{
"componentChunkName": "component---src-templates-blog-blog-detail-tsx",
"path": "/blog/an-explanation-of-the-heap-profiling-principle",
"result": {"pageContext":{"blog":{"id":"Blogs_317","title":"内存泄漏的定位与排查:Heap Profiling 原理解析","tags":["TiKV 性能优化"],"category":{"name":"产品技术解读"},"summary":"本文将介绍一些常见的 Heap Profiler 的实现原理及使用方法,帮助读者更容易地理解 TiKV 中相关实现,或将这类分析手段更好地运用到自己项目中。","body":"系统长时间运行之后,可用内存越来越少,甚至导致了某些服务失败,这就是典型的内存泄漏问题。这类问题通常难以预测,也很难通过静态代码梳理的方式定位。Heap Profiling 就是帮助我们解决此类问题的。\n\nTiKV 作为分布式系统的一部分,已经初步拥有了 Heap Profiling 的能力。本文将介绍一些常见的 Heap Profiler 的实现原理及使用方法,帮助读者更容易地理解 TiKV 中相关实现,或将这类分析手段更好地运用到自己项目中。\n\n\n## 什么是 Heap Profiling\n\n运行时的内存泄漏问题在很多场景下都相当难以排查,因为这类问题通常难以预测,也很难通过静态代码梳理的方式定位。\n\nHeap Profiling 就是帮助我们解决此类问题的。\n\nHeap Profiling 通常指对应用程序的堆分配进行收集或采样,来向我们报告程序的内存使用情况,以便分析内存占用原因或定位内存泄漏根源。\n\n## Heap Profiling 是如何工作的\n\n作为对比,我们先简单了解下 CPU Profiling 是如何工作的。\n\n当我们准备进行 CPU Profiling 时,通常需要选定某一**时间窗口**,在该窗口内,CPU Profiler 会向目标程序注册一个定时执行的 hook(有多种手段,譬如 SIGPROF 信号),在这个 hook 内我们每次会获取业务线程此刻的 stack trace。\n\n我们将 hook 的执行频率控制在特定的数值,譬如 100hz,这样就做到每 10ms 采集一个业务代码的调用栈样本。当时间窗口结束后,我们将采集到的所有样本进行聚合,最终得到每个函数被采集到的次数,相较于总样本数也就得到了每个函数的**相对占比**。\n\n借助此模型我们可以发现占比较高的函数,进而定位 CPU 热点。\n\n在数据结构上,Heap Profiling 与 CPU Profiling 十分相似,都是 stack trace + statistics 的模型。如果你使用过 Go 提供的 pprof,会发现二者的展示格式是几乎相同的:\n\n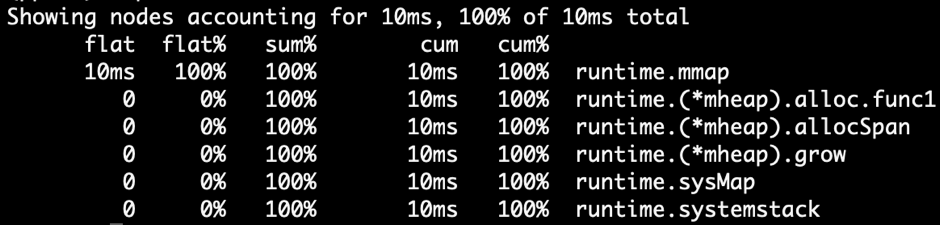\n\nGo CPU Profile\n\n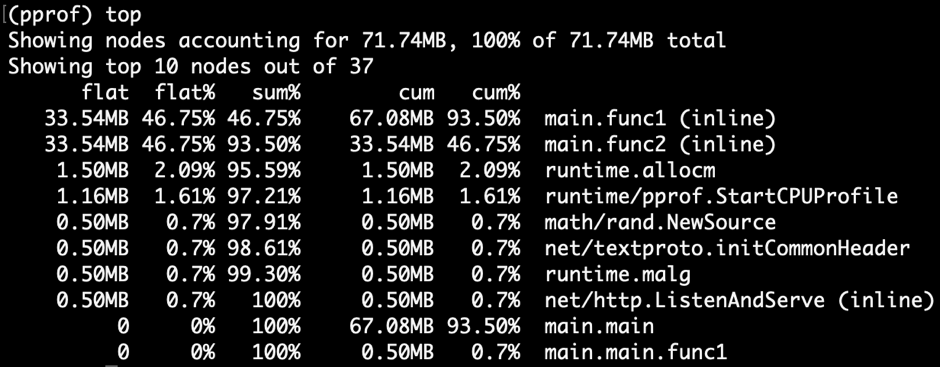\n\nGo Heap Profile\n\n与 CPU Profiling 不同的是,Heap Profiling 的数据采集工作并非简单通过定时器开展,而是需要侵入到内存分配路径内,这样才能拿到内存分配的数量。所以 Heap Profiler 通常的做法是**直接将自己集成在内存分配器内**,当应用程序进行内存分配时拿到当前的 stack trace,最终将所有样本聚合在一起,这样我们便能知道**每个函数直接或间接地内存分配数量**了。\n\n**Heap Profile 的 stack trace + statistics 数据模型与 CPU Proflie 是一致的**。\n\n接下来我们将介绍多款 Heap Profiler 的使用和实现原理。\n\n注:诸如 [GNU gprof](https://sourceware.org/binutils/docs/gprof/)、[Valgrind](https://www.valgrind.org/) 等工具的使用场景与我们的目的场景不匹配,因此本文不会展开。原因参考 [gprof, Valgrind and gperftools - an evaluation of some tools for application level CPU profiling on Linux - Gernot.Klingler](https://gernotklingler.com/blog/gprof-valgrind-gperftools-evaluation-tools-application-level-cpu-profiling-linux/)。\n## Heap Profiling in Go\n\n大部分读者应该对 Go 会更加熟悉一些,因此我们以 Go 为起点和基底来进行调研。\n\n\n注:如果一个概念我们在靠前的小节讲过了,后边的小节则不再赘述,即使它们不是同一个项目。另外出于完整性目的,每个项目都配有 usage 小节来阐述其用法,对此已经熟悉的同学可以直接跳过。\n\n### Usage\n\nGo runtime 内置了方便的 profiler,heap 是其中一种类型。我们可以通过如下方式开启一个 debug 端口:\n\n```\nimport _ \"net/http/pprof\"\n\ngo func() {\n log.Print(http.ListenAndServe(\"0.0.0.0:9999\", nil))\n}()\n```\n然后在程序运行期间使用命令行拿到当前的 Heap Profiling 快照:\n\n```\n$ go tool pprof http://127.0.0.1:9999/debug/pprof/heap\n```\n\n或者也可以在应用程序代码的特定位置直接获取一次 Heap Profiling 快照:\n\n```\nimport \"runtime/pprof\"\n\npprof.WriteHeapProfile(writer)\n```\n\n这里我们用一个完整的 demo 来串一下 heap pprof 的用法:\n\n```\npackage main\n\nimport (\n \"log\"\n \"net/http\"\n _ \"net/http/pprof\"\n \"time\"\n)\n\nfunc main() {\n go func() {\n log.Fatal(http.ListenAndServe(\":9999\", nil))\n }()\n\n var data [][]byte\n for {\n data = func1(data)\n time.Sleep(1 * time.Second)\n }\n}\n\nfunc func1(data [][]byte) [][]byte {\n data = func2(data)\n return append(data, make([]byte, 1024*1024)) // alloc 1mb\n}\n\nfunc func2(data [][]byte) [][]byte {\n return append(data, make([]byte, 1024*1024)) // alloc 1mb\n```\n代码持续地在 func1 和 func2 分别进行内存分配,每秒共分配 2mb 堆内存。