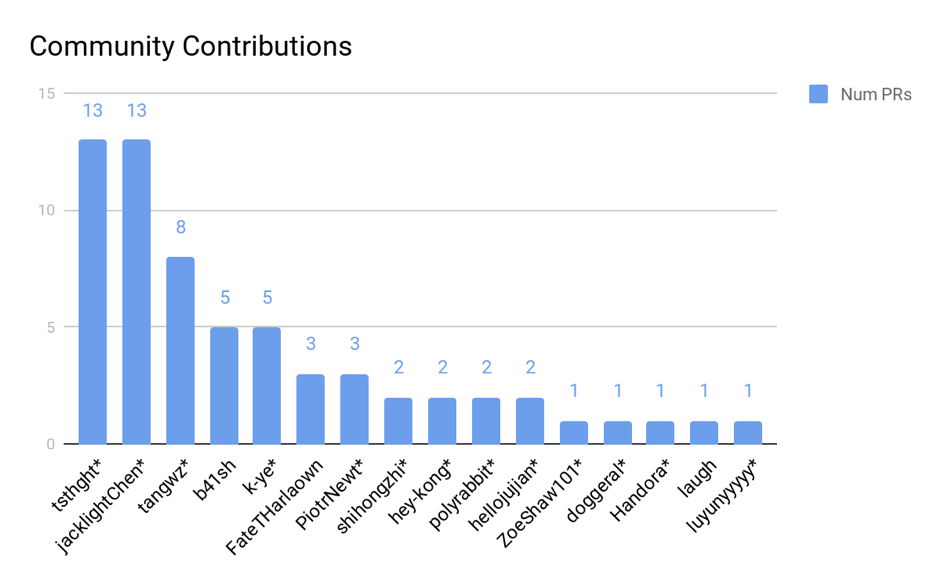\n\n再次感谢社区伙伴们的大力支持!也恭喜新晋 Contributor,当然 TiDB Contributor 专属马克杯也已经准备好啦,社区运营小姐姐将会统一邮寄给大家,敬请期待!\n\n在 TiDB 的 Expression Package 上,下面几位同学的 PR 贡献数已经超过了 8 个(包括向量化相关的 PR),达到了 Active Contributor 的要求,他们分别是:[jacklightChen](https://github.com/jacklightChen),[tsthght](https://github.com/tsthght),[tangwz](https://github.com/tangwz) 和 [b41sh](https://github.com/b41sh),也恭喜他们!\n\n成为 Active Contributor 之后,如果继续为 Expression Package 贡献 PR,且合并的 PR 数量超过 20 个,就有机会获得提名成为 Expression Package [Reviewer](https://github.com/pingcap/community/blob/master/special-interest-groups/sig-exec/roles-and-organization-management.md#from-active-contributor-to-reviewer)。Expression Package 的 Reviewer 在技术上受到社区认可,其对 PR 的 review comments 具有技术公信力,可以和 TiDB 工程师一起 Review Expression 包的 PR,并拥有点赞的权限,当然还拥有持续发展成 TiDB Committer 的机会!\n\n## 未来工作\n\n[上篇文章](https://pingcap.com/blog-cn/10mins-become-contributor-of-tidb-20190916/) 中提到,我们成立了 [Vectorized Expression Working Group](https://github.com/pingcap/community/blob/master/working-groups/wg-vec-expr.md),并在 slack - [tidbcommunity](https://pingcap.com/tidbslack) 中开放了 #wg-vec-expr 的公共 channel 供大家讨论问题,欢迎感兴趣的同学参与进来一起讨论表达式计算的向量化优化。目前表达式向量化重构的工作还在继续,欢迎各位新老 Contributor 持续的参与这项工程。\n\n此外,我们后续会优化升级 Community Organizer 组织架构,除了现在 Working Group 的组织以外,还会新增 Special Interest Group(简称 SIG),负责专门维护和开发 TiDB 中某些具体模块,并将在国庆节后成立 Expression 的 SIG。届时将邀请 Expression Package 中 Active Contributor 及以上角色的同学参加。我们会在 Expression SIG 中为社区同学提供详尽的辅导,帮助 SIG 中的同学在提升自我,满足自己兴趣的同时,持续为 TiDB 贡献代码,和 TiDB 一起成长,敬请期待! \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2019-09-30","author":"Yuanjia Zhang","fillInMethod":"writeDirectly","customUrl":"10mins-become-tidb-contributor-20190930","file":null,"relatedBlogs":[]},{"id":"Blogs_46","title":"十分钟成为 Contributor 系列 | 助力 TiDB 表达式计算性能提升 10 倍","tags":["TiDB","社区","Contributor"],"category":{"name":"社区动态"},"summary":"最近我们扩展了 TiDB 表达式计算框架,增加了向量化计算接口,初期的性能测试显示,多数表达式计算性能可大幅提升,部分甚至可提升 1~2 个数量级。为了让所有的表达式都能受益,我们需要为所有内建函数实现向量化计算。","body":"最近我们扩展了 TiDB 表达式计算框架,增加了向量化计算接口,初期的性能测试显示,多数表达式计算性能可大幅提升,部分甚至可提升 1~2 个数量级。为了让所有的表达式都能受益,我们需要为所有内建函数实现向量化计算。\n\nTiDB 的向量化计算是在经典 Volcano 模型上的进行改进,尽可能利用 CPU Cache,SIMD Instructions,Pipeline,Branch Predicatation 等硬件特性提升计算性能,同时降低执行框架的迭代开销,这里提供一些参考文献,供感兴趣的同学阅读和研究:\n\n1. [MonetDB/X100: Hyper-Pipelining Query Execution](http://cidrdb.org/cidr2005/papers/P19.pdf)\n\n2. [Balancing Vectorized Query Execution with Bandwidth-Optimized Storage](https://dare.uva.nl/search?identifier=5ccbb60a-38b8-4eeb-858a-e7735dd37487)\n\n3. [The Design and Implementation of Modern Column-Oriented Database Systems](https://www.nowpublishers.com/article/DownloadSummary/DBS-024)\n\n在这篇文章中,我们将描述:\n\n1. 如何在计算框架下实现某个函数的向量化计算;\n\n2. 如何在测试框架下做正确性和性能测试;\n\n3. 如何参与进来成为 TiDB Contributor。\n\n## 表达式向量化\n\n### 1. 如何访问和修改一个向量\n\n在 TiDB 中,数据按列在内存中连续存在 Column 内,Column 详细介绍请看:[TiDB 源码阅读系列文章(十)Chunk 和执行框架简介](https://pingcap.com/blog-cn/tidb-source-code-reading-10/)。本文所指的向量,其数据正是存储在 Column 中。\n\n我们把数据类型分为两种:\n\n1. 定长类型:`Int64`、`Uint64`、`Float32`、`Float64`、`Decimal`、`Time`、`Duration`;\n\n2. 变长类型:`String`、`Bytes`、`JSON`、`Set`、`Enum`。\n\n定长类型和变长类型数据在 Column 中有不同的组织方式,这使得他们有如下的特点:\n\n1. 定长类型的 Column 可以随机读写任意元素;\n\n2. 变长类型的 Column 可以随机读,但更改中间某元素后,可能需要移动该元素后续所有元素,导致随机写性能很差。\n\n对于定长类型(如 `int64`),我们在计算时会将其转成 Golang Slice(如 `[]int64`),然后直接读写这个 Slice。相比于调用 Column 的接口,需要的 CPU 指令更少,性能更好。同时,转换后的 Slice 仍然引用着 Column 中的内存,修改后不用将数据从 Slice 拷贝到 Column 中,开销降到了最低。\n\n对于变长类型,元素长度不固定,且为了保证元素在内存中连续存放,所以不能直接用 Slice 的方式随机读写。我们规定变长类型数据以追加写(`append`)的方式更新,用 Column 的 `Get()` 接口进行读取。\n\n总的来说,变长和定长类型的读写方式如下:\n\n1. 定长类型(以 `int64` 为例)\n\n a. `ResizeInt64s(size, isNull)`:预分配 size 个元素的空间,并把所有位置的 `null` 标记都设置为 `isNull`;\n \n b. `Int64s()`:返回一个 `[]int64` 的 Slice,用于直接读写数据;\n \n c. `SetNull(rowID, isNull)`:标记第 `rowID` 行为 `isNull`。\n\n2. 变长类型(以 `string` 为例)\n \n a. `ReserveString(size)`:预估 size 个元素的空间,并预先分配内存;\n \n b. `AppendString(string)`: 追加一个 string 到向量末尾;\n \n c. `AppendNull()`:追加一个 `null` 到向量末尾;\n \n d. `GetString(rowID)`:读取下标为 `rowID` 的 string 数据。\n\n当然还有些其他的方法如 `IsNull(rowID)`,`MergeNulls(cols)` 等,就交给大家自己去探索了,后面会有这些方法的使用例子。\n\n### 2. 表达式向量化计算框架\n\n向量化的计算接口大概如下([完整的定义在这里](https://github.com/pingcap/tidb/blob/master/expression/builtin.go#L340)):\n\n```\nvectorized() bool\nvecEvalXType(input *Chunk, result *Column) error\n```\n\n* `XType` 可能表示 `Int`, `String` 等,不同的函数需要实现不同的接口;\n\n* `input` 表示输入数据,类型为 `*Chunk`;\n\n* `result` 用来存放结果数据。\n\n外部执行算子(如 Projection,Selection 等算子),在调用表达式接口进行计算前,会通过 `vectorized()` 来判断此表达式是否支持向量化计算,如果支持,则调用向量化接口,否则就走行式接口。\n\n对于任意表达式,只有当其中所有函数都支持向量化后,才认为这个表达式是支持向量化的。\n\n比如 `(2+6)*3`,只有当 `MultiplyInt` 和 `PlusInt` 函数都向量化后,它才能被向量化执行。\n\n## 为函数实现向量化接口\n\n要实现函数向量化,还需要为其实现 `vecEvalXType()` 和 `vectorized()` 接口。\n\n* 在 `vectorized()` 接口中返回 `true` ,表示该函数已经实现向量化计算;\n\n* 在 `vecEvalXType()` 实现此函数的计算逻辑。\n\n**尚未向量化的函数在 [issue/12058](https://github.com/pingcap/tidb/issues/12058) 中,欢迎感兴趣的同学加入我们一起完成这项宏大的工程。**\n\n向量化代码需放到以 `_vec.go` 结尾的文件中,如果还没有这样的文件,欢迎新建一个,注意在文件头部加上 licence 说明。\n\n这里是一个简单的例子 [PR/12012](https://github.com/pingcap/tidb/pull/12012),以 `builtinLog10Sig` 为例:\n\n1. 这个函数在 `expression/builtin_math.go` 文件中,则向量化实现需放到文件 `expression/builtin_math_vec.go` 中;\n\n2. `builtinLog10Sig` 原始的非向量化计算接口为 `evalReal()`,那么我们需要为其实现对应的向量化接口为 `vecEvalReal()`;\n\n3. 实现完成后请根据后续的说明添加测试。\n\n下面为大家介绍在实现向量化计算过程中需要注意的问题。\n\n### 1. 如何获取和释放中间结果向量\n\n存储表达式计算中间结果的向量可通过表达式内部对象 `bufAllocator` 的 `get()` 和 `put()` 来获取和释放,参考 [PR/12014](https://github.com/pingcap/tidb/pull/12014),以 `builtinRepeatSig` 的向量化实现为例:\n\n```\nbuf2, err := b.bufAllocator.get(types.ETInt, n)\nif err != nil {\n return err\n}\ndefer b.bufAllocator.put(buf2) // 注意释放之前申请的内存\n```\n\n### 2. 如何更新定长类型的结果\n\n如前文所说,我们需要使用 `ResizeXType()` 和 `XTypes()` 来初始化和获取用于存储定长类型数据的 Golang Slice,直接读写这个 Slice 来完成数据操作,另外也可以使用 `SetNull()` 来设置某个元素为 `NULL`。代码参考 [PR/12012](https://github.com/pingcap/tidb/pull/12012),以 `builtinLog10Sig` 的向量化实现为例:\n\n```\nf64s := result.Float64s()\nfor i := 0; i < n; i++ {\n if isNull {\n result.SetNull(i, true)\n } else {\n f64s[i] = math.Log10(f64s[i])\n }\n}\n```\n\n### 3. 如何更新变长类型的结果\n\n如前文所说,我们需要使用 `ReserveXType()` 来为变长类型预分配一段内存(降低 Golang runtime.growslice() 的开销),使用 `AppendXType()` 来追加一个变长类型的元素,使用 `GetXType()` 来读取一个变长类型的元素。代码参考 [PR/12014](https://github.com/pingcap/tidb/pull/12014),以 `builtinRepeatSig` 的向量化实现为例:\n\n```\nresult.ReserveString(n)\n...\nfor i := 0; i < n; i++ {\n str := buf.GetString(i)\n if isNull {\n result.AppendNull()\n } else {\n result.AppendString(strings.Repeat(str, int(num)))\n }\n}\n```\n\n### 4. 如何处理 Error\n\n所有受 SQL Mode 控制的 Error,都利用对应的错误处理函数在函数内就地处理。部分 Error 可能会被转换成 Warn 而不需要立即抛出。\n\n这个比较杂,需要查看对应的非向量化接口了解具体行为。代码参考 [PR/12042](https://github.com/pingcap/tidb/pull/12042),以 `builtinCastIntAsDurationSig` 的向量化实现为例:\n\n```\nfor i := 0; i < n; i++ {\n ...\n dur, err := types.NumberToDuration(i64s[i], int8(b.tp.Decimal))\n if err != nil {\n if types.ErrOverflow.Equal(err) {\n err = b.ctx.GetSessionVars().StmtCtx.HandleOverflow(err, err) // 就地利用对应处理函数处理错误\n }\n if err != nil { // 如果处理不掉就抛出\n return err\n }\n result.SetNull(i, true)\n continue\n }\n ...\n}\n```\n\n### 5. 如何添加测试\n\n我们做了一个简易的测试框架,可避免大家测试时做一些重复工作。\n\n该测试框架的代码在 `expression/bench_test.go` 文件中,被实现在 `testVectorizedBuiltinFunc` 和 `benchmarkVectorizedBuiltinFunc` 两个函数中。\n\n我们为每一个 `builtin_XX_vec.go` 文件增加了 `builtin_XX_vec_test.go` 测试文件。当我们为一个函数实现向量化后,需要在对应测试文件内的 `vecBuiltinXXCases` 变量中,增加一个或多个测试 case。下面我们为 log10 添加一个测试 case:\n\n```\nvar vecBuiltinMathCases = map[string][]vecExprBenchCase {\n ast.Log10: {\n {types.ETReal, []types.EvalType{types.ETReal}, nil},\n },\n}\n```\n\n具体来说,上面结构体中的三个字段分别表示:\n\n1. 该函数的返回值类型;\n\n2. 该函数所有参数的类型;\n\n3. 是否使用自定义的数据生成方法(dataGener),`nil` 表示使用默认的随机生成方法。\n\n对于某些复杂的函数,你可自己实现 dataGener 来生成数据。目前我们已经实现了几个简单的 dataGener,代码在 `expression/bench_test.go` 中,可直接使用。\n\n添加好 case 后,在 expression 目录下运行测试指令:\n\n```\n# 功能测试\nGO111MODULE=on go test -check.f TestVectorizedBuiltinMathFunc\n\n# 性能测试\ngo test -v -benchmem -bench=BenchmarkVectorizedBuiltinMathFunc -run=BenchmarkVectorizedBuiltinMathFunc\n```\n\n在你的 PR Description 中,请把性能测试结果附上。不同配置的机器,性能测试结果可能不同,我们对机器配置无任何要求,你只需在 PR 中带上你本地机器的测试结果,让我们对向量化前后的性能有一个对比即可。\n\n## 如何成为 Contributor\n\n**为了推进表达式向量化计算,我们正式成立 Vectorized Expression Working Group,其具体的目标和制度详见[这里](https://github.com/pingcap/community/blob/master/working-groups/wg-vec-expr.md)。与此对应,我们在 [TiDB Community Slack](https://pingcap.com/tidbslack/) 中创建了 [wg-vec-expr channel](https://app.slack.com/client/TH91JCS4W/CMRD79DRR) 供大家交流讨论,不设门槛,欢迎感兴趣的同学加入。**\n\n如何成为 Contributor:\n\n1. 在此 [issue](https://github.com/pingcap/tidb/issues/12058) 内选择感兴趣的函数并告诉大家你会完成它;\n\n2. 为该函数实现 `vecEvalXType()` 和 `vectorized()` 的方法;\n\n3. 在向量化测试框架内添加对该函数的测试;\n\n4. 运行 `make dev`,保证所有 test 都能通过;\n\n5. 发起 Pull Request 并完成 merge 到主分支。\n\n如果贡献突出,可能被提名为 reviewer,reviewer 的介绍请看 [这里](https://github.com/pingcap/community/blob/master/CONTRIBUTING.md#reviewer)。\n\n如果你有任何疑问,也欢迎到 wg-vec-expr channel 中提问和讨论。 \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)\n","date":"2019-09-16","author":"Yuanjia Zhang","fillInMethod":"writeDirectly","customUrl":"10mins-become-contributor-of-tidb-20190916","file":null,"relatedBlogs":[]},{"id":"Blogs_72","title":"从使用者到开发者,知乎参与 TiDB 社区背后的故事","tags":["社区"],"category":{"name":"社区动态"},"summary":"“从前我们更多是站在使用者的角度从开源社区汲取养分,随着知乎技术架构和内部工程能力的成长,未来我们希望能够以更加积极主动的状态参与开源项目,回馈社区。”","body":">**作者介绍**:孙晓光,知乎技术平台团队负责人,负责建设知乎在线和离线的基础设施平台,为业务开发提供统一的基础设施。曾多年从事私有云相关产品开发工作,关注云原生技术,TiKV 项目 Committer。\n\n关注 TiDB 的朋友们可能发现继 Follower Read 在 TiKV 端的 PR 合并后,TiDB 端相关的 PR 也于近期完成了到主干的合并工作。如果后期的稳定性测试一切正常,相关功能应该会随 TiDB 3.1 发布。Follower Read 功能本身从代码量上看并不大,但这个功能的意义尤其是对互联网类型业务来说是非常大的。\n\n前段时间 PingCAP CTO 黄东旭已经写了 [一篇文章](https://pingcap.com/blog-cn/follower-read-the-new-features-of-tidb/),从原理角度对 Follower Read 做了非常透彻的介绍和分析。今天我想从非技术的角度介绍 Follower Read 功能的落地过程,并从 Contributor 的视角跟大家聊一聊个人参与 TiDB 开发过程中的体验和感受。最后站在知乎技术平台团队的角度,聊一下我们未来在积极参与开源项目,共同建设社区的愿望和决心。\n\n\n## Follower Read 背后的故事\n\n\nFollower Read 的实现思路在 PingCAP 工程师大脑里应该已经存在很久了,但出于各种原因这个特性的优先级一直不够高,并没有能排到开发计划中。年中的时候我们开始尝试在知乎更广泛的业务中引入 TiDB,在灰度过程中我们遇到了某些特定工作负载下 TiDB 表现不够理想的问题。目前看来 TiDB 读写操作都交给 Leader 完成,是我们目前在特定负载下遇到吞吐问题的瓶颈点。\n\n在理清思路后,我们同 PingCAP 的工程师做了几次交流并达成一致,决定通过 Follower Read 的方式来解决我们业务场景中极端热点数据访问的吞吐问题。在实际需求的驱动下, PingCAP 同学将 Follower Read 相关特性的优先级提高,快速确定了相关功能的技术方案并启动了 TiKV 端的开发工作。作为 Follower Read 功能的需求方,知乎负责这个需求在 TiDB 上的落地工作。\n\nPingCAP 工程师用了大约两周的时间完成了 [TiKV 层 Follower Read 整个功能的开发测试](https://github.com/tikv/tikv/pull/5051),并将其合并到 master 分支中,随后我们开始了 [TiDB 侧相应功能的开发](https://github.com/pingcap/tidb/pull/11347),在 PingCAP 小伙伴们的帮助下最终完成了相应功能到 master 分支的合并。作为知乎和 PingCAP 两家公司第一次联合开发的成果,这个功能的落地对双方都有着重大的意义。\n\n## 从 Contributor 到 Committer\n\n在以知乎技术平台团队成员的身份参与 TiDB 贡献之前,个人曾经在过去的一年里以用户的身份为 TiKV & TiDB 做过一些小型的贡献。接下来我就从个人角度聊一下从 Contributor 到 Committer 的成长过程和其中的体验。\n\n第一次为 PingCAP 旗下项目提交 PR 并成为 Contributor 发生在大约一年前,我在为内部开发的业务系统选择合适的存储后端时,尝试给 TiKV 增加了一些批量操作接口。PR 提出后,PingCAP 首席架构师唐刘很快就跟我建立了联系,在随后的交流中帮助我快速完善 PR 并最终合并到 TiKV 的主干中。\n\n虽然以往以零散的方式给很多开源项目提交过 Patch,但这次的体验是完全不同的,PingCAP 和社区伙伴们热心的帮助和鼓励让我切身感受到了活跃的开源社区所具有的独特魅力。随后出于个人兴趣,我在 TiDB 相关的项目中又陆陆续续做了一些简单的贡献,最终得到大家的认可成为 TiKV 项目的 Committer 之一。\n\n## 拥抱开源\n\n回过头来看这段时间的成长和收获都是巨大的,不但学习到了如何同开源社区众多优秀的贡献者更加高效的交流,并且对开源的价值理念和开源在基础软件领域的重大意义有了更加深入的理解。\n\n近期随着在公司所在团队的转换,我个人开始更多的关注在线和离线的基础设施在知乎的演进。知乎一直以来都鼓励拥抱开源,并基于大量开源组件搭建了知乎的技术架构,得益于开源的力量,知乎的内部平台一直都紧随着行业技术发展的潮流。从前我们更多是站在使用者的角度从开源社区汲取养分,随着知乎技术架构和内部工程能力的成长,未来我们希望能够以更加积极主动的状态参与开源项目,回馈社区。Follower Read 是知乎第一次以 Contributor 身份参与 TiDB 社区建设,未来我们会参与更多的技术社区的建设为开源社区的发展贡献我们的力量。","date":"2019-09-12","author":"孙晓光","fillInMethod":"writeDirectly","customUrl":"zhihu-the-story-of-contributing-to-tidb-community","file":null,"relatedBlogs":[]},{"id":"Blogs_175","title":"三十分钟成为 Contributor | 提升 TiDB Parser 对 MySQL 8.0 语法的兼容性","tags":["TiDB","社区","Contributor"],"category":{"name":"社区动态"},"summary":"本次活动聚焦于语法兼容,提升 TiDB SQL Parser 对 MySQL 8.0 的语法支持。对于新的贡献者而言,除了能将理论知识运用到实践上以外,还可以从中体验参与一个开源项目的整体流程与规范。","body":"TiDB 的一大特性就是和 MySQL 高度兼容,目标是让用户能够无需修改代码即可从 MySQL 迁移至 TiDB。要达成这个目标,需要完成两个提升兼容性的任务,分别是「语法兼容」和「功能行为兼容」。\n\n**本次活动聚焦于语法兼容,提升 TiDB SQL Parser 对 MySQL 8.0 的语法支持。对于新的贡献者而言,除了能将理论知识运用到实践上以外,还可以从中体验参与一个开源项目的整体流程与规范。**\n\n我们把 TiDB Parser 整体看作一个函数,输入是 SQL 字符串,输出是用于描述 SQL 语句的抽象语法树(AST)。在这个转换的过程中涉及到的组件有两个:一个是 lexer,负责将字符流变成 Token,并赋予它们类别标识,这个过程叫「Tokenize」;另一个是 parser,负责将 Token 转为树状结构,便于将来遍历和转换,这个过程叫「Parse」;TiDB 使用了 parser 生成工具 goyacc,它能够根据 `parser.y` 生成 `parser.go`,其中包含了名称为 `Parse` 的函数接口,供 TiDB 直接使用。更多关于 TiDB Parser 以及 Lex & Yacc 的信息请参考 [TiDB SQL Parser 的实现](https://pingcap.com/blog-cn/tidb-source-code-reading-5/)。\n\n## 参与流程\n\n参与流程分为 7 步:**领任务 -> 写 test case -> make test -> coding -> 补充 test case -> make test -> 提 PR**。