{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/book-rush-tidb-6.x-in-action-release",
"result": {"pageContext":{"blog":{"id":"Blogs_410","title":"《TiDB 6.x in Action》发布,凝聚社区集体智慧的 6.x 实践汇总!","tags":["TiDB"],"category":{"name":"社区动态"},"summary":"为了帮助更多的用户把 TiDB 6.x 新版本中那些“好用”的特性用起来,我们集结社区的集体智慧,共同创作了《TiDB 6.x in Action》。今天,这本书正式发布啦!","body":"今年,TiDB 已经发布了 6.0 和 6.1 两个较大的版本更新,在 6.0 中大幅度加强了 TiDB 的可管理性和可运维性, 6.1 中又进一步提升了 TiDB 产品的稳定性。为了帮助更多的用户把新版本中这些“好用”的特性用起来,我们集结社区的集体智慧,共同创作了[《TiDB 6.x in Action》](https://tidb.net/book/book-rush/)。今天,这本书正式发布啦!\n\n\n\n## TiDB 6.x in Action 内容概览\n\n《TiDB 6.x in Action》分为 TiDB 6.x 原理和特性、TiDB Developer 体验指南、TiDB 6.x 可管理性、TiDB 6.x 内核优化与性能提升、TiDB 6.x 测评、TiDB 6.x 最佳实践 6 大内容模块,汇聚了 TiDB 6.x 新特性的原理、测评、试用心得等等干货。不管你是 DBA 运维还是应用开发者,如果你正在或有意向使用 TiDB 6.x,这本书都可以给你提供参考和实践指南。\n\n\n\n针对 TiDB 6.x 中引入的十几个新特性,比如热点小表缓存,更多算子和函数支持,数据放置框架(Placement Rules In SQL),TiUniManager ,PingCAP Clinic 等,《TiDB 6.x in Action》中都有单独的章节策划,每个章节都有用户实践文章的收录;针对 4 月份刚刚开源的 TiFlash,电子书专门策划了“TiFlash 源码阅读”章节,帮助大家了解 TiFlash 背后的设计原理;另外值得关注的是,本书还专门针对应用开发者人群,策划了“TiDB Developer 体验指南”的章节,帮助用户了解如何基于 TiDB 构建不同语言的应用程序。\n\n### 大咖推荐\n\n**刘奇**,PingCAP 创始人兼 CEO\n\nTiDB 6.0 提供了很多我非常喜欢的易用性改进,也提供了一些我们称作元功能的功能 (Placement Rules),这个功能的意义就像分布式系统里面的元数据,本身只是整个系统数据很小的一部分,但带来了整个系统巨大的存储潜力,我也希望看到这些元功能撑起更多的各种场景下的使用创新,在社区的集体智慧中不断突破想象力边界,给大家带来更多惊喜。\n\n**贾世闻**,京东科技架构师,old TiDBer\n\n很高兴看到 TiDB Book Rush 6.0 的成果。本次 Book Rush 因为档期问题没能参与,有些遗憾。2020 年第一次 Book Rush 以 4.0 为蓝本,后来有了《TiDB 4.0 in Action》。用一个词来形容看到新版本的第一感受就是 evolution 。新特性带来新的用户体验,希望 TiDB 不断进化,带来更多惊喜。\n\n**孙晓光**,PingCAP Cloud Ecosystem 团队负责人\n\n两年间 TiDB 有了长足的进步,《TiDB 6.x in Action》也为大家带来全面更新的 TiDB 知识。感谢社区伙伴们的贡献,相信 TiDB in Action 会为大家更好地使用和理解 TiDB 带来巨大的帮助。\n\n**杨攀**,TDengine 开发者关系和生态 VP\n\n24 小时分布式成书的《TiDB 4.0 in Action》在当年给大家留下了深刻的印象。开放协作是这个世界上最酷的生产力,《TiDB 6.x in Action》将再次向我们展现开源和开源社区的力量。也希望 PingCAP 代表的头部开源厂商不断去探索开源协作的新形式、新边界,推动开源社区不断发展壮大。\n\n### 凝聚社区集体智慧的 6.x 实践汇总\n\n《TiDB 6.x in Action》托管在 GitHub 上,活动之初就公布了电子书大纲,整个创作过程耗时 3 个月,历经新版本试用、文章撰写、文章 Review、文章修改、提交 PR 等环节,每个环节都凝聚了参与者非常多的精力和付出,给所有参与者们点赞!\n\n\n上图为所有报名小伙伴的社区昵称词云 \n\n电子书最终共收录 46 篇文章,这些来自社区小伙伴的文章,都是用户在自己的环境里使用 TiDB 6.x 的实践总结,每一篇文章都图文并茂,有实际操作的依据,并且在试用过程中遇到的问题及解决方案也都被总结到了文章中。\n\n此外,由社区活跃成员和 PingCAP 产研小伙伴们组成的 Reviewer 小组,历时 2 个多月,对每篇文章都进行了至少 2 遍的深度审核,在文章正确性和可读性方面提出了很多宝贵建议,保证了最终入选文章的准确性和高质量。感谢所有参与 Review 的老师们,感谢所有参与到本次活动每个环节中的小伙伴们。\n\n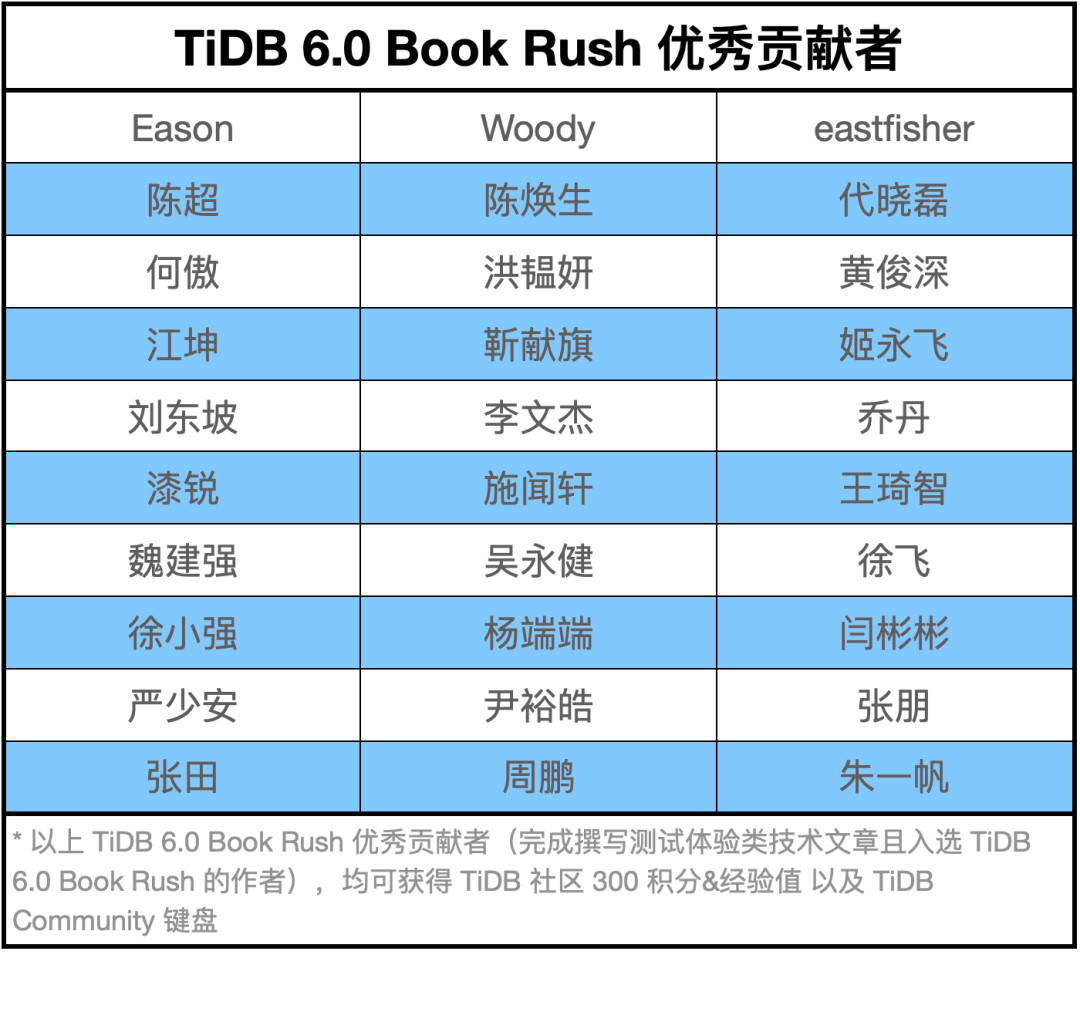\n\n\n\n\n\n\n## 欢迎 TiDBer 们分享 & 持续指正\n\n《TiDB 6.x in Action》所有文章均经过社区多次内容 review,但是我们相信它肯定还存在优化的空间。TiDBer 们在阅读文章的时候,如果发现存在任何语病、或是觉得需要修改的地方、或是觉得描述不够准备的部分,非常欢迎 TiDBer 们以 PR 的形式进行贡献指正。\n\n- 参与方式:GitHub 中 PR 形式提交本次 Book Rush 你觉得需要修改的内容, 并在 **PR 提交正文处注明社区昵称**,截图在活动帖()中回复即可,例如:\n\n\n\n- 活动奖励:每个 PR 合入,获得 100 积分&经验值,最高奖励 500 积分&经验值(此活动长期有效,没有截止时间)\n\n再次感谢 TiDBer 们对 TiDB 6.0 Book Rush 的支持,期待下次共创。","date":"2022-07-25","author":"PingCAP","fillInMethod":"writeDirectly","customUrl":"book-rush-tidb-6.x-in-action-release","file":null,"relatedBlogs":[{"relatedBlog":{"body":"> 本文源自“TiDB 6.0 Book Rush” 投稿。作者:h5n1,TiDB 爱好者,目前就职于联通软件研究院。\n\n## 前言\n\nTiDB 作为一个分布式数据库,计算节点 tidb server 和存储节点 tikv/tiflash server 有着近乎线性的扩展能力,当资源不足时直接在线扩容即可。但作为整个集群大脑的 PD 节点因为只有 leader 提供服务,不能像其他组件一样通过扩展节点而提高处理能力。\n过往版本 TSO 分配的主要问题: \n\n1. TSO 分配由 PD Leader 节点提供,大量请求下会导致 Leader 节点 CPU 利用率增高,影响事务延迟。\n2. PD Follower 节点基本处于空闲状态,系统资源利用率较低。\n3. TiDB 跨数据中心访问 PD Leader 时,数据中心间的延迟导致事务延迟增加。\n\n为提升 TSO 的处理性能针对部分场景 TiDB 引入了 TSO Follower Proxy、RC Read TSO 优化、Local TSO 等特性,通过扩展 PD 处理能力和减少 TSO 请求的方式,提升整体吞吐量,降低事务延迟。\n\n## TSO\n\nTSO 是一个单调递增的时间戳,由 PD leader 分配。TiDB 在事务开始时会获取 TSO 作为 start_ts、提交时获取 TSO 作为 commit_ts,依靠 TSO 实现事务的 MVCC。TSO 为 64 位的整型数值,由物理部分和逻辑部分组成,高 48 位为物理部分是 unixtime 的毫秒时间,低 18 位为逻辑部分是一个数值计数器,理论上每秒可产生 262144000(即 2 ^ 18 * 1000)个 TSO。