\n\n\n将程序运行一段时间后,执行如下命令拿到 profile 快照并开启一个 web 服务来进行浏览:\n```\n$ go tool pprof -http=\":9998\" localhost:9999/debug/pprof/heap\n```\n\n\n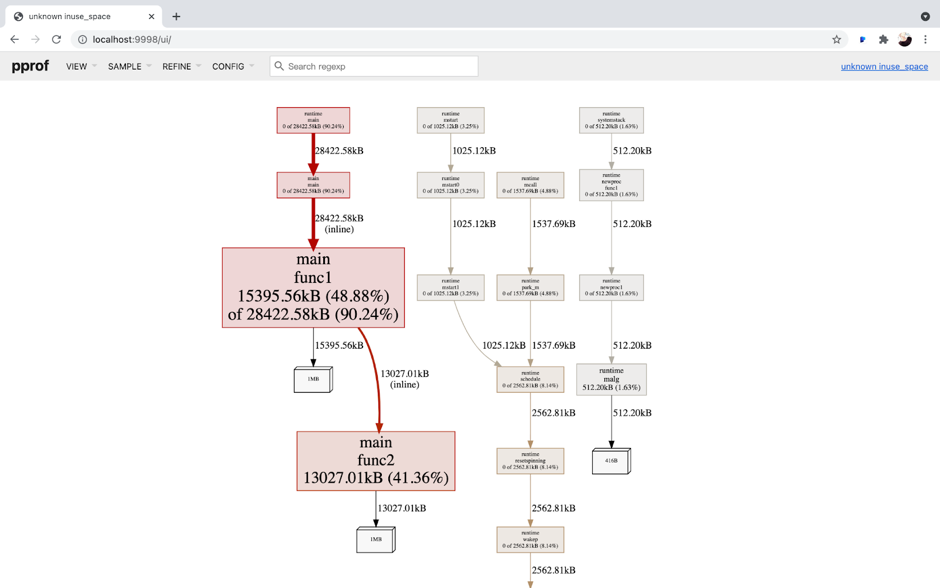\n\nGo Heap Graph\n\n从图中我们能够很直观的看出哪些函数的内存分配占大头(方框更大),同时也能很直观的看到函数的调用关系(通过连线)。譬如上图中很明显看出是 func1 和 func2 的分配占大头,且 func2 被 func1 调用。\n\n注意,由于 Heap Profiling 也是**采样**的(默认每分配 512k 采样一次),所以这里展示的内存大小要小于实际分配的内存大小。同 CPU Profiling 一样,这个数值仅仅是用于计算**相对占比**,进而定位内存分配热点。\n\n注:事实上,Go runtime 对采样到的结果有估算原始大小的逻辑,但这个结论并不一定准确。\n\n此外,func1 方框中的 48.88% of 90.24% 表示 Flat% of Cum%。\n\n什么是 Flat% 和 Cum%?我们先换一种浏览方式,在左上角的 View 栏下拉点击 Top:\n\n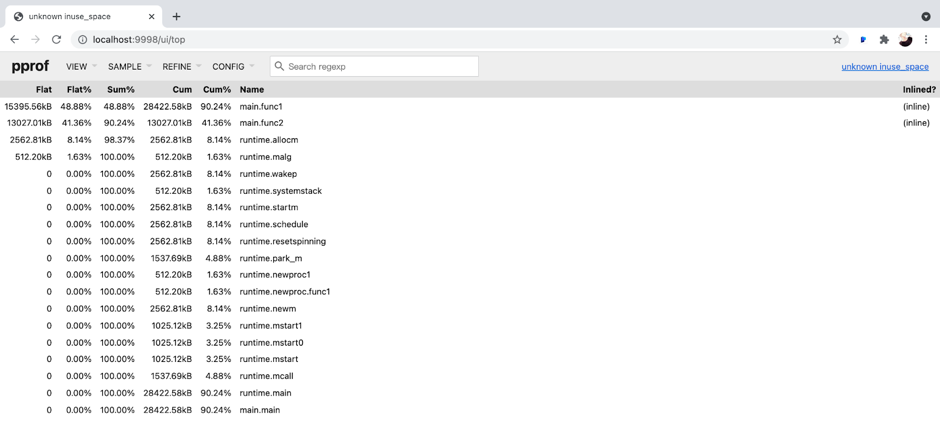\n\n\nGo Heap Top\n\n* **Name** 列表示相应的函数名\n\n* **Flat** 列表示该函数自身分配了多少内存\n\n* **Flat%** 列表示 Flat 相对总分配大小的占比\n\n* **Cum** 列表示该函数,**及其调用的所有子函数**一共分配了多少内存\n\n* **Cum%** 列表示 Cum 相对总分配大小的占比\n\n\nSum% 列表示自上而下 Flat% 的累加(可以直观的判断出从哪一行往上一共分配的多少内存)\n上述两种方式可以帮助我们定位到具体的函数,Go 提供了更细粒度的代码行数级别的分配源统计,在左上角 View 栏下拉点击 Source:\n\n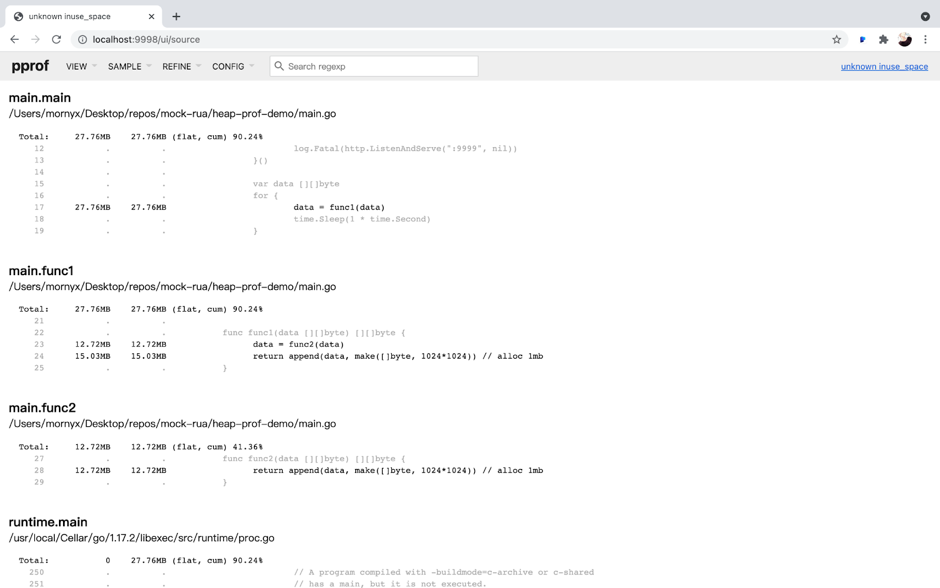\n\n\nGo Heap Source\n\n在 CPU Profiling 中我们常用火焰图找宽顶来快速直观地定位热点函数。当然,由于数据模型的同质性,Heap Profiling 数据也可以通过火焰图来展现,在左上角 View 栏下拉点击 Flame Graph:\n\n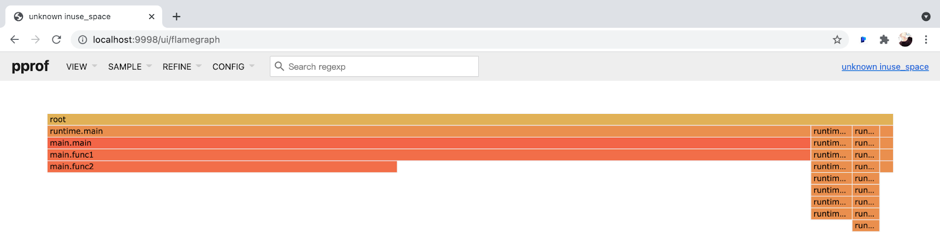\n\n\nGo Heap Flamegraph\n\n通过上述各种方式我们可以很简单地看出内存分配大头在 func1 和 func2。然而现实场景中绝不会这么简单就让我们定位到问题根源,由于我们拿到的是某一刻的快照,对于内存泄漏问题来说这并不够用,我们需要的是一个增量数据,来判断哪些内存在持续地增长。所以可以在间隔一定时间后再获取一次 Heap Profile,对两次结果做 diff。\n\n### Implementation details\n\n本节我们重点关注 Go Heap Profiling 的实现原理。\n\n回顾 “Heap Profiling 是如何工作的” 一节,Heap Profiler 通常的做法是直接将自己集成在内存分配器内,当应用程序进行内存分配时拿到当前的 stack trace,而 Go 正是这么做的。\n\n\nGo 的内存分配入口是 src/runtime/malloc.go 中的 mallocgc() 函数,其中一段关键代码如下:\n\n```\nfunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {\n // ...\n if rate := MemProfileRate; rate > 0 {\n // Note cache c only valid while m acquired; see #47302\n if rate != 1 && size < c.nextSample {\n c.nextSample -= size\n } else {\n profilealloc(mp, x, size)\n }\n }\n // ...\n}\n\nfunc profilealloc(mp *m, x unsafe.Pointer, size uintptr) {\n c := getMCache()\n if c == nil {\n throw(\"profilealloc called without a P or outside bootstrapping\")\n }\n c.nextSample = nextSample()\n mProf_Malloc(x, size)\n}\n```\n\n这也就意味着,每通过 mallocgc() 分配 512k 的堆内存,就调用 profilealloc() 记录一次 stack trace。\n\n\n为什么需要定义一个采样粒度?每次 mallocgc() 都记录下当前的 stack trace 不是更准确吗?\n\n完全精确地拿到所有函数的内存分配看似更加吸引人,但这样**带来的性能开销是巨大的**。malloc() 作为用户态库函数会被应用程序**非常频繁地调用**,优化内存分配性能是 allocator 的责任。如果每次 malloc() 调用都伴随一次栈回溯,带来的开销几乎是不可接受的,尤其是在服务端长期持续进行 profiling 的场景。选择 “采样” 并非结果上更优,而仅仅是一种妥协。\n\n当然,我们也可以自行修改 MemProfileRate 变量,将其设置为 1 会导致每次 mallocgc() 必定进行 stack trace 记录,设置为 0 则会完全关闭 Heap Profiling,用户可以根据实际场景来权衡性能与精确度。\n\n注意,当我们将 MemProfileRate 设置为一个通常的采样粒度时,这个值并不是完全精确的,而是每次都在以 MemProfileRate 为**平均值的指数分布中随机取一个值**。\n\n```\n// nextSample returns the next sampling point for heap profiling. The goal is\n// to sample allocations on average every MemProfileRate bytes, but with a\n// completely random distribution over the allocation timeline; this\n// corresponds to a Poisson process with parameter MemProfileRate. In Poisson\n// processes, the distance between two samples follows the exponential\n// distribution (exp(MemProfileRate)), so the best return value is a random\n// number taken from an exponential distribution whose mean is MemProfileRate.