\n\n### 1. 从 Issue 领取任务\n\n我们会在 [Improve parser compatibility](https://github.com/pingcap/tidb/issues/11486) 周期性发布不兼容的 Bad SQL Case 组,每组 Case 都会构成一个 Issue,Contributor 选择某个 Issue,在它的下方评论:**Let me fix it**。在我们将 Contributor 的 Github ID 添加到 Index Issue 中后,即完成任务的领取。\n\n### 2. 编写测试用例\n\n根据 Issue 描述的情况在 [`parser_test.go`](https://github.com/pingcap/parser/blob/master/parser_test.go) 中编写测试用例,除了 Issue 中提到的 Case 以外,可以适当添加更多的 Case。保证目标 SQL Case 语句能够通过 Parser 解析,并且通过 Restore 还原为预期的 SQL。\n\n### 3. 执行所有测试\n\nparser 根目录下运行 `make test`,确保第一次测试失败,并且失败的 Case 是第 2 步编写的。\n\n### 4. 编码\n\nContributor 修改文法规则。对于涉及到语义层面的规则变动,需要同步修改 AST 节点的数据结构(AST 节点定义在 `parser/ast` 中)。TiDB 通过 AST 树生成执行计划,修改 AST 节点可能会影响 TiDB 的行为,因此应尽量保持原有结构,不改变原有的属性,如果确实有修改 AST 树必要,我们会帮助 Contributor 检查 TiDB 的行为是否正常。另外,AST 节点其中的两个接口方法是 `Accept` 和 `Restore`,分别用于遍历子树和通过 AST 树还原 SQL 字符串。应确保它们的行为都符合预期。\n\n另外,还要检查新加的规则是否存在冲突问题。「冲突」可以被理解为当 parser 读到某个 token 时,有两种或以上的方式来构造语法树,从而导致歧义。goyacc 所生成的 parser 采用了 `LALR(1)` 方法进行解析,冲突有两类:一类是两条规则都能被用于归约,称为 `reduce-reduce` 冲突。另一类是既能使用一条规则归约,又能按照另一条规则移进下一个 token,称为 `shift-reduce` 冲突。可以通过指定优先级的方式消除冲突,具体可以参考 yacc 的 [%precedence 和 %prec 指示](https://www.gnu.org/software/bison/manual/html_node/Precedence.html#Precedence)。\n\n编码完成后在项目根目录下运行 `make parser`,这时会执行 goyacc 重新生成 `parser.go` 文件。\n\n### 5. 补充 test case\n\n根据实际情况尽可能提升测试覆盖率。\n\n### 6. 执行所有测试\n\nparser 根目录下运行 `make test`,确保测试通过。\n\n### 7. 提交 PR\n\t\n提交 PR 之前请先阅读 [contributing 指南](https://github.com/pingcap/tidb/blob/master/CONTRIBUTING.md)。下面是 PR 的模板,逐项填写即可。\n\n```\t\n### What problem does this PR solve?\n\n#### [ Put the subtask title here ]\n\nIssue: [ put the subtask issue link here ]\n\n#### MySQL Syntax:\n\n[ describe MySQL syntax here ]\n\n#### Bad SQL Case:\n\n[ give a SQL statement example that passes MySQL but fails TiDB parser ]\n\n[ give a SQL statement example that passes MySQL but fails TiDB parser ]\n\t\n...\n\t\n### Check List\n\t\nTests\n\n- Unit test\n```\n\n## 示例\n\n**下面以添加 「REMOVE PARTITIONING」 语法支持为例解释说明整个过程**。\n\n### 1. 从 Issue 领取任务\n\n从 [这里](https://github.com/pingcap/tidb/issues/11486) 找到 `REMOVE PARTITIONING` 子任务。[子任务 Issue](https://github.com/pingcap/parser/issues/402) 中有若干不兼容的 Case。\n\n首先,手动测试任一 Case,发现在 MySQL 下输出:\n\n```\nError 1505: Partition management on a not partitioned table is not possible\n```\n\n而在 TiDB 下输出:\n\n```\nError 1064: You have an error in your SQL syntax; check the manual that corresponds to your TiDB version for the right syntax to use line 1 column 20 near \"remove partitioning\"\n```\n\n这意味着 parser 无法识别 remove 关键字。\n\n确认了问题存在后,到 [该 Issue](https://github.com/pingcap/parser/issues/402) 下评论:**Let me fix it**,完成任务领取。\n\n### 2. 编写测试用例\n\n在 `parser_test.go` 下寻找合适位置添加测试用例,这里我们选择在 `func (s *testParserSuite) TestDDL(c *C)` 的 [末尾](https://github.com/pingcap/parser/pull/396/files#diff-688912c3f38a8a80d6bdc16c02088d69R2172) 添加:\n\n```\n// for remove partitioning\n{\"alter table t remove partitioning\", true, \"ALTER TABLE `t` REMOVE PARTITIONING\"},\n{\"alter table db.ident remove partitioning\", true, \"ALTER TABLE `db`.`ident` REMOVE PARTITIONING\"},\n{\"alter table t lock = default remove partitioning\", true, \"ALTER TABLE `t` LOCK = DEFAULT REMOVE PARTITIONING\"},\n```\n\n这里每一个 test case 分成了三部分,第一列是用于测试的 SQL 语句,第二列是「是否期望第一列的语句 parse 通过」,第三列是「从语法树 restore 后期望的 SQL 语句」。具体可以参考 [`TestDDL.RunTest()`](https://github.com/pingcap/parser/blob/53c769c5836485c83d5f339faab97ef5d853d560/parser_test.go#L308)。\n\n### 3. 执行所有测试\n\nparser 根目录下运行 `make test`,确保第一次测试失败,并且 fail 的 case 是第 2 步编写的。\n\n```\nFAIL: parser_test.go:1664: testParserSuite.TestDDL\n\nparser_test.go:2148:\n s.RunTest(c, table)\nparser_test.go:318:\n c.Assert(err, IsNil, comment)\n... value *errors.withStack = line 1 column 20 near \"remove partitioning\" (\"line 1 column 20 near \\\"remove partitioning\\\" \")\n... source alter table t remove partitioning\n```\n\n错误信息和期望的一致,则可以开始进行下一步。\n\n### 4. 编码\n\n#### 4.1 修改 `parser.y` 文件\n\n首先从 [MySQL 文法](https://github.com/mysql/mysql-server/blob/8.0/sql/sql_yacc.yy) 中找到 remove partitioning 的定义:\n\n```\nalter_table_stmt: ALTER TABLE_SYM table_ident opt_alter_table_actions\n| ALTER TABLE_SYM table_ident standalone_alter_table_action\n\nopt_alter_table_actions: opt_alter_command_list\n| opt_alter_command_list alter_table_partition_options\n\nalter_table_partition_options: partition_clause\n| REMOVE_SYM PARTITIONING_SYM\n```\n\n经过分析可得该语法只能出现在 SQL 语句的最后一个部分,并且只能出现一次。\n\n在 `parser.y` 中找到 `AlterTableStmt`,其中一条规则是:\n\n```\n\"ALTER\" IgnoreOptional \"TABLE\" TableName AlterTableSpecListOpt PartitionOpt\n```\n\n其中最后一个符号 PartitionOpt 和 MySQL 中 `partition_clause` 非常相似,为了支持 remove partitioning,容易想到引入一条规则:\n\n```\nAlterTablePartitionOpt: PartitionOpt | \"REMOVE\" \"PARTITIONING\"\n```\n\n将 `PartitionOpt` 的语义动作移到 `AlterTablePartitionOpt` 中,`REMOVE PARTITIONING` 部分先返回 `nil`,并添加 parser 警告,表示目前 parser 能够解析但 TiDB 尚未支持该功能。修改后的规则如下:\n\n```\nAlterTablePartitionOpt:\n\tPartitionOpt\n\t{\n\t\tif $1 != nil {\n\t\t\t$$ = &ast.AlterTableSpec{\n\t\t\t\tTp: ast.AlterTablePartition,\n\t\t\t\tPartition: $1.(*ast.PartitionOptions),\n\t\t\t}\n\t\t} else {\n\t\t\t$$ = nil\n\t\t}\n\t}\n|\t\"REMOVE\" \"PARTITIONING\"\n\t{\n\t\t$$ = nil\n\t\tyylex.AppendError(yylex.Errorf(\"The REMOVE PARTITIONING clause is parsed but ignored by all storage engines.\"))\n\t\tparser.lastErrorAsWarn()\n\t}\n```\n\n由于 `REMOVE` 和 `PARTITIONING` 都是新添加的关键字,如果不做任何处理,lexer 扫描的时候只会将它们看作普通的标识符。于是需要在 `parser.y` 的 `%token` 字段上补充声明,其中一个目的是为该字符串产生一个 `tokenID`(一个整数),供 lexer 标识。另外 `goyacc` 也会对 `parser.y` 中所有的字符串常量进行检查,如果没有相应的 `token` 声明,会报 `Undefined symbol` 的错误。\n\n为支持这两个关键字,我们在文件开头的 `token` 字段添加声明。由于 `REMOVE` 和 `PARTITIONING` 都是非保留关键字,它们应被添加在含有 `The following tokens belong to UnReservedKeyword` [注释](https://github.com/pingcap/parser/blob/53c769c5836485c83d5f339faab97ef5d853d560/parser.y#L274) 的下方。此外,非保留字说明它们能够作为标识符 `Identifier`,因此在 `Identifier` 规则下的 [`UnRerservedKeyword`](https://github.com/pingcap/parser/blob/53c769c5836485c83d5f339faab97ef5d853d560/parser.y#L3717) 中也应加上 `REMOVE` 和 `PARTITIONING`。\n\n关于如何确定一个关键字是保留的还是非保留的,可以参考 [MySQL 文档](https://dev.mysql.com/doc/refman/8.0/en/keywords.html)。\n\n#### 4.2 增加「关键字-`tokenID`」映射\n\n前文提到,添加声明是为了让 lexer 能够识别关键字并赋予对应的 `tokenID`,对于 lexer 而言,它需要一个从关键字字符串到 `tokenID` 的映射关系。在 TiDB parser 中,这个映射关系就是 [`misc.go`](https://github.com/pingcap/parser/blob/53c769c5836485c83d5f339faab97ef5d853d560/misc.go) 中的 `tokenMap` 结构。\n\n在这个例子中,我们往 `tokenMap` 中添加 `remove` 和 `partitioning`(如果不添加,会使关键字一致性的检查测试失败)。\n\n#### 4.3 修改 AST 节点\n\n到目前为止,我们已经让 `goyacc` 生成的 parser 能够解析 remove partitioning 语法。但是,解析完成后并没有返回有效的数据结构(4.1 中我们返回了 `nil`),这意味着 parser 不能够根据语法树重新生成原 SQL 语句。\n\n所以,要修改现有的 AST 节点,使它们能够以某种形式保存 remove partitioning 信息。回顾目前规则层面的修改:\n\n```\nAlterTableStmt:\n\"ALTER\" IgnoreOptional \"TABLE\" TableName AlterTableSpecListOpt PartitionOpt\n```\n\n已改为:\n\n```\nAlterTableStmt:\n\"ALTER\" IgnoreOptional \"TABLE\" TableName AlterTableSpecListOpt AlterTablePartitionOpt\nAlterTablePartitionOpt:\n PartitionOpt | \"REMOVE\" \"PARTITIONING\"\n```\n\n其中几个非终结符对应的数据结构如下:\n\n```\nAlterTableSpecListOpt -> []AlterTableSpec\nPartitionOpt -> PartitionOptions\n```\n\n关于修改节点,有几种方案可以选择:\n\n1. 增加一个新的节点 struct,表示 `AlterTablePartitionOpt`。其中包含 `PartitionOptions` 和一个 bool 值,表示是否为 remove partitioning。\n\n2. 将 remove partitioning 看作 `PartitionOptions`,在内部添加一个 bool 成员 `isRemovePartitioning` 以做区分。\n\n3. 将 `PartitionOpt` 和 remove partitioning 都看作 `AlterTableSpec`,为 `AlterTableSpec` 的添加一个类型,单独表示 remove partitioning。\n\n经过比较和分析,我们发现第一个方案会引入新的数据结构,有较大的概率会引起现有的 TiDB 测试不过,为此可能要修改 TiDB 方面的代码,工作量大的同时提高了 parser 的复杂度,因此作为备选方案;第二个方案没有引入新的数据结构,但是修改了现有的数据结构(加了个 bool 成员);第三个方案即没有添加也没有修改数据结构,并且能够以较少的代码完成任务,作为首选方案。\n\n**在以上的选择中,我们遵循「尽量不修改 AST 节点结构」的原则。**\n\n按照方案三,观察 [`AlterTableSpec`](https://github.com/pingcap/parser/pull/396/files#diff-688d51c34d61e5d538b15582305c9a8dL1768),其定义如下:\n\n```\ntype AlterTableSpec struct {\n node\n ...\n Tp AlterTableType\n Name string\n ...\n}\n```\n\n其中一个成员是 `Tp`,它所属的类型包含了 `AlterTable` 的许多操作,例如 `AddColumn`,`AddConstraint`,`DropColumn` 等。我们的任务是添加一个 [类似的 Type](https://github.com/pingcap/parser/pull/396/files#diff-688d51c34d61e5d538b15582305c9a8dR1708),让它能够表示 remove partitioning。\n\n到这里,解析完 SQL 语句生成的 AST 树已经包含 remove partitioning 的信息了。接下来要处理 Restore,让它能够从 AST 树还原出 SQL 语句。`AlterTableSpec` 的 Restore 十分简单,加一个 case 即可,这里不再赘述。\n\n#### 4.4 完善 `parser.y`\n\n第一次修改 `parser.y` 的时候我们在新加规则的语义动作中返回了 `nil`,原因是尚未确定 AST 是否需要修改,以及如何修改。而到这一步,这些都已经确定下来了,把 remove partitioning 看作 `AlterTableSpec` 类型:\n\n```\n| \"REMOVE\" \"PARTITIONING\"\n {\n $$ = &ast.AlterTableSpec{\n Tp: ast.AlterTableRemovePartitioning,\n }\n yylex.AppendError(yylex.Errorf(\"The REMOVE PARTITIONING clause is parsed but ignored by all storage engines.\"))\n parser.lastErrorAsWarn()\n }\n```\n\n注意,这里必须抛出警告,表示虽然目前 parser 能够解析该语法,但实际上 TiDB 并未支持相应的功能。\n\n#### 5. 补充 test case\n\n这里,所有的代码修改引入的分支结构都能够被现有的测试覆盖,因此在提升覆盖率上没有需求。当然,如果想要测试更多类似的 case,可以将它们添加到前面提到的 `TestDDL` 函数中。\n\n#### 6. 执行所有测试(`make test`)\n\n```\ngofmt (simplify)\nsh test.sh\nok github.com/pingcap/parser 4.294s coverage: 62.1% of statements in ./...\nok github.com/pingcap/parser/ast 2.090s coverage: 42.3% of statements in ./...\nok github.com/pingcap/parser/auth 1.155s coverage: 1.3% of statements in ./... [no tests to run]\nok github.com/pingcap/parser/charset 1.094s coverage: 2.0% of statements in ./...\nok github.com/pingcap/parser/format 1.114s coverage: 2.5% of statements in ./...\n? github.com/pingcap/parser/goyacc [no test files]\nok github.com/pingcap/parser/model 1.100s coverage: 3.5% of statements in ./...\nok github.com/pingcap/parser/mysql 1.102s coverage: 1.3% of statements in ./... [no tests to run]\nok github.com/pingcap/parser/opcode 1.099s coverage: 1.4% of statements in ./...\nok github.com/pingcap/parser/terror 1.091s coverage: 2.3% of statements in ./...\nok github.com/pingcap/parser/types 1.106s coverage: 7.0% of statements in ./...\n\n```\n\n**确保所有的 test 都是 ok 的状态。**\n\n#### 7. 提交 PR\n\n按照 PR 模板逐项填写。\n\n```\n### What problem does this PR solve?\n\n#### Fix compatibility problem about keyword REMOVE PARTITIONING\n\nIssue: pingcap/parser#402\n\n#### MySQL Syntax:\n\nalter_specification:\n...\n | REMOVE PARTITIONING\n\n### Bad SQL Case:\n\nalter table t remove partitioning;\nalter table t lock = default, remove partitioning;\nalter table t drop check c, remove partitioning;\n\n### Check List\n\nTests\n- Unit test\n\n```\n\n**需要特别指出的是,我们鼓励各位 Contributor 多使用 `make test`。当不知道从何处入手或者失去目标时,`make test` 输出的错误信息或许能够引导大家进行思考和探索**。\n\n>Tips: [完整的 PR 示例](https://github.com/pingcap/parser/pull/396)\n\n## FAQ\n\n以下是在增加 remove partitioning 语法支持时遇到的问题和解决方法。\n\n**Q1. 为什么不在 `PartitionOpt` 中直接添加规则?** \n\n**A1**:`PartitionOpt` 用于匹配含有 `partition by` 的 SQL 语句,除了 `Alter Table` 语句以外,它还被 `Create Table` 使用,而 `remove partitioning` 只存在于 `alter table` 语句中,因此不能在 `PartitionOpt` 中添加规则。\n\n**Q2. 执行 make test 时报错:** \n\n```\nparser.y:1100:1: undefined symbol \"PARTITIONING\"\nparser.y:1100:1: undefined symbol \"REMOVE\"\nmake[1]: *** [Makefile:19: parser] Error 1\n```\n\n**A2**:在 yacc 中,出现在规则中的字符串,要么是 `token`(终结符),要么是非终结符。这里引用一段 yacc 的规范:\n\n```\nNames refer to either tokens or nonterminal symbols.\nNames representing tokens must be declared; this is most simply done by writing\n%token name1 name2 . . .\n```\n\n所以,修复方法是在 `parser.y` 的 `%token` 字段上添加 `PARTITIONING` 和 `REMOVE` 的声明。\n\n**Q3. 执行 make test 时报错:** \n\n```\n c.Assert(len(tokenMap)-len(aliases), Equals, keywordCount-len(windowFuncTokenMap))\n... obtained int = 454\n... expected int = 456\n```\n\n**A3**:这是关键字的一致性检查出了问题,解决方案是补充 `tokenMap`(它是关键字到 `token ID` 的映射,被 scanner 用来判断某个字符串是否为关键字)。\n\n**Q4. 执行 make test 时报错:** \n\n```\nFAIL: parser_test.go:1666: testParserSuite.TestDDL\nparser_test.go:2166:\n s.RunTest(c, table)\nparser_test.go:351:\n c.Assert(restoreSQLs, Equals, expectSQLs, comment)\n... obtained string = \"ALTER TABLE `t`\"\n... expected string = \"ALTER TABLE `t` REMOVE PARTITIONING\"\n... restore ALTER TABLE `t`; expect ALTER TABLE `t` REMOVE PARTITIONING\n```\n\n**A4**:这个错误说明 parser 已经解析通过,但不能从语法树中恢复原 SQL 语句的 remove partitioning 部分。此时应检查相应 AST 节点的 Restore 方法是否正确处理了 `REMOVE PARTITIONING`。\n\n***最后欢迎大家加入 [TiDB Contributor Club](https://pingcap.com/community-cn/),无门槛参与开源项目,改变世界从这里开始吧!*** \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2019-08-08","author":"谢腾进 赵一霖","fillInMethod":"writeDirectly","customUrl":"30mins-become-contributor-of-tidb-20190808","file":null,"relatedBlogs":[]},{"id":"Blogs_119","title":"写给社区的回顾和展望:TiDB 2019, Level Up!","tags":["TiDB","TiKV","社区","社区动态"],"category":{"name":"社区动态"},"summary":"2018 年对于 TiDB 和 PingCAP 来说是一个由少年向成年的转换的一年,如果用一个关键字来概括就是「蜕变」。","body":"**2018 年对于 TiDB 和 PingCAP 来说是一个由少年向成年的转换的一年,如果用一个关键字来概括就是「蜕变」**。