\n\n\n\n为保证性能 PD 并不会每次为一个请求生成一个 TSO,而是会预先申请一个可分配的时间窗口,时间窗口是当前时间和当前时间+3 秒后的 TSO,并保存在 etcd 内,之后便可以从窗口中分配 TSO。每隔一定时间就会触发更新时间窗口。当 PD 重启或 leader 切换后会从 etcd 内获取保存的最大 TSO 开始分配,以保证 TSO 的连续递增。\n\n## Follower Proxy\n\n默认情况下 TSO 请求由 PD leader 处理,TiDB 内部通过 PD Client 向 PD leader 发送请求获取 TSO,PD client 并不会将收到的请求立刻发送给 PD leader ,而将同一时刻收到的所有请求打包发送给 PD leader,然后由 PD leader 返回一批 TSO。由于仅有 leader 提供服务,tidb server 数量较多时会有较多的 PD Client 和 PD Leader 建立连接,导致切换处理连接请求时 CPU 消耗较高。同时 follower 节点仅通过 raft 同步数据和提供选举等功能,基本处于空闲状态。 \n\n在 5.3.0 版本引入 TSO Follower Proxy 功能,当开启后 TiDB 的 PD Client 会随机选择一个 PD 节点(包括 leader 和 follower)发送 TSO 请求,PD Follower 会作为一个代理服务将收到的一批请求按照默认情况下 PD Client 处理 TSO 方式打包发送给 leader 处理,以进一步减少 PD Client 和 PD Leader 的交互次数以及 PD leader 的连接数,以此降低 leader 的 CPU 负载。 \n\n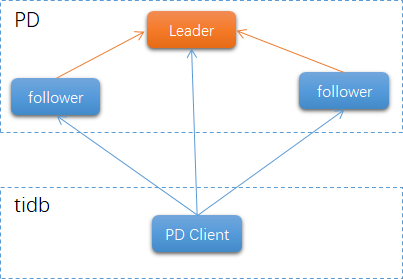\n\n通过设置全局变量 tidb_enable_tso_follower_proxy 为 true 即可开启 PD follower 的 TSO 代理功能,该功能适用于 tidb server 数量较多并发请求很高,PD leader 因高压力的 TSO 请求而达到 CPU 瓶颈,导致 TSO RPC 请求的延迟较高的场景。\n\n## RC Read TSO 优化\n\nRead-Commited 隔离级别需要在悲观事务模式下,在悲观事务中每个 SQL 执行时会从 PD 获取 TSO (for_update_ts) 用于一致性读、冲突检测等,每个 SQL 相当于一个 Snapshot-Isolation 的’小事务’,相比乐观事务模式悲观事务产生的 TSO 请求会更多,在整个事务期间如果能在不破坏事务一致性和隔离性的情况下减少 tso 请求次数,就能够降低 PD 的负载和事务延迟,从而提升整体性能。 \n\n6.0 版本中对 RC 事务中的 SELECT 语句 TSO 请求做了优化,使用一种乐观方式获取 TSO ,仅当遇到新版本后才会获取最新的 TSO 读取数据,通过减少读操作从 PD 获取 TSO 的请求次数,从而降低查询延迟,提升读写冲突较小场景的 QPS。该特性由 tidb_rc_read_check_ts 变量控制,默认为 off,开启该功能设置为 on 即可。 \n\n优化后 select 语句处理基本过程如下: \n\n1. Select 语句执行时不从 PD 获取 TSO 作为 for_update_ts,而是使用上一个有效的 TSO 作为 for_update_ts(即为 read_ts)。如果是事务中的第一个语句则是 start_ts,否则是上一个 SQL 的 for_update_ts。\n2. 构建执行计划并执行,发送到 tikv 的数据读取请求(pointget、coprocessor)会带上 RcReadCheckTS 标志。\n3. 数据读取请求使用前面获得的 read_ts 做一致性读取,并将数据返回 tidb server。\n4. TiKV 会检查返回的数据是否有更新版本,如果有更新的版本则返回 WriteConflict 错误,否则返回数据后正常结束执行。\n5. 如果此时 tidb 还未向 client 发送数据则会从 PD 获取最新的 TSO 作为 for_update_ts 重新执行整个查询,否则会向 client 返回错误。 \n\n从上面的过程可以看出遇到新版本会导致 tidb server 使用正常的流程重新获取 TSO 和执行 SQL,在读写冲突的情况下会降低性能使得事务执行时间延长。如果已经有部分数据返回 client 的话会导致报错 SQL 执行失败,虽然通过增加 tidb_init_chunk_size 变量大小延迟 tikv 返回数据时间,可以降低一些上述错误发生的情况,但仍然不是一个根本解决方式。 \n\n## Local TSO\n\n在多数据中心场景下 PD leader 位于某个数据中心内,数据中心间的延迟会造成 TSO 请求延迟增加,如果能够在数据中心内完成 TSO 请求和分配则可以大大降低 TSO 请求延迟。基于此 TiDB 引入了 Local TSO (实验功能),PD 中设计 2 个 TSO allocator 角色:local tso allocator 和 global tso allocator,相应的事务也被分成了本地事务 local transaction 和全局事务 global transaction 两种。 \n\n### Local TSO\n\n当通过 enable-local-tso 启用后数据中心内的 PD 会选出一个节点作为 local tso allocator 用于分配 TSO,该节点作为 local tso 分配的 leader 角色(PD 角色仍为 follower)。当事务操作的数据仅涉及到本数据中心的数据时,则判断为本地事务,向本地 tso allocator 申请 local tso。 \n\n每个数据中心分配自己的 local tso,相互之间是独立的,为避免不同数据中心分配了相同的 TSO,PD 会设置 local tso 中的逻辑时间低几位做后缀,不同的数据中心使用不同的值,同时这些信息会持久化记录到 PD 内。\n\n### Global TSO\n\n当事务操作的数据涉及到其他数据中心时则为全局事务,此时需要向 PD leader 申请 global tso, PD leader 作为 global tso allocator。当未启用 local-tso 功能时,仍按原来的逻辑所有数据中的 TSO 请求由 PD leader 负责处理。 \n\n为保证 local tso 和 global tso 的线性增长,global tso allocator 和 local tso allocator 会进行 max_tso 同步: \n\n1. Global tso allocator 收集所有 local tso allocator 的最大 local tso。\n2. 从所有 local tso 中选出一个最大的 local tso 作为 max_tso 下发到 local allocator。\n3. 如果 max_tso 比自己的大则更新 TSO 为 max_tso,否则直接返回成功。\n\nLocal tso 的使用需要考虑不同的数据中心处理不同的业务,同时要结合 PlacementRules in SQL 将表根据业务规则按数据中心进行分布,同时可设置 txn_scope 变量为 local/global 用于人为控制获取 global tso 还是 local tso。 \n\n基本配置步骤(目前不支持 Local TSO 回退为 Global TSO 模式): \n\n1.PD、TiKV、TiDB server 均需要根据实际部署设置 label,为保证高可用每个 DC 的 PD 数量应>1。\n\n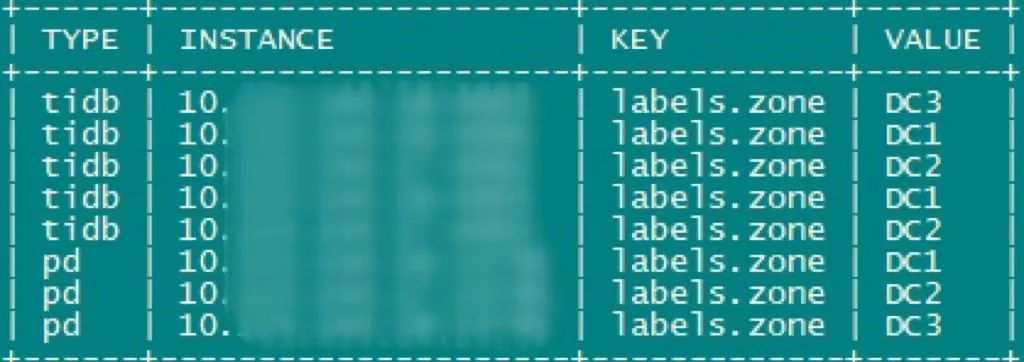\n\n\n\n2.开启库或表级 Placement Rules in SQL,根据地域和业务关系进行调度。 \n\n```\nCREATE PLACEMENT POLICY dc1_leader LEADER_CONSTRAINTS=\"DC1\" FOLLOWER_CONSTRAINTS=\"DC1,DC2,DC3\" FOLLOWERS=2;\nAlter table new_order PARTITION p0 PLACEMENT POLICY dc1_leaders\n```\n3.设置 PD 参数 enable-local-tso=on 使用 tiup reload 重启 PD 开启 Local TSO 功能。启用之后可通过 `pd-ctl -u pd_ip:pd_port member` 中 `tso_allocator_leaders` 项内容查看每个中心的 local tso allocator leader。