\nfunc nextSample() uintptr\n```\n\n由于很多情况下内存分配是有规律的,如果按照固定的粒度进行采样,最终得到的结果可能会存在很大的误差,可能刚好每次采样都赶上了某个特定类型的内存分配。这就是这里选择随机化的原因。\n\n不只是 Heap Profiling,基于 sampling 的各类 profiler 总会有一些误差存在(例:[SafePoint Bias](http://psy-lob-saw.blogspot.com/2016/02/why-most-sampling-java-profilers-are.html)),在审阅基于 sampling 的 profiling 结果时,需要时刻提醒自己不要忽视误差存在的可能性。\n\n位于 src/runtime/mprof.go 的 mProf_Malloc() 函数负责具体的采样工作:\n\n```\n// Called by malloc to record a profiled block.\nfunc mProf_Malloc(p unsafe.Pointer, size uintptr) {\n var stk [maxStack]uintptr\n nstk := callers(4, stk[:])\n lock(&proflock)\n b := stkbucket(memProfile, size, stk[:nstk], true)\n c := mProf.cycle\n mp := b.mp()\n mpc := &mp.future[(c+2)%uint32(len(mp.future))]\n mpc.allocs++\n mpc.alloc_bytes += size\n unlock(&proflock)\n\n // Setprofilebucket locks a bunch of other mutexes, so we call it outside of proflock.\n // This reduces potential contention and chances of deadlocks.\n // Since the object must be alive during call to mProf_Malloc,\n // it's fine to do this non-atomically.\n systemstack(func() {\n setprofilebucket(p, b)\n })\n}\n\nfunc callers(skip int, pcbuf []uintptr) int {\n sp := getcallersp()\n pc := getcallerpc()\n gp := getg()\n var n int\n systemstack(func() {\n n = gentraceback(pc, sp, 0, gp, skip, &pcbuf[0], len(pcbuf), nil, nil, 0)\n })\n return n\n}\n```\n\n通过调用 callers() 以及进一步的 gentraceback() 来获取当前调用栈保存在 stk 数组中(即 PC 地址的数组),这一技术被称为调用栈回溯,在很多场景均有应用(譬如程序 panic 时的栈展开)。\n\n\n注:术语 PC 指 Program Counter,特定于 x86-64 平台时为 RIP 寄存器;FP 指 Frame Pointer,特定于 x86-64 时为 RBP 寄存器;SP 指 Stack Pointer,特定于 x86-64 时为 RSP 寄存器。\n\n一种原始的调用栈回溯实现方式是在函数调用约定(Calling Convention)上保证发生函数调用时 RBP 寄存器(on x86-64)保存的一定是栈基址,而不再作为通用寄存器使用,由于 call 指令会首先将 RIP (返回地址)入栈,我们只要保证接下来入栈的第一条数据是当前的 RBP,那么所有函数的栈基址就以 RBP 为头,串成了一条地址链表。我们只需为每个 RBP 地址向下偏移一个单元,便能拿到 RIP 的数组了。\n\n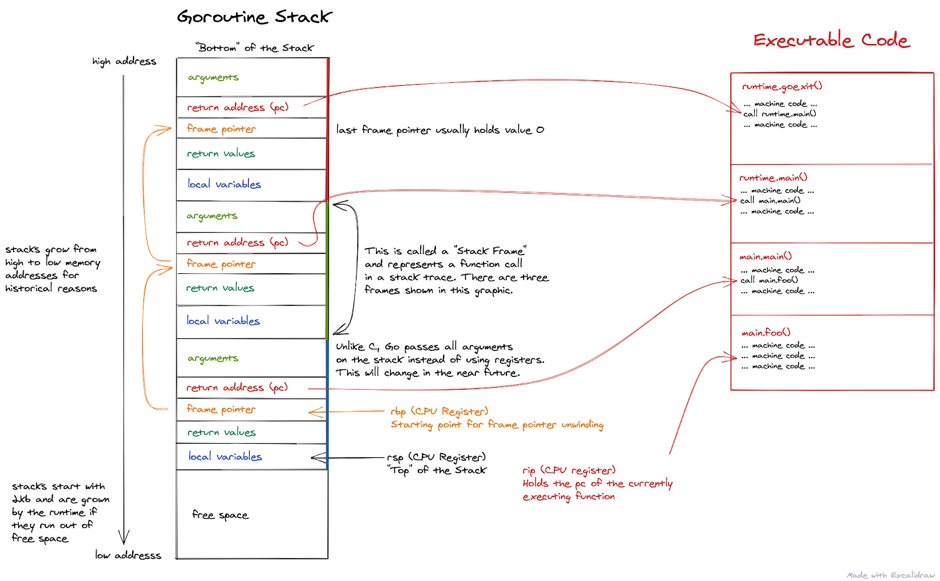\n\n\nGo FramePointer Backtrace(图片来自 [go-profiler-notes](https://github.com/DataDog/go-profiler-notes))\n\n注:图中提到 Go 的所有参数均通过栈传递,这一结论现在已经过时了,Go 从 1.17 版本开始支持寄存器传参。\n\n由于 x86-64 将 RBP 归为了通用寄存器,诸如 GCC 等编译器默认不再使用 RBP 保存栈基址,除非使用特定的选项将其打开。然而 Go 编译器却**保留了这个特性**,因此在 Go 中通过 RBP 进行栈回溯是可行的。\n\n但 Go 并没有采用这个简单的方案,原因是在某些特殊场景下该方案会带来一些问题,譬如如果某个函数被 inline 掉了,那么通过 RBP 回溯得到的调用栈就是缺失的。另外这个方案需要在常规函数调用间插入额外的指令,且需要额外占用一个通用寄存器,存在一定的性能开销,即使我们不需要栈回溯。\n\n每个 Go 的二进制文件都包含一个名为 gopclntab 的 section,这是 Go Program Counter Line Table 的缩写,它维护了 PC 到 SP 及其返回地址的映射。这样我们就无需依赖 FP,便能**直接通过查表的方式完成 PC 链表的串联**。同时 gopclntab 中**维护了 PC 及其所处函数是否已被内联优化的信息**,所以我们在栈回溯过程中便不会丢失内联函数帧。此外 gopclntab 还维护了符号表,保存 PC 对应的代码信息(函数名,行数等),所以我们最终才能看到人类可读的 panic 结果或者 profiling 结果,而不是一大坨地址信息。\n\n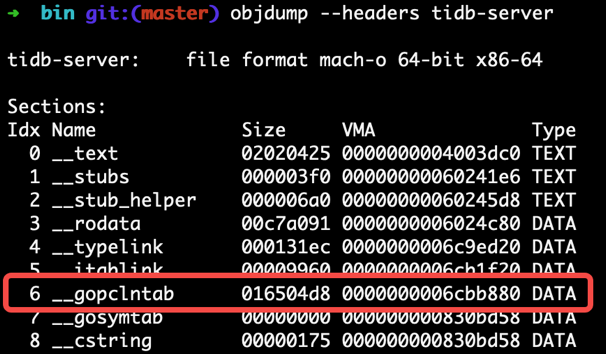\n\n\ngopclntab\n\n与特定于 Go 的 gopclntab 不同,DWARF 是一种标准化的调试格式,Go 编译器同样为其生成的 binary 添加了 DWARF (v4) 信息,所以一些非 Go 生态的外部工具可以依赖它对 Go 程序进行调试。值得一提的是,DWARF 所包含的信息是 gopclntab 的超集。\n\n回到 Heap Profiling 来,当我们通过栈回溯技术(前边代码中的 gentraceback() 函数)拿到 PC 数组后,并不需要着急直接将其符号化,符号化的开销是相当可观的,我们完全可以先通过指针地址栈进行聚合。所谓的聚合就是在 hashmap 中对相同的样本进行累加,相同的样本指的是两个数组内容完全一致的样本。\n\n通过 stkbucket() 函数以 stk 为 key 获取相应的 bucket,然后将其中统计相关的字段进行累加。\n\n另外,我们注意到 memRecord 有多组 memRecordCycle 统计数据:\n\n```\ntype memRecord struct {\n active memRecordCycle\n future [3]memRecordCycle\n}\n```\n\n在累加时是通过 mProf.cycle 全局变量作为下标取模来访问某组特定的 memRecordCycle。mProf.cycle 每经过一轮 GC 就会递增,这样就记录了三轮 GC 间的分配情况。