在这一年很欣喜的看到 TiDB 和 TiKV 在越来越多的用户使用在了越来越广泛的场景中,作为一个刚刚 3 岁多的开源项目,没有背后强大的社区的话,是没有办法取得这样的进展的。\n同时在技术上,2018 年我觉得也交出了一份令人满意的答卷,TiDB 的几个主要项目今年一共合并了 4380 个提交,这几天在整理 2018 年的 Change Log 时候,对比了一下年初的版本,这 4380 个 Commits 背后代表了什么,这里简单写一个文章总结一下。\n\n回想起来,TiDB 是最早定位为 HTAP 的通用分布式数据库之一,如果熟悉我们的老朋友一定知道,我们最早时候一直都是定位 NewSQL,当然现在也是。但是 NewSQL 这个词有个问题,到底 New 在哪,解决了哪些问题,很难一目了然,其实一开始我们就想解决一个 MySQL 分库分表的问题,但是后来慢慢随着我们的用户越来越多,使用的场景也越来越清晰,很多用户的场景已经开始超出了一个「更大的 MySQL 」的使用范围,于是我们从实验室和学术界找到了我们觉得更加清晰的定义:HTAP,希望能构建一个融合 OLTP 和 OLAP 通用型分布式数据库。但是要达成这个目标非常复杂,我们的判断是如果不是从最底层重新设计,很难达到我们的目标,**我们认为这是一条更困难但是正确的路,现在看来,这条路是走对了,而且未来会越走越快,越走越稳。**\n\n\n在 SQL 层这边,TiDB 选择了 MySQL 的协议兼容,一方面持续的加强语法兼容性,另一方面选择自研优化器和执行器,带来的好处就是没有任何历史负担持续优化。回顾今年最大的一个工作应该是重构了执行器框架,TiDB的 SQL 层还是经典的 Volcano 模型,我们引入了新的内存数据结构 Chunk 来批量处理多行数据,并对各个算子都实现了基于 Chunk 的迭代器接口,这个改进对于 OLAP 请求的改进非常明显,在 TiDB 的 TPC-H 测试集上能看出来([TiDB TPC-H 50G 性能测试报告](https://docs.pingcap.com/zh/search/?lang=zh&type=tidb&version=v4.0&q=TPCH)),Chunk 的引入为我们全面的向量化执行和 CodeGen 支持打下了基础。目前在 TiKV 内部对于下推算子的执行还没有使用 Chunk 改造,不过这个已经在计划中,在 TiKV 中这个改进,预期对查询性能的提升也将非常显著。\n\n另一方面,一个数据库查询引擎最核心的组件之一:优化器,在今年也有长足的进步。我们在 2017 年就已经全面引入了基于代价的 SQL 优化(CBO,Cost-Based Optimization),我们在今年改进了我们的代价评估模型,加入了一些新的优化规则,同时实现了 Join Re-Order 等一系列优化,从结果上来看,目前在 TPC-H 的测试集上,对于所有 Query,TiDB 的 SQL 优化器大多已给出了最优的执行计划。CBO 的另一个关键模块是统计信息收集,在今年,我们引入了自动的统计信息收集算法,使优化器的适应性更强。另外针对 OLTP 的场景 TiDB 仍然保留了轻量的 RBO 甚至直接 Bypass 优化器,以提升 OLTP 性能。另外,感谢三星韩国研究院的几位工程师的贡献,他们给 TiDB 引入了 Query Plan Cache,对高并发场景下查询性能的提升也很明显。另外在功能上,我们引入了 Partition Table 的支持,对于一些 Partition 特性很明显的业务,TiDB 能够更加高效的调度数据的写入读取和更新。\n\n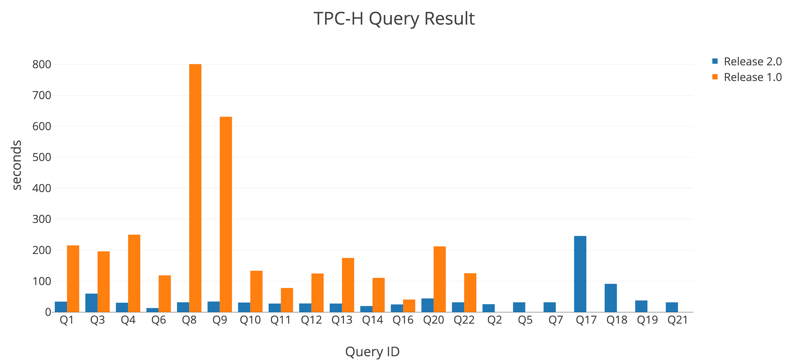\n\n一直以来,TiDB 的 SQL 层作为纯 Go 语言实现的最完备的 MySQL 语法兼容层,很多第三方的 MySQL 工具在使用着 TiDB 的 SQL Parser,其中的优秀代表比如小米的 Soar([https://github.com/XiaoMi/soar](https://github.com/XiaoMi/soar))。为了方便第三方更好的复用 TiDB Parser,我们在 2018 年将 Parser 从主项目中剥离了出来,成为了一个独立的项目:pingcap/parser,希望能帮到更多的人。\n\n说到 TiDB 的底层存储 TiKV 今年也有很多让人眼前一亮的更新。在 TiKV 的基石——一致性算法 Raft 这边,大家知道 TiKV 采用的是 Multi-Raft 的架构,内部通过无数个 Raft Group 动态的分裂、合并、移动以达到动态伸缩和动态负载均衡。我们在今年仍然持续在扩展 Multi-Raft 的边界,我们今年加入了动态的 Raft Group 合并,以减轻元信息存储和心跳通信的负担;给 Raft 扩展了 Learner 角色(只同步 Log 不投票的角色) 为 OLAP Read 打下基础;给 Raft 的基础算法加入了 Pre-Vote 的阶段,让整个系统在异常网络状态下可靠性更高。\n\n\n\nRaft Group Merge
\n\n在性能方面,我们花了很大的精力重构了我们单机上多 Raft Group 的线程模型([https://github.com/tikv/tikv/pull/3568](https://github.com/tikv/tikv/pull/3568)), 虽然还没有合并到 master 分支,在我们测试中,这个优化带来了两倍以上的吞吐提升,同时写入延迟降低至现在的版本的 1/2 ,预计在这两周我们会完成这个巨大的 PR 的 Code Review,各位同学可以期待一下 :)\n\n第三件事情是我们开始将 TiKV 的本地存储引擎的接口彻底抽象出来,目标是能做到对 RocksDB 的弱耦合,这点的意义很大,不管是社区还是我们自己,对新的单机存储引擎支持将变得更加方便。\n\n\n\n**在 TiKV 社区这边,今年的另外一件大事是加入了 CNCF,变成了 CNCF 的托管项目,也是 CNCF 基金会第一个非结构化数据库项目。** 后来很多朋友问我,为什么捐赠的是 TiKV 而不是 TiDB,其实主要的原因就像我在当天的一条 Tweet 说的,TiKV 更像是的一个更加通用的组件,当你有一个可以弹性伸缩的,支持跨行 ACID 事务的 Key-Value 数据库时,你会发现构建其他很多可靠的分布式系统会容易很多,这在我们之后的 [TiDB Hackathon](https://mp.weixin.qq.com/s/mKygN5EQoaaeFMDIFeAzsw)\n中得到了很好的体现。另外社区已经开始出现基于 TiKV 构建的 Redis 协议支持,以及分布式队列系统,例如 [meitu/titan](https://mp.weixin.qq.com/s/2tyAtcmKUU2L1yoE_V3SsA) 项目。作为一个基金会项目,社区不仅仅可以直接使用,更能够将它作为构建其他系统的基石,我觉得更加有意义。类似的,今年我们将我们的 Raft 实现从主项目中独立了出来(pingcap/raft-rs),也是希望更多的人能从中受益。\n\n>*“……其 KV与 SQL分层的方式,刚好符合我们提供 NoSQL 存储和关系型存储的需求,另外,PingCAP 的文档齐全,社区活跃,也已经在实际应用场景有大规模的应用,公司在北京,技术交流也非常方便,事实证明,后面提到的这几个优势都是对的……”*\n>\n>*——美图公司 Titan 项目负责人任勇全对 TiKV 的评论*\n\n在 TiDB 的设计之初,我们坚定将调度和元信息从存储层剥离出来(PD),现在看来,好处正渐渐开始显示出来。今年在 PD 上我们花了很大精力在处理热点探测和快速热点调度,调度和存储分离的架构让我们不管是在开发,测试还是上线新的调度策略时效率很高。瞬时热点一直是分布式存储的最大敌人,如何快速发现和处理,我们也有计划尝试将机器学习引入 PD 的调度中,这是 2019 会尝试的一个事情。总体来说,这个是一个长期的课题。\n\n我在几个月前的一篇文章提到过 TiDB 为什么从 Day-1 起就 All-in Kubernetes (《[十问 TiDB:关于架构设计的一些思考](https://pingcap.com/blog-cn/10-questions-tidb-structure/)》),今年很欣喜的看到,Kubernetes 及其周边生态已经渐渐成熟,已经开始有很多公司用 Kubernetes 来运行 Mission-critical 的系统,这也佐证了我们当年的判断。2018 年下半年,我们也开源了我们的 [TiDB Operator](https://pingcap.com/blog-cn/tidb-operator-introduction/)([https://github.com/pingcap/tidb-operator](https://github.com/pingcap/tidb-operator)),这个项目并不止是一个简单的在 K8s 上自动化运维 TiDB 的工具,在我们的战略里面,是作为 Cloud TiDB 的重要基座,过去设计一个完善的多租户系统是一件非常困难的事情,同时调度对象是数据库这种带状态服务,更是难上加难,TiDB-Operator 的开源也是希望能够借助社区的力量,一起将它做好。\n\n\n\n多租户 TiDB
\n\n今年还做了一件很大的事情,我们成立了一个新的部门 TEP(TiDB Enterprise Platform)专注于商业化组件及相关的交付质量控制。作为一个企业级的分布式数据库,TiDB 今年完成了商业化从0到1的跨越,越来越多的付费客户证明 TiDB 的核心的成熟度已经可以委以重任,成立 TEP 小组也是希望在企业级产品方向上继续发力。从 [TiDB-Lightning](https://pingcap.com/blog-cn/tidb-ecosystem-tools-2/)(MySQL 到 TiDB 高速离线数据导入工具)到 [TiDB-DM](https://pingcap.com/blog-cn/tidb-ecosystem-tools-3/)(TiDB-DataMigration,端到端的数据迁移-同步工具)能看到发力的重点在让用户无缝的从上游迁移到 TiDB 上。另一方面,[TiDB-Binlog](https://pingcap.com/blog-cn/tidb-ecosystem-tools-1/) 虽然不是今年的新东西,但是今年这一年在无数个社区用户的场景中锻炼,越来越稳定。做工具可能在很多人看来并不是那么「高科技」, 很多时候也确实是脏活累活,但是这些经过无数用户场景打磨的周边工具和生态才是一个成熟的基础软件的护城河和竞争壁垒,在 PingCAP 内部,负责工具和外围系统研发的团队规模几乎和内核团队是 1:1 的配比,重要性可见一斑。\n\n在使用场景上,TiDB 的使用规模也越来越大,下面这张图是我们统计的我们已知 TiDB 的用户,包括上线和准上线的用户,**从 1.0 GA 后,几乎是以一个指数函数的曲线在增长,应用的场景也从简单的 MySQL Sharding 替代方案变成横跨 OLTP 到实时数据中台的通用数据平台组件。**\n\n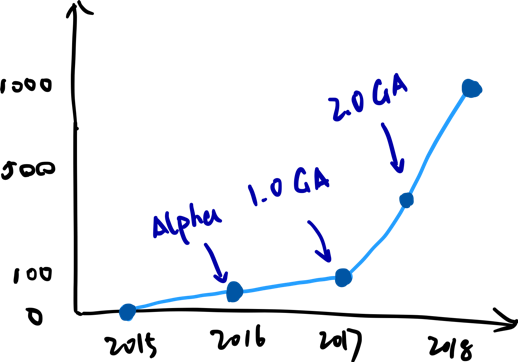\n\nTiDB 的用户数统计
\n\n今年几个比较典型的用户案例,从美团的横跨 OLTP 和实时数仓的深度实践,到转转的 All-in TiDB 的体验,再到 TiDB 支撑的北京银行的核心交易系统。可以看到,这些案例从互联网公司的离线线数据存储到要求极端 SLA 的传统银行核心交易系统,TiDB 在这些场景里面都发光发热,甚至有互联网公司(转转)都喊出了 All-in TiDB 的口号,我们非常珍视这份信任,一定尽全力做出漂亮的产品,高质量的服务好我们的用户和客户。另一方面,TiDB 也慢慢开始产生国际影响力的,在线视频巨头葫芦软件(Hulu.com),印度最大的在线票务网站 BookMyShow,东南亚最大的电商之一 Shopee 等等都在大规模的使用 TiDB,在北美和欧洲也已经不少准上线和测试中的的巨头互联网公司。\n\n**简单回顾了一下过去的 2018 年,我们看看未来在哪里。**\n\n其实从我们在 2018 年做的几个比较大的技术决策就能看到,2019 年将是上面几个方向的延续。大的方向的几个指导思想是:\n\n1. **Predicable.** (靠谱,在更广泛的场景中,做到行为可预测。)\n\n2. **Make it right before making it fast.**(稳定,先做稳,再做快。)\n\n3. **Ease of use.** (好用,简单交给用户,复杂留给自己。)\n\n对于真正的 HTAP 场景来说,最大的挑战的是如何很好的做不同类型的 workload 隔离和数据结构根据访问特性自适应。我们在这个问题上给出了自己的答案:通过拓展 Raft 的算法,将不同的副本存储成异构的数据结构以适应不同类型的查询。\n\n这个方法有以下好处:\n\n1. 本身在 Multi-Raft 的层面上修改,不会出现由数据传输组件造成的瓶颈(类似 Kafka 或者 DTS),因为 Multi-Raft 本身就是可扩展的,数据同步的单位从 binlog,变成 Raft log,这个效率会更高,进一步降低了同步的延迟。\n\n2. 更好的资源隔离,通过 PD 的调度,可以真正将不同的副本调度到隔离的物理机器上,真正做到互不影响。\n\n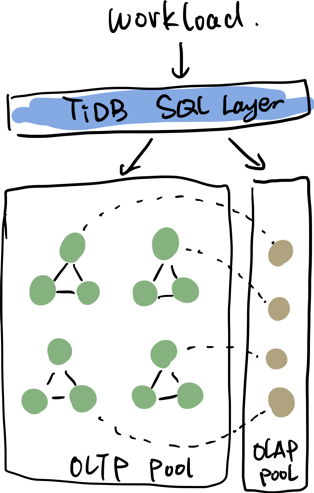\n\nTiDB 2019 年会变成这个样子
\n\n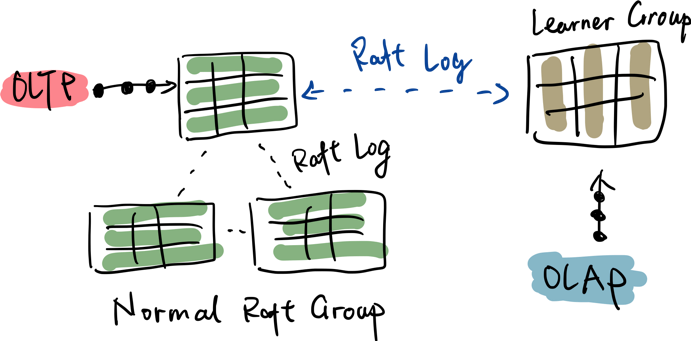\n\nLearner 在 HTAP 中的应用
\n\n在执行器方面,我们会继续推进向量化,不出意外的话,今年会完成所有算子的全路径的向量化执行。\n\n这个 HTAP 方案的另一个关键是存储引擎本身。2019 年,我们会引入新的存储引擎,当然第一阶段仍然会继续在 RocksDB 上改进,改进的目标仍然是减小 LSM-Tree 本身的写放大问题。选用的模型是 [WiscKey(FAST16)](https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf),WiscKey 的核心思想是将 Value 从 LSM-Tree 中剥离出来,以减少写放大,如果关注 TiKV 的朋友,已经能注意到我们已经在前几天将一个**新存储引擎 Titan**(PingCAP 的 Titan,很遗憾和美图那个项目重名了)合并到了 TiKV 的主干分支,这个 Titan 是我们在 RocksDB 上的 WiscKey 模型的一个实现,除了 WiscKey 的核心本身,我们还加入了对小 KV 的 inline 等优化,Titan 在我们的内部测试中效果很好,对长度随机的 key-value 写入的吞吐基本能达到原生 RocksDB 的 2 - 3 倍,当然性能提升并不是我最关注的,这个引擎对于 TiDB 最大的意义就是,这个引擎将让 TiDB 适应性更强,做到更加稳定,更加「可预测」。\n\n\n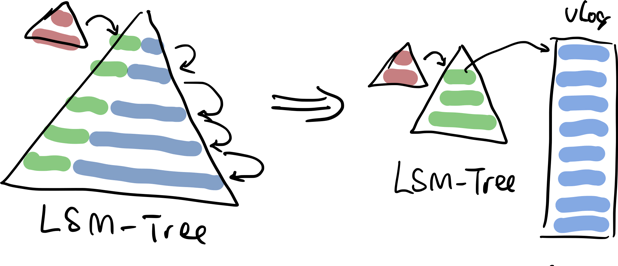\n\nTiKV 新的本地存储引擎 Titan
\n\n在 Titan 走向稳定的同时,我们也在调研从头构建一个更适合 TiDB 的 OLTP workload 的存储引擎,前面说到 2018 年做了抽象 TiKV 的本地存储引擎的事情就是为了这个打基础,当然我们仍然会走 LSM-Tree 的路线。这里多提一句,其实很多人都误解了 LSM-Tree 模型的真正优势,在我看来并不是性能,而是:做到可接受的性能的同时,LSM-Tree 的实现非常简单可维护,只有简单的东西才可以依赖,这个决定和我们在 Raft 与 Paxos 之间的选择偏好也是一致的。另外 LSM-Tree 的设计从宏观上来说,更加符合「冷热分层」以适配异构存储介质的想法,这个我相信是未来在存储硬件上的大趋势。\n\n**至于在 OLAP 的存储引擎这边,我们走的就是纯列式存储的路线了,但是会和传统的 Columnar 数据结构的设计不太一样,这块的进展,我们会在 1 月 19 号的 [TiDB DevCon](https://pingcap.com/community-cn/devcon2019/) 上首秀,这里先卖个关子。**\n\n另一个大的方向是事务模型,目前来说,TiDB 从诞生起,事务模型就没有改变过,走的是传统的 Percolator 的 2PC。这个模型的好处是简单,吞吐也不是瓶颈,但是一个比较大的问题是延迟,尤其在跨数据中心的场景中,这里的延迟主要表现在往 TSO 拿时间戳的网络 roundtrip 上,当然了,我目前仍然认为时钟(TSO)是一个必不可少组件,在不降低一致性和隔离级别的大前提下也是目前我们的最好选择,另外 Percolator 的模型也不是没有办法对延迟进行优化,我们其实在 2018 年,针对 Percolator 本身做了一些理论上的改进,减少了几次网络的 roundtrip,也在年中书写了新的 2PC 改进的 [完整的 TLA+ 的证明](https://github.com/pingcap/tla-plus/blob/master/OptimizedCommitTS/OptimizedCommitTS.tla),证明了这个新算法的正确性,2019 年在这块还会有比较多的改进,其实我们一直在思考,怎么样能够做得更好,选择合适的时机做合适的优化。另外一方面,在事务模型这方面,2PC 在理论和工程上还有很多可以改进的空间,但是现在的当务之急继续的优化代码结构和整体的稳定性,这部分的工作在未来一段时间还是会专注在理论和证明上。另外一点大家可以期待的是,2019 年我们会引入安全的 Follower/Learner Read,这对保持一致性的前提下读的吞吐会提升,另外在跨数据中心的场景,读的延迟会更小。\n\n\n\n差不多就这些吧,最后放一句我特别喜欢的丘吉尔的一句名言作为结尾。\n\nSuccess is not final, failure is not fatal: it is the courage to continue that counts.\n\n成功不是终点,失败也并非终结,最重要的是继续前进的勇气。","date":"2019-01-02","author":"黄东旭","fillInMethod":"writeDirectly","customUrl":"for-community-tidb-2019-level-up","file":null,"relatedBlogs":[]},{"id":"Blogs_221","title":"十分钟成为 Contributor 系列 | 支持 AST 还原为 SQL","tags":["TiDB","Contributor","SQL","社区"],"category":{"name":"社区动态"},"summary":"为了实现一些新特性,我们需要为 AST 实现可以还原为 SQL 文本的功能,这篇教程描述如何为 AST 节点添加该功能。首先介绍一些必需的背景知识,然后介绍实现 Restore() 函数的流程,最后会展示一个例子。","body":"## **背景知识**\n\nSQL 语句发送到 TiDB 后首先会经过 parser,从文本 parse 成为 AST(抽象语法树),AST 节点与 SQL 文本结构是一一对应的,我们通过遍历整个 AST 树就可以拼接出一个与 AST 语义相同的 SQL 文本。\n\n对 parser 不熟悉的小伙伴们可以看 [TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现](https://pingcap.com/blog-cn/tidb-source-code-reading-5/)。\n\n为了控制 SQL 文本的输出格式,并且为方便未来新功能的加入(例如在 SQL 文本中用 “*” 替代密码),我们引入了 `RestoreFlags` 并封装了 `RestoreCtx` 结构([相关源码](https://github.com/pingcap/parser/blob/9339d225378fa9b50e1bf8373c2040524b96c6af/ast/util.go#L78)):\n\n```\n// `RestoreFlags` 中的互斥组:\n// [RestoreStringSingleQuotes, RestoreStringDoubleQuotes]\n// [RestoreKeyWordUppercase, RestoreKeyWordLowercase]\n// [RestoreNameUppercase, RestoreNameLowercase]\n// [RestoreNameDoubleQuotes, RestoreNameBackQuotes]\n// 靠前的 flag 拥有更高的优先级。\nconst (\n\tRestoreStringSingleQuotes RestoreFlags = 1 << iota\n\n\t...\n)\n\n// RestoreCtx is `Restore` context to hold flags and writer.\ntype RestoreCtx struct {\n\tFlags RestoreFlags\n\tIn io.Writer\n}\n\n// WriteKeyWord 用于向 `ctx` 中写入关键字(例如:SELECT)。\n// 它的大小写受 `RestoreKeyWordUppercase`,`RestoreKeyWordLowercase` 控制\nfunc (ctx *RestoreCtx) WriteKeyWord(keyWord string) {\n\t...\n}\n\n// WriteString 用于向 `ctx` 中写入字符串。\n// 它是否被引号包裹及转义规则受 `RestoreStringSingleQuotes`,`RestoreStringDoubleQuotes`,`RestoreStringEscapeBackslash` 控制。\nfunc (ctx *RestoreCtx) WriteString(str string) {\n\t...\n}\n\n// WriteName 用于向 `ctx` 中写入名称(库名,表名,列名等)。\n// 它是否被引号包裹及转义规则受 `RestoreNameUppercase`,`RestoreNameLowercase`,`RestoreNameDoubleQuotes`,`RestoreNameBackQuotes` 控制。\nfunc (ctx *RestoreCtx) WriteName(name string) {\n\t...\n}\n\n// WritePlain 用于向 `ctx` 中写入普通文本。\n// 它将被直接写入不受 flag 影响。\nfunc (ctx *RestoreCtx) WritePlain(plainText string) {\n\t...\n}\n\n// WritePlainf 用于向 `ctx` 中写入普通文本。\n// 它将被直接写入不受 flag 影响。\nfunc (ctx *RestoreCtx) WritePlainf(format string, a ...interface{}) {\n\t...\n}\n```\n\n我们在 `ast.Node` 接口中添加了一个 `Restore(ctx *RestoreCtx) error` 函数,这个函数将当前节点对应的 SQL 文本追加至参数 `ctx` 中,如果节点无效则返回 `error`。\n\n```\ntype Node interface {\n // Restore AST to SQL text and append them to `ctx`.\n // return error when the AST is invalid.\n\tRestore(ctx *RestoreCtx) error\n\n ...\n}\n```\n\n以 SQL 语句 `SELECT column0 FROM table0 UNION SELECT column1 FROM table1 WHERE a = 1` 为例,如下图所示,我们通过遍历整个 AST 树,递归调用每个节点的 `Restore()` 方法,即可拼接成一个完整的 SQL 文本。\n\n\n\n值得注意的是,SQL 文本与 AST 是一个多对一的关系,我们不可能从 AST 结构中还原出与原 SQL 完全一致的文本,\n因此我们只要保证还原出的 SQL 文本与原 SQL **语义相同** 即可。所谓语义相同,指的是由 AST 还原出的 SQL 文本再被解析为 AST 后,两个 AST 是相等的。\n\n我们已经完成了接口设计和测试框架,具体的`Restore()` 函数留空。因此**只需要选择一个留空的 `Restore()` 函数实现,并添加相应的测试数据,就可以提交一个 PR 了!**\n\n## **实现 `Restore()` 函数的整体流程**\n\n1. 请先阅读 [Proposal](https://github.com/pingcap/tidb/tree/master/docs/design/2018-11-29-ast-to-sql-text.md)、[Issue](https://github.com/pingcap/tidb/issues/8532)\n\n2. 在 [Issue](https://github.com/pingcap/tidb/issues/8532) 中找到未实现的函数\n\n 1. 在 [Issue-pingcap/tidb#8532](https://github.com/pingcap/tidb/issues/8532) 中找到一个没有被其他贡献者认领的任务,例如 `ast/expressions.go: BetweenExpr`。\n\n 2. 在 [pingcap/parser](https://github.com/pingcap/parser) 中找到任务对应文件 `ast/expressions.go`。\n\n 3. 在文件中找到 `BetweenExpr` 结构的 `Restore` 函数:\n\n ```\n // Restore implements Node interface.\n func (n *BetweenExpr) Restore(ctx *RestoreCtx) error {\n return errors.New(\"Not implemented\")\n }\n ```\n\n3. 实现 `Restore()` 函数\n\n 根据 Node 节点结构和 SQL 语法实现函数功能。\n\n > 参考 [MySQL 5.7 SQL Statement Syntax](https://dev.mysql.com/doc/refman/5.7/en/sql-statements.html)\n\n4. 写单元测试\n\n 参考示例在相关文件下添加单元测试。\n\n5. 运行 `make test`,确保所有的 test case 都能跑过。\n\n6. 提交 PR\n\n PR 标题统一为:`parser: implement Restore for XXX`\n 请在 PR 中关联 Issue: `pingcap/tidb#8532`\n\n## **示例**\n\n这里以[实现 BetweenExpr 的 Restore 函数 PR](https://github.com/pingcap/parser/pull/71/files) 为例,进行详细说明:\n\n1. 首先看 `ast/expressions.go`:\n\n 1. 我们要实现一个 `ast.Node` 结构的 `Restore` 函数,首先清楚该结构代表什么短语,例如 `BetweenExpr` 代表 `expr [NOT] BETWEEN expr AND expr` (参见:[MySQL 语法 - 比较函数和运算符](https://dev.mysql.com/doc/refman/5.7/en/comparison-operators.html#operator_between))。