\n\n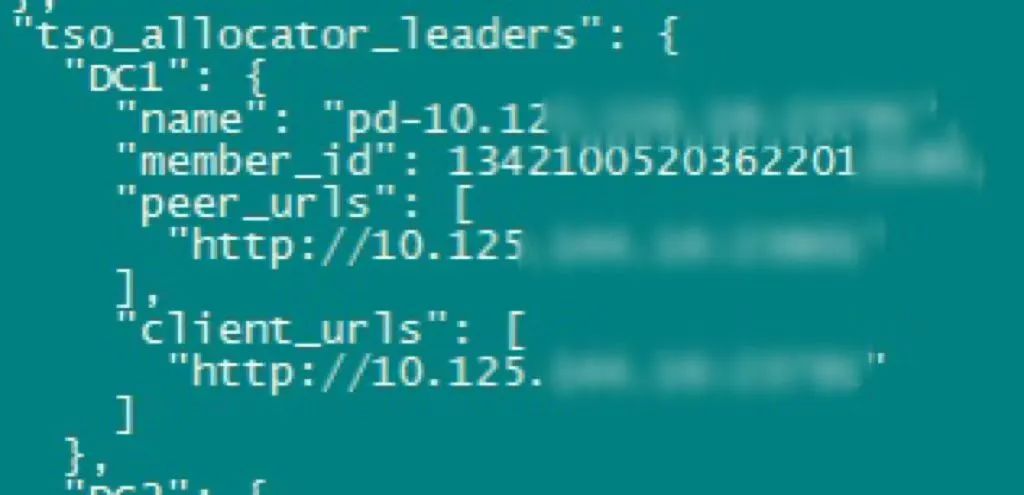\n\n\n## 测试\n\n### 测试环境\n\n\n\n### TSO Follower Proxy\n\n在 1024 线程下使用 sysbench 对 6 张 1 亿记录表在开启 TSO Follower Proxy 前后的 TPS 和平均延迟如下:\n\n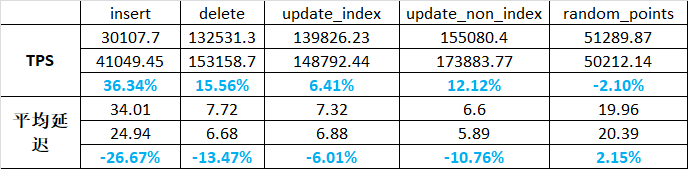\n\n测试期间 TSO Follower Proxy 关闭和开启时的 CPU 利用率: \n\n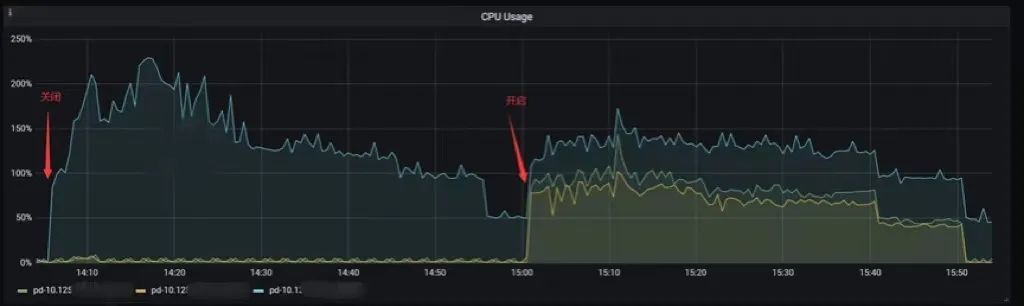\n\n### RC Read TSO\n\n使用 tiup-bench 测试不同线程下开启 tidb_rc_read_check_ts 前后的 TPCC,可以看到开启该功能后对 TPCC 有一定提升,但随着线程数增加冲突增多 TPCC 出现下降情况。\n\n\n\n通过 TiDB –> PD Client –> PD Client CMD OPS 监控可以看到 256 线程下开启 tidb_rc_read_check_ts 后 PD client 中等待 TSO 的次数明显降低。\n\n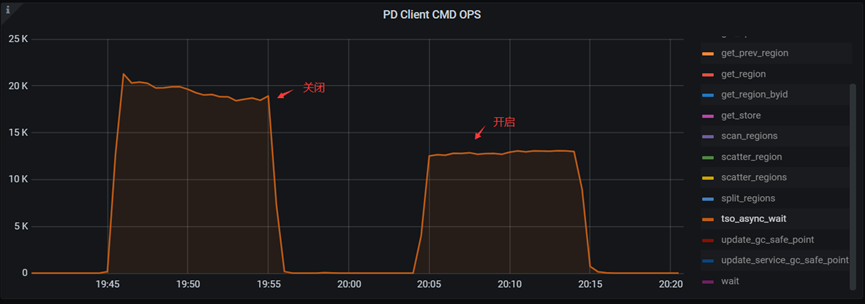\n\n### Local TSO\n\nLocal TSO 作为实验功能尚需完善,TPCC 测试中当开启该功能后出现大量报主键重复错误。\n\n\n## 总结\n\n为提升 TSO 的扩展性和效率,TiDB 进行了大量的优化工作,但这些优化有确定的场景,需要结合业务和实际情况考虑,否则盲目开启有可能会造成 QPS 降低、延迟增高的情况: \n\n1. 对于 Follower TSO Proxy 适合于由于 PD Leader CPU 繁忙导致的 TSO 获取延迟的场景,通过开启 Follower Proxy 后降低 leader 的压力。\n2. RC Read TSO 优化适合于读多写少的场景,如果数据冲突严重反而会造成性能下降。\n3. Local TSO 作为 TiDB 分布式授时方案从理论上能够解决因数据中心间的延迟造成的 TSO 延迟,不过目前实验功能尚有一些问题,将在后续版本不断改进。","author":"h5n1","category":4,"customUrl":"tidb-6.0-make-tso-more-efficient","fillInMethod":"writeDirectly","id":399,"summary":"TSO 是 TiDB 中一个单调递增的时间戳,由 PD leader 分配。TiDB 在事务开始时会获取 TSO 作为 start_ts、提交时获取 TSO 作为 commit_ts,依靠 TSO 实现事务的 MVCC。本文介绍了 TiDB 6.0 版本中对 TSO 分配优化的原理和验证。","tags":["TiDB"],"title":"TiDB 6.0:让 TSO 更高效丨TiDB Book Rush"}},{"relatedBlog":{"body":"> 本文源自“TiDB 6.0 Book Rush” 投稿。作者:啦啦啦啦啦,TiDB 老粉,目前就职于京东物流,社区资深用户。\n\n## 背景\n\n一般情况下使用 TiDB 单表大小为千万级别以上在业务中性能最优,但是在实际业务中总是会存在小表。例如配置表对写请求很少,而对读请求的性能的要求更高。TiDB 作为一个分布式数据库,大表的负载很容易利用分布式的特性分散到多台机器上,但当表的数据量不大,访问又特别频繁的情况下,数据通常会集中在 TiKV 的一个 Region 上,形成读热点,更容易造成性能瓶颈。 \n\nTiDB v6.0.0(DMR) 版本推出了缓存表的功能,第一次看到这个词的时候让我想到了 MySQL 的内存表。MySQL 内存表的表结构创建在磁盘上,数据存放在内存中。内存表的缺点很明显:当 MySQL 启动着的时候,表和数据都存在,当 MySQL 重启后,表结构存在,数据消失。TiDB 的缓存表不存在这个问题。从 asktug 论坛中看到很多小伙伴都很期待缓存表的表现,个人也对它的性能很期待,因此在测试环境中实际看看缓存表的性能如何。\n\n## 缓存表的使用场景\n\n以下部分内容来自官方文档,详情见[缓存表](https://docs.pingcap.com/zh/tidb/v6.0/cached-tables#%E7%BC%93%E5%AD%98%E8%A1%A8) \n\n> TiDB 缓存表功能适用于以下特点的表: \n\n- 表的数据量不大\n- 只读表,或者几乎很少修改\n- 表的访问很频繁,期望有更好的读性能\n\n关于第一点官方文档中提到缓存表的大小限制为包含索引在内的所有 key-value 记录的总大小不能超过 64 MB。实际测试使用 Sysbench 生成下文中表结构的表,将数据量从 20w 提高到 30w 后就无法将普通表转换为缓存表,因此生产环境中实际使用缓存表的场景应该最多不超过几十万级别的数据量。关于缓存表对包含读写操作方面的性能,使用多种不同的读写请求比例进行了测试,相较普通表均没有达到更好的性能表现。这是因为为了读取数据的一致性,在缓存表上执行修改操作后,租约时间内写操作会被阻塞,最长可能出现 [tidb_table_cache_lease](https://docs.pingcap.com/zh/tidb/v6.0/system-variables#tidb_table_cache_lease%E4%BB%8E-v600-%E7%89%88%E6%9C%AC%E5%BC%80%E5%A7%8B%E5%BC%95%E5%85%A5) 变量值时长的等待,会导致 QPS 降低。因此缓存表更适合只读表,或者几乎很少修改的场景。\n\n缓存表把整张表的数据从 TiKV 加载到 TiDB Server 中,查询时可以不通过访问 TiKV 直接从 TiDB Server 的缓存中读取,节省了磁盘 IO 和网络带宽。使用普通表查询时,返回的数据量越多索引的效率可能越低,直到和全表扫描的代价接近优化器可能会直接选择全表扫描。缓存表本身数据都在 TiDB Server 的内存中,可以避免磁盘 IO,因此查询效率也会更高。以配置表为例,当业务重启的瞬间,全部业务连接一起加载配置,会造成较高的数据库读延迟。如果使用了缓存表,读请求可以直接从内存中读取数据,可以有效降低读延迟。在金融场景中,业务通常会同时涉及订单表和汇率表。汇率表通常不大,表结构很少发生变化因此几乎不会有 DDL,加上每天只更新一次,也非常适合使用缓存表。其他业务场景例如银行分行或者网点信息表,物流行业的城市、仓号库房号表,电商行业的地区、品类相关的字典表等等,对于这种很少新增记录项的表都是缓存表的典型使用场景。\n\n## 测试环境\n\n### 1. 硬件配置及集群拓扑规划\n\n使用 2 台云主机,硬件配置为 4C 16G 100G 普通 SSD 硬盘。 \n\n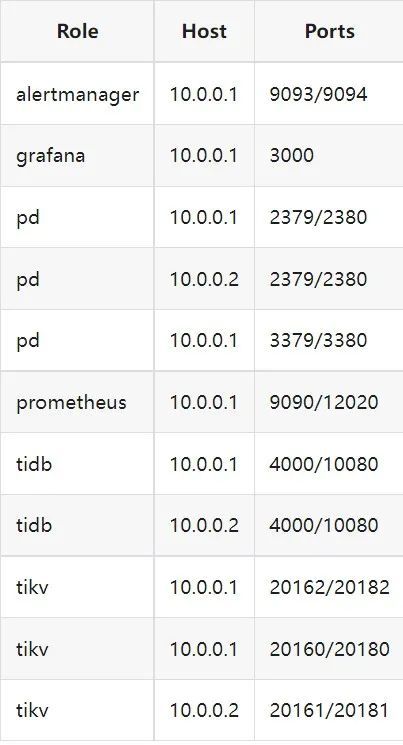\n\n\n### 2. 软件配置\n\n\n\n\n### 3. 参数配置\n\n```\nserver_configs:\ntidb:\nlog.slow-threshold: 300\nnew_collations_enabled_on_first_bootstrap: true\n\ntikv:\nreadpool.coprocessor.use-unified-pool: true\nreadpool.storage.use-unified-pool: false\npd:\nreplication.enable-placement-rules: true\n replication.location-labels:\n - host\n```\n\n由于硬件条件受限,只有 2 台普通性能的云主机混合部署的集群(实际上和单机部署也差不多了)。单机 CPU 核数较少且 TiDB Server 没有做负载均衡所以并发无法调整太高。以下测试均使用一个 TiDB Server 节点进行压测,因此不用特别关注本次测试的测试数据,可能会跟其他测试结果有所出入,不代表最佳性能实践和部署,测试结果仅限参考。