只有当一轮 GC 结束后,才会将上一轮 GC 到这一轮 GC 之间的内存分配、释放情况并入最终展示的统计数据中。这个设计是为了避免在 GC 执行前拿到 Heap Profile,给我们看到大量无用的临时内存。\n\n\n并且,在一轮 GC 周期的不同时刻我们也可能会看到不稳定的堆内存状态。\n\n最终调用 setprofilebucket() 将 bucket 记录到此次分配地址相关的 mspan 上,用于后续 GC 时调用 mProf_Free() 来记录相应的释放情况。\n\n就这样,Go runtime 中始终维护着这份 bucket 集合,当我们需要进行 Heap Profiling 时(譬如调用 pprof.WriteHeapProfile() 时),就会访问这份 bucket 集合,转换为 pprof 输出所需要的格式。\n\n这也是 Heap Profiling 与 CPU Profiling 的一个区别:CPU Profiling 只在进行 profiling 的时间窗口内对应用程序存在一定采样开销,而 Heap Profiling 的采样是无时无刻不在发生的,**执行一次 profiling 仅仅是 dump 一下迄今为止的数据快照**。\n\n接下来我们将进入 C/C++/Rust 的世界,幸运的是,由于大部分 Heap Profiler 的实现原理是类似的,前文所述的很多知识在后文对应的上。最典型的,Go Heap Profiling 其实就是从 Google tcmalloc 移植而来的,它们具备相似的实现方式。\n\n## Heap Profiling with gperftools\n\n[gperftools](https://github.com/gperftools/gperftools)(Google Performance Tools)是一套工具包,包括 Heap Profiler、Heap Checker、CPU Profiler 等工具。之所以在 Go 之后紧接着介绍它,是因为它与 Go 有很深的渊源。\n\n\n前文提到的 Go runtime 所移植的 Google tcmalloc 从内部分化出了两个社区版本:一个是 [tcmalloc](https://github.com/google/tcmalloc),即纯粹的 malloc 实现,不包含其它附加功能;另一个就是 [gperftools](https://github.com/gperftools/gperftools),是带 Heap Profiling 能力的 malloc 实现,以及配套的其它工具集。\n\n其中 pprof 也是大家最为熟知的工具之一。pprof 早期是一个 perl 脚本,后来演化成了 Go 编写的强大工具 [pprof](https://github.com/google/pprof),现在已经被集成到了 Go 主干,平时我们使用的 go tool pprof 命令内部就是直接使用的 pprof 包。\n\n注:gperftools 的主要作者是 Sanjay Ghemawat,与 Jeff Dean 结对编程的牛人。\n\n### Usage\n\nGoogle 内部一直在使用 gperftools 的 Heap Profiler 分析 C++ 程序的堆内存分配,它可以做到:\n\n* Figuring out what is in the program heap at any given time\n* Locating memory leaks\n* Finding places that do a lot of allocation\n\n作为 Go pprof 的祖先,看起来和 Go 提供的 Heap Profiling 能力是相同的。\n\nGo 是直接在 runtime 中的内存分配函数硬编入了采集代码,与此类似,gperftools 则是在它提供的 libtcmalloc 的 malloc 实现中植入了采集代码。用户需要在项目编译链接阶段执行 -ltcmalloc 链接该库,以替换 libc 默认的 malloc 实现。\n\n当然,我们也可以依赖 Linux 的动态链接机制来在运行阶段进行替换:\n\n```\n$ env LD_PRELOAD=\"/usr/lib/libtcmalloc.so\" \n```\n\n当使用 LD_PRELOAD 指定了 libtcmalloc.so 后,我们程序中所默认链接的 malloc() 就被覆盖了,Linux 的动态链接器保证了优先执行 LD_PRELOAD 所指定的版本。\n\n\n在运行链接了 libtcmalloc 的可执行文件之前,如果我们将环境变量 HEAPPROFILE 设置为一个文件名,那么当程序执行时,Heap Profile 数据就会被写入该文件。\n\n在默认情况下,每当我们的程序分配了 1g 内存时,或每当程序的内存使用高水位线增加了 100mb 时,都会进行一次 Heap Profile 的 dump。这些参数可以通过环境变量来修改。\n\n使用 gperftools 自带的 pprof 脚本可以分析 dump 出来的 profile 文件,用法与 Go 基本相同。 \n\n```\n$ pprof --gv gfs_master /tmp/profile.0100.heap\n```\n\n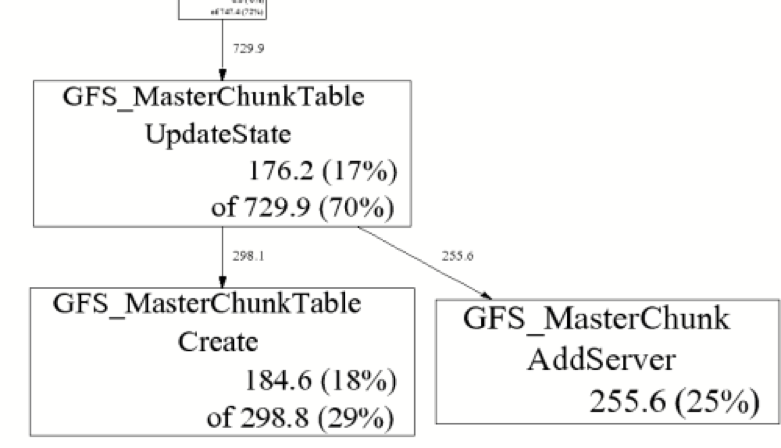\n\ngperftools gv\n\n```\n$ pprof --text gfs_master /tmp/profile.0100.heap\n 255.6 24.7% 24.7% 255.6 24.7% GFS_MasterChunk::AddServer\n 184.6 17.8% 42.5% 298.8 28.8% GFS_MasterChunkTable::Create\n 176.2 17.0% 59.5% 729.9 70.5% GFS_MasterChunkTable::UpdateState\n 169.8 16.4% 75.9% 169.8 16.4% PendingClone::PendingClone\n 76.3 7.4% 83.3% 76.3 7.4% __default_alloc_template::_S_chunk_alloc\n 49.5 4.8% 88.0% 49.5 4.8% hashtable::resize\n ...\n```\n\n同样的,从左到右依次是 Flat(mb),Flat%,Sum%,Cum(mb),Cum%,Name。\n\n\n### Implementation details\n\n类似的,tcmalloc 在 malloc() 和 operator new 中增加了一些采样逻辑,当根据条件触发采样 hook 时,会执行以下函数:\n\n```\n// Record an allocation in the profile.\nstatic void RecordAlloc(const void* ptr, size_t bytes, int skip_count) {\n // Take the stack trace outside the critical section.