\n\n 2. 观察 `BetweenExpr` 结构:\n\n ```\n // BetweenExpr is for \"between and\" or \"not between and\" expression.\n type BetweenExpr struct {\n exprNode\n // 被检查的表达式\n Expr ExprNode\n // AND 左侧的表达式\n Left ExprNode\n // AND 右侧的表达式\n Right ExprNode\n // 是否有 NOT 关键字\n Not bool\n }\n ```\n\n 3. 实现 `BetweenExpr` 的 `Restore` 函数:\n\n ```\n // Restore implements Node interface.\n func (n *BetweenExpr) Restore(ctx *RestoreCtx) error {\n // 调用 Expr 的 Restore,向 ctx 写入 Expr\n if err := n.Expr.Restore(ctx); err != nil {\n return errors.Annotate(err, \"An error occurred while restore BetweenExpr.Expr\")\n }\n // 判断是否有 NOT,并写入相应关键字\n if n.Not {\n ctx.WriteKeyWord(\" NOT BETWEEN \")\n } else {\n ctx.WriteKeyWord(\" BETWEEN \")\n }\n // 调用 Left 的 Restore\n if err := n.Left.Restore(ctx); err != nil {\n return errors.Annotate(err, \"An error occurred while restore BetweenExpr.Left\")\n }\n // 写入 AND 关键字\n ctx.WriteKeyWord(\" AND \")\n // 调用 Right 的 Restore\n if err := n.Right.Restore(ctx); err != nil {\n return errors.Annotate(err, \"An error occurred while restore BetweenExpr.Right \")\n }\n return nil\n }\n ```\n\n2. 接下来给函数实现添加单元测试, `ast/expressions_test.go`:\n\n ```\n // 添加测试函数\n func (tc *testExpressionsSuite) TestBetweenExprRestore(c *C) {\n // 测试用例\n testCases := []NodeRestoreTestCase{\n {\"b between 1 and 2\", \"`b` BETWEEN 1 AND 2\"},\n {\"b not between 1 and 2\", \"`b` NOT BETWEEN 1 AND 2\"},\n {\"b between a and b\", \"`b` BETWEEN `a` AND `b`\"},\n {\"b between '' and 'b'\", \"`b` BETWEEN '' AND 'b'\"},\n {\"b between '2018-11-01' and '2018-11-02'\", \"`b` BETWEEN '2018-11-01' AND '2018-11-02'\"},\n }\n // 为了不依赖父节点实现,通过 extractNodeFunc 抽取待测节点\n extractNodeFunc := func(node Node) Node {\n return node.(*SelectStmt).Fields.Fields[0].Expr\n }\n // Run Test\n RunNodeRestoreTest(c, testCases, \"select %s\", extractNodeFunc)\n }\n ```\n\n **至此 `BetweenExpr` 的 `Restore` 函数实现完成,可以提交 PR 了。为了更好的理解测试逻辑,下面我们看 `RunNodeRestoreTest`:**\n\n ```\n // 下面是测试逻辑,已经实现好了,不需要 contributor 实现\n func RunNodeRestoreTest(c *C, nodeTestCases []NodeRestoreTestCase, template string, extractNodeFunc func(node Node) Node) {\n parser := parser.New()\n for _, testCase := range nodeTestCases {\n // 通过 template 将测试用例拼接为完整的 SQL\n sourceSQL := fmt.Sprintf(template, testCase.sourceSQL)\n expectSQL := fmt.Sprintf(template, testCase.expectSQL)\n stmt, err := parser.ParseOneStmt(sourceSQL, \"\", \"\")\n comment := Commentf(\"source %#v\", testCase)\n c.Assert(err, IsNil, comment)\n var sb strings.Builder\n // 抽取指定节点并调用其 Restore 函数\n err = extractNodeFunc(stmt).Restore(NewRestoreCtx(DefaultRestoreFlags, &sb))\n c.Assert(err, IsNil, comment)\n // 通过 template 将 restore 结果拼接为完整的 SQL\n restoreSql := fmt.Sprintf(template, sb.String())\n comment = Commentf(\"source %#v; restore %v\", testCase, restoreSql)\n // 测试 restore 结果与预期一致\n c.Assert(restoreSql, Equals, expectSQL, comment)\n stmt2, err := parser.ParseOneStmt(restoreSql, \"\", \"\")\n c.Assert(err, IsNil, comment)\n CleanNodeText(stmt)\n CleanNodeText(stmt2)\n // 测试解析的 stmt 与原 stmt 一致\n c.Assert(stmt2, DeepEquals, stmt, comment)\n }\n }\n ```\n\n**不过对于 `ast.StmtNode`(例如:`ast.SelectStmt`)测试方法有些不一样,\n由于这类节点可以还原为一个完整的 SQL,因此直接在 `parser_test.go` 中测试。**\n\n下面以[实现 UseStmt 的 Restore 函数 PR](https://github.com/pingcap/parser/pull/62/files) 为例,对测试进行说明:\n\n1. `Restore` 函数实现过程略。\n\n2. 给函数实现添加单元测试,参见 `parser_test.go`:\n\n 在这个示例中,只添加了几行测试数据就完成了测试:\n\n ```\n // 添加 testCase 结构的测试数据\n {\"use `select`\", true, \"USE `select`\"},\n {\"use `sel``ect`\", true, \"USE `sel``ect`\"},\n {\"use select\", false, \"USE `select`\"},\n ```\n\n 我们看 `testCase` 结构声明:\n\n ```\n type testCase struct {\n // 原 SQL\n src string\n // 是否能被正确 parse\n ok bool\n // 预期的 restore SQL\n restore string\n }\n ```\n\n 测试代码会判断原 SQL parse 出 AST 后再还原的 SQL 是否与预期的 restore SQL 相等,具体的测试逻辑在 `parser_test.go` 中 `RunTest()`、`RunRestoreTest()` 函数,逻辑与前例类似,此处不再赘述。\n\n---\n\n加入 TiDB Contributor Club,无门槛参与开源项目,改变世界从这里开始吧(萌萌哒)。\n\n\n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2018-12-20","author":"赵一霖","fillInMethod":"writeDirectly","customUrl":"support-ast-restore-to-sql-text","file":null,"relatedBlogs":[]},{"id":"Blogs_198","title":"TiDB 开源社区指南(上)","tags":["TiDB","社区"],"category":{"name":"社区动态"},"summary":"本系列文章旨在帮助社区开发者了解 TiDB 项目的全貌,更好的参与 TiDB 项目开发。上篇会聚焦在社区参与者的角度,描述如何更好的参与 TiDB 项目开发。","body":"本系列文章旨在帮助社区开发者了解 TiDB 项目的全貌,更好的参与 TiDB 项目开发。大致会分两个角度进行描述:\n\n* 从社区参与者的角度描述如何更好的参与 TiDB 项目开发;\n\n* 从 PingCAP 内部团队的角度展示 TiDB 的开发流程,包括版本规划、开发流程、Roadmap 制定等。\n\n希望通过一内一外两条线的描述,读者能在技术之外对 TiDB 有更全面的了解。本篇将聚焦在社区参与者的角度进行描述,也就是“外线”。\n\n## 了解 TiDB\n\n参与一个开源项目第一步总是了解它,特别是对 TiDB 这样一个大型的项目,了解的难度比较高,这里列出一些相关资料,帮助 newcomers 从架构设计到工程实现细节都能有所了解:\n\n* [Overview](https://github.com/pingcap/docs#tidb-introduction)\n* [How we build TiDB](https://pingcap.com/blog/2016-10-17-how-we-build-tidb/)\n* [TiDB 源码阅读系列文章](https://pingcap.com/blog-cn/#%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB)\n* [Deep Dive TiKV (Work-In-Process)](https://github.com/tikv/deep-dive-tikv/)\n\n当然,最高效地熟悉 TiDB 的方式还是使用它,在某些场景下遇到了问题或者是想要新的 feature,去跟踪代码,找到相关的代码逻辑,在这个过程中很容易对相关模块有了解,不少 Contributor 就是这样完成了第一次贡献。 \n\n我们还有一系列的 Infra Meetup,大约两周一次,如果方便到现场的同学可以听到这些高质量的 Talk。除了北京之外,其他的城市(上海、广州、成都、杭州)也开始组织 Meetup,方便更多的同学到现场来面基。\n\n## 发现可以参与的事情\n\n对 TiDB 有基本的了解之后,就可以选一个入手点。在 TiDB repo 中我们给一些简单的 issue 标记了 [for-new-contributors](https://github.com/pingcap/tidb/issues?q=is%3Aissue+is%3Aopen+label%3A%22for+new+contributors%22) 标签,这些 issue 都是我们评估过容易上手的事情,可以以此为切入点。另外我们也会定期举行一些活动,把框架搭好,教程写好,新 Contributor 按照固定的模式即可完成某一特性开发。\n\n当然除了那些标记为 for-new-contributors 的 issue 之外,也可以考虑其他的 issue,标记为 [help-wanted](https://github.com/pingcap/tidb/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22) 标签的 issue 可以优先考虑。除此之外的 issue 可能会比较难解决,需要对 TiDB 有较深入的了解或者是对完成时间有较高的要求,不适合第一次参与的同学。\n\n当然除了现有的 issue 之外,也欢迎将自己发现的问题或者是想要的特性提为新的 issue,然后自投自抢 :) 。 \n\n当你已经对 TiDB 有了深入的了解,那么可以尝试从 [Roadmap](https://pingcap.com/docs-cn/v3.0/roadmap/) 上找到感兴趣的事项,和我们讨论一下如何参与。\n\n## 讨论方案\n\n找到一个感兴趣的点之后,可以在 issue 中进行讨论,如果是一个小的 bug-fix 或者是小的功能点,可以简单讨论之后开工。即使再简单的问题,也建议先进行讨论,以免出现解决方案有问题或者是对问题的理解出了偏差,做了无用功。\n\n但是如果要做的事情比较大,可以先写一个详细的设计文档,提交到 [docs/design](https://github.com/pingcap/tidb/tree/master/docs/design) 目录下面,这个目录下有设计模板以及一些已有的设计方案供你参考。一篇好的设计方案要写清楚以下几点:\n\n* 背景知识\n\n* 解决什么问题\n\n* 方案详细设计\n\n* 对方案的解释说明,证明正确性和可行性\n\n* 和现有系统的兼容性\n\n* 方案的具体实现 \n\n用一句话来总结就是写清楚“你做了什么,为什么要做这个,怎么做的,为什么要这样做”。如果对自己的方案不太确定,可以先写一个 Google Doc,share 给我们简单评估一下,再提交 PR。\n\n## 提交 PR\n\n按照方案完成代码编写后,就可以提交 PR。当然如果开发尚未完成,在某些情况下也可以先提交 PR,比如希望先让社区看一下大致的解决方案,这个时候请将 PR 标记为 WIP。\n\n对于 PR 我们有一些要求:\n\n1. 需要能通过 `make dev` 的测试,跑过基本的单元测试;\n\n2. 必须有测试,除非只是改动文档或者是依赖包,其他情况需要有充足的理由说明没有测试的原因;\n\n3. 代码以及注释的质量需要足够高,查看 [Code style](https://github.com/pingcap/community/blob/master/CONTRIBUTING.md#code-style) 有一些关于编码风格和 commit message 的 guide;\n\n4. 请尽可能详细的填写 PR 的描述,并打上合适的 label。\n\n**对于 PR 的描述,我们提供了一个模板,希望大家能够认真填写,一个好的描述能够加速 PR 的 review 过程。通过这个模板能够向 reviewers 以及社区讲明白:**\n\n* 这个PR 解决什么问题:相关的问题描述或者是 issue 链接;\n\n* 如何解决:具体的解决方法,reviewers 会根据这里的描述去看代码变动,所以请将这一段写的尽可能详细且有帮助;\n\n* 测试的情况;\n\n* 其他相关信息(如果需要):benchmark 结果、兼容性问题、是否需要更新文档。\n\n最后再说几句测试,正确性是数据库安身立命之本,怎么强调测试都不为过。PR 中的测试不但需要充足,覆盖到所做的变动,还需要足够清晰,通过代码或者注释来表达测试的目的,帮助 reviewer 以及今后可能变动/破坏相关逻辑的人能够容易的理解这段测试。一段完善且清晰的测试也有利于让 reviewer 相信这个 Patch 是正确的。\n\n## PR review\n\nPR review 的过程就是 reviewer 不断地提出 comment,PR 作者持续解决 comment 的过程。\n\n**每个 PR 在合并之前都需要至少得到两个 Committer/Maintainer 的 LGTM,一些重要的 PR 需要得到三个,比如对于 DDL 模块的修改,默认都需要得到三个 LGTM。**\n\n#### Tips:\n\n* 提了PR 之后,可以 at 一下相关的同学来 review;\n\n* Address comment 之后可以 at 一下之前提过 comment 的同学,标准做法是 comment 一下 “**PTAL @xxx**”,这样我们内部的 Slack 中可以得到通知,相关的同学会受到提醒,让整个流程更紧凑高效。\n\n## 与项目维护者之间的交流\n\n**目前标准的交流渠道是 GitHub issue**,请大家优先使用这个渠道,我们有专门的同学来维护这个渠道,其他渠道不能保证得到研发同学的及时回复。这也是开源项目的标准做法。\n\n无论是遇到 bug、讨论具体某一功能如何做、提一些建议、产品使用中的疑惑,都可以来提 issue。在开发过程中遇到了问题,也可以在相关的 issue 中进行讨论,包括方案的设计、具体实现过程中遇到的问题等等。\n\n**最后请大家注意一点,除了 pingcap/docs-cn 这个 repo 之外,请大家使用英文。**\n\n## 更进一步\n\n当你完成上面这些步骤的之后,恭喜你已经跨过第一个门槛,正式进入了 TiDB 开源社区,开始参与 TiDB 项目开发,成为 TiDB Contributor。\n\n如果想更进一步,深入了解 TiDB 的内部机制,掌握一个分布式数据库的核心模块,并能做出改进,那么可以了解更多的模块,提更多的 PR,进一步向 Committer 发展([Become a Committer](https://github.com/pingcap/community/blob/master/become-a-committer.md) 这篇文档解释了什么是 Committer)。目前 TiDB 社区的 Committer 还非常少,我们希望今后能出现更多的 Committer 甚至是 Maintainer。\n\n从 Contributor 到 Committer 的门槛比较高,比如今年的新晋 Committer 杜川同学,在成为 Committer 的道路上给 tidb/tikv 项目提交了大约 80 个 PR,并且对一些模块有非常深入的了解。当然,成为 Committer 之后,会有一定的权利,比如对一些 PR 点 LGTM 的权利,参加 PingCAP 内部的技术事项、开发规划讨论的权利,参加定期举办的 TechDay/DevCon 的权利。目前社区中还有几位贡献者正走在从 Contributor 到 Committer 的道路上。","date":"2018-11-09","author":"申砾","fillInMethod":"writeDirectly","customUrl":"tidb-community-guide-1","file":null,"relatedBlogs":[]},{"id":"Blogs_79","title":"三十分钟成为 Contributor | 为 TiKV 添加 built-in 函数","tags":["TiKV","社区","Contributor"],"category":{"name":"社区动态"},"summary":"手把手教你如何在三十分钟内成为 TiKV 项目的 Contributor。","body":"## 背景知识\n\nSQL 语句发送到 TiDB 后经过 parser 生成 AST(抽象语法树),再经过 Query Optimizer 生成执行计划,执行计划切分成很多子任务,这些子任务以表达式的方式最后下推到底层的各个 TiKV 来执行。\n\n\n\n图 1
\n\n如图 1,当 TiDB 收到来自客户端的查询请求\n\n`select count(*) from t where a + b > 5`\n\n时,执行顺序如下:\n\n1. TiDB 对 SQL 进行解析,组织成对应的表达式,下推给 TiKV\n\n2. TiKV 收到请求后,循环以下过程\n\n\t* 获取下一行完整数据,并按列解析\n\n\t* 使用参数中的 where 表达式对数据进行过滤\n\n\t* 若上一条件符合,进行聚合计算\n\n3. TiKV 向 TiDB 返回聚合计算结果\n\n4. TiDB 对所有涉及的结果进行二次聚合,返回给客户端\n\n这里的 where 条件便是以表达式树的形式下推给 TiKV。在此之前 TiDB 只会向 TiKV 下推一小部分简单的表达式,比如取出某一个列的某个数据类型的值,简单数据类型的比较操作,算术运算等。为了充分利用分布式集群的资源,进一步提升 SQL 在整个集群的执行速度,我们需要将更多种类的表达式下推到 TiKV 来运行,其中的一大类就是 MySQL built-in 函数。\n\n目前,由于 TiKV 的 built-in 函数尚未全部实现,对于无法下推的表达式,TiDB 只能自行解决。这无疑将成为提升 TiDB 速度的最大绊脚石。好消息是,TiKV 在实现 built-in 函数时,可以直接参考 TiDB 的对应函数逻辑(顺便可以帮 TiDB 找找 Bug),为我们减少了不少工作量。\n\n**Built-in 函数无疑是 TiDB 和 TiKV 成长道路上不可替代的一步,如此艰巨又庞大的任务,我们需要广大社区朋友们的支持与鼓励。亲爱的朋友们,想玩 Rust 吗?想给 TiKV 提 PR 吗?想帮助 TiDB 跑得更快吗?动动您的小手指,拿 PR 来砸我们吧。您的 PR 一旦被采用,将会有小惊喜哦。**\n\n## 手把手教你实现 built-in 函数\n\n### Step 1:准备下推函数\n\n在 TiKV 的 [https://github.com/tikv/tikv/issues/3275](https://github.com/tikv/tikv/issues/3275) issue 中,找到未实现的函数签名列表,选一个您想要实现的函数。\n\n### Step 2:获取 TiDB 中可参考的逻辑实现\n\n在 TiDB 的 [expression](https://github.com/pingcap/tidb/tree/master/expression) 目录下查找相关 builtinXXXSig 对象,这里 XXX 为您要实现的函数签名,本例中以 [MultiplyIntUnsigned](https://github.com/tikv/tikv/pull/3277) 为例,可以在 TiDB 中找到其对应的函数签名(`builtinArithmeticMultiplyIntUnsignedSig`)及 [实现](https://github.com/pingcap/tidb/blob/master/expression/builtin_arithmetic.go#L532)。\n\n### Step 3:确定函数定义\n\n1. built-in 函数所在的文件名要求与 TiDB 的名称对应,如 TiDB 中,[expression](https://github.com/pingcap/tidb/tree/master/expression) 目录下的下推文件统一以 builtin_XXX 命名,对应到 TiKV 这边,就是 `builtin_XXX.rs`。若同名对应的文件不存在,则需要自行在同级目录下新建。对于本例,当前函数存放于 TiDB 的 [builtin_arithmetic.go](https://github.com/pingcap/tidb/blob/master/expression/builtin_arithmetic.go#L532) 文件里,对应到 TiKV 便是存放在 [builtin_arithmetic.rs](https://github.com/tikv/tikv/blob/master/components/tidb_query/src/expr/builtin_arithmetic.rs) 中。\n\n2. 函数名称:函数签名转为 Rust 的函数名称规范,这里 `MultiplyIntUnsigned` 将会被定义为 `multiply_int_unsigned`。\n\n3. 函数返回值,可以参考 TiDB 中实现的 `Eval` 函数,对应关系如下:\n\n | TiDB 对应实现的 Eval 函数 | TiKV 对应函数的返回值类型 |\n | ----------------------- | ---------------------- |\n | `evalInt` | `Result>` |\n | `evalReal` | `Result>` |\n | `evalString` | `Result>>` |\n | `evalDecimal` | `Result>>` |\n | `evalTime` | `Result>>` |\n | `evalDuration` | `Result>>`|\n | `evalJSON` | `Result>>`|\n\n 可以看到 TiDB 的 `builtinArithmeticMultiplyIntUnsignedSig` 对象实现了 evalInt 方法,故当前函数(`multiply_int_unsigned`)的返回类型应该为 `Result>`。\n\n4. 函数的参数, 所有 builtin-in 的参数都与 Expression 的 `eval` 函数一致,即:\n\n\t* 环境配置量 (ctx:&StatementContext)\n\n\t* 该行数据每列具体值 (row:&[Datum])\n\n综上,`multiply_int_unsigned` 的下推函数定义为:\n\n```\n pub fn multiply_int_unsigned(\n &self,\n ctx: &mut EvalContext,\n row: &[Datum],\n ) -> Result>\n``` \n\n\n### Step 4:实现函数逻辑\n\n这一块相对简单,直接对照 TiDB 的相关逻辑实现即可。这里,我们可以看到 TiDB 的 `builtinArithmeticMultiplyIntUnsignedSig` 的具体实现如下:\n\n```\nfunc (s *builtinArithmeticMultiplyIntUnsignedSig) evalInt(row types.Row) (val int64, isNull bool, err error) {\n a, isNull, err := s.args[0].EvalInt(s.ctx, row)\n if isNull || err != nil {\n return 0, isNull, errors.Trace(err)\n }\n unsignedA := uint64(a)\n b, isNull, err := s.args[1].EvalInt(s.ctx, row)\n if isNull || err != nil {\n return 0, isNull, errors.Trace(err)\n }\n unsignedB := uint64(b)\n result := unsignedA * unsignedB\n if unsignedA != 0 && result/unsignedA != unsignedB {\n return 0, true, types.ErrOverflow.GenByArgs(\"BIGINT UNSIGNED\", fmt.Sprintf(\"(%s * %s)\", s.args[0].String(), s.args[1].String()))\n }\n return int64(result), false, nil\n}\n```\n\n参考以上代码,翻译到 TiKV 即可,如下:\n\n```\n pub fn multiply_int_unsigned(\n &self,\n ctx: &mut EvalContext,\n row: &[Datum],\n ) -> Result> {\n let lhs = try_opt!