\n\n\n## 性能测试\n\nSysbench 生成的表结构 \n\n```\nCREATE TABLE sbtest1 (\nid int(11) NOT NULL AUTO_INCREMENT,\nk int(11) NOT NULL DEFAULT '0',\nc char(120) NOT NULL DEFAULT '',\npad char(60) NOT NULL DEFAULT '',\nPRIMARY KEY (id),\nKEY k_1 (k)\n) ENGINE = InnoDB CHARSET = utf8mb4 COLLATE = utf8mb4_bin AUTO_INCREMENT = 1\n```\n\n### 读性能测试\n\n**测试主要参数** \n\n**oltp_point_select** 主键查询测试(点查,条件为唯一索引列) \n\n主要 SQL 语句: \n\n`SELECT c FROM sbtest1 WHERE id=?` \n\n**select_random_points** 随机多个查询(主键列的 select in 操作) \n\n主要 SQL 语句: \n\n`SELECT id, k, c, pad FROM sbtest1 WHERE k IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)` \n\n**select_random_ranges** 随机范围查询(主键列的 select between and 操作) \n\n主要 SQL 语句: \n\n`SELECT count(k) FROM sbtest1 WHERE k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ?` \n\n**oltp_read_only** 只读操作(包含聚合、去重等) \n\n主要 SQL 语句: \n\n```\nSELECT c FROM sbtest1 WHERE id=?\nSELECT SUM(k) FROM sbtest1 WHERE id BETWEEN ? AND ?\nSELECT c FROM sbtest1 WHERE id BETWEEN ? AND ? ORDER BY c\nSELECT DISTINCT c FROM sbtest1 WHERE id BETWEEN ? AND ? ORDER BY c\n```\n\n**Sysbench 测试命令示例**\n\n```\nsysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \\\n--threads=8 --report-interval=10 --db-driver=mysql oltp_point_select --tables=1 --table-size=5000 run\n\nsysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \\\n--threads=8 --report-interval=10 --db-driver=mysql oltp_read_only --tables=1 --table-size=5000 run\n\nsysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \\\n--threads=8 --report-interval=10 --db-driver=mysql select_random_points --tables=1 --table-size=5000 run\n\nsysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \\\n--threads=8 --report-interval=10 --db-driver=mysql select_random_ranges --tables=1 --table-size=5000 run\n```\n\n#### 一、使用普通表\n\n**1.单表数据量 5000,测试 QPS** \n\n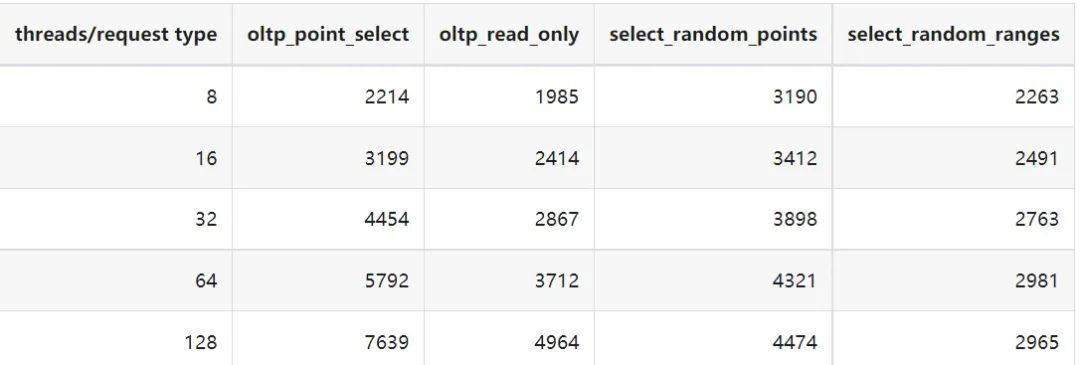\n\n\n**2.单表数据量 50000,测试 QPS**\n\n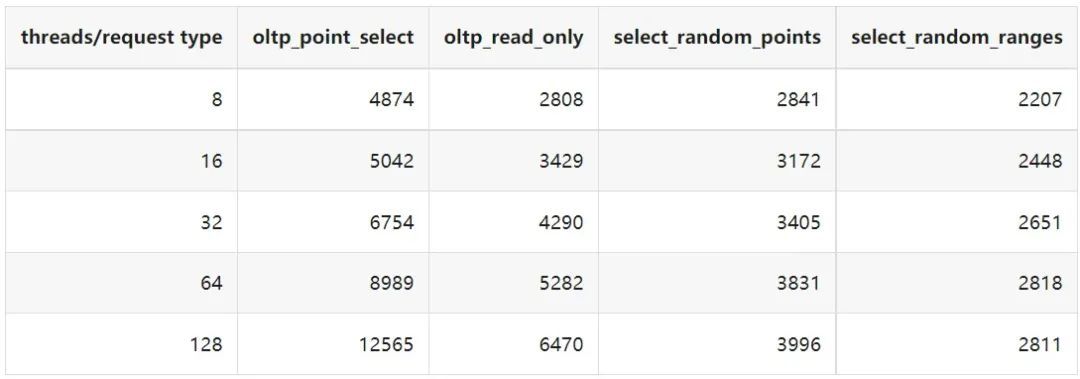\n\n\n#### 二、使用缓存表\n\n**1.单表数据量 5000,测试 QPS**\n\n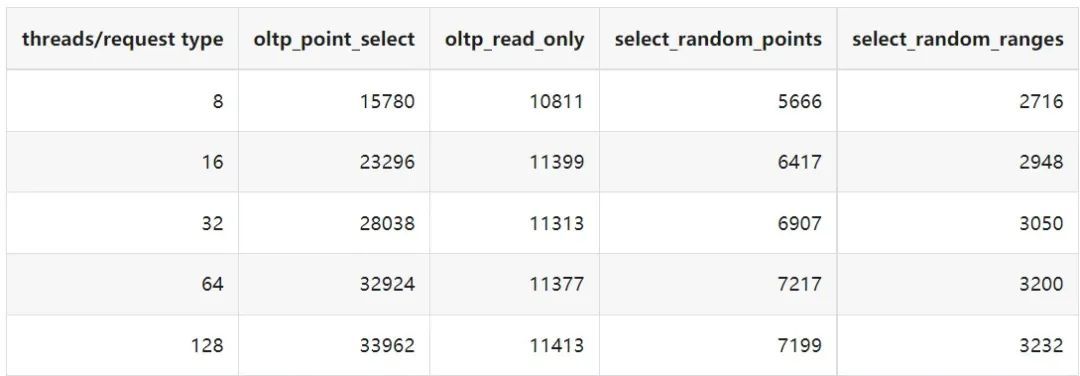\n\n\n**2.单表数据量 50000,测试 QPS**\n\n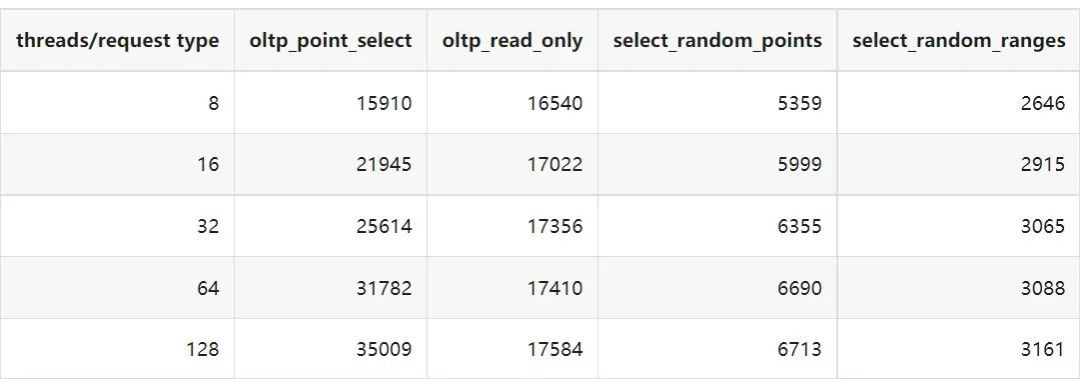\n\n\n#### 三、性能对比\n\n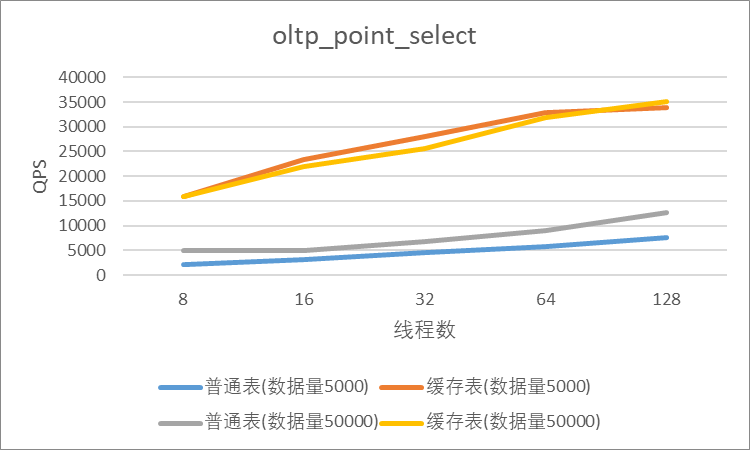\n\n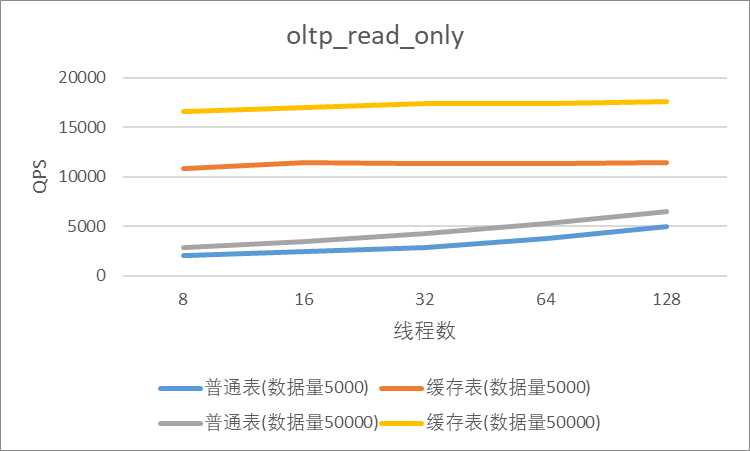\n\n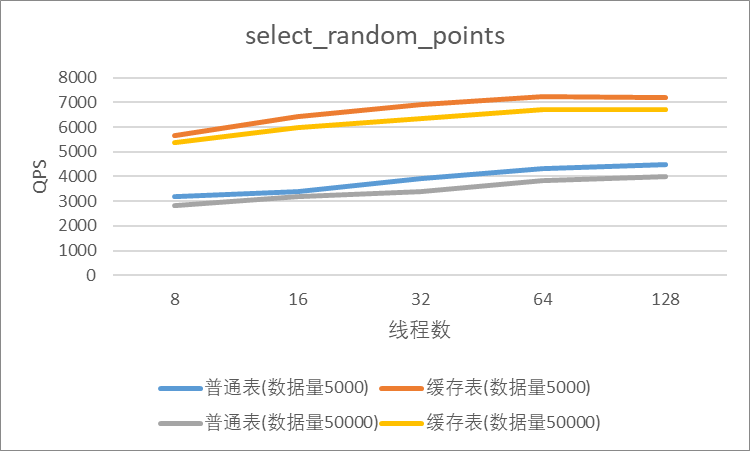\n\n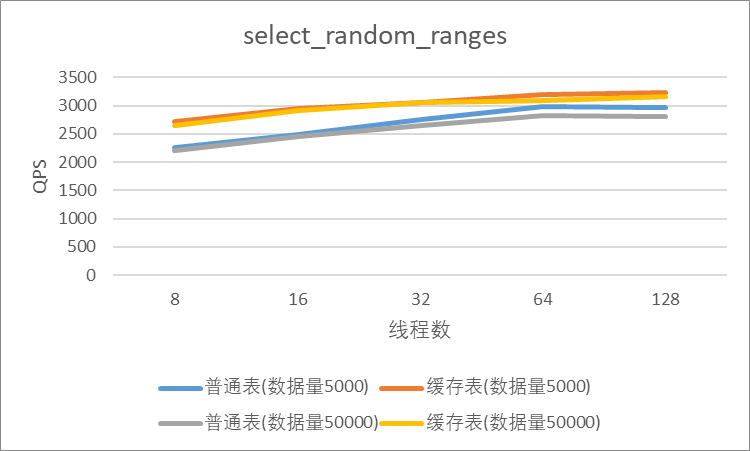\n\n\n### 读写混合性能测试\n\n**测试主要场景参数** \n\noltp_read_write 表示混合读写 \n\npoint_selects(每个事务里点查的数量) \n\ndelete_inserts(每个事务里插入/删除组合的数量) \n\n主要 SQL 语句:\n \n```\nINSERT INTO sbtest1 (id, k, c, pad) VALUES (?, ?, ?, ?)\nDELETE FROM sbtest1 WHERE id=?\nSELECT c FROM sbtest1 WHERE id=?\n```\n\n本次测试通过单个事务中请求类型的数量 --delete_inserts 固定为 10 且调整 --point_selects 参数的值来模拟不同读写比例下的性能差异,其余请求参数使用默认值,具体命令可参考下面 Sysbench 测试命令示例。\n\n**Sysbench 测试命令示例** \n\n`sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 --threads=8 --report-interval=10 --db-driver=mysql oltp_read_write --tables=1 --table-size=5000 --point_selects=10 --non_index_updates=0 --delete_inserts=10 --index_updates=0 run`\n\n#### 一、使用普通表\n\n**1.单表数据量 5000,测试 QPS** \n\n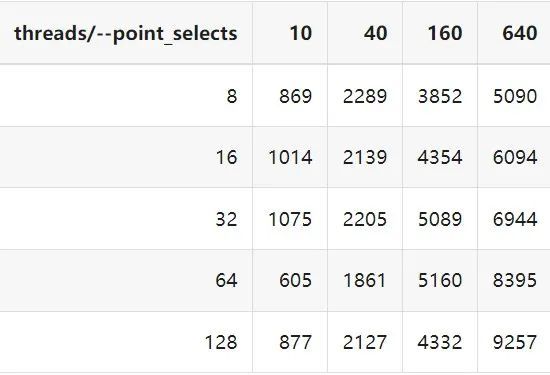\n\n\n**2.单表数据量 50000,测试 QPS** \n\n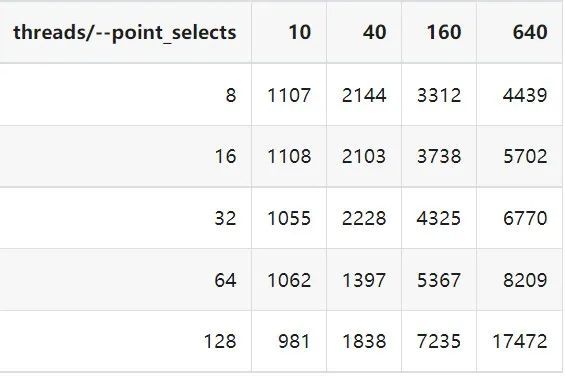\n\n\n#### 二、使用缓存表\n\n**1.单表数据量 5000,测试 QPS** \n\n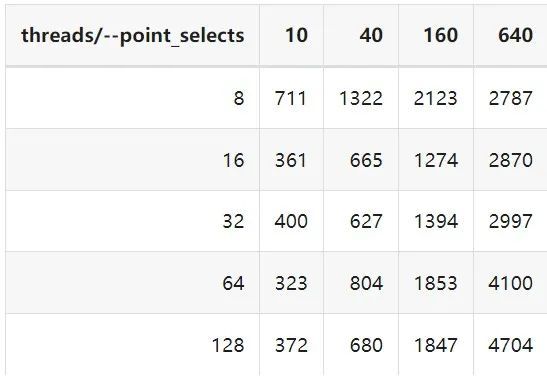\n\n\n**2.单表数据量 50000,测试 QPS**\n\n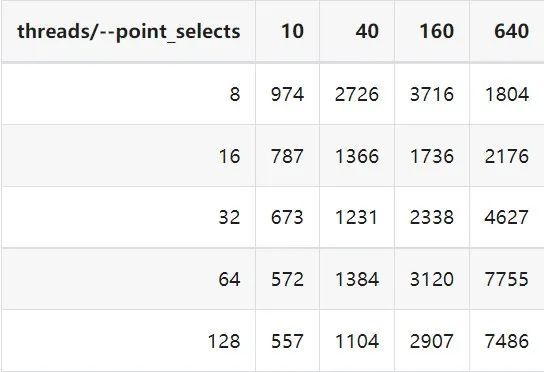\n\n\n#### 三、性能对比\n\n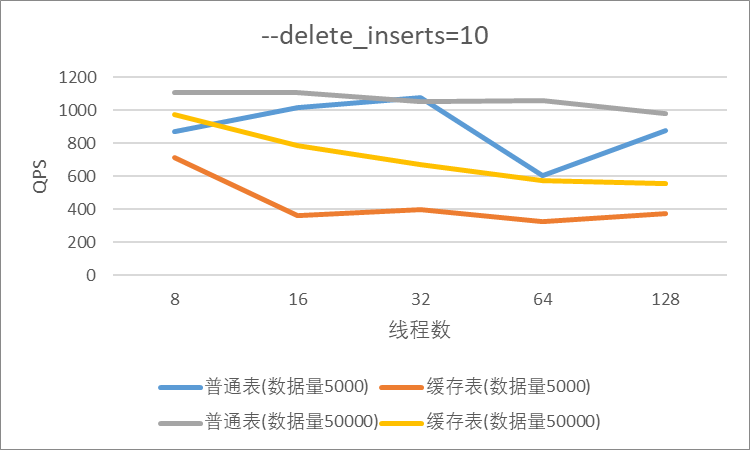\n\n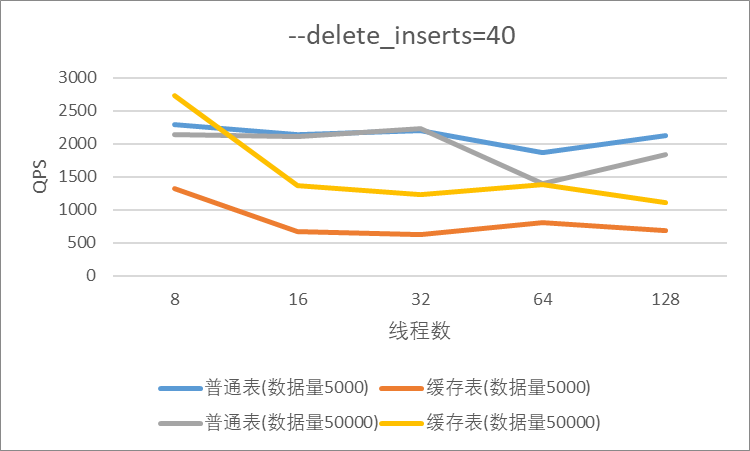\n\n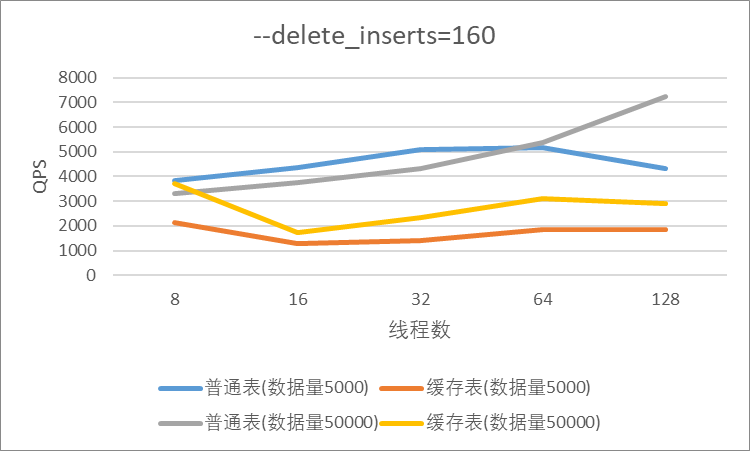\n\n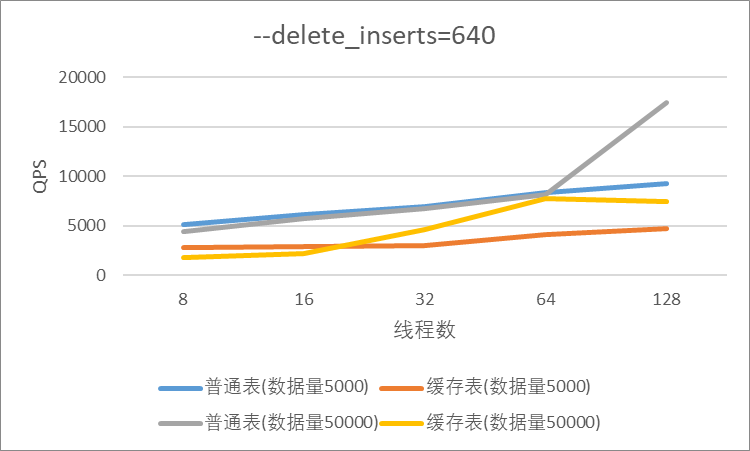\n\n\n## 遇到的问题\n\n- 尝试将 30w 数据的表改为缓存表时报错 。ERROR 8242 (HY000): 'table too large' is unsupported on cache tables。 \n\n目前 TiDB 对于每张缓存表的大小限制为 64 MB,因此太大的表无法缓存在内存中。另外,缓存表无法执行普通的 DDL 语句。若要对缓存表执行 DDL 语句,需要先使用 ALTER TABLE xxx NOCACHE 语句去掉缓存属性,将缓存表设回普通表后,才能对其执行其他 DDL 语句。\n\n- 测试过程中缓存表性能出现了不稳定的情况,有些时候缓存表反而比普通表读取性能差,使用 trace 语句(TRACE SELECT * FROM sbtest1;)查看发现返回结果中出现了regionRequest.SendReqCtx,说明 TiDB 尚未将所有数据加载到内存中,多次尝试均未加载完成。