\nvoid* stack[HeapProfileTable::kMaxStackDepth];\n int depth = HeapProfileTable::GetCallerStackTrace(skip_count + 1, stack);\n SpinLockHolder l(&heap_lock);\n if (is_on) {\n heap_profile->RecordAlloc(ptr, bytes, depth, stack);\n MaybeDumpProfileLocked();\n }\n}\n\nvoid HeapProfileTable::RecordAlloc(\n const void* ptr, size_t bytes, int stack_depth,\n const void* const call_stack[]) {\n Bucket* b = GetBucket(stack_depth, call_stack);\n b->allocs++;\n b->alloc_size += bytes;\n total_.allocs++;\n total_.alloc_size += bytes;\n\n AllocValue v;\n v.set_bucket(b); // also did set_live(false); set_ignore(false)\n v.bytes = bytes;\n address_map_->Insert(ptr, v);\n}\n```\n\n执行流程如下:\n\n1. 调用 GetCallerStackTrace() 获取调用栈。\n\n2. 以调用栈作为 hashmap 的 key 调用 GetBucket() 获取相应的 Bucket。\n\n3. 累加 Bucket 中的统计数据。\n\n\n由于没有了 GC 的存在,采样流程相比 Go 简单了许多。从变量命名上来看,Go runtime 中的 profiling 代码的确是从这里移植过去的。\n\nsampler.h 中详细描述了 gperftools 的采样规则,总的来说也和 Go 一致,即:512k average sample step。\n\n在 free() 或 operator delete 中同样需要增加一些逻辑来记录内存释放情况,这比拥有 GC 的 Go 同样要简单不少:\n\n```\n// Record a deallocation in the profile.\nstatic void RecordFree(const void* ptr) {\n SpinLockHolder l(&heap_lock);\n if (is_on) {\n heap_profile->RecordFree(ptr);\n MaybeDumpProfileLocked();\n }\n}\n\nvoid HeapProfileTable::RecordFree(const void* ptr) {\n AllocValue v;\n if (address_map_->FindAndRemove(ptr, &v)) {\n Bucket* b = v.bucket();\n b->frees++;\n b->free_size += v.bytes;\n total_.frees++;\n total_.free_size += v.bytes;\n }\n}\n```\n\n找到相应的 Bucket,累加 free 相关的字段即可。\n\n\n现代 C/C++/Rust 程序获取调用栈的过程通常是依赖 libunwind 库进行的,libunwind 进行栈回溯的原理上与 Go 类似,都没有选择 Frame Pointer 回溯模式,都是依赖程序中的某个特定 section 所记录的 unwind table。不同的是,Go 所依赖的是自己生态内创建的名为 gopclntab 的特定 section,而 C/C++/Rust 程序依赖的是 .debug_frame section 或 .eh_frame section。\n\n其中 .debug_frame 为 DWARF 标准定义,Go 编译器也会写入这个信息,但自己不用,只留给第三方工具使用。GCC 只有开启 -g 参数时才会向 .debug_frame 写入调试信息。\n\n而 .eh_frame 则更为现代一些,在 [Linux Standard Base](https://refspecs.linuxfoundation.org/LSB_5.0.0/LSB-Core-generic/LSB-Core-generic/ehframechpt.html) 中定义。原理是让编译器在汇编代码的相应位置插入一些伪指令([CFI Directives](https://sourceware.org/binutils/docs-2.31/as/CFI-directives.html),Call Frame Information),来协助汇编器生成最终包含 unwind table 的 .eh_frame section。\n\n以如下代码为例:\n\n```\n// demo.c\n\nint add(int a, int b) {\n return a + b;\n}\n```\n\n我们使用 cc -S demo.c 来生成汇编代码(gcc/clang 均可),注意这里并没有使用 -g 参数。\n\n```\n .section __TEXT,__text,regular,pure_instructions\n .build_version macos, 11, 0 sdk_version 11, 3\n .globl _add ## -- Begin function add\n .p2align 4, 0x90\n_add: ## @add\n .cfi_startproc\n## %bb.0:\n pushq %rbp\n .cfi_def_cfa_offset 16\n .cfi_offset %rbp, -16\n movq %rsp, %rbp\n .cfi_def_cfa_register %rbp\n movl %edi, -4(%rbp)\n movl %esi, -8(%rbp)\n movl -4(%rbp), %eax\n addl -8(%rbp), %eax\n popq %rbp\n retq\n .cfi_endproc\n ## -- End function\n.subsections_via_symbols\n```\n\n从生成的汇编代码中可以看到许多以 .cfi_ 为前缀的伪指令,它们便是 CFI Directives。\n\n## Heap Profiling with jemalloc\n\n接下来我们关注 jemalloc,这是因为 TiKV 默认使用 jemalloc 作为内存分配器,能否在 jemalloc 上顺利地进行 Heap Profiling 是值得我们关注的要点。\n\n\n### Usage\n\njemalloc 自带了 Heap Profiling 能力,但默认是不开启的,需要在编译时指定 --enable-prof 参数。\n\n```\n./autogen.sh\n./configure --prefix=/usr/local/jemalloc-5.1.0 --enable-prof\nmake\nmake install\n```\n\n与 tcmalloc 相同,我们可以选择通过 -ljemalloc 将 jemalloc 链接到程序,或通过 LD_PRELOAD 用 jemalloc 覆盖 libc 的 malloc() 实现。\n\n\n我们以 Rust 程序为例展示如何通过 jemalloc 进行 Heap Profiling。