(self.children[0].eval_int(ctx, row));\n let rhs = try_opt!(self.children[1].eval_int(ctx, row));\n let res = (lhs as u64).checked_mul(rhs as u64).map(|t| t as i64);\n // TODO: output expression in error when column's name pushed down.\n res.ok_or_else(|| Error::overflow(\"BIGINT UNSIGNED\", &format!(\"({} * {})\", lhs, rhs)))\n .map(Some)\n }\n```\n\n### Step 5:添加参数检查\n\nTiKV 在收到下推请求时,首先会对所有的表达式进行检查,表达式的参数个数检查就在这一步进行。\n\nTiDB 中对每个 built-in 函数的参数个数有严格的限制,这一部分检查可参考 TiDB 同目录下 builtin.go 相关代码。\n\n在 TiKV 同级目录的 `scalar_function.rs` 文件里,找到 ScalarFunc 的 `check_args` 函数,按照现有的模式,加入参数个数的检查即可。\n\n### Step 6:添加下推支持\n\nTiKV 在对一行数据执行具体的 expression 时,会调用 `eval` 函数,`eval` 函数又会根据具体的返回类型,执行具体的子函数。这一部分工作在 `scalar_function.rs` 中以宏(dispatch_call)的形式完成。\n\n对于 `MultiplyIntUnsigned`, 我们最终返回的数据类型为 Int,所以可以在 dispatch_call 中找到 `INT_CALLS`,然后照着加入 `MultiplyIntUnsigned => multiply_int_unsigned` , 表示当解析到函数签名 `MultiplyIntUnsigned` 时,调用上述已实现的函数 `multiply_int_unsigned`。\n\n至此 `MultiplyIntUnsigned` 下推逻辑已完全实现。\n\n### Step 7:添加测试\n\n在函数 `multiply_int_unsigned` 所在文件 [builtin_arithmetic.rs](https://github.com/tikv/tikv/blob/master/components/tidb_query/src/expr/builtin_arithmetic.rs) 底部的 test 模块中加入对该函数签名的单元测试,要求覆盖到上述添加的所有代码,这一部分也可以参考 TiDB 中相关的测试代码。本例在 TiKV 中实现的测试代码如下:\n\n```\n #[test]\n fn test_multiply_int_unsigned() {\n let cases = vec![\n (Datum::I64(1), Datum::I64(2), Datum::U64(2)),\n (\n Datum::I64(i64::MIN),\n Datum::I64(1),\n Datum::U64(i64::MIN as u64),\n ),\n (\n Datum::I64(i64::MAX),\n Datum::I64(1),\n Datum::U64(i64::MAX as u64),\n ),\n (Datum::U64(u64::MAX), Datum::I64(1), Datum::U64(u64::MAX)),\n ];\n let mut ctx = EvalContext::default();\n for (left, right, exp) in cases {\n let lhs = datum_expr(left);\n let rhs = datum_expr(right);\n let mut op = Expression::build(\n &mut ctx,\n scalar_func_expr(ScalarFuncSig::MultiplyIntUnsigned, &[lhs, rhs]),\n ).unwrap();\n op.mut_tp().set_flag(types::UNSIGNED_FLAG as u32);\n let got = op.eval(&mut ctx, &[]).unwrap();\n assert_eq!(got, exp);\n }\n // test overflow\n let cases = vec![\n (Datum::I64(-1), Datum::I64(2)),\n (Datum::I64(i64::MAX), Datum::I64(i64::MAX)),\n (Datum::I64(i64::MIN), Datum::I64(i64::MIN)),\n ];\n for (left, right) in cases {\n let lhs = datum_expr(left);\n let rhs = datum_expr(right);\n let mut op = Expression::build(\n &mut ctx,\n scalar_func_expr(ScalarFuncSig::MultiplyIntUnsigned, &[lhs, rhs]),\n ).unwrap();\n op.mut_tp().set_flag(types::UNSIGNED_FLAG as u32);\n let got = op.eval(&mut ctx, &[]).unwrap_err();\n assert!(check_overflow(got).is_ok());\n }\n }\n```\n\n### Step 8:运行测试\n\n运行 make expression,确保所有的 test case 都能跑过。\n\n完成以上几个步骤之后,就可以给 TiKV 项目提 PR 啦。想要了解提 PR 的基础知识,尝试移步 [此文](https://pingcap.com/blog-cn/how-to-contribute/),看看是否有帮助。 \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2018-08-01","author":"吴雪莲","fillInMethod":"writeDirectly","customUrl":"30mins-become-contributor-of-tikv","file":null,"relatedBlogs":[]},{"id":"Blogs_105","title":"十分钟成为 Contributor 系列 | 重构内建函数进度报告","tags":["TiDB","Contributor","社区"],"category":{"name":"社区动态"},"summary":"为了方便社区同学更好地参与 TiDB 项目,本文一方面对继上一篇文章发布后参考社区的反馈对表达式计算框架所做的修改进行详细介绍,另一方面对尚未重写的 built-in 函数进行陈列。","body":"6 月 22 日,TiDB 发布了一篇如何十分钟成为 TiDB Contributor 系列的[十分钟成为 Contributor 系列 | 为 TiDB 重构 built-in 函数](https://pingcap.com/blog-cn/reconstruct-built-in-function),向大家介绍如何为 TiDB 重构 built-in 函数。\n\n截止到目前,得到了来自社区的积极支持与热情反馈,TiDB 参考社区 contributors 的建议,对计算框架进行了部分修改以降低社区同学参与的难度。\n\n本文完成以下**2 项工作**,希望帮助社区更好的参与进 TiDB 的项目中来:\n\n1. 对尚未重写的 built-in 函数进行陈列\n2. 对继上篇文章后,计算框架所进行的修改,进行详细介绍\n\n### 一. 尚未重写的 built-in 函数陈列如下:\n\n共计 165 个\n在 expression 目录下运行 `grep -rn \"^\\tbaseBuiltinFunc$\" -B 1 * | grep \"Sig struct {\" | awk -F \"Sig\" '{print $1}' | awk -F \"builtin\" '{print $3}' > ~/Desktop/func.txt` 命令可以获得所有未实现的 built-in 函数\n\n| 0 | 1 | 2 | 3 | 4 |\n|:-------------:|:------------------------:|:-------------:|:---------------:|:-:|\n| Coalesce | Uncompress | Log10 | Default | UnaryOp |\n| Greatest | UncompressedLength | Rand | InetAton | IsNull |\n| Least | ValidatePasswordStrength | Pow | InetNtoa | In |\n| Interval | Database | Round | Inet6Aton | Row |\n| CaseWhen | FoundRows | Conv | Inet6Ntoa | SetVar |\n| If | CurrentUser | CRC32 | IsFreeLock | GetVar |\n| IfNull | User | Sqrt | IsIPv4 | Values |\n| NullIf | ConnectionID | Arithmetic | IsIPv4Prefixed | BitCount |\n| AesDecrypt | LastInsertID | Acos | IsIPv6 | Reverse |\n| AesEncrypt | Version | Asin | IsUsedLock | Convert |\n| Compress | Benchmark | Atan | MasterPosWait | Substring |\n| Decode | Charset | Cot | NameConst | SubstringIndex |\n| DesDecrypt | Coercibility | Exp | ReleaseAllLocks | Locate |\n| DesEncrypt | Collation | PI | UUID | Hex |\n| Encode | RowCount | Radians | UUIDShort | UnHex |\n| Encrypt | Regexp | Truncate | AndAnd | Trim |\n| OldPassword | Abs | Sleep | OrOr | LTrim |\n| RandomBytes | Ceil | Lock | LogicXor | RTrim |\n| SHA1 | Floor | ReleaseLock | BitOp | Rpad |\n| SHA2 | Log | AnyValue | IsTrueOp | BitLength |\n| Char | Format | FromDays | DayOfWeek | Timestamp |\n| CharLength | FromBase64 | Hour | DayOfYear | AddTime |\n| FindInSet | InsertFunc | Minute | Week | ConvertTz |\n| Field | Instr | Second | WeekDay | MakeTime |\n| MakeSet | LoadFile | MicroSecond | WeekOfYear | PeriodAdd |\n| Oct | Lpad | Month | Year | PeriodDiff |\n| Quote | Date | MonthName | YearWeek | Quarter |\n| Bin | DateDiff | Now | FromUnixTime | SecToTime |\n| Elt | TimeDiff | DayName | GetFormat | SubTime |\n| ExportSet | DateFormat | DayOfMonth | StrToDate | TimeFormat |\n| UTCTim | ToSeconds | TimestampDiff | DateArith | Extract |\n| UnixTimestamp | UTCTimestamp | UTCDate | Time | CurrentTime |\n| ToDays | TimestampAdd | TimeToSec | CurrentDate | SysDate |\n\n### 二. 计算框架进行的修改:\n\n此处依然使用 Length 函数( expression/builtin_string.go )为例进行说明,与前文采取相同目录结构:\n\n**1. expression/builtin_string.go**\n\n(1)`lengthFunctionClass.getFunction()` 方法: **简化类型推导实现**\n\ngetFunction 方法用来生成 built-in 函数对应的函数签名,在[构造 ScalarFunction](https://github.com/pingcap/tidb/blob/master/expression/scalar_function.go#L76) 时被调用\n\n``` go\nfunc (c *lengthFunctionClass) getFunction(args []Expression, ctx context.Context) (builtinFunc, error) {\n // 此处简化类型推导过程,对 newBaseBuiltinFuncWithTp() 实现进行修改,新的实现中,传入 Length 返回值类型 tpInt 表示返回值类型为 int,参数类型 tpString 表示返回值类型为 string\n bf, err := newBaseBuiltinFuncWithTp(args, ctx, tpInt, tpString)\n if err != nil {\n return nil, errors.Trace(err)\n }\n // 此处参考 MySQL 实现,设置返回值长度为 10(character length)\n // 对于 int/double/decimal/time/duration 类型返回值,已在 newBaseBuiltinFuncWithTp() 中默认调用 types.setBinChsClnFlag() 方法,此处无需再进行设置\n bf.tp.Flen = 10\n sig := &builtinLengthSig{baseIntBuiltinFunc{bf}}\n return sig.setSelf(sig), errors.Trace(c.verifyArgs(args))\n}\n```\n\n***注:***\n\n- 对于**返回值类型为 string** 的函数,需要,注意参考 MySQL 行为设置\n\n `bf.tp.[charset | collate | flag]`\n查看 MySQL 行为可以通过在终端启动\n\n ` $ mysql -uroot \\-\\-column-type-info`,这样对于每一个查询语句,可以查看每一列详细的 metadata\n对于返回值类型为 string 的函数,以 [concat](https://github.com/pingcap/tidb/blob/master/expression/builtin_string.go#L204) 为例,当存在类型为 string 且包含 binary flag 的参数时,其返回值也应设置 binary flag\n\n- 对于**返回值类型为 Time** 的函数,需要注意,根据函数行为,设置\n\n `bf.tp.Tp = [ TypeDate | TypeDatetime | TypeTimestamp ]` ,\n 若为 `TypeDate/ TypeDatetime`,还需注意推导 `bf.tp.Decimal` (即小数位数)\n\n- 不确定性的函数:\n\n| 0 | 1 | 2 | 3 | 4 | 5 |\n|:------:|:------------:|:------------:|:-----------:|:----------:|:--------:|\n| Rand | ConnectionID | CurrentUser | User | Database | RowCount |\n| Schema | FoundRows | LastInsertId | Version | Sleep | UUID |\n| GetVar | SetVar | Values | SessionUser | SystemUser | |\n\n(2)实现 `builtinLengthSig.evalInt()` 方法:保持不变,此处请注意修改该函数的注释 (s/ eval/ evalXXX)\n\n**2. expression/builtin_string_test.go**\n\n```go\nfunc (s *testEvaluatorSuite) TestLength(c *C) {\n defer testleak.AfterTest(c)()\n cases := []struct {\n args interface{}\n expected int64\n isNil bool\n getErr bool\n }{\n ......\n }\n\n for _, t := range cases {\n f, err := newFunctionForTest(s.ctx, ast.Length, primitiveValsToConstants([]interface{}{t.args})...)\n c.Assert(err, IsNil)\n d, err := f.Eval(nil)\n // 注意此处不再对 LENGTH 函数的返回值类型进行测试,相应测试被移动到 plan/typeinfer_test.go/TestInferType 函数中,(注意不是expression/typeinferer_test.go)\n if t.getErr {\n c.Assert(err, NotNil)\n } else {\n c.Assert(err, IsNil)\n if t.isNil {\n c.Assert(d.Kind(), Equals, types.KindNull)\n } else {\n c.Assert(d.GetInt64(), Equals, t.expected)\n }\n }\n }\n\n // 测试函数是否具有确定性\n // 在 review 社区的 PRs 过程中发现,这个测试经常会被遗漏,烦请留意\n f, err := funcs[ast.Length].getFunction([]Expression{Zero}, s.ctx)\n c.Assert(err, IsNil)\n c.Assert(f.isDeterministic(), IsTrue)\n}\n```\n\n**3. executor/executor_test.go**\n\n与上一篇文章保持不变,需要注意的是,为了保证可读性, `TestStringBuiltin()` 方法仅对 `expression/builtin_string.go` 文件中的 built-in 函数进行测试。如果 `executor_test.go` 文件中不存在对应的 `TestXXXBuiltin()` 方法,可以新建一个对应的测试函数。\n\n**4. plan/typeinfer_test.go**\n\n```go\nfunc (s *testPlanSuite) TestInferType(c *C) {\n ....\n tests := []struct {\n sql string\n tp byte\n chs string\n flag byte\n flen int\n decimal int\n }{\n ...\n // 此处添加对 length 函数返回值类型的测试\n // 此处注意,对于返回值类型、长度等受参数影响的函数,此处测试请尽量覆盖全面\n {\"length(c_char, c_char)\", mysql.TypeLonglong, charset.CharsetBin, mysql.BinaryFlag, 10, 0},\n ...\n }\n for _, tt := range tests {\n ...\n }\n}\n```\n\n***注:***\n\n当有多个 PR 同时在该文件中添加测试时,若有别的 contributor 的 PR 先于自己的 PR merge 进 master,有可能会发生冲突,此时在本地 merge 一下 master 分支,解决一下再 push 一下即可。\n\n----------------\n\n**成为 New Contributor 赠送限量版马克杯**的活动还在继续中,任何一个新加入集体的小伙伴都将收到我们充满了诚意的礼物,很荣幸能够认识你,也很高兴能和你一起坚定地走得更远。\n\n#### 成为 New Contributor 获赠限量版马克杯,马克杯获取流程如下:\n\n1. 提交 PR\n2. PR提交之后,请耐心等待维护者进行 Review。\n - 目前一般在一到两个工作日内都会进行 Review,如果当前的 PR 堆积数量较多可能回复会比较慢。\n - 代码提交后 CI 会执行我们内部的测试,你需要保证所有的单元测试是可以通过的。期间可能有其它的提交会与当前 PR 冲突,这时需要修复冲突。\n - 维护者在 Review 过程中可能会提出一些修改意见。修改完成之后如果 reviewer 认为没问题了,你会收到 LGTM(looks good to me) 的回复。当收到两个及以上的 LGTM 后,该 PR 将会被合并。\n3. 合并 PR 后自动成为 Contributor,会收到来自 PingCAP Team 的感谢邮件,请查收邮件并填写领取表单\n - 表单填写地址:[http://cn.mikecrm.com/01wE8tX](http://cn.mikecrm.com/01wE8tX)\n4. 后台 AI 核查 GitHub ID 及资料信息,确认无误后随即便快递寄出属于你的限量版马克杯\n5. 期待你分享自己参与开源项目的感想和经验,TiDB Contributor Club 将和你一起分享开源的力量\n\n\n了解更多关于 TiDB 的资料请登陆我们的官方网站:[https://pingcap.com](https://pingcap.com)\n\n加入 TiDB Contributor Club 请添加我们的 AI 微信:\n\n \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2017-07-14","author":"徐怀宇","fillInMethod":"writeDirectly","customUrl":"reconstruct-built-in-function-report","file":null,"relatedBlogs":[]},{"id":"Blogs_12","title":"十分钟成为 Contributor 系列 | 为 TiDB 重构 built-in 函数","tags":["TiDB","社区","Contributor"],"category":{"name":"社区动态"},"summary":"为了加速表达式计算速度,最近我们对表达式的计算框架进行了重构,这篇教程为大家分享如何利用新的计算框架为 TiDB 重写或新增 built-in 函数。","body":"这是十分钟成为 TiDB Contributor 系列的第二篇文章,让大家可以无门槛参与大型开源项目,感谢社区为 TiDB 带来的贡献,也希望参与 TiDB Community 能为你的生活带来更多有意义的时刻。\n\n为了加速表达式计算速度,最近我们对表达式的计算框架进行了重构,这篇教程为大家分享如何利用新的计算框架为 TiDB 重写或新增 built-in 函数。对于部分背景知识请参考[《十分钟成为 TiDB Contributor 系列 | 添加內建函数》](https://pingcap.com/blog-cn/add-a-built-in-function)这篇文章,本文将首先介绍利用新的表达式计算框架重构 built-in 函数实现的流程,然后以一个函数作为示例进行详细说明,最后介绍重构前后表达式计算框架的区别。\n\n## 重构 built-in 函数整体流程\n\n1. 在 TiDB 源码 expression 目录下选择任一感兴趣的函数,假设函数名为 XX\n\n2. 重写 **XXFunctionClass.getFunction()** 方法\n\n - 该方法参照 MySQL 规则,根据 built-in 函数的参数类型推导函数的返回值类型\n - 根据参数的个数、类型、以及函数的返回值类型生成不同的函数签名,关于函数签名的详细介绍见文末附录\n\n3. 实现该 built-in 函数对应的所有函数签名的 **evalYY()** 方法,此处 YY 表示该函数签名的返回值类型\n\n4. 添加测试:\n\n - 在 expression 目录下,完善已有的 TestXX() 方法中关于该函数实现的测试\n - 在 executor 目录下,添加 SQL 层面的测试\n\n5. 运行 make dev,确保所有的 test cast 都能跑过\n\n## 示例\n\n这里以重写 LENGTH() 函数的 PR 为例,进行详细说明\n\n**首先看 expression/builtin_string.go:**\n\n(1)实现 lengthFunctionClass.getFunction() 方法\n\n该方法主要完成两方面工作:\n\n1. 参照 MySQL 规则推导 LEGNTH 的返回值类型\n2. 根据 LENGTH 函数的参数个数、类型及返回值类型生成函数签名。由于 LENGTH 的参数个数、类型及返回值类型只存在确定的一种情况,因此此处没有定义新的函数签名类型,而是修改已有的 builtinLengthSig,使其**组合了 baseIntBuiltinFunc(表示该函数签名返回值类型为 int)**\n\n\n```go\ntype builtinLengthSig struct {\n\tbaseIntBuiltinFunc\n}\n\nfunc (c *lengthFunctionClass) getFunction(args []Expression, ctx context.Context) (builtinFunc, error) {\n\t// 参照 MySQL 规则,对 LENGTH 函数返回值类型进行推导\n\ttp := types.NewFieldType(mysql.TypeLonglong)\n\ttp.Flen = 10\n\ttypes.SetBinChsClnFlag(tp)\n\n\t// 根据参数个数、类型及返回值类型生成对应的函数签名,注意此处与重构前不同,使用的是 newBaseBuiltinFuncWithTp 方法,而非 newBaseBuiltinFunc 方法\n\t// newBaseBuiltinFuncWithTp 的函数声明中,args 表示函数的参数,tp 表示函数的返回值类型,argsTp 表示该函数签名中所有参数对应的正确类型\n\t// 因为 LENGTH 的参数个数为1,参数类型为 string,返回值类型为 int,因此此处传入 tp 表示函数的返回值类型,传入 tpString 用来标识参数的正确类型。