把 tidb_table_cache_lease 调整为 10 后没有出现该问题。\n\n在 asktug 中向研发大佬提出了这个问题得到了解答。根据 中的描述,当机器负载较重时,load table 需要 3s 以上 ,但是默认的 tidb_table_cache_lease 是 3s, 表示加载的数据是立即过时的,因此需要重新加载,并且该过程永远重复。导致了浪费了大量的 CPU 资源并且降低了 QPS。目前可以将 tidb_table_cache_lease 的值调大来解决,该问题在 master 分支中已经解决,后续版本应该不会出现。 \n\n- 根据测试结果,写入较为频繁的情况下缓存表的性能是比较差的。在包含写请求的测试中,缓存表相较于普通表的性能几乎都大幅下降。\n\n在 lease 过期之前,无法对数据执行修改操作。为了保证数据一致性,修改操作必须等待 lease 过期,所以会出现写入延迟。例如 tidb_table_cache_lease 为 10 时,写入可能会出现较大的延迟。因此写入比较频繁或者对写入延迟要求很高的业务不建议使用缓存表。\n\n## 测试总结\n\n### 读性能\n\n单表 5000,缓存表相比普通表提升的百分比\n\n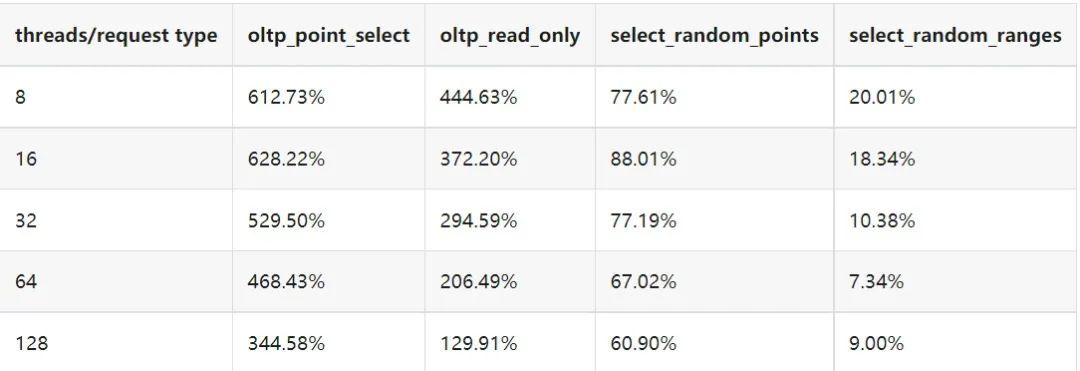\n\n单表 50000,缓存表相比普通表提升的百分比\n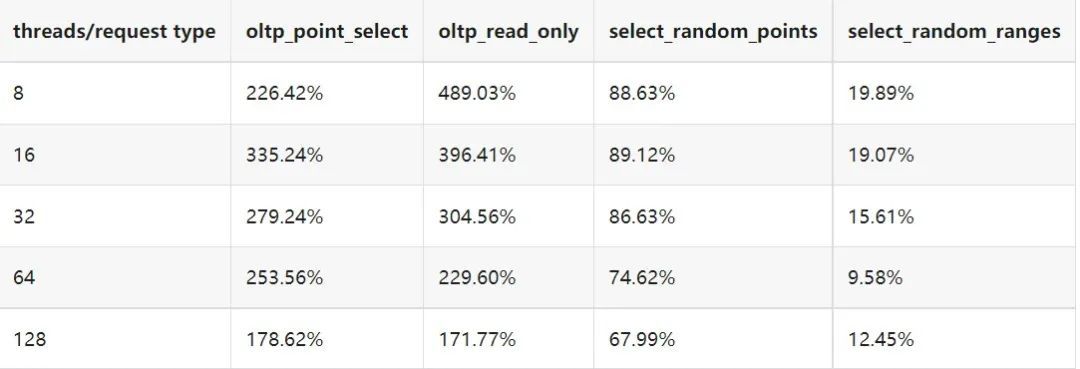\n\n### 读写混合\n\n单表 5000,缓存表相比普通表提升的百分比(负增长符合预期) \n\n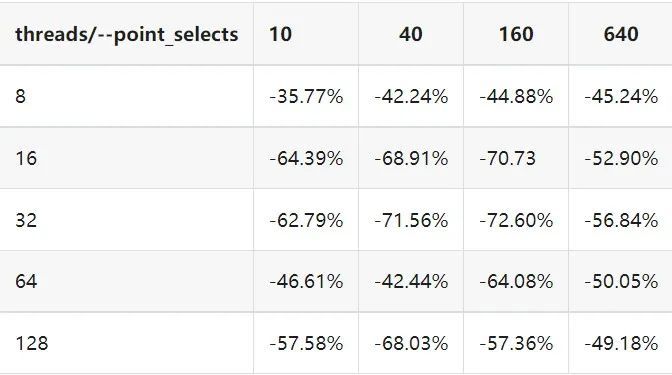\n\n单表 50000,缓存表相比普通表提升的百分比(负增长符合预期) \n\n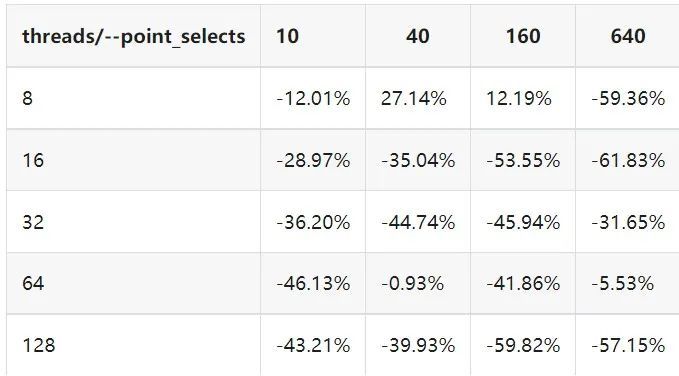\n\n\n结果显示,相比于普通表,缓存表在 oltp_point_select、oltp_read_only、select_random_points、select_random_ranges 几种只读的场景下性能有非常大的提升,但在包含写请求的测试中无法提供更好的性能。它的机制决定了使用场景目前仅限于表的数据量不大的只读表,或者几乎很少修改的小表。综上,虽然缓存表目前的使用场景相对比较单一,但是在合适的场景下确实是一个解决了业务痛点的好功能,也期待在后续的版本中能有更高的稳定性和更优秀的性能表现。\n\n","author":"啦啦啦啦啦","category":4,"customUrl":"first-try-of-cached-table-in-tidb-6.0","fillInMethod":"writeDirectly","id":400,"summary":"TiDB v6.0.0 (DMR) 版本推出了缓存表的功能,以应对很少新增记录项的小表上频繁的读请求。在金融场景的订单表、汇率表,银行分行或者网点信息表,物流行业的城市、仓号库房号表,电商行业的地区、品类相关的字典表等等场景下能够很大程度地提高效率。本文通过测试验证了 TiDB 缓存表的性能表现。","tags":["TiDB"],"title":"TiDB v6.0.0 (DMR) :缓存表初试丨TiDB Book Rush"}},{"relatedBlog":{"body":"> 本文源自“TiDB 6.0 Book Rush” 投稿,作者吴永健。\n\n## 简介\n\nTiDB 6.0 版本正式提供了基于 SQL 接口的[数据放置框架](https://pingcap.com/zh/blog/what-are-placement-rules-in-sql)(Placement Rules in SQL),特性用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。通过该功能,用户可以将表和分区指定部署至不同的地域、机房、机柜、主机。适用场景包括低成本优化数据高可用策略、保证本地的数据副本可用于本地 Stale Read 读取、遵守数据本地要求等。它支持针对任意数据提供副本数、角色类型、放置位置等维度的灵活调度管理能力,这使得在多业务共享集群、跨 AZ 部署等场景下,TiDB 得以提供更灵活的数据管理能力,满足多样的业务诉求。\n\n该功能可以实现以下业务场景:\n\n- 合并多个不同业务的数据库,大幅减少数据库常规运维管理的成本;\n\n- 增加重要数据的副本数,提高业务可用性和数据可靠性;\n\n- 将最新数据存入 SSD,历史数据存入 HDD,降低归档数据存储成本;\n\n- 把热点数据的 leader 放到高性能的 TiKV 实例上;\n\n- 将冷数据分离到不同的存储中以提高可用性。\n\n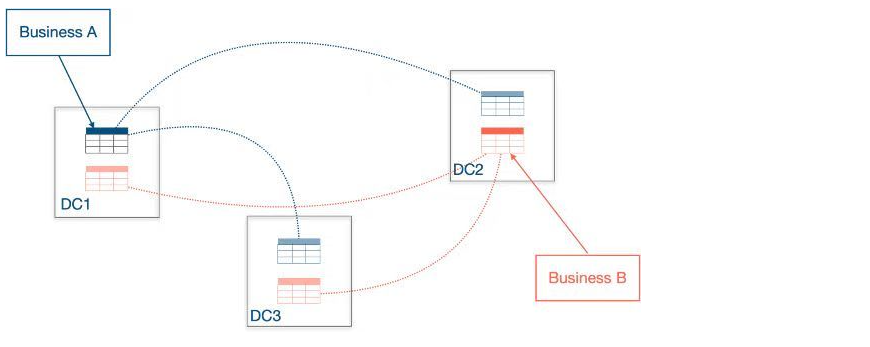\n\n使用放置规则时有 2 种方式\n\n(1) 直接放置\n\n直接放置是指在 create table 时或使用 alter table 方式直接在表的 DDL 语句中使用放置选项\n\n`create table jian(id int) primary_region='bj' folllowers=4`\n\n(2) 放置策略\n\n使用放置策略时首先通过 create placement policy 建立放置策略,然后在 create table 或 alter table 中直接指定放置策略。\n\n```\ncreate placement policy location_policy primary_region='bj' folllowers=4;\nalter table jian placement policy location_policy;\n```\n\n使用时:创建放置策略会使 placement policy 更加易于管理,通过修改放置策略可以直接更新所有使用该策略的对象。另一方面对于 create table 时使用和 alter table 时指定,这里也建议大家能注意以下两点:\n\n1. create 方式建议在项目初期的库表结构设计节点进行设定,那么在初始话项目数据库的时候可以一次成型。否则需要将整个表进行 recreate,此处就需要考虑历史数据的问题。\n\n2. alter 方式由于是使用 ALTER 进行修改当表数据量大的时候可能会产生大量数据 peer 的移动,可能会消耗一定的资源,建议在业务低峰进行,但是也较好地弥补了一些即存表没有进行放置规则的设定后期需要添加,或者版本升级后需要使用新特性的问题。\n\n### Placement Rules in SQL 的应用场景猜想\n\n由于 Placement Rules in SQL 的灵活性,在使用时可以“因地适宜”。以下是几个可以考虑的场景:\n\n1. 当采取两地三中心或跨地域数据中心部署的时候,由于 TiDB 是无状态的应用那么可以利用就近原则将业务接入点进行分块,同时对于数据的分布也可以采用同样的方式。使数据的存放可以达到“本地数据本地访问”,即所有的数据存储,管理在本地区内完成。减少了数据跨地区复制延迟,降低流量成本。\n\n2. 当系统 IO 存在某些瓶颈时可以考虑将某些 TiKV 节点的数据盘更换为 SSD,之后经过 Placement Rules 动态调整数据副本的存放策略,提高数据库的 IO 性能。对于一些历史及记录类的数据可以选择存放在一些主要由普通硬盘构成的 TiKV 节点上。使硬件资源的配置得到充分的利用,而又不铺张浪费。\n\n3. 同时也考虑当进行硬件更换时可以使用 Placement Rules 对数据分布进行调整以减小 TiKV 节点下线时的 peer 移动所需要的时间,因为通过 Placement Rules 可以将数据移动的动作提前进行分散在平时的小维护中。\n\n4. 由于数据的重要程度不同对于以往的副本设置可能更偏向于全局,引入 Placement Rules in SQL 后对于数据的副本数就可以进行灵活的限定,对高要求的数据表进行多副本设置,对于不太紧要的表尽量的减小副本数,在保证数据的安全性的情况下又可以节约存储资源。\n\n5. 如果业务采用了分库的模式为了减少运维成本,那么也可以考虑进行数据库整合,将分散的 MySQL 实例迁移到一个 TiDB 集群中以多 schema 的方式存在,同时根据 Placement Rules 原始业务数据库的数据存放节点仍然可以放置在原来的硬件节点上,但是逻辑上由于整合到了一个数据库集群中升级、打补丁、备份计划、扩缩容等日常运维管理频率可以大幅缩减,降低管理负担提升效率。