\n\n```\nfn main() {\n let mut data = vec![];\n loop {\n func1(&mut data);\n std::thread::sleep(std::time::Duration::from_secs(1));\n }\n}\n\nfn func1(data: &mut Vec>) {\n data.push(Box::new([0u8; 1024*1024])); // alloc 1mb\n func2(data);\n}\n\nfn func2(data: &mut Vec>) {\n data.push(Box::new([0u8; 1024*1024])); // alloc 1mb\n}\n```\n\n与 Go 一节中提供的 demo 类似,我们同样在 Rust 中每秒分配 2mb 堆内存,func1 和 func2 各分配 1mb,由 func1 调用 func2。\n\n\n直接使用 rustc 不带任何参数编译该文件,然后执行如下命令启动程序:\n\n```\n$ export MALLOC_CONF=\"prof:true,lg_prof_interval:25\"\n$ export LD_PRELOAD=/usr/lib/libjemalloc.so\n$ ./demo\n```\n\nMALLOC_CONF 用于指定 jemalloc 的相关参数,其中 prof:true 表示开启 profiler,log_prof_interval:25 表示每分配 2^25 字节(32mb)堆内存便 dump 一份 profile 文件。\n\n\n注:更多 MALLOC_CONF 选项可以参考[文档](http://jemalloc.net/jemalloc.3.html#tuning)。\n\n等待一段时间后,即可看到有一些 profile 文件产生。\n\n\n\n\njemalloc 提供了一个和 tcmalloc 的 pprof 类似的工具,叫 jeprof,事实上它就是由 pprof perl 脚本 fork 而来的,我们可以使用 jeprof 来审阅 profile 文件。\n\n```\n$ jeprof ./demo jeprof.7262.0.i0.heap\n```\n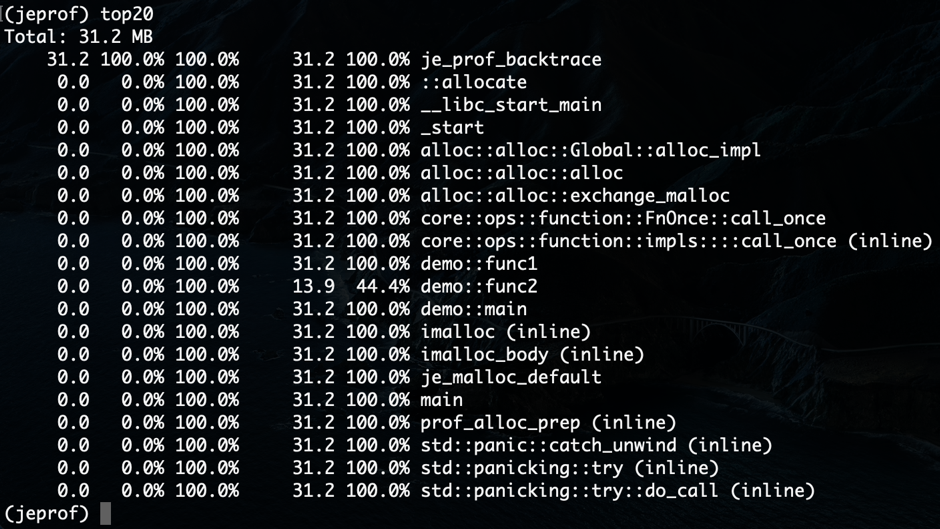\n\n\n同样可以生成与 Go/gperftools 相同的 graph:\n\n```\n$ jeprof --gv ./demo jeprof.7262.0.i0.heap\n```\n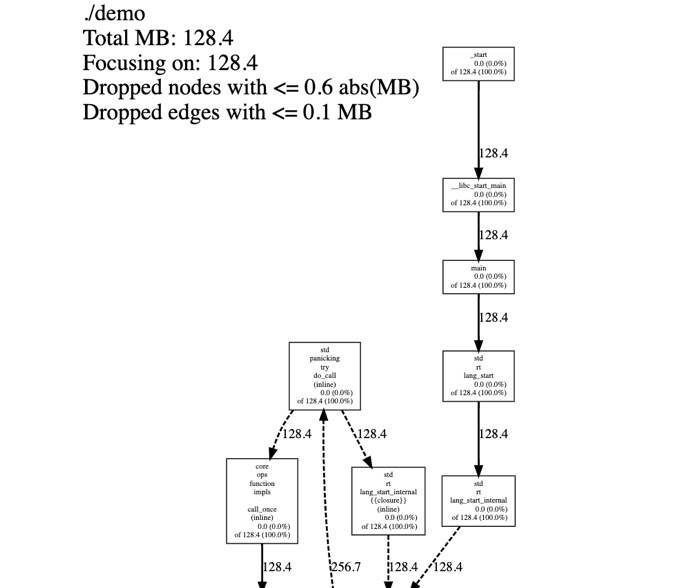\n\n\njeprof svg\n\n\n### Implementation details\n\n与 tcmalloc 类似,jemalloc 在 malloc() 中增加了采样逻辑:\n\n```\nJEMALLOC_ALWAYS_INLINE int\nimalloc_body(static_opts_t *sopts, dynamic_opts_t *dopts, tsd_t *tsd) {\n // ...\n // If profiling is on, get our profiling context.\n if (config_prof && opt_prof) {\n bool prof_active = prof_active_get_unlocked();\n bool sample_event = te_prof_sample_event_lookahead(tsd, usize);\n prof_tctx_t *tctx = prof_alloc_prep(tsd, prof_active,\n sample_event);\n\n emap_alloc_ctx_t alloc_ctx;\n if (likely((uintptr_t)tctx == (uintptr_t)1U)) {\n alloc_ctx.slab = (usize <= SC_SMALL_MAXCLASS);\n allocation = imalloc_no_sample(\n sopts, dopts, tsd, usize, usize, ind);\n } else if ((uintptr_t)tctx > (uintptr_t)1U) {\n allocation = imalloc_sample(\n sopts, dopts, tsd, usize, ind);\n alloc_ctx.slab = false;\n } else {\n allocation = NULL;\n }\n\n if (unlikely(allocation == NULL)) {\n prof_alloc_rollback(tsd, tctx);\n goto label_oom;\n }\n prof_malloc(tsd, allocation, size, usize, &alloc_ctx, tctx);\n } else {\n assert(!opt_prof);\n allocation = imalloc_no_sample(sopts, dopts, tsd, size, usize,\n ind);\n if (unlikely(allocation == NULL)) {\n goto label_oom;\n }\n }\n // ...\n}\n```\n\n在 prof_malloc() 中调用 prof_malloc_sample_object() 对 hashmap 中相应的调用栈记录进行累加:\n\n```\nvoid\nprof_malloc_sample_object(tsd_t *tsd, const void *ptr, size_t size,\n size_t usize, prof_tctx_t *tctx) {\n // ...\n malloc_mutex_lock(tsd_tsdn(tsd), tctx->tdata->lock);\n size_t shifted_unbiased_cnt = prof_shifted_unbiased_cnt[szind];\n size_t unbiased_bytes = prof_unbiased_sz[szind];\n tctx->cnts.curobjs++;\n tctx->cnts.curobjs_shifted_unbiased += shifted_unbiased_cnt;\n tctx->cnts.curbytes += usize;\n tctx->cnts.curbytes_unbiased += unbiased_bytes;\n // ...\n}\n```\n\njemalloc 在 free() 中注入的逻辑也与 tcmalloc 类似,同时 jemalloc 也依赖 libunwind 进行栈回溯,这里均不再赘述。\n\n## Heap Profiling with bytehound\n\nBytehound 是一款 Linux 平台的 Memory Profiler,用 Rust 编写。特点是提供的前端功能比较丰富,我们关注的重点在于它是如何实现的,以及能否在 TiKV 中使用,所以只简单介绍下基本用法。\n\n\n### Usage\n\n我们可以在 Releases 页面下载 bytehound 的二进制动态库,只有 Linux 平台的支持。\n\n然后,像 tcmalloc 或 jemalloc 一样,通过 LD_PRELOAD 挂载它自己的实现。