对于多个参数的函数,调用 newBaseBuiltinFuncWithTp 时,需要传入所有参数的正确类型\n\tbf, err := newBaseBuiltinFuncWithTp(args, tp, ctx, tpString)\n\tif err != nil {\n\t\treturn nil, errors.Trace(err)\n\t}\n\tsig := &builtinLengthSig{baseIntBuiltinFunc{bf}}\n\treturn sig.setSelf(sig), errors.Trace(c.verifyArgs(args))\n}\n```\n\n\n(2) 实现 builtinLengthSig.evalInt() 方法\n\n\n```go\nfunc (b *builtinLengthSig) evalInt(row []types.Datum) (int64, bool, error) {\n\t// 对于函数签名 builtinLengthSig,其参数类型已确定为 string 类型,因此直接调用 b.args[0].EvalString() 方法计算参数\n\tval, isNull, err := b.args[0].EvalString(row, b.ctx.GetSessionVars().StmtCtx)\n\tif isNull || err != nil {\n\t\treturn 0, isNull, errors.Trace(err)\n\t}\n\treturn int64(len([]byte(val))), false, nil\n}\n```\n\n**然后看 expression/builtin\\_string\\_test.go,对已有的 TestLength() 方法进行完善:**\n\n```go\nfunc (s *testEvaluatorSuite) TestLength(c *C) {\n\tdefer testleak.AfterTest(c)() // 监测 goroutine 泄漏的工具,可以直接照搬\n \t// cases 的测试用例对 length 方法实现进行测试\n\t// 此处注意,除了正常 case 之外,最好能添加一些异常的 case,如输入值为 nil,或者是多种类型的参数\n\tcases := []struct {\n\t\targs interface{}\n\t\texpected int64\n\t\tisNil bool\n\t\tgetErr bool\n\t}{\n\t\t{\"abc\", 3, false, false},\n\t\t{\"你好\", 6, false, false},\n\t\t{1, 1, false, false},\n\t\t...\n\t}\n\tfor _, t := range cases {\n\t\tf, err := newFunctionForTest(s.ctx, ast.Length, primitiveValsToConstants([]interface{}{t.args})...)\n\t\tc.Assert(err, IsNil)\n\t\t// 以下对 LENGTH 函数的返回值类型进行测试\n\t\ttp := f.GetType()\n\t\tc.Assert(tp.Tp, Equals, mysql.TypeLonglong)\n\t\tc.Assert(tp.Charset, Equals, charset.CharsetBin)\n\t\tc.Assert(tp.Collate, Equals, charset.CollationBin)\n\t\tc.Assert(tp.Flag, Equals, uint(mysql.BinaryFlag))\n\t\tc.Assert(tp.Flen, Equals, 10)\n\t\t// 以下对 LENGTH 函数的计算结果进行测试\n\t\td, err := f.Eval(nil)\n\t\tif t.getErr {\n\t\t\tc.Assert(err, NotNil)\n\t\t} else {\n\t\t\tc.Assert(err, IsNil)\n\t\t\tif t.isNil {\n\t\t\t\tc.Assert(d.Kind(), Equals, types.KindNull)\n\t\t\t} else {\n\t\t\t\tc.Assert(d.GetInt64(), Equals, t.expected)\n\t\t\t}\n\t\t}\n\t}\n\t// 以下测试函数是否是具有确定性\n\tf, err := funcs[ast.Length].getFunction([]Expression{Zero}, s.ctx)\n\tc.Assert(err, IsNil)\n\tc.Assert(f.isDeterministic(), IsTrue)\n}\n```\n\n\n\n**最后看 executor/executor_test.go,对 LENGTH 的实现进行 SQL 层面的测试:**\n\n\n```go\n// 关于 string built-in 函数的测试可以在这个方法中添加\nfunc (s *testSuite) TestStringBuiltin(c *C) {\n\tdefer func() {\n\t\ts.cleanEnv(c)\n\t\ttestleak.AfterTest(c)()\n\t}()\n\ttk := testkit.NewTestKit(c, s.store)\n\ttk.MustExec(\"use test\")\n\n\t// for length\n\t// 此处的测试最好也能覆盖多种不同的情况\n\ttk.MustExec(\"drop table if exists t\")\n\ttk.MustExec(\"create table t(a int, b double, c datetime, d time, e char(20), f bit(10))\")\n\ttk.MustExec(`insert into t values(1, 1.1, \"2017-01-01 12:01:01\", \"12:01:01\", \"abcdef\", 0b10101)`)\n\tresult := tk.MustQuery(\"select length(a), length(b), length(c), length(d), length(e), length(f), length(null) from t\")\n\tresult.Check(testkit.Rows(\"1 3 19 8 6 2 \"))\n}\n```\n\n\n## 重构前的表达式计算框架\n\nTiDB 通过 Expression 接口(在 expression/expression.go 文件中定义)对表达式进行抽象,并定义 eval 方法对表达式进行计算:\n\n\n```go\ntype Expression interface{\n ...\n eval(row []types.Datum) (types.Datum, error)\n ...\n}\n```\n\n\n实现 Expression 接口的表达式包括:\n\n- Scalar Function:标量函数表达式\n- Column:列表达式\n- Constant:常量表达式\n\n下面以一个例子说明重构前的表达式计算框架。\n\n例如:\n\n\n```sql\ncreate table t (\n c1 int,\n c2 varchar(20),\n c3 double\n)\n\nselect * from t where c1 + CONCAT( c2, c3 < “1.1” )\n```\n\n\n对于上述 select 语句 where 条件中的表达式:\n在**编译阶段**,TiDB 将构建出如下图所示的表达式树:\n\n\n\n在**执行阶段**,调用根节点的 eval 方法,通过后续遍历表达式树对表达式进行计算。\n\n对于表达式 ‘<’,计算时需要考虑两个参数的类型,并根据一定的规则,将两个参数的值转化为所需的数据类型后进行计算。上图表达式树中的 ‘<’,其参数类型分别为 double 和 varchar,根据 MySQL 的计算规则,此时需要使用浮点类型的计算规则对两个参数进行比较,因此需要将参数 “1.1” 转化为 double 类型,而后再进行计算。\n\n同样的,对于上图表达式树中的表达式 CONCAT,计算前需要将其参数分别转化为 string 类型;对于表达式 ‘+’,计算前需要将其参数分别转化为 double 类型。\n\n因此,在重构前的表达式计算框架中,对于参与运算的每一组数据,计算时都需要**大量的判断分支重复地对参数的数据类型进行判断**,若参数类型不符合表达式的运算规则,则需要将其转换为对应的数据类型。\n\n此外,由 Expression.eval() 方法定义可知,在运算过程中,需要**通过 Datum 结构不断地对中间结果进行包装和解包**,由此也会带来一定的时间和空间开销。\n\n为了解决这两点问题,我们对表达式计算框架进行重构。\n\n## 重构后的表达式计算框架\n\n重构后的表达式计算框架,一方面,在编译阶段利用已有的表达式类型信息,生成参数类型“符合运算规则”的表达式,从而保证在运算阶段中无需再对类型增加分支判断;另一方面,运算过程中只涉及原始类型数据,从而避免 Datum 带来的时间和空间开销。\n\n继续以上文提到的查询为例,在**编译阶段**,生成的表达式树如下图所示,对于不符合函数参数类型的表达式,为其加上一层 cast 函数进行类型转换;\n\n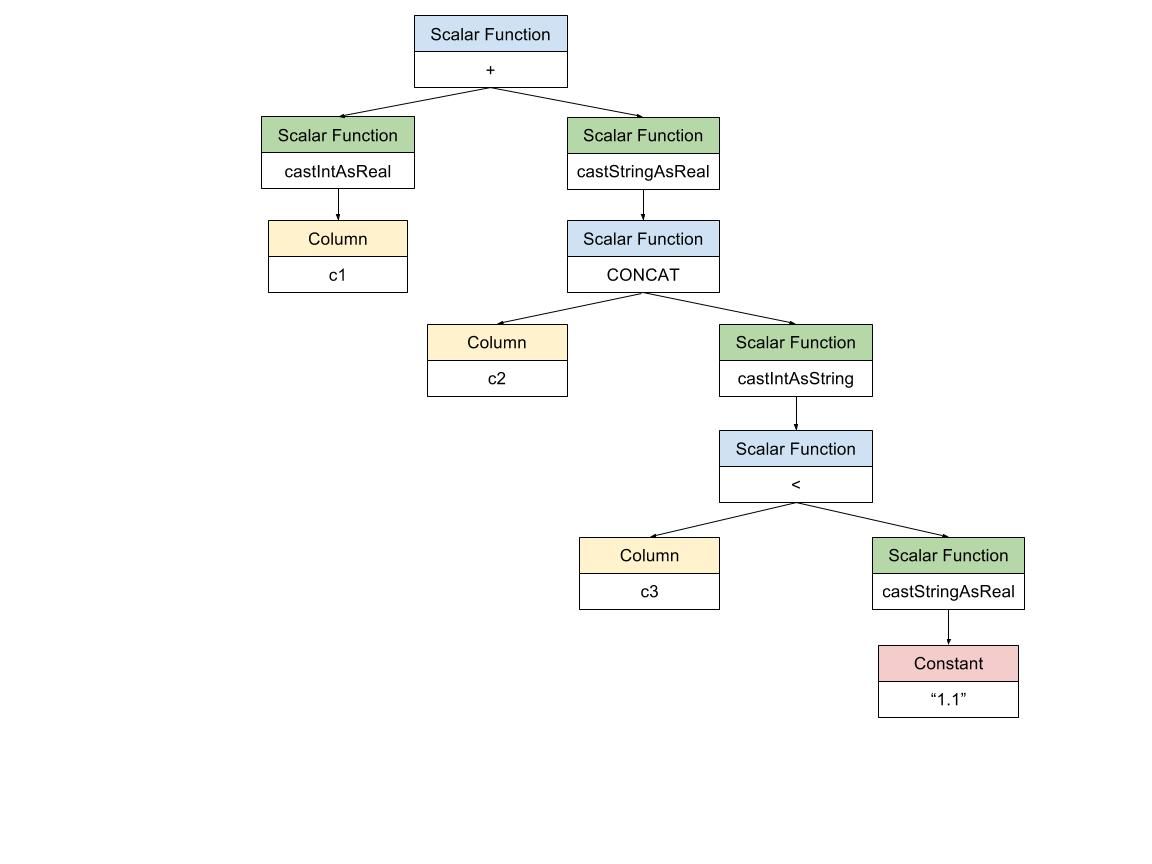\n\n\n这样,在**执行阶段**,对于每一个 ScalarFunction,可以保证其所有的参数类型一定是符合该表达式运算规则的数据类型,无需在执行过程中再对参数类型进行检查和转换。\n\n## 附录\n\n- 对于一个 built-in 函数,由于其参数个数、类型以及返回值类型的不同,可能会生成多个函数签名分别用来处理不同的情况。对于大多数 built-in 函数,其每个参数类型及返回值类型均确定,此时只需要生成一个函数签名。\n- 对于较为复杂的返回值类型推导规则,可以参考 CONCAT 函数的实现和测试。可以利用 MySQLWorkbench 工具运行查询语句 `select funcName(arg0, arg1, ...)` 观察 MySQL 的 built-in 函数在传入不同参数时的返回值数据类型。\n- 在 TiDB 表达式的运算过程中,只涉及 6 种运算类型(目前正在实现对 JSON 类型的支持),分别是\n 1. int (int64)\n 2. real (float64)\n 3. decimal\n 4. string\n 5. Time\n 6. Duration\n 通过 WrapWithCastAsXX() 方法可以将一个表达式转换为对应的类型。\n- 对于一个函数签名,其返回值类型已经确定,所以定义时需要组合与该类型对应的 baseXXBuiltinFunc,并实现 evalXX() 方法。(XX 不超过上述 6 种类型的范围)\n\n\n---------------------------- 我是 AI 的分割线 ----------------------------------------\n\n回顾三月启动的《十分钟成为 TiDB Contributor 系列 | 添加內建函数》活动,在短短的时间内,我们收到了来自社区贡献的超过 200 条新建內建函数,这之中有很多是来自大型互联网公司的资深数据库工程师,也不乏在学校或是刚毕业在刻苦钻研分布式系统和分布式数据库的学生。\n\nTiDB Contributor Club 将大家聚集起来,我们互相分享、讨论,一起成长。\n\n感谢你的参与和贡献,在开源的道路上我们将义无反顾地走下去,和你一起。\n\n**成为 New Contributor 赠送限量版马克杯**的活动还在继续中,任何一个新加入集体的小伙伴都将收到我们充满了诚意的礼物,很荣幸能够认识你,也很高兴能和你一起坚定地走得更远。\n\n#### 成为 New Contributor 获赠限量版马克杯,马克杯获取流程如下:\n\n1. 提交 PR\n2. PR提交之后,请耐心等待维护者进行 Review。\n - 目前一般在一到两个工作日内都会进行 Review,如果当前的 PR 堆积数量较多可能回复会比较慢。\n - 代码提交后 CI 会执行我们内部的测试,你需要保证所有的单元测试是可以通过的。期间可能有其它的提交会与当前 PR 冲突,这时需要修复冲突。\n - 维护者在 Review 过程中可能会提出一些修改意见。修改完成之后如果 reviewer 认为没问题了,你会收到 LGTM(looks good to me) 的回复。当收到两个及以上的 LGTM 后,该 PR 将会被合并。\n3. 合并 PR 后自动成为 Contributor,会收到来自 PingCAP Team 的感谢邮件,请查收邮件并填写领取表单\n - 表单填写地址:[http://cn.mikecrm.com/01wE8tX](http://cn.mikecrm.com/01wE8tX)\n4. 后台 AI 核查 GitHub ID 及资料信息,确认无误后随即便快递寄出属于你的限量版马克杯\n5. 期待你分享自己参与开源项目的感想和经验,TiDB Contributor Club 将和你一起分享开源的力量\n\n\n了解更多关于 TiDB 的资料请登陆我们的官方网站:[https://pingcap.com](https://pingcap.com)\n\n加入 TiDB Contributor Club 请添加我们的 AI 微信:\n\n \n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2017-06-22","author":"徐怀宇","fillInMethod":"writeDirectly","customUrl":"reconstruct-built-in-function","file":null,"relatedBlogs":[]},{"id":"Blogs_141","title":"【Infra Meetup No.45】Rust in TiKV","tags":[],"category":{"name":"社区动态"},"summary":null,"body":">本文整理自 4 月 16 日 Rust 专场 Meetup 上,我司首席架构师唐刘同学的现场分享,共享给大家。enjoy~\n\nHello everyone, today I will talk about how we use Rust in TiKV.\n\nBefore we begin, let me introduce myself. My name is TangLiu, the Chief Architect of PingCAP. Before I joined PingCAP, I had worked at Kingsoft and Tencent. I love open source and have developed some projects like LedisDB, go-mysql, etc…\n\nAt first, I will explain the reason why we chose Rust to develop TiKV, then show you the architecture of TiKV briefly and the key technologies. In the end, I will introduce what we plan to do in the future.\n\n## What’s TiKV?\n\nAll right, let’s begin. First, what is TiKV. TiKV is a distributed Key-Value database with the following features:\n\n- **Geo-replication**: We use Raft and Placement Driver to replicate data geographically to guarantee data safety.\n\n- **Horizontal scalability**: We can add some nodes directly if we find that the rapidly growing data will soon exceed the system capacity.\n\n- **Consistent distributed transaction**: We use an optimized, two phase commit protocol, based on Google Percolator, to support distributed transactions. You can use “begin” to start a transaction, then do something, then use “commit” or “rollback” to finish the transaction.\n\n- **Coprocessor for distributed computing**: Just like HBase, we support a coprocessor framework to let user do computing in TiKV directly.\n\n- **Working with TiDB like Spanner with F1**: Using TiKV as a backend storage engine of TiDB, we can provide the best distributed relational database.\n\n## We need a language with…\n\nAs you see, TiKV has many powerful features. To develop these features, we also need a powerful programming language. The language should have:\n\n- **Fast speed**: We take the performance of TiKV very seriously, so we need a language which runs very fast at runtime.\n\n- **Memory safety**: As a program that is going to run for a long time, we don’t want to meet any memory problem, such as dangling pointer, memory leak, etc…\n\n- **Thread safety**: We must guarantee data consistency all the time, so any data race problem must be avoided.\n\n- **Binding C efficiency**: We depend on RocksDB heavily, so we must be able to call the RocksDB API as fast as we can, without any performance reduction.\n\n## Why not C++?\n\nTo develop a high performance service, C++ may be the best choice in most cases, but we didn’t choose it. We figured we might spend too much time avoiding the memory problem or the data race problem. Moreover, C++ has no official package manager and that makes the maintaining and compiling third dependences very troublesome and difficult, resulting in a long development cycle.\n\n## Why not Go?\n\nAt first, we considered using Go, but then gave up this idea. Go has GC which fixes many memory problems, but it might stop the running process sometimes. No matter how little time the stop takes, we can’t afford it. Go doesn’t solve the data race problem either. Even we can use double dash race in test or at runtime, this isn’t enough.\n\nBesides, although we can use Goroutine to write the concurrent logic easily, we still can’t neglect the runtime expenses of the scheduler. We met a problem a few days ago: we used multi goroutines to select the same context but found that the performance was terrible, so we had to use one sub context for one goroutine, then the performance became better.\n\nMore seriously, CGO has heavy expenses, but we need to call RocksDB API without delay. For the above reasons, we didn’t choose Go even this is the favorite language in our team.\n\n## So we turned to Rust… But Rust…\n\nRust is a system programming language, maintained by Mozilla. It is a very powerful language, however, you can see the curve, the learning curve is very very steep.\n\n\n\nI have been using many programming languages, like C++, Go, python, lua, etc. and Rust is the hardest language for me to master. In PingCAP, we will let the new colleague spend at least one month to learn Rust, to struggle with the compiling errors, and then to rise above it. This would never happen for Go.\n\nBesides, the compiling time is very long, even longer than C++. Each time when I type cargo build to start building TiKV, I can even do some pushups.\n\nAlthough Rust is around for a long time, it still lacks of libraries and tools, and some third projects have not been verified in production yet. These are all the risks for us. Most seriously, it is hard for us to find Rust programmer because only few know it in China, so we are always shorthanded.\n\n## Then, Why Rust?\n\nAlthough Rust has the above disadvantages, its advantages are attractive for us too. Rust is memory safe, so we don’t need to worry about memory leak, or dangling pointer any more.\n\nRust is thread safe, so there won’t be any data race problem. All the safety are guaranteed by compiler. So in most cases, when the compiling passes, we are sure that we can run the program safely.\n\nRust has no GC expenses, so we won’t meet the “stop the world” problem. Calling C through FFI is very fast, so we don’t worry the performance reduction when calling the RocksDB API. At last, Rust has an official package manager, crate, we can find many libraries and use them directly.\n\n**We made a hard but great decision: Use Rust!**\n\n## TiKV Timeline\n\n\n\nHere you can see the TiKV timeline. We first began to develop TiKV January 1st, 2016, and made it open source on April 1st, 2016, and this is not a joke like Gmail at All April Fool’s Day. TiKV was first used in production in October, 2016, when we had not even released a beta version. In November, 2016, we released the first beta version; then RC1 in December, 2016, RC2 in February, this year. Later we plan to release RC3 in April and the first GA version in June.\n\nAs you can see, the development of TiKV is very fast and the released versions of TiKV are stable. Choosing Rust has already been proved a correct decision. Thanks, Rust.\n\n## TiKV Architecture\n\n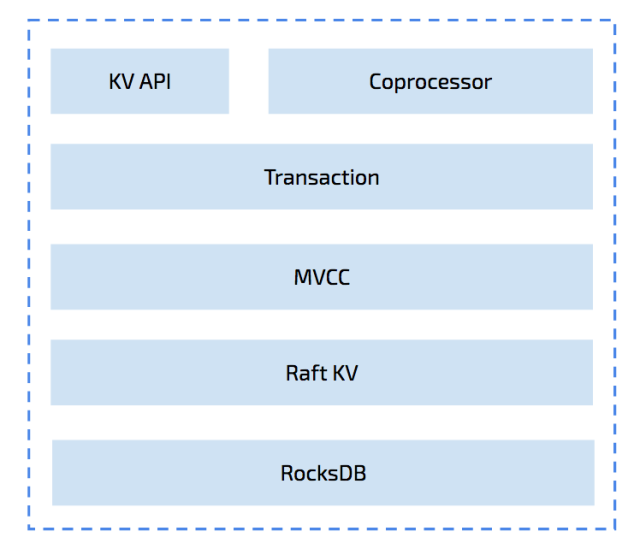\n\nNow let’s go deep into TiKV. You can see from the TiKV architecture that the hierarchy of TiKV is clear and easy to understand.