\n\n6. 对于经典的热点问题在 Placement Rules in SQL 也添加了更多的解决方案,通过 Placement Rules in SQL 也可以进行热点表的分布调整,而且也更加的方便与安全。虽然不能精确到 Region 的级别,但是在表的粒度上也多提供了一种处理方法。\n\n下面我们来详细看看 placement policy 的使用方法:\n\n当前 TiKV 节点以及集群的信息如下:\n```\nID Role Host Ports OS/Arch Status Data Dir Deploy Dir\n\n\\-- ---- ---- ----- ------- ------ -------- ----------\n\n192.168.135.148:9093 alertmanager 192.168.135.148 9093/9094 linux/x86_64 Up /tidb-data/alertmanager-9093 /tidb-deploy/alertmanager-9093\n\n192.168.135.148:3000 grafana 192.168.135.148 3000 linux/x86_64 Up - /tidb-deploy/grafana-3000\n\n192.168.135.148:2379 pd 192.168.135.148 2379/2380 linux/x86_64 Up|L|UI /tidb-data/pd-2379 /tidb-deploy/pd-2379\n\n192.168.135.148:9090 prometheus 192.168.135.148 9090/12020 linux/x86_64 Up /tidb-data/prometheus-9090 /tidb-deploy/prometheus-9090\n\n192.168.135.148:4000 tidb 192.168.135.148 4000/10080 linux/x86_64 Up - /tidb-deploy/tidb-4000\n\n192.168.135.148:20160 tikv 192.168.135.148 20160/20180 linux/x86_64 Up /tidb-data/tikv-20160 /tidb-deploy/tikv-20160\n\n192.168.135.148:20161 tikv 192.168.135.148 20161/20181 linux/x86_64 Up /tidb-data/tikv-20161 /tidb-deploy/tikv-20161\n\n192.168.135.148:20162 tikv 192.168.135.148 20162/20182 linux/x86_64 Up /tidb-data/tikv-20162 /tidb-deploy/tikv-20162\n```\n\n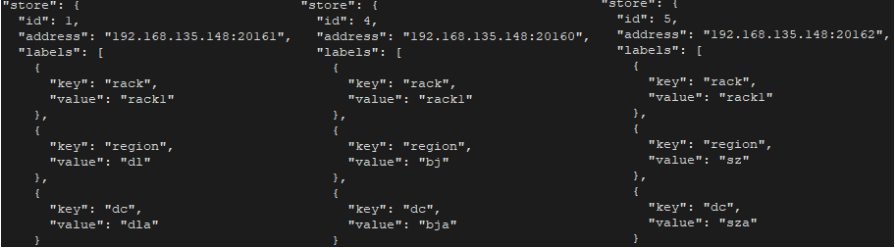\n\n这里有一点需要大家注意一下:**默认的 PLACEMENT POLICY 是需要以 region 来作为区分标签的,所以在创建 TiKV 的时候这里需要明确的指定 TiKV 的 region 的标签,不然的话在show placement labels 时是无法看到 region lable 的。这里可以参照[官方文档](https://docs.pingcap.com/zh/tidb/stable/placement-rules-in-sql)的建议**。\n\n## PLACEMENT RULES 的使用\n\n### 创建 PLACEMENT POLICY,并指定 PLACEMENT POLICY,定制其副本放置的位置\n\n这里创建一个 PLACEMENT POLICY 使其 PRIMARY_REGION 放置在 region lable 为 bj 的 tikv 节点上,其余副本放置在 region lable 为 dl,sz 的 tikv 节点上\n\n注意:**primary region 必须包含在 region 的定义中**\n\n**此处的 Raft leader 在 4 号 store 上,看之前开头的环境信息可以验证 PLACEMENT POLICY 已经生效**\n\n```\n(root\\@127.0.0.1) \\[test] 12:00:14> CREATE PLACEMENT POLICY jianplacementpolicy PRIMARY_REGION=\"bj\" REGIONS=\"bj,dl,sz\";\n\nQuery OK, 0 rows affected (0.10 sec)\n\n(root\\@127.0.0.1) \\[test] 12:00:32> CREATE TABLE jian1 (id INT) PLACEMENT POLICY=jianplacementpolicy;\n\nQuery OK, 0 rows affected (0.10 sec)\n\n(root\\@127.0.0.1) \\[test] 12:03:36> show table jian1 regions\\G\n\nREGION_ID: 135\n\nSTART_KEY: t_68\\_\n\nEND_KEY: t_69\\_\n\nLEADER_ID: 137\n\nLEADER_STORE_ID: 4 这里可以看到store_id是4 \n\nPEERS: 136, 137, 138\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 39\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.00 sec)\n```\n\n### 创建表不指定 PLACEMENT POLICY,之后修改 PLACEMENT POLICY 定制其副本放置的位置\n\n**leader 的 store 节点由原来的 1 变为了 4,看之前开头的环境信息可以验证 PLACEMENT POLICY 已经生效,可使用这个特性来修改表的 leader 节点或者当有热点问题时也可以变相的通过这种方式去修改频繁访问的表的 leader 所在的 tikv 的节点位置**\n\n```\n(root\\@127.0.0.1) \\[test] 12:03:39> create table jian2(id int);\n\nQuery OK, 0 rows affected (0.10 sec)\n\n(root\\@127.0.0.1) \\[test] 12:05:14> show table jian2 regions\\G\n\n\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\* 1. row \\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\n\nREGION_ID: 2\n\nSTART_KEY: t_70\\_\n\nEND_KEY:\n\nLEADER_ID: 3\n\nLEADER_STORE_ID: 1\n\nPEERS: 3, 63, 85\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 0\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.00 sec)\n\n(root\\@127.0.0.1) \\[test] 12:05:16> alter table jian2 PLACEMENT POLICY=jianplacementpolicy;\n\nQuery OK, 0 rows affected (0.09 sec)\n\n(root\\@127.0.0.1) \\[test] 12:05:50> show table jian2 regions\\G\n\n\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\* 1. row \\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\n\nREGION_ID: 143\n\nSTART_KEY: t_70\\_\n\nEND_KEY: t_71\\_\n\nLEADER_ID: 145\n\nLEADER_STORE_ID: 4 \n\nPEERS: 144, 145, 146\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 0\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.00 sec)\n```\n\n### 通过 PLACEMENT POLICY 修改表的副本数\n\n> Follower 的数量。