这里我们假设运行的是 Heap Profiling with jemalloc 一节相同的带有内存泄漏的 Rust 程序:\n\n```\n$ LD_PRELOAD=./libbytehound.so ./demo\n```\n\n接下来在程序的工作目录会产生一个 memory-profiling_*.dat 文件,这便是 bytehound 的 Heap Profiling 产物。注意,与其它 Heap Profiler 不同的是,这个文件是持续更新的,而非每隔特定的时间就生成一个新的文件。\n\n接下来执行如下命令开启一个 web 端口用于实时分析上述文件:\n\n```\n$ ./bytehound server memory-profiling_*.dat\n```\n\n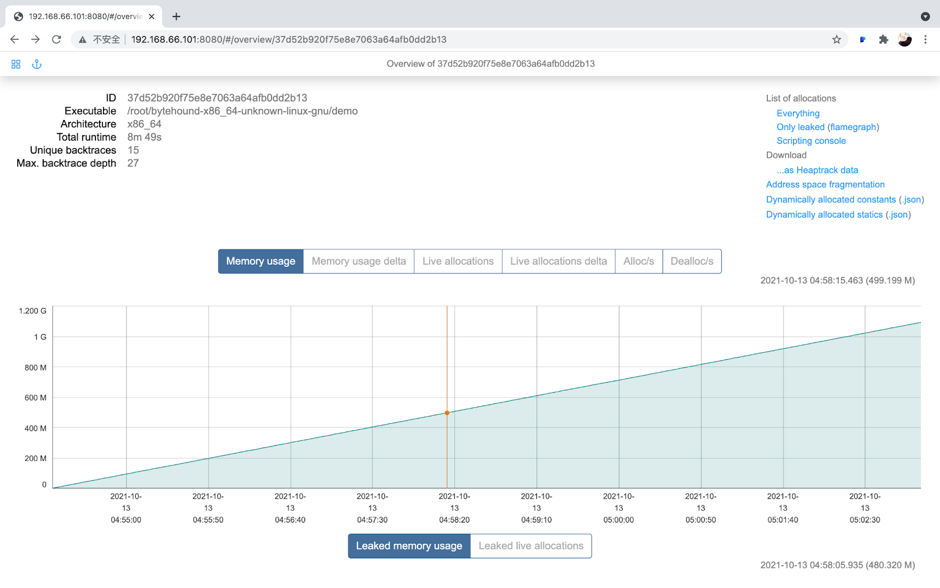\n\n\nBytehound GUI\n\n最直观的方法是点击右上角的 Flamegraph 查看火焰图:\n\n\n\nBytehound Flamegraph\n\n从图中可以轻易看出 demo::func1 与 demo::func2 的内存热点。\n\nBytehound 提供了丰富的 GUI 功能,这是它的一大亮点,大家可以参考[文档](https://koute.github.io/bytehound/introduction.html)自行探索。\n\n### Implementation details\n\nBytehound 同样是替换掉了用户默认的 malloc 实现,但 bytehound 本身并没有实现内存分配器,而是基于 jemalloc 做了包装。\n\n```\n// 入口\n#[cfg_attr(not(test), no_mangle)]\npub unsafe extern \"C\" fn malloc( size: size_t ) -> *mut c_void {\n allocate( size, AllocationKind::Malloc )\n}\n\n#[inline(always)]\nunsafe fn allocate( requested_size: usize, kind: AllocationKind ) -> *mut c_void {\n // ...\n // 调用 jemalloc 进行内存分配\n let pointer = match kind {\n AllocationKind::Malloc => {\n if opt::get().zero_memory {\n calloc_real( effective_size as size_t, 1 )\n } else {\n malloc_real( effective_size as size_t )\n }\n },\n // ...\n };\n // ...\n // 栈回溯\n let backtrace = unwind::grab( &mut thread );\n // ...\n // 记录样本\n on_allocation( id, allocation, backtrace, thread );\n pointer\n}\n\n// xxx_real 链接到 jemalloc 实现\n#[cfg(feature = \"jemalloc\")]\nextern \"C\" {\n #[link_name = \"_rjem_mp_malloc\"]\n fn malloc_real( size: size_t ) -> *mut c_void;\n // ...\n}\n```\n\n看起来在每次 malloc 时都会固定进行栈回溯和记录,没有采样逻辑。而在 on_allocation hook 中,分配记录被发送到了 channel,由统一的 processor 线程进行异步处理。\n\n```\npub fn on_allocation(\n id: InternalAllocationId,\n allocation: InternalAllocation,\n backtrace: Backtrace,\n thread: StrongThreadHandle\n) {\n // ...\n crate::event::send_event_throttled( move || {\n InternalEvent::Alloc {\n id,\n timestamp,\n allocation,\n backtrace,\n }\n });\n}\n\n#[inline(always)]\npub(crate) fn send_event_throttled< F: FnOnce() -> InternalEvent >( callback: F ) {\n EVENT_CHANNEL.chunked_send_with( 64, callback );\n}\n```\n\n而 EVENT_CHANNEL 的实现是简单的 Mutex>:\n\n```\npub struct Channel< T > {\n queue: Mutex< Vec< T > >,\n condvar: Condvar\n}\n```\n\n## Performance overhead\n\n本节我们来探寻一下前文所述的各个 Heap Profiler 的性能开销,具体测量方法因场景而异。\n\n所有测试均单独运行在下述物理机环境:\n\n\n| 主机 | Intel NUC11PAHi7 |\n| -------- | ------------------------------------------- |\n| CPU | Intel Core i7-1165G7 2.8GHz~4.7GHz 4核8线程 |\n| 内存 | Kingston 64G DDR4 3200MHz |\n| 硬盘 | Samsung 980PRO 1T SSD PCIe4. |\n| 操作系统 | Arch Linux Kernel-5.14.1 |\n\n\n### Go\n\n在 Go 中我们的测量方式是使用 TiDB + unistore 部署单节点,针对 runtime.MemProfileRate 参数进行调整然后分别用 sysbench 进行测量。\n\n相关软件版本及压测参数数据:\n\n| Go Version | 1.17.1 |\n| ------------ | ---------------------------------------- |\n| TiDB Version | v5.3.0-alpha-1156-g7f36a07de |\n| Commit Hash | 7f36a07de9682b37d46240b16a2107f5c84941ba |\n| **Sysbench** | \n| Version | 1.0.20 |\n| Tables | 8 |\n| TableSize | 100000 |\n| Threads | 128 |\n| Operation | oltp_read_only |\n\n得到的结果数据:\n\n| MemProfileRate | 结论 |\n| -------------- | ------------------------------------------------------------ |\n| 0: 不记录 | Transactions: 1505224 (2508.52 per sec.)