\n\nAt the bottom layer, TiKV uses RocksDB, a high performance, persistent Key-Value store, as the backend storage engine.\n\nThe next layer is Raft KV. TiKV uses the Raft to replicate data geographically. TiKV is designed to store tons of data which one Raft group can’t hold. So we split the data with ranges and use each range as an individual Raft group. We name this approach: Multi-Raft groups.\n\nTiKV provides a simple Key-Value API including SET, GET, DELETE to let user use it just as any distributed Key-Value storage. The upper layer also uses these to support advanced functions.\n\nAbove the Raft layer, it is MVCC. All the keys saved in TiKV must contain a globally unique timestamp, which is allocated by Placement Driver. TiKV uses it to support distributed transactions.\n\nOn the top layer, it is the KV and coprocessor API layer for handling client requests.\n\n## Multi-Raft\n\n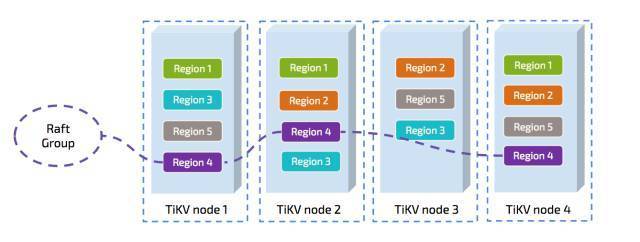\n\nHere is an example of Multi-Raft.\n\nYou can see that there are four TiKV nodes. Within each store, we have several regions. Region is the basic unit of data movement and is replicated by Raft. Each region is replicated to three nodes. These three replicas of one Region make a Raft group.\n\n## Scale Out\n\n### Scale-out (initial state)\n\n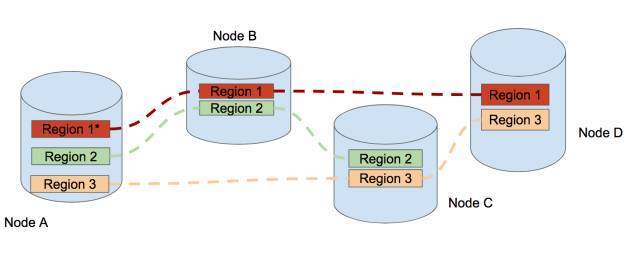\n\nHere is an example of horizontal scalability. At first, we have four nodes, Node A has three regions, others have two regions.\n\nOf course, Node A is busier than other nodes, and we want to reduce its stress.\n\n### Scale-out (add new node)\n\n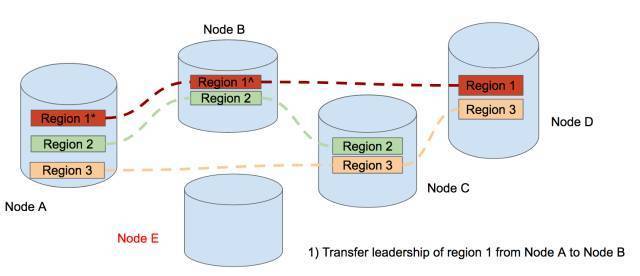\n\nSo we add a new Node E, and begin to move the region 1 in Node A to Node E. But here we find that the leader of region 1 is in Node A, so we will first transfer the leader from Node A to Node B.\n\n### Scale-out (balancing)\n\n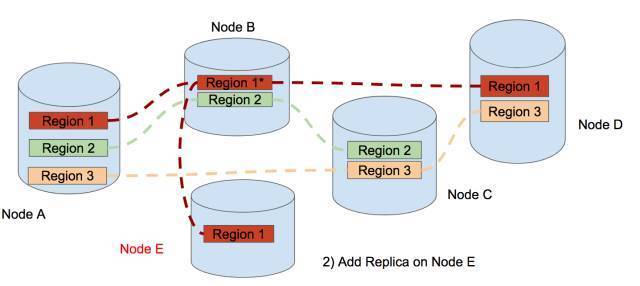\n\nAfter that, the leader of region 1 is in Node B now, then we add a new replica of region 1 in Node E.\n\n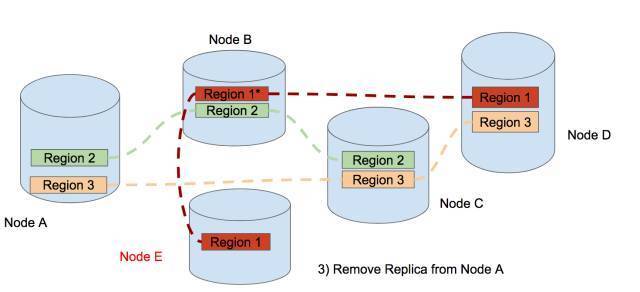\n\nThen we remove the replica of region 1 from Node A. All these are executed by the Placement Driver automatically. What we only need is to add node, if we find the system is busy. Very easy, right?\n\n## A simple write flow\n\n\n\nHere is a simple write flow: when a client sends a write request to TiKV, TiKV first parses the protocol and then dispatches the request to the KV thread, then the KV thread executes some transaction logics and sends the request to Raft thread, after TiKV replicates the Raft log and applies it to RocksDB, the write request is finished.\n\n## Key technologies\n\nNow let’s move on to the key technologies:\n\nFor networking, we use a widely used protocol, Protocol Buffers, to serialize or unserialize data fastly.\n\nAt first, we used **MIO** to build up the network framework. Although MIO encapsulates low level network handling, it is still a very basic library that we need to receive or send data manually, and to decode or encode our customized network protocol. It is not convenient actually. So from RC2, we have been refactoring networking with gRPC. The benefit of gRPC is very obvious. We don’t need to care how to handle network anymore, only focusing on our logic, and the code looks simple and clear. Meanwhile, users can build their own TiKV client with other programming languages easily. We have already been developing a TiKV client with Java.\n\nFor **asynchronous framework**. After receiving the request, TiKV dispatches the request to different threads to handle it asynchronously. At first, we used the MIO plus callback to handle the asynchronous request, but callback may break the code logic, and it is hard to read and write correctly, so now we have been refactoring with tokio-core and futures, and we think this style is more modern for Rust in the future. Sometimes, we also use the thread pool to dispatch simple tasks, and we will use futures-cpupool later.\n\nFor **storage**, we use rust-rocksdb to access RocksDB.\n\nFor **monitoring**, we wrote a rust client for Prometheus, and this client is recommended in the official wiki. For profiling, we use the jemallocator with enabling profile feature and use clippy to check our codes.\n\n## Future plan\n\nOk, that’s what we have done and are doing. Here are what we will do in the future:\n\n- Make TiKV faster, like removing Box. we have used many boxes in TiKV to write code easily, this is not efficient. In our benchmark, dynamic dispatch is at least three times slower than static dispatch, so later we will use Trait Trait directly.\n\n- Make TiKV more stable, like introducing Rust sanitizer.\n\n- Contribute more Rust open source modules, like raft library, open-tracing, etc.\n\n- Participate in other Rust projects more deeply, like rust-gRPC\n\n- Write more articles about Rust on Chinese social media and organize more Rust meetups.\n\n- Be a strong advocate of Rust in China.\n\n","date":"2017-05-31","author":"唐刘","fillInMethod":"writeDirectly","customUrl":"rust-in-tikv","file":null,"relatedBlogs":[]},{"id":"Blogs_223","title":"如何从零开始参与大型开源项目","tags":["开源","社区"],"category":{"name":"社区动态"},"summary":"我们欢迎所有的具有气质的开发者能和 TiDB 一起成长,一起见证数据库领域的革新,改变世界这事儿有时候也不那么难。","body":"## 写在前面的话\n\n上世纪 70 年代,IBM 发明了关系型数据库。但是随着现在移动互联网的发展,接入设备越来越多,数据量越来越大,业务越来越复杂,传统的数据库显然已经不能满足海量数据存储的需求。虽然目前市场上也不乏分布式数据库模型,但没有品位的文艺青年不是好工程师,我们觉得,不,这些方案都不是我们想要的,它们不够美,鲜少能够把分布式事务与弹性扩展做到完美。\n\n受 Google Spanner/F1 的启发,一款从一开始就选择了开源道路的 TiDB 诞生了。 它是一款代表未来的新型分布式 NewSQL 数据库,它可以随着数据增长而无缝水平扩展,只需要通过增加更多的机器来满足业务增长需求,应用层可以不用关心存储的容量和吞吐,用东旭的话说就是「他自己会生长」。\n\n在开源的世界里,TiDB 和 TiKV 吸引了更多的具有极客气质的开发者,目前已经拥有超过 9000 个 star 和 100 个 Contributor,这已然是一个世界顶级开源项目的水准。而成就了这一切的,则是来自社区的力量。\n\n最近我们收到了很多封这样的邮件和留言,大家说:\n\n- “谢谢你们,使得旁人也能接触大型开源项目。本身自己是 DBA,对数据库方面较感兴趣,也希望自己能逐步深入数据库领域,深入TiDB,为 TiDB 社区贡献更多、更有价值的力量。”\n\n- “我是一个在校学生,刚刚收到邮件说我成为了 TiDB 的 Contributor,这让我觉得当初没听父母的话坚持了自己喜欢的计算机技术,是个正确的选择,但我还需要更多的历练,直到能完整地展现、表达我的思维。”\n\n这让我感触颇多,因为,应该是我们感谢你们才是啊,没有社区,一个开源项目就成不了一股清泉甚至一汪海洋。\n\n公司的小姑娘说,她觉得还有很多的人想要参与进来的,可工程师团队欠缺平易近人的表达,这个得改。\n\n于是便有了这篇文章以及未来的多篇文章和活动,我们欢迎所有的具有气质的开发者能和 TiDB 一起成长,一起见证数据库领域的革新,改变世界这事儿有时候也不那么难。\n\n我要重点感谢今天这篇文章的作者,来自社区的朱武(GitHub ID: viile )、小卢(GitHub ID: lwhhhh )和杨文(GitHub ID: yangwenmai),当在 TiDB Contributor Club 里提到想要做这件事的时候,是他们踊跃地加入了 TiDB Tech Writer 的队伍,高效又专业地完成了下文的编辑,谢谢你们。\n\n## 一个典型的开源项目是由什么组成的\n\n### The Community(社区)\n\n- 一个项目经常会有一个围绕着它的社区,这个社区由各个承担不同角色的用户组成。\n\n- **项目的拥有者**:在他们账号中创建项目并拥有它的用户或者组织。\n\n- **维护者和合作者**:主要做项目相关的工作和推动项目发展,通常情况下拥有者和维护者是同一个人,他们拥有仓库的写入权限。\n\n- **贡献者**:发起拉取请求(pull request)并且被合并到项目里面的人。\n\n- **社区成员**:对项目非常关心,并且在关于项目的特性以及 pull requests 的讨论中非常活跃的人。\n\n### The Docs(文档)\n\n项目中经常出现的文件有:\n\n- **Readme**:几乎所有的 Github 项目都包含一个 README\\.md 文件,readme 文件提供了一些项目的详细信息,包括如何使用,如何构建。有时候也会告诉你如何成为贡献者。\n - [TiDB README](https://github.com/pingcap/tidb/blob/master/README.md)\n\n- **Contributing**:项目以及项目的维护者各式各样,所以参与贡献的最佳方式也不尽相同。如果你想成为贡献者的话,那么你要先阅读那些有 CONTRIBUTING 标签的文档。Contributing 文档会详细介绍了项目的维护者希望得到哪些补丁或者是新增的特性。\n\n 文件里也可以包含需要写哪些测试,代码风格,或者是哪些地方需要增加补丁之类的内容。\n \n - [TiDB Contributing 文档](https://github.com/pingcap/tidb/blob/master/CONTRIBUTING.md)\n\n- **License**:LICENSE 文件就是这个开源项目的许可证。一个开源项目会告知用户他们可以做什么,不可做什么(比如:使用,修改,重新分发),以及贡献者允许其他人做哪些事。开源许可证有多种,你可以在 [认识各种开源协议及其关系](http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html) 了解更多关于开源许可证的信息。\n - TiDB 遵循 [Apache-2.0 License](https://github.com/pingcap/tidb/blob/master/LICENSE)\n - TiKV 遵循 [Apache-2.0 License](https://github.com/pingcap/tikv/blob/master/LICENSE)\n\n- **Documentation**:许多大型项目不会只通过自述文件去引导用户如何使用。在这些项目中你经常可以找到通往其他文件的超链接,或者是在仓库中找到一个叫做 docs 的文件夹.\n - [TiDB Docs](https://github.com/pingcap/tidb/tree/master/docs)\n \n \n \n TiDB Docs
\n\n\n## 齐步走成为 Contributor\n\n### Create an Issue\n\n如果你在使用项目中发现了一个 bug,而且你不知道怎么解决这个 bug。或者使用文档时遇到了麻烦。或者有关于这个项目的问题。你可以创建一个 issue。\n\n不管你有什么 bug,你提出 bug 后,会对那些和你有同样 bug 的人提供帮助。\n更多关于 issue 如何工作的信息,请点击 [Issues guide](http://guides.github.com/features/issues)。\n\n\n#### Issues Pro Tips\n\n* **检查你的问题是否已经存在** 重复的问题会浪费大家的时间,所以请先搜索打开和已经关闭的问题,来确认你的问题是否已经提交过了。\n\n* **清楚描述你的问题**\n\n TiDB Issue 模版如下:\n\n \n \n TiDB Issue 模版
\n\n TiKV Issue 模版如下:\n \n \n \n TiKV Issue 模版
\n\n* **给出你的代码链接** 使用像 [JSFiddle](http://jsfiddle.net/) 或者 [CodePen](http://codepen.io/) 等工具,贴出你的代码,好帮助别人复现你的问题。\n\n* **详细的系统环境介绍** 例如使用什么版本的浏览器,什么版本的库,什么版本的操作系统等其他你运行环境的介绍。\n\n ```\n go 版本: go version\n Linux 版本: uname -a\n ```\n\n* **详细的错误输出或者日志** 使用 [Gist](http://gist.github.com/) 贴出你的错误日志。如果你在 issue 中附带错误日志,请使用 ``` 来标记你的日志。以便更好的显示。\n\n### Pull Request\n\n如果你能解决这个 bug,或者你能够添加其他的功能。并且知道如何成为贡献者,理解 license,已经签过 [Contributor License Agreement](https://en.wikipedia.org/wiki/Contributor_License_Agreement)(CLA)后,请发起 Pull Request。这样维护人员可以将你的分支与现有分支进行比较,来决定是否合并你的更改。\n\n### Pull Request Pro Tips\n\n* **[Fork](http://guides.github.com/activities/forking/) 代码并且 clone 到你本地** 通过将项目的地址添加为一个 remote,并且经常从 remote 合并更改来保持你的代码最新,以便在提交你的 pull 请求时,尽可能少的发生冲突。详情请参阅 [Syncing a fork](https://help.github.com/articles/syncing-a-fork)。\n\n* **创建 [branch](http://guides.github.com/introduction/flow/)** 来修改你的代码,目前 TiDB 相关的项目默认的 branch 命名规则是 user/name。例如 disksing/grpc,简单明确,一目了然。\n\n* **描述清楚你的问题**方便其他人能够复现。或者说明你添加的功能有什么作用,并且清楚描述你做了哪些更改。\n\n* **注意测试** 如果项目中包含逻辑修改,那么必须包含相应的测试,在 CI 中会包含测试覆盖率的检测,如果测试覆盖率下降,那么是不可以合并到 master 的。\n\n* **包含截图** 如果您的更改包含 HTML/CSS 中的差异,请添加前后的屏幕截图。将图像拖放到您的 pull request 的正文中。\n\n* **保持良好的代码风格**这意味着使用与你自己的代码风格中不同的缩进,分号或注释,但是使维护者更容易合并,其他人将来更容易理解和维护。目前 TiDB 项目的 CI 检测包含代码风格的检查,如果代码风格不符合要求,那么是不可以合并到 master 的。\n\n### Open Pull Requests\n\n一旦你新增一个 pull request,讨论将围绕你的更改开始。其他贡献者和用户可能会进入讨论,但最终决定是由维护者决定的。你可能会被要求对你的 pull request 进行一些更改,如果是这样,请向你的 branch 添加更多代码并推送它们,它们将自动进入现有的 pull request。\n\n\n\nOpen Pull Requests
\n\n如果你的 pull request 被合并,这会非常棒。如果没有被合并,不要灰心。也许你的更改不是项目维护者需要的。或者更改已经存在了。发生这种情况时,我们建议你根据收到的任何反馈来修改代码,并再次提出 pull request。或创建自己的开源项目。\n\n### TiDB 合并流程\n\nPR 提交之后,请耐心等待维护者进行 Review。\n\n目前一般在一到两个工作日内都会进行 Review,如果当前的 PR 堆积数量较多可能回复会比较慢。\n代码提交后 CI 会执行我们内部的测试,你需要保证所有的单元测试是可以通过的。期间可能有其它的提交会与当前 PR 冲突,这时需要修复冲突。\n\n维护者在 Review 过程中可能会提出一些修改意见。修改完成之后如果 reviewer 认为没问题了,你会收到 LGTM(looks good to me)的回复。当收到两个及以上的 LGTM 后,该 PR 将会被合并。\n\n>标注:本文「一个典型的开源项目是由什么组成的」及「齐步走为 Contributor」参考自英文 GitHub Guide,由社区成员朱武(GitHub ID: viile)、小卢(GitHub ID:lwhhhh)着手翻译并替换部分原文中的截图。GitHub Guides:如何参与一个 GitHub 开源项目 [英文原文](https://guides.github.com/activities/contributing-to-open-source/)。\n\n**加入 TiDB Contributor Club**\n\n为更好地促进 Contributor 间的交流,便于随时提出好的想法和反馈,我们创建了一个 Contributor Club 微信群,对成为 TiDB Contributor 有兴趣的同学可以添加 TiDB Robot 微信号,它会在后台和你打招呼,并积极招募你成为开源社区的一员。\n\n","date":"2017-03-27","author":"TiDB Contributor","fillInMethod":"writeDirectly","customUrl":"how-to-contribute","file":null,"relatedBlogs":[]},{"id":"Blogs_38","title":"十分钟成为 TiDB Contributor 系列 | 添加內建函数","tags":["TiDB","Contributor","内建函数","社区"],"category":{"name":"社区动态"},"summary":"最近我们对 TiDB 代码做了些改进,大幅度简化了添加內建函数的流程,这篇教程描述如何为 TiDB 新增 builtin 函数。首先介绍一些必需的背景知识,然后介绍增加 builtin 函数的流程,最后会以一个函数作为示例。","body":"## **背景知识**\n\nSQL 语句发送到 TiDB 后首先会经过 parser,从文本 parse 成为 AST(抽象语法树),通过 Query Optimizer 生成执行计划,得到一个可以执行的 plan,通过执行这个 plan 即可得到结果,这期间会涉及到如何获取 table 中的数据,如何对数据进行过滤、计算、排序、聚合、滤重以及如何对表达式进行求值。\n对于一个 builtin 函数,比较重要的是进行语法解析以及如何求值。其中语法解析部分需要了解如何写 yacc 以及如何修改 TiDB 的词法解析器,较为繁琐,我们已经将这部分工作提前做好,大多数 builtin 函数的语法解析工作已经做完。\n对 builtin 函数的求值需要在 TiDB 的表达式求值框架下完成,每个 builtin 函数被认为是一个表达式,用一个 ScalarFunction 来表示,每个 builtin 函数通过其函数名以及参数,获取对应的函数类型以及函数签名,然后通过函数签名进行求值。\n总体而言,上述流程对于不熟悉 TiDB 的朋友而言比较复杂,我们对这部分做了些工作,将一些流程性、较为繁琐的工作做了统一处理,目前已经将大多数未实现的 buitlin 函数的语法解析以及寻找函数签名的工作完成,但是函数实现部分留空。***换句话说,只要找到留空的函数实现,将其补充完整,即可作为一个 PR。***\n\n## **添加 builtin 函数整体流程**\n\n1. 找到未实现的函数\n\n 在 TiDB 源码中的 expression 目录下搜索 `errFunctionNotExists`,即可找到所有未实现的函数,从中选择一个感兴趣的函数,比如 SHA2 函数:\n\n ```\n func (b *builtinSHA2Sig) eval(row []types.Datum) (d types.Datum, err error) {\n return d, errFunctionNotExists.GenByArgs(\"SHA2\")\n }\n ```\n\n2. 实现函数签名\n\n 接下来要做的事情就是实现 eval 方法,函数的功能请参考 MySQL 文档,具体的实现方法可以参考目前已经实现函数。\n\n3. 在 typeinferer 中添加类型推导信息\n\n 在 plan/typeinferer.go 中的 handleFuncCallExpr() 里面添加这个函数的返回结果类型,请保持和 MySQL 的结果一致。全部类型定义参见 [MySQL Const](https://github.com/pingcap/tidb/blob/source-code/mysql/type.go#L17)。\n\n > **注意**:大多数函数除了需要填写返回值类型之外,还需要获取返回值的长度。\n\n4. 写单元测试\n\n 在 expression 目录下,为函数的实现增加单元测试,同时也要在 plan/typeinferer_test.go 文件中添加 typeinferer 的单元测试\n\n5. 运行 make dev,确保所有的 test case 都能跑过。\n\n## **示例**\n\n这里以[新增 SHA1() 函数的 PR](https://github.com/pingcap/tidb/pull/2781/files) 为例,进行详细说明\n\n1. 