例如 FOLLOWERS=2 表示数据有 3 个副本(2 个 follower 和 1 个 leader)。\n\n```\n(root\\@127.0.0.1) \\[test] 12:10:34> alter PLACEMENT POLICY jianplacementpolicy FOLLOWERS=1;\n\nQuery OK, 0 rows affected (0.11 sec)\n\n(root\\@127.0.0.1) \\[test] 12:10:40> show table jian2 regions\\G\n\n\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\* 1. row \\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\n\nREGION_ID: 143\n\nSTART_KEY: t_70\\_\n\nEND_KEY: t_71\\_\n\nLEADER_ID: 145\n\nLEADER_STORE_ID: 4\n\nPEERS: 144, 145 **副本数从 3 个已经调整到了 2 个\n**\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 0\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.00 sec)\n\n(root\\@127.0.0.1) \\[test] 12:10:44> alter PLACEMENT POLICY jianplacementpolicy FOLLOWERS=2;\n\nQuery OK, 0 rows affected (0.09 sec)\n\n(root\\@127.0.0.1) \\[test] 12:10:59> show table jian2 regions\\G\n\n\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\* 1. row \\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\n\nREGION_ID: 143\n\nSTART_KEY: t_70\\_\n\nEND_KEY: t_71\\_\n\nLEADER_ID: 145\n\nLEADER_STORE_ID: 4\n\nPEERS: 144, 145, 148\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 0\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.02 sec)\n```\n\n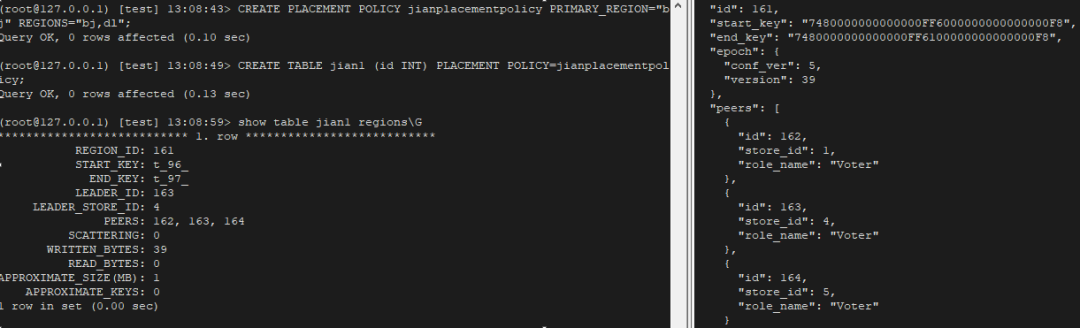\n\n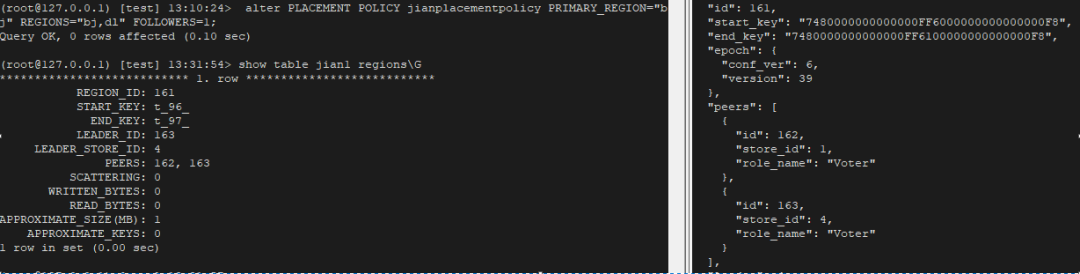\n\n### 修改 PLACEMENT POLICY 定义\n\n**注意:修改定义时需要将原来的定义都带上否则会将其覆盖**。\n\n这一点在官方文档中并没有特殊说明,也是自己在测试这个功能的时候偶然的发现,目前官方也没有直接修改的语法,所以大家在修改放置规则的时候一定要注意之前的定义以免将之前的定义覆盖。\n\n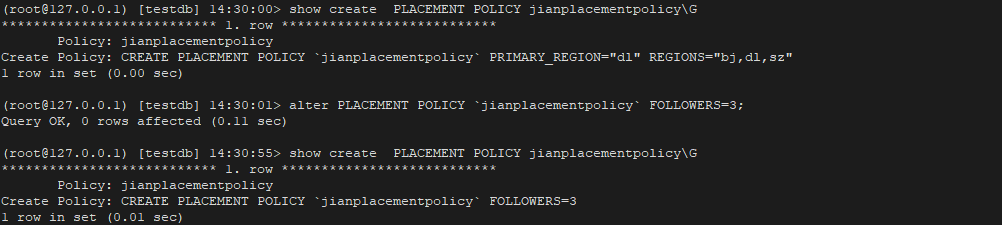\n\n```\n##########################################################\n之前的 PRIMARY_REGION=\"bj\" REGIONS=\"bj,dl,sz\" 定义已经被覆盖了\n##########################################################\n```\n\n### PRIMARY_REGION 节点宕机\n\n**如果 PRIMARY_REGION 的 TiKV 节点宕机,那么 leader 节点也会转移到非 PRIMARY_REGION 节点,当 TiKV 节点恢复正常后 leader 节点也会随之转移回来**\n\n以下的过程\n\n> leader 节点:store4-- 停止 store 的 tikv ---> store1 -- 恢复 tikv 节点-- > store4 \n\n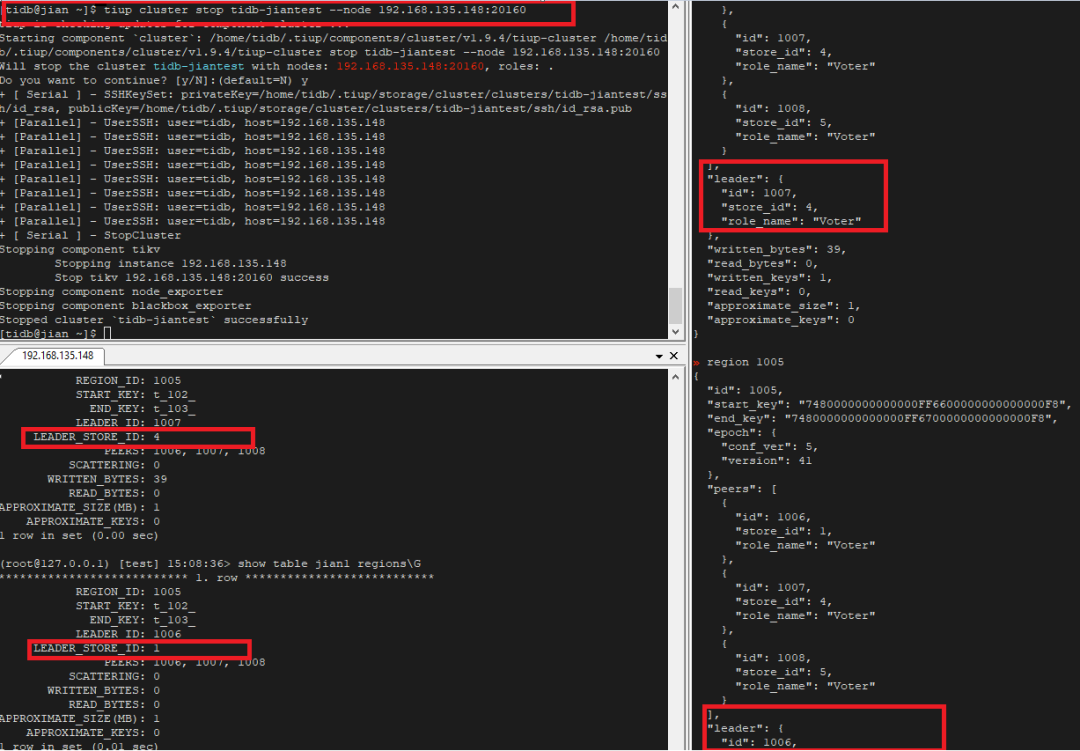\n\n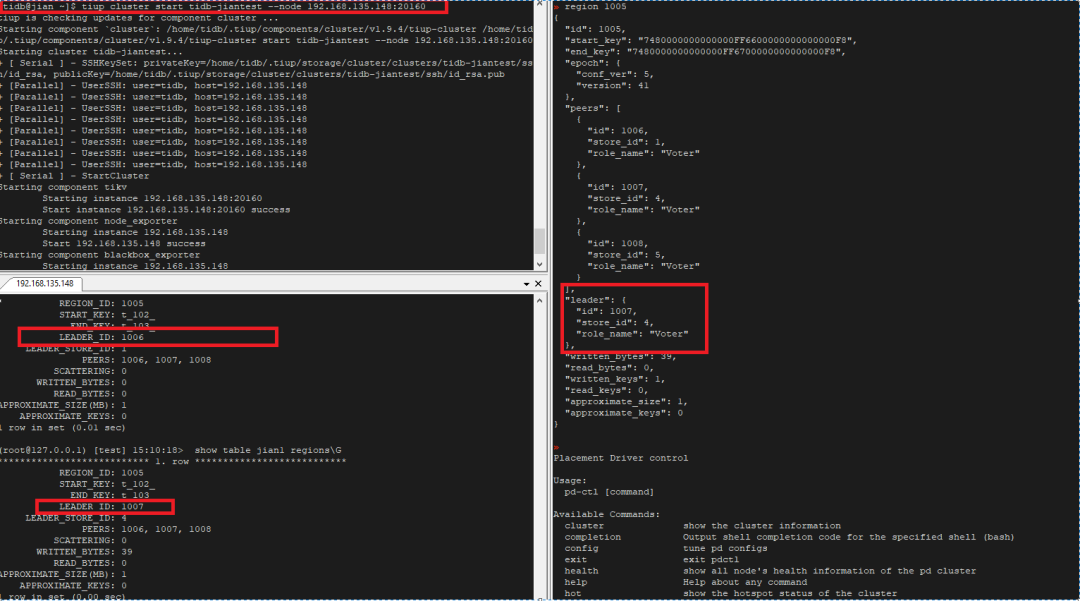\n\n### 更改 PRIMARY_REGION\n\n**如果更改表当前 palcement policy 定义的 primary region 那么表的 leader 也会随 PRIMARY_REGION 的改变而改变**\n\n> 下图 jian1 表一开始的 region 1005 的 leader 是在 store4(bj)上边,之后修改其 PRIMARY_REGION 为 dl(store 1),可以看到 region 1005 的 leader 也确实随之发生了改变\n\n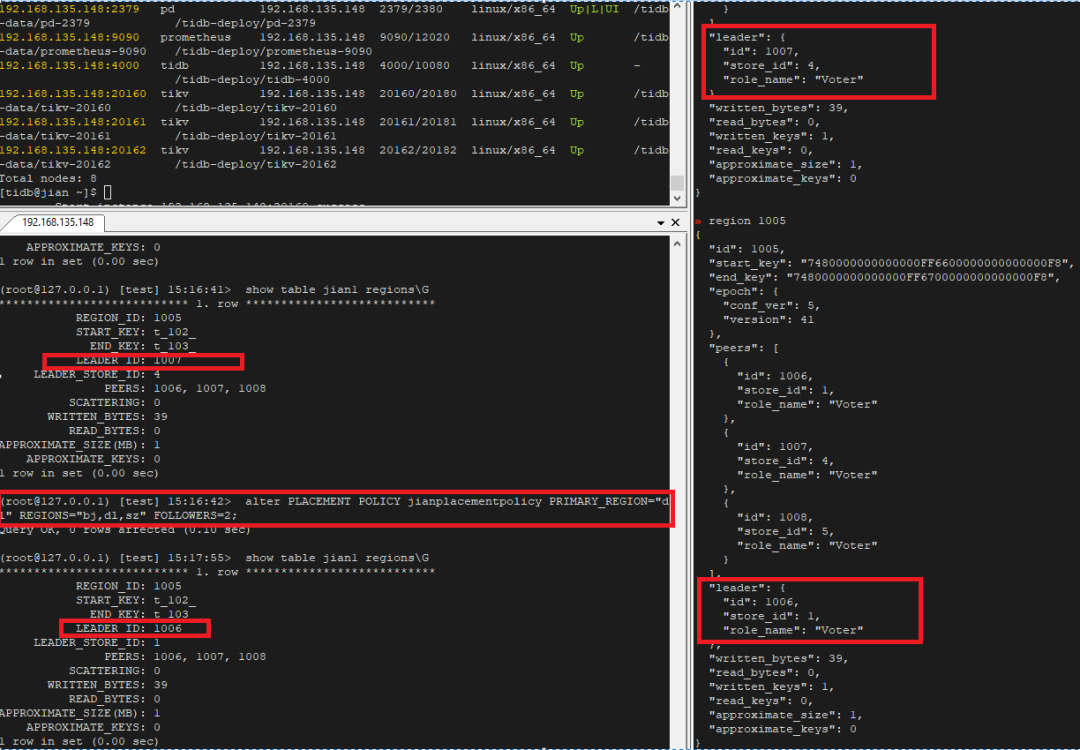\n\n### PLACEMENT POLICY 同样适用与分区表\n\n**以下样例中我们手动指定了每一个分区的 PLACEMENT POLICY,使其每个分区的 leader 都存放于不同的 store 上**。\n\n```\nCREATE PLACEMENT POLICY policy_table FOLLOWERS=3;\n\nCREATE PLACEMENT POLICY policy_dl PRIMARY_REGION=\"dl\" REGIONS=\"dl,bj,sz\";\n\nCREATE PLACEMENT POLICY policy_bj PRIMARY_REGION=\"bj\" REGIONS=\"dl,bj,sz\";\n\nCREATE PLACEMENT POLICY policy_sz PRIMARY_REGION=\"sz\" REGIONS=\"dl,bj,sz\" FOLLOWERS=1;\n\nSET tidb_enable_list_partition = 1;\n\nCREATE TABLE t1 (\n\nlocation VARCHAR(10) NOT NULL,\n\nuserdata VARCHAR(100) NOT NULL\n\n) PLACEMENT POLICY=policy_table PARTITION BY LIST COLUMNS (location) (\n\nPARTITION p_dl VALUES IN ('dl') PLACEMENT POLICY=policy_dl,\n\nPARTITION p_bj VALUES IN ('bj') PLACEMENT POLICY=policy_bj,\n\nPARTITION p_sz VALUES IN ('sz') PLACEMENT POLICY=policy_sz\n\n);\n```\n\n下图可以看到 t1 的 region 分别存放在 store 1(dl),4(bj),5(sz) 上边\n\n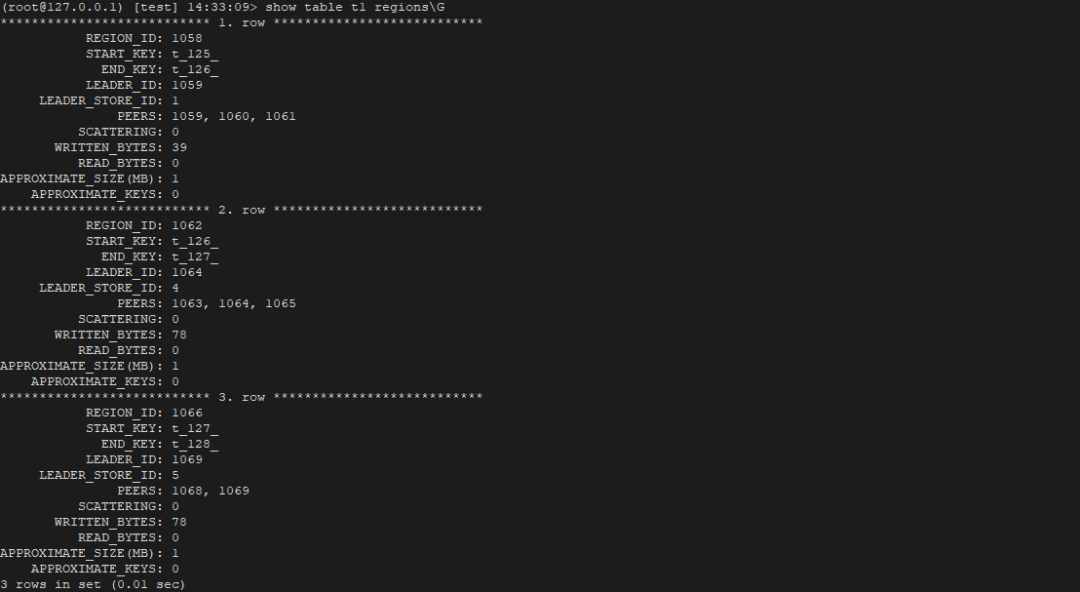\n\n### 查看数据库中现有的 PLACEMENT POLICY\n\n\n\n### 设置数据库级别的 PLACEMENT POLICY\n\n> 更改默认的放置选项,但更改不影响已有的表 \n创建新表会自动继承当前数据的放置规则 \n表级别的放置规则要优先于数据库级别的放置规则\n\n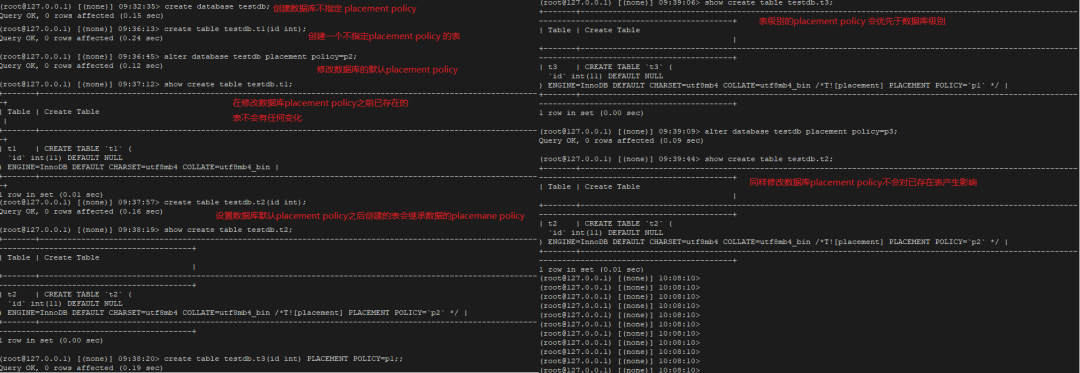\n\n### 高级放置规则\n\n**注意:PRIMARY_REGION、REGIONS 和 SCHEDULE 选项不可与 CONSTRAINTS 选项同时指定,否则会报错**。\n\n**以下 placement policy 的解读为**:\n\n1. 