Queries: 24083584 (40136.30 per sec.)
Latency (AVG): 51.02
Latency (P95): 73.13 |\n| 512k: 采样记录 | Transactions: 1498855 (2497.89 per sec.)
Queries: 23981680 (39966.27 per sec.)
Latency (AVG): 51.24
Latency (P95): 74.46 |\n| 1: 全量记录 | Transactions: 75178 (125.18 per sec.)
Queries: 1202848 (2002.82 per sec.)
Latency (AVG): 1022.04
Latency (P95): 2405.65 |\n\n\n相较 “不记录” 来说,无论是 TPS/QPS,还是 P95 延迟线,**512k 采样记录的性能损耗基本都在 1% 以内**。而 “全量记录” 带来的性能开销符合“会很高”的预期,但却高的出乎意料:**TPS/QPS 缩水了 20 倍,P95 延迟增加了 30 倍**。\n\n由于 Heap Profiling 是一项通用功能,我们无法准确的给出所有场景下的通用性能损耗,只有在特定项目下的测量结论才有价值。TiDB 是一个相对偏计算密集型的应用,内存分配频率可能不及一些内存密集型应用,因此该结论(及后续所有结论)仅可用做参考,读者可自行测量自身应用场景下的开销。\n\n### tcmalloc/jemalloc\n\n我们基于 TiKV 来测量 tcmalloc/jemalloc,方法是在机器上部署一个 PD 进程和一个 TiKV 进程,采用 go-ycsb 进行压测,关键参数如下:\n\n```\nthreadcount=200\nrecordcount=100000\noperationcount=1000000\nfieldcount=20\n```\n\n在启动 TiKV 前分别使用 LD_PRELOAD 注入不同的 malloc hook。其中 tcmalloc 使用默认配置,即类似 Go 的 512k 采样;jemalloc 使用默认采样策略,且每分配 1G 堆内存就 dump 一份 profile 文件。\n\n\n最终得到如下数据:\n\n| default | OPS: **119037.2** Avg(us): 4186 99th(us): **14000** |\n| ------------ | ----------------------------------------------------- |\n| **tcmalloc** | OPS: **113708.8** Avg(us): 4382 99th(us): **16000** |\n| **jemalloc** | OPS: **114639.9** Avg(us): 4346 99th(us): **15000** |\n\ntcmalloc 与 jemalloc 的表现相差无几,OPS 相较默认内存分配器下降了 4% 左右,P99 延迟线上升了 10% 左右。\n\n\n在前边我们已经了解到 tcmalloc 的实现和 Go heap pprof 的实现基本相同,但这里测量出来的数据却不太一致,推测原因是 TiKV 与 TiDB 的内存分配特征存在差异,这也印证了前文所讲的:“我们无法准确的给出所有场景下的通用性能损耗,只有在特定项目下的测量结论才有价值”。\n\n### bytehound\n\n我们没有将 bytehound 与 tcmalloc/jemalloc 放在一起的原因是在 TiKV 上实际使用 bytehound 时会在启动阶段遇到死锁问题。\n\n由于我们推测 **bytehound 的性能开销会非常高**,理论上是无法应用在 TiKV 生产环境的,所以我们只需印证这个结论即可。\n\n注:推测性能开销高的原因是在 bytehound 代码中没有找到采样逻辑,每次采集到的数据通过 channel 发送给后台线程处理,而 channel 也只是简单使用 Mutex + Vec 封装了下。\n\n我们选择一个简单的 [mini-redis](https://github.com/tokio-rs/mini-redis) 项目来测量 bytehound 性能开销,由于目标仅仅是确认是否能够满足 TiKV 生产环境使用的要求,而不是精确测量数据,所以我们只简单统计并对比其 TPS 即可,具体 driver 代码片段如下:\n\n```\nvar count int32\n\nfor n := 0; n < 128; n++ {\n go func() {\n for {\n key := uuid.New()\n err := client.Set(key, key, 0).Err()\n if err != nil {\n panic(err)\n }\n err = client.Get(key).Err()\n if err != nil {\n panic(err)\n }\n atomic.AddInt32(&count, 1)\n }\n }()\n}\n```\n\n开启 128 goroutine 对 server 进行读写操作,一次读/写被认为是一次完整的 operation,其中仅仅对次数进行统计,没有测量延迟等指标,最终使用总次数除以执行时间,得到开启 bytehound 前后的不同 TPS,数据如下:\n\n| 默认 | Count: 11784571 Time: 60s TPS: 196409 |\n| :----------------: | ------------------------------------------- |\n| **开启 bytehound** | **Count: 5660952 Time: 60s TPS: 94349** |\n\n\n**从结果来看 TPS 损失了 50% 以上**。\n\n## What can BPF bring\n\n虽然 BPF 性能开销很低,但基于 BPF 很大程度上只能拿到系统层面的指标,通常意义上的 Heap Profiling 需要在内存分配链路上进行统计,**但内存分配是趋于分层的。**\n\n\n举个例子,如果我们在自己的程序里提前 malloc 了一大块堆内存作为内存池,自己设计了分配算法,接下来所有业务逻辑所需的堆内存全都从内存池里自行分配,那么现有的 Heap Profiler 就没法用了。因为它只告诉你你在启动阶段申请了一大段内存,其它时候的内存申请数量为0。在这种场景下我们就需要侵入到自己设计的内存分配代码中,在入口处做 Heap Profiler 该做的事情。\n\nBPF 的问题与此类似,我们可以挂个钩子在 brk/sbrk 上,当用户态真正需要向内核申请扩容堆内存时,对当前的 stack trace 进行记录。然而内存分配器是复杂的黑盒,最常触发 brk/sbrk 的用户栈不一定就是导致内存泄漏的用户栈。这需要做一些实验来验证,如果结果真的有一定价值,那么将 BPF 作为低成本的兜底方案长期运行也未尝不可(需要额外考虑 BPF 的权限问题)。\n\n至于 uprobe,只是无侵入的代码植入,对于 Heap Profiling 本身还是要在 allocator 里走相同的逻辑,进而带来相同的开销,而我们对代码的侵入性并不敏感。\n\n[https://github.com/parca-dev/parca](https://github.com/parca-dev/parca) 实现了基于 BPF 的 Continuous Profiling,但真正利用了 BPF 的模块其实只有 CPU Profiler。在 bcc-tools 中已经提供了一个 Python 工具用来做 CPU Profiling([https://github.com/iovisor/bcc/blob/master/tools/profile.py](https://github.com/iovisor/bcc/blob/master/tools/profile.py)),核心原理是相同的。对于 Heap Profiling 暂时没有太大的借鉴意义。\n","date":"2021-11-17","author":"张业祥","fillInMethod":"writeDirectly","customUrl":"an-explanation-of-the-heap-profiling-principle","file":null,"relatedBlogs":[]}}},
"staticQueryHashes": ["1327623483","1820662718","3081853212","3430003955","3649515864","4265596160","63159454"]}