首先看 `expression/builtin_encryption.go`:\n将 SHA1() 的求值方法补充完整\n\n ```\n func (b *builtinSHA1Sig) eval(row []types.Datum) (d types.Datum, err error) {\n // 首先对参数进行求值,这块一般不用修改\n args, err := b.evalArgs(row)\n if err != nil {\n return types.Datum{}, errors.Trace(err)\n }\n // 每个参数的意义请参考 MySQL 文档\n // SHA/SHA1 function only accept 1 parameter\n arg := args[0]\n if arg.IsNull() {\n return d, nil\n }\n // 这里对参数值做了一个类型转换,函数的实现请参考 util/types/datum.go\n bin, err := arg.ToBytes()\n if err != nil {\n return d, errors.Trace(err)\n }\n hasher := sha1.New()\n hasher.Write(bin)\n data := fmt.Sprintf(\"%x\", hasher.Sum(nil))\n // 设置返回值\n d.SetString(data)\n return d, nil\n }\n ```\n\n2. 接下来给函数实现添加单元测试,参见 `expression/builtin_encryption_test.go`:\n\n ```\n var shaCases = []struct {\n origin interface{}\n crypt string\n }{\n {\"test\", \"a94a8fe5ccb19ba61c4c0873d391e987982fbbd3\"},\n {\"c4pt0r\", \"034923dcabf099fc4c8917c0ab91ffcd4c2578a6\"},\n {\"pingcap\", \"73bf9ef43a44f42e2ea2894d62f0917af149a006\"},\n {\"foobar\", \"8843d7f92416211de9ebb963ff4ce28125932878\"},\n {1024, \"128351137a9c47206c4507dcf2e6fbeeca3a9079\"},\n {123.45, \"22f8b438ad7e89300b51d88684f3f0b9fa1d7a32\"},\n }\n\n func (s *testEvaluatorSuite) TestShaEncrypt(c *C) {\n defer testleak.AfterTest(c)() // 监测 goroutine 泄漏的工具,可以直接照搬\n fc := funcs[ast.SHA]\n for _, test := range shaCases {\n in := types.NewDatum(test.origin)\n f, _ := fc.getFunction(datumsToConstants([]types.Datum{in}), s.ctx)\n crypt, err := f.eval(nil)\n c.Assert(err, IsNil)\n res, err := crypt.ToString()\n c.Assert(err, IsNil)\n c.Assert(res, Equals, test.crypt)\n }\n // test NULL input for sha\n var argNull types.Datum\n f, _ := fc.getFunction(datumsToConstants([]types.Datum{argNull}), s.ctx)\n crypt, err := f.eval(nil)\n c.Assert(err, IsNil)\n c.Assert(crypt.IsNull(), IsTrue)\n }\n ```\n \n > **注意**:除了正常 case 之外,最好能添加一些异常的case,如输入值为 nil,或者是多种类型的参数\n \n3. 最后还需要添加类型推导信息以及 test case,参见 `plan/typeinferer.go`,`plan/typeinferer_test.go`:\n\n ```\n case ast.SHA, ast.SHA1:\n tp = types.NewFieldType(mysql.TypeVarString)\n chs = v.defaultCharset\n tp.Flen = 40\n ```\n \n ```\n {`sha1(123)`, mysql.TypeVarString, \"utf8\"},\n {`sha(123)`, mysql.TypeVarString, \"utf8\"},\n ```\n\n\n编辑按:添加 TiDB Robot 微信,加入 TiDB Contributor Club,无门槛参与开源项目,改变世界从这里开始吧(萌萌哒)。\n\n \n\n> 点击查看更多 [成为 Contributor 系列文章](https://pingcap.com/zh/blog/?tag=Contributor)","date":"2017-03-14","author":"申砾","fillInMethod":"writeDirectly","customUrl":"add-a-built-in-function","file":null,"relatedBlogs":[]}],"blogCategories":[{"name":"产品技术解读"},{"name":"公司动态"},{"name":"社区动态"},{"name":"案例实践"},{"name":"观点洞察"}],"blogRecommend":[{"blog":{"author":"黄东旭","summary":"PingCAP 联合创始人兼 CTO 黄东旭分介绍了 TiDB Serverless 作为未来一代数据库的核心设计理念,同时探讨了 TiDB Serverless 对于中国用户的价值。","title":"黄东旭:The Future of Database,掀开 TiDB Serverless 的引擎盖","date":"2023-07-24","customUrl":"the-future-of-database-2023"}},{"blog":{"author":"张翔","summary":"本次分享在介绍 Serverless Tier 的技术细节之余,全面解析了 TiDB 的技术生态全景和在生态构建中所做的努力。阅读本文,了解有关 Serverless 的更多信息,以及 PingCAP 在技术领域的最新进展。","title":"TiDB Serverless 和技术生态全景","date":"2023-02-20","customUrl":"tidb-serverless-and-technology-ecology-overview"}},{"blog":{"author":"韩锋","summary":"本文转载自公众号:韩锋频道(hanfeng_channel)。文章从金融用户角度入手,对如何选择分布式数据库及选型后的最优实践进行了阐述。","title":"金融业分布式数据库选型及 HTAP 场景实践","date":"2022-05-19","customUrl":"distributed-database-selection-and-htap-practice-in-financial-industry"}},{"blog":{"author":"黄东旭","summary":"很多时候「品味」之所以被称为「品味」,就是因为说不清道不明,这固然是软件开发艺术性的一种体现,但是这也意味着它不可复制,不易被习得。本系列文章会试着总结一下好的基础软件体验到底从哪里来。作为第一篇,本文将围绕可观测性和可交互性两个比较重要的话题来谈。","title":"做出让人爱不释手的基础软件:可观测性和可交互性","date":"2021-10-15","customUrl":"how-to-develop-an-infrasoft-observability-and-interactivity"}},{"blog":{"author":"刘奇","summary":"我们更多时候是站在哲学层面思考整个公司的运转和 TiDB 这个产品的演进的思路。这些思路很多时候是大家看不见的,因为不是一个纯粹的技术层面或者算法层面的事情。","title":"势高,则围广:TiDB 的架构演进哲学","date":"2019-05-30","customUrl":"guiding-ideologies-in-the-evolution-of-tidb"}}],"blogMostPopular":[{"blog":{"author":"申砾","customUrl":"tidb-internal-1","date":"2017-05-15","summary":"数据库、操作系统和编译器并称为三大系统,可以说是整个计算机软件的基石。其中数据库更靠近应用层,是很多业务的支撑。这一领域经过了几十年的发展,不断的有新的进展。很多人用过数据库,但是很少有人实现过一个数据库,特别是实现一个分布式数据库。了解数据库的实现原理和细节,一方面可以提高个人技术,对构建其他系统有帮助,另一方面也有利于用好数据库。研究一门技术最好的方法是研究其中一个开源项目,数据库也不例外。单机数据库领域有很多很好的开源项目,其中 MySQL 和 PostgreSQL 是其中知名度最高的两个,不少同学都看过这两个项目的代码。但是分布式数据库方面,好的开源项目并不多。 TiDB 目前获得了广泛的关注,特别是一些技术爱好者,希望能够参与这个项目。由于分布式数据库自身的复杂性,很多人并不能很好的理解整个项目,所以我希望能写一些文章,自顶向下,由浅入深,讲述 TiDB 的一些技术原理,包括用户可见的技术以及大量隐藏在 SQL 界面后用户不可见的技术点。","title":"三篇文章了解 TiDB 技术内幕 - 说存储"}},{"blog":{"author":"申砾","customUrl":"tidb-internal-2","date":"2017-05-24","summary":"上一篇介绍了 TiDB 如何存储数据,也就是 TiKV 的一些基本概念。本篇将介绍 TiDB 如何利用底层的 KV 存储,将关系模型映射为 Key-Value 模型,以及如何进行 SQL 计算。","title":"三篇文章了解 TiDB 技术内幕 - 说计算"}},{"blog":{"author":"申砾","customUrl":"tidb-internal-3","date":"2017-06-06","summary":"任何一个复杂的系统,用户感知到的都只是冰山一角,数据库也不例外。前两篇文章介绍了 TiKV、TiDB 的基本概念以及一些核心功能的实现原理,这两个组件一个负责 KV 存储,一个负责 SQL 引擎,都是大家看得见的东西。在这两个组件的后面,还有一个叫做 PD(Placement Driver)的组件,虽然不直接和业务接触,但是这个组件是整个集群的核心,负责全局元信息的存储以及 TiKV 集群负载均衡调度。本篇文章介绍一下这个神秘的模块。这部分比较复杂,很多东西大家平时不会想到,也很少在其他文章中见到类似的东西的描述。我们还是按照前两篇的思路,先讲我们需要什么样的功能,再讲我们如何实现,大家带着需求去看实现,会更容易的理解我们做这些设计时背后的考量。","title":"三篇文章了解 TiDB 技术内幕 - 谈调度"}},{"blog":{"author":"PingCAP","customUrl":"introduction-of-open-source-license","date":"2021-10-20","summary":"PingCAP 从第一行代码开源,六年里积累了一些经验和教训,在《开源知识科普》栏目中,我们将与大家分享和交流在开源成长路径中的思考和感受,以及参与开源项目的正确姿势。本期话题就从开源的基础——开源许可证开始,希望对大家了解开源、参与开源有一定帮助。","title":"一文看懂开源许可证丨开源知识科普"}},{"blog":{"author":"唐刘","customUrl":"grpc","date":"2017-06-18","summary":"经过很长一段时间的开发,TiDB 终于发了 RC3。RC3 版本对于 TiKV 来说最重要的功能就是支持了 gRPC,也就意味着后面大家可以非常方便的使用自己喜欢的语言对接 TiKV 了。gRPC 是基于 HTTP/2 协议的,要深刻理解 gRPC,理解下 HTTP/2 是必要的,这里先简单介绍一下 HTTP/2 相关的知识,然后再介绍下 gRPC 是如何基于 HTTP/2 构建的。","title":"深入了解 gRPC:协议"}}],"allTags":[{"name":"TiDB","count":179},{"name":"社区","count":103},{"name":"TiKV","count":30},{"name":"社区动态","count":29},{"name":"TiDB 源码阅读","count":24},{"name":"TiKV 源码解析","count":21},{"name":"HTAP","count":20},{"name":"Release","count":17},{"name":"TiFlash","count":16},{"name":"Chaos Mesh","count":15},{"name":"TiDB Hackathon 2021","count":13},{"name":"Raft","count":11},{"name":"TiCDC","count":11},{"name":"TiDB 4.0 新特性","count":11},{"name":"DM 源码阅读","count":10},{"name":"Contributor","count":9},{"name":"TiDB Binlog 源码阅读","count":9},{"name":"TiFlash 源码阅读","count":9},{"name":"TiDB Hackathon 2022","count":8},{"name":"技术出海","count":8},{"name":"Serverless","count":7},{"name":"TiDB Hackathon 2020","count":7},{"name":"TiDB 性能调优","count":7},{"name":"分布式数据库","count":7},{"name":"DM","count":6},{"name":"SQL","count":6},{"name":"最佳实践","count":6},{"name":"架构","count":6},{"name":"Hackathon","count":5},{"name":"PD","count":5},{"name":"Rust","count":5},{"name":"TiDB Binlog","count":5},{"name":"TiDB Cloud","count":5},{"name":"TiDB Operator","count":5},{"name":"TiDB Operator 源码阅读","count":5},{"name":"TiSpark","count":5},{"name":"事务","count":5},{"name":"事务前沿研究","count":5},{"name":"新经济 DTC 转型","count":5},{"name":"DevCon","count":4},{"name":"Linux","count":4},{"name":"MySQL","count":4},{"name":"TiDB 易用性挑战赛","count":4},{"name":"TiKV 功能介绍","count":4},{"name":"分布式系统前沿技术","count":4},{"name":"备份恢复","count":4},{"name":"大促背后的数据库","count":4},{"name":"工具","count":4},{"name":"性能","count":4},{"name":"数据迁移","count":4},{"name":"Committer","count":3},{"name":"Go","count":3},{"name":"Kubernetes","count":3},{"name":"Percolator","count":3},{"name":"PingCAP 用户峰会","count":3},{"name":"Prometheus","count":3},{"name":"RocksDB","count":3},{"name":"TiDB Ecosystem Tools","count":3},{"name":"TiDB Serverless","count":3},{"name":"TiKV 源码阅读","count":3},{"name":"云原生","count":3},{"name":"分布式系统测试","count":3},{"name":"基础软件","count":3},{"name":"BR","count":2},{"name":"Cloud-TiDB","count":2},{"name":"Dumpling","count":2},{"name":"Flink","count":2},{"name":"K8s","count":2},{"name":"Key Visualizer","count":2},{"name":"MVCC","count":2},{"name":"PingCAP","count":2},{"name":"PingCAP 用户峰会","count":2},{"name":"Spanner","count":2},{"name":"TiDB 性能挑战赛","count":2},{"name":"TiDB-4.0","count":2},{"name":"TiUP","count":2},{"name":"WebAssembly","count":2},{"name":"gRPC","count":2},{"name":"优化器","count":2},{"name":"升级","count":2},{"name":"多业务融合","count":2},{"name":"带着问题读 TiDB 源码","count":2},{"name":"性能优化","count":2},{"name":"性能调优","count":2},{"name":"数据同步","count":2},{"name":"版本","count":2},{"name":"资源管控","count":2},{"name":"集群调度","count":2},{"name":"2PC","count":1},{"name":"AI","count":1},{"name":"Ansible","count":1},{"name":"CAP","count":1},{"name":"Chat2Query","count":1},{"name":"ChatGPT","count":1},{"name":"Cloud","count":1},{"name":"DNB","count":1},{"name":"Data Platform","count":1},{"name":"Database","count":1},{"name":"Database Branching","count":1},{"name":"Elasticsearch","count":1},{"name":"Failpoint","count":1},{"name":"Fintech","count":1},{"name":"Flink TiDB 物化视图","count":1},{"name":"GA","count":1},{"name":"Grafana","count":1},{"name":"HAProxy","count":1},{"name":"HTAP TiFlash","count":1},{"name":"Hadoop","count":1},{"name":"Horoscope","count":1},{"name":"Jepsen","count":1},{"name":"Kudu","count":1},{"name":"LSM-tree","count":1},{"name":"Lease Read","count":1},{"name":"Libbpf-tools","count":1},{"name":"Linearizability","count":1},{"name":"MPP","count":1},{"name":"Multi-Raft","count":1},{"name":"MySQL 架构演进","count":1},{"name":"NewSQL","count":1},{"name":"OpenAI","count":1},{"name":"OpenSource","count":1},{"name":"Oracle 迁移","count":1},{"name":"Partitioned Raft KV","count":1},{"name":"Partitioned-Raft-KV","count":1},{"name":"PiTR","count":1},{"name":"Redis","count":1},{"name":"Resource Control","count":1},{"name":"SMP","count":1},{"name":"SQL Plan Management","count":1},{"name":"SaaS","count":1},{"name":"Spark","count":1},{"name":"Syncer","count":1},{"name":"THP","count":1},{"name":"Talent Plan","count":1},{"name":"Test","count":1},{"name":"The Future of Database","count":1},{"name":"TiDB + Flink","count":1},{"name":"TiDB 4.0","count":1},{"name":"TiDB 4.0 捉虫竞赛","count":1},{"name":"TiDB Dashboard","count":1},{"name":"TiDB DevCon 2020","count":1},{"name":"TiDB Hackathon 2023","count":1},{"name":"TiDB 工具","count":1},{"name":"TiDB-DM","count":1},{"name":"TiDB-Lightning","count":1},{"name":"TiEM","count":1},{"name":"TiKV 性能优化","count":1},{"name":"TiPocket","count":1},{"name":"Tile","count":1},{"name":"Titan","count":1},{"name":"Tools","count":1},{"name":"futures","count":1},{"name":"java","count":1},{"name":"k8s","count":1},{"name":"knossos","count":1},{"name":"一致性","count":1},{"name":"主从","count":1},{"name":"全文检索","count":1},{"name":"内建函数","count":1},{"name":"分布式","count":1},{"name":"分布式SQL","count":1},{"name":"分布式事务","count":1},{"name":"分布式计算","count":1},{"name":"历史读","count":1},{"name":"可串行化","count":1},{"name":"合作伙伴生态","count":1},{"name":"在线 DDL","count":1},{"name":"垃圾回收","count":1},{"name":"备份","count":1},{"name":"多版本并发控制","count":1},{"name":"多租户","count":1},{"name":"大数据","count":1},{"name":"存储","count":1},{"name":"存储引擎","count":1},{"name":"安装部署","count":1},{"name":"容灾机制","count":1},{"name":"工程实践","count":1},{"name":"平凯数据库","count":1},{"name":"应用场景","count":1},{"name":"开源","count":1},{"name":"开源知识科普","count":1},{"name":"异构复制","count":1},{"name":"性能挑战赛","count":1},{"name":"悲观锁","count":1},{"name":"持续性能分析","count":1},{"name":"数字化转型","count":1},{"name":"数据分片","count":1},{"name":"数据库","count":1},{"name":"无锁快照","count":1},{"name":"智能制造","count":1},{"name":"服务可观察","count":1},{"name":"机器学习","count":1},{"name":"查询优化","count":1},{"name":"核心批量核算","count":1},{"name":"水平扩展","count":1},{"name":"测试","count":1},{"name":"测试工具","count":1},{"name":"混沌工程","count":1},{"name":"源码分析","count":1},{"name":"版本迁移","count":1},{"name":"用户实践","count":1},{"name":"监控","count":1},{"name":"线性一致","count":1},{"name":"自动化","count":1},{"name":"自动化测试","count":1},{"name":"计算","count":1},{"name":"调优","count":1},{"name":"调度","count":1},{"name":"跨数据中心","count":1},{"name":"运维","count":1},{"name":"金融","count":1},{"name":"隔离级别","count":1},{"name":"高并发","count":1}],"hotTags":[{"name":"TiDB","count":179},{"name":"社区","count":103},{"name":"TiKV","count":30},{"name":"社区动态","count":29},{"name":"TiDB 源码阅读","count":24},{"name":"TiKV 源码解析","count":21},{"name":"HTAP","count":20},{"name":"Release","count":17},{"name":"TiFlash","count":16},{"name":"Chaos Mesh","count":15},{"name":"TiDB Hackathon 2021","count":13},{"name":"Raft","count":11},{"name":"TiCDC","count":11},{"name":"TiDB 4.0 新特性","count":11},{"name":"DM 源码阅读","count":10},{"name":"Contributor","count":9},{"name":"TiDB Binlog 源码阅读","count":9},{"name":"TiFlash 源码阅读","count":9},{"name":"TiDB Hackathon 2022","count":8},{"name":"技术出海","count":8}]}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}