使用该规则的表的 region 只可以放置在含有 rack 标签且等于 rack1 的 tikv 节点上;\n\n2. 使用该规则的表的 leader region 只可以放置在含有 dc 标签且等于 bja 的 tikv 节点上;\n\n3. 使用该规则的表的 follower region 只可以放置在含有 dc 标签且等于 dla 的 tikv 节点上。\n\n```\n(root\\@127.0.0.1) \\[(none)] 16:34:28> create placement policy localtion_policy CONSTRAINTS=\"\\[+rack=rack1]\" LEADER_CONSTRAINTS=\"\\[+dc=bja]\" FOLLOWER_CONSTRAINTS=\"{+dc=dla: 1}\";\n\nQuery OK, 0 rows affected (0.10 sec)\n\n(root\\@127.0.0.1) \\[(none)] 16:35:41> create table testdb.jian2(id int) placement policy=localtion_policy;\n\nQuery OK, 0 rows affected (0.19 sec)\n\n(root\\@127.0.0.1) \\[(none)] 16:35:49> show table testdb.jian2 regions\\G\n\n\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\* 1. row \\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\n\nREGION_ID: 1127\n\nSTART_KEY: t_167\\_\n\nEND_KEY: t_168\\_\n\nLEADER_ID: 1129\n\nLEADER_STORE_ID: 4\n\nPEERS: 1128, 1129\n\nSCATTERING: 0\n\nWRITTEN_BYTES: 0\n\nREAD_BYTES: 0\n\nAPPROXIMATE_SIZE(MB): 1\n\nAPPROXIMATE_KEYS: 0\n\n1 row in set (0.01 sec)\n```\n\n注意:虽然 placement policy 高级匹配规则的默认 followers 是 2(三副本)但是实际的副本数还是要看符合 lable 的 tikv 的数量,如果实际的 tikv 节点数量无法满足 2followers 那么最终也只会有两个副本(也就是只有一个 followers 和一个 leader)上边的查询结果可以看到实际 region 的副本只有两个,但是当查询 localtion_policy 这个规则定义的时候 followers 为 2。\n\n```\nPOLICY_ID: 17\n\nCATALOG_NAME: def\n\nPOLICY_NAME: localtion_policy\n\nPRIMARY_REGION:\n\nREGIONS:\n\nCONSTRAINTS: \\[+rack=rack1]\n\nLEADER_CONSTRAINTS: \\[+dc=bja]\n\nFOLLOWER_CONSTRAINTS: {+dc=dla: 1}\n\nLEARNER_CONSTRAINTS:\n\nSCHEDULE:\n\nFOLLOWERS: 2\n\nLEARNERS: 0\n```\n\n### placement policy 的创建选项\n\n| 选项名| 描述 |\n|:----|:---- |\n| PRIMARY_REGION\t| Raft leader 被放置在有 region 标签的节点上,且这些 region 标签匹配本选项的值。| \n| REGIONS\t| Raft followers 被放置在有 region 标签的节点上,且这些 region 标签匹配本选项的值。| \n| SCHEDULE\t| 用于调度 follower 放置位置的策略。可选值为 EVEN(默认值)或 MAJORITY_IN_PRIMARY。| \n| FOLLOWERS\t| Follower 的数量。例如 FOLLOWERS=2 表示数据有 3 个副本(2 个 follower 和 1 个 leader)。| \n| CONSTRAINTS\t| 适用于所有角色 (role) 的约束列表。例如,CONSTRAINTS=\"[+disk=ssd]\"。| \n| LEADER_CONSTRAINTS\t| 仅适用于 leader 的约束列表。| \n| FOLLOWER_CONSTRAINTS\t| 仅适用于 follower 的约束列表。| \n| LEARNER_CONSTRAINTS\t| 仅适用于 learner 的约束列表。| \n| LEARNERS \t| 指定 learner 的数量。| \n\n\n### 删除 placement policy\n\n删除 placement policy 时一定要确保没有任何表在使用当前的 placement policy 否则会报错:\n\n```\n(root\\@127.0.0.1) \\[test] 12:11:43> drop PLACEMENT POLICY jianplacementpolicy;\n\nERROR 8241 (HY000): Placement policy 'jianplacementpolicy' is still in use\n\n(root\\@127.0.0.1) \\[test] 12:16:20> alter table jian1 PLACEMENT POLICY=default;\n\nQuery OK, 0 rows affected (0.08 sec)\n```\n\n查看某个 placement policy 是否正在被表使用:\n\n```\nSELECT table\\_schema, table\\_name FROM information\\_schema.tables WHERE tidb\\_placement\\_policy\\_name='jianplacementpolicy';\n\nSELECT table\\_schema, table\\_name FROM information\\_schema.partitions WHERE tidb\\_placement\\_policy\\_name='jianplacementpolicy';\n```\n\n## 总结\n\n当前版本在使用 Placement Rules in SQL 时如果使用基本的放置规则那么只可以使用 PRIMARY_REGION 和 REGIONS 来进行放置规则的设置,但是如果使用高级放置规则那么 tikv 的 label 标签不需要必须设置 region 层级的标签,可以灵活使用和定义已存在或者需要的标签。\n\n高级放置规则的默认 followers 的数量为 2,但是如果在设置规则 FOLLOWER_CONSTRAINTS 时如果满足的节点不满足 2 时只会在 FOLLOWER_CONSTRAINTS 匹配的节点上创建副本,这一点在创建时一定要规划好自己的集群中的 tikv 节点的标签设计,以免导致 region 的副本数过少。\n\nPlacement Rules in SQL 可以通过它对分区 / 表 / 库不同级别的数据进行基于标签的自由放置。\n\n总之 TiDB 6.0 的 Placement Rules In SQL 暴露了以往用户无法控制的内部调度能力,并提供了方便的 SQL 接口,这开启了诸多以往不可能实现的场景,更多的运用方式与使用场景还期待各位的发掘。\n\n","author":"吴永健","category":4,"customUrl":"practice-of-placement-rules-in-sql","fillInMethod":"writeDirectly","id":411,"summary":"本文简要介绍了 Placement Rules in SQL 的应用场景,并通过一个例子详细介绍了 placement policy 的使用方法。","tags":["TiDB"],"title":"TiDB Placement Rules in SQL 使